spark
--启动spark集群的步骤: #step1:启动zookeeper ./ssh_all.sh /usr/local/zookeeper/bin/zkServer.sh start #step2:启动spark /usr/local/spark/sbin/start-all.sh #step3:在nn2.hadoop节点启动spark ha /usr/local/spark/sbin/start-master.sh
1.spark都有什么特色?
大量使用内存进行计算,中间结果尽量避免落地磁盘,速度快,类实时,将数据流赞成一个个小批次处理,生态圈比较丰富,有spark-core,spark-sql,spark-streaming等等
spark相对于mr来说的优势是:
(1)spark可以把多次使用的数据放到内存中(2)spark会的算法多,方便处理数据(3)spark大部分算子都没有shuffle阶段,不会频繁的落地磁盘,降低了磁盘的IO (4)在代码的编写方面,不需要写那么复杂的MapReduce逻辑
2.为什么有的公司偏向于spark on yarn 而不是StandAlone模式?
主要是为了提高资源的利用率
3.spark的运行模式有哪些?
Standalone 模式 (spark集群模式) spark on yarn 模式 local模式指的是spark job在一台机器上面跑
4.spark主要是替代hadoop的什么部分?
mapreduce计算模型
5.spark与MapReduce相比,有什么优缺点?
优点:使用的是内存计算,速度快。中间结果避免落地磁盘。 缺点:大量的使用内存 可能会造成内存的不足
6.spark生态都有哪些主要组件,它们分别都解决了什么问题?
spark core 计算处理 批量运算 spark sql sql分析 spark streaming 流式处理
7.详细说一下spark提交任务的流程
(1)启动work时候,把节点资源的情况上报
(2)driver节点提交代码端,执行sparkContext初始化,向集群管理端master节点申请资源
(3)集群管理端master节点给资源开启executor
(4) executor和driver端通信driver端知道要下发的任务在哪一个executor上执行 (本地化处理,数据不动,计算动)
(5)driver端把代码,序列化传输到对应的executor,会遵循移动计算,不移动数据的原则,executor会启动线程运行任务,driver端监控任务的运行情况
8.sparkHA的自动切换模式是借助什么实现的?
zookeeper
9.spark架构中,driver master worker executor task分别起什么作用?分别对应yarn的什么进程
driver 申请资源 提交application,管理该任务的Executor 对应yarn的client和ApplicationMaster
master 管理work子节点 调度资源 接收任务请求 对应yarn的resourcemanager
worker开启executor 对应NodeManager
executor 计算task 对应container
task 具体的计算任务 对应于map task reduce task
10.什么是RDD,它具有什么主要特性?
RDD弹性分布式数据集,代表可并行操作元素的不可变分区集合,
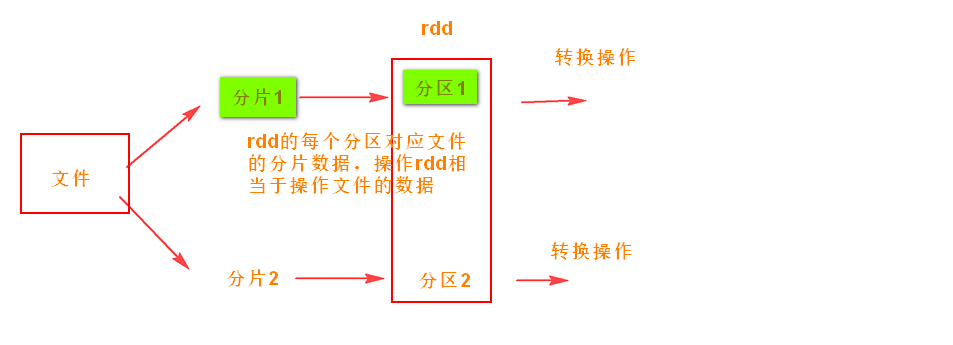
RDD可以从文件系统加载数据创建RDD,也可以从一个已经存在的集合上创建RDD,RDD间可以通过转换算子进行转换,窄依赖不用落地磁盘,有血缘关系,还可以设置检查点,容错能力恢复力强
checkpoint-->hdfs 不需要记住血缘关系 直接从检查点恢复 不需要重新计算父RDD cache--》内存 需要记住DAG关系 父分区进行计算 driver来记住
rdd特性 :高容错(血缘关系) 中间结果持久化到内存 存放的数据可以是java对象 避免了不必要的序列化和反序列化
11.RDD算子分为哪两种?他们有什么特点?
转换算子:由一个rdd转换成另一个rdd,惰性执行
行动算子:由一个rdd转换成一个值或者对象,执行的时候会先触发之前的转换算子
12.Spark中的哪些操作会产生shuffle?
RDD之间形成宽依赖的转换操作, groupByKey sortByKey reduceByKey combinerByKey等等 join非协同划分
13.pairRDD与普通RDD对比有什么不同?它是通过什么方式获取到的?
pairRdd的元素是键值对的形式,可以通过键值对集合创建,也可以通过普通的RDD转换得来
14.一个rdd有多少个task是由什么决定的?
由该rdd的分区数决定的
15.一个spark的job能同时并行处理多少个任务是由什么决定的?
Task被执行的并发度 = Executor数目 * 每个Executor核数
16.RDD的宽依赖和窄依赖有什么区别?
本质区别是一个父rdd的分区会被多个子rdd使用就是宽依赖,否则就是窄依赖
窄依赖各分区之间task独立运行,可以并发进行流水线操作,宽依赖则要等到父rdd所有的分区都计算完成之后才能尽心下一步的操作,窄依赖错误恢复效率高,宽依赖则比较低。
17.stage是怎么划分阶段的?怎么确定每个stage有多少个rdd?
从action算子向前划分,遇到宽依赖就断开,划分一个stage。 看看窄依赖有多少次
18.sparkContext有哪些主要的组件?他们有什么用?
DAGScheduler:是调度阶段的任务调度器,负责接收Spark提交的作业,根据rdd依赖关系划分阶段,然后一并提交给TaskScheduler
TaskScheduler:它接收DAGScheduler提交过来的Stage,然后把任务分发到指定的Worker节点的Executor来运行该任务。
19.rdd的foreach的和foreachPartition有什么不同?
都没有返回值, foreach 对于每个元素都是使用同一个函数, foreachPartition 先分区 对每个分区使用同一个函数
20.rdd的缓存级别有哪些? persitt和cache模式是什么级别的缓存?
MEMORY_ONLY MEMORY_AND_DISK DISK_ONLY MAMORY_AND_DISK_SER MEMORY_ONLY_SER MEMORY_ONLY_2 MEMORY_AND_DISK_2 默认是MEMORY_ONLY
21 rdd的checkpoint和cache有什么不同?
checkpoint 作用是将DAG中比较重要的中间数据作为一个检查点将结果存储到一个高可用的地方(hdfs)
cache 可以将中间的结果放到内存或者是硬盘中,但是这样不能保证数据的不丢失,存储的这个内存或者硬盘出现了问题也会导致spark再从头在计算一遍
22.怎么修改executor的storage memory的内存比例?
spark.memory.uselegacyMode=true 调整spark.storage.memoryFraction参数 spark.memory.uselegacyMode=false的时候 它会自动帮你调整参数,所以当我们需要修改的时候,我们要关闭自动调整,变为手动调整
23.blockManager中的diskStore、memoryStore connectionManager blockManagerWorker都有什么作用?BlockManagerMaster里面存储的是什么?
memoryStore:负责对内存上的数据进行存储和读写
diskStore:负责对硬盘上的数据进行存储和读写
blockManagerWorker:负责对远程其他Executor的BlockManager的数据进行读写
connectionManager:负责与远程其他的Executor建立网络连接
BlockManagerMaster存储的是元数据信息的映射
24.使用广播变量和外部变量会有什么不同吗?
当在executor端使用到Driver变量,不使用广播变量的时候,在Executor中有多少个Task就有多少个Driver端变量副本,如果这个变量中的数据很大的话,会产生很高的传输负载,导致执行效率降低,也可能会造成内存溢出,需要广播变量提高运行效率。
25.1.5以前的版本默认开启consolidation机制吗?consolidation机制的开启与关闭的shuffle有什么不同?
不是默认开启的,需要手动去开启,减少了文件的输出个数,
26.spark中的shuffle中output lost异常是什么原因造成的?
垃圾回收造成的
27.在scala中怎么使用Comparable和Comparator?
ordered内部比较器 Comparable
ordering外部比较器 Comparator
28.eq equals sameElements使用的区别?
equals比较样例类的属性是否相同,eq不能比较 sameElements比较集合中的元素是否相同
比较样例类对象是否相等用eq,如果比较样例类对象的数据是否相等用equals
29.详细说明coalesce和repartition的区别?
两个都可以改变重新分区,coalesce默认的情况shuffle为false,repartition内部调用了coalesce,默认开启shuffle,但是在极端情况下(1000个分区变成1个分区),这时如果将shuffle设置为false,父子RDD是窄依赖关系,他们同处在一个Stage中,就可能造成spark程序的并行度不够,
30spark中都支持哪些序列化方法,默认是哪种?
java的序列化 kryo的序列化 默认是java的序列化
31.kryo相比java的序列化方法有什么特点?他有几种方法分别是?
kryo序列化序列化机制比java序列化机制提高10倍,但是因为不支持所有对象的序列化,同时kryo需要用户在使用之前要注册需要序列化的类型,不够方便。
(1)序列化的类注册给Kryo (2)封装一个自定义注册类,然后把自定义注册类注册给kryo
32.spark中怎么使用hadoop的outputformat和inputformat?
SaveAsNewAPIHadoopFile outputformat
newAPIHadoopFile inputformat
33.详细说一下GC对spark性能的影响?
GC时会停止其他的进程,导致spark变慢
34.saprk-submit提交任务的时候怎么使用第三方的jar包?
spark-submit --jars --files
35.spark任务在yarn模式运行的时候怎么避免每次启动任务的时候都重复上传jar包?
上传到hdfs目录
36.spark2以前的版本yarn模式分为哪两种?这两种方式都有什么不同?
yarn-client yarn-cluster client模式 查看日志方便,但是需要client监控task的运行情况 yarn-cluster查看日志不方便 因为在executor内部 但是提交完任务 可以直接离开
37.略
38.使用spark-sql能复用hive的数据仓储吗?
可以
39.通过spark-sql脚本和start-thriftserver脚本创建的服务有什么不同?hive on spark使用的是哪一种服务?
spark-sql资源是独占的 不是共享的 start-thriftserver资源共享 为什么不用hive on spark 因为资源利用不合理
40.spark的job任务设置多少个cpu资源比较合适?怎么计算出来的?
一个cpu跑三个任务 (2-3)*cpu=partitions
41.spark-sql能执行update语句吗?
不可以
42.spark任务rdd的缓存使用的空间可能通过什么方式得到的?它与读取的文件大小一致吗?
rdd.cache
43.spark-sql执行过程中可以划分为几个阶段?
你自己写的sql--解析你的逻辑执行计划--解析后的逻辑执行计划--优化你的逻辑执行计划--物理执行计划----executor,执行最终的逻辑执行计划---rdd
44.spark-sql 任务的shuffle的默认值是多少?能改吗?
默认是200 可以修改 set spark.sql.shuffle.partitions=400
45.df ds rdd有什么不同,它们之间怎么互相转换?
rdd是弹性分布式数据集 df 是一种以rdd为基础的分布式数据集 传统的数据库的二维表格,df所表示的二维表格数据集的每一列都带有名称和类型。ds是一个强类型的特定领域的对象 type DataFrame = Dataset[Row]
三者共性:都是弹性分布式数据集 都有惰性机制
区别是 rdd不支持spark-sql操作 可用于处理非结构化数据和结构化的数据 ds和df用于处理结构化的数据 df每一行的类型固定为Row 只有通过解析才能获取各个字段的值
Dataset中,每一行是什么类型是固定的,在自定义了case class之后可以很自由的获得每一行的信息
46.spark-sql能实现hive的功能吗?比如UDF和窗口函数?
可以
47.saprk-streaming的batch是什么意思?
规定时间间隔内积攒的数据
48spark-streaming 中的socketStream源中的每个batch有多少个partition怎么计算的?
batch/blockinteval
49.spark-streaming中的fileStream源每个batch有多少个partition怎么计算的?
inputformat getSplit
50.spark-streaming的windows函数中有那3个重要的参数?设置的时候要注意些什么?
滑动间隔 窗口间隔 批次间隔 滑动间隔和窗口间隔是批次间隔的整数倍
51.写出sql,求出user_install_status表中每个用户最新安装的10个应用?
select * from (select aid,pkgname,uptime,row_number() over (partition by aid order by uptime desc) as rn from user_install_status) a where a.rn <=10;
52.updateStateByKey保存历史数据需要设置什么?
设置checkpoint getOrCreate(path,()=>{
})
53.从getOrCreate得到streamingContext需要注意什么?
StreamingContext创建流只能在getOrCreate()中创建,外部不能再创建一个流了,要不然两个流程序会报错,当已经生成这个任务的checkpoint的时候,修改端口不生效,因为是恢复已经村存在的checkpoint的Streamingcontext,rdd里面的函数可以修改
54.24小时运行的sparkStreaming程序是怎么更新配置文件的?有几种方法,优缺点是什么?
用文件流更新spark-streaming-file监控目录文件的读入,目录进入新文件的时候,新文件就会参与本批次运算,本批次运算完成之后这个文件就等于已经处理过了,下个批次就不会再重复读取了,
方法1:spark-streaming-socket cogroup spark-streaming-file 优点:热加载机制,可以不停止集群进行更新,缺点:会产生shuffle
方法2:SparkStreaming-kafka 优点:热加载机制 直接在map端进行join,不会产生shuffle
55.kafka有什么特点?
支持TB级别以上的访问性能 高吞吐率 支持消息分区和分布式消费 支持离线数据处理和实时数据处理 支持在线水平扩展
56.kafka有哪些基本组件?说明以下他们的关系?
broker 集群中的每个服务器叫做broker
topic 每条发送到kafka集群中的消息都有一个类别 叫做topic
parititon topic中的数据分割为一个或者多个partition 每个topic至少有一个partition,每个partition中的数据是有序的,但是不能保证整体是有序的
producer 生产者就是数据的发布者 将消息发送到kafka的topic中
consumer消费者可以从broker中获取数据,消费者可以消费多个topic中的数据
57.kafka中的数据默认的删除时间是多少?
默认是168个小时,可以配置
58.kafka中的队列消费全局有序的吗?怎么让消费有序?
不是全局有序的 通过将一个topic中的每个partition分配给一个consumer 也就是说消费者组中的一个消费者消费,并且producer只往那个topic中的partition中放数据
59. kafka中的consumer group中的每个consumer能得到相同的数据吗?
不能 组内互斥 组之间相同
60.kafka不同的consumer group能得到相同的数据吗?
可以
61.kafka中的partition是均衡分布在每一台机器上的吗?
是的
62.一般情况下 kafka的partition数量大于等于broker的数量?
实现负载均衡
63.kafka安装的服务器为什么不需要raid
因为kafka在软件上面已经实现了备份和分盘的读写
64. 一个topic的partiiton设置多了会有什么优缺点?
优点:增加了消费者组内consumer的并发度 缺点:产生文件过多 增加端对端的延时 导致更高的不可用性
65.能减少一个topic的partition的数量吗?
不能 会造成数据的丢失
66.kafka底层存储的数据类型是什么?为什么要使用这种数据类型?
使用的二进制数据类型 因为kafka作为消息队列中间件,服务与上游和下游,和编程语言无关。
67.说一下redis的一致性hash原理?
主要是解决了 key的归属问题
68.redis与hbase对比有什么优缺点?
适应的场景:
redis适用于24小时的在线服务,而hbase不适应于24小时的在线服务
hbase适用于大数据场景的hive多分区表的排重合并,也常用于存储用户的属性(用户画像系统)利用其宽列存储的特点,随意扩展列,不存不占空间
速度比对:
读:
redis快
hbase有缓存的时候快
写
redis慢,相比hbase没有直接生成底层文件的方式快速导入
hbase快,因为支持跑mr任务批量写入
69.什么是倒排索引?
lucene快是因为,添加数据的时候,就对数据进行了分词,并用分的词建立索引,存储到索引库中,然后将真正的内容,保存到文件区域内,查找也是将查询的数据进行分词,先在索引库中进行查找,如果能查到,会返回一个文件的id,然后再根据文件ID,去存储文档的区域查找真正的数据,这种方法相比传统数据库的like方法要快很多
70 elasticsearch与solr对比有什么特点?
solr利用zookeeper进行分布式管理,而Elasticsearch自身带有分布式协调管理功能
solr支持更多格式的数据,而Elasticsearch仅支持json文件的格式
solr官方提供的功能歌迷囊更多,而Elasticsearch本身更注重于核心功能,高级功能多有第三方插件提供
solr在传统的搜索应用中表现好于Elasticsearch 但是在处理实时搜索应用下效率明显低于Elasticsearch
71.ELK是什么?
elasticsearch:后台分布式存储以及全文搜索
logstash:用来日志的收集 分析 过滤日志的工具,支持大量的数据获取方式
kibana:数据可视化展示
ELK架构为数据分布式存储 可视化拆线呢和日志解析创建了一个强大的管理链,
72 elasticsearch为什么要进行索引重建?
Elasticsearch的索引一旦创建是不可变更的,如果我们要修改索引的Setting,Mapping,这个时候就需要重建索引,es内置了两种重建索引的API
Update By Query :在现有索引上重建索引
Reindex:在其他索引上重建索引
73 elasticsearch的动态映射Dynamic mapping配置有哪些作用?
可以通过dynamic设置来控制这种行为 它能够接收以下的选项:
true :默认值 动态添加字段
false:忽略新字段
strict:如果碰到陌生的生字段,抛出异常 整条数据都无法插入

 浙公网安备 33010602011771号
浙公网安备 33010602011771号