
python基于百度unit实现语音识别与语音交互
一、百度Unit新建机器人
网址:https://ai.baidu.com/tech/speech/asr:
1、新建机器人并添加预置技能步骤
(1)、新建机器人(添加预置技能),并填写机器人具体信息
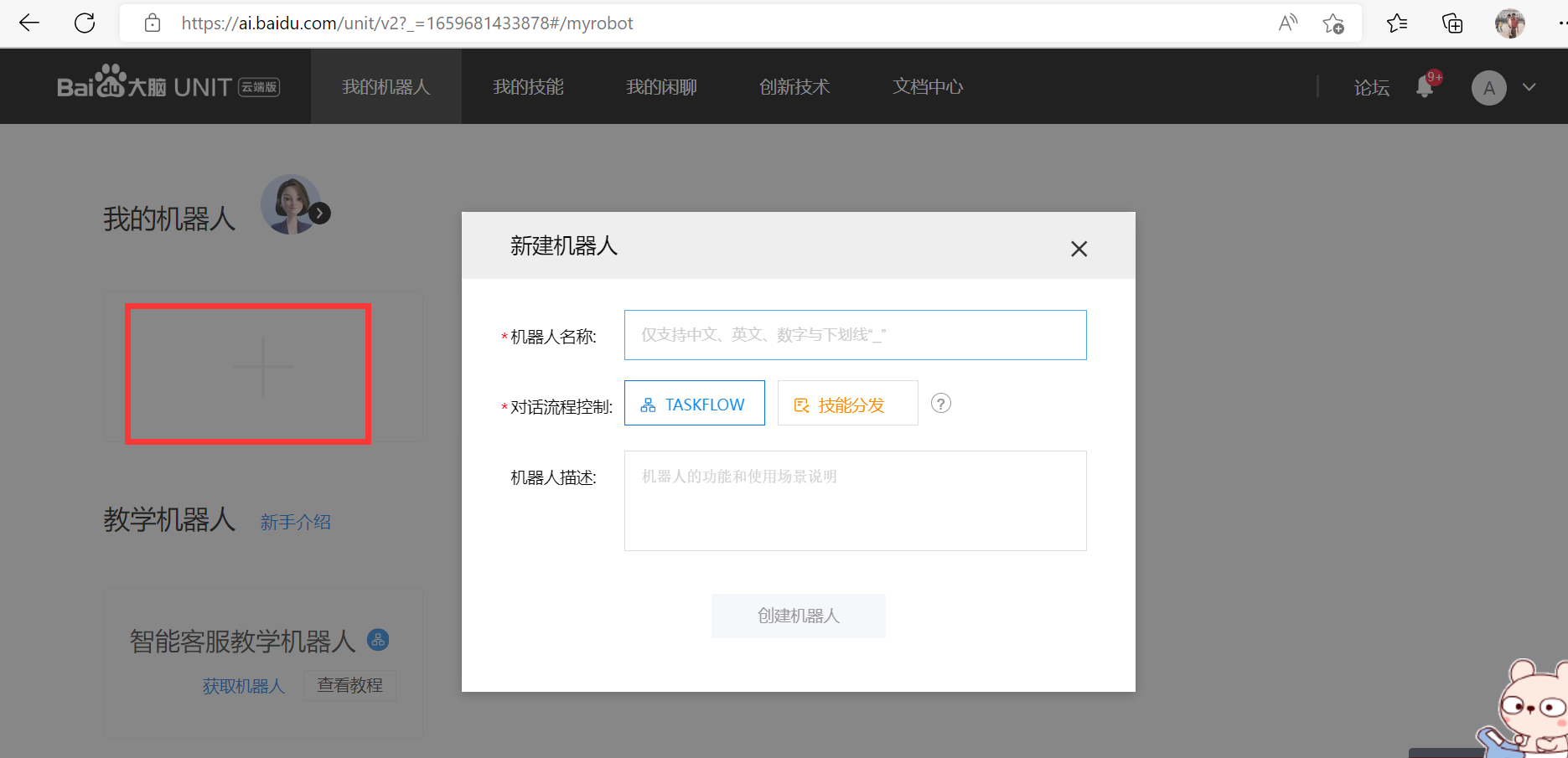
(2)、进入新建的机器人 -> 选择技能管理 -> 添加技能
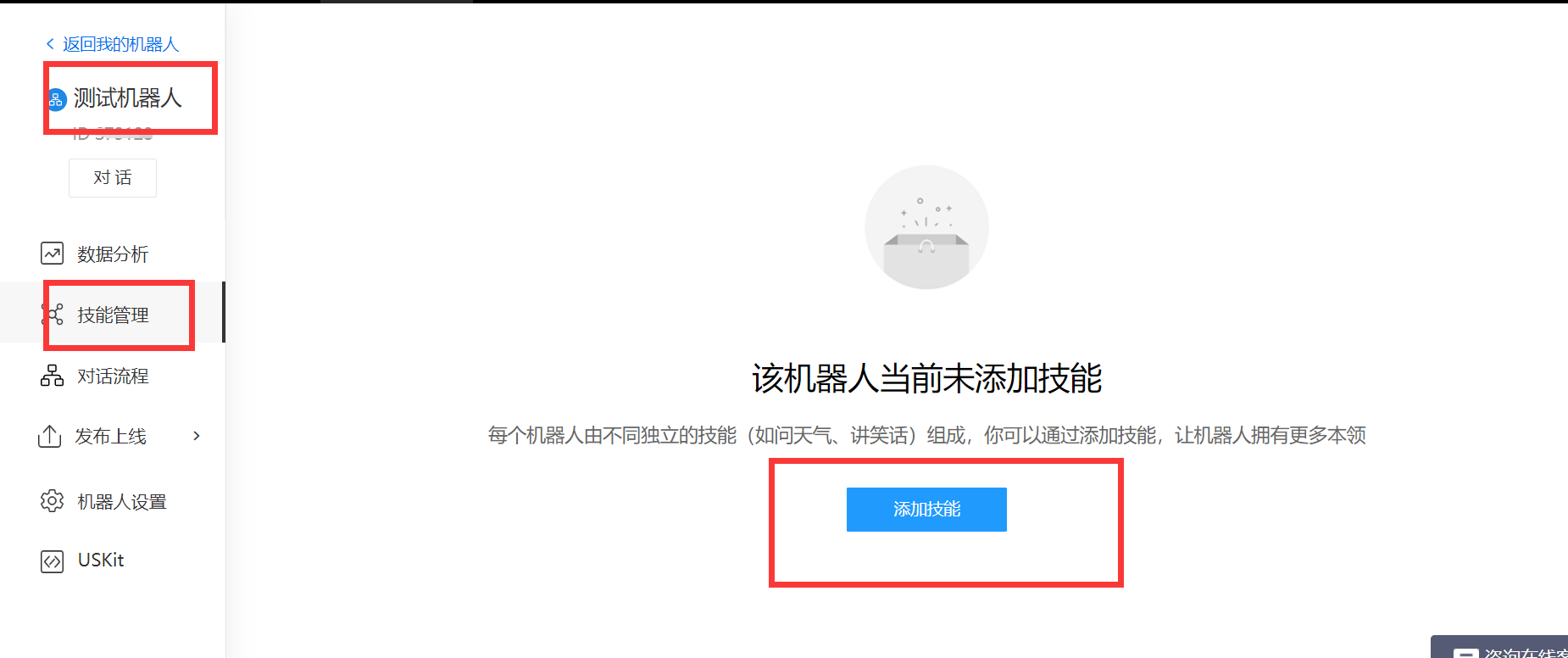
(3)、可以选择预置技能 -> 进度条拉到最后 -> 闲聊功能 ->获取该技能
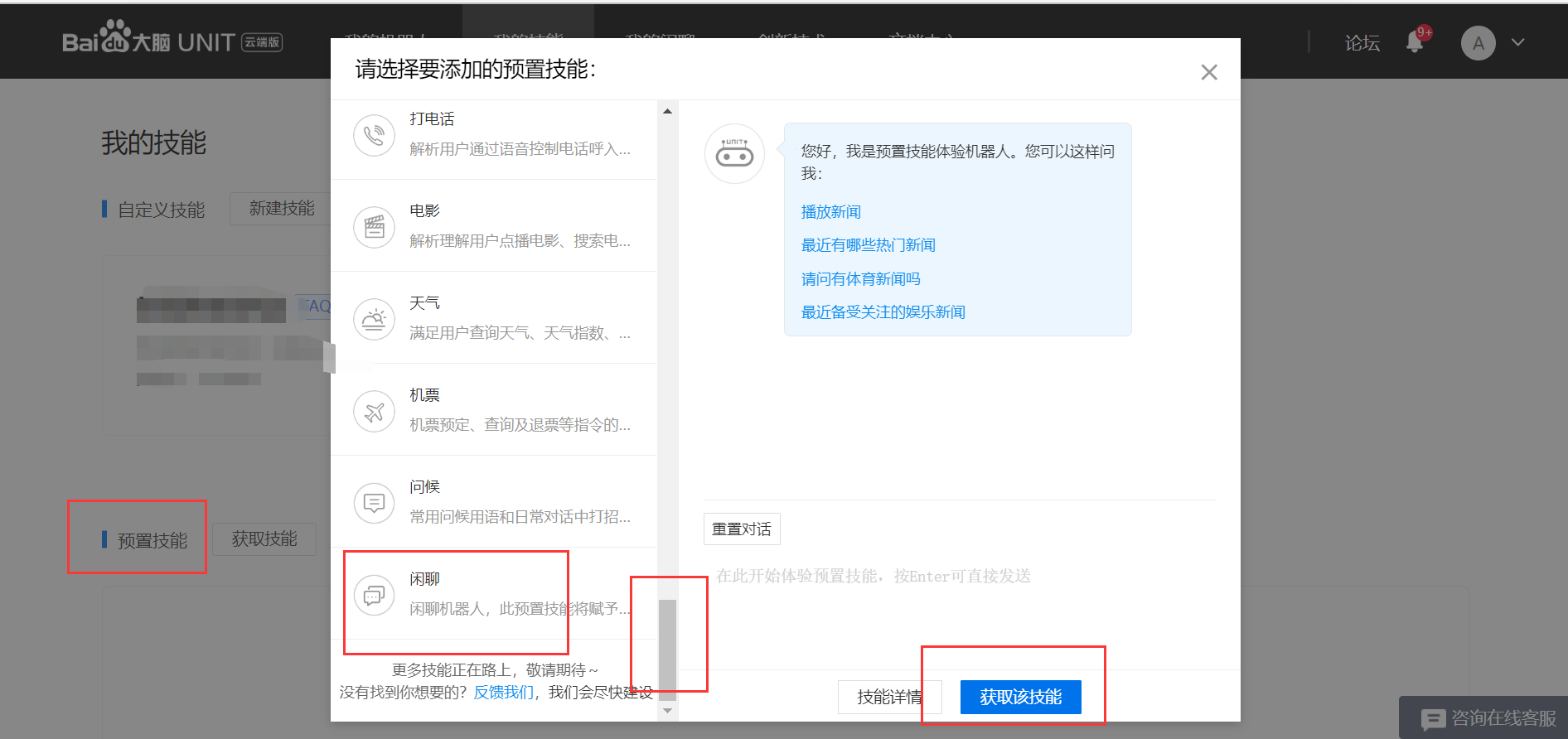
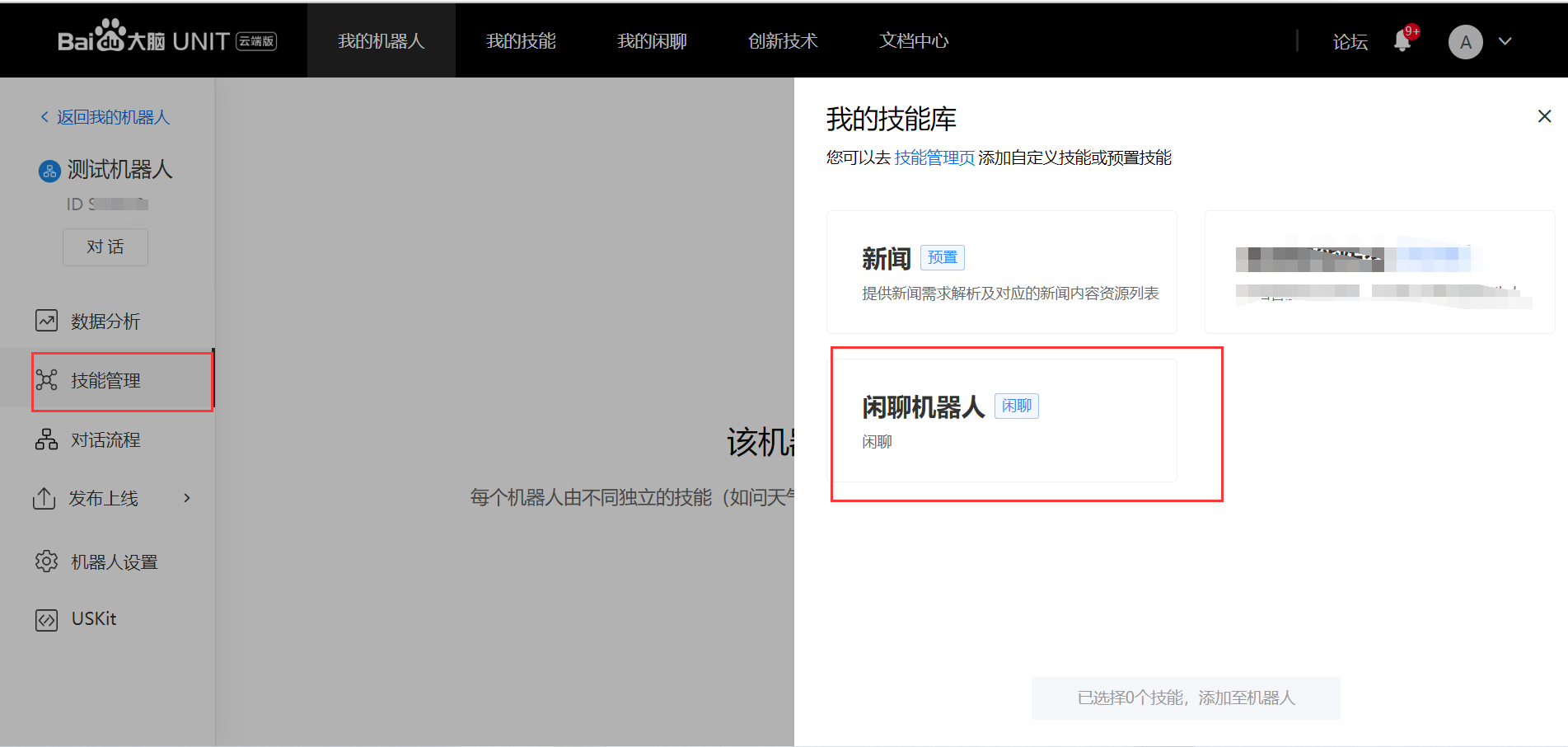
(4)、技能管理 ->将闲聊机器人添加到技能中
(5)、发布上线 -> 研发环境 ->获取API key / Secret Key
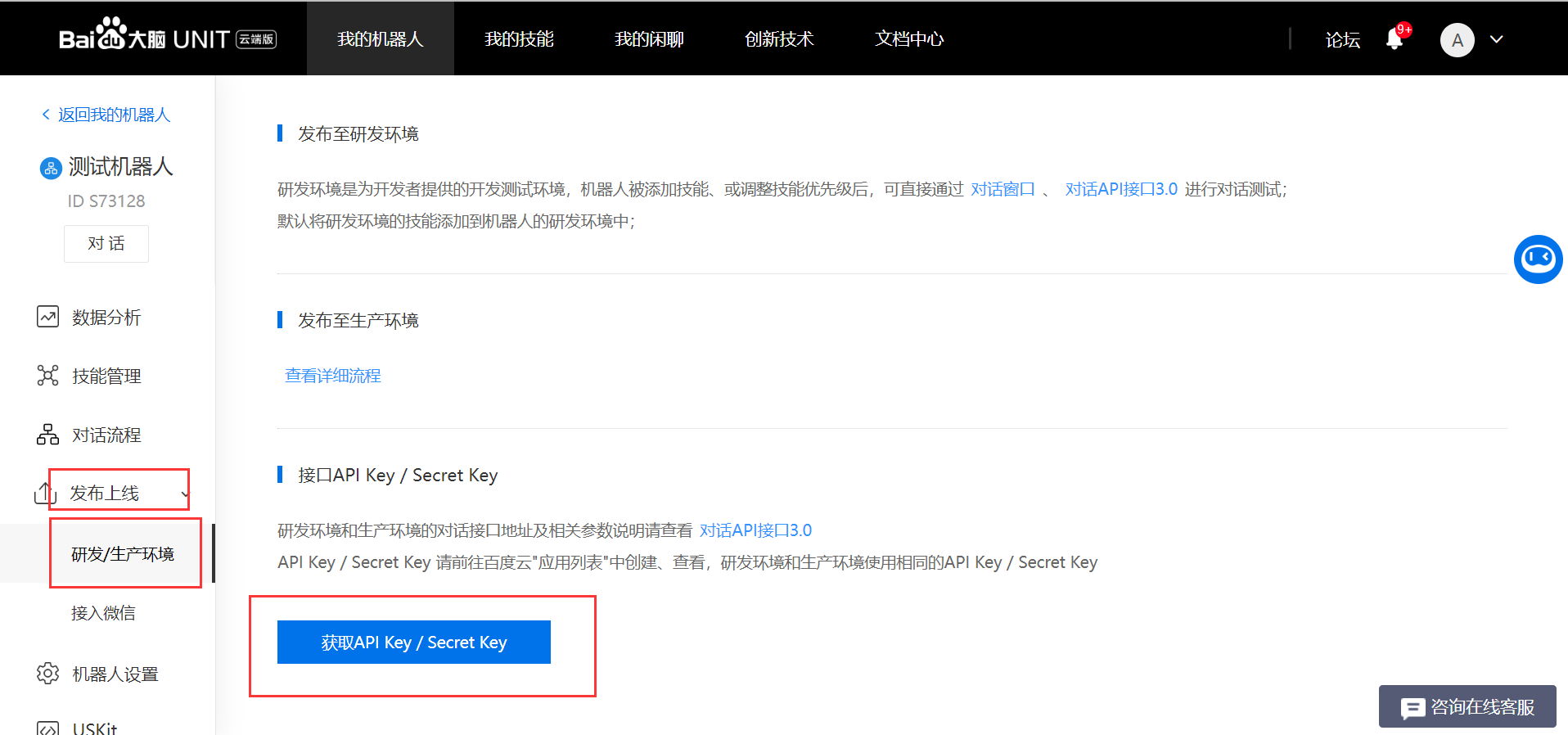
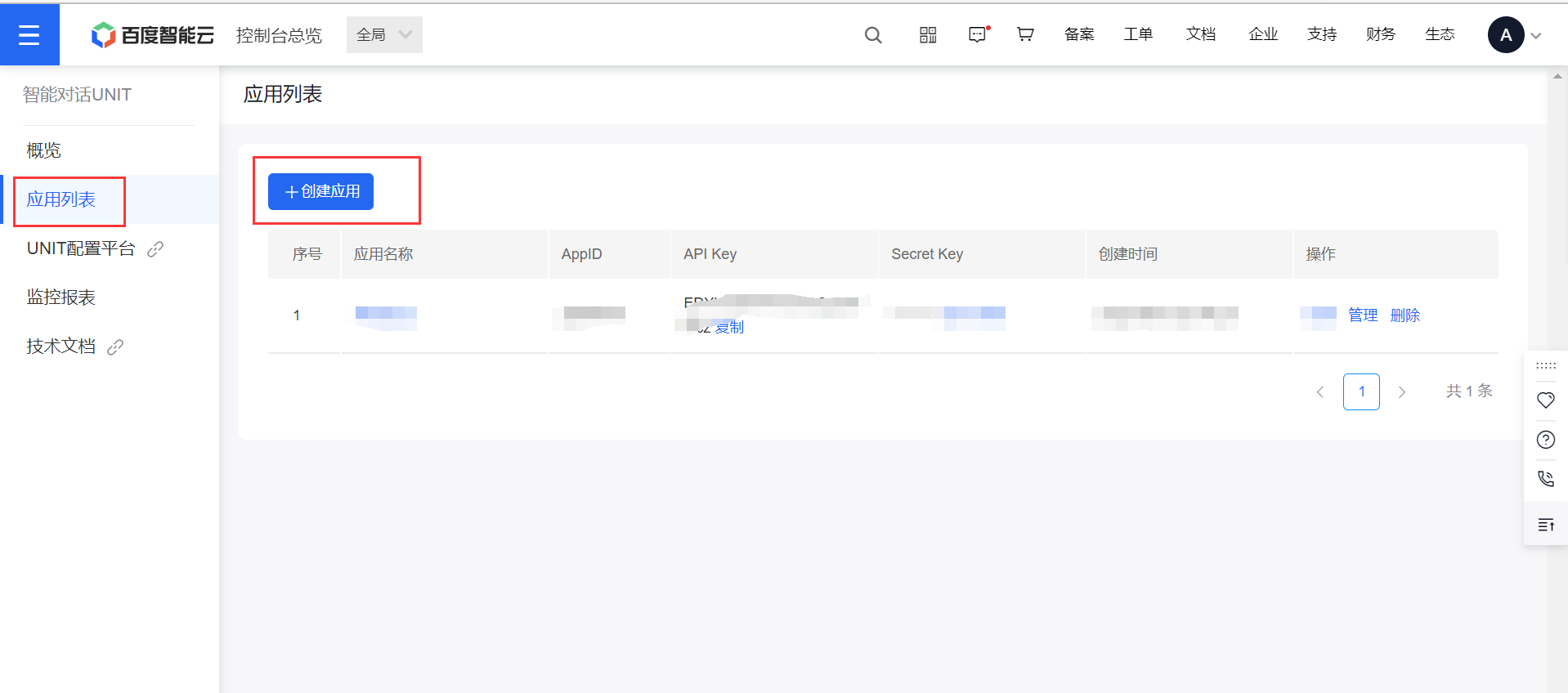
(6)、应用列表 -> 创建应用
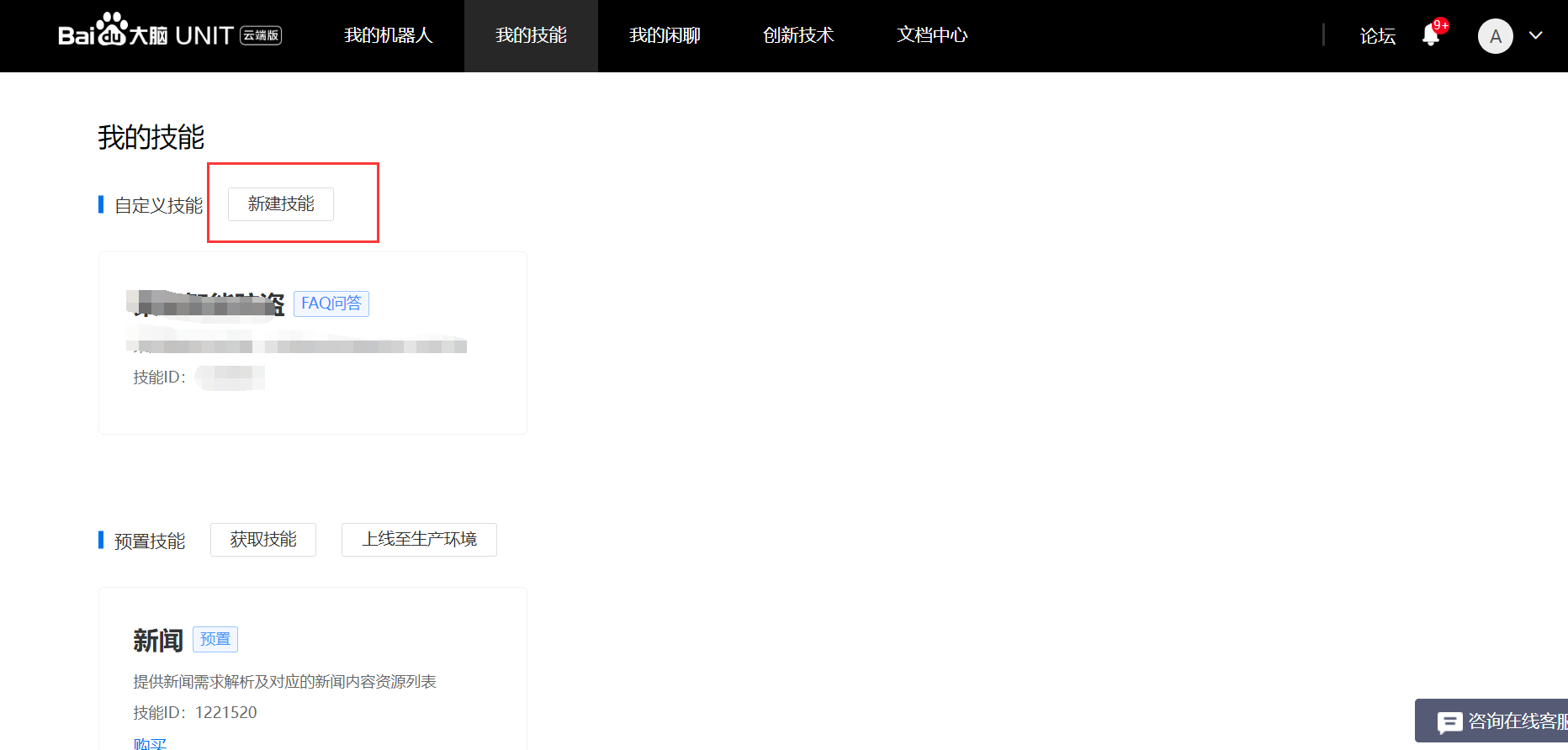
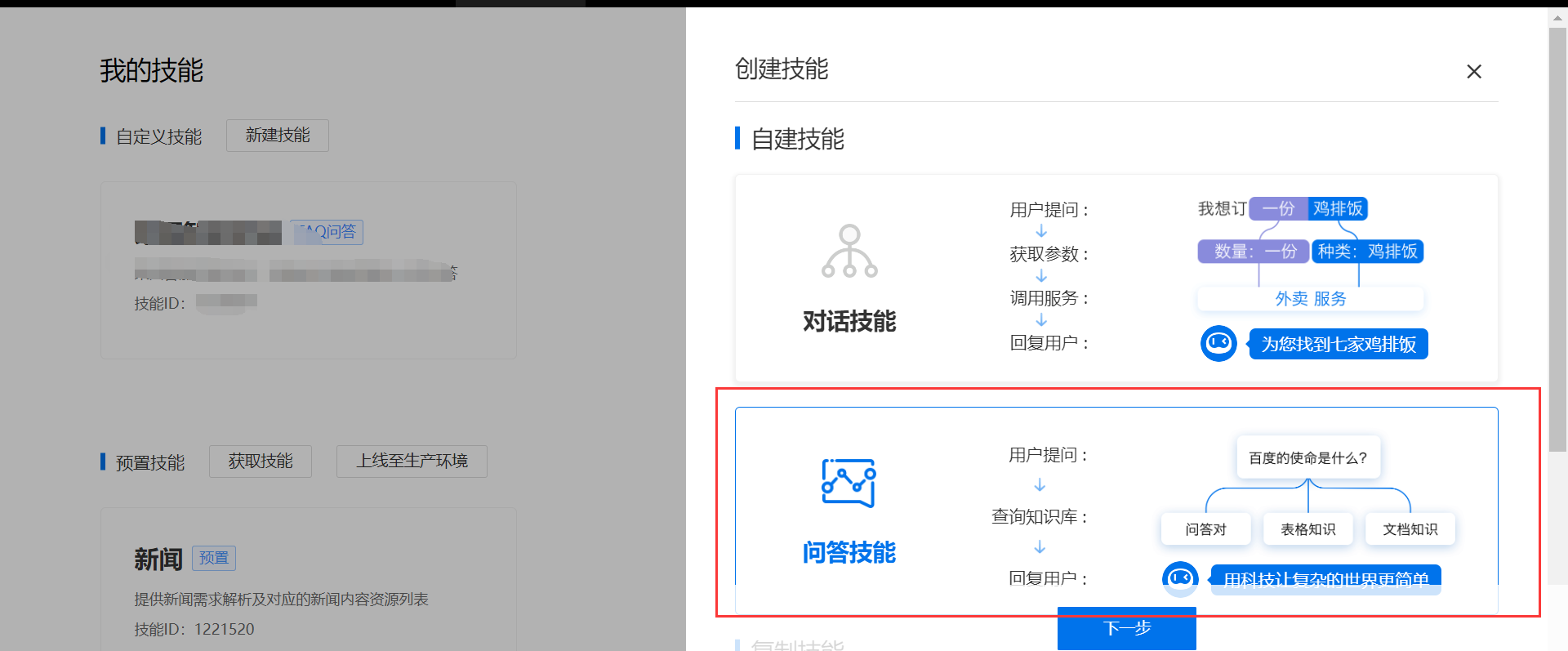
2、新建机器人并添加自定义技能步骤
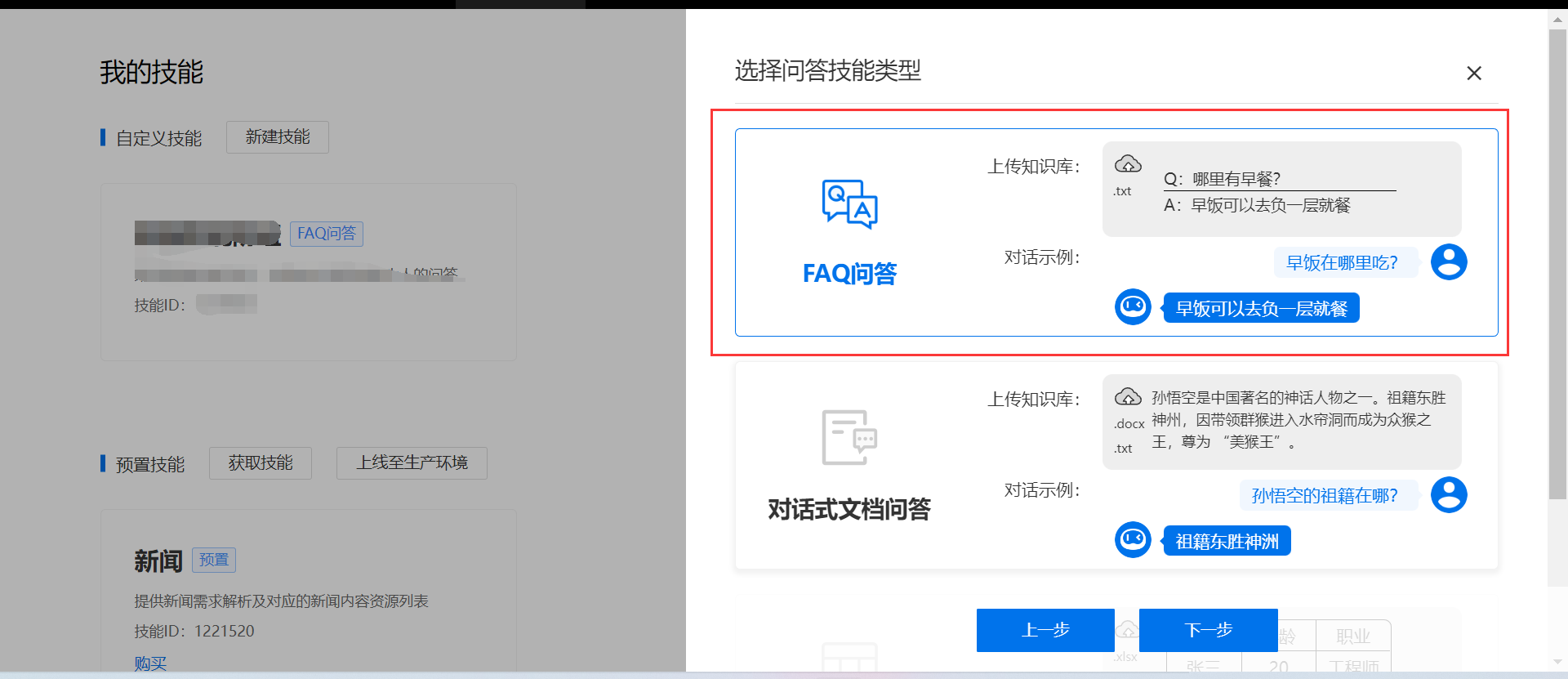
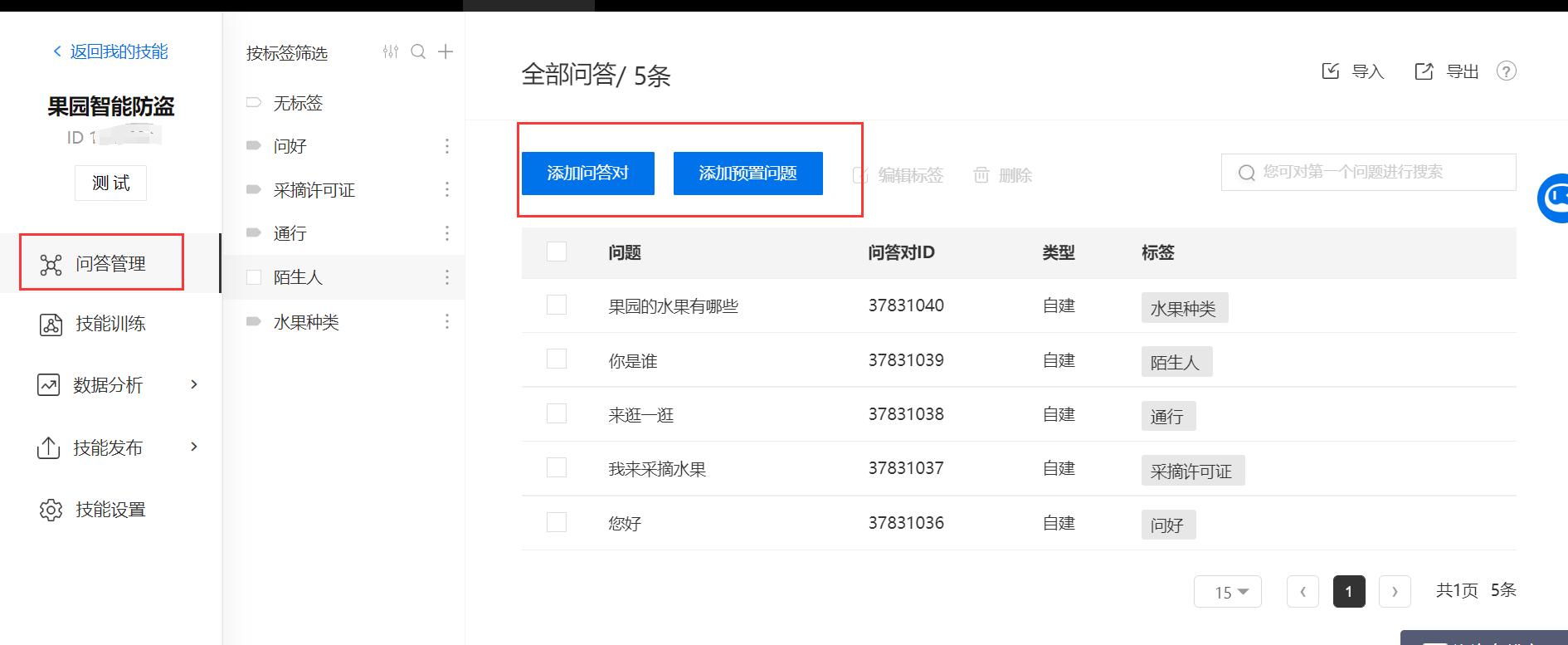
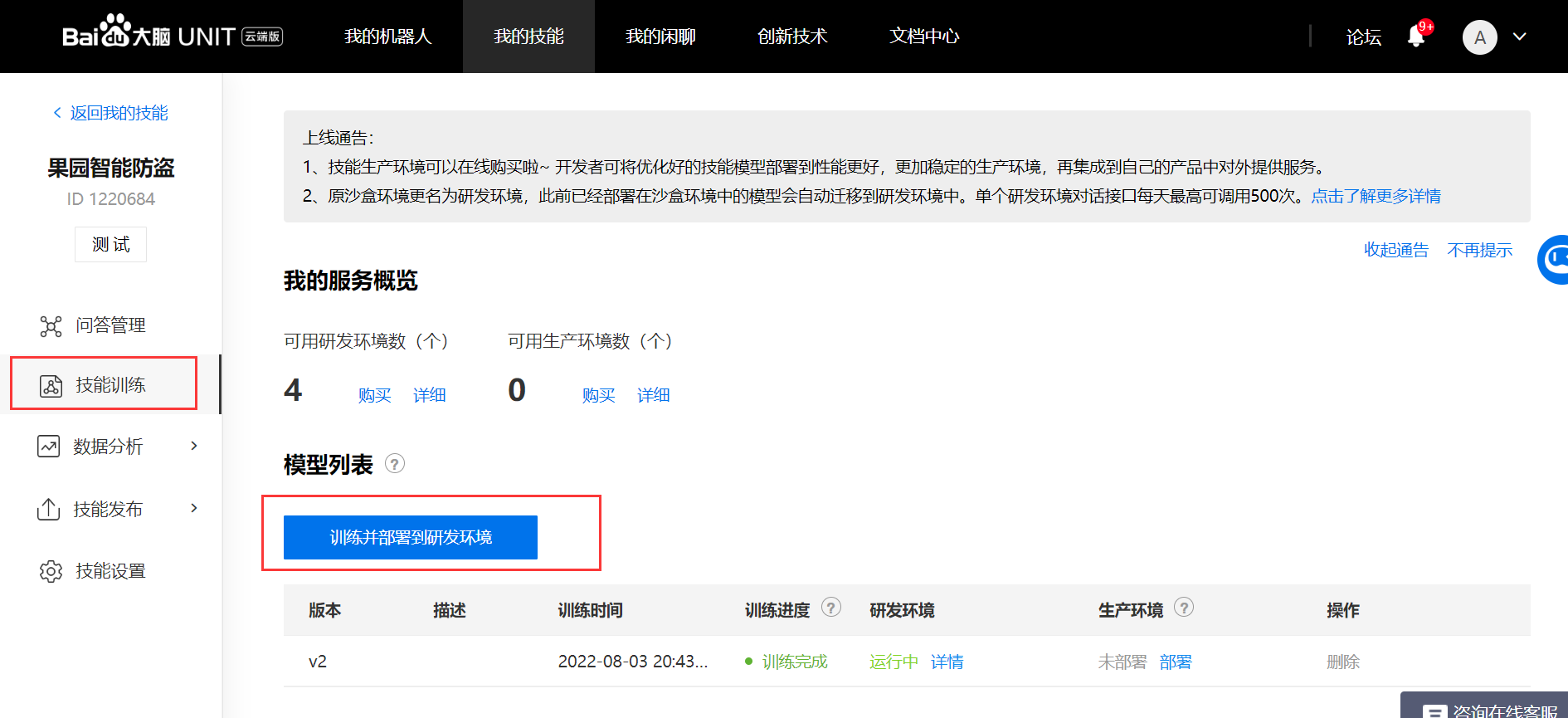
二、代码
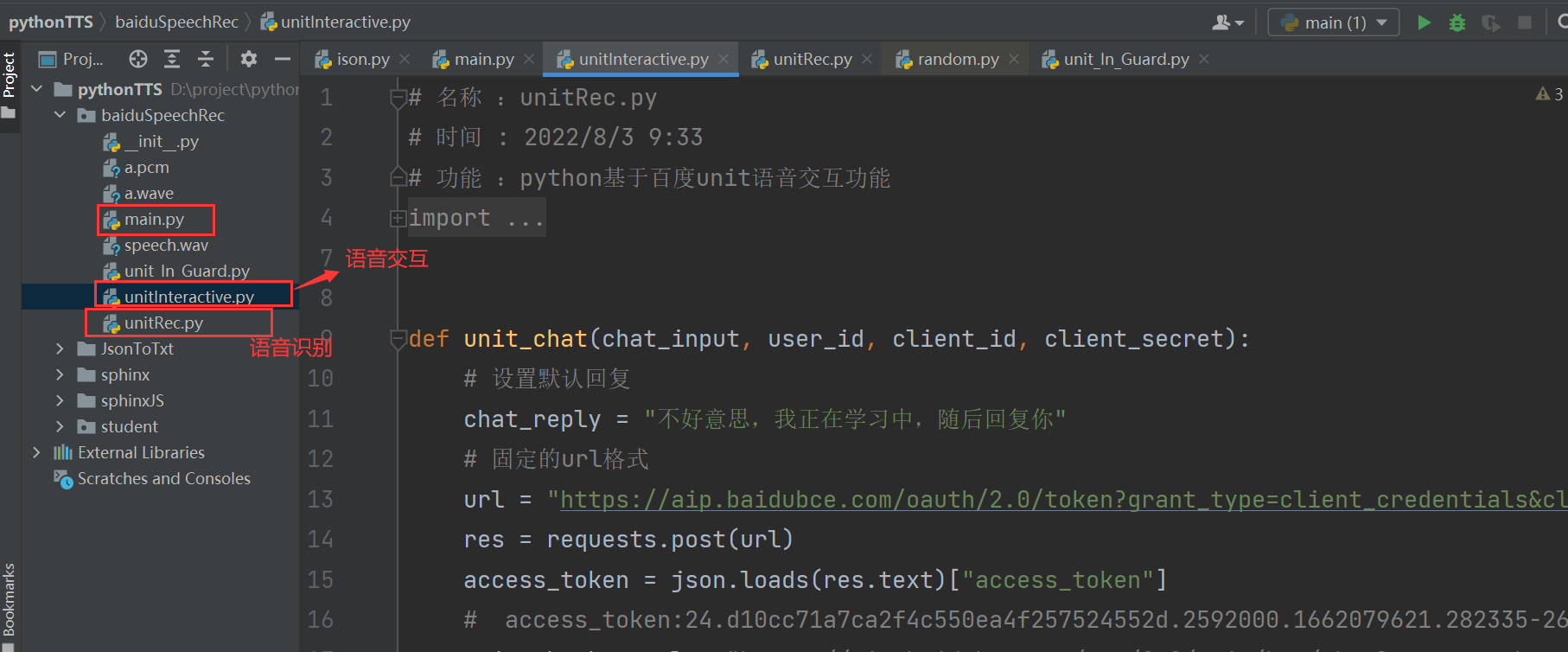
unitRec.py:
# 名称 :unitRec.py # 时间 : 2022/8/3 9:33 # 功能 :python基于百度unit语音识别功能 import wave import requests import time import base64 from pyaudio import PyAudio, paInt16 import webbrowser framerate = 16000 # 采样率 num_samples = 2000 # 采样点 channels = 1 # 声道 sampwidth = 2 # 采样宽度2bytes def getToken(host): res = requests.post(host) return res.json()['access_token'] def save_wave_file(filepath, data): wf = wave.open(filepath, 'wb') wf.setnchannels(channels) wf.setsampwidth(sampwidth) wf.setframerate(framerate) wf.writeframes(b''.join(data)) wf.close() def my_record(FILEPATH): pa = PyAudio() stream = pa.open(format=paInt16, channels=channels, rate=framerate, input=True, frames_per_buffer=num_samples) my_buf = [] # count = 0 t = time.time() # print('正在录音...') while time.time() < t + 3: # 秒 string_audio_data = stream.read(num_samples) my_buf.append(string_audio_data) # print('录音结束.') save_wave_file(FILEPATH, my_buf) stream.close() def get_audio(file): with open(file, 'rb') as f: data = f.read() return data def speech2text(speech_data, token, dev_pid): FORMAT = 'wav' RATE = '16000' CHANNEL = 1 CUID = '*******' SPEECH = base64.b64encode(speech_data).decode('utf-8') data = { 'format': FORMAT, 'rate': RATE, 'channel': CHANNEL, 'cuid': CUID, 'len': len(speech_data), 'speech': SPEECH, 'token': token, 'dev_pid': dev_pid } url = 'https://vop.baidu.com/server_api' headers = {'Content-Type': 'application/json'} # r=requests.post(url,data=json.dumps(data),headers=headers) # print('正在识别...') r = requests.post(url, json=data, headers=headers) Result = r.json() if 'result' in Result: return Result['result'][0] else: return Result def openbrowser(text): maps = { '百度': ['百度', 'baidu'], '腾讯': ['腾讯', 'tengxun'], '网易': ['网易', 'wangyi'] } if text in maps['百度']: webbrowser.open_new_tab('https://www.baidu.com') elif text in maps['腾讯']: webbrowser.open_new_tab('https://www.qq.com') elif text in maps['网易']: webbrowser.open_new_tab('https://www.163.com/') else: webbrowser.open_new_tab('https://www.baidu.com/s?wd=%s' % text)
unitInteractive.py:
# 名称 :unitInteractive.py # 时间 : 2022/8/3 9:33 # 功能 :python基于百度unit语音交互功能 import json import random import requests def unit_chat(chat_input, user_id, client_id, client_secret): # 设置默认回复 chat_reply = "不好意思,我正在学习中,随后回复你" # 固定的url格式 url = "https://aip.baidubce.com/oauth/2.0/token?grant_type=client_credentials&client_id=%s&client_secret=%s"%(client_id, client_secret) res = requests.post(url) access_token = json.loads(res.text)["access_token"] # access_token:24.d10cc71a7ca2f4c550ea4f257524552d.2592000.1662079621.282335-26807073 unit_chatbot_url = "https://aip.baidubce.com/rpc/2.0/unit/bot/chat?access_token=" + access_token # 拼装聊天接口对应请求 post_data = { "log_id": str(random.random()), # 登陆的id,是什么不重要,我们用随机数生成一个id即可 "request": { "query": chat_input, # 用户输入的内容 "user_id": user_id # 用户id }, "session_id": "",
# 机器人ID:机器人下面带着的id "service_id": "****", "version": "2.0", "encode": "utf-8", # 技能id 闲聊ID: 12**** 防盗系统ID:12**** "bot_id": "1220***", } # 将聊天接口对应请求数据转为json数据 res = requests.post(url=unit_chatbot_url, json=post_data) # 获取聊天接口返回数据 unit_chat_obj = json.loads(res.content) # print(unit_chat_obj) # 判断聊天接口返回数据是否出错(error_code == 0则表示请求正确) if unit_chat_obj["error_code"] != 0: return chat_reply # 解析聊天接口返回数据,找到返回文本内容 result -> response -> action_list -> say unit_chat_obj_result = unit_chat_obj["result"] # print(unit_chat_obj_result) unit_chat_response = unit_chat_obj_result["response"] unit_chat_response_schema = unit_chat_response["schema"] # print(unit_chat_response_schema.slots) unit_chat_response_slots_list = unit_chat_response_schema["slots"] unit_chat_response_slots_obj = random.choice(unit_chat_response_slots_list) unit_chat_response_reply = unit_chat_response_slots_obj["normalized_word"] return unit_chat_response_reply # if __name__ == "__main__": # while True: # chat_input = input("请输入:") # if chat_input == 'Bye' or chat_input == "bye": # break # chat_reply = unit_chat(chat_input) # print("Unit:", chat_reply)
main.py:
# 名称 : mian.py
# 时间 : 2022/8/3 9:33 # 功能 :主函数 import unitRec import unit_In_Guard as UI import pyttsx3 base_url = "https://openapi.baidu.com/oauth/2.0/token?grant_type=client_credentials&client_id=%s&client_secret=%s" # 填写自己的语音识别接口key和secretkey
# 语音识别百度unit网址:https://console.bce.baidu.com/ai/#/ai/speech/app/list
APIKey = "oPm6vuaOKjFwr8tOBq***" SecretKey = "cidsvzuO75snttKOnTmtw****" # 填写自己的语音交互key和secretkey
# 语音交互百度unit网址:https://ai.baidu.com/unit/v2#/myrobot
client_id = "EDYbuiSbkYK1skiG****" client_key = "HLhTqZ4zDl1B4coeRG7xj*** HOST = base_url % (APIKey, SecretKey) FILEPATH = 'speech.wav' # 语音ttx初始化 engine = pyttsx3.init() if __name__ == '__main__': while True: # devpid = input('1536:普通话(简单英文),1537:普通话(有标点),1737:英语,1637:粤语,1837:四川话\n') print('请普通话语音输入: ') unitRec.my_record(FILEPATH) TOKEN = unitRec.getToken(HOST) speech = unitRec.get_audio(FILEPATH) # 设置语音输入默认为普通话 int(devpid) = 1537 result = unitRec.speech2text(speech, TOKEN, 1537) if 'result' in result: print(result['result'][0]) else: print("语音输入内容: ", result) chat_input = result if chat_input == '拜拜' or chat_input == "拜。": break user_id = "88888" # 默认user_id都为88888 chat_reply = UI.unit_chat(chat_input, user_id, client_id, client_key) print("交互输出: ", chat_reply) engine.say(chat_reply) # 合成并播放语音 engine.runAndWait() # 等待语音播放完
三、反思
(1)可使用postman查看接口是否调通
(2)交互接口返回的json格式有区别,注意打印调试
(3)语音播放使用Python中的TTS

 浙公网安备 33010602011771号
浙公网安备 33010602011771号