Python之xml文档及配置文件处理(ElementTree模块、ConfigParser模块)
本节内容
- 前言
- XML处理模块
- ConfigParser/configparser模块
- 总结
一、前言
我们在 <<Python之数据序列化>> 中我们描述了Python数据持久化的大体概念和基本处理方式,通过这些知识点我们已经能够处理大部分Python数据序列化/反序列化的需求。本节我们来介绍下另外两个模块,它们都有各自特殊的用途,且提供了功能更加强大的api:
模块名称 | 描述
- | - | -
xml.etree.ElementTree(简称ET) | 一个简单、轻量级的XML处理器,用于创建、解析、处理XML数据
ConfigParser(Python 3.x中已改名为configparser) | 配置文件解析器, 用于创建、解析、处理类似Windows系统上的INI配置文件
二、xml处理模块:xml.etree.ElementTree
1. XML简介
XML,全称eXtensible Markup Language,即可扩展标记语言。它可以用来标记数据、定义数据类型,是一种允许用户对自己的标记语言进行定义的源语言。XML的结构与HMTL(超文本标记语言)结构很相似,但是HTML是用来显示数据的,而XML主要用来传输和存储数据。
来看一个XML实例,它表示的是一个植物列表:
<?xml version="1.0" encoding="utf-8"?>
<CATALOG>
<PLANT id='001'>
<NAME>Sanguinaria canadensis</NAME>
<LIGHT>Mostly Shady</LIGHT>
</PLANT>
<PLANT id='002'>
<NAME>Aquilegia canadensis</NAME>
<LIGHT>Mostly Shady</LIGHT>
</PLANT>
<PLANT id='003'>
<NAME>Phlox divaricata</B=NAME>
<LIGHT>Sun or Shade</LIGHT>
</PLANT>
</CATALOG>
由上面的XML实例,可以看出XML数据有以下几个特征:
- XML是由多个标签对组成,如:
<CATALOG></CATALOG>,<PLANT></PLANT>等 - 标签是可以有属性的,如:
<PLANT id='001'></PLANT>中的id就是PLANT标签的一个属性 - 标签对应的数据放在标签对中间,如:
<NAME>Sanguinaria canadensis</NAME> - 标签可以嵌套,如下所示:
<CATALOG>
<PLANT>
<NAME></NAME>
</PLANT>
</CATALOG>
2. XML tree 和 elements的概念和相关类介绍
XML是一种层级化的数据格式,因此它最自然的表示方式是一个(倒置的)树形结构。如上面表示植物列表的XML对应的树形结构应该是这样的:
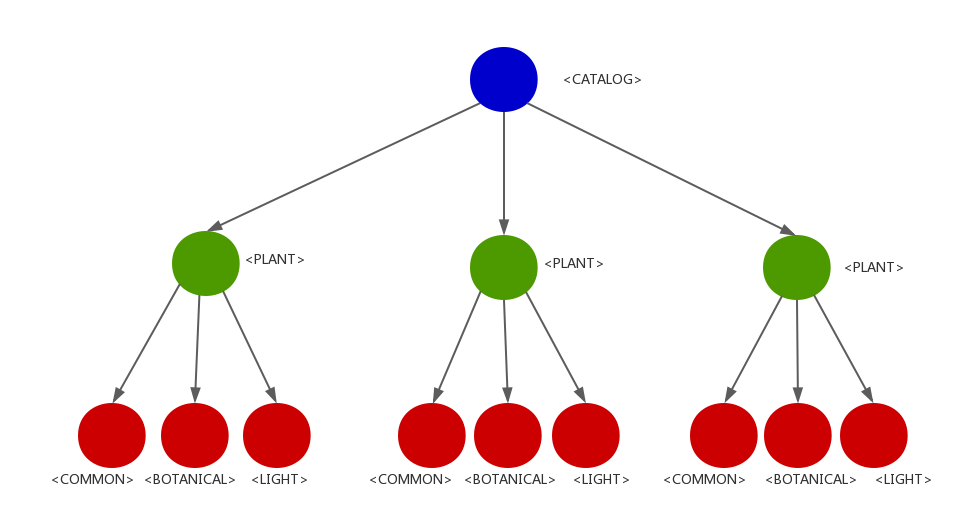
在面向对象的编程语言中,我们需要定义几个类来表示这个树形结构的组成部分。分析这个树形结构我们发现其实每个节点(指的是上图中的每个圆形,对应XML中的每个标签对)都可以抽象为一个共同的类,比如叫Leaf(叶子)、Node(节点)、Element都可以。但是,除了表示节点的类,我们还需要定义一个类来表示这个树本身。ET(xml.etree.ElementTree)中就设计了以下几个类:
- ElementTree: 表示整个XML层级结构
- Element: 表示树形结构中所有的父节点
- SubElement: 表示树形结构中所有的子节点
有些节点既是父节点,又是子节点
下面来看下这两个类的定义及其提供的函数:
Element类
class xml.etree.ElementTree.Element(tag, attrib={}, **extra)
Element类对应的是树形结构中的每个节点,对应的是XML文档中的标签对。我们上面提到过XML标签有以下几个特征,除了子标签外都有相应的属性与之对应:
标签特征 | 对应的类属性 | 数据类型
- | - | -
标签名称 | tag | 字符串
属性 | attrib | 字典,所有属性和属性值的集合
标签值 | text | 通常是字符串
与下一个标签之间的值 | tail | 通常是字符串
子标签 | 无 | 标签的父子关系是在SubElement中指定的
关于Element.text和Element.tail属性的说明:
- 它们可被用于保存于该Element相关的额外数据;
- 它们的值通常是字符串,但是也可以是任何应用特定的对象类型;
- 如果Element对象是由一个XML创建而来的,那么
text属性保存的是这个element的开始标签与它的第一个子标签或结束标签之间的文本或是None;而tail保存的是这个element的结束标签与下一个标签之间的文本或None,可以看下面的例子。
<a><b>1<c>2<d/>3</c></b>4</a>
- element a 的text和tail属性值都是None;
- element b 的text属性值是1,tail属性值是4;
- element c 的text属性值是2, tail属性值是None;
- element d 的text属性值是None, tail的属性值是3;
Element类中用于操作标签属性attrib的方法(类似于字典的方法):
# 以一个(name, value)的序列的形式返回该element所有属性,且属性在序列是随机的
items()
# 返回该element所有属性的名称列表,属性名称顺序随机
keys()
# 获取该element指定属性key的值
get(key, default=None)
# 设置该element指定属性的值
set(key, value)
# 重置当前element:删除所有的 subelemnts、清空所有属性、设置text和tail属性值为None
clear()
Element类中用于操作子标签(subelement)的方法:
# 向最后添加一个子标签
append(subelement)
# 向最后追加多个子标签,subelements是一个Element序列;这是Python 3.2中新增的方法
extends(subelements)
# 像该element的指定位置插入一个subelement
insert(index, subelement)
# 返回第一个与match匹配的subelement或None,match可以是一个tag名称(标签名称),也可以是一个path
find(match, namespaces=None)
# 返回所有与match匹配的subelement列表或None,match可以是一个tag名称(标签名称),也可以是一个path
findall(match, namespaces=None)
# 返回第一个与match匹配的subelement的text属性值,如果匹配到的element没有text属性则返回一个空字符串,如果没有匹配到subelement则返回default参数定义的值
findtext(match, default=None, namespaces=None)
# Python 3.2开始已将该方法废弃,请使用list(elem)或迭代
getchildren()
# Python 3.2开始已将该方法废弃,改用Element.iter()
getiterator(tag=None)
# 这是Python 3.2中新增的方法。以当前element作为根创建一个tree迭代器,该迭代器会议深度优先的方式迭代这个element及其下面的所有elements。如果tag不是None或'*',则只有tag值等于tag参数所指定值的element才会被这个迭代器返回;如果树形结构在迭代过程中被修改,则结果为undefined。
iter(tag=None)
# 这是Python 3.2中新增的方法。查找与match参数指定的tag名称或path相匹配的所有subelements,返回一个以文档顺序产生所有匹配element的可迭代对象。
iterfind(match, namespaces=None)
# 这是Python 3.2中新增的方法。创建一个迭代器,这个迭代器以文档顺序循环当前element和所有subelements并返回所有内部文本。
itertext()
# 从当前element中移除指定的subelement
remove(subelement)
SubElement类
SubElement(parent, tag, attrib={}, **extra)
parent参数表示父节点(标签对),它应该是一个Element类的实例。SubElement的其他属性和函数与Element相同。
ElementTree类
ElementTree表示的是整个element层级关系,并且该类还添加了一些对标准XML序列化和反序列化的额外支持。
class xml.etree.ElementTree.ElementTree(element=None, file=None)
element: 是一个Element实例,表示root element;
file: 是一个XML文件文成,如果该参数被给出,则会以该文件的内容初始化树形层次结构;
下面是ElementTree提供的方法:
# 以指定的element实例替换当前tree的root element,相当于把整个XML的内容替换掉了
_setroot(element)
# 返回当前树形层级结构的root element
getroot()
# 与Element.find()功能相同,只是它是从树形结构的root element开始查找
find(match, namespaces=None)
# 与Element.findall()功能相同,只是它是从树形结构的root element开始查找
findall(match, namespaces=None)
# 与Element.findtext()功能相同,只是它是从树形结构的root element开始查找
findtext(match, default=None, namespaces=None)
# Python 3.2开始已将该方法废弃,改用ElementTree.iter()
getiterator(tag=None)
# Python 3.2新增的方法。为当前root element创建并返回一个树迭代器,该迭代器将会按顺序循环这个树形结构的中的所有与tag匹配的elements,默认返回所有elements
iter(tag=None)
# Python 3.2新增的方法。与Element.iterfind()功能相同,只是它是从树形结构的root element开始查找
iterfind(match, namespaces=None)
# 加载一个外部XML片断到当前element树并返回该XML片断的root element。source是一个文件名称或文件对象。parser是一个可选的parser实例,如果没有给出该参数,将会使用标准的XMLParser解析器。
parse(source, parser=None)
# 将当前element tree以XML形式写入一个文件中。
# file 是一个文件名称或一个以写模式打开的文件对象
# encoding 用于指定输出编码
# xml_declaration 用于控制师傅将一个XML声明也添加到文件中(False表示添加、True表示不添加、None表示只有编码不是"US-ASCII"或"UTF-8"或"Unicode"时才添加)
# default_namespace 设置默认的XML命名空间(“xmlns”)
# method 可取值为"xml"、"html"和"text",默认为"xml"
# short_empty_elements 是唯一一个关键字参数,是Python 3.4新增加的参数。它用于控制那些不包含任何内容的elements的格式,如果该参数值为Ture则这些标签将会被输出为一个单独的自关闭标签(如: <a/>),如果值为False则这些标签将会被输出为一个标签对(如:<a></a>)
write(file, encoding="us-ascii", xml_declaration=None, default_namespace=None, method="xml", *, short_empty_elements=True)
注意:
write()方法的输出可以是一个字符串(str),可以可以是二进制(bytes)。这是受encoding参数控制的:
- 如果encoding参数值为"unicode",则输出是一个字符串;
- 否则,输出时二进制字节。
如果file是一个(以可写模式)打开的文件对象,这有可能会发生冲突。因此,我们需要确定不会尝试将一个字符串写入一个二进制流,反之亦然。
3. xml.etree.ElementTree模块提供的函数
xml.etree.ElementTree模块也直接提供了一些函数便于我们直接对XML进行操作,下面来介绍几个常用的函数:
# 解析包含XML数据的字符串,返回一个Element实例
xml.etree.ElementTree.fromstring(text)
# 生成并返回指定的Element实例对应的包含XML数据的字符串(encoding="unicode")或字节流
# 参数讲解请参考上面的ElementTree类的write()方法
xml.etree.ElementTree.toString(element, encoding="us-ascii", method="xml", *, short_empty_elements=True)
# 解析包含XML数据的文件名或文件对象,返回一个ElementTree实例
xml.etree.ElementTree.parse(source, parser=None)
# 将XML数据以递增的方式解析到元素树中,并向用户报告发生了什么(类似SAX的回调机制),最终返回一个提供(event, elem)对的迭代器(iterator)。
# source 是一个包含XML数据的文件名称或文件对象
# events 是一个包含要报告的事件序列,这里支持的事件包括:"start"、"end"、"start-ns"、"end-ns"(“ns”事件用于获取详细的命名空间信息)。如果event参数被省略,则仅报告"end"事件。
# parser是一个可选的解析器实例,如果为给出则使用标准的XMLParser解析器
xml.etree.ElementTree.iterparse(source, events=None, parser=None)
关于xml.etree.ElementTree.iterparse()方法的说明:
- 虽然它以递增的方式构建元素树,但是它仍然会锁定对source的读取操作。因此,它不适用于不能接受读阻塞的应用。
- 它只保证在发出一个“start”事件时,它已经看到了起始标签(tag)的">"结束字符,因此此时它定义了atrrib属性,但是text和tail属性的内容在那一时刻是没有被定义的(这同样适用于子元素)。如果你需要一个完全填充的元素,请查找“end”事件。
4. 实例
实例1:生成XML数据
生成上面表示植物列表XML数据:
import xml.etree.ElementTree as ET
# 创建root element
catalog = ET.Element("CATALOG")
# 直接通过SubElement类为root element添加一个子元素
plant01 = ET.SubElement(catalog, "PLANT", attrib={"id": "001"})
name01 = ET.SubElement(plant01, "NAME")
name01.text = "Sanguinaria canadensis"
light01 = ET.SubElement(plant01, "LIGHT")
light01.text = "Mostly Shady"
# 通过Element.append()方法为root element添加一个子元素
plant02 = ET.Element("PLANT", id="002")
name02 = ET.Element("NAME")
name02.text = "Aquilegia canadensis"
light02 = ET.Element("LIGHT")
light02.text = "Mostly Shady"
plant02.append(name02)
plant02.append(light02)
catalog.append(plant02)
# 通过SubElement类和Element.append()方法为root element添加一个子元素
plant03 = ET.Element("PLANT", id="003")
name03 = ET.SubElement(plant03, "NAME")
name03.text = "Phlox divaricata"
light03 = ET.SubElement(plant03, "LIGHT")
light03.text = "Sun or Shade"
catalog.append(plant03)
# 以指定的root element创建一个ElementTree实例
et = ET.ElementTree(element=catalog)
# 将创建的ElementTree对应的XML数据写入(序列化)到本地文件
et.write("plants.xml", encoding="utf-8", xml_declaration=True)
此时会在当前目录生成一个名为"plants.xml"的文件,内容和上面表示植物列表的XML数据一致。另外,通过上面的实例可知,使用SubElement创建和添加子元素是最方便的。
<?xml version='1.0' encoding='utf-8'?>
<CATALOG>
<PLANT id="001">
<NAME>Sanguinaria canadensis</NAME>
<LIGHT>Mostly Shady</LIGHT>
</PLANT>
<PLANT id="002">
<NAME>Aquilegia canadensis</NAME>
<LIGHT>Mostly Shady</LIGHT>
</PLANT>
<PLANT id="003">
<NAME>Phlox divaricata</NAME>
<LIGHT>Sun or Shade</LIGHT>
</PLANT>
</CATALOG>
实例2:解析XML数据
解析上面生成的XML数据
import xml.etree.ElementTree as ET
# 由以下两种方式可以从一个包含XML数据的文件创建一个ElementTree实例
# et = ET.ElementTree(file="plants.xml")
et = ET.parse("plants.xml")
# 获取root element
elem01 = et.getroot()
print(elem01.tag) # CATALOG
# 获取第一个标签为"PLANT"的“直接” subelement
elem02 = et.find("PLANT")
print(elem02.tag)
print(elem02.attrib)
print(elem02.items())
print(elem02.keys())
print(elem02.get("id"))
# 遍历指定element的所有subelement
for e in elem02:
ET.dump(e)
# 获取所有标签为"PLANT"的“直接” subelement
for e in et.findall("PLANT"):
print(ET.tostring(e, encoding="unicode"))
print(e.items())
# 遍历XML中所有的element
for e in et.iter():
print(ET.tostring(e))
输出结果为:
CATALOG
PLANT
{'id': '001'}
[('id', '001')]
['id']
001
<NAME>Sanguinaria canadensis</NAME>
<LIGHT>Mostly Shady</LIGHT>
<PLANT id="001"><NAME>Sanguinaria canadensis</NAME><LIGHT>Mostly Shady</LIGHT></PLANT>
[('id', '001')]
<PLANT id="002"><NAME>Aquilegia canadensis</NAME><LIGHT>Mostly Shady</LIGHT></PLANT>
[('id', '002')]
<PLANT id="003"><NAME>Phlox divaricata</NAME><LIGHT>Sun or Shade</LIGHT></PLANT>
[('id', '003')]
<CATALOG><PLANT id="001"><NAME>Sanguinaria canadensis</NAME><LIGHT>Mostly Shady</LIGHT></PLANT><PLANT id="002"><NAME>Aquilegia canadensis</NAME><LIGHT>Mostly Shady</LIGHT></PLANT><PLANT id="003"><NAME>Phlox divaricata</NAME><LIGHT>Sun or Shade</LIGHT></PLANT></CATALOG>
<PLANT id="001"><NAME>Sanguinaria canadensis</NAME><LIGHT>Mostly Shady</LIGHT></PLANT>
<NAME>Sanguinaria canadensis</NAME>
<LIGHT>Mostly Shady</LIGHT>
<PLANT id="002"><NAME>Aquilegia canadensis</NAME><LIGHT>Mostly Shady</LIGHT></PLANT>
<NAME>Aquilegia canadensis</NAME>
<LIGHT>Mostly Shady</LIGHT>
<PLANT id="003"><NAME>Phlox divaricata</NAME><LIGHT>Sun or Shade</LIGHT></PLANT>
<NAME>Phlox divaricata</NAME>
<LIGHT>Sun or Shade</LIGHT>
实例3:修改与删除XML数据
import xml.etree.ElementTree as ET
# 从plants.xml文件初始化一个ElementTree实例
et = ET.parse("plants.xml")
# 获取第一个标签为PLANT的element
elem = et.find("PLANT")
print(ET.tostring(elem, encoding="unicode"))
# 为这个element设置一个新的标签属性
elem.set("color", "red")
print(ET.tostring(elem, encoding="unicode"))
# 清空这个element的所有属性、文本和 subelement
elem.clear()
print(ET.tostring(elem, encoding="unicode"))
print(ET.tostring(elem, encoding="unicode", short_empty_elements=False))
namelist = ET.Element("NameList")
name = ET.SubElement(namelist, "name", attrib={"name": "Tom"})
age = ET.SubElement(name, "age")
age.text = '22'
role = ET.SubElement(name, "role")
role.text = 'cat'
name = ET.SubElement(namelist, "name", attrib={"name": "Jerry"})
age = ET.SubElement(name, "age")
age.text = '20'
role = ET.SubElement(name, "role")
role.text = 'mouse'
# 替换整个XML属性结构的内容为一个名字列表
et._setroot(namelist)
print(ET.tostring(namelist, encoding="unicode"))
# 将修改过的ElementTree实例以XML的形式序列化到新的文件中
et.write("name_list.xml", encoding="utf-8", xml_declaration=True)
输出结果为:
<PLANT id="001"><NAME>Sanguinaria canadensis</NAME><LIGHT>Mostly Shady</LIGHT></PLANT>
<PLANT color="red" id="001"><NAME>Sanguinaria canadensis</NAME><LIGHT>Mostly Shady</LIGHT></PLANT>
<PLANT />
<PLANT></PLANT>
<NameList><name name="Tom"><age>22</age><role>cat</role></name><name name="Jerry"><age>20</age><role>mouse</role></name></NameList>
同时,会在当前目录下生成一个新的名为"name_list.xml"的文件:
<?xml version='1.0' encoding='utf-8'?>
<NameList>
<name name="Tom">
<age>22</age>
<role>cat</role>
</name>
<name name="Jerry">
<age>20</age>
<role>mouse</role>
</name>
</NameList>
5. 补充说明
需要说明的是,Python中用于处理和操作XML数据的模块不仅仅是这里介绍的xml.etree.ElementTree模块,下面这张图是Python 3.5.2中xml包(package)下的所有模块。

Python处理XML数据的4种方法
总体来讲,这些模块对应的是对XML进行操作的种中方法:
- DOM: DOM解析器在进行任何处理之前,必须把XML文件生成的树形结构数据一次性完全放到内存中,所以DOM解析器的内存使用量完全是由要处理的XML数据的大小决定的。
- SAX: SAX是Simple API for XML的缩写,它牺牲了便捷性来获取内存占用量的降低。它是事件驱动的,并需要一次性读入整个XML文档,文档的读入过程就是SAX的解析过程。所谓事件驱动,是指一种基于回调机制的程序运行方法,通常我们需要提前写好相应的处理函数等待被回调(比如,当读取到一个开始标签时、读取到一个结束标签时,这些都是一种事件)。
- Expat: expat接口与SAX类似,也是基于事件回调机制,但是该接口并不是标准化的,只适用于expat库。
- ElementTree: ElementTree是一个轻量级的DOM实现,它提供了Pythonic的API,同时还有一个高效的C语言实现,即 xml.etree.cElementTree。但是从Python 3.3开始cElementTree模块已经被废弃了,从官方文档上的说明来看,应该是与ElementTree合并了,解释器会在尽可能多的情况下自动启动更高效的处理方式。
以上几种方式的对比
- 与DOM相比,ET的速度更快,API使用也更直观、便捷。
- 与SAX相比,ET.iterparse()函数同样提供了按需解析XML数据的功能,而可以不用一次性在内存中读入整个文档。ET的性能与SAX模块大致相仿,但是它的API抽象层次更高,使用更加方便。
可见,ET与SAX和DOM相比更加有优势,因此我们推荐使用ET处理XML数据。当然,如果在某种特定的情况下需要使用其它API也是可以的。
注意: 解析XML的这几种API并不是Python独创的,Python是通过借鉴其它语言或直接从其它语言引入进来的。例如expat就是一个用C语言开发的、用来解析XML文档的开发库;SAX最初是由DavidMegginson使用java语言开发的;而DOM可以以一种独立于平台和语言的方式访问和修改一个文档的内容和结构,也就是说它可以应用于任何编程语言。
以上文字来自<<这里>>。
三、ConfigParser/configparser模块
1. 模块初识
ConfigParser模块在Python3中已经被重命名为configparser,从模块名称上就可以看出这是一个配置解析器模块。那么这里哟两个问题:
问题1:这个模块用于处理什么格式的配置文件?
它用于处理(读写)与Windows上的INI文件结构相似的文件,其格式类似于这样:
[DEFAULT]
ServerAliveInterval = 45
Compression = yes
CompressionLevel = 9
ForwardX11 = yes
[bitbucket.org]
User = hg
[topsecret.server.com]
Port = 50022
# Enable X11 forward protocol or not?
ForwardX11 = no
可看出,则个文件由3个组成部分:
组成部分名称 | 描述 | 实例
- | - | -
[section] | 相当于一个分组 | [DEFAULT]、 [bitbucket.ogrg]
options | 每个分组下面包含0个多个的key = value形式的选项,也可以这样写key : value| User = hg, Port = 50022
comment | 注释,说明性文字;默认以“#”号或“;”号开头的行 | # Enable X11 forward protocol or not?
说明:
[DEFAULT]是一个特殊的section,它为其它section提供它所包含的option的默认值。也就是说其它section默认会继承[DEFAULT]下所有option的值,但是各个section可以覆盖这些默认值。换句话说,在获取某个section下不存在但是在[DEFAULT]下存在的option的值时,获取的就是[DEFAULT]下这个option的值。
搞运维的同学会说,这跟mysql和php的配置文件结构一样。是的,这种格式的文件已经被广泛使用。
问题2:Python开发的什么场景下会用到这个模块?
当我们需要编写一个允许用户自定义某些功能参数的Python程序时就会用到这个模块。这其实很好理解,想想mysql和php的配置文件的作用就明白了。php和mysql就相当于我们自己编写的Python程序,它们允许我们这些用户通过配置文件(my.cnf和php.ini)来自定义一些参数从而影响php和mysql的运行。显然,php和mysql的实现程序中必然要有相应的代码来解析这些配置文件中的参数值。而在编写Python程序时,这个解析配置文件的工作就可以由ConfigParser/configparser模块来完成。只是ConfigParser/configparser模块不仅仅可以解析配置信息,还可以创建、修改和删除配置信息。
2. 如果让你来开发这个模块,你会提供哪些功能?
这个配置文件很简单,只有3个组成部分:section、options、comment,因此这个模块提供的功能应该就是对这3个组成部分的增、删、改、查操作。那么我们至少应该提供以下几个函数:
功能 | 模拟函数名
- | -
添加一个section | add_section(section_name)
在一个section下添加或修改一个option | set_option(section_name, option_name, option_value)
删除指定的section | remove_section(section_name)
删除一个section下的某个option | remove_option(section_name, option_name)
返回所有section的列表 | list_sections()
返回指定section下所有option名称列表 | list_option_keys(section_name)
返回包含指定setcion下所有option的字典 | list_option_items(section_name)
获取指定section下的指定option的值 | get_option(section_name,option_name)
好的,思考结束,下面来看看大神们是怎么做的。
3. Python 2中的ConfigParser模块
模块概述
Python 2中的ConfigParser模块提供了3个相关的类,这3各类是依次的继承关系,下面每一层缩进都表示一层继承关系:
class RawConfigParser
class ConfigParser
class SafeConfigParser
它们提供的功能是依次增强的:
类名 | 描述
- | -
RawConfigParser | 提供配置文件读写相关功能、不支持格式字符串替换
ConfigParser | 允许取当前section或DEFAULT下option的值进行格式字符串替换
SafeConfigParser | 允许取其他section下option的值进行格式字符串替换
格式字符串替换 是指一个option的值中可以包含并动态引用其它option的值,如:
base_dir = /data/wwww
project_dir = %(base_dir)s/myproject
对于上面这个实例,以上3个类对于project_dir值中的base_dir变量的查找过程如下:
类名 | 格式字符串查找过程 | project_dir的值
- | - | -
RawConfigParser | 不进行格式字符串的查找 | %(base_dir)s/myproject
ConfigParser | 尝试分别从 当前section -> [DEFAULT] 查找base_dir的值 | /data/www/myproject
SafeConfigParser | 尝试分别从 当前section -> [DEFAULT] -> 其他section 查找base_dir的值 | /data/www/myproject
各个类的构造方法:
class ConfigParser.RawConfigParser([defaults[, dict_type[, allow_no_value]]])
class ConfigParser.ConfigParser([defaults[, dict_type[, allow_no_value]]])
class ConfigParser.SafeConfigParser([defaults[, dict_type[, allow_no_value]]])
可见,这几个类的构造方法中的参数都是可选参数:
- defaults: 如果该参数被提供,它将被初始化为一个默认值的字典。
- dict_type: 如果该参数被提供,她将被用于为section列表、一个section中的options以及默认选项创建一个该类型的字典对象。该参数于 Python 2.6被添加,Python 2.7时其默认值改为collections.OrderedDict。
- allow_no_value: 表示是否允许option没有值的情况发生(此时获取该选项的值为None),默认值为False,表示不允许。该参数于Python 2.7被添加。
ConfigParser.RawConfigParser类
与 section 相关的方法:
# 添加一个section。
# 如果该section名称已经存在,将会引发DuplicateSectionError;
# 如果name参数的值是`DEFAULT`或任何它的大小写不敏感的变体(如:default、Default),将会引发ValueError
add_section(section)
# 删除指定的section,如果该section存在则返回True, 否则返回False
remove_section(section)
# 返回一个所有可用section的列表,但是不包括`DEFAULT`
sections()
# 判断指定的section是否已经存在,返回True或False
has_section(section)
与 option 相关的方法:
# 添加或修改某个已存在的section下option的值,如果section不存在将会引发NoSectionError。
set(section, option, value)
# 获取某个section下指定option的值, 返回值为str,如果需要其他数据类型需要自己进行转换
get(section, option)
# 对get()方法的字符串结果强制转换为整数并返回
getint(section, option)
# 对get()方法的字符串结果强制转换为浮点数并返回
getfloat(section, option)
# 对get()方法的字符串结果转换为布尔值并返回,但是这里并不是简单的数据类型的转换:
# "1", "yes", "true", "on" 将会返回True
# “0”, “no”, "false", "off" 将会返回False
getboolen(section, option)
# 删除指定section下的某option
# 如果section不存在将会引发NoSectionError;如果存在将被删除的option则返回Ture,否则返回False
remove_option(section, option)
# 返回一个包含默认值的字典--即`[DEFAULT]`下所有option
defaults()
# 返回一个指定section下所有可用options的key的列表
options(section)
# 返回一个由指定section中包含的每个option的(key, value)对组成的列表
items(section)
# 判断某个指定的section下是否包含某个option
# 如果指定的section存在,并且包含这个option,则返回True,否则返回False
has_option(section, option)
# 将指定的option名字转换为内部使用的格式,默认实现是转换为小写。可以通过子类和设置实例属性这两种方法来改变其默认行为,如`cfgparser.optionxform = str`则保持原样。
optionxform(option)
配置文件读写相关方法:
# 读取并解析文件对象中的配置数据到当前实例中,如果filename被忽略且fp有一个name属性,则filename将会取这个属性值
readfp(fp[, filename])
# 将当前实例中的配置数据写入指定的文件对象中
write(fileobject)
# 尝试读取并解析一个文件列表,然后返回一个被成功解析的文件列表。filenames可以是一个字符串,也可以是一个文件名列表:
# 如果filenames是一个字符串或Unicode字符串,它将会被当做一个单数的文件;
# 如果filenames列表中的某个文件不能被打开,该文件将会被忽略;
# 该方法的设计目的在于让用户可以指定一个可能的配置文件位置列表,所有存在的配置文件都会被读取,如果任何一个配置文件都不存在,则ConfigParser实例将会包含一个空的数据集。
# 官方文档给出的建议是:如果一个应用需要从一个配置文件加载初始参数值,应该线使用readp()方法加载必要文件中的数据,然后再调用read()方法加载可选配置文件中的数据。
read(filenames)
总结: readp()用于读取必要配置文件,read()用于读取可选配置文件。
ConfigParser.ConfigParser类
首先,ConfigParser类是RawConfigParser的子类,所以它继承了RawConfigParser的以上方法;然后,ConfigParser类相对于RawConfigParser类的增强功能在于,它支持option值的格式化替换。为了向后兼容,允许用户关闭对option值的格式化替换功能,它重写了以下两个方法:
# 获取指定section下某个otpion的值
get(section, option[, raw[, vars]])
# 返回一个由指定section下的每个option的(key, value)对组成的列表
items(section[, raw[, vars]])
可以看出,这两个方法的参数列表与RawConfigParser类相相应方法相比多了两个参数:
raw: 这是一个布尔值,主要是为了向后兼容。该参数默认值为False,所有的option值中包含的'%'格式字符串都会被替换为相应的值;如果该参数值为True,则不对这些格式字符串做处理,直接返回。
vars: 这是一个字典,可以用来临时定义某个被格式字符串引用的option的值,此时被格式字符串应用的option的查找过程是: vars(如果被提供) -> 当前section -> DEFAULT
ConfigParser.SafeConfigParser类
SafeConfigParser类只是在ConfigParser类的基础上对set()方法做了一些限制:
添加或修改某个已存在的section下option的值,如果section不存在将会引发NoSectionError。
set(section, option, value)
但是它要求option的value必须是一个字符串(str或unicode),否则将会引发TypeError。
实例
实例1:创建一个配置文件
import ConfigParser as CP
# 这里用RawConfigParser、ConfigParser和SafeConfigParser都是一样的效果
config = CP.RawConfigParser({'BAZ': 'hard', 'Bar': 'Life'})
config.add_section('Section1')
config.set('Section1', 'an_int', '15')
config.set('Section1', 'a_float', '3.1415')
config.set('Section1', 'a_bool', 'true')
config.add_section('Section2')
config.set('Section2', 'baz', 'fun')
config.set('Section2', 'bar', 'Python')
config.set('Section2', 'foo', '%(bar)s is %(baz)s!')
with open('example.cfg', 'wb') as configfile:
config.write(configfile)
生成一个名为 example.cfg的文件,内容如下:
[DEFAULT]
bar = Life
baz = hard
[Section1]
an_int = 15
a_float = 3.1415
a_bool = true
[Section2]
baz = fun
bar = Python
foo = %(bar)s is %(baz)s!
说明:
- option的key被写入文件时默认会被转换成小写形式。
- [DEFAULT]这个section是不能、也不需要通过
config.add_section('DEFAULT')的方式添加的,默认就存在。
实例2:读取一个已存在的配置文件
>>> config = CP.RawConfigParser()
>>> config.read('example.cfg')
['example.cfg']
>>>
>>> config.sections() # 结果是不包含'DEFAULT'的
['Section1', 'Section2']
>>>
>>> config.has_section('Section1')
True
>>> config.has_section('Section11')
False
>>> config.has_section('DEFAULT') # 注意这里
False
>>> config.has_section('Default')
False
>>>
>>> config.defaults()
OrderedDict([('bar', 'Life'), ('baz', 'hard')])
>>>
>>> config.options('Section1') # 包括[DEFAULT]下的option
['an_int', 'a_float', 'a_bool', 'bar', 'baz']
>>>
>>> config.items('Section1')
[('bar', 'Life'), ('baz', 'hard'), ('an_int', '15'), ('a_float', '3.1415'), ('a_bool', 'true')]
>>>
>>> config.has_option('Section1', 'an_int')
True
>>>
>>> config.has_option('Section1', 'two_int')
False
>>>
>>> config.get('Section1', 'an_int')
'15'
>>> config.getint('Section1', 'an_int')
15
>>> config.getfloat('Section1', 'a_float')
3.1415
>>>
>>> config.get('Section1', 'a_bool')
'true'
>>>
>>> config.getboolean('Section1', 'a_bool')
True
>>>
>>> config.get('Section2', 'Foo') # 重点在这里
'%(bar)s is %(baz)s!'
要想支持格式化字符串替换,就只能使用ConfigParser或SafeConfigParser类:
>>> import ConfigParser as CP
>>>
>>> config = CP.ConfigParser()
>>> config.read('example.cfg')
['example.cfg']
>>>
>>> config.get('Section2', 'foo') # %(bar)s和%(baz)s取[Section2]所包含的option的值
'Python is fun!'
>>>
>>> config.get('Section2', 'foo', raw=True) # 不进行格式字符串替换
'%(bar)s is %(baz)s!'
>>>
>>> config.get('Section2', 'foo', vars={'baz': 'busy', 'bar': 'Job'}) # %(bar)s和%(baz)s取vars参数所包含的option的值
'Job is busy!'
>>>
>>> config.remove_option('Section2', 'baz')
True
>>> config.remove_option('Section2', 'bar')
True
>>> config.get('Section2', 'foo') # %(bar)s和%(baz)s取[DEFAULT]所包含的option的值
'Life is hard!'
如果已存在的配置数据中包含没有值的option,需要在创建解析器实例时指定allow_no_value=True :
>>> import ConfigParser as CP
>>> import io
>>>
>>> sample_config = """
... [mysqld]
... user = mysql
... pid-file = /var/run/mysqld/mysqld.pid
... skip-external-locking
... old_passwords = 1
... skip-bdb
... skip-innodb
... """
>>> config = CP.RawConfigParser(allow_no_value=True)
>>> config.readfp(io.BytesIO(sample_config))
>>> config.get('mysqld', 'user')
'mysql'
>>>
>>> config.get('mysqld', 'skip-bdb') # 返回None
>>>
>>> config.get('mysqld', 'does-not-exist') # 获取不存在的option会报错
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "C:\Python27\lib\ConfigParser.py", line 340, in get
raise NoOptionError(option, section)
ConfigParser.NoOptionError: No option 'does-not-exist' in section: 'mysqld'
>>>
实例3:修改配置文件
貌似大神们没有提供相应的方法来实现将一个section下的option移动到另外一个section下的功能,那么我们自己来实现它。
思路很简单: 取出原section下要移动的option的值 --> 在目标section(如果不存在则添加该section)下添加该option --> 从原section中删除移动的option
def move_option(config, section_from, section_to, option):
try:
config.set(section_to, option, config.get(section_from, option))
except ConfigParser.NoSectionError:
config.add_section(section_to)
move_option(config, section_from, section_to, option)
else:
config.remove_option(section_from, option)
有人会问,如果原section不存在,或者要移动的option不存在怎么办?个人觉得这些判断在调用这个函数之前进行处理会更好,这个函数只处理移动操作:
>>> import ConfigParser
>>>
>>> config = ConfigParser.ConfigParser()
>>> config.read('example.cfg')
['example.cfg']
# 查看当前已存在的section以及各section下所包含的option
>>> config.sections()
['Section1', 'Section2']
>>> config.items('Section1')
[('bar', 'Life'), ('baz', 'hard'), ('an_int', '15'), ('a_float', '3.1415'), ('a_bool', 'true')]
>>> config.items('Section2')
[('bar', 'Python'), ('baz', 'fun'), ('foo', 'Python is fun!')]
# 将Section1下的an_int移动到已经存在的Section2下
>>> move_option(config, 'Section1', 'Section2', 'an_int')
# 将Section1下的a_float移动到不存在的Section3下
>>> move_option(config, 'Section1', 'Section3', 'a_float')
# 查看当前已存在的section以及各section下所包含的option
>>> config.sections()
['Section1', 'Section2', 'Section3']
>>> config.items('Section1')
[('bar', 'Life'), ('baz', 'hard'), ('a_bool', 'true')]
>>> config.items('Section2')
[('bar', 'Python'), ('baz', 'fun'), ('foo', 'Python is fun!'), ('an_int', '15')]
>>> config.items('Section3')
[('bar', 'Life'), ('baz', 'hard'), ('a_float', '3.1415')]
# 移除Section1
>>> config.remove_section('Section1')
True
# 将当前配置数据写回配置文件
with open('example.cfg', 'wb') as configfile:
config.write(configfile)
此时,配置文件的内容已被修改为:
[DEFAULT]
bar = Life
baz = hard
[Section2]
baz = fun
bar = Python
foo = %(bar)s is %(baz)s!
an_int = 15
[Section3]
a_float = 3.1415
4. Python 3中的configparser模块
Python 3中不仅仅是将ConfigParser改名为configparse,还对该模块做了一些改进:
改进1:允许我们以类似字典的方式来操作配置数据
生成一个配置文件:
import configparser
config = configparser.ConfigParser()
config['DEFAULT'] = {'BAR': 'Life',
'BAZ': 'hard'}
config['Section1'] = {}
config['Section1']['an_int'] = '15'
config['Section1']['a_float'] = '3.1415'
config['Section1']['a_bool'] = 'true'
config['Section2'] = {}
config['Section2']['baz'] = 'fun'
config['Section2']['bar'] = 'Python'
config['Section2']['fun'] = '%(bar)s is %(baz)s!'
with open('example.ini', 'w') as configfile:
config.write(configfile)
读取一个已存在的配置文件:
>>> import configparser
>>>
>>> config = configparser.ConfigParser()
>>> config.read('example.ini')
['example.ini']
>>>
>>> config['Section1']['an_int']
'15'
>>> config['Section2']['fun']
'Python is fun!'
改进2:所有的get*()方法都增加了一个fallback参数
Python 2的ConfigParser模块中定义的解析器所提供的get*()方法在获取一个不存在的option的值时会抛出ConfigParser.NoOptionError错误:
>>> import ConfigParser
>>> config = ConfigParser.ConfigParser()
>>> config.read('example.ini')
['example.ini']
>>>
>>> config.options('Section1')
['an_int', 'a_float', 'a_bool', 'bar', 'baz']
>>> config.get('Section1', 'not_exist_option')
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "C:\Python27\lib\ConfigParser.py", line 618, in get
raise NoOptionError(option, section)
ConfigParser.NoOptionError: No option 'not_exist_option' in section: 'Section1'
>>>
因此,我们需要在获取某个Section下的option时需要先判断该option是否存在,或者需要处理相应的异常信息。而Python 3中的configparser模块提供的所有的get*()方法都增加了一个fallback参数,这个fallback参数可以用于指定获取一个不存在的option的时的默认值,这其实也是类似字典的操作。
需要注意的是: 这个fallback参数必须以关键词参数的形式提供,如果不提供该参数还是会抛出异常(KeyError)。
>>> config = configparser.ConfigParser()
>>> config.read('example.ini')
['example.ini']
>>>
>>> config.options('Section1')
['an_int', 'a_float', 'a_bool', 'bar', 'baz']
>>> config.get('Section1', 'an_int')
'15'
>>> config.get('Section1', 'not_exist_option', fallback='None')
'None'
>>>
改进3:读取配置信息的read*()方法
read()方法新加了一个encoding参数
之前读取配置文件时,都使用open()函数的default encoding,Python 3.2新加了encoding参数允开发者修改打开文件的要使用的字符编码:
read(filenames, encoding=None)
以read_file()方法替代readfp()方法
从Python 3.2开始以read_file()方法替代readp()方法
read_file(f, source=None)
新加了read_string()和read_dict()方法
Python 2中可以使用read()和readfp()方法很方便的从文件中读取配置信息,如果要从一个字符串中读取配置信息,需要这样做:config.readfp(io.BytesIO(str_config_data)) ,上面有例子。且Python 2中没有提供从一个Python字典读取配置数据的方法。
Python 3中专门提供了read_string()和read_dict()方法来分别从字符串和Python字典中读取配置数据:
read_string(string, source='<string>')
read_dict(dictionary, source='<dict>')
改进4:write()方法新加了一个space_around_delimiter参数
Python 3中的write()方法新加了一个space_around_delimiter参数,用于写入文件的配置数据的option的key和option之间的分隔符前后是否保留空白字符。该参数默认值为True,则文件格式是这样的:
[DEFAULT]
bar = Life
baz = hard
...
如果该参数值为False,则文件格式是这样的:
[DEFAULT]
bar=Life
baz=hard
...
改进5:解析器类的构造函数增加了很多灵活的参数
class configparser.ConfigParser(defaults=None, dict_type=collections.OrderedDict,
allow_no_value=False, delimiters=('=', ':'),
comment_prefixes=('#', ';'), inline_comment_prefixes=None,
strict=True, empty_lines_in_values=True,
default_section=configparser.DEFAULTSECT,
interpolation=BasicInterpolation(), converters={})
class configparser.RawConfigParser(defaults=None, dict_type=collections.OrderedDict,
allow_no_value=False, *, delimiters=('=', ':'),
comment_prefixs=('#', ';'), inline_comment_prefixes=None,
strict=True, empty_lines_in_values=True,
default_section=configparser.DEFAULTSECT[, interpolation])
四、总结
本文对Python中的XML数据和应用配置文件的处理模块进行了尽可能详细的介绍并附带了一些示例代码。本文主要是对之前那篇《Python之数据序列化》的一个补充,但是在实际开发工作中也经常会用到这些内容,希望对大家有所帮助。
问题交流群:666948590

 浙公网安备 33010602011771号
浙公网安备 33010602011771号