
通过java api统计hive库下的所有表的文件个数、文件大小
更新hadoop fs 命令实现:
[ss@db csv]$ hadoop fs -count /my_rc/my_hive_db/* 18/01/14 15:40:19 INFO hdfs.PeerCache: SocketCache disabled. 3 2 0 /my_rc/my_hive_db/.hive-staging_hive_2017-08-19_16-52-39_153_7217997288202811839-170149 2 0 0 /my_rc/my_hive_db/.hive-staging_hive_2018-01-03_15-23-10_240_5147839610865108930-52517 1 0 0 /my_rc/my_hive_db/BusinessGtUser 4 1 321008 /my_rc/my_hive_db/ZJ2_SenseSta 1 1 143 /my_rc/my_hive_db/anthgain 1 1 27228 /my_rc/my_hive_db/anthgainpoint 1 1 70 /my_rc/my_hive_db/antvgain 1 1 27429 /my_rc/my_hive_db/antvgainpoint
通过hadoop fs -du 或者 hadoop fs -count只能统计指定的某个hdfs路径(hive表目录)的总文件个数及文件的大小,但是通过hadoop命令没有办法实现批量处理hive中多个表一次进行统计,如果一次性统计多个hive表目录的文件个数、文件总大小只能通过java程序使用hadoop api实现。
package com.my.hdfsopt; import java.io.FileNotFoundException; import java.io.IOException; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.FileStatus; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; public class HdfsPathMonitor { // submit shell /* * main类的路径不需要指定,否则会被认为是参数传递进入。 * yarn jar /app/m_user1/service/Hangzhou_HdfsFileMananger.jar /hive_tenant_account/hivedbname/ */ public static void main(String[] args) throws Exception { System.out.println("the args is " + String.join(",", args)); String dirPath = args[0]; Configuration conf = new Configuration(); /* * <property> <name>fs.defaultFS</name> <value>hdfs://mycluster</value> * </property> */ conf.set("fs.defaultFS", "hdfs://mycluster"); FileSystem fileSystem = FileSystem.get(conf); Path path = new Path(dirPath); // 获取文件列表 FileStatus[] files = fileSystem.listStatus(path); if (files == null || files.length == 0) { throw new FileNotFoundException("Cannot access " + dirPath + ": No such file or directory."); } System.out.println("dirpath \t total file size \t total file count"); for (int i = 0; i < files.length; i++) { String pathStr = files[i].getPath().toString(); FileSystem fs = files[i].getPath().getFileSystem(conf); long totalSize = fs.getContentSummary(files[i].getPath()).getLength(); long totalFileCount = listAll(conf, files[i].getPath()); fs.close(); System.out.println(("".equals(pathStr) ? "." : pathStr) + "\t" + totalSize + "\t" + totalFileCount); } } /** * @Title: listAll @Description: 列出目录下所有文件 @return void 返回类型 @throws */ public static Long listAll(Configuration conf, Path path) throws IOException { long totalFileCount = 0; FileSystem fs = FileSystem.get(conf); if (fs.exists(path)) { FileStatus[] stats = fs.listStatus(path); for (int i = 0; i < stats.length; ++i) { if (!stats[i].isDir()) { // regular file // System.out.println(stats[i].getPath().toString()); totalFileCount++; } else { // dir // System.out.println(stats[i].getPath().toString()); totalFileCount += listAll(conf, stats[i].getPath()); } } } fs.close(); return totalFileCount; } }
执行命令:
yarn jar /app/m_user1/tommyduan_service/Hangzhou_HdfsFileMananger.jar /hive_tenant_account/hivedbname/
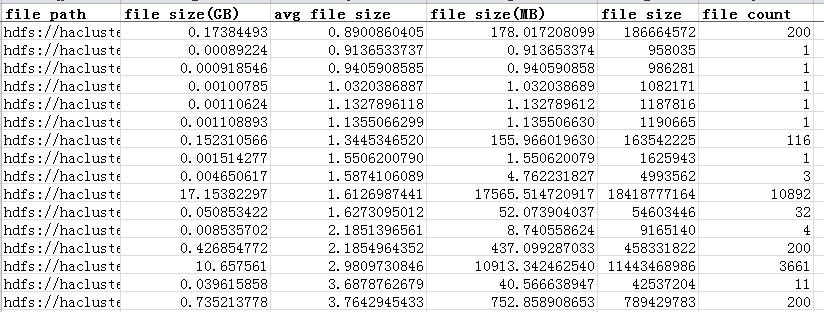
执行结果:
基础才是编程人员应该深入研究的问题,比如:
1)List/Set/Map内部组成原理|区别
2)mysql索引存储结构&如何调优/b-tree特点、计算复杂度及影响复杂度的因素。。。
3)JVM运行组成与原理及调优
4)Java类加载器运行原理
5)Java中GC过程原理|使用的回收算法原理
6)Redis中hash一致性实现及与hash其他区别
7)Java多线程、线程池开发、管理Lock与Synchroined区别
8)Spring IOC/AOP 原理;加载过程的。。。
【+加关注】。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号