
Spark2.2(三十九):如何根据appName监控spark任务,当任务不存在则启动(任务存在当超过多久没有活动状态则kill,等待下次启动)
业务需求
实现一个根据spark任务的appName来监控任务是否存在,及任务是否卡死的监控。
1)给定一个appName,根据appName从yarn application -list中验证任务是否存在,不存在则调用spark-submit.sh脚本来启动任务;
2)如果任务存在yarn application -list中,则读取‘监控文件(监控文件内容包括:appId,最新活动时间)’,从监控文件中读取出最后活动的日期,计算当前日期与app的最后活动日期相差时间为X,如果X大于30minutes(认为任务处于假死状态[再发布环境发现有的任务DAG抛出OOM,导致app的executor和driver依然存在,当时不执行任务调度,程序卡死。具体错误详情请参考《https://issues.apache.org/jira/browse/SPARK-26452》]),则执行yarn application -kill appId(杀掉任务),等待下次监控脚本执行时重启任务。
监控实现
脚本
#/bin/sh #LANG=zh_CN.utf8 #export LANG export SPARK_KAFKA_VERSION=0.10 export LANG=zh_CN.UTF-8 # export env variable if [ -f ~/.bash_profile ]; then source ~/.bash_profile fi source /etc/profile myAppName='myBatchTopic' #这里指定需要监控的spark任务的appName,注意:这名字重复了会导致监控失败。 apps='' for app in `yarn application -list` do apps=${app},$apps done apps=${apps%?} if [[ $apps =~ $myAppName ]]; then echo "appName($myAppName) exists in yarn application list" #1)运行 hadop fs -cat /目录/appName,读取其中最后更新日期;(如果文件不存在,则跳过等待文件生成。) monitorInfo=$(hadoop fs -cat /user/dx/streaming/monitor/${myAppName}) LD_IFS="$IFS" IFS="," array=($monitorInfo) IFS="$OLD_IFS" appId=${array[0]} monitorLastDate=${array[1]} echo "loading mintor information 'appId:$appId,monitorLastUpdateDate:$monitorLastDate'" current_date=$(date "+%Y-%m-%d %H:%M:%S") echo "loading current date '$current_date'" #2)与当前日期对比: # 如果距离当前日期相差小于30min,则不做处理; # 如果大于30min则kill job,根据上边yarn application -list中能获取对应的appId,运行yarn application -kill appId t1=`date -d "$current_date" +%s` t2=`date -d "$monitorLastDate" +%s` diff_minute=$(($(($t1-$t2))/60)) echo "current date($current_date) over than monitorLastDate($monitorLastDate) $diff_minute minutes" if [ $diff_minute -gt 30 ]; then echo 'over then 30 minutes' $(yarn application -kill ${appId}) echo "kill application ${appId}" else echo 'less than 30 minutes' fi else echo "appName($myAppName) not exists in yarn application list" #./submit_x1_x2.sh abc TestRestartDriver #这里指定需要启动的脚本来启动相关任务 $(nohup ./submit_checkpoint2.sh >> ./output.log 2>&1 &) fi
监控脚本业务流程图:
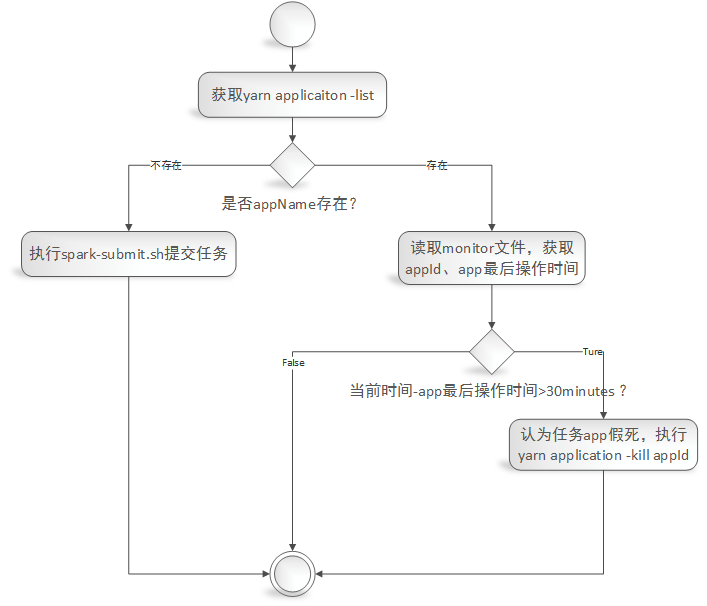
监控文件生成
我这里程序是spark structured streaming,因此可以注册sparkSesssion的streams()的query的监听事件
sparkSession.streams().addListener(new GlobalStreamingQueryListener(sparkSession。。。))
在监听事件中实现如下:
public class GlobalStreamingQueryListener extends StreamingQueryListener { private static final org.slf4j.Logger logger = org.slf4j.LoggerFactory.getLogger(GlobalStreamingQueryListener.class); private static final String monitorBaseDir = "/user/dx/streaming/monitor/"; private SparkSession sparkSession = null; private LongAccumulator triggerAccumulator = null; public GlobalStreamingQueryListener(SparkSession sparkSession, LongAccumulator triggerAccumulator) { this.sparkSession = sparkSession; this.triggerAccumulator = triggerAccumulator; } @Override public void onQueryStarted(QueryStartedEvent queryStarted) { System.out.println("Query started: " + queryStarted.id()); } @Override public void onQueryTerminated(QueryTerminatedEvent queryTerminated) { System.out.println("Query terminated: " + queryTerminated.id()); } @Override public void onQueryProgress(QueryProgressEvent queryProgress) { System.out.println("Query made progress: " + queryProgress.progress()); // sparkSession.sql("select * from " + // queryProgress.progress().name()).show(); triggerAccumulator.add(1); System.out.println("Trigger accumulator value: " + triggerAccumulator.value()); logger.info("minitor start .... "); try { if (HDFSUtility.createDir(monitorBaseDir)) { logger.info("Create monitor base dir(" + monitorBaseDir + ") success"); } else { logger.info("Create monitor base dir(" + monitorBaseDir + ") fail"); } } catch (IOException e) { logger.error("An error was thrown while create monitor base dir(" + monitorBaseDir + ")"); e.printStackTrace(); } // spark.app.id application_1543820999543_0193 String appId = this.sparkSession.conf().get("spark.app.id"); // spark.app.name myBatchTopic String appName = this.sparkSession.conf().get("spark.app.name"); String mintorFilePath = (monitorBaseDir.endsWith(File.separator) ? monitorBaseDir : monitorBaseDir + File.separator) + appName; logger.info("The application's id is " + appId); logger.info("The application's name is " + appName); logger.warn("If the appName is not unique,it will result in a monitor error"); try { HDFSUtility.overwriter(mintorFilePath, appId + "," + new SimpleDateFormat("yyyy-MM-dd HH:mm:ss").format(new Date())); } catch (IOException e) { logger.error("An error was thrown while write info to monitor file(" + mintorFilePath + ")"); e.printStackTrace(); } logger.info("minitor stop .... "); } }
HDFSUtility.java中方法如下:
public class HDFSUtility { private static final org.slf4j.Logger logger = org.slf4j.LoggerFactory.getLogger(HDFSUtility.class); /** * 当目录不存在时,创建目录。 * * @param dirPath * 目标目录 * @return true-創建成功;false-失敗。 * @throws IOException * */ public static boolean createDir(String dirPath) throws IOException { FileSystem fs = null; Path dir = new Path(dirPath); boolean success = false; try { fs = FileSystem.get(new Configuration()); if (!fs.exists(dir)) { success = fs.mkdirs(dir); } else { success = true; } } catch (IOException e) { logger.error("create dir (" + dirPath + ") fail:", e); throw e; } finally { try { fs.close(); } catch (IOException e) { e.printStackTrace(); } } return success; } /** * 覆盖文件写入信息 * * @param filePath * 目标文件路径 * @param content * 被写入内容 * @throws IOException * */ public static void overwriter(String filePath, String content) throws IOException { FileSystem fs = null; // 在指定路径创建FSDataOutputStream。默认情况下会覆盖文件。 FSDataOutputStream outputStream = null; Path file = new Path(filePath); try { fs = FileSystem.get(new Configuration()); if (fs.exists(file)) { System.out.println("File exists(" + filePath + ")"); } outputStream = fs.create(file); outputStream.write(content.getBytes()); } catch (IOException e) { logger.error("write into file(" + filePath + ") fail:", e); throw e; } finally { if (outputStream != null) { try { outputStream.close(); } catch (IOException e) { e.printStackTrace(); } } try { fs.close(); } catch (IOException e) { e.printStackTrace(); } } } }
基础才是编程人员应该深入研究的问题,比如:
1)List/Set/Map内部组成原理|区别
2)mysql索引存储结构&如何调优/b-tree特点、计算复杂度及影响复杂度的因素。。。
3)JVM运行组成与原理及调优
4)Java类加载器运行原理
5)Java中GC过程原理|使用的回收算法原理
6)Redis中hash一致性实现及与hash其他区别
7)Java多线程、线程池开发、管理Lock与Synchroined区别
8)Spring IOC/AOP 原理;加载过程的。。。
【+加关注】。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号