

第3届83行代码大赛第2关赛题官方解析
简介: 由阿里云云效主办的2021年第3届83行代码挑战赛已经收官。超2万人围观,近4000人参赛,85个团队组团来战。大赛采用游戏闯关玩儿法,融合元宇宙科幻和剧本杀元素,让一众开发者玩得不亦乐乎。
其中大赛第二题,号称魔鬼算法题,拦住诸多代码好汉。
我们请来了第二题的出题人,刘力华(阿里云云效代码平台),为大家系统揭秘,从设计到攻略,还有优秀代码解析供大家参考。
赛题设计
我设计的第二关是希望能考察参赛者的基础算法、数据结构的能力。
设计来源
本赛题采用的是字符串前缀匹配算法,参数者需要先通过OSS获取待匹配的数据集,然后参赛者需要从中找出与指定前缀字符串相匹配的字符串数据。为什么会选择该算法呢?源于近期我在使用我们自己的开发插件时,它能够当我在代码搜索的输入框中输入Java API关键词时,可以自动提供API名称的补全提示,受该功能模块启发,因此希望设计一个题目让参赛者实现一个Java API名称的前缀匹配算法。
此处打个广告:我们的插件是阿里云智能编码插件,现已上架JetBrains插件市场,可以在IntelliJ IDEA中通过搜索Alibaba Cloud AI Coding Assistant下载使用。插件包含了代码智能补全及代码示例搜索功能,让开发者更快速、行云流水的完成编码。
整个赛题的设计难点在于如何让本赛题具备一定的挑战性。但又保证一定的通关率。该赛题在外部题库有类似的算法题,属于中等难度,所以中等难度能提高一定的通过率。为了避免参赛者通过Java的String.startsWith及双循环就直接通过,所以增大了评测的数据量,但是为了控制赛题难度,评测的数据集分为几十万的小数据集以及几百万的大数据集,只要能较好的解决小数据集问题,就能通过该赛题。
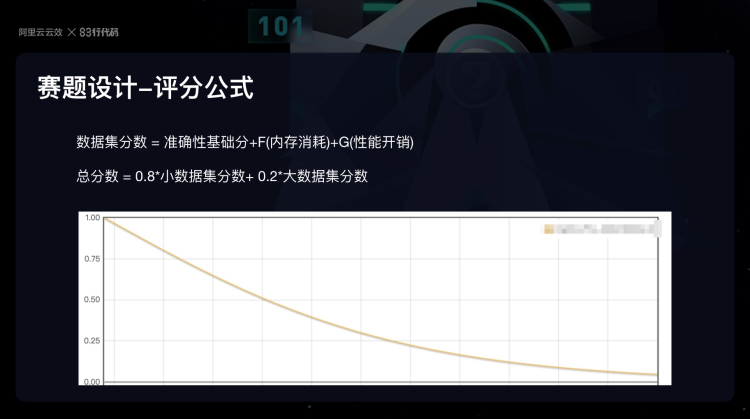
评分系统
本赛题的打分系统基于函数计算设计,系统会随机选择一个小规模数据集和一个大规模数据集,并依次串行运行参赛者的代码,并针对这两个数据集对参赛者编写的代码从准确性、性能开销、内存消耗维度进行评估。
赛题攻略
OSS数据获取
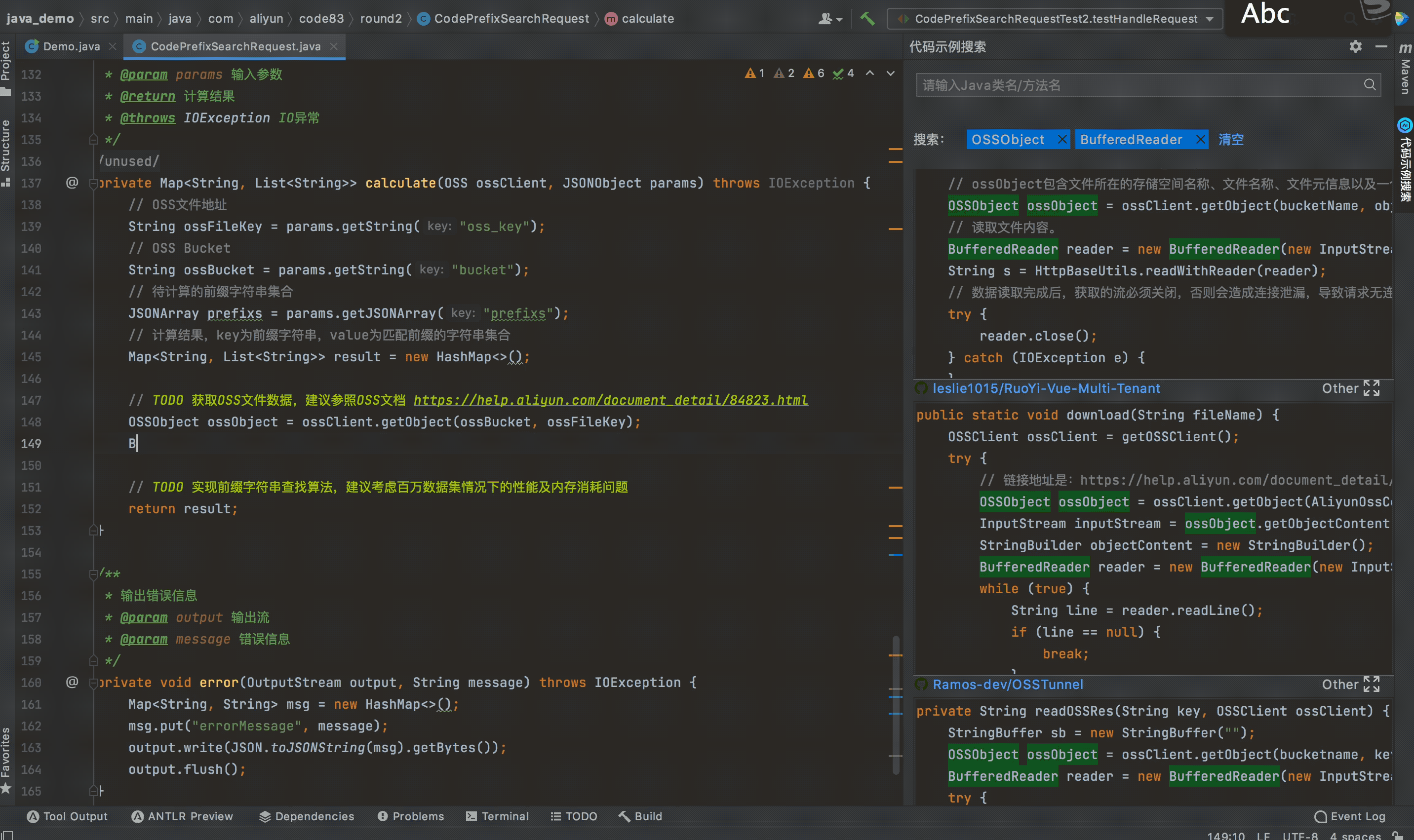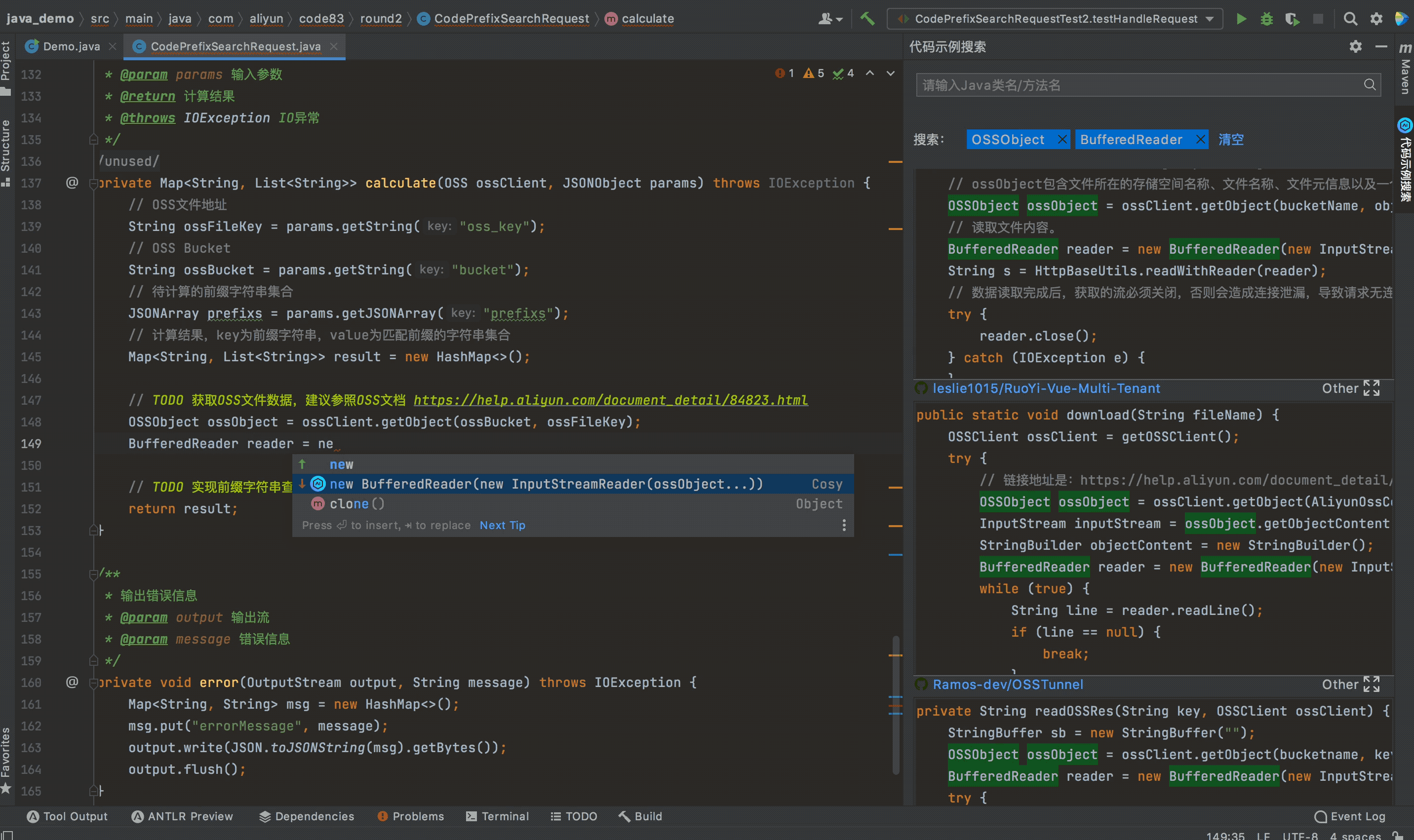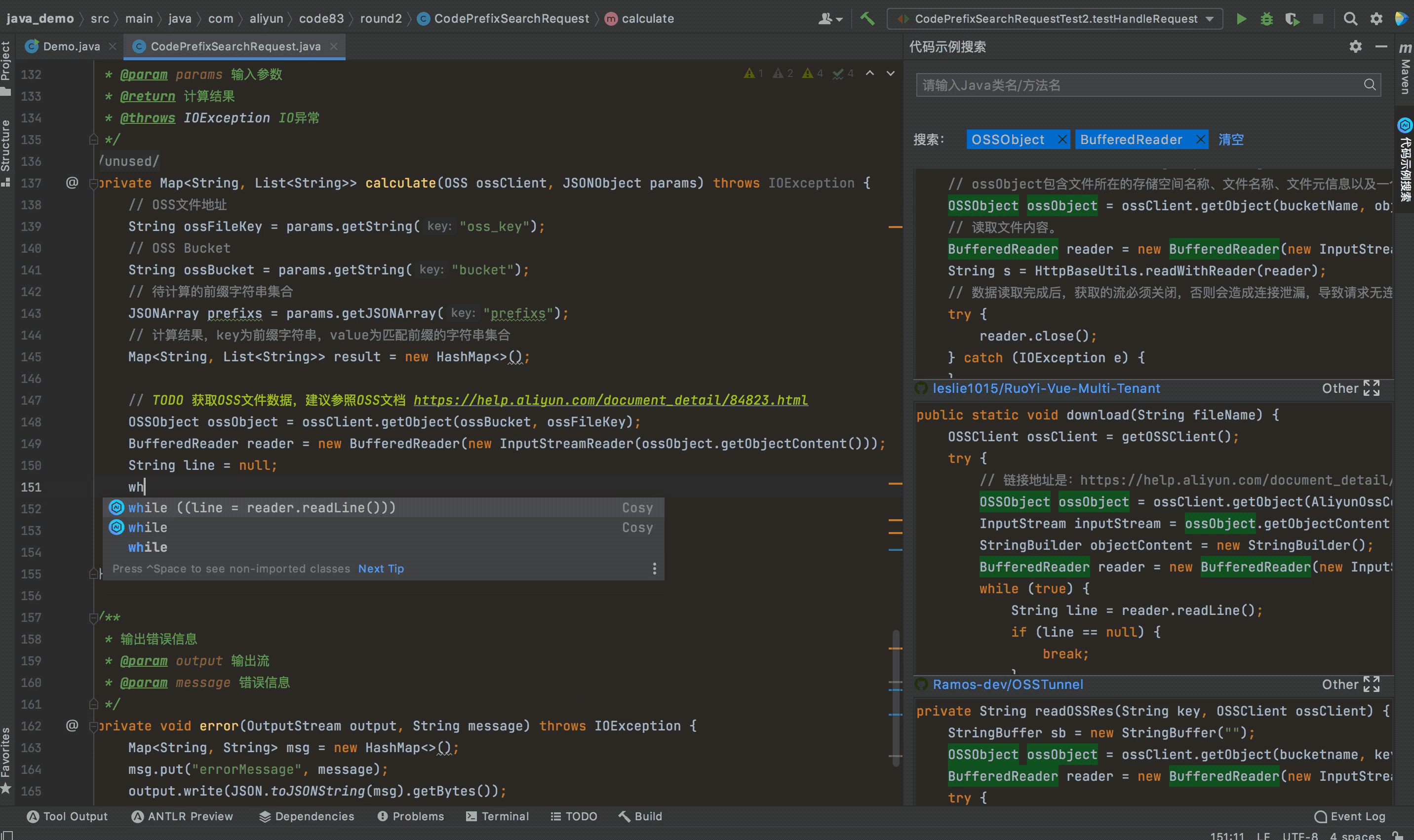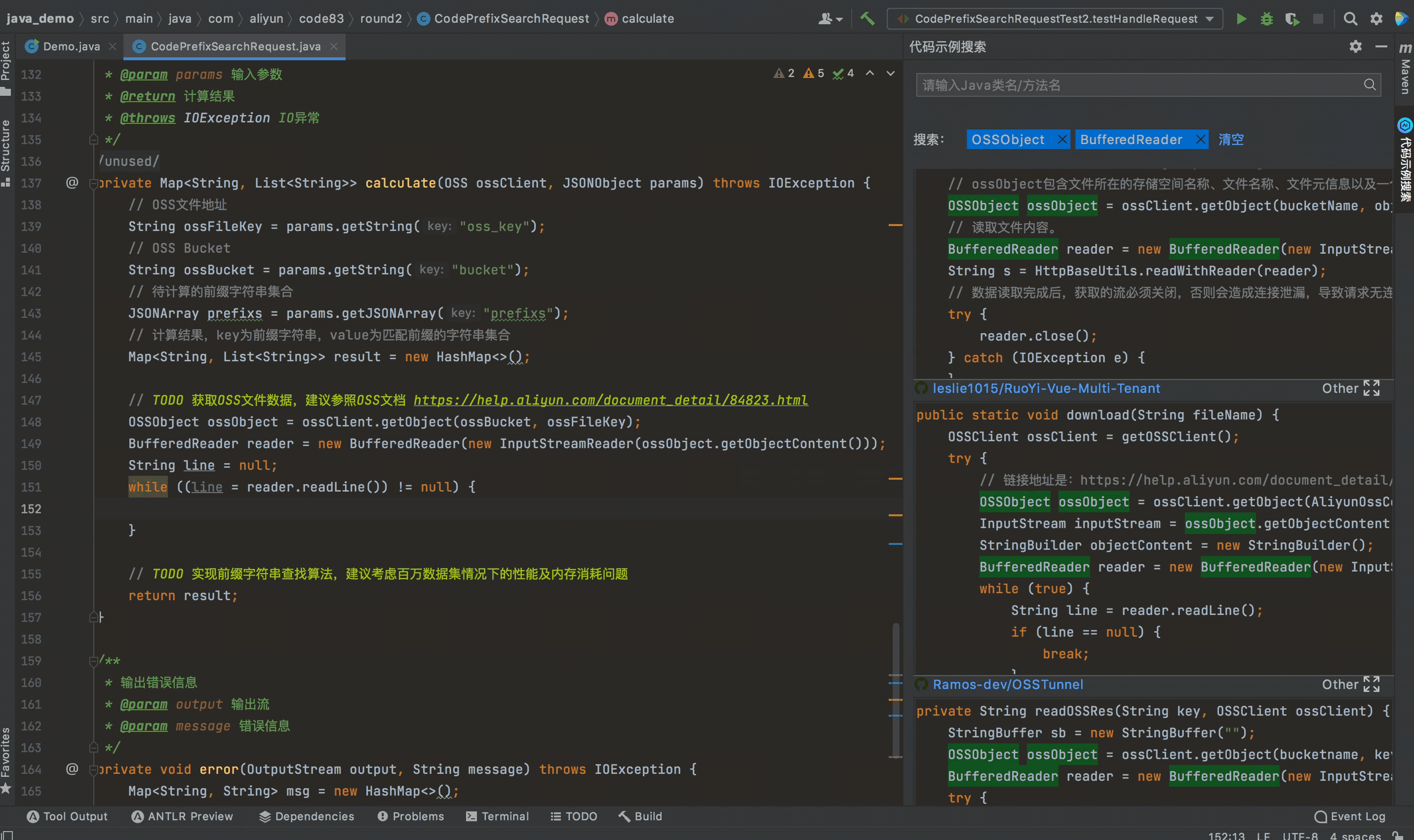
本赛题的数据集存储在OSS中,所以需要参赛者通过OSS的SDK进行数据的获取,参赛者可以通过代码注释中的文档链接去学习OSS SDK如何使用,也可以通过近期发布的阿里云智能编码插件(Cosy)快速查看OSS SDK的示例代码。

如上图所示,如果参赛者想知道OSSObject的数据如何获取,可以在该API上右键点击“查看代码示例”,智能编码插件就能快速查找出实现OSS数据获取相关的代码示例,参赛者只需要选择性复制并修改部分代码即可。
此外,开发者也能通过代码智能补全功能,通过选择整行的代码补全结果,快速的编写出获取OSS数据的代码,如下图所示。
算法攻略
该赛题的解题方法是比较多样化的,参赛者采用的方法主要分为以下几种。
第一种:自己实现算法及数据结构
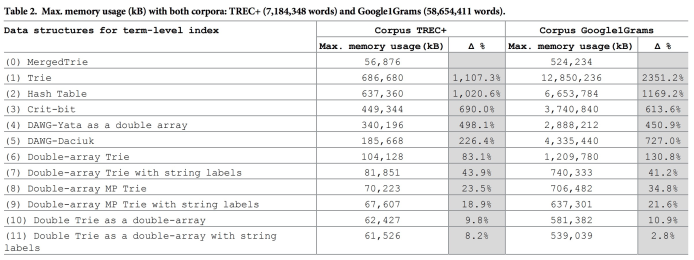
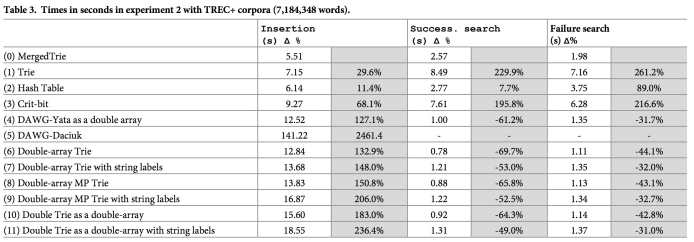
赛题攻略中提到了Trie Tree,一个较为基础的数据结构,一个较好的Trie Tree也能够通关本赛题。但是Trie Tree的性能开销及内存消耗也都是比较大的,可以考虑Trie Tree的诸多变种,比如Double Array Trie,用双数组去节省空间,比如Radix Tree及其诸多变种,通过减少树的深度去压缩Trie Tree的内存占用。为了对比各种Trie Tree实现的效果,这里引用《MergedTrie: Efficient textual indexing》论文的相关评测数据。
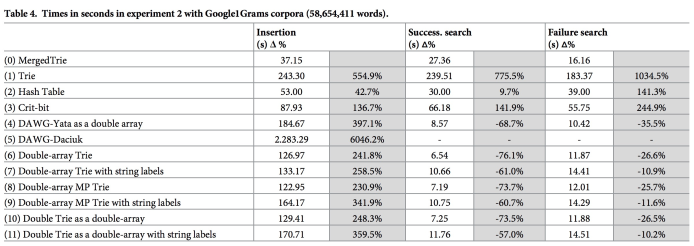
还有很多参赛者通过减少双层循环的次数、减少前缀匹配的性能开销等方法,也同样获得了较高的分数。
第二种,使用JDK内置的数据结构
JDK内置数据结构的性能也是比较高的,部分参赛者使用了TreeSet进行排序,然后通过用subSet方法就能直接获取匹配的前缀字符串数据,该方式比较简单快捷,且代码量较小。
参赛代码SHOW
参赛者对本赛题的解法诸多,由于篇幅限制,本文章只展示四位参赛者的代码片段。
参赛者代码片段一
该解法通过String.substring方法去截取字符串不同长度的前缀,并将截取的前缀直接从result的Map中进行查找,该方法无需像String.startsWith逐一进行字符的比较,所以效率会有较大提升,使用这种解法的参赛者比较多,还有部分参赛者会对截取的长度进行限制,比如事先统计前缀字符串的最短及最长的长度,只需遍历生成该长度范围内的前缀即可。
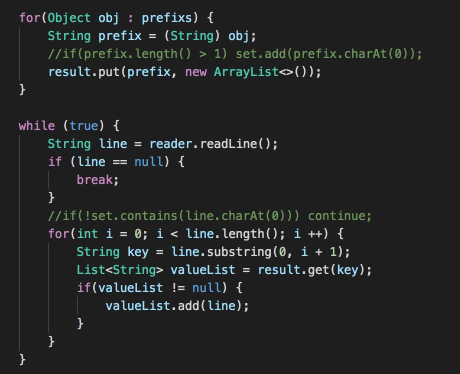
参赛者代码片段二
该解法会先排除超出前缀字符串最短及最长长度范围的数据,然后对数据集进行排序。随后遍历待匹配的前缀字符串列表,为每个前缀字符串通过二分查找计算数据集中,与其匹配位置的数组上界及下界,然后将该范围内的数据抽取出来即可。

参赛者代码片段三
该解法与排序方法类似,使用了JDK内置的TreeSet进行排序,然后通过TreeSet.subSet方法截取与前缀字符串匹配的数据。
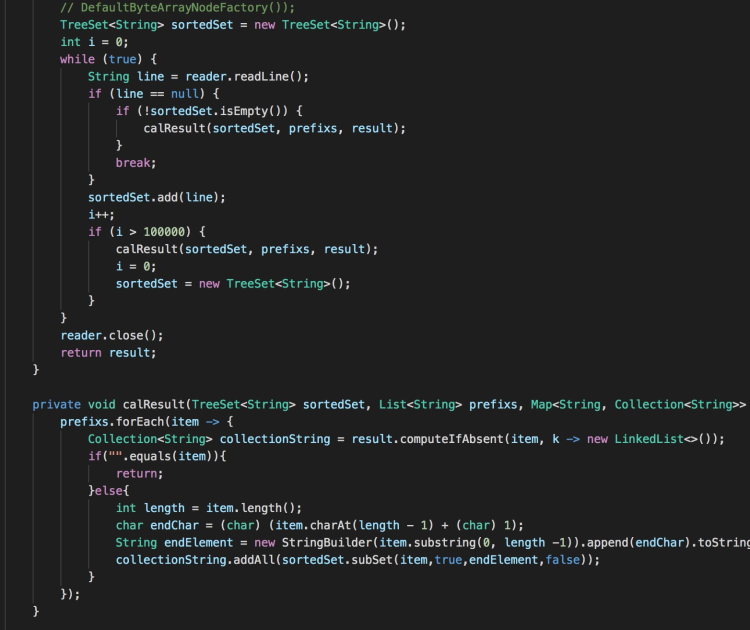
部分参赛者为了提高挑战性,放弃使用TreeSet,自己实现了相关的排序及查找方法
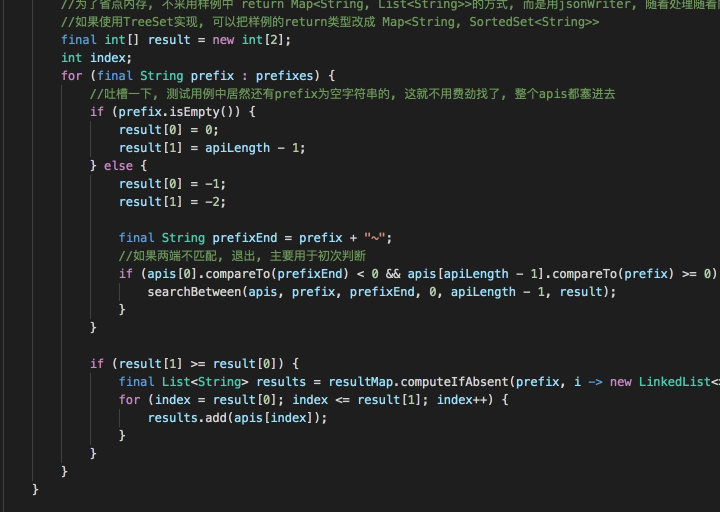
参赛者代码片段四
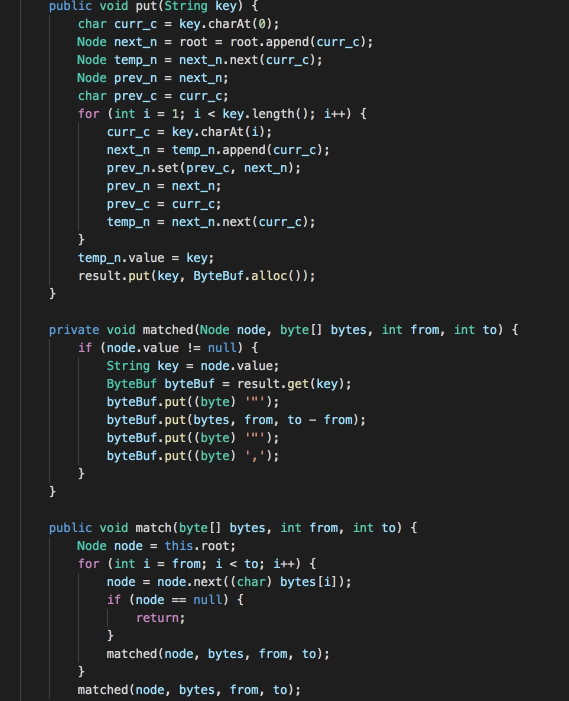
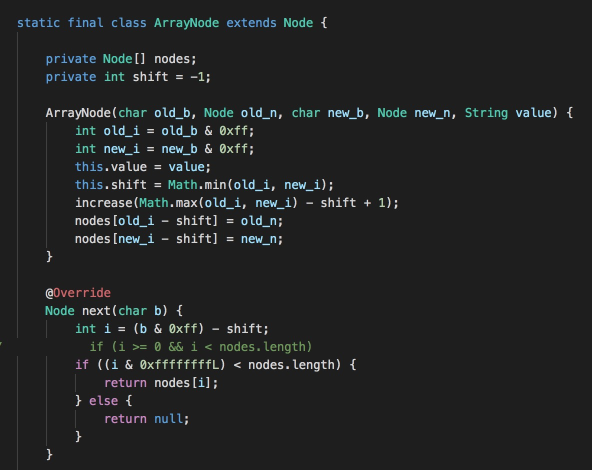
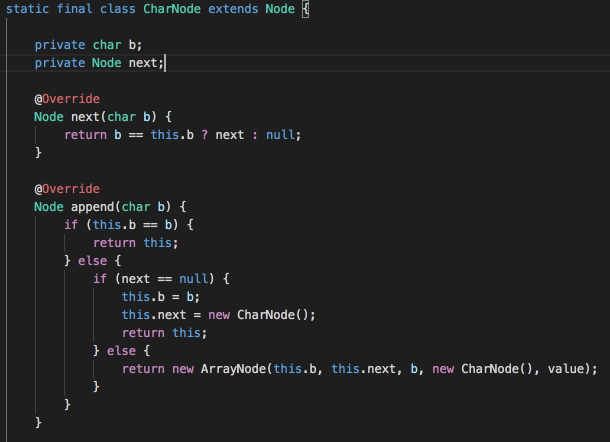
这是排名第一的参赛者的代码,该参赛者对Trie树进行了优化,使用CharNode、ArrayNode减少部分存储消耗,其中ArrayNode中通过shift存储偏移量,数组的下标位置加上shift偏移量即为字符的ASCII码。
并且该参赛者在输出数据时没有将字符串存储到字符串数组中,而是定义了ByteBuf,在输出时直接以JSON字符串形式存储到字节数组中。
总结
尽管很多参赛者在这一关遇到了较多困难,尤其是在处理大规模数据集时。但正因为如此,我们也发现很多选手并不止步于通关,他们会努力尝试不同的解法、不断地优化算法,哪怕只是提升了0.01分,这一点对我们团队的触动也是很大的。赛事后我们也反思了一些做得不够好的地方,比如IDE评分栏缺少内存消耗、性能开销等具体数字的展示,导致部分参赛者不知道实际的内存消耗,后续我们会对这些细节点上进行优化,如果大家有好的想法及建议,欢迎反馈给我们!
看完攻略如果你还想体验赛题,依然可以前往https://code83.ide.aliyun.com,我们目前仍然开放给大家进行体验。
最后,欢迎大家试用智能编码插件:https://developer.aliyun.com/tool/cosy,它作为一款AI开发插件,拥有强大的代码智能补全、代码示例搜索等功能,让开发行云流水般编码,事半功倍地完成开发工作。你可以在IntelliJ IDEA或JetBrains插件市场中搜索Alibaba Cloud AI Coding Assistant或Cosy,使用中如果有任何问题或建议都可以反馈到Github Issues中,我们会认真倾听你的声音。
大赛目前全部关卡开放体验,域名地址:https://code83.ide.aliyun.com/,欢迎你来。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 记一次.NET内存居高不下排查解决与启示
· 探究高空视频全景AR技术的实现原理
· 理解Rust引用及其生命周期标识(上)
· 浏览器原生「磁吸」效果!Anchor Positioning 锚点定位神器解析
· 没有源码,如何修改代码逻辑?
· 全程不用写代码,我用AI程序员写了一个飞机大战
· DeepSeek 开源周回顾「GitHub 热点速览」
· MongoDB 8.0这个新功能碉堡了,比商业数据库还牛
· 记一次.NET内存居高不下排查解决与启示
· 白话解读 Dapr 1.15:你的「微服务管家」又秀新绝活了