
Hadoop:搭建hadoop集群
- 操作系统环境准备:
准备几台服务器(我这里是三台虚拟机):
linux ubuntu 14.04 server x64(下载地址:http://releases.ubuntu.com/14.04.2/ubuntu-14.04.2-server-amd64.iso)
master:192.168.1.200
node1:192.168.1.201
node2:192.168.1.202
备注:我在安装ubuntu虚拟机时,我把账号名和密码都设置为:hadoop,所有虚拟机的账户名密码一致。
- 为每台虚拟机配置ip及连网:
请参考我的文章:Linux:宿主机通过桥接方式连接的VMware内部Linux14.04虚拟机(静态IP)实现上网方案
- 为每台虚拟机安装Java&Scala:
备注:因为我后边要集成spark进来所以也就直接把scala安装了。
安装java8在ubuntu14.04上,具体操作请参考我的文章:Linux:Ubuntu 14.04 Server 离线安装Jjava8(及在线安装)
安装scala在ubuntu14.04上,具体操作请参考我的文章:Linux:Ubuntu14.04离线安装scala(在线安装)
- 为每台虚拟机添加hadoop账户组,并把hadoop账户添加添加到hadoop账户组:
1、怎么添加hadoop用户组,具体操作请参考我的文章:Linux下添加用户及用户组
2、添加完用户组后,修改hadoop用户组权限(赋予hadoop用户组管理员权限):
$ sudo vim /etc/sudoers # 在sudoers文件中修改|添加hadoop用户组拥有管理员权限 # Members of the admin group may gain root privileges %admin ALL=(ALL) ALL hadoop ALL=(ALL) ALL
- 为每台虚拟机安装ssh(openssh-server)服务及为Master虚拟机配置ssh无密码登录:
具体操作请参考我的文章:Linux:实现Hadoop集群Master无密码登录(SSH)各个子节点
- 为Master虚拟机安装Hadoop(我这里需要的是Hadoop+Spark,所以没有配置Maperduce):
1、首先下载hadoop安装包到Master桌面上(http://mirror.bit.edu.cn/apache/hadoop/common/hadoop-2.6.4/hadoop-2.6.4.tar.gz)

linux下载命令:
2、解压并修改hadoop安装目录权限:
# 解压hadoop-2.6.4.tar.gz 到/usr/local目录下 sudo tar -zxvf hadoop-2.6.4.tar.gz -C /usr/local cd /usr/local # 重名 sudo mv ./hadoop-2.6.4/ ./hadoop # 把hadoop安装目录控制权限分配给hadoop用户组的hadoop账户 sudo chown –R hadoop:hadoop ./hadoop
3、创建tmp文件夹:
mkdir usr/local/hadoop/tmp
4、修改/ect/profile,将hadoop安装目录配置到/etc/profile中:
在/etc/profile最后追加:
export JAVA_HOME=/usr/lib/jvm/java-8-oracle export JRE_HOME=/usr/lib/jvm/java-8-oracle export SCALA_HOME=/opt/scala/scala-2.10.5 # add hadoop bin/ directory to PATH export HADOOP_HOME=/usr/local/hadoop export PATH=$JAVA_HOME/bin:$JAVA_HOME/jre/bin:$JAVA_HOME:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$SCALA_HOME/bin:$PATH export CLASSPATH=$CLASS_PATH::$JAVA_HOME/lib:$JAVA_HOME/jre/lib
5、配置hadoop-env.sh:
sudo vim /usr/local/hadoop/etc/hadoop/hadoop-env.sh
在文件末尾追加java8的安装目录:
export JAVA_HOME=/usr/lib/jvm/java-8-oracle
备注:
1)尽管我们在/etc/profile中已经配置了JAVA_HOME,且hadoop-env.sh中已经包含了
# The java implementation to use. export JAVA_HOME=${JAVA_HOME}我们依然需要最佳上边这行配置。
2)Hadoop配置文件全部在conf目录下,有三个配置文件:core-site.xml,hdfs-site.xml,mapred-site.xml。
core-site.xml和hdfs-site.xml是站在HDFS角度上配置文件,core-site.xml和mapred-site.xml是站在MapReduce角度上配置文件。
6、配置core-site.xml:
hadoop的核心配置文件,我们这里配置hdfs的地址和端口号。
vim /usr/local/hadoop/etc/hadoop/core-site.xml
配置内容如下:
<configuration> <property> <name>hadoop.tmp.dir</name> <value>/usr/local/hadoop/tmp</value> <description>A base for other temporary directories.</description> </property> <property> <name>fs.defaultFS</name> <value>hdfs://192.168.1.200:9000</value> </property> <property> <name>fs.default.name</name> <value>hdfs://192.168.1.200:9000</value> </property> <property> <name>hadoop.native.lib</name> <value>false</value> </property> <property> <name>hadoop.proxyuser.hadoop.hosts</name> <value>*</value> </property> <property> <name>hadoop.proxyuser.hadoop.groups</name> <value>*</value> </property> </configuration>
7、配置hdfs-site.xml:
vim /usr/local/hadoop/etc/hadoop/hdfs-site.xml
配置内容如下:
<configuration> <property> <name>dfs.replication</name> <value>3</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>/usr/local/hadoop/dfs/name</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>/usr/local/hadoop/dfs/data</value> </property> <property> <name>dfs.webhdfs.enabled</name> <value>true</value> </property> <property> <name>dfs.permissions</name> <value>false</value> </property> </configuration>
8、配置slaves文件(master机器特有):
vim /usr/local/hadoop/etc/hadoop/slaves
注意:每行写一个ip。
我的集群配置如下:
192.168.1.200 192.168.1.201 192.168.1.202
9、手动创建目录(该项可以避免/usr/local/hadoop/dfs/logs、/usr/local/hadoop/dfs/name和/usr/local/hadoop/dfs/data出现权限问题):
1)为了不出问题,一般我们需要手动创建目录/usr/local/hadoop/dfs/logs、/usr/local/hadoop/dfs/name和/usr/local/hadoop/dfs/data目录,并分配777权限。
2)在hadoop初始化启动后,在master上/usr/local/hadoop/dfs/name下会自动创建./current/VERSION文件路径。
3)在hadoop初始化启动后,在所有node(node1、node2)上/usr/local/hadoop/dfs/data下会自动创建./current/VERSION文件路径。
- 将Master虚拟机配置后的Hadoop目录复制(拷贝,反正不是剪切)到各个子节点(Node1,Node2):
1、复制master上的hosts文件到所有节点(node1、node2)上:
hadoop@master:~/ scp /etc/hosts hadoop@node1:/ect/hosts
hadoop@master:~/ scp /etc/hosts hadoop@node2:/ect/hosts
备注:
1)如果遇到权限文件,修改master下/etc/host权限为777(sudo chmod 777 /etc/hosts)
2)如果修改权限后,还是拷贝失败,请直接ssh node1(node2)去修改,把所有子节点(node1、node2)上的/etc/hosts修改与master的/etc/hosts文件内容一致。
3)我这/etc/hosts文件内容如下:
192.168.1.200 master 192.168.1.201 node1 192.168.1.202 node2 # The following lines are desirable for IPv6 capable hosts #::1 localhost ip6-localhost ip6-loopback #ff02::1 ip6-allnodes #ff02::2 ip6-allrouters
2、复制master上配置好的hadoop文件到所有节点(node1、node2)下:
首先,需要在各个节点(node1、node2)上创建目录/usr/local/hadoop,并分配777权限:
hadoop@master:~/ ssh hadoop@node1 hadoop@node1:~/ mkdir /etc/local/hadoop hadoop@node1:~/ sudo chmod 777 /etc/local/hadoop #........ hadoop@node1:~/ exit hadoop@master:~/ ssh hadoop@node2 hadoop@node2:~/ mkdir /etc/local/hadoop hadoop@node2:~/ sudo chmod 777 /etc/local/hadoop #........ hadoop@node2:~/ exit
然后,拷贝master上配置好的hadoop文件到所有节点(node1、node2)下:
hadoop@master:~/ scp -r /usr/loca/hadoop hadoop@node1:/usr/local/
hadoop@master:~/ scp -r /usr/loca/hadoop hadoop@node2:/usr/local/
最后,修改各个节点(node1、node2)/etc/profile文件,追加HADOOP_HOME.
export JAVA_HOME=/usr/lib/jvm/java-8-oracle export JRE_HOME=/usr/lib/jvm/java-8-oracle export SCALA_HOME=/opt/scala/scala-2.10.5 # add hadoop bin/ directory to PATH export HADOOP_HOME=/usr/local/hadoop export PATH=$JAVA_HOME/bin:$JAVA_HOME/jre/bin:$JAVA_HOME:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$SCALA_HOME/bin:$PATH export CLASSPATH=$CLASS_PATH::$JAVA_HOME/lib:$JAVA_HOME/jre/lib
- 启动及测试Hadoop集群是否配置好:
1、格式化hdfs文件系统:
以hadoop账户登录master,执行命令:
hadoop namenode -format
如果有必要可以执行格式化datanode命令:
hadoop datanode -format
2、启动hadoop:
再启动前可以关闭所有防火墙:
service iptables stop # 或者 ufw disable
启动hadoop集群:
hadoop@master:~/ start-all.sh #如果这里不识别该命令,到/usr/loca/hadoop/sbin下执行该命令。
3、测试是否安装&启动正常
方法一:jps命令,如果在master查看到如下几个进程:

ssh 进入node1、node2,执行jps命令:

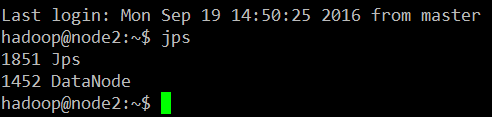
方法二:用hadoop dfsadmin -report命令
hadoop@master:~$ hadoop dfsadmin -report DEPRECATED: Use of this script to execute hdfs command is deprecated. Instead use the hdfs command for it. Configured Capacity: 37234434048 (34.68 GB) Present Capacity: 30607450112 (28.51 GB) DFS Remaining: 30607400960 (28.51 GB) DFS Used: 49152 (48 KB) DFS Used%: 0.00% Under replicated blocks: 0 Blocks with corrupt replicas: 0 Missing blocks: 0 ------------------------------------------------- Live datanodes (2): Name: 192.168.1.201:50010 (node1) Hostname: node1 Decommission Status : Normal Configured Capacity: 18617217024 (17.34 GB) DFS Used: 24576 (24 KB) Non DFS Used: 3238232064 (3.02 GB) DFS Remaining: 15378960384 (14.32 GB) DFS Used%: 0.00% DFS Remaining%: 82.61% Configured Cache Capacity: 0 (0 B) Cache Used: 0 (0 B) Cache Remaining: 0 (0 B) Cache Used%: 100.00% Cache Remaining%: 0.00% Xceivers: 1 Last contact: Thu Sep 22 00:21:32 CST 2016 Name: 192.168.1.202:50010 (node2) Hostname: node2 Decommission Status : Normal Configured Capacity: 18617217024 (17.34 GB) DFS Used: 24576 (24 KB) Non DFS Used: 3388751872 (3.16 GB) DFS Remaining: 15228440576 (14.18 GB) DFS Used%: 0.00% DFS Remaining%: 81.80% Configured Cache Capacity: 0 (0 B) Cache Used: 0 (0 B) Cache Remaining: 0 (0 B) Cache Used%: 100.00% Cache Remaining%: 0.00% Xceivers: 1 Last contact: Thu Sep 22 00:21:33 CST 2016 hadoop@master:~$
方法三:输入http://(master ip):50070
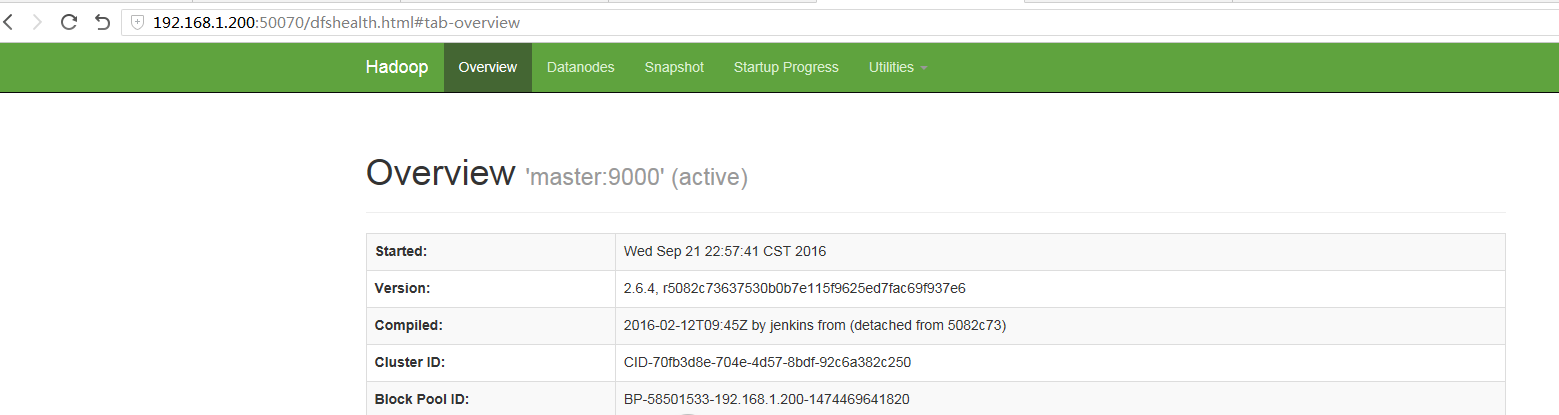
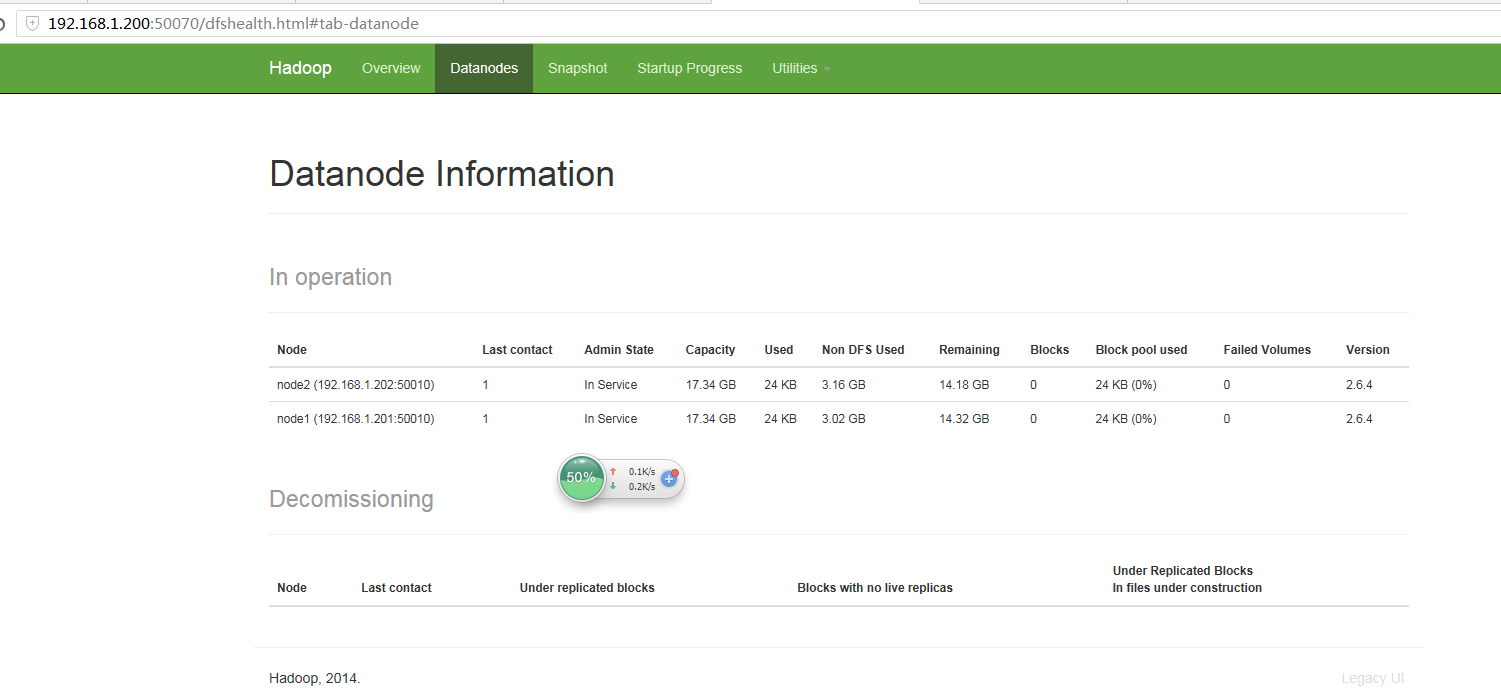
- 参考文章:
(如何验证是否hadoop配置成功)http://blog.csdn.net/chenyuangege/article/details/45582831
(坐标类型转化):http://api.zdoz.net/gcj2wgs.aspx?lat=34.121&lng=115.21212
基础才是编程人员应该深入研究的问题,比如:
1)List/Set/Map内部组成原理|区别
2)mysql索引存储结构&如何调优/b-tree特点、计算复杂度及影响复杂度的因素。。。
3)JVM运行组成与原理及调优
4)Java类加载器运行原理
5)Java中GC过程原理|使用的回收算法原理
6)Redis中hash一致性实现及与hash其他区别
7)Java多线程、线程池开发、管理Lock与Synchroined区别
8)Spring IOC/AOP 原理;加载过程的。。。
【+加关注】。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号