
Spark2.x(五十五):在spark structured streaming下sink file(parquet,csv等),正常运行一段时间后:清理掉checkpoint,重新启动app,无法sink记录(file)到hdfs。
场景:
在spark structured streaming读取kafka上的topic,然后将统计结果写入到hdfs,hdfs保存目录按照month,day,hour进行分区:
1)程序放到spark上使用yarn开始运行(yarn-client或yarn-cluster),可以正常sink结果到目录下(分配了executor,executor上有task分配,hdfs有结果输出);
2)程序出现问题,然后修改bug,将checkpoint删除了(为了重新消费kafka的topic上的数据),hdfs sink hdfs结果目录不清理,此时问题出现了:程序启动起来后,一直在触发批次,通过查看日志“Monitoring Streaming Queries-》Metrics”信息发现topic的offset随着批次触发增加偏移位置也在增加,并成功commit,记录offset到checkpoint下。但是一直未DAGScheduler划分stage、提交stage、提交任务。
3)短时间测试发现:executor在任务提交成功后,成功分配了executor,但是executor一直未分配任何任务;
4)长时间测试发现:2019-07-25 00:00:00开始提交任务,在2019-07-25 03:06:00开始执行代码解析,DAGScheduler划分stage、提交stage、提交任务。
程序如下:
//输出2个文件 Dataset<Row> dataset = this.sparkSession.readStream().format("kafka") .options(this.getSparkKafkaCommonOptions(sparkSession)) //读取spark-testapp.conf,自定义配置信息。 .option("kafka.bootstrap.servers", "192.168.1.1:9092,192.168.1.2:9092") .option("subscribe", "myTopic1,myTopic2") .option("startingOffsets", "earliest") .load(); String mdtTempView = "mdtbasetemp"; ExpressionEncoder<Row> Rowencoder = this.getSchemaEncoder(new Schema.Parser().parse(baseschema.getValue())); Dataset<Row> parseVal = dataset.select("value").as(Encoders.BINARY()) .map(new MapFunction<Row>(){ .... }, Rowencoder) .createOrReplaceGlobalTempView(mdtTempView); Dataset<Row> queryResult = this.sparkSession.sql("select 。。。 from global_temp." + mdtTempView + " where start_time<>\"\""); /*输出路径*/ String outputPath = "/user/dx/streaming/data/testapp"; String checkpointLocation= "/user/dx/streaming/checkpoint/testapp"; // Sink方法1: StreamingQuery query = queryResult.writeStream().format("parquet") .option("path", outputPath) .option("checkpointLocation", checkpointLocation) .partitionBy("month", "day", "hour") .outputMode(OutputMode.Append()) .trigger(Trigger.ProcessingTime(1, TimeUnit.MINUTES)) .start(); try { query.awaitTermination(); } catch (StreamingQueryException e) { e.printStackTrace(); }
长时间执行日志:
程序在00:00左右开始提交,分配executor,然后开始读取kafka数据,开始多次触发批次,在03:06开始生成自行代码,DAGScheduler划分stage、提交stage、提交task到executor,回落正常情况。
...... 9/07/25 03:05:00 INFO internals.Fetcher: [Consumer clientId=consumer-1, groupId=spark-kafka-source-032985c5-b382-41ab-a115-ec44d9ba26bc-462898594-driver-0] Resetting offset for partition myTopic-97 to offset 147327. 19/07/25 03:05:00 INFO internals.Fetcher: [Consumer clientId=consumer-1, groupId=spark-kafka-source-032985c5-b382-41ab-a115-ec44d9ba26bc-462898594-driver-0] Resetting offset for partition myTopic-101 to offset 147329. 19/07/25 03:05:00 INFO internals.Fetcher: [Consumer clientId=consumer-1, groupId=spark-kafka-source-032985c5-b382-41ab-a115-ec44d9ba26bc-462898594-driver-0] Resetting offset for partition myTopic-37 to offset 147327. 19/07/25 03:05:00 INFO streaming.CheckpointFileManager: Writing atomically to hdfs://hadoop7:8020/user/dx/streaming/checkpoint/testapp/offsets/202 using temp file hdfs://hadoop7:8020/user/dx/streaming/checkpoint/testapp/offsets/.202.22f580ca-bfb3-422d-9e45-d83186088b42.tmp 19/07/25 03:05:00 INFO streaming.CheckpointFileManager: Renamed temp file hdfs://hadoop7:8020/user/dx/streaming/checkpoint/testapp/offsets/.202.22f580ca-bfb3-422d-9e45-d83186088b42.tmp to hdfs://hadoop7:8020/user/dx/streaming/checkpoint/testapp/offsets/202 19/07/25 03:05:00 INFO streaming.MicroBatchExecution: Committed offsets for batch 202. Metadata OffsetSeqMetadata(0,1563995100011,Map(spark.sql.streaming.stateStore.providerClass -> org.apache.spark.sql.execution.streaming.state.HDFSBackedStateStoreProvider, spark.sql.streaming.flatMapGroupsWithState.stateFormatVersion -> 2, spark.sql.streaming.multipleWatermarkPolicy -> min, spark.sql.streaming.aggregation.stateFormatVersion -> 2, spark.sql.shuffle.partitions -> 100)) 19/07/25 03:05:00 INFO kafka010.KafkaMicroBatchReader: Partitions added: Map() 19/07/25 03:05:00 INFO streaming.FileStreamSink: Skipping already committed batch 202 19/07/25 03:05:00 INFO streaming.CheckpointFileManager: Renamed temp file hdfs://hadoop7:8020/user/dx/streaming/checkpoint/testapp/commits/.202.0cb8f1ad-7b00-46fd-b65f-7bf055eda4ae.tmp to hdfs://hadoop7:8020/user/dx/streaming/checkpoint/testapp/commits/202 Trigger load count accumulator value: 192 19/07/25 03:05:00 INFO streaming.MicroBatchExecution: #这里实际上两个topic,我只摘取了一个topic的metrics Streaming query made progress: { "id" : "c5537e0c-979d-4575-b4d2-1f8a746d2673", "runId" : "d7c5a8f6-e876-45c4-8a02-984045e031ec", "name" : null, "timestamp" : "2019-07-24T19:05:00.000Z", "batchId" : 202, "numInputRows" : 0, "inputRowsPerSecond" : 0.0, "processedRowsPerSecond" : 0.0, "durationMs" : { "addBatch" : 52, "getBatch" : 1, "getEndOffset" : 1, "queryPlanning" : 319, "setOffsetRange" : 10, "triggerExecution" : 486, "walCommit" : 67 }, "stateOperators" : [ ], "sources" : [ { "description" : "KafkaV2[Subscribe[myTopic-2]]", "startOffset" : { "myTopic-2" : { ...... "6" : 146978, "0" : 146978 } }, "endOffset" : { "myTopic-2" : { ...... "6" : 147329, "0" : 147329 } }, "numInputRows" : 0, "inputRowsPerSecond" : 0.0, "processedRowsPerSecond" : 0.0 } ], "sink" : { "description" : "FileSink[/user/dx/streaming/data/testapp]" } } .... 19/07/25 03:06:00 INFO internals.Fetcher: [Consumer clientId=consumer-1, groupId=spark-kafka-source-032985c5-b382-41ab-a115-ec44d9ba26bc-462898594-driver-0] Resetting offset for partition myTopic-2 to offset 147659. 19/07/25 03:06:00 INFO internals.Fetcher: [Consumer clientId=consumer-1, groupId=spark-kafka-source-032985c5-b382-41ab-a115-ec44d9ba26bc-462898594-driver-0] Resetting offset for partition myTopic-66 to offset 147662. 19/07/25 03:06:00 INFO streaming.CheckpointFileManager: Writing atomically to hdfs://hadoop7:8020/user/dx/streaming/checkpoint/testapp/offsets/203 using temp file hdfs://hadoop7:8020/user/dx/streaming/checkpoint/testapp/offsets/.203.72235ff6-aa6d-4e8f-b924-888335fe2035.tmp 19/07/25 03:06:00 INFO streaming.CheckpointFileManager: Renamed temp file hdfs://hadoop7:8020/user/dx/streaming/checkpoint/testapp/offsets/.203.72235ff6-aa6d-4e8f-b924-888335fe2035.tmp to hdfs://hadoop7:8020/user/dx/streaming/checkpoint/testapp/offsets/203 19/07/25 03:06:00 INFO streaming.MicroBatchExecution: Committed offsets for batch 203. Metadata OffsetSeqMetadata(0,1563995160011,Map(spark.sql.streaming.stateStore.providerClass -> org.apache.spark.sql.execution.streaming.state.HDFSBackedStateStoreProvider, spark.sql.streaming.flatMapGroupsWithState.stateFormatVersion -> 2, spark.sql.streaming.multipleWatermarkPolicy -> min, spark.sql.streaming.aggregation.stateFormatVersion -> 2, spark.sql.shuffle.partitions -> 100)) 19/07/25 03:06:00 INFO kafka010.KafkaMicroBatchReader: Partitions added: Map() 19/07/25 03:06:00 INFO parquet.ParquetFileFormat: Using default output committer for Parquet: parquet.hadoop.ParquetOutputCommitter 19/07/25 03:06:01 INFO codegen.CodeGenerator: Code generated in 316.896471 ms 19/07/25 03:06:01 INFO spark.SparkContext: Starting job: start at MdtStreamDriver.java:184 19/07/25 03:06:01 INFO scheduler.DAGScheduler: Got job 0 (start at MdtStreamDriver.java:184) with 128 output partitions 19/07/25 03:06:01 INFO scheduler.DAGScheduler: Final stage: ResultStage 0 (start at MdtStreamDriver.java:184) 19/07/25 03:06:01 INFO scheduler.DAGScheduler: Parents of final stage: List() 19/07/25 03:06:01 INFO scheduler.DAGScheduler: Missing parents: List() 19/07/25 03:06:01 INFO scheduler.DAGScheduler: Submitting ResultStage 0 (MapPartitionsRDD[7] at start at MdtStreamDriver.java:184), which has no missing parents 19/07/25 03:06:02 INFO memory.MemoryStore: Block broadcast_4 stored as values in memory (estimated size 255.5 KB, free 5.6 GB) 19/07/25 03:06:02 INFO memory.MemoryStore: Block broadcast_4_piece0 stored as bytes in memory (estimated size 84.7 KB, free 5.6 GB) 19/07/25 03:06:02 INFO storage.BlockManagerInfo: Added broadcast_4_piece0 in memory on hadoop7:35113 (size: 84.7 KB, free: 6.2 GB) 19/07/25 03:06:02 INFO spark.SparkContext: Created broadcast 4 from broadcast at DAGScheduler.scala:1161 19/07/25 03:06:02 INFO scheduler.DAGScheduler: Submitting 128 missing tasks from ResultStage 0 (MapPartitionsRDD[7] at start at MdtStreamDriver.java:184) (first 15 tasks are for partitions Vector(0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14)) 19/07/25 03:06:02 INFO cluster.YarnScheduler: Adding task set 0.0 with 128 tasks 19/07/25 03:06:02 INFO scheduler.TaskSetManager: Starting task 11.0 in stage 0.0 (TID 0, hadoop6, executor 6, partition 11, PROCESS_LOCAL, 8821 bytes) 19/07/25 03:06:02 INFO scheduler.TaskSetManager: Starting task 6.0 in stage 0.0 (TID 1, hadoop6, executor 2, partition 6, PROCESS_LOCAL, 8821 bytes) 19/07/25 03:06:02 INFO scheduler.TaskSetManager: Starting task 21.0 in stage 0.0 (TID 2, hadoop37, executor 9, partition 21, PROCESS_LOCAL, 8822 bytes) 19/07/25 03:06:02 INFO scheduler.TaskSetManager: Starting task 2.0 in stage 0.0 (TID 3, hadoop37, executor 10, partition 2, PROCESS_LOCAL, 8823 bytes) 19/07/25 03:06:02 INFO scheduler.TaskSetManager: Starting task 0.0 in stage 0.0 (TID 4, hadoop6, executor 1, partition 0, PROCESS_LOCAL, 8821 bytes) 19/07/25 03:06:02 INFO scheduler.TaskSetManager: Starting task 7.0 in stage 0.0 (TID 5, hadoop6, executor 3, partition 7, PROCESS_LOCAL, 8821 bytes) 19/07/25 03:06:02 INFO scheduler.TaskSetManager: Starting task 4.0 in stage 0.0 (TID 6, hadoop6, executor 4, partition 4, PROCESS_LOCAL, 8821 bytes) 19/07/25 03:06:02 INFO scheduler.TaskSetManager: Starting task 1.0 in stage 0.0 (TID 7, hadoop37, executor 8, partition 1, PROCESS_LOCAL, 8822 bytes) 19/07/25 03:06:02 INFO scheduler.TaskSetManager: Starting task 3.0 in stage 0.0 (TID 8, hadoop37, executor 7, partition 3, PROCESS_LOCAL, 8822 bytes) 19/07/25 03:06:02 INFO scheduler.TaskSetManager: Starting task 5.0 in stage 0.0 (TID 9, hadoop6, executor 5, partition 5, PROCESS_LOCAL, 8821 bytes) 19/07/25 03:06:02 INFO scheduler.TaskSetManager: Starting task 41.0 in stage 0.0 (TID 10, hadoop6, executor 6, partition 41, PROCESS_LOCAL, 8821 bytes) 19/07/25 03:06:02 INFO scheduler.TaskSetManager: Starting task 31.0 in stage 0.0 (TID 11, hadoop6, executor 2, partition 31, PROCESS_LOCAL, 8821 bytes) 19/07/25 03:06:02 INFO scheduler.TaskSetManager: Starting task 27.0 in stage 0.0 (TID 12, hadoop37, executor 9, partition 27, PROCESS_LOCAL, 8822 bytes) 19/07/25 03:06:02 INFO scheduler.TaskSetManager: Starting task 12.0 in stage 0.0 (TID 13, hadoop37, executor 10, partition 12, PROCESS_LOCAL, 8823 bytes) 19/07/25 03:06:02 INFO scheduler.TaskSetManager: Starting task 9.0 in stage 0.0 (TID 14, hadoop6, executor 1, partition 9, PROCESS_LOCAL, 8821 bytes) 19/07/25 03:06:02 INFO scheduler.TaskSetManager: Starting task 19.0 in stage 0.0 (TID 15, hadoop6, executor 3, partition 19, PROCESS_LOCAL, 8821 bytes) 19/07/25 03:06:02 INFO scheduler.TaskSetManager: Starting task 23.0 in stage 0.0 (TID 16, hadoop6, executor 4, partition 23, PROCESS_LOCAL, 8821 bytes) 19/07/25 03:06:02 INFO scheduler.TaskSetManager: Starting task 8.0 in stage 0.0 (TID 17, hadoop37, executor 8, partition 8, PROCESS_LOCAL, 8822 bytes) 19/07/25 03:06:02 INFO scheduler.TaskSetManager: Starting task 20.0 in stage 0.0 (TID 18, hadoop37, executor 7, partition 20, PROCESS_LOCAL, 8822 bytes) 19/07/25 03:06:02 INFO scheduler.TaskSetManager: Starting task 10.0 in stage 0.0 (TID 19, hadoop6, executor 5, partition 10, PROCESS_LOCAL, 8821 bytes) 19/07/25 03:06:02 INFO scheduler.TaskSetManager: Starting task 42.0 in stage 0.0 (TID 20, hadoop6, executor 6, partition 42, PROCESS_LOCAL, 8821 bytes) 19/07/25 03:06:02 INFO scheduler.TaskSetManager: Starting task 39.0 in stage 0.0 (TID 21, hadoop6, executor 2, partition 39, PROCESS_LOCAL, 8821 bytes) 19/07/25 03:06:02 INFO scheduler.TaskSetManager: Starting task 53.0 in stage 0.0 (TID 22, hadoop37, executor 9, partition 53, PROCESS_LOCAL, 8822 bytes) 19/07/25 03:06:02 INFO scheduler.TaskSetManager: Starting task 29.0 in stage 0.0 (TID 23, hadoop37, executor 10, partition 29, PROCESS_LOCAL, 8823 bytes) 19/07/25 03:06:02 INFO scheduler.TaskSetManager: Starting task 15.0 in stage 0.0 (TID 24, hadoop6, executor 1, partition 15, PROCESS_LOCAL, 8821 bytes) 19/07/25 03:06:02 INFO scheduler.TaskSetManager: Starting task 26.0 in stage 0.0 (TID 25, hadoop6, executor 3, partition 26, PROCESS_LOCAL, 8821 bytes) 19/07/25 03:06:02 INFO scheduler.TaskSetManager: Starting task 32.0 in stage 0.0 (TID 26, hadoop6, executor 4, partition 32, PROCESS_LOCAL, 8821 bytes) 19/07/25 03:06:02 INFO scheduler.TaskSetManager: Starting task 13.0 in stage 0.0 (TID 27, hadoop37, executor 8, partition 13, PROCESS_LOCAL, 8822 bytes) 19/07/25 03:06:02 INFO scheduler.TaskSetManager: Starting task 22.0 in stage 0.0 (TID 28, hadoop37, executor 7, partition 22, PROCESS_LOCAL, 8822 bytes) 19/07/25 03:06:02 INFO scheduler.TaskSetManager: Starting task 16.0 in stage 0.0 (TID 29, hadoop6, executor 5, partition 16, PROCESS_LOCAL, 8821 bytes) 19/07/25 03:06:02 INFO storage.BlockManagerInfo: Added broadcast_4_piece0 in memory on hadoop37:49766 (size: 84.7 KB, free: 4.6 GB) 19/07/25 03:06:02 INFO storage.BlockManagerInfo: Added broadcast_4_piece0 in memory on hadoop37:59401 (size: 84.7 KB, free: 4.6 GB) 19/07/25 03:06:02 INFO storage.BlockManagerInfo: Added broadcast_4_piece0 in memory on hadoop37:39051 (size: 84.7 KB, free: 4.6 GB) 19/07/25 03:06:02 INFO storage.BlockManagerInfo: Added broadcast_4_piece0 in memory on hadoop37:53105 (size: 84.7 KB, free: 4.6 GB) 19/07/25 03:06:02 INFO storage.BlockManagerInfo: Added broadcast_4_piece0 in memory on hadoop6:60796 (size: 84.7 KB, free: 4.6 GB) 19/07/25 03:06:02 INFO storage.BlockManagerInfo: Added broadcast_4_piece0 in memory on hadoop6:40022 (size: 84.7 KB, free: 4.6 GB) 19/07/25 03:06:02 INFO storage.BlockManagerInfo: Added broadcast_4_piece0 in memory on hadoop6:37348 (size: 84.7 KB, free: 4.6 GB) 19/07/25 03:06:02 INFO storage.BlockManagerInfo: Added broadcast_4_piece0 in memory on hadoop6:40556 (size: 84.7 KB, free: 4.6 GB) 19/07/25 03:06:02 INFO storage.BlockManagerInfo: Added broadcast_4_piece0 in memory on hadoop6:58914 (size: 84.7 KB, free: 4.6 GB) 19/07/25 03:06:02 INFO storage.BlockManagerInfo: Added broadcast_4_piece0 in memory on hadoop6:38491 (size: 84.7 KB, free: 4.6 GB) 19/07/25 03:06:07 INFO storage.BlockManagerInfo: Added broadcast_1_piece0 in memory on hadoop37:49766 (size: 1527.0 B, free: 4.6 GB) 19/07/25 03:06:07 INFO storage.BlockManagerInfo: Added broadcast_0_piece0 in memory on hadoop37:49766 (size: 1527.0 B, free: 4.6 GB) 19/07/25 03:06:07 INFO scheduler.TaskSetManager: Starting task 33.0 in stage 0.0 (TID 30, hadoop37, executor 7, partition 33, PROCESS_LOCAL, 8822 bytes) 19/07/25 03:06:07 INFO scheduler.TaskSetManager: Starting task 40.0 in stage 0.0 (TID 31, hadoop37, executor 7, partition 40, PROCESS_LOCAL, 8822 bytes) 19/07/25 03:06:07 INFO scheduler.TaskSetManager: Starting task 49.0 in stage 0.0 (TID 32, hadoop37, executor 7, partition 49, PROCESS_LOCAL, 8822 bytes)
其中代码中一个比较重要的日志:
19/07/25 03:05:00 INFO streaming.FileStreamSink: Skipping already committed batch 202
上边代码包含两个批次的触发:
触发时刻1):“19/07/25 03:05:00”成功分配task之前的空触发(未分配task的最后一次触发,这是一次错误的出发批次。注意的:实际上每次错误触发批次中都包含上边红色日志“INFO streaming.FileStreamSink: Skipping already committed batch $batchId”
触发时刻2):“19/07/25 03:06:00”这批触发可以从上边日志清晰看到,生成了执行代码,DAGScheduler成功划分了stage、提交stage、提交task、executor中开始运行task等信息。这是一次正常的触发批次。
问题解决:
方案1)(采用foreachBatch方式来sink file替换):
经过测试发现如果把最后sink的format修改为console方式,每次都可以正常触发,第一次触发就分配stage,给executor分配了task;如果把sink file的format设置为csv、parquet就不能正常触发,猜测是触发方式的问题:修改触发方式为foreachBatch。
// Sink方法2: /**.repartition(1) 可以考虑加上,能避免小文件,repartition越小,小文件相对会少,但是性能会差点。*/ StreamingQuery query = queryResult.writeStream() .option("checkpointLocation", checkpointLocation) .foreachBatch(new VoidFunction2<Dataset<Row>,Long>(){ private static final long serialVersionUID = 2689158908273637554L; @Override public void call(Dataset<Row> v1, Long v2) throws Exception { v1.write().partitionBy("month", "day", "hour").mode(SaveMode.Append).save(outputPath); }}) .outputMode(OutputMode.Append()) .trigger(Trigger.ProcessingTime(1, TimeUnit.MINUTES)) .start();
经过多次测试发现,问题确实解决了。但是上边那种sink file(parquet/csv)方式也是官方推出的,不应该有bug、
方案2)(未验证):
上边日志中“INFO streaming.FileStreamSink: Skipping already committed batch $batchId”这个信息很重要,这个日志每次未正常sink数据到hdfs的触发打印日志中都有打印,这个日志是org/apache/spark/sql/execution/streaming/FileStreamSink.scala的108行代码(spark2.4)中出现输出的。
/** * A sink that writes out results to parquet files. Each batch is written out to a unique * directory. After all of the files in a batch have been successfully written, the list of * file paths is appended to the log atomically. In the case of partial failures, some duplicate * data may be present in the target directory, but only one copy of each file will be present * in the log. */ class FileStreamSink( sparkSession: SparkSession, path: String, fileFormat: FileFormat, partitionColumnNames: Seq[String], options: Map[String, String]) extends Sink with Logging { private val basePath = new Path(path) private val logPath = new Path(basePath, FileStreamSink.metadataDir) private val fileLog = new FileStreamSinkLog(FileStreamSinkLog.VERSION, sparkSession, logPath.toUri.toString) private val hadoopConf = sparkSession.sessionState.newHadoopConf() private def basicWriteJobStatsTracker: BasicWriteJobStatsTracker = { val serializableHadoopConf = new SerializableConfiguration(hadoopConf) new BasicWriteJobStatsTracker(serializableHadoopConf, BasicWriteJobStatsTracker.metrics) } override def addBatch(batchId: Long, data: DataFrame): Unit = { if (batchId <= fileLog.getLatest().map(_._1).getOrElse(-1L)) { logInfo(s"Skipping already committed batch $batchId") } else { val committer = FileCommitProtocol.instantiate( className = sparkSession.sessionState.conf.streamingFileCommitProtocolClass, jobId = batchId.toString, outputPath = path) committer match { case manifestCommitter: ManifestFileCommitProtocol => manifestCommitter.setupManifestOptions(fileLog, batchId) case _ => // Do nothing } // Get the actual partition columns as attributes after matching them by name with // the given columns names. val partitionColumns: Seq[Attribute] = partitionColumnNames.map { col => val nameEquality = data.sparkSession.sessionState.conf.resolver data.logicalPlan.output.find(f => nameEquality(f.name, col)).getOrElse { throw new RuntimeException(s"Partition column $col not found in schema ${data.schema}") } } val qe = data.queryExecution FileFormatWriter.write( sparkSession = sparkSession, plan = qe.executedPlan, fileFormat = fileFormat, committer = committer, outputSpec = FileFormatWriter.OutputSpec(path, Map.empty, qe.analyzed.output), hadoopConf = hadoopConf, partitionColumns = partitionColumns, bucketSpec = None, statsTrackers = Seq(basicWriteJobStatsTracker), options = options) } } override def toString: String = s"FileSink[$path]" }
从上边代码可以确定代码中做了特殊处理:当前batchId小于当日志中记录的最新的batchId时,将不触发写入信息到hdfs中,只是打印了这个“Skipping already committed batch $batchId”
上边日志是保存到sink file的path下的,猜测是保存到了path/_spark_metadata下了。
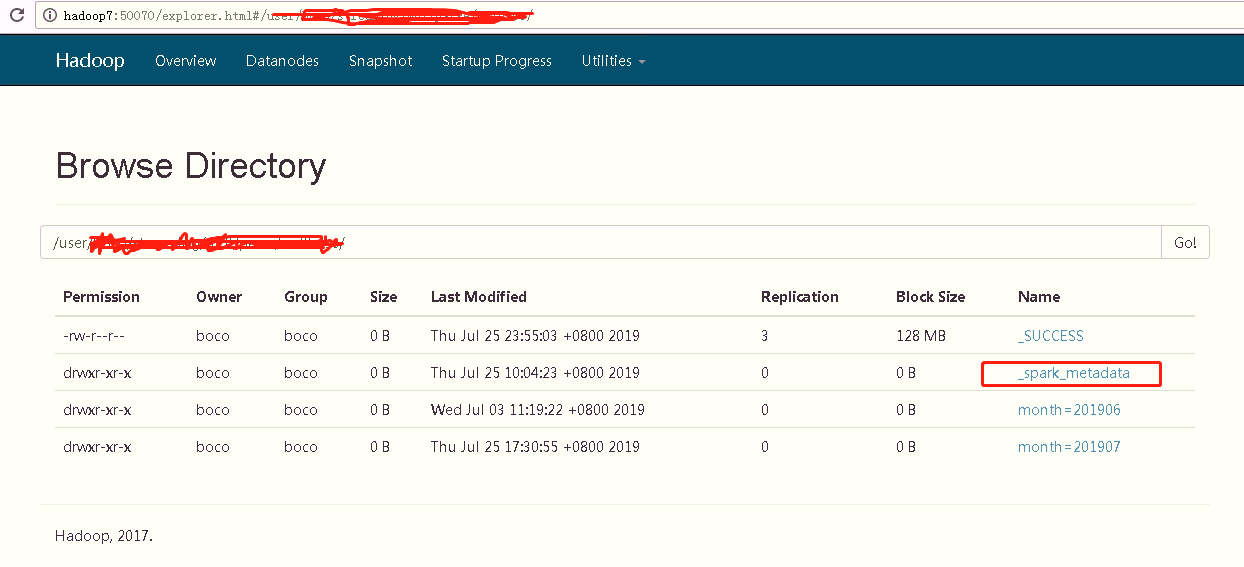
如果重新执行时,删除了checkpoint,应该也必须删除sink file的保存hdfs目录下的日志,日志中保存batchId信息,删除batchId日志信息才能从头开始触发,按照代码分析应该是这么一个原因,但是还未验证。
基础才是编程人员应该深入研究的问题,比如:
1)List/Set/Map内部组成原理|区别
2)mysql索引存储结构&如何调优/b-tree特点、计算复杂度及影响复杂度的因素。。。
3)JVM运行组成与原理及调优
4)Java类加载器运行原理
5)Java中GC过程原理|使用的回收算法原理
6)Redis中hash一致性实现及与hash其他区别
7)Java多线程、线程池开发、管理Lock与Synchroined区别
8)Spring IOC/AOP 原理;加载过程的。。。
【+加关注】。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号