
Python:使用pymssql批量插入csv文件到数据库测试
并行进程怎么使用?
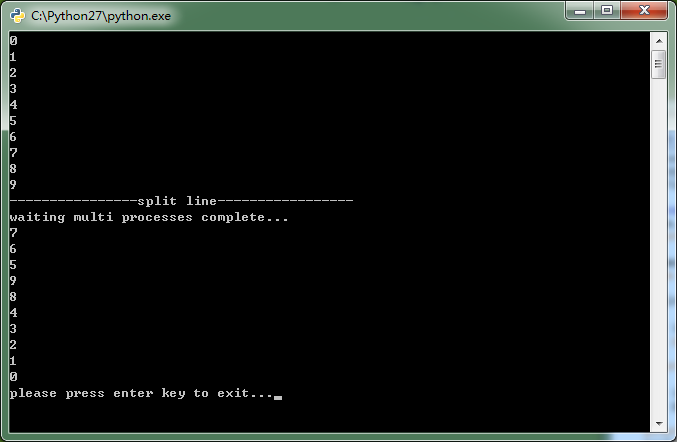
1 import os 2 import sys 3 import time 4 5 def processFunc(i): 6 time.sleep(10-i) 7 print i 8 9 if __name__=='__main__': 10 from multiprocessing import Pool 11 12 pool=Pool() 13 14 for i in range(0,10): 15 print i 16 17 print '----------------split line-----------------' 18 19 for i in range(0,10): 20 pool.apply_async(processFunc,args=(i,)) 21 22 print 'waiting multi processes complete...' 23 pool.close() 24 pool.join() 25 26 s = raw_input("please press enter key to exit...") 27 print s 28
怎么确定我们使用的是多进程呢?

实现批量入库:
import os import sys import pymssql server="172.21.111.222" user="Nuser" password="NDb" database="iNek_TestWithPython" def connectonSqlServer(): conn=pymssql.connect(server,user,password,database) cursor=conn.cursor() cursor.execute("""select getdate()""") row=cursor.fetchone() while row: print("sqlserver version:%s"%(row[0])) row=cursor.fetchone() conn.close() def getCreateTableScript(enodebid): script="""IF NOT EXISTS (SELECT * FROM sys.objects WHERE object_id = OBJECT_ID(N'[dbo].[rFile{0}]') AND type in (N'U')) BEGIN CREATE TABLE [dbo].[rFile{0}]( [OID] [bigint] IDENTITY(1,1) NOT NULL, [TimeStamp] [datetime] NULL, [rTime] [datetime] NOT NULL, [bTime] [datetime] NOT NULL, [eTim] [datetime] NOT NULL, [rid] [int] NOT NULL, [s] [int] NOT NULL, [c] [int] NOT NULL, [muid] [decimal](18, 2) NULL, [lsa] [decimal](18, 2) NULL, [lsrip] [int] NULL, [lcOID] [int] NULL, [lcrq] [decimal](18, 2) NULL, [gc2c1] [int] NULL, [tdcCP] [decimal](18, 2) NULL,
...
... CONSTRAINT [PK_rFile{0}] PRIMARY KEY NONCLUSTERED ( [OID] ASC, [rTime] ASC )WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PS_OnrTime]([rTime]) ) ON [PS_OnrTime]([rTime]) END IF NOT EXISTS (SELECT * FROM sys.indexes WHERE object_id = OBJECT_ID(N'[dbo].[rFile{0}]') AND name = N'IX_rFile_c{0}') BEGIN CREATE NONCLUSTERED INDEX [IX_rFile_c{0}] ON [dbo].[rFile{0}] ([c] ASC)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, IGNORE_DUP_KEY = OFF, DROP_EXISTING = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY] End
...
... """.format(enodebid) return script def getBulkInsertScript(enodebid,csvFilePath,formatFilePath): script="""BULK INSERT [dbo].[rFile{0}] FROM '{1}' WITH ( BATCHSIZE=10000, FIELDTERMINATOR='\\t', ROWTERMINATOR ='\\r\\n', FORMATFILE ='{2}' )""".format(enodebid,csvFilePath,formatFilePath) return script def batchInsertToDB(enodebid,filePath): from time import time start=time() fileExt=os.path.splitext(filePath)[1] #print fileExt if os.path.isfile(filePath) and (fileExt=='.gz' or fileExt=='.zip' or fileExt=='.xml' or fileExt==".csv"): # 1)create table with index conn=pymssql.connect(server,user,password,database) cursor=conn.cursor() cursor.execute(getCreateTableScript(enodebid)) conn.commit() # 2)load csv file to db cursor.execute(getBulkInsertScript(enodebid=enodebid,csvFilePath=filePath,formatFilePath="D:\\python_program\\rFileTableFormat.xml")) conn.commit() conn.close() end=time() print 'file:%s |size:%0.2fMB |timeuse:%0.1fs' % (os.path.basename(filePath),os.path.getsize(filePath)/1024/1024,end-start) if __name__=="__main__": from time import time #it's mutilple pro2cess not mutilple thread. from multiprocessing import Pool start=time() pool=Pool() rootDir="D:\\python_program\\csv" for dirName in os.listdir(rootDir): for fileName in os.listdir(rootDir+'\\'+dirName): pool.apply_async(batchInsertToDB,args=(dirName,rootDir+'\\'+dirName+'\\'+fileName,)) #single pool apply #batchInsertToDB(dirName,rootDir+'\\'+dirName+'\\'+fileName) print 'Waiting for all subprocesses done.....' pool.close() pool.join() end=time() print 'use time: %.1fs' %(end-start)
测试环境:
2.22服务器,CPU:E54620,Memory:64,磁盘SAS/万转以上。
测试速度:41分钟,处理200个ENB,一共4749个csv文件,一共19.1G,入库记录1 1491 1843条记录,每条记录30个字段左右,平均每秒入库46712条记录(每条记录32列)。
Python是8个进程运行。
监控图:
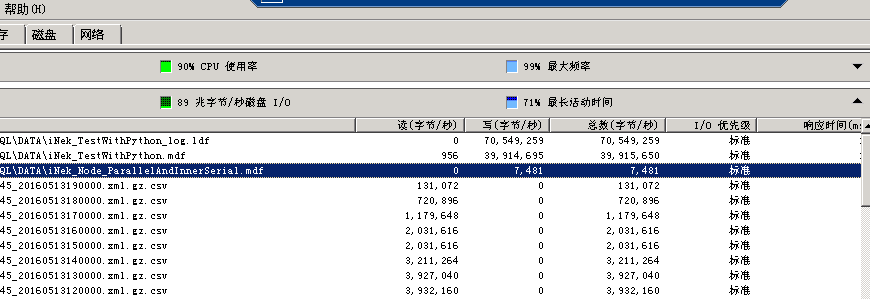
平均数据库日志文件写入速度:70M/S
平均数据库 文件写入速度:30M/S~40M/S
.net 并行多进程操作:
-- 2016-08-02 00:06:19.567 2016-08-01 23:37:14.067
-- 16parallel task :10s/enb
-- 2016-08-02 00:29:42.083 2016-08-02 00:09:29.297
-- 8 parallel task : 7s/enb
select (20*60+13)/160
基础才是编程人员应该深入研究的问题,比如:
1)List/Set/Map内部组成原理|区别
2)mysql索引存储结构&如何调优/b-tree特点、计算复杂度及影响复杂度的因素。。。
3)JVM运行组成与原理及调优
4)Java类加载器运行原理
5)Java中GC过程原理|使用的回收算法原理
6)Redis中hash一致性实现及与hash其他区别
7)Java多线程、线程池开发、管理Lock与Synchroined区别
8)Spring IOC/AOP 原理;加载过程的。。。
【+加关注】。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号