
Kafka:ZK+Kafka+Spark Streaming集群环境搭建(十四)定义一个avro schema使用comsumer发送avro字符流,producer接受avro字符流并解析
参考《在Kafka中使用Avro编码消息:Consumer篇》、《在Kafka中使用Avro编码消息:Producter篇》
在了解如何avro发送到kafka,再从kafka解析avro数据之前,我们可以先看下如何使用操作字符串:
producer:


package com.spark; import org.apache.kafka.clients.producer.Producer; import org.apache.kafka.clients.producer.ProducerRecord; import java.util.Properties; /** * Created by Administrator on 2017/8/29. */ public class KafkaProducer { public static void main(String[] args) throws InterruptedException { Properties props = new Properties(); props.put("bootstrap.servers", "localhost:9092"); props.put("acks", "all"); props.put("retries", 0); props.put("batch.size", 16384); props.put("linger.ms", 1); props.put("buffer.memory", 33554432); props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer"); props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer"); Producer<String, String> producer = new org.apache.kafka.clients.producer.KafkaProducer(props); int i=0; while (true) { producer.send(new ProducerRecord<String, String>("my-topic", Integer.toString(i), Integer.toString(i))); System.out.println(i++); Thread.sleep(1000); } // producer.close(); } }
consumer:
package com.spark; import org.apache.kafka.clients.consumer.ConsumerRecord; import org.apache.kafka.clients.consumer.ConsumerRecords; import org.apache.kafka.clients.consumer.KafkaConsumer; import java.util.Arrays; import java.util.Properties; /** * Created by Administrator on 2017/8/29. */ public class MyKafkaConsumer { public static void main(String[] args) { Properties props = new Properties(); props.put("bootstrap.servers", "localhost:9092"); props.put("group.id", "test"); props.put("enable.auto.commit", "true"); props.put("auto.commit.interval.ms", "1000"); props.put("session.timeout.ms", "30000"); props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer"); props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer"); KafkaConsumer<String, String> consumer = new KafkaConsumer<String, String>(props); consumer.subscribe(Arrays.asList("my-topic")); while (true) { ConsumerRecords<String, String> records = consumer.poll(100); for (ConsumerRecord<String, String> record : records){ System.out.printf("offset = %d, key = %s, value = %s \n", record.offset(), record.key(), record.value()); } } } }
Avro操作工程pom.xml:
<dependency> <groupId>org.apache.kafka</groupId> <artifactId>kafka-clients</artifactId> <version>0.10.0.1</version> </dependency> <dependency> <groupId>org.slf4j</groupId> <artifactId>slf4j-simple</artifactId> <version>1.7.21</version> </dependency> <dependency> <groupId>org.apache.avro</groupId> <artifactId>avro</artifactId> <version>1.8.0</version> </dependency> <dependency> <groupId>com.twitter</groupId> <artifactId>bijection-avro_2.10</artifactId> <version>0.9.2</version> </dependency> <dependency> <groupId>org.apache.avro</groupId> <artifactId>avro</artifactId> <version>1.7.4</version> </dependency>
需要依赖于avro的包,同时这里是需要使用kafka api。
在使用 Avro 之前,我们需要先定义模式(schemas)。模式通常使用 JSON 来编写,我们不需要再定义相关的类,这篇文章中,我们将使用如下的模式:
{ "fields": [ { "name": "str1", "type": "string" }, { "name": "str2", "type": "string" }, { "name": "int1", "type": "int" } ], "name": "Iteblog", "type": "record" }
上面的模式中,我们定义了一种 record 类型的对象,名字为 Iteblog,这个对象包含了两个字符串和一个 int 类型的fields。定义好模式之后,我们可以使用 avro 提供的相应方法来解析这个模式:
Schema.Parser parser = new Schema.Parser(); Schema schema = parser.parse(USER_SCHEMA);
这里的 USER_SCHEMA 变量存储的就是上面定义好的模式。
解析好模式定义的对象之后,我们需要将这个对象序列化成字节数组,或者将字节数组转换成对象。Avro 提供的 API 不太易于使用,所以本文使用 twitter 开源的 Bijection 库来方便地实现这些操作。我们先创建 Injection 对象来讲对象转换成字节数组:
Injection<GenericRecord, byte[]> recordInjection = GenericAvroCodecs.toBinary(schema);
现在我们可以根据之前定义好的模式来创建相关的 Record,并使用 recordInjection 来序列化这个 Record :
GenericData.Record record = new GenericData.Record(schema); avroRecord.put("str1", "My first string"); avroRecord.put("str2", "My second string"); avroRecord.put("int1", 42); byte[] bytes = recordInjection.apply(record);
Producter实现
有了上面的介绍之后,我们现在就可以在 Kafka 中使用 Avro 来序列化我们需要发送的消息了:
package example.avro; import java.util.Properties; import org.apache.avro.Schema; import org.apache.avro.generic.GenericData; import org.apache.avro.generic.GenericRecord; import org.apache.kafka.clients.producer.KafkaProducer; import org.apache.kafka.clients.producer.ProducerRecord; import com.twitter.bijection.Injection; import com.twitter.bijection.avro.GenericAvroCodecs; public class AvroKafkaProducter { public static final String USER_SCHEMA = "{" + "\"type\":\"record\"," + "\"name\":\"Iteblog\"," + "\"fields\":[" + " { \"name\":\"str1\", \"type\":\"string\" }," + " { \"name\":\"str2\", \"type\":\"string\" }," + " { \"name\":\"int1\", \"type\":\"int\" }" + "]}"; public static final String TOPIC = "t-testavro"; public static void main(String[] args) throws InterruptedException { Properties props = new Properties(); props.put("bootstrap.servers", "192.168.0.121:9092,192.168.0.122:9092"); props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer"); props.put("value.serializer", "org.apache.kafka.common.serialization.ByteArraySerializer"); Schema.Parser parser = new Schema.Parser(); Schema schema = parser.parse(USER_SCHEMA); Injection<GenericRecord, byte[]> recordInjection = GenericAvroCodecs.toBinary(schema); KafkaProducer<String, byte[]> producer = new KafkaProducer<String, byte[]>(props); for (int i = 0; i < 1000; i++) { GenericData.Record avroRecord = new GenericData.Record(schema); avroRecord.put("str1", "Str 1-" + i); avroRecord.put("str2", "Str 2-" + i); avroRecord.put("int1", i); byte[] bytes = recordInjection.apply(avroRecord); ProducerRecord<String, byte[]> record = new ProducerRecord<String, byte[]>(TOPIC, "" + i, bytes); producer.send(record); System.out.println(">>>>>>>>>>>>>>>>>>" + i); } producer.close(); System.out.println("complete..."); } }
因为我们使用到 Avro 和 Bijection 类库,所有我们需要在 pom.xml 文件里面引入以下依赖:
<dependency> <groupId>org.apache.avro</groupId> <artifactId>avro</artifactId> <version>1.8.0</version> </dependency> <dependency> <groupId>com.twitter</groupId> <artifactId>bijection-avro_2.10</artifactId> <version>0.9.2</version> </dependency>
从 Kafka 中读取 Avro 格式的消息
从 Kafka 中读取 Avro 格式的消息和读取其他类型的类型一样,都是创建相关的流,然后迭代:
ConsumerConnector consumer = ...; Map<String, List<KafkaStream<byte[], byte[]>>> consumerStreams = consumer.createMessageStreams(topicCount); List<KafkaStream<byte[], byte[]>> streams = consumerStreams.get(topic); for (final KafkaStream stream : streams) { .... }
关键在于如何将读出来的 Avro 类型字节数组转换成我们要的数据。这里还是使用到我们之前介绍的模式解释器:
Schema.Parser parser = new Schema.Parser(); Schema schema = parser.parse(USER_SCHEMA); Injection<GenericRecord, byte[]> recordInjection = GenericAvroCodecs.toBinary(schema);
上面的 USER_SCHEMA 就是上边介绍的消息模式,我们创建了一个 recordInjection 对象,这个对象就可以利用刚刚解析好的模式将读出来的字节数组反序列化成我们写入的数据:
GenericRecord record = recordInjection.invert(message).get();
然后我们就可以通过下面方法获取写入的数据:
record.get("str1")
record.get("str2")
record.get("int1")
Kafka 0.9.x 版本Consumer实现
package example.avro; import java.util.Collections; import java.util.Properties; import org.apache.avro.Schema; import org.apache.avro.generic.GenericRecord; import org.apache.kafka.clients.consumer.ConsumerRecord; import org.apache.kafka.clients.consumer.ConsumerRecords; import org.apache.kafka.clients.consumer.KafkaConsumer; import org.apache.kafka.common.serialization.ByteArrayDeserializer; import org.apache.kafka.common.serialization.StringDeserializer; import org.slf4j.Logger; import org.slf4j.LoggerFactory; import com.twitter.bijection.Injection; import com.twitter.bijection.avro.GenericAvroCodecs; public class AvroKafkaConsumer { public static void main(String[] args) { Logger logger = LoggerFactory.getLogger("AvroKafkaConsumer"); Properties props = new Properties(); props.put("bootstrap.servers", "192.168.0.121:9092,192.168.0.122:9092"); props.put("group.id", "testgroup"); props.put("key.deserializer", StringDeserializer.class.getName()); props.put("value.deserializer", ByteArrayDeserializer.class.getName()); KafkaConsumer<String, byte[]> consumer = new KafkaConsumer<String, byte[]>(props); consumer.subscribe(Collections.singletonList(AvroKafkaProducter.TOPIC)); Schema.Parser parser = new Schema.Parser(); Schema schema = parser.parse(AvroKafkaProducter.USER_SCHEMA); Injection<GenericRecord, byte[]> recordInjection = GenericAvroCodecs.toBinary(schema); try { while (true) { ConsumerRecords<String, byte[]> records = consumer.poll(1000); for (ConsumerRecord<String, byte[]> record : records) { GenericRecord genericRecord = recordInjection.invert(record.value()).get(); String info = String.format(String.format("topic = %s, partition = %s, offset = %d, customer = %s,country = %s\n", record.topic(), record.partition(), record.offset(), record.key(), genericRecord.get("str1"))); logger.info(info); } } } finally { consumer.close(); } } }
测试:
producer:
[main] INFO org.apache.kafka.common.utils.AppInfoParser - Kafka version : 0.10.0.1
[main] INFO org.apache.kafka.common.utils.AppInfoParser - Kafka commitId : a7a17cdec9eaa6c5
>>>>>>>>>>>>>>>>>>0
>>>>>>>>>>>>>>>>>>1
>>>>>>>>>>>>>>>>>>2
>>>>>>>>>>>>>>>>>>3
>>>>>>>>>>>>>>>>>>4
>>>>>>>>>>>>>>>>>>5
>>>>>>>>>>>>>>>>>>6
>>>>>>>>>>>>>>>>>>7
>>>>>>>>>>>>>>>>>>8
>>>>>>>>>>>>>>>>>>9
>>>>>>>>>>>>>>>>>>10
...
>>>>>>>>>>>>>>>>>>997
>>>>>>>>>>>>>>>>>>998
>>>>>>>>>>>>>>>>>>999
[main] INFO org.apache.kafka.clients.producer.KafkaProducer - Closing the Kafka producer with timeoutMillis = 9223372036854775807 ms.
complete...
consumer:
[main] INFO AvroKafkaConsumer - topic = t-testavro, partition = 0, offset = 4321, customer = 165,country = Str 1-165
[main] INFO AvroKafkaConsumer - topic = t-testavro, partition = 0, offset = 4322, customer = 166,country = Str 1-166
[main] INFO AvroKafkaConsumer - topic = t-testavro, partition = 0, offset = 4323, customer = 167,country = Str 1-167
[main] INFO AvroKafkaConsumer - topic = t-testavro, partition = 0, offset = 4324, customer = 168,country = Str 1-168
[main] INFO AvroKafkaConsumer - topic = t-testavro, partition = 0, offset = 4325, customer = 169,country = Str 1-169
[main] INFO AvroKafkaConsumer - topic = t-testavro, partition = 0, offset = 4326, customer = 170,country = Str 1-170
[main] INFO AvroKafkaConsumer - topic = t-testavro, partition = 0, offset = 4327, customer = 171,country = Str 1-171
GenericRecord打印:
import org.apache.avro.Schema; import org.apache.avro.generic.GenericData; import org.apache.avro.generic.GenericRecord; public class AvroToJson { public static void main(String[] args) { String avroSchema = "{" + "\"type\": \"record\", " + "\"name\": \"LongList\"," + "\"aliases\": [\"LinkedLongs\"]," + "\"fields\" : [" + " {\"name\": \"name\", \"type\": \"string\"}," + " {\"name\": \"favorite_number\", \"type\": [\"null\", \"long\"]}," + " {\"name\": \"favorite_color\", \"type\": [\"null\", \"string\"]}" + " ]" + "}"; Schema schema = new Schema.Parser().parse(avroSchema); GenericRecord user1 = new GenericData.Record(schema); user1.put("name", "Format"); user1.put("favorite_number", 666); user1.put("favorite_color", "red"); GenericData genericData = new GenericData(); String result = genericData.toString(user1); System.out.println(result); } }
打印结果:
{"name": "Format", "favorite_number": 666, "favorite_color": "red"}
该信息在调试,想查看avro对象内容时,十分实用。
一次有趣的测试:
avro schema:
{ "type":"record", "name":"My", "fields":[ {"name":"id","type":["null", "string"]}, {"name":"start_time","type":["null", "string"]}, {"name":"stop_time","type":["null", "string"]}, {"name":"insert_time","type":["null", "string"]}, {"name":"eid","type":["null", "string"]}, {"name":"V_00","type":["null", "string"]}, {"name":"V_01","type":["null", "string"]}, {"name":"V_02","type":["null", "string"]}, {"name":"V_03","type":["null", "string"]}, {"name":"V_04","type":["null", "string"]}, {"name":"V_05","type":["null", "string"]}, {"name":"V_06","type":["null", "string"]}, {"name":"V_07","type":["null", "string"]}, {"name":"V_08","type":["null", "string"]}, {"name":"V_09","type":["null", "string"]} ] }
测试程序:
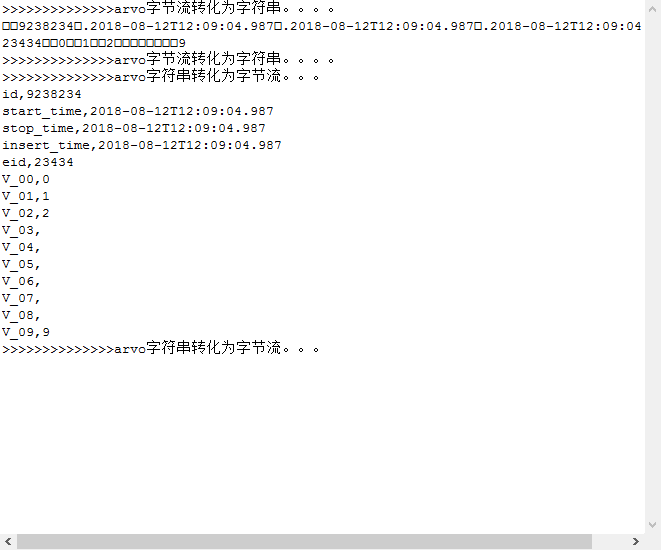
public static void main(String[] args) throws StreamingQueryException, IOException { String filePathString = "E:\\work\\my.avsc"; Schema.Parser parser = new Schema.Parser(); InputStream inputStream = new FileInputStream(filePathString); Schema schema = parser.parse(inputStream); inputStream.close(); Injection<GenericRecord, byte[]> recordInjection = GenericAvroCodecs.toBinary(schema); GenericData.Record avroRecord = new GenericData.Record(schema); avroRecord.put("id", "9238234"); avroRecord.put("start_time", "2018-08-12T12:09:04.987"); avroRecord.put("stop_time", "2018-08-12T12:09:04.987"); avroRecord.put("insert_time", "2018-08-12T12:09:04.987"); avroRecord.put("eid", "23434"); avroRecord.put("V_00", "0"); avroRecord.put("V_01", "1"); avroRecord.put("V_02", "2"); avroRecord.put("V_09", "9"); byte[] bytes = recordInjection.apply(avroRecord); String byteString = byteArrayToStr(bytes); //String byteString= bytes.toString(); System.out.println(">>>>>>>>>>>>>>arvo字节流转化为字符串。。。。"); System.out.println(byteString); System.out.println(">>>>>>>>>>>>>>arvo字节流转化为字符串。。。。"); System.out.println(">>>>>>>>>>>>>>arvo字符串转化为字节流。。。"); byte[] data = strToByteArray(byteString); GenericRecord record = recordInjection.invert(data).get(); for (Schema.Field field : schema.getFields()) { String value = record.get(field.name()) == null ? "" : record.get(field.name()).toString(); System.out.println(field.name() + "," + value); } System.out.println(">>>>>>>>>>>>>>arvo字符串转化为字节流。。。"); } public static String byteArrayToStr(byte[] byteArray) { if (byteArray == null) { return null; } String str = new String(byteArray); return str; } public static byte[] strToByteArray(String str) { if (str == null) { return null; } byte[] byteArray = str.getBytes(); return byteArray; }
经过测试,可以正常运行,输出信息为:
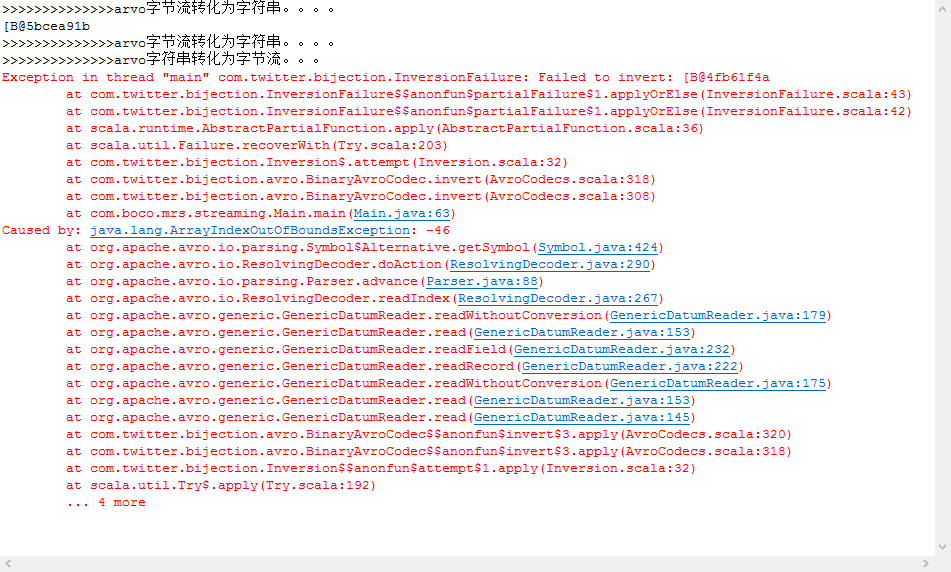
但是如果把代码中的byte转化为字符代码修改为:
//String byteString = byteArrayToStr(bytes); String byteString= bytes.toString();
就抛出错误了:
基础才是编程人员应该深入研究的问题,比如:
1)List/Set/Map内部组成原理|区别
2)mysql索引存储结构&如何调优/b-tree特点、计算复杂度及影响复杂度的因素。。。
3)JVM运行组成与原理及调优
4)Java类加载器运行原理
5)Java中GC过程原理|使用的回收算法原理
6)Redis中hash一致性实现及与hash其他区别
7)Java多线程、线程池开发、管理Lock与Synchroined区别
8)Spring IOC/AOP 原理;加载过程的。。。
【+加关注】。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号