
分布式多计算机调度平台
方案:
1,) 目前我们的程序,单独一台计算机一天分析100G以内的xml数据,有选择的将需要的数据入库数据库(sqlserver2008 r2 64)记录近1亿左右,一台128G内存,32核的计算机勉强能完成任务;
2,) 随着市场的扩展,我们拿到的数据量一天的数据就有1T左右的xml数据,单台计算机运行已经分析完成时间成为了瓶颈,可能需要十天或者更长的时间。
解决方案:
为了能够让我们的产品能有更强的生存力,吸引到更多的用户;项目组就有了这么一个讨论:
方案1,)使用hadoop对这种大数据处理,但由于目前公司针对hadoop技术了解深度有限,正常应用到产品中还需要一段时间,因此hadoop方案只作为实施级别比较低,但不太表我们不会做,时间的问题。
方案2,)基于我们目前的平台进一步扩展,怎么扩展?
2.1,)让我们的工具在多个计算机运行,把任务拆分到不同的计算进行运行。假设1T的数据,我们有10计算机,每台给平均分发100G的数据,这样对数据库及计算机的压力会减少少多,横向扩展是我们目前不能立即上线的一个必行方案;
2.2,)工具扩展后,存储数据库也一定需要扩展,每台计算机最好能对应一台存储数据库,对业务实现及数据库压力减负,都有好处。
2.3,)对数据库扩展后,应用端怎么合并数据就成为了一个必须不可不考虑问题。那么我们计划怎么处理合并呢?首先,每台计算节点上的服务器在插入必要数据的同时,更具业务需求将必须要的数据插入到汇总数据库中,而详细信息只保存到对应的计算节点对应的数据库中,应用端直接访问数据库为汇总数据库,但查看某条信息的具体信息时,可以从该条信息中找到具体信息存储的数据,进而从对应的数据库中拿到详细信息。
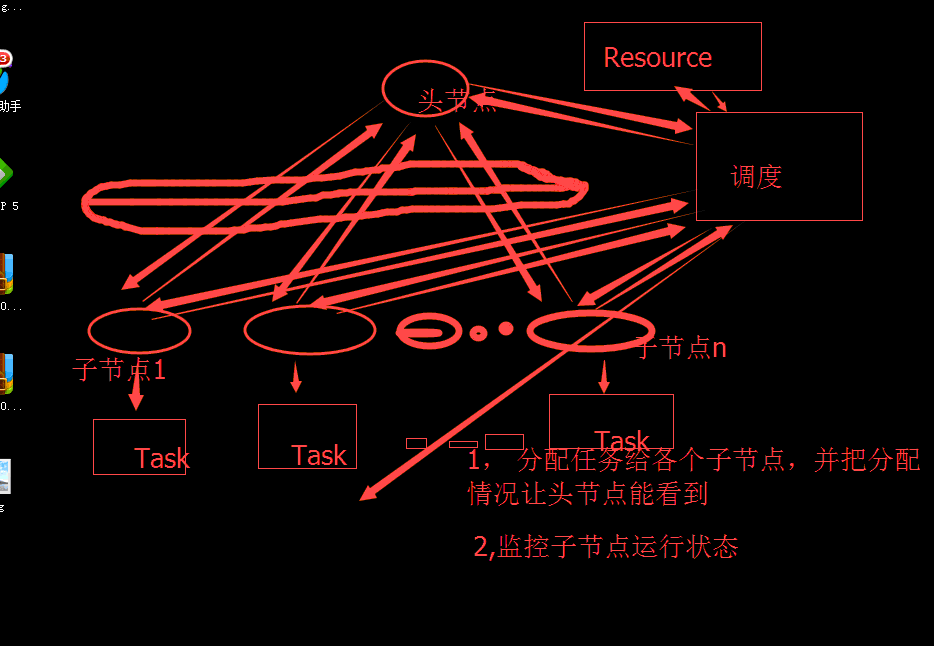
决定:
方案2已经通过了调研,怎实施?实施有多大难度?技术难题在哪?
其他问题先不说,就谈下技术难点,既然要分布多计算执行,就一定要有一个调度器,而调度器中的难点大家就都清晰吧------心跳监控任务执行状态,通信的稳定性,高效性,准确性,消息队列怎么规划?
基础才是编程人员应该深入研究的问题,比如:
1)List/Set/Map内部组成原理|区别
2)mysql索引存储结构&如何调优/b-tree特点、计算复杂度及影响复杂度的因素。。。
3)JVM运行组成与原理及调优
4)Java类加载器运行原理
5)Java中GC过程原理|使用的回收算法原理
6)Redis中hash一致性实现及与hash其他区别
7)Java多线程、线程池开发、管理Lock与Synchroined区别
8)Spring IOC/AOP 原理;加载过程的。。。
【+加关注】。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号