RNN与CNN最强科普
版权声明:本文为博主许佳佳原创文章,转载请务必注明出处。 https://blog.csdn.net/Double2hao/article/details/84451405
概要
本文科普性质偏多,主要讲一下神经网络中一些常见的概念,如果是完全不懂的小白也可以阅读。
本文参考:
https://blog.csdn.net/v_JULY_v/article/details/51812459
https://zhuanlan.zhihu.com/p/33841176
https://blog.csdn.net/v_JULY_v/article/details/79434745
https://blog.csdn.net/qq_23225317/article/details/77834890
一个例子理解NN(神经网络) 模型
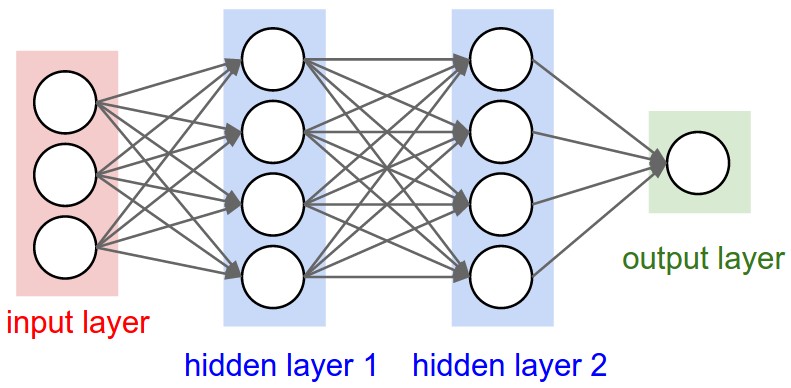
现在想要计算一个人的智商,目前影响智商的因素有身高、体重、家庭背景三个,三者的影响权重也不同,最终能通过三者和权重计算出一个人的智商。这些所有的因素结合到一起就可以称为是神经网络,如下图:
由此可以引申出神经网络的三个概念:
输入层(Input layer):众多神经元接受大量非线形输入讯息。
输出层(Output layer):讯息在神经元链接中传输、分析、权衡,形成输出结果。
隐藏层(Hidden layer):是输入层和输出层之间众多神经元和链接组成的各个层面。
拿上面的例子来讲:
输入层(Input layer):输入身高、体重、家庭背景等的过程。
隐藏层(Hidden layer):把身高、体重等参数与权重一起计算出结果的过程。
输出层(Output layer):输出这个人智商的过程。
由此也可以很简单地理解“神经元”的概念。
身高、体重、家庭背景,每个都是输入层的神经元。
计算智商的过程可能很复杂,可以把这个计算的大过程分解成很多个小过程,而每一个小过程就是隐藏层的神经元。
最终输出的智商,则是输出层的一个神经元。
RNN(循环神经网络)
RNN是在自然语言处理领域中最先被用起来的,比如,RNN可以为语言模型来建模。
语言模型:给定一个一句话前面的部分,预测接下来最有可能的一个词是什么。
比如:
我昨天上学迟到了,老师批评了____。
一般的神经网络由输入层、隐藏层、输出层组成,隐藏层一般会根据输入层输入的内容来计算出输出结果。
而RNN(循环神经网络)的隐藏层不仅会根据输入层输入的内容计算,同时也会把上一个神经网络隐藏层计算出的结果作为参考之一。
举个例子:
句子A: 老师 批评 了 ____。
句子B: 我 昨天 上学 迟到 了 ,老师 批评 了 ____。
如果仅仅分析句子A,很难判断出老师到底批评了谁,有可能是“我”,也有可能是“小明”。
但是在句子B中,后面的内容如果同时加进了“我昨天上学迟到了”这句话的意思,后面的内容就有很大概率是“我”了。
双向循环神经网络
双向循环神经网络就是不仅仅会考虑到前面的神经网络的计算结果,后面的神经网络的计算结果也会作为计算的参考之一,例子和模型图如下:
我的手机坏了,我打算____一部新手机。
CNN(卷积神经网络)
解决的问题
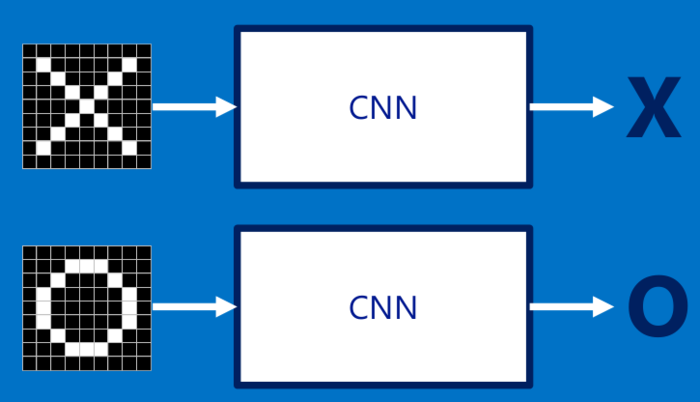
比如我们要让计算机识一张“X”的图片,我们可能就会让计算机去记录该图片的一个个像素点,如下图:
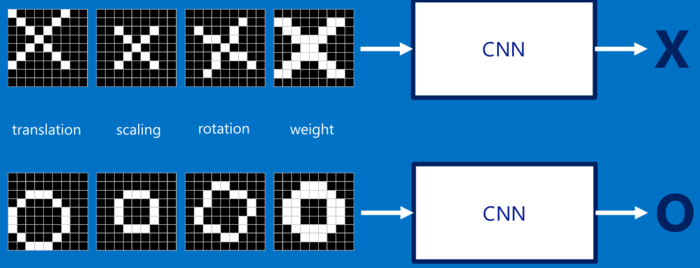
但是如果图片有稍微的旋转,或者是位置上的变化,那么这种简单的方式就无法识别出来了,而通过CNN,我们就可以解决这个问题。

过程
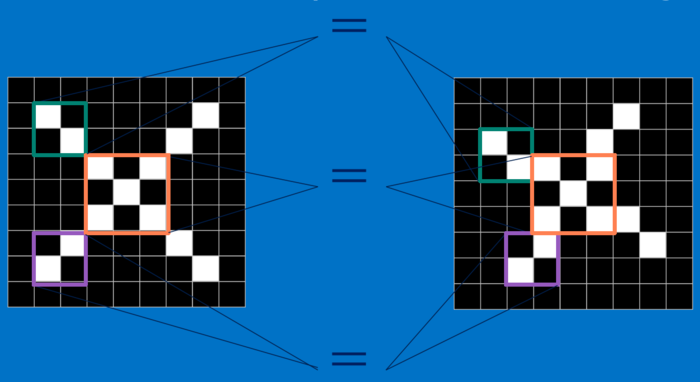
CNN将一整个问题分解成一个个小的特征,通过卷积的数学操作找到这些特征,然后再将一个个小特征放到一起来判断是否是最终的结果。
特征
上面的识别“X”的例子,对于CNN来说,它是一块一块地来进行比对。它拿来比对的这个“小块”就是特征。
每一个特征就像是一个小图(就是一个比较小的有值的二维数组)。不同的特征匹配图像中不同的特征。在字母"X"的例子中,那些由对角线和交叉线组成的特征基本上能够识别出大多数"X"所具有的重要特征。
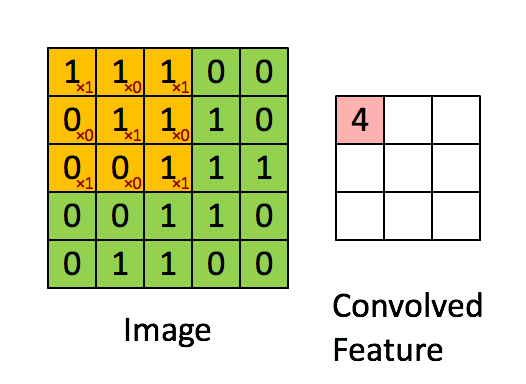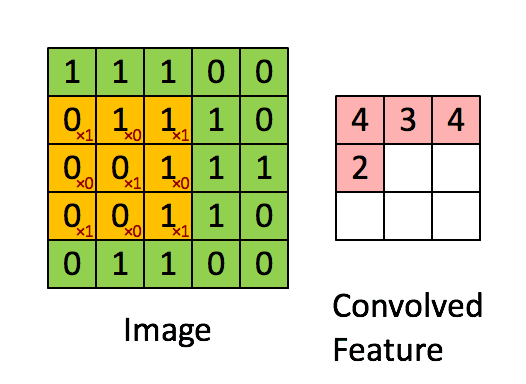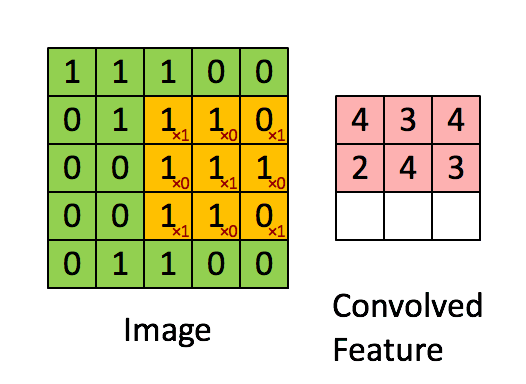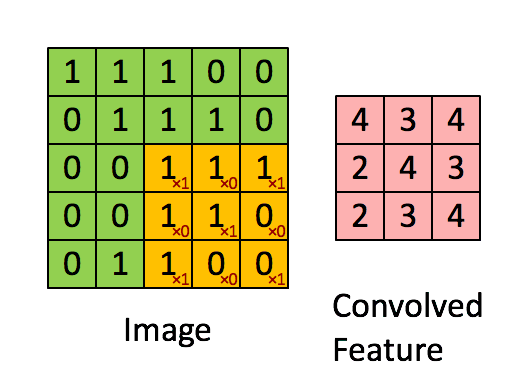
那么计算机究竟是如何找到这些一个个特征的?这就要用到了一个数学操作——卷积。

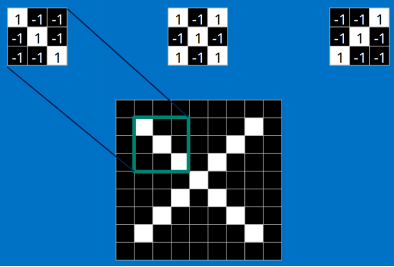

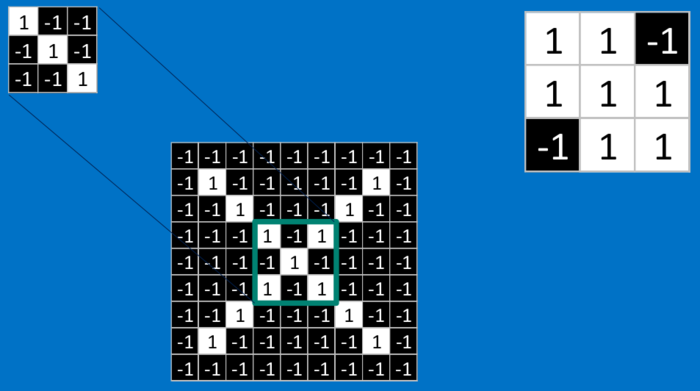
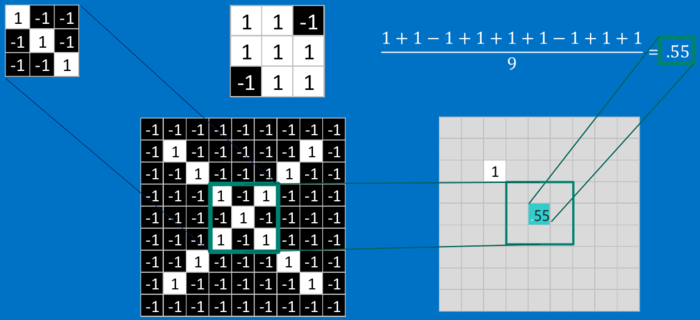
卷积
卷积的gif如下:
还是看上面的识别“X”的例子:
最终这个特征的计算结果如下图:
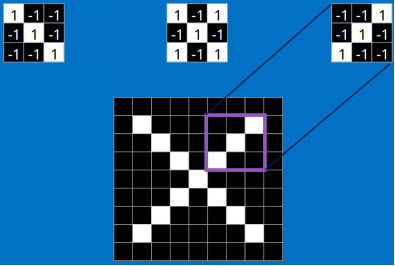
接下来就换其他特征继续运算,最终所有特征的计算结果如下:


由卷积的计算过程可知,上面图中每个位置的值越大,就说明这个位置和我们寻找的特征值越匹配。
而实际过程中,我们不需要知道每个点的特征的匹配程度,其实只需要知道“这个特征是否存在”就可以。
打个比方,我们通过“猫头”、“猫爪”、“猫的身子”这个三个特征来判断出是一只猫,而至于这些特征是在图片的上方,下方还是左方右方,我们并不关心,只要最终能找到这些特征,我们就能判断是一只猫。
也因此就有了“池化”的必要。
池化
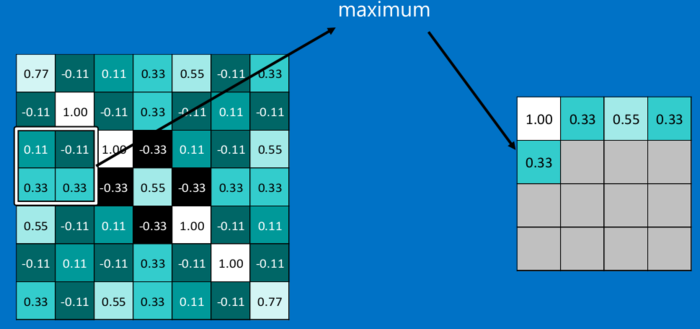
池化可以将一幅大的图像缩小,同时又保留其中的重要信息。常情况下,池化都是2*2大小,比如对于max-pooling来说,就是取输入图像中2*2大小的块中的最大值,作为结果的像素值,相当于将原始图像缩小了4倍。
因为最大池化(max-pooling)保留了每一个小块内的最大值,所以它相当于保留了这一块最佳的匹配结果(因为值越接近1表示匹配越好)。这也就意味着它不会具体关注窗口内到底是哪一个地方匹配了,而只关注是不是有某个地方匹配上了。这也就能够看出,CNN能够发现图像中是否具有某种特征,而不用在意到底在哪里具有这种特征。

通过上面的过程,其实我们已经在图片中找到一个个特征了,那么我们又是如何通过一个个特征来判断出最终的结果的呢?这就是全连接层做的事情。
全连接层
我们从一个比较形象的例子来解释全连接层做的事情:
现在有一张图片,我们要识别图片里面的是一只猫,按照CNN的思路,我们肯定要先找到各个特征,比如“猫头”、“猫尾巴”。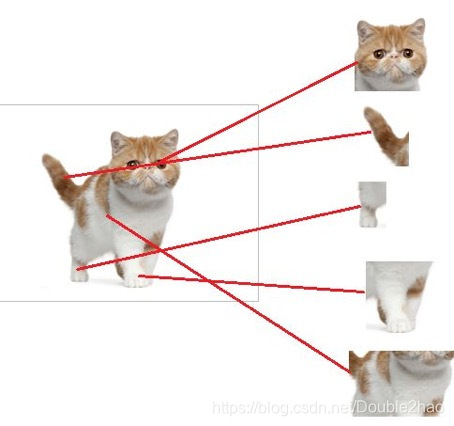
如果找到了这些特征,我们自然可以得出“猫”的结果: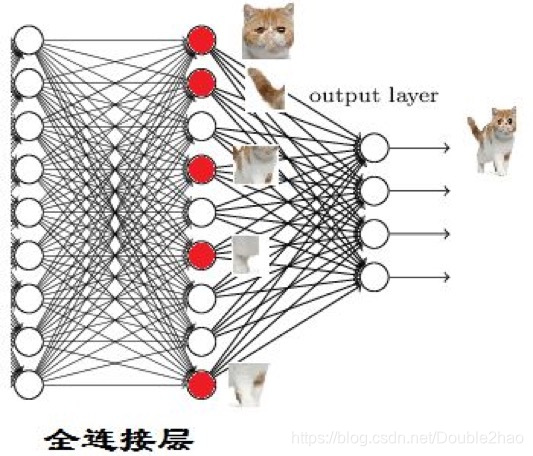
但是,问题是计算机也肯定无法直接识别出“猫头”、“猫尾巴”这些特征啊?所以这些特征只能由一些更小的特征得出,比如要得出“猫头”的特征,就要得到“猫眼睛”、“猫耳朵”等特征。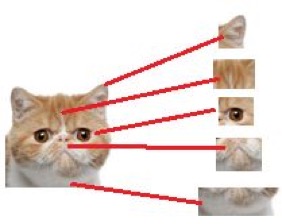
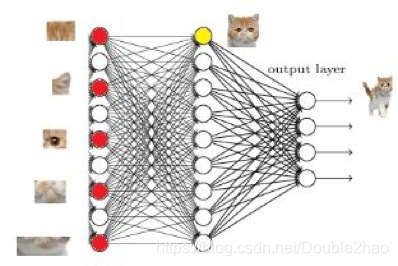
那么“猫眼睛”、“猫耳朵”这些细小的特征又从哪里来呢?是从前面的卷积层来的。
其他概念
迁移学习
当你在处理一张图片时,你的神经网络最后一层可能是在找孩子、狗或飞机或别的任何东西。如果你向前两层看,网络可能是在找眼睛、耳朵、嘴巴或者轮子。
迁移学习就是当你用一个数据集训练CNN时,砍掉最后的一(些)层,再用另一个不同的数据集重新训练最后一(些)层的模型。直观地说,你在重新训练模型来识别不同的高级层次特征。作为结果,训练时间大幅减少。所以当你没有足够的数据或者训练的资源时,迁移学习是非常有用的一个工具。
posted on 2019-09-04 17:37 Nancy_Fighting 阅读(772) 评论(0) 收藏 举报

 浙公网安备 33010602011771号
浙公网安备 33010602011771号