Hive中的Join总结
Join语句
Hive支持通常的SQL JOIN语句,但是只支持等值连接,不支持非等值连接。标准的SQL支持非等值连接。
根据员工表和部门表中的部门编号相等,查询员工编号、员工名称和部门名称
select e.empno, e.ename, d.deptno, d.dname from emp e join dept d on e.deptno = d.deptno;
内连接
内连接:只有进行连接的两个表中都存在与连接条件相匹配的数据才会被保留下来。
select e.empno, e.ename, d.deptno from emp e join dept d on e.deptno = d.deptno;
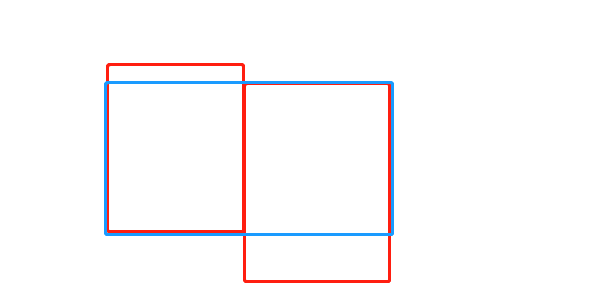
左外连接
左外连接:JOIN操作符左边表中符合WHERE子句的所有记录将会被返回。如果右边表对应字段没有符合条件的值,则会使用NULL值代替。
select e.empno, e.ename, d.deptno from emp e left join dept d on e.deptno = d.deptno;
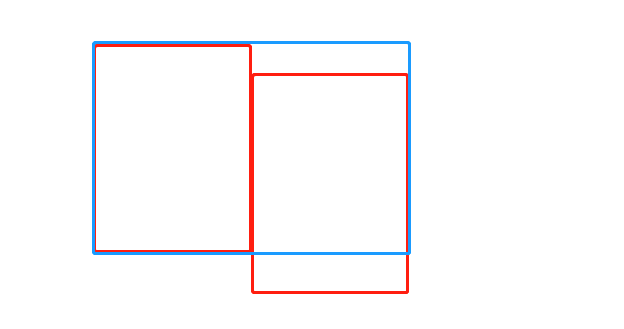
右外连接
右外连接:JOIN操作符右边表中符合WHERE子句的所有记录将会被返回。如果左边表对应字段没有符合条件的值,则会使用NULL值代替。
select e.empno, e.ename, d.deptno from emp e right join dept d on e.deptno = d.deptno;
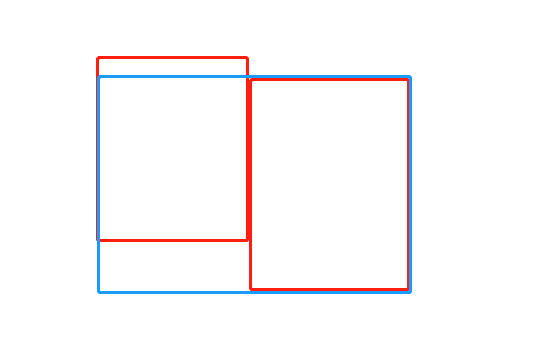
满外连接
满外连接:将会返回所有表中符合WHERE语句条件的所有记录。如果任一表的指定字段没有符合条件的值的话,那么就使用NULL值替代。
select e.empno, e.ename, d.deptno from emp e full join dept d on e.deptno = d.deptno;
如下图所示:

多表连接
注意:连接 n个表,至少需要n-1个连接条件。例如:连接三个表,至少需要两个连接条件。
SELECT e.ename, d.deptno, l. loc_name
FROM emp e
JOIN dept d
ON d.deptno = e.deptno
JOIN location l
ON d.loc = l.loc;
大多数情况下,Hive会对每对JOIN连接对象启动一个MapReduce任务。本例中会首先启动一个MapReduce job对表e和表d进行连接操作,然后会再启动一个MapReduce job将第一个MapReduce job的输出和表l,进行连接操作。
注意:为什么不是表d和表l先进行连接操作呢?这是因为Hive总是按照从左到右的顺序执行的。
当对3个或者更多个表进行Join时,如果每个on子句都使用相同的连接键的话,那么只会产生一个MR Job。
左半开连接
Hive当前没有实现IN/EXISTS子查询,在Hive中可以通过LEFT SEMI JOIN实现IN/EXISTS子查询的处理效果。不过LEFT SEMI JOIN使用时存在一些限制:
1、不能在Where子句中引用到Join子句右边表中的字段;
2、不能在Select子句中引用到Join子句右边表中的字段;
案例演示
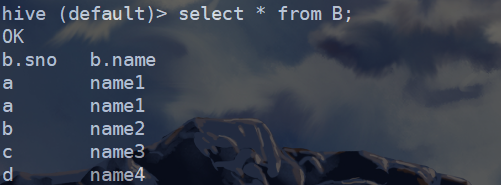
1、创建两个表A和B,其表内容如下:
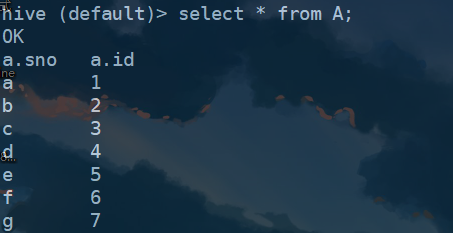
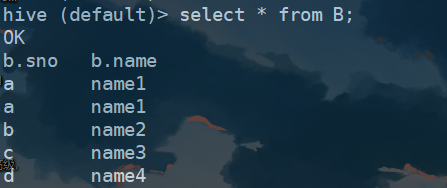
2、先使用内连接,进行查看
select a.sno,a.id,b.name from A a join B b on a.sno=b.sno;
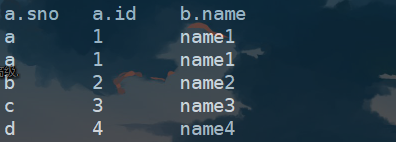
3、再使用左半开连接查看结果
select a.sno,a.id,b.name from A a left semi join B b on a.sno=b.sno;
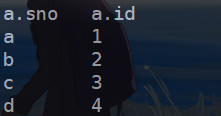
注意在select子句中是不能出现右边表中的字段的,否则会发生错误:

从上面的案例演示中我们可以看出,使用“left semi join”这个连接时,如果在右表中遇到了重复记录,那么左表会跳过,只产生一条连接记录;而对于join来说,则会一直遍历,在右边有重复的记录时会产生多条连接记录。这也是“left semi join”比join更加高效的原因。
map-side Join
如果所有表中只有一张表是小表,那么可以在最大的表通过mapper的时候将小表完全放到内存中。Hive可以在map端执行连接过程,称为map-side Join。这是因为Hive可以和内存中的小表进行逐一匹配,从而省略掉常规连接操作所需要的reduce过程。即使对于很小的数据集,这个优化也明显地快于常规的连接操作。其不仅较少了reduce过程,而且有时还可以同时减少map过程的执行步骤。
开启map-side join的方式,在命令行配置以下参数,就可以开启了,当再次进行join操作的时候,会自动的进行map-side Join:
hive> set hive.auto.convert.join=true
当设置为true的时候,hive会自动获取两张表的数据,判定哪个是小表,然后放在内存中
当然,用户也可以自己配置能够使用map-side Join的小表的大小,配置以下属性即可,其默认是如下所示(单位是字节):
hive.mapjoin.smalltable.filesize=25000000
默认值大小大约是25M,也就是说,当小表的大小小于等于25M的时候,就可以自动开启map-side Join。
Hive对于右外连接和全外连接不支持这个优化。
案例演示
1、首先创建两张表A和B,A中的字段为sno和id,向其插入1000条数据:
create external table if not exists A(sno string,id int) row format delimited fields terminated by '\t';
B中的字段为sno和name,向其插入少许几条数据:
create external table if not exists B(sno string,name string) row format delimited fields terminated by '\t';
2、先将map-side Join关闭,然后将B表作为连接的左表,A表作为右表,然后进行连接,效果如下图所示:
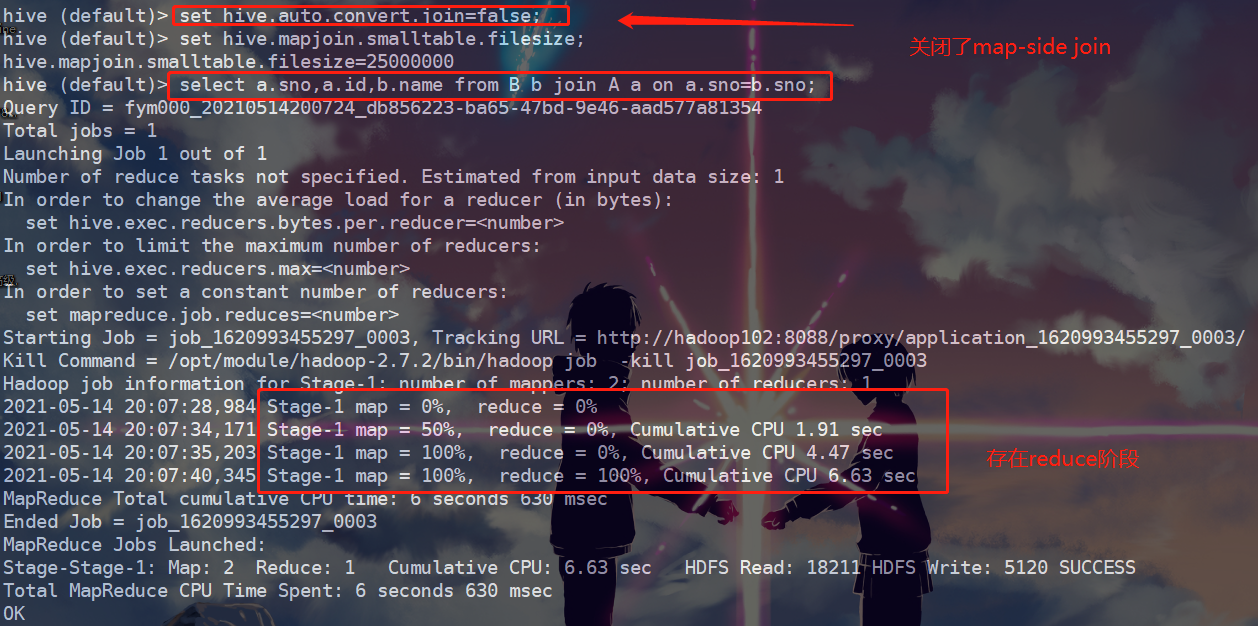
可以看出,关闭map-side Join时,查询语句的执行过程包含了map和reduce两个阶段,执行MR任务一共花费了6.63s的时间。
3、开启map-side Join,然后执行同样的查询语句
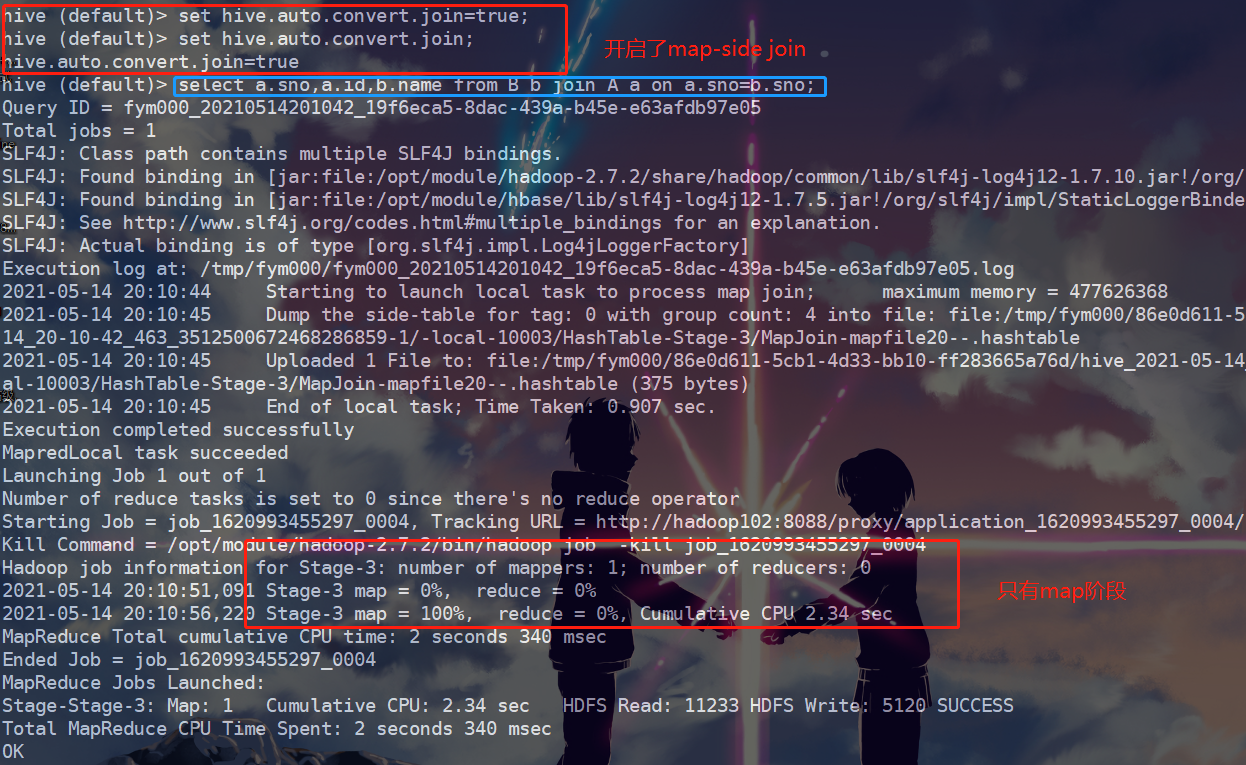
可以看出,开启map-side Join之后,只有map阶段而没有reduce阶段,同时执行MR任务花费的时间只有2.34s,效率得到了很大的提升。
hive1.2.1版本中,map-side join默认情况下是开启的。
笛卡尔积
笛卡尔集会在下面条件下产生
(1)省略连接条件
(2)连接条件无效
(3)所有表中的所有行互相连接
select empno, dname from emp, dept;
连接谓词不支持or
select e.empno, e.ename, d.deptno from emp e join dept d on e.deptno = d.deptno or e.ename=d.ename; 错误的

 浙公网安备 33010602011771号
浙公网安备 33010602011771号