Python之正则表达式(re模块)
本节内容
- re模块介绍
- 使用re模块的步骤
- re模块简单应用示例
- 关于匹配对象的说明
- 说说正则表达式字符串前的r前缀
- re模块综合应用实例
- 参考文档
提示: 由于该站对MARKDOWN的表格支持的不是很好,所以本文中的表格均以图片的形式提供,大家如果看着比较模糊,可以放大来看或下载图片在本地查看。
正则表达式(Regluar Expressions)又称规则表达式,在代码中常简写为REs,regexes或regexp(regex patterns)。它本质上是一个小巧的、高度专用的编程语言。 通过正则表达式可以对指定的文本实现
匹配测试、内容查找、内容替换、字符串分割 等功能。正则表达式的语法不是本节要讲的内容(关于正则表达式的详细介绍请参考另一篇博文《正则表达式总结》),本节主要介绍的是Python中是如何使用re模块来完成正则表达式的相关操作的。
一、re模块介绍
Python中的re模块提供了一个正则表达式引擎接口,它允许我们将正则表达式编译成模式对象,然后通过这些模式对象执行模式匹配搜索和字符串分割、子串替换等操作。re模块为这些操作分别提供了模块级别的函数以及相关类的封装。
1. re模块提供的类
Python中的re模块中最重要的两个类:
| 类 | 描述 |
|---|---|
| Regular Expression Objects | 正则表达式对象,用于执行正则表达式相关操作的实体 |
| Match Objects | 正则表达式匹配对象,用于存放正则表达式匹配的结果并提供用于获取相关匹配结果的方法 |
正则表达式对象中的方法和属性
通过re模块的compile()函数编译得到的正则表达式对象(下面用regex表示)支持如下方法:

参数说明:
- string: 要匹配或处理的字符串
- pos: 可选参数,表示从string字符串的哪个位置开始,相当于先对字符串做切片处理string[pos:]
- endpos: 可选参数,表示到string字符串的哪个位置结束(不包含该位置)
- maxsplit: regex.split()方法的可选参数,表示最大切割次数;默认值为0,表示能切割多少次就尽可能多的切割多少次
- count: regex.sub()和regex.subn()方法的可选参数,表示最大替换次数;默认为0,表示能替换多少次就尽可能多的替换多少次
- repl: sub和subn函数中的repl表示replacement,用于指定将匹配到的子串替换成什么内容,需要说明的是该参数的值可以是一个字符串,也可以是一个函数
说明: 如果指定了pos和endpos参数,就相当于在进行正则处理之前先对字符串做切片操作 string[pos, endpos],如rx.search(string, 5, 50)就等价于rx.search(string[5:50]),也等价于rx.search(string[:50], 5);如果endpos比pos的值小,则不会找到任何匹配。
匹配对象中的方法和属性
调用正则表达式对象的regex.match()、regex.fullmatch()和regex.search()得到的结果就是一个匹配对象,匹配对象支持以下方法和属性:

参数说明:
- template: m.expand()方法中的template参数是一个模板字符串,这个字符串中可以使用分组对应的的数值索引进行后向引用(如:\1,\2)或命名后向引用(如\g<1>,\g<NAME>)来表示某个分组的占位符;m.expand()方法的执行过程实际上就是通过sub()方法把template字符串中的这些分组占位符用当前匹配对象中的数据进行替换。
- default: m.groups()与m.groupdict()方法中的default都是为未匹配成功的捕获组提供默认匹配值的。
- group: m.group()、m.start()、m.end()和m.span()方法中的group参数都表示要选择的分组索引值,1表示第一个分组,2表示第二个分组,依次类推,group参数的默认值是0,表示整个正则表达式所匹配的内容。
2. re模块提供的函数
re模块提供了以下几个模块级别的函数
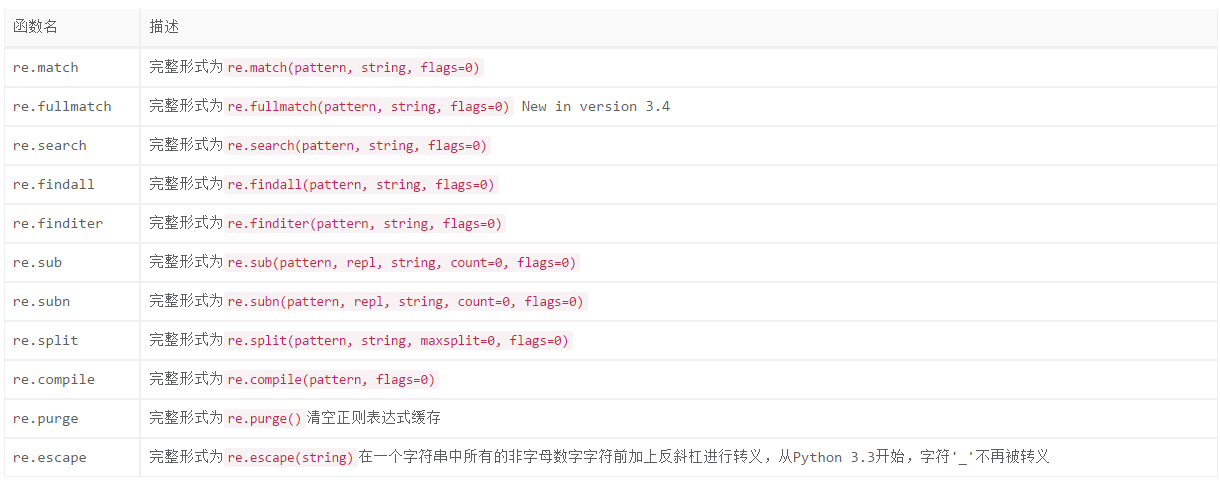
将pattern参数只能是字符串;
- string: 需要用正则表达式来匹配的字符串对象
- flags: 一个标志位,它会影响正则表达式对象的匹配行为,可取值下面会介绍;但是有一点需要说明的是,只有当pattern参数是字符串时才能指定这个flags参数,否则会报错;如果pattren参数是一个正则表达式对象,则flags参数需要在调用re.compile()函数时指定。
- repl: sub和subn函数中的repl表示replacement,用于指定将匹配到的子串替换成什么内容,需要说明的是该参数的值可以是一个字符串,也可以是一个函数
- count: sub和subn函数中的count表示最多可替换次数
- maxsplit: split函数中的maxsplit蚕食表示最大分隔次数
说明: 通过对比会发现,上面这些re模块级别的函数除了re.compile、re.purge和re.escape这几个函数外,其它函数名都与正则表达式对象支持的方法同名。实际上re模块的这些函数都是对正则表达式对象相应方法的封装而已,功能是相同的。只是少了对pos和endpos参数的支持,但是我们可以手动通过字符串切片的方式来达到相应的需求。个人认为,我们应该尽可能的使用模块级别的函数,这样可以增强代码的兼容性。
3. 标志位flags
由上面的描述可知,flags参数在上面这些模块函数中是要个可选参数,re模块中预定了该参数可取的值:

说明: 这些flag可以单独使用,也可以通过逻辑或操作符'|'进行拼接来联合使用。
二、使用re模块的步骤
我们有必要对re模块中所包含的类及其工作流程进行一下简单的、整体性的说明,这讲有利于我们对下面内容的理解。
1. 使用re模块进行正则匹配操作的步骤
- 1)编写表示正则表达式规则的Python字符串str;
- 2)通过re.compile()函数编译该Python字符串获得一个正则表达式对象(Pattern Object)p;
- 3)通过正则表达式对象的p.match()或p.fullmatch()函数获取匹配结果--匹配对象(Match Object)m;
- 4)通过判断匹配对象m是否为空可知是否匹配成功,也可以通过匹配对象m提供的方法获取匹配内容。
2. 使用re模块进行内容查找、替换和字符串分隔操作的步骤
- 1)编写表示正则表达式规则的Python字符串str;
- 2)通过re.compile()函数编译该Python字符串获得一个正则表达式对象(Pattern Object)p;
- 3)通过正则表达式对象的p.search()或p.findall()或p.finditer()或p.sub()或p.subn()或p.split()函数完内容查找、替换和字符串分隔操作并获取相应的操作结果;
总结: 关于正则表达式的语法和编写示例请参考《正则表达式总结》)。根据上面的描述可知,将一个表示正则表达式的Python字符串编译成一个正则表达式对象是使用正则表达式完成相应功能的首要步骤,re模块中用于完成正则表达式编译功能的函数为re.compile()。
三、re模块简单应用示例
在上面的内容中,我们已经列出了re模块所提供的类,以及这些类的对象所支持的函数和属性,还有re模块所提供的模块级别的函数。这里我们要讨论的是怎样合理的使用这些方法和函数,换句话说就是在什么情况下使用这些方法和函数,以及如何使用的问题。我们之前说过,正则表达式主要可以用来提供以下几个功能:
- 匹配测试
- 子串/内容查找
- 子串/内容替换
- 字符串分割
下面我们就分别通过对这几个功能的实例实现对上面这些函数和方法以及参数和属性的使用做下说明和具体的解释。
1. 匹配测试
匹配测试,意思是通过特定的正则表达式对一个指定的字符串进行匹配来判断该字符串是否符合这个正则表达式所要求的格式。常见的使用场景举例:
- 查看某个字符串(通常来自用户输入)是否是一个邮箱或电话号码
- 用户注册时填写的用户名和密码是否符合指定需求
使用的函数或方法
通过re模块执行匹配测试时可以使用的函数或方法是:
- re模块级别的match()和fullmatch()函数
- 正则表达式对象的match()和fullmatch()方法
实例1
前面提到过,match()函数或方法只是匹配字符串的开始位置,而fullmatch匹配的是整个字符串;fullmatch()函数或方法就相当于给match()函数或方法的pattern或string参数加上行首边界元字符'^'和行尾边界元字符'$',下面来看个例子:
import re
# 定义一个函数来对匹配结果进行展示
def display_match_obj(match_obj):
if match_obj is None:
print('Regex Match Fail!')
else:
print('Regex Match Success!', match_obj)
if __name__ == '__main__':
p = re.compile(r'[a-z]+')
display_match_obj(p.match('hello'))
display_match_obj(p.match('hello123'))
display_match_obj(p.fullmatch('hello'))
display_match_obj(p.fullmatch('hello123'))
display_match_obj(p.match('123hello'))
display_match_obj(p.match('123hello', 3))
输出结果:
Regex Match Success! <_sre.SRE_Match object; span=(0, 5), match='hello'>
Regex Match Success! <_sre.SRE_Match object; span=(0, 5), match='hello'>
Regex Match Success! <_sre.SRE_Match object; span=(0, 5), match='hello'>
Regex Match Fail!
Regex Match Fail!
Regex Match Success! <_sre.SRE_Match object; span=(3, 8), match='hello'>
分析:
- '[a-z]+'能与'hello'和'hello123'的开头部分匹配
- '[a-z]+'能与'hello'完全匹配
- '[a-z]+'不能与'hello123'完全匹配
- '[a-z]+'不能与'123hello'的开头部分匹配
- '[a-z]+'能与'123hello'的切片'123hello'[3:]的开头部分匹配
实例2
上面使用的是正则表达式对象的match()和fullmatch()方法,我们也可以通过re提供的模块级别的函数来实现:
if __name__ == '__main__':
p = re.compile(r'[a-z]+')
display_match_obj(re.match(p, 'hello'))
display_match_obj(re.match(p, 'hello123'))
display_match_obj(re.fullmatch(p, 'hello'))
display_match_obj(re.fullmatch(p, 'hello123'))
display_match_obj(re.match(p, '123hello'))
display_match_obj(re.match(p, '123hello'[3:])) # 唯一不同的是这里
输出结果跟上面是一样的
re模块的match()和fullmatch()函数不支持pos和endpos参数,所以只能通过字符串切片先对字符串进行切割。
实例3
再来看个对比:
if __name__ == '__main__':
display_match_obj(re.match(r'[a-z]+', 'hello123'))
display_match_obj(re.match(r'[a-z]+$', 'hello123'))
display_match_obj(re.match(r'^[a-z]+$', 'hello123'))
输出结果:
Regex Match Success! <_sre.SRE_Match object; span=(0, 5), match='hello'>
Regex Match Fail!
Regex Match Fail!
分析:
- re.match()和re.fullmatch()中的pattern参数可以是正则表达式对象,也可以是Python字符串
- re.match()函数中的正则表达式参数加上边界元字符'^'和'$'就相当于re.fullmatch()了
- 当匹配过程是从字符串的第一个字符开始匹配时re.match(r'[1]+$', 'hello123') 与 re.match(r'[a-z]+$', 'hello123')效果是一样的,因为re.match()本来就是从字符串开头开始匹配的;但是,如果匹配过程不是从字符串的第一个字符开始匹配时,它们是有区别的,具体请看下面这个例子。
实例4
if __name__ == '__main__':
p1 = re.compile(r'[a-z]+$')
p2 = re.compile(r'^[a-z]+$')
display_match_obj(p1.match('123hello', 3))
display_match_obj(p2.match('123hello', 3))
输出结果:
Regex Match Success! <_sre.SRE_Match object; span=(3, 8), match='hello'>
Regex Match Fail!
这个很好理解,因为元字符'^'匹配的是表示字符串开始位置的特殊字符,而不是字符串内容的第一个字符。match()匹配的是字符串内容的第一个字符,因此即使是在
MULTILINE模式,re.match()也将只匹配字符串的开始位置,而不是该字符串每一行的行首。
2. 内容查找
内容查找,意思是通过特定的正则表达式对一个指定的字符串的内容进行扫描来判断该字符串中是否包含与这个正则表达式相匹配的内容。
使用的函数或方法
通过re模块执行匹配测试时可以使用的函数或方法是:
- re模块级别的search()、findall()和 finditer()函数
- 正则表达式对象的search()、findall()和finditer()方法
实例1:search() vs match()
这个例子中,我们来看下search()函数的使用,以及它与match()函数的对比。
Python提供了两个不同的基于正则表达式的简单操作:
- re.match(): 该函数仅是在字符串的开始位置进行匹配检测
- re.search(): 该函数会在字符串的任意位置进行匹配检测
import re
string = 'abcdef'
print(re.match(r'c', string))
print(re.search(r'c', string))
输出结果:
None
<_sre.SRE_Match object; span=(2, 3), match='c'>
这个比较简单,不做过多解析。
我们应该能够想到,当正则表达式以'^'开头时,search()也会从字符串的开头进行匹配:
import re
string = 'abcdef'
print(re.match(r'c', string))
print(re.search(r'^c', string))
print(re.search(r'^a', string))
输出结果:
None
None
<_sre.SRE_Match object; span=(0, 1), match='a'>
这里再重复一下上面提到过的内容,就是元字符''与match()的从字符串开始位置开始匹配并不是完全等价的。因为元字符''匹配的是表示字符串开始位置的特殊字符,而不是字符串内容的第一个字符。match()匹配的是字符串内容的第一个字符,因此即使是在
MULTILINE模式,re.match()也将只匹配字符串的开始位置,而不是该字符串每一行的行首;相关search('^...')却可以匹配每一行的行首。
下面来看个例子:
string = '''
A
B
X
'''
print(re.match(r'X', string, re.MULTILINE))
print(re.search(r'^X', string, re.MULTILINE))
输出结果:
None
<_sre.SRE_Match object; span=(5, 6), match='X'>
实例2:findall()与finditer()
findall()与finditer()也是用来查找一个字符串中与正则表达式相匹配的内容,但是从名字上就能看出来,findall()与finditer()会讲这个字符串中所有与正则表达式匹配的内容都找出来,而search()仅仅是找到第一个匹配的内容。另外findall()返回的是所有匹配到的子串所组成的列表,而finditer()返回的是一个迭代器对象,该迭代器对象会将每一次匹配到的结果都作为一个匹配对象返回。下面来看一个例子:
尝试找出一个字符串中的所有副词(英语的副词通常都是以字母‘ly’结尾):
import re
text = "He was carefully disguised but captured quickly by police."
print(re.findall(r"\w+ly", text))
输出结果:
['carefully', 'quickly']
如果我们想要获取关于所有匹配内容的更多信息,而不仅仅是文本信息的话,就可以使用finditer()函数。finditer()可以提供与各个匹配内容相对应的匹配对象,然后我们就可以通过这个匹配对象的方法和属性来获取我们想要的信息。
我们来尝试获取一个字符串中所有副词以及它们各自在字符串中的切片位置:
import re
text = "He was carefully disguised but captured quickly by police."
for m in re.finditer(r"\w+ly", text):
print("%02d-%02d: %s" % (m.start(), m.end(), m.group()))
输出结果:
07-16: carefully
40-47: quickly
3. 内容替换
传统的字符串操作只能替换明确指定的子串,而使用正则表达式默认是对一个字符串中所有与正则表达式相匹配的内容进行替换,也可以指定替换次数。
可使用的函数或方法
- re模块的sub()和subn()函数
- 正则表达式对象的sub()和subn()方法
sub函数返回的是被替换后的字符串,如果字符串中没有与正则表达式相匹配的内容,则返回原始字符串;subn函数除了返回被替换后的字符串,还会返回一个替换次数,它们是以元组的形式返回的。下面来看个例子:将一个字符串中的所有的'-'字符删除
import re
text = 'pro----gram-files'
print(re.sub(r'-+', '', text))
print(re.subn(r'-+', '', text))
输出结果:
programfiles
('programfiles', 2)
说明: 被替换的内容(repl参数)可以是一个字符串,还可以是一个函数名。该函数会在每一次匹配时被调用,且该函数接收的唯一的参数是当次匹配相对应的匹配对象,通过这个函数我们可以来做一些逻辑更加复杂的替换操作。
比如,上面那个例子中,如果我们想要得到'program files'这个结果,我们就需要把多个连续的'-'和单个'-'分别替换为 空字符串 和 一个空白字符:
def dashrepl(match_obj):
if match_obj.group() == '-':
return ' '
else:
return ''
if __name__ == '__main__':
text = 'pro----gram-files'
print(re.sub(r'-+', dashrepl, text))
print(re.subn(r'-+', dashrepl, text))
输出结果:
program files
('program files', 2)
说明: 当被替换的内容(repl参数)是一个字符串时可以使用'\1'、'\g<NAME>'来引用正则表达式中的捕获组所匹配到的内容,但是需要注意的是这个字符串必须带上r前缀。
下面来看个例子:把一个函数名前面加上'py_'前缀
p = r'def\s+([A-Za-z_]\w*)\s*\((?P<param>.*)\)'
repl = r'def py_\1(\g<param>)'
text = 'def myfunc(*args, **kwargs):'
print(re.sub(p, repl, text))
输出结果:
def py_myfunc(*args, **kwargs):
4. 字符串分割
通过正则表达式对字符串进行分割的过程是:扫描整个字符串,查找与正则表达式匹配的内容,然后以该内容作为分割符对字符串进行分割,最终返回被分割后的子串列表。这对于将文本数据转换为Python易于读取和修改的结构化数据非常有用。
可以使用的函数或方法
- re模块的split()函数
- 正则表达式对象的split()方法
我们可以通过maxsplit参数来限制最大切割次数。
实例1:简单示例
print(re.split(r'\W+', 'Words, words, words.'))
print(re.split(r'\W+', 'Words, words, words.', 1))
print(re.split(r'[a-f]+', '0a3B9', flags=re.IGNORECASE))
输出结果:
['Words', 'words', 'words', '']
['Words', 'words, words.']
['0', '3', '9']
分析:
- 第一行代码中,一共分割了3次(分隔符分别为:两个', '和一个'.'),因此返回的列表中有4个元素;
- 第二行代码中,限制了最大分割次数为1,因此返回的列表中只有2个元素;
- 第三行代码中,指定分隔符为一个或多个连续的小写字字母,但是指定的flag为忽略大小写,因此大写字母也可以作为分隔符使用;那么从小写字母'a'和大写字母'B'分别进行切割,所以返回的列表中有3个元素。
实例2:捕获组与匹配空字符串的正则表达式
- 如果用于作为分割符的正则表达式包含捕获组,那么该捕获组所匹配的内容也会作为一个结果元素被返回;
- 从Python 3.5开始,如果作为分隔符的正则表达式可以匹配一个空字符串,将会引发一个warning;
- 从Python 3.5开始,如果作为分隔符的正则表达式只能匹配一个空字符串,那么它将会被拒绝使用并抛出异常。
print(re.split(r'(\W+)', 'Words, words, words.'))
print(re.split(r'x*', 'abcxde'))
print(re.split(r'^$', '\nfoo\nbar\n', re.M))
输出结果:
['Words', ', ', 'words', ', ', 'words', '.', '']
C:\Python35\lib\re.py:203: FutureWarning: split() requires a non-empty pattern match.
return _compile(pattern, flags).split(string, maxsplit)
['abc', 'de']
Traceback (most recent call last):
File "C:/Users/wader/PycharmProjects/PythonPro/regex2.py", line 68, in <module>
print(re.split(r'^$', '\nfoo\nbar\n', re.M))
File "C:\Python35\lib\re.py", line 203, in split
return _compile(pattern, flags).split(string, maxsplit)
ValueError: split() requires a non-empty pattern match.
实例3:实现一个电话簿
我们现在要使用Python正则表达式的字符串分割功能实现一个电话簿,具体流程是:从一个给定的文本中读取非空的行,然后把这些非空行进行切割得到相关信息。
text = """Ross McFluff: 834.345.1254 155 Elm Street
Ronald Heathmore: 892.345.3428 436 Finley Avenue
Frank Burger: 925.541.7625 662 South Dogwood Way
Heather Albrecht: 548.326.4584 919 Park Place"""
entries = re.split(r'\n+', text)
phonebook = [re.split(r':?\s+', entry, 3) for entry in entries]
print(phonebook)
输出结果:
[
['Ross', 'McFluff', '834.345.1254', '155 Elm Street'],
['Ronald', 'Heathmore', '892.345.3428', '436 Finley Avenue'],
['Frank', 'Burger', '925.541.7625', '662 South Dogwood Way'],
['Heather', 'Albrecht', '548.326.4584', '919 Park Place']
]
说明:实际输出中是没有这样的缩进格式的,这里只是为了方便大家查看。
分析:
- 上面这个例子总体上有两个分割过程,第一个分割是通过换行符为分割符得到所有的非空行列表,第二个分割是对得到的每一行文本进行切割,得到每一个联系人的相关信息;
- 每一行的内容分别为:firstname, lastname, tel, addr;
- 由于lastname与tel之间包含一个冒号,而其他内容之间只是包含空白字符,所以用于作为分隔符的正则表达式应该是':?\s+';
- 由于最后的那个addr是由多个段组成,且这些段之间也有空白字符,此时可以利用maxsplit参数限定最大分割次数,从而使得最后的3个字段作为一个addr整体返回。
四、关于匹配对象的说明
当我们通过re.match或re.search函数得到一个匹配对象m后,可以通过if m is None来判断是否匹配成功。在匹配成功的条件下,我们可能还想要获取匹配的值。Python中的匹配对象主要是以“组”的形式来获取匹配内容的,下面我们来看下具体操作:我们现在要通过一个正则表达式获取一个字符串中的'姓名'、'年龄'和'手机号码'
import re
p = re.compile(r'.*name\s+is\s+(\w+).*am\s+(?P<age>\d{1,3})\s+years.*tel\s+is\s+(?P<tel>\d{11}).*', re.DOTALL)
string = '''
My name is Tom,
I am 16 years old,
My tel is 13972773480.
'''
m = re.match(p, string)
# 或
# m = p.match(string)
if m is None:
print('Regex match fail.')
else:
result = '''
name: %s
age: %s
tel: %s
'''
print(result % (m.group(1), m.group(2), m.group('tel')))
输出结果:
name: Tom
age: 16
tel: 13972773480
分析:
- 由于要匹配的字符串中包括换行符,为了让元字符'.'能够匹配换行符,所以编译正则表达式需要指定re.DOTALL这个flag;
- 调用匹配对象的方法或属性前需要判断匹配是否成功,如果匹配失败,得到的匹配对象将是None,其方法和属性调用会报错;
- 对于"非命名捕获组"只能通过分组索引数字来获取其匹配到的内容,如m.group(1);而对于命名捕获组既可以通过分组索引数字来获取其匹配到的内容,如m.group(2),也可以通过分组名称来获取其匹配到的内容,如m.group('tel')。
使用match.expand(template)方法
我们在上面介绍匹配对象所提供的方法时对expand方法进行过说明:
match.expand(template)方法可用于通过得到的匹配对象来构造并返回一个新的字符串,template是一个字符串,用于指定新字符串的格式;从Python 3.5开始,未匹配到的分组将会替换为一个空字符串
这里我们用它来实现上面这个例子的输出效果,大家体会下它的功能:
import re
p = re.compile(r'.*name\s+is\s+(\w+).*am\s+(?P<age>\d{1,3})\s+years.*tel\s+is\s+(?P<tel>\d{11}).*', re.DOTALL)
string = '''
My name is Tom,
I am 16 years old,
My tel is 13972773480.
'''
# m = re.match(p, string)
# 或
m = p.match(string)
if m is None:
print('Regex match fail.')
else:
template_str = '''
name: \g<1>
age: \g<2>
tel: \g<tel>
'''
print(m.expand(template_str))
输出结果,跟上面是一样的。
打印匹配对象中包含的数据
这里,我们主要是想通过对匹配对象各个方法和属性的调用,让大家更深刻的理解通过这些方法和属性我们可以得到什么。
p = re.compile(r'.*name\s+is\s+(\w+).*am\s+(?P<age>\d{1,3})\s+years.*tel\s+is\s+(?P<tel>\d{11}).*', re.DOTALL)
string = '''
My name is Tom,
I am 16 years old,
My tel is 13972773480.
'''
# m = re.match(p, string)
# 或
m = p.match(string)
if m is None:
print('Regex Match Fail!')
else:
print('match_obj.group(): ', '匹配到的所有内容: ', m.group())
print('match_obj.group(0): ', '同上: ', m.group(0))
print('match_obj.group(1): ', '第一个捕获组匹配到的内容: ', m.group(1))
print('match_obj.group(2): ', '第二个命名捕获组匹配到的内容: ', m.group(2))
print('match_obj.group("tel"): ', '第三个命名捕获组匹配到的内容: ', m.group('tel'))
print('match_obj.groups(): ', '所有捕获组匹配到的内容组成的元组对象: ', m.groups())
print('match_obj.groupdict(): ', '所有命名捕获组匹配到的内容组成的字典对象: ', m.groupdict())
print('match_obj: ', '直接打印匹配对象: ', m)
print('match_obj.string: ', '传递给re.match函数的字符串参数: ', m.string)
print('match_obj.re: ', '传递给re.match函数的正则表达式对象: ', m.re)
print('match_obj.pos, match_obj.endpos: ', '传递个match方法的pos和endpos参数: ', m.pos, m.endpos)
print('match_obj.pos, match_obj.start(1), match_obj.end(1): ', '第一个捕获组匹配的内容在字符串中的切片位置: ', m.start(1), m.end(1))
print('match_obj.pos, match_obj.span(1): ', '第一个捕获组匹配的内容在字符串中的切片位置: ', m.span(1))
print('match_obj.pos, match_obj.start("tel"), match_obj.end("tel"): ', '命名捕获组tel匹配的内容在字符串中的切片位置: ', m.start('tel'), m.end('tel'))
print('match_obj.pos, match_obj.span(tel): ', '命名捕获组tel匹配的内容在字符串中的切片位置: ', m.span('tel'))
输出结果:
match_obj.group(): 匹配到的所有内容:
My name is Tom,
I am 16 years old,
My tel is 13972773480.
match_obj.group(0): 同上:
My name is Tom,
I am 16 years old,
My tel is 13972773480.
match_obj.group(1): 第一个捕获组匹配到的内容: Tom
match_obj.group(2): 第二个命名捕获组匹配到的内容: 16
match_obj.group("tel"): 第三个命名捕获组匹配到的内容: 13972773480
match_obj.groups(): 所有捕获组匹配到的内容组成的元组对象: ('Tom', '16', '13972773480')
match_obj.groupdict(): 所有命名捕获组匹配到的内容组成的字典对象: {'age': '16', 'tel': '13972773480'}
match_obj: 直接打印匹配对象: <_sre.SRE_Match object; span=(0, 75), match='\n My name is Tom,\n I am 16 years old,\n >
match_obj.string: 传递给re.match函数的字符串参数:
My name is Tom,
I am 16 years old,
My tel is 13972773480.
match_obj.re: 传递给re.match函数的正则表达式对象: re.compile('.*name\\s+is\\s+(\\w+).*am\\s+(?P<age>\\d{1,3})\\s+years.*tel\\s+is\\s+(?P<tel>\\d{11}).*', re.DOTALL)
match_obj.pos, match_obj.endpos: 传递个match方法的pos和endpos参数: 0 75
match_obj.pos, match_obj.start(1), match_obj.end(1): 第一个捕获组匹配的内容在字符串中的切片位置: 16 19
match_obj.pos, match_obj.span(1): 第一个捕获组匹配的内容在字符串中的切片位置: (16, 19)
match_obj.pos, match_obj.start("tel"), match_obj.end("tel"): 命名捕获组tel匹配的内容在字符串中的切片位置: 58 69
match_obj.pos, match_obj.span(tel): 命名捕获组tel匹配的内容在字符串中的切片位置: (58, 69)
五、说说正则表达式字符串前的r前缀
前面我们介绍re模块使用步骤时,第一步就是“编写一个表示正则表达式规则的Python字符串”,那么正则表达式与Python字符串之间是什么关系呢?另外,我们通常都在一个正则表达式字符串前加上一个前缀r是何用意呢?
因为正则表达式并不是Python语言的核心部分(有些应用程序根本就不需要正则表达式,re模块就像socket或zlib一样,只是包含在Python中的一个简单的C语言扩展模块),也没有创建专门的语法来表示它们,所以在Python中正则表达式是以Python字符串的形式来编写并进行处理的。但是,我们应该知道的是字符串有 字符串的字面值(我们给一个字符串赋的值) 和 字符串的实际值(这个字符串的打印值),且正则表达式引擎把一个字符串作为正则表达式处理时,所取的是这个字符串的实际值,而不是它的字面值。
问题1:
字符串的字面值 与 字符串的实际值 不一定是等价的,因为有些字符组合起来表示的是一个特殊的符号,此时会导致正则表达式错误而无法匹配到想要的结果。比如:\1在正则表达式中表示引用第一个捕获组所匹配到的内容,而在字符串中却表示一个特殊的字符,因此如果一个表示正则表达式的字符串中包含"\1"且没有做任何处理的话,它是无法匹配到我们想要的结果的。如下图所示:

如果想要匹配正确结果就需要对该字符串中表示特殊字符的字符组合进行处理,我们只需要在'\1'前加一个反斜线对'\1'中的反斜线进行转义就可以了,即字符串"\1"的字面值才是\1。如下图所示:

也就是说,一个正则表达式要想用一个Python字符串来表示时,可能需要对这个字符串的字面值做一些特殊的转义处理。
问题2:
现在反过来考虑,\s在正则表达式中表示空白字符,如果我们想匹配一个字符串中'\s'这两个字符,就需要在正则表达式中\s前也加一个反斜线进行转义\\s。那么这时候表示正则表达式的字符串同样不能直接写'\\s',因为它是字符串字面值,其实际值是\s,因此此时也是不能匹配到我们想要的结果的。如下图所示:

如果想要匹配正确结果就需要对该字符串进行一些处理,我们需要在'\\s'前加两个反斜线对'\\s'中的两个反斜线分别进行转义,即字符串"\\\\s"的字面值才是\\s。如下图所示:

字符串的r前缀
通过上面两个问题我们可以得出以下结论:
- 1)这些问题都是由于反斜线引起的,这种现象也被称为"反斜线瘟疫";
- 2)Python字符串与正则表达式都使用反斜线进行字符转义,正是由于这种冲突才引起了这些问题;
- 3)当一个正则表达式中又很多个反斜线要处理时,那无疑将是一种灾难。
怎么办呢?忘掉上面这所有的问题吧,你只需要在表示正则表达式的字符串前加上一个前缀r就可以把这个字符串当然正则表达式来写了。 r是Raw,即“原始”的意思,带有r前缀的字符串就叫做“Raw String”,即原始字符串的意思。也就是说当一个字符串带有r前缀时,它的字面值就是其真实值,也就是正则表达式的值。


简单来说,表示正则表达式匹配规则的字符串前面的r前缀是为了解决字符串中的反斜线与正则表达式中的反斜线引起的冲突问题。另外,我们根本无需关心哪些字符会引起这样的冲突,只需要在每个表示正则表达式的字符串前加上一个r前缀就可以了。
六、re模块综合应用实例
0. 实例背景与准备工作
假设你正在写一个扑克游戏,每张牌分别用一个字符来表示:
- 'a' 代表老A,也叫“尖儿”
- 'k' 代表老K
- 'q' 代表Q,也叫“圈儿”
- 'j' 代表J, 也叫“钩儿”
- 't' 代表10
- '2'-'9' 分别代表2-9这几个数字
另外,游戏规则要求每个玩家手中要有5张牌,不能多也不能少。
首先,我们先来写一个工具函数来帮助我们更优雅的展示匹配结果:
def display_match_obj(match_obj):
if match_obj is None:
return None
return '<Match: %r, groups=%r>' % (match_obj.group(), match_obj.groups())
实例1. 首先匹配玩家手中的牌是否符合游戏规则
匹配规则分析
游戏规则有两个:
- 1)玩家手中的牌只能是'a', 'k', 'q', 'j', 't' 和 '2'-'9'中的字符
- 2)玩家手中的牌只能有5张
所需知识点
- 字符群组元字符:[]
- 量词元字符:
- 边界匹配元字符:'^'和'$'
正则表达式
正确的正则表达式应该是这样的:'^[akqjt2-9]{5}$'
匹配测试
下面来看下面几个匹配测试
import re
p = re.compile(r"^[atjqk2-9]{5}$")
display_match_obj(p.match("akt5q"))
display_match_obj(p.match("akt5e"))
display_match_obj(p.match("akt"))
display_match_obj(p.match("727ak"))
display_match_obj(p.match("aaaak"))
输出结果:
<Match: 'akt5q', groups=()>
Invalid
Invalid
<Match: '727ak', groups=()>
<Match: 'aaaak', groups=()>
分析:
- 'akt5e'中的包含非法字符'e',因此匹配不成功
- 'akt'中字符个数不是5,因此匹配不成功
- groups为空元组表示没有匹配到分组信息
实例2. 匹配玩家手中的牌是否包含对子(两张一样的牌)
匹配规则分析
这里,我们先不考虑上面的规则,仅仅考虑需要包含两张一样的牌。
所需知识点
- 分组与向后引用:(...)和\n
正则表达式
正确的正则表达式应该是这样的:'.*(.).*\1.*'
匹配测试
下面来看下面几个匹配测试
import re
p = re.compile(r".*(.).*\1.*")
display_match_obj(p.match("akt5q"))
display_match_obj(p.match("akt5e"))
display_match_obj(p.match("akt"))
display_match_obj(p.match("727ak"))
display_match_obj(p.match("aaaak"))
输出结果:
Invalid
Invalid
Invalid
<Match: '727ak', groups=('7',)>
<Match: 'aaaak', groups=('a',)>
分析:
- 只有'727ak'和'aaaak'中的包含两个相同的字符,其他的字符串都不匹配。
- '727ak'和'aaaak'中被分组匹配到的字符分别是'7'和'a'
思考:如果想匹配包含3张或者4张相同牌,正则表达式该怎样写呢?
其实很简单,只要重复相应次数的 '\1.*' 就可以了:
- 匹配包含3张相同牌的正则表达式:
'.*(.).*\1.*\1.*' - 匹配包含4张相同牌的正则表达式:
'.*(.).*\1.*\1.*\1.*'
实例3:把上面两个例子的匹配需求整合起来
匹配分析
这个要求的难点在于,这两个匹配需求的匹配规则相对独立无法用一个常规的正则表达式匹配模式来表达。要把多个相对独立的正则表达式整合到一起,我们有两种实现方式:
- 1)匹配两次:先用第一个例子中的正则表达式进行匹配,匹配通过再进行第二个匹配
- 2)使用元字符特殊构造:(?=...)
第1种实现方式:匹配两次
import re
def process_match(string):
p1 = re.compile(r"^[akqjt2-9]{5}$")
if p1.match(string):
p2 = re.compile(r".*(.).*\1.*")
display_match_obj(p2.match(string))
else:
display_match_obj(None)
if __name__ == "__main__":
process_match("727a")
process_match("727akk")
process_match("72tak")
process_match("727ak")
输出结果:
Invalid
Invalid
Invalid
<Match: '727ak', groups=('7',)>
分析:
- '727a'和'727akk'中的字符个数都不满足第一个正则表达式,因此匹配失败
- '72tak'虽然满足第一个正则表达式,但是不包含对子,因此也匹配失败
- 只有'727ak'既满足第一个正则表达式,又包含对子(一对7),因此匹配成功
- 可见,两个正则表达式都生效了
第2种实现方式:使用元字符特殊构造 (?=...)
import re
p = re.compile(r"(?=^[akqjt2-9]{5}$)(?=.*(.).*\1.*)")
display_match_obj(p.match("727a"))
display_match_obj(p.match("727akk"))
display_match_obj(p.match("72tak"))
display_match_obj(p.match("727ak"))
输出结果:
Invalid
Invalid
Invalid
<Match: '', groups=('7',)>
分析:
- 由输出结果可知,同样也是最后一个匹配成功,因此这个正则表达式
'(?=^[akqjt2-9]{5}$)(?=.*(.).*\1.*)'是满足要求的;- 另外,发现Match的结果为空,这是因为特殊构造
(?=...)在匹配过程中是不消费字符的,这也就说明这种特殊构造只适合做匹配测试,不能获取匹配到的内容。
七、参考文档
问题交流群:666948590
a-z ↩︎

 浙公网安备 33010602011771号
浙公网安备 33010602011771号