

flume介绍与原理(一)
转自:http://www.cnblogs.com/gongxijun/p/5656778.html
1 .背景
flume是由cloudera软件公司产出的可分布式日志收集系统,后与2009年被捐赠了apache软件基金会,为hadoop相关组件之一。尤其近几年随着flume的不断被完善以及升级版本的逐一推出,特别是flume-ng;同时flume内部的各种组件不断丰富,用户在开发的过程中使用的便利性得到很大的改善,现已成为apache top项目之一.
2 .概述
1. 什么是flume?
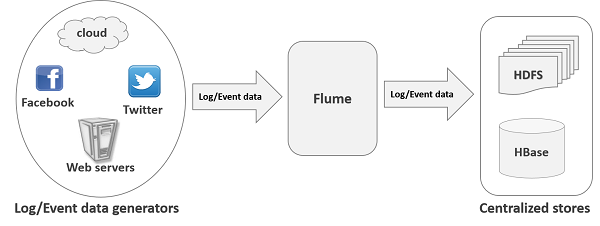
apache Flume 是一个从可以收集例如日志,事件等数据资源,并将这些数量庞大的数据从各项数据资源中集中起来存储的工具/服务,或者数集中机制。flume具有高可用,分布式,配置工具,其设计的原理也是基于将数据流,如日志数据从各种网站服务器上汇集起来存储到HDFS,HBase等集中存储器中。其结构如下图所示:
2.应用场景
比如我们在做一个电子商务网站,然后我们想从消费用户中访问点特定的节点区域来分析消费者的行为或者购买意图. 这样我们就可以更加快速的将他想要的推送到界面上,实现这一点,我们需要将获取到的她访问的页面以及点击的产品数据等日志数据信息收集并移交给Hadoop平台上去分析.而Flume正是帮我们做到这一点。现在流行的内容推送,比如广告定点投放以及新闻私人定制也是基于次,不过不一定是使用FLume,毕竟优秀的产品很多,比如facebook的Scribe,还有Apache新出的另一个明星项目chukwa,还有淘宝Time Tunnel。
3.Flume的优势
1. Flume可以将应用产生的数据存储到任何集中存储器中,比如HDFS,HBase
2. 当收集数据的速度超过将写入数据的时候,也就是当收集信息遇到峰值时,这时候收集的信息非常大,甚至超过了系统的写入数据能力,这时候,Flume会在数据生产者和数据收容器间做出调整,保证其能够在两者之间提供一共平稳的数据.
3. 提供上下文路由特征
4. Flume的管道是基于事务,保证了数据在传送和接收时的一致性.
5. Flume是可靠的,容错性高的,可升级的,易管理的,并且可定制的。
4. Flume具有的特征:
1. Flume可以高效率的将多个网站服务器中收集的日志信息存入HDFS/HBase中
2. 使用Flume,我们可以将从多个服务器中获取的数据迅速的移交给Hadoop中
3. 除了日志信息,Flume同时也可以用来接入收集规模宏大的社交网络节点事件数据,比如facebook,twitter,电商网站如亚马逊,flipkart等
4. 支持各种接入资源数据的类型以及接出数据类型
5. 支持多路径流量,多管道接入流量,多管道接出流量,上下文路由等
6. 可以被水平扩展
3. Flume的结构
1. flume的外部结构:
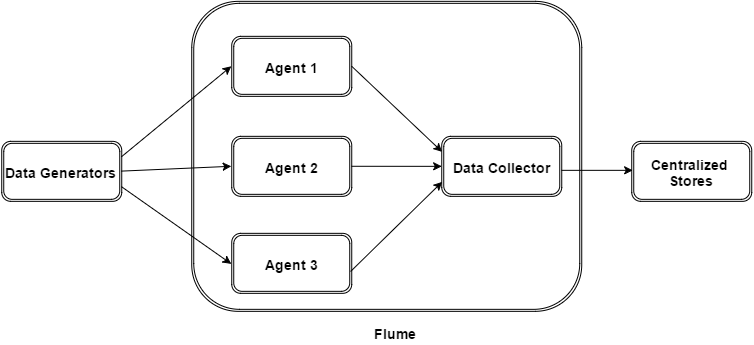
如上图所示,数据发生器(如:facebook,twitter)产生的数据被被单个的运行在数据发生器所在服务器上的agent所收集,之后数据收容器从各个agent上汇集数据并将采集到的数据存入到HDFS或者HBase中
2. Flume 事件
事件作为Flume内部数据传输的最基本单元.它是由一个转载数据的字节数组(该数据组是从数据源接入点传入,并传输给传输器,也就是HDFS/HBase)和一个可选头部构成.
典型的Flume 事件如下面结构所示:

我们在将event在私人定制插件时比如:flume-hbase-sink插件是,获取的就是event然后对其解析,并依据情况做过滤等,然后在传输给HBase或者HDFS.
3.Flume Agent
我们在了解了Flume的外部结构之后,知道了Flume内部有一个或者多个Agent,然而对于每一个Agent来说,它就是一共独立的守护进程(JVM),它从客户端哪儿接收收集,或者从其他的 Agent哪儿接收,然后迅速的将获取的数据传给下一个目的节点sink,或者agent. 如下图所示flume的基本模型
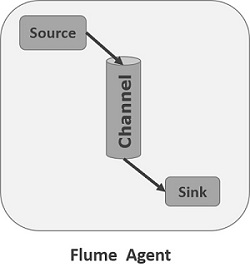
Agent主要由:source,channel,sink三个组件组成.
Source:
从数据发生器接收数据,并将接收的数据以Flume的event格式传递给一个或者多个通道channal,Flume提供多种数据接收的方式,比如Avro,Thrift,twitter1%等
Channel:
channal是一种短暂的存储容器,它将从source处接收到的event格式的数据缓存起来,直到它们被sinks消费掉,它在source和sink间起着一共桥梁的作用,channal是一个完整的事务,这一点保证了数据在收发的时候的一致性. 并且它可以和任意数量的source和sink链接. 支持的类型有: JDBC channel , File System channel , Memort channel等.
sink:
sink将数据存储到集中存储器比如Hbase和HDFS,它从channals消费数据(events)并将其传递给目标地. 目标地可能是另一个sink,也可能HDFS,HBase.
它的组合形式举例:
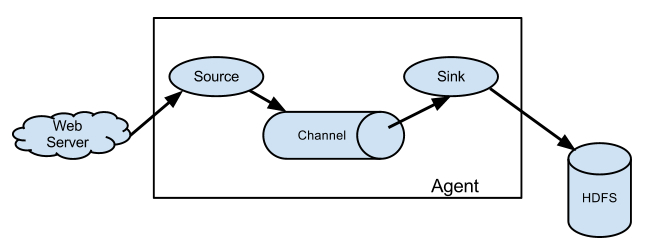
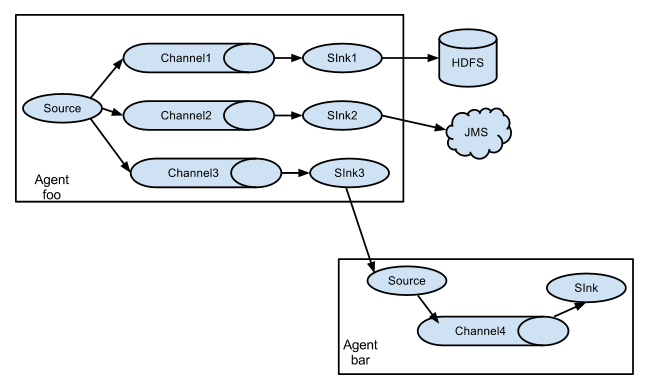
以上介绍的flume的主要组件,下面介绍一下Flume插件:
1. Interceptors拦截器
用于source和channel之间,用来更改或者检查Flume的events数据
2. 管道选择器 channels Selectors
在多管道是被用来选择使用那一条管道来传递数据(events). 管道选择器又分为如下两种:
默认管道选择器: 每一个管道传递的都是相同的events
多路复用通道选择器: 依据每一个event的头部header的地址选择管道.
3.sink线程
----------------------------------------------------<完>-------------------------------------------------------

 浙公网安备 33010602011771号
浙公网安备 33010602011771号