
Spark2.x(六十二):(Spark2.4)共享变量 - Broadcast原理分析
之前对Broadcast有分析,但是不够深入《Spark2.3(四十三):Spark Broadcast总结》,本章对其实现过程以及原理进行分析。
带着以下几个问题去写本篇文章:
1)driver端如何实现broadcast的装备,是否会把broadcast数据发送给executor端?
2)executor如何获取到broadcast数据?
导入
Spark一个非常重要的特征就是共享变量。共享变量分为广播变量(broadcast variable)和累加器(Accumulators)。
- 广播变量可以在driver程序中写入,在executor端读取。
- 累加器在executors中写入,而在驱动程序(driver端)读取。
但本章只讲解broadcast变量
Spark官网“共享变量”简介请参考:
http://spark.apache.org/docs/latest/rdd-programming-guide.html#broadcast-variables
通常,当传递给Spark算子(比如map或reduce)函数在远程集群节点上执行时,它在函数中使用的所有变量的单独副本上工作。这些变量被复制到每台服务器上,对远程服务器上变量的任何更新都不会传播回driver程序。通常支持跨Tasks的读写共享变量性能比较低。也就是说如果在一个算子函数中使用到了某个外部的变量,那么这个变量的值会被拷贝到每个task中。此时每个task只能操作自己的那份变量副本。如果多个task想要共享某个变量,那么这种方式是做不到的。
然而,Spark确实为两种常见的使用模型提供了两种有限类型的共享变量:广播变量和累加器。
广播变量的概念
广播变量提供了一种方法,可以在driver端获取本地数据,并将它的只读副本分发给运行有executor(与driver一起构成一个应用程序的executor,不是另外一个应用程序的executor)的节点服务器,而不是为每个Task发送新副本。广播变量允许程序员在每台计算机上缓存只读变量,而不是将其副本与Tasks一起发送。例如,它们可以有效地为每个节点提供一个大型输入数据集的副本。Spark还尝试使用有效的广播算法来分发广播变量,以降低通信成本。Spark将值传递给Executor(一次),当在Executor中多次使用广播变量时,Task可以共享它而不会导致重复的网络传输。
Spark应用程序作业的执行由一系列Stage构成,由分布式“shuffle”操作分隔。Spark自动广播每个Stage中Tasks所需的公共数据。以这种方式广播的数据以序列化形式缓存,并在运行每个Task之前进行反序列化。这意味着,仅当跨多个Stage的Tasks需要相同的数据或以反序列化形式缓存数据时,显式创建广播变量才有用。
广播变量是通过调用sparkContext.broadcast(v)从变量v创建的。广播变量是围绕v的包装器,它的值可以通过调用value方法来访问。使用示例:
scala> val broadcastVar = sc.broadcast(Array(1, 2, 3)) broadcastVar: org.apache.spark.broadcast.Broadcast[Array[Int]] = Broadcast(0) scala> broadcastVar.value res0: Array[Int] = Array(1, 2, 3)
创建广播变量后,应在集群上运行的任何函数中使用它,而不是使用值v,这样V就不会多次发送到节点。此外,对象v在广播后不应进行修改,以确保所有节点都获得广播变量的相同值(例如,如果变量稍后被发送到新节点)。
使用广播变量的场景示例:
- 大表join小表时,将小表广播掉,以(broadcast join)方式运行,实现优化。
- 广播机器学习模型以便能够对我们的数据进行预测
通过SparkContext#broadcast(v)来创建广播变量,返回的广播变量其实就是一个实现了Broadcast接口的包装类(TorrentBroadcast)对象。在使用时,需要在executor上运行的算子(map/reduce等)内部会引用该broadcast包装的广播变量。
另外创建后在driver端修改广播变量中的值,而不做其他操作时,executor是无法拿到driver端修改后的数据的。如果要修改创建后的广播变量,请参考《Spark2.3(四十二):Spark Streaming和Spark Structured Streaming更新broadcast总结(二)》。
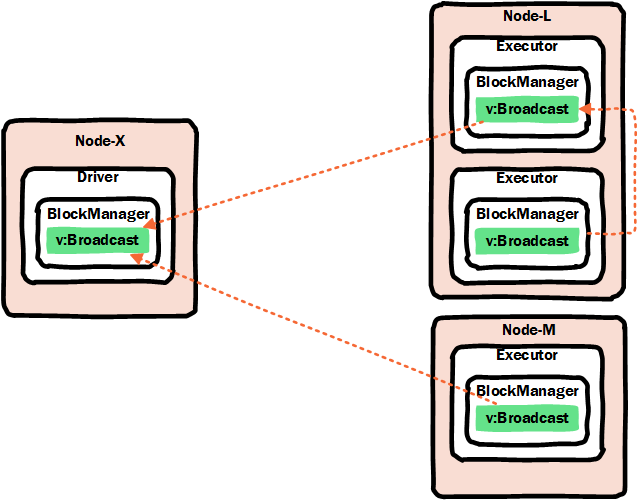
广播替代方案
其实我们可以在闭包中捕获局部变量,以便将数据从driver程序传输到worker,但这种方式是每个Task都发送一个副本变量,相对于broadcast方式比较耗费网络带宽和内存空间。
另外我们也可以在Executor端采用单例的方式去加载资源文件,来替代broadcast方案,但是这种方案与broadcast还是有区别:
- broadcast不涉及到当executor多个vcore时,并行task之间同时加载单例资源数据线程安全问题(当然单利中可以通过synchronized同步实现线程安全,首次加载并行线程排队问题会涉及到效率问题);
- broadcast比较完美情况下,在executor的节点服务器上只有一个executor从driver端通过remote方式读取副本数据,该节点服务器上的其他executor从local读取资源,读取不到时才会remote读取资源;但单例方式每个executor都需要加载一次资源;
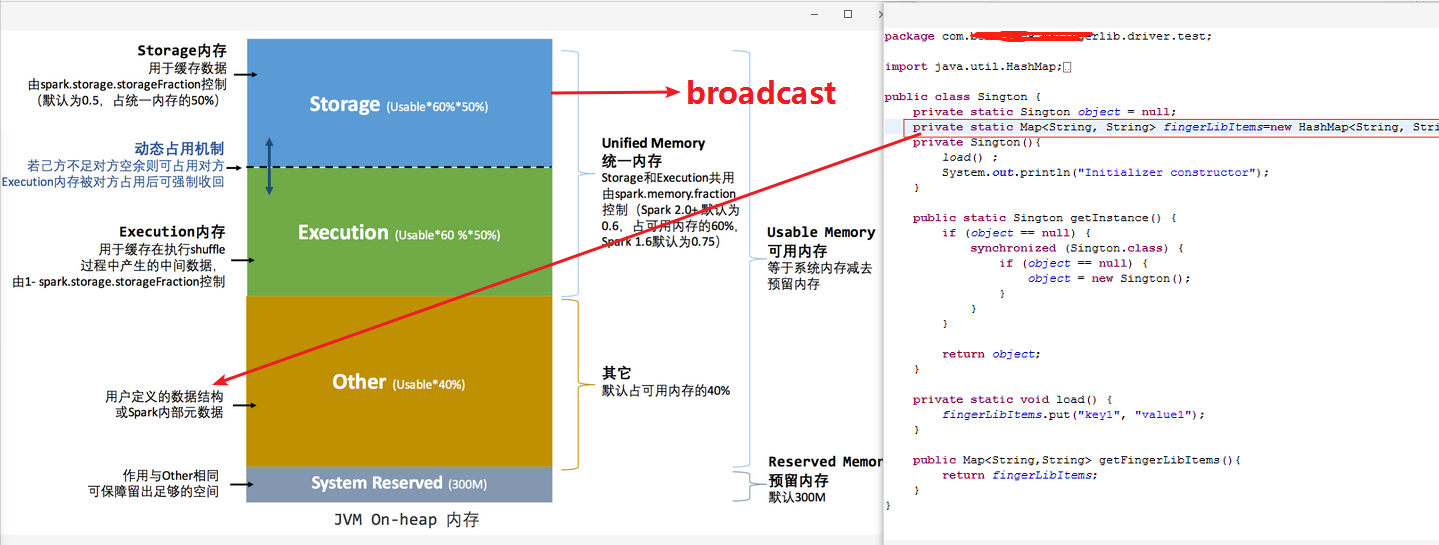
- 存储结构不同,broadcast是在spark2.0+内存结构中存储在Storage Memory这块内存区上,而单例方式的数据是存放到“用户自定义数据结构”Other内存区上。
使用时注意事项
1)broadcast的定义必须在Driver端,不能再executor端定义;
2)调用unpersist(),unpersist(boolean blocking),destroy(),distroy(boolean blocking)方法这些方法必须在driver端调用。
3)在Driver端可以修改广播变量的值,在Executor端无法修改广播变量的值。
具体操作步骤:
a.在driver端调用unpersist(true)方法;
b.对该broadcast实例对象进行重新赋值。
参考《Spark2.2(三十三):Spark Streaming和Spark Structured Streaming更新broadcast总结(一)》、《Spark2.3(四十二):Spark Streaming和Spark Structured Streaming更新broadcast总结(二)》
4)能不能将一个RDD使用广播变量广播出去?
不能,因为RDD是不存储数据的。可以将RDD的结果广播出去。
5)如果executor端用到了Driver的变量,如果不使用广播变量在Executor有多少task就有多少Driver端的变量副本。
6)如果Executor端用到了Driver的变量,如果使用广播变量在每个Executor中只有一份Driver端的变量副本。
7)使用时,算子函数内部引用的是broadcast包装类对象,而不是broadcast.getValue()的值。否则,毫无意义,每个task都会存在一份副本。
Broadcast的实现
首先我们我们看下broadcast的类结构:
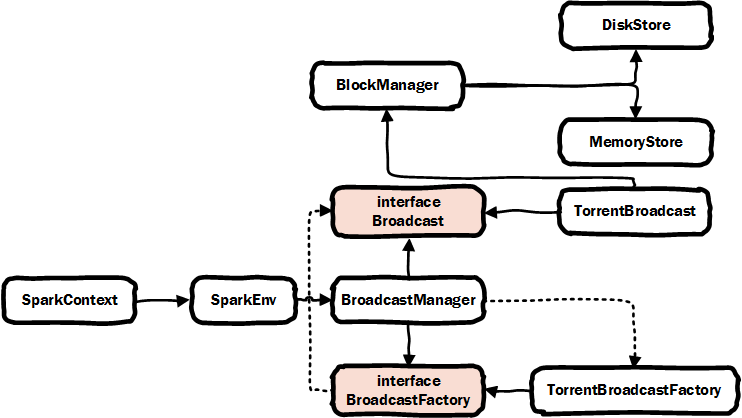
SparkContext类:https://github.com/apache/spark/blob/branch-2.4/core/src/main/scala/org/apache/spark/SparkContext.scala,是broadcast使用的入口函数。
Broadcast接口类:https://github.com/apache/spark/blob/branch-2.4/core/src/main/scala/org/apache/spark/broadcast/Broadcast.scala,是broadcast包装类的接口类。
BroadcastFactory接口类:https://github.com/apache/spark/blob/branch-2.4/core/src/main/scala/org/apache/spark/broadcast/BroadcastFactory.scala,是broadcast包装的工厂类接口。
TorrentBroadcast类:https://github.com/apache/spark/blob/branch-2.4/core/src/main/scala/org/apache/spark/broadcast/TorrentBroadcast.scala,是broadcast包装类的唯一实现类。
TorrentBroadcastFactory类:https://github.com/apache/spark/blob/branch-2.4/core/src/main/scala/org/apache/spark/broadcast/TorrentBroadcastFactory.scala,是broadcast包装的工厂类接口的唯一实现类。
BroadcastManager类:https://github.com/apache/spark/blob/branch-2.4/core/src/main/scala/org/apache/spark/broadcast/BroadcastManager.scala,broadcast管理类,在SparkEnv中引用,SparkContext#broadcast中调用就是SparkContext#env#broadcastManager的。
BlockManager类:https://github.com/apache/spark/blob/branch-2.4/core/src/main/scala/org/apache/spark/storage/BlockManager.scala,blockManager是env中引用对block的管理类,它会把数据根据存储级别来存储数据。如果是memory存储则调用memoryStore来实现存储,如果是磁盘存储则使用diskStore来实现存储。
MemoryStore类:https://github.com/apache/spark/blob/branch-2.4/core/src/main/scala/org/apache/spark/storage/memory/MemoryStore.scala,内存存储实现类。读、写操作。
DiskStore类结构:https://github.com/apache/spark/blob/branch-2.4/core/src/main/scala/org/apache/spark/storage/DiskStore.scala,磁盘存储实现类。读、写操作。
SparkContext中broadcast(v)函数
用来创建broadcast variable的broadcasat(v)函数定义在SparkContext中,SparkContext中broadcas(v)t代码如下:
/** * Broadcast a read-only variable to the cluster, returning a * [[org.apache.spark.broadcast.Broadcast]] object for reading it in distributed functions. * The variable will be sent to each cluster only once. * * @param value value to broadcast to the Spark nodes * @return `Broadcast` object, a read-only variable cached on each machine */ def broadcast[T: ClassTag](value: T): Broadcast[T] = { assertNotStopped() require(!classOf[RDD[_]].isAssignableFrom(classTag[T].runtimeClass), "Can not directly broadcast RDDs; instead, call collect() and broadcast the result.") val bc = env.broadcastManager.newBroadcast[T](value, isLocal) val callSite = getCallSite logInfo("Created broadcast " + bc.id + " from " + callSite.shortForm) cleaner.foreach(_.registerBroadcastForCleanup(bc)) bc }
调用了SparkContext#broadcast(v)会创建一个广播变量,并返回一个org.apache.spark.broadcast.Broadcast对象,这样就可以分布式函数中来读取该广播变量的值。该变量会被发送到各个存在executor的节点上。
Broadcast()函数的实现流程如下:
1)判断需要广播的变量是否是分布式变量,若是则会终止函数,报告"Can not directly broadcast RDDs; instead, call collect() and broadcast the result.”的错误。
2)通过BroadcastManger#newBroadcast函数来创建广播变量,并返回一个Broadcast对象,Broadcast只是一个接口类,真正返回的是TorrentBroadcast类的对象。
3)注册broadcast的cleanup函数,实际上相当于注册到ContextCleaner中,后边ContextCleaner内部有一个线程会默认每30分钟触发一次对弱引用的broadcast等的清理工作。
4)返回新创建的实现了Broadcast接口的类对象(或者说,返回broadcast包装类对象)。
BroadcastManager类
BroadcastManager在SparkContext#broadcast(v)中被使用到,因此我们沿着这个路线,来看下这个BroadcastManager的实现类。它是一个broadcast的管理类,用来统一创建broadcast对外的接口:创建,销毁。
BroadcastManager的类定义如下:
private[spark] class BroadcastManager( val isDriver: Boolean, conf: SparkConf, securityManager: SecurityManager) extends Logging { private var initialized = false private var broadcastFactory: BroadcastFactory = null initialize() // Called by SparkContext or Executor before using Broadcast private def initialize() { synchronized { if (!initialized) { broadcastFactory = new TorrentBroadcastFactory broadcastFactory.initialize(isDriver, conf, securityManager) initialized = true } } } def stop() { broadcastFactory.stop() } private val nextBroadcastId = new AtomicLong(0) private[broadcast] val cachedValues = { new ReferenceMap(AbstractReferenceMap.HARD, AbstractReferenceMap.WEAK) } def newBroadcast[T: ClassTag](value_ : T, isLocal: Boolean): Broadcast[T] = { broadcastFactory.newBroadcast[T](value_, isLocal, nextBroadcastId.getAndIncrement()) } def unbroadcast(id: Long, removeFromDriver: Boolean, blocking: Boolean) { broadcastFactory.unbroadcast(id, removeFromDriver, blocking) } }
该类的构造函数流程如下:
// 是否已经初始 private var initialized = false private var broadcastFactory: BroadcastFactory = null initialize() // 生成广播变量的id,该id是唯一的,这里先初始化,会在创建broadcast变量时进行自增操作 private val nextBroadcastId = new AtomicLong(0)
1)定义了两个proviate的变量:initialized,nextBroadcastId。其中nextBroadcastId为每个广播变量生成一个唯一的id,在创建broadcast变量时,会通过nextBroadcastId,getAndIncrement()进行自增,并调用initialize()函数来进行初始化。
2)initialize()函数的实现逻辑如下:
// Called by SparkContext or Executor before using Broadcast private def initialize() { synchronized { // 加锁 if (!initialized) { // 初始化broadcastFactory变量,这里创建了TorrentBroadcastFactory对象 broadcastFactory = new TorrentBroadcastFactory // 调用TorrentBroadcastFactory的initialize函数来初始化 broadcastFactory.initialize(isDriver, conf, securityManager) // 把initialized设置为true,同一个对象只初始化一次 initialized = true } } }
2.1)初始化broadcastFactory变量,这里创建了TorrentBroadcastFactory对象;
2.2)调用TorrentBroadcastFactory#initialize()进行初始化,可以查阅TorrentBroadcastFactory,会发现这个initialize()方法实现为空,什么也不做;
2.3)把initialize变量设置为true,并结合synchronized实现broadcastFactory只能被实例化一次。
BroadcastManager中定义了unbroadcast()方法
实现broadcast清理功能:删除executor上与此TorrentBroadcast关联的所有持久化块。如果removeFromDriver为true,也要删除driver程序上的这些持久block。
- id: Long, 这里指broadcatId
- removeFromDriver: Boolean, 是否从driver端移除broadcast持久化block数据,否则driver端会残留broadcast持久化block数据。
- blocking: Boolean,是否同步等待完成才返回。如果false,则会异步的删除executor上broadcast副本数据。
BroadcastManager中定义了newBroadcast()方法
该方法是SparkConetxt#broadcast()中调用用来创建broadcast对象使用的,那么我们看下其具体实现:
def newBroadcast[T: ClassTag](value_ : T, isLocal: Boolean): Broadcast[T] = {
broadcastFactory.newBroadcast[T](value_, isLocal, nextBroadcastId.getAndIncrement())
}
1)根据上边分析,在BroadcastManager初始化时,broadcastFactory给赋值为TorrentBroadcastFactory,那么这个broadcastFactory其实就是TorrentBroadcastFactory的实例对象;
2)分析到这里,我们可以清楚的知道真正创建broadcast包装类的实现是在TorrentBroadcastFactory#newBroadcast()实现的,那么接下来我们来查阅TorrentBroadcastFactory的实现。
TorrentBroadcastFactory类
该类实现了一个类似于BitTorrent的协议,通过该协议把广播数据分发到各个executor中。这些操作其实是在类TorrentBroadcast中实现的。
比特流(BitTorrent)是一种内容分发协议,由布拉姆·科恩自主开发(2003年,软件工程师Bram Cohen发明了BitTorrent协议)。它采用高效的软件分发系统和点对点技术共享大体积文件(如一部电影或电视节目),并使每个用户像网络重新分配结点那样提供上传服务。一般的下载服务器为每一个发出下载请求的用户提供下载服务,而BitTorrent的工作方式与之不同。分配器或文件的持有者将文件发送给其中一名用户,再由这名用户转发给其它用户,用户之间相互转发自己所拥有的文件部分,直到每个用户的下载都全部完成。这种方法可以使下载服务器同时处理多个大体积文件的下载请求,而无须占用大量带宽。
TorrentBroadcastFactory的代码定义如下:
/** * A [[org.apache.spark.broadcast.Broadcast]] implementation that uses a BitTorrent-like * protocol to do a distributed transfer of the broadcasted data to the executors. Refer to * [[org.apache.spark.broadcast.TorrentBroadcast]] for more details. */ private[spark] class TorrentBroadcastFactory extends BroadcastFactory { override def initialize(isDriver: Boolean, conf: SparkConf, securityMgr: SecurityManager) { } override def newBroadcast[T: ClassTag](value_ : T, isLocal: Boolean, id: Long): Broadcast[T] = { new TorrentBroadcast[T](value_, id) } override def stop() { } /** * Remove all persisted state associated with the torrent broadcast with the given ID. * @param removeFromDriver Whether to remove state from the driver. * @param blocking Whether to block until unbroadcasted */ override def unbroadcast(id: Long, removeFromDriver: Boolean, blocking: Boolean) { TorrentBroadcast.unpersist(id, removeFromDriver, blocking) } }
TorrentBroadcast类
TorrentBroadcasat是真正广播变量操作实现类
该类实现机制:
1)driver端将序列化对象分成多个小block,并将这些block存储到driver端的blockManager中,blockManager是上会根据当前存储类型(MEMORY_AND_DISK_SER,这也是当driver内存不够时,driver也不内存溢出的原因)去存储,优先使用内存存储,调用MemoryStore来存储,如果内存不够,则使用DiskStore来进行磁盘存储。
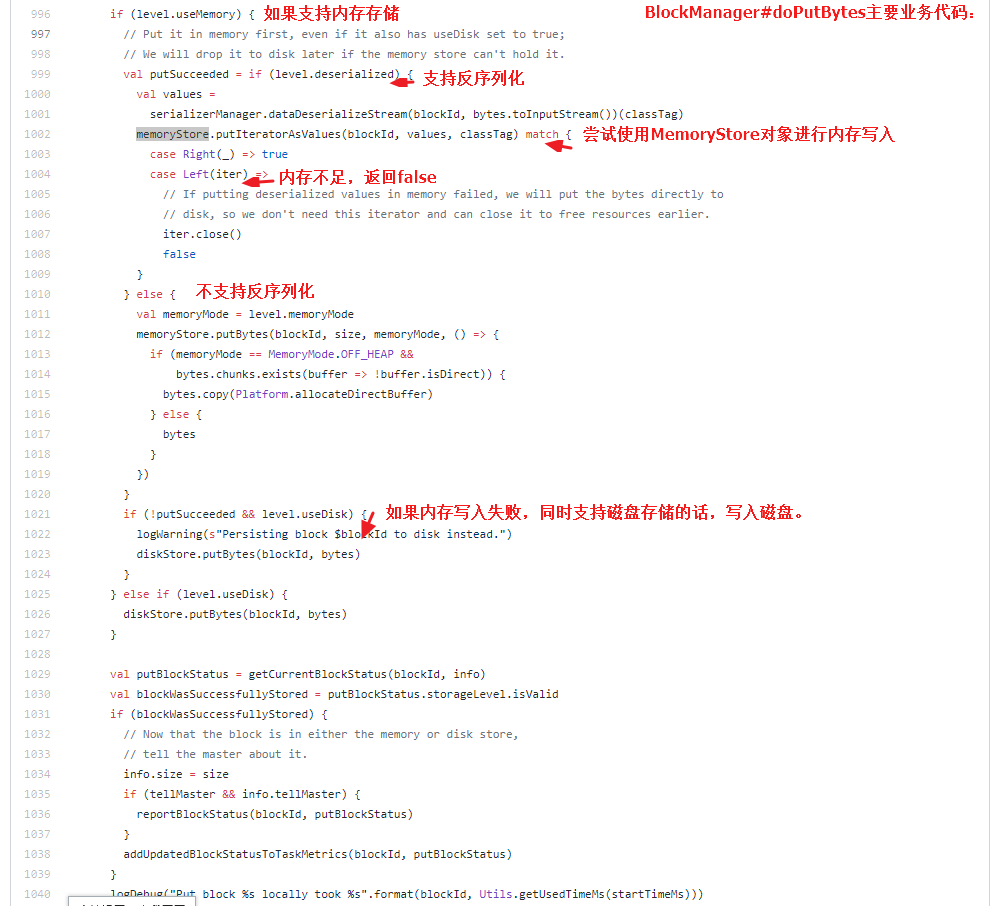
2)在每个executor上,executor使用到broadcast对象时,会尝试从当前executor的blockManager中获取数据,若不存在,则远程从driver或其他executor(如果可用)中获取对象block,一旦获取到block,它就会将block存放到broadcastCache中,为其他executor来获取数据做好准备。
3)通过这种方式,可以防止driver成为(向每个executor)发送广播副本的瓶颈。如果driver向每个executor都要发送广播副本则会导致driver网络带宽成为瓶颈,效率也会比较低。
代码分析:
该类的构造函数:
1)通过readBroadcastBlock函数构造broadcast,并存放到broadcastCache中。在driver端,若需要value值,它会直接从本地的block manager中读取数据。readBroadcastBlock函数的实现逻辑如下:
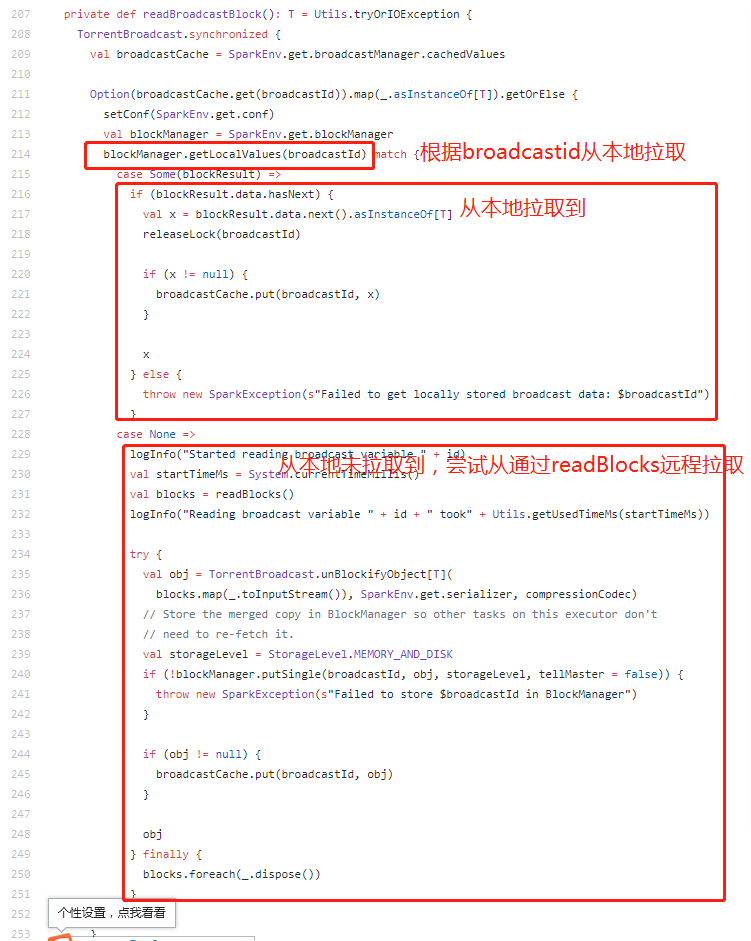
readBlock业务:
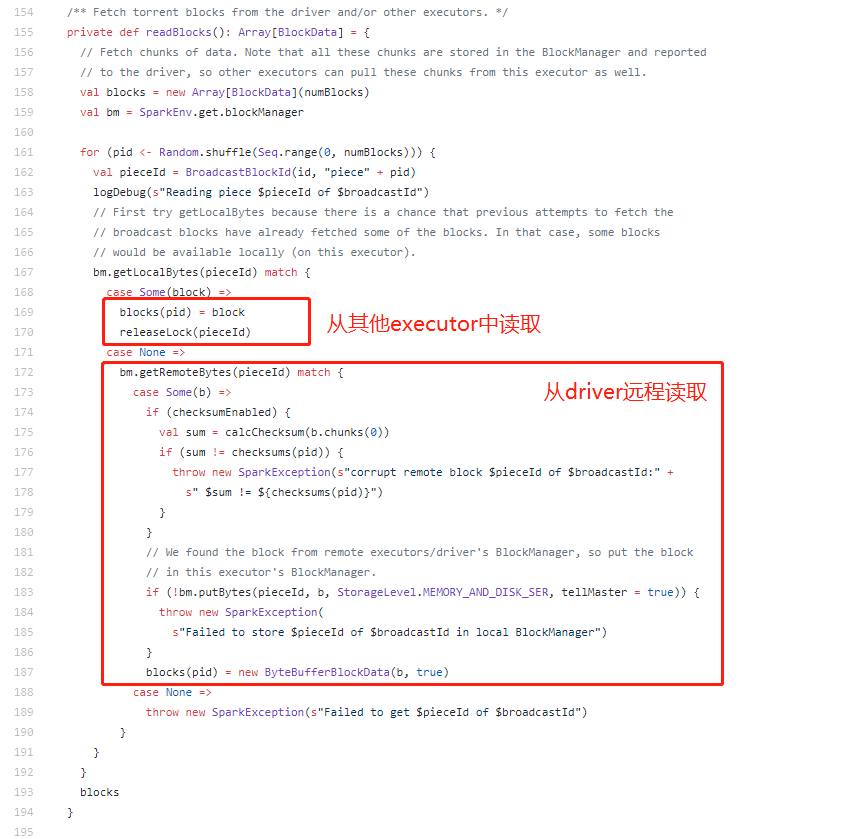
获取流程为:尝试从当前executor的blockManager中获取数据,若不存在,则远程从driver或其他executor(如果可用)中获取对象block,获取到后存放到broadcastCache中。
1)从当前executor本地获取数据块:SparkEnv.get.broadcastManager.cachedValues获取对应broadcastId的数据块值:broadcastCache.get(broadcastId)
2)从blockManager中获取对应id的广播变量的值:blockManager.getLocalValues(broadcastId)
3)若从blockManager中获取到了该变量的值,则:broadcastCache.put(broadcastId, x)
4)若不能从blockManager中获取值,则调用readBlocks函数来读取数据块。该函数会从driver或其他的executors中读取该变量的数据。
2)设置配置信息:setConf(SparkEnv.get.conf)
3)初始化广播变量的唯一值:private val broadcastId=BraodcastBlockId(id)
4)调用writeBlocks把广播变量划分成多个块,并保存到blockManager中。
注意:其中该类中有些属性被@transient修饰的,被@transient修饰的属性不能被序列化。
Executor端如何获取broadcast值
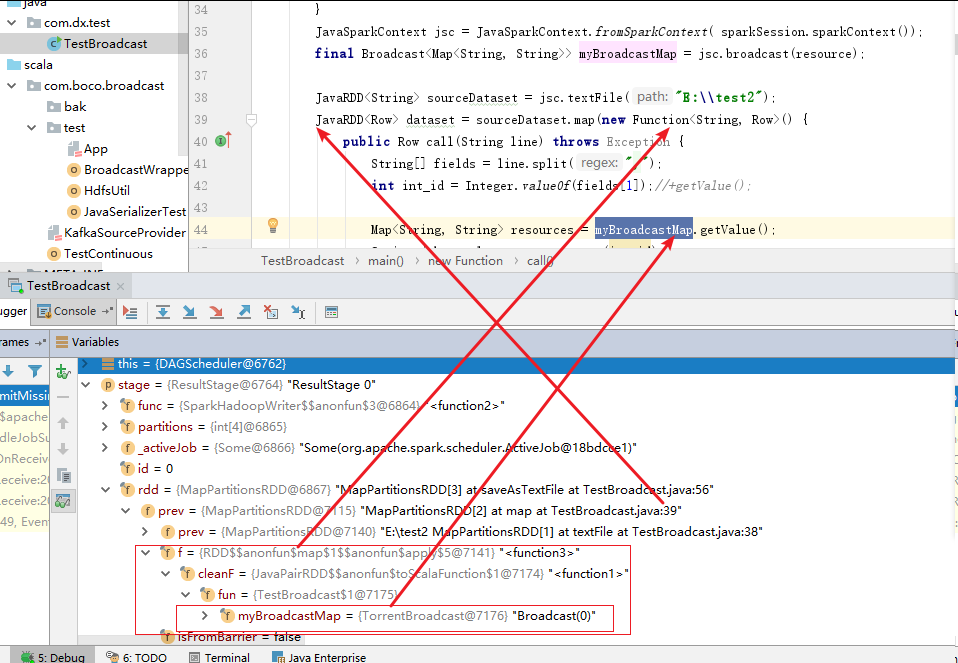
从实际开发中,我们常先定义的broadcast,然后把broadcast对象传递给算子(比如:MapFunction)内部调用。传递给算子时,是传递的broadcast数据的包装类对象(实际上就是TorrentBroadcast对象),在内部通过broadcast#getValue()获取broadcast值。举例说明:
StructType resulStructType = new StructType(); resulStructType = resulStructType.add("int_id", DataTypes.StringType, false); resulStructType = resulStructType.add("job_result", DataTypes.StringType, true); ExpressionEncoder<Row> resultEncoder = RowEncoder.apply(resulStructType); JavaSparkContext javaSparkContext = new JavaSparkContext(spark.sparkContext().getConf()); Map<String, String> resource = new java.util.HashMap<String, String>(); for (int i = 0; i < 10000; i++) { resource.put(String.valueOf(i), String.valueOf(i)); } Broadcast<Map<String, String>> broadcastMap = javaSparkContext.broadcast(resource); sourceDataset = sourceDataset.map(new MapFunction<Row, Row>() { private static final long serialVersionUID = 1L; @Override public Row call(Row row) throws Exception { int int_id_idx = row.schema().fieldIndex("int_id"); Object int_idObject = row.get(int_id_idx); String int_id = int_idObject.toString();
Map<String, String> resources = broadcastMap.getValue(); String job_result = resources.get(int_id); Object[] values = new Object[2]; values[0] = int_id; values[1] = job_result; return RowFactory.create(values); } }, resultEncoder); sourceDataset.printSchema();
那么,我们接下来从源码分析下,这个TorrentBroadcast#getValue()方法是如何实现的:
private[spark] class TorrentBroadcast[T: ClassTag](obj: T, id: Long) extends Broadcast[T](id) with Logging with Serializable { /** * Value of the broadcast object on executors. This is reconstructed by [[readBroadcastBlock]], * which builds this value by reading blocks from the driver and/or other executors. * * On the driver, if the value is required, it is read lazily from the block manager. */ @transient private lazy val _value: T = readBroadcastBlock() /** The compression codec to use, or None if compression is disabled */ @transient private var compressionCodec: Option[CompressionCodec] = _ /** Size of each block. Default value is 4MB. This value is only read by the broadcaster. */ @transient private var blockSize: Int = _ private def setConf(conf: SparkConf) { compressionCodec = if (conf.getBoolean("spark.broadcast.compress", true)) { Some(CompressionCodec.createCodec(conf)) } else { None } // Note: use getSizeAsKb (not bytes) to maintain compatibility if no units are provided blockSize = conf.getSizeAsKb("spark.broadcast.blockSize", "4m").toInt * 1024 checksumEnabled = conf.getBoolean("spark.broadcast.checksum", true) } setConf(SparkEnv.get.conf) private val broadcastId = BroadcastBlockId(id) /** Total number of blocks this broadcast variable contains. */ private val numBlocks: Int = writeBlocks(obj) /** Whether to generate checksum for blocks or not. */ private var checksumEnabled: Boolean = false /** The checksum for all the blocks. */ private var checksums: Array[Int] = _ override protected def getValue() = { _value } 。。。 }
从上边代码中我们可以知道:
1)传递给executor的算子(类似MapFunction)的broadcast包装对象就是TorrentBroadcast对象。
2)“Broadcast包装对象”传递给executor时,携带的传递属性包含TorrentBroadcast的broadcastId,numBlocks等(除被@transient修饰外的属性):
在executor端获取值是通过“Broadcast包装对象”#getValue()方法获取值得,driver端传递过去的只是TorrentBroadcast对象的序列化字符串(被task引用的,因此随task而传递[这点可质疑],是不是broadcast有特殊机制对task引用的broadcast对象采用单独传递方式?),当executor端反序列化task时,会把TorrentBroadcast反序列化为对象,通过调用broadcast#getValue()方法获取broadcast的值。
TorrentBroadcast在driver端被序列化时,只能对TorrentBroadcast的非@transient 修饰的属性进行序列化(被@transient修饰的属性不能被序列化),因为TorrentBroadcast的_value是被@transient修饰,所以broadcast的值在driver端并不能被反序列化传递给executor。
这也是实现driver端传递broadcast给executor时,只传递broadcastId,numBlocks等属性(除去_value值外)的真正实现。
3)在executor端,执行map算子时,会调用TorrentBroadcast对象的getVlaue()方法,此时实际上是读取_value=readBroadcastBlock(),也就是尝试从当前executor的blockManager读取,当前executor中读取不到则从当前节点其他executor中获取,如果还是获取不到则从远程driver读取。
断点监控结果截图:
参考
《spark2原理分析-广播变量(Broadcast Variables)的实现原理》
《SparkSQL中的三种Join及其具体实现(broadcast join、shuffle hash join和sort merge join)》
基础才是编程人员应该深入研究的问题,比如:
1)List/Set/Map内部组成原理|区别
2)mysql索引存储结构&如何调优/b-tree特点、计算复杂度及影响复杂度的因素。。。
3)JVM运行组成与原理及调优
4)Java类加载器运行原理
5)Java中GC过程原理|使用的回收算法原理
6)Redis中hash一致性实现及与hash其他区别
7)Java多线程、线程池开发、管理Lock与Synchroined区别
8)Spring IOC/AOP 原理;加载过程的。。。
【+加关注】。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号