Reduce端分组排序源码分析
一、流程源码分析
在xxxJobRunner类中有一个内部类ReduceTaskRunnable,该类是一个专门执行ReduceTask任务的线程类,其中的run方法就是开始执行reduce任务的方法,在run方法的内部,以下代码标志reduce任务开始执行:
ReduceTask reduce = new ReduceTask(systemJobFile.toString(),
reduceId, taskId, mapIds.size(), 1);
…………
reduce.run(localConf, Job.this);
查看reduce.run内部逻辑,关键在于执行以下代码(该run方法是ReduceTask类中的):
if (useNewApi) {
runNewReducer(job, umbilical, reporter, rIter, comparator,
keyClass, valueClass);
} else {
runOldReducer(job, umbilical, reporter, rIter, comparator,
keyClass, valueClass);
}
执行的是runNewReducer方法,继续查看它的逻辑,其中以下方法就是将分好组的数据一组一组的送入我们自定义的reduce方法中:
reducer.run(reducerContext);
该方法的底层逻辑就是Reducer类的run方法,如下所示:
public void run(Context context) throws IOException, InterruptedException {
setup(context);
try {
while (context.nextKey()) {
reduce(context.getCurrentKey(), context.getValues(), context);
// If a back up store is used, reset it
Iterator<VALUEIN> iter = context.getValues().iterator();
if(iter instanceof ReduceContext.ValueIterator) {
((ReduceContext.ValueIterator<VALUEIN>)iter).resetBackupStore();
}
}
} finally {
cleanup(context);
}
}
在该方法中,通过while循环遍历上下文对象中的key,执行的是nextKey方法,那么继续查看nextKey方法的逻辑是什么样的:
/** Start processing next unique key. */
public boolean nextKey() throws IOException,InterruptedException {
while (hasMore && nextKeyIsSame) {
nextKeyValue();
}
if (hasMore) {
if (inputKeyCounter != null) {
inputKeyCounter.increment(1);
}
return nextKeyValue();
} else {
return false;
}
}
可以看到该方法首先会以while循环的方式调用nextKeyValue方法,循环的条件是"hasMore && nextKeyIsSame",即是否还有数据以及下一个数据的key是否和上一个的相同,如果这两个条件都满足了,那么就会一直循环执行nextKeyValue方法,那么继续查看nextKeyValue方法的源码:
/**
* Advance to the next key/value pair.
*/
@Override
public boolean nextKeyValue() throws IOException, InterruptedException {
if (!hasMore) {
key = null;
value = null;
return false;
}
firstValue = !nextKeyIsSame;
DataInputBuffer nextKey = input.getKey();
currentRawKey.set(nextKey.getData(), nextKey.getPosition(),
nextKey.getLength() - nextKey.getPosition());
buffer.reset(currentRawKey.getBytes(), 0, currentRawKey.getLength());
key = keyDeserializer.deserialize(key);
DataInputBuffer nextVal = input.getValue();
buffer.reset(nextVal.getData(), nextVal.getPosition(), nextVal.getLength()
- nextVal.getPosition());
value = valueDeserializer.deserialize(value);
currentKeyLength = nextKey.getLength() - nextKey.getPosition();
currentValueLength = nextVal.getLength() - nextVal.getPosition();
if (isMarked) {
backupStore.write(nextKey, nextVal);
}
hasMore = input.next();
if (hasMore) {
nextKey = input.getKey();
nextKeyIsSame = comparator.compare(currentRawKey.getBytes(), 0,
currentRawKey.getLength(),
nextKey.getData(),
nextKey.getPosition(),
nextKey.getLength() - nextKey.getPosition()
) == 0;
} else {
nextKeyIsSame = false;
}
inputValueCounter.increment(1);
return true;
}
在该方法中,首先会进行合法性判断,然后判断当前这个键值对中的值是不是当前key所代表的组的第一个值,接着就是将当前的数据存入上下文对象中。
其中继续向下有一段比较重要的代码涉及到了分组排序的操作,即:
hasMore = input.next();
if (hasMore) {
nextKey = input.getKey();
nextKeyIsSame = comparator.compare(currentRawKey.getBytes(), 0,
currentRawKey.getLength(),
nextKey.getData(),
nextKey.getPosition(),
nextKey.getLength() - nextKey.getPosition()
) == 0;
} else {
nextKeyIsSame = false;
}
nextKeyIsSame的值就是依据分组排序的结果来进行的。此处调用的comparator.compare方法,具体实现在于传入的比较器对象中实现的compare方法,那么这个比较器对象是在哪里确定的呢?本着一种不见棺材不落泪,不到南墙不回头的精神继续查看源码:
comparator在Reduce上下文对象ReduceContextImpl中是一个成员变量,其具体的类型是:
private RawComparator<KEYIN> comparator;
它的赋值操作是在ReduceContextImpl的构造方法中完成的,所以要想看谁对它赋的值,需要看谁声明了这个上下文对象,继续看:
在Task类中的createReduceContext方法中声明了ReduceContextImpl,并进行了初始化
protected static <INKEY,INVALUE,OUTKEY,OUTVALUE>
org.apache.hadoop.mapreduce.Reducer<INKEY,INVALUE,OUTKEY,OUTVALUE>.Context
createReduceContext(
…………
RawComparator<INKEY> comparator,
Class<INKEY> keyClass, Class<INVALUE> valueClass
) throws IOException, InterruptedException {
org.apache.hadoop.mapreduce.ReduceContext<INKEY, INVALUE, OUTKEY, OUTVALUE>
reduceContext =
new ReduceContextImpl<INKEY, INVALUE, OUTKEY, OUTVALUE>(
…………
comparator,
…………);
……
return reducerContext;
}
继续查看谁调用了createReduceContext方法,发现在ReduceTask类中的runNewReducer方法中调用了该方法,并传入了比较器对象:
org.apache.hadoop.mapreduce.Reducer.Context
reducerContext = createReduceContext(reducer, job, getTaskID(),
rIter, reduceInputKeyCounter,
reduceInputValueCounter,
trackedRW,
committer,
reporter, comparator, keyClass,
valueClass);
createReduceContext方法是在reduce.run之前执行的,可见在reduce任务真正开始之前,需要进行一系列的准备工作,其中就包括比较器对象的准备。
而此处的comparator对象,也是传入Reducer方法的一个参数,继续查看是谁向runNewReducer方法中传入了comparator:
在ReduceTask类的run方法中,先是获取用户为当前job定义的比较器,以用于将输入到reduce的key进行分组,然后将这个比较器传入到runNewReducer方法中:
RawComparator comparator = job.getOutputValueGroupingComparator();
if (useNewApi) {
runNewReducer(job, umbilical, reporter, rIter, comparator,
keyClass, valueClass);
} else {
runOldReducer(job, umbilical, reporter, rIter, comparator,
keyClass, valueClass);
}
查看JobConf类中的getOutputValueGroupingComparator方法:
/**
* Get the user defined {@link WritableComparable} comparator for
* grouping keys of inputs to the reduce.
*
* @return comparator set by the user for grouping values.
* @see #setOutputValueGroupingComparator(Class) for details.
*/
public RawComparator getOutputValueGroupingComparator() {
Class<? extends RawComparator> theClass = getClass(
JobContext.GROUP_COMPARATOR_CLASS, null, RawComparator.class);
if (theClass == null) {
return getOutputKeyComparator();
}
return ReflectionUtils.newInstance(theClass, this);
}
在该方法内部首先会尝试获取JobContext.GROUP_COMPARATOR_CLASS这个属性值,如果我们自定义了一个比较器的类,并在Driver类中设置了该属性的值,那么设置的值就作为比较器对象,否则就返回默认值null。

如果theClass的值为null,那么会执行getOutputKeyComparator方法:
public RawComparator getOutputKeyComparator() {
Class<? extends RawComparator> theClass = getClass(
JobContext.KEY_COMPARATOR, null, RawComparator.class);
if (theClass != null)
return ReflectionUtils.newInstance(theClass, this);
return WritableComparator.get(getMapOutputKeyClass().asSubclass(WritableComparable.class), this);
}
getOutputKeyComparator方法内部也是,如果设置了KEY_COMPARATOR属性值的值就创建这个属性值对象,否者就返回在Driver类中设置的Key的OutputKeyClass的对象。getMapOutputKeyClass返回的是map输出数据的key类型,如果没有设置,会使用最终输出数据的key类型返回。
public Class<?> getMapOutputKeyClass() {
Class<?> retv = getClass(JobContext.MAP_OUTPUT_KEY_CLASS, null, Object.class);
if (retv == null) {
retv = getOutputKeyClass();
}
return retv;
}
还有必须要注意的是,map输出的数据的key类型必须是WritableComparable类的子类,也就是说必须继承了WritableComparable这个类,这也就是说为什么当我们自定义的bean对象作为key的时候,一定要继承WritableComparable类了。
继续查看WritableComparator.get方法,
public static WritableComparator get(
Class<? extends WritableComparable> c, Configuration conf) {
WritableComparator comparator = comparators.get(c);
if (comparator == null) {
// force the static initializers to run
forceInit(c);
// look to see if it is defined now
comparator = comparators.get(c);
// if not, use the generic one
if (comparator == null) {
comparator = new WritableComparator(c, conf, true);
}
}
// Newly passed Configuration objects should be used.
ReflectionUtils.setConf(comparator, conf);
return comparator;
}
该方法首先会执行comparators.get(c)方法获取c所映射的值,如果c没有映射的值,那么get方法就返回null,否则就返回它所映射的比较器对象。
如果我们自定义的key类型没有所映射的值,那么返回null,此时就会使用反射技术创建一个comparator实例,这个实例也就是在后面Reduce端遍历key的时候,使用的comparator实例。
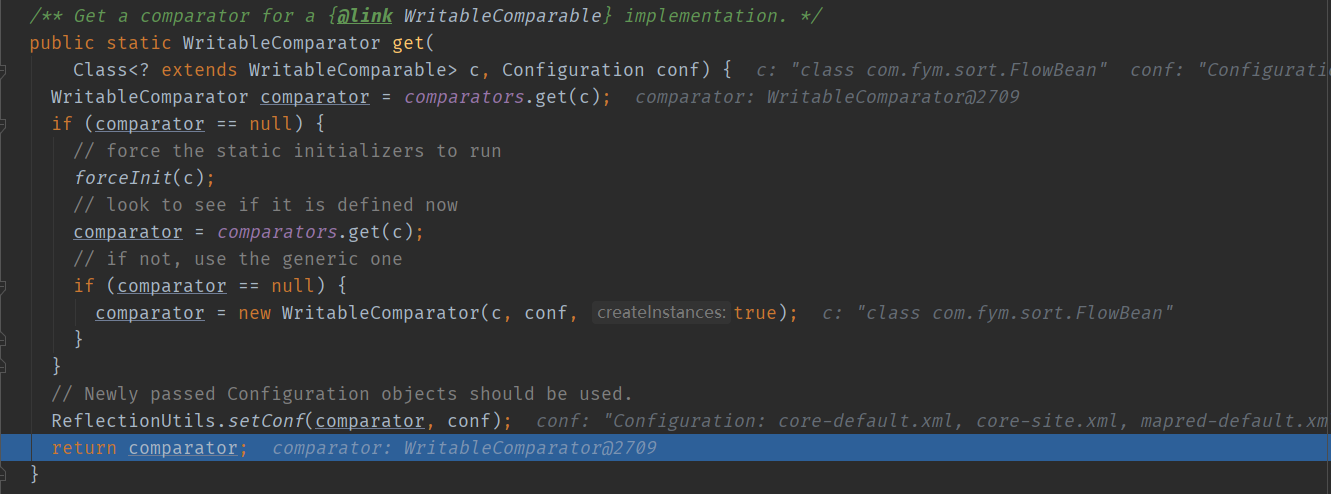
如果key的类型Text,那么是可以找到对应映射的value,也就是有对应的比较器对象,那么直接返回即可。
此时我们就搞清楚了,Reduce端是如何分组的,它需要借助一个key的比较器,然后在遍历数据的时候进行key的比较,如果key相同那么就是一组的,否则就不属于同一组。其实从更加准确的角度来讲,将数据的key传入到比较器的compare方法中,compare方法如果返回的结果是0,那么成员变量nextKeyIsSame的值就是true,说明当前一条记录的key与下一条记录的key是相同的,它们属于同一组,如果不为0,nextKeyIsSame的值就为false。
所以,如果我们想要将一些key不完全相同的数据放入同一组,就可以自定义一个bean对象,这个bean对象要继承WritableComparable类,然后实现compareTo方法,在compareTo方法中可以定义哪些key是一组的,哪些不是。还有一种可以自定义分组的方式就是自定义一个类继承WritableComparator类,然后重写该类的compare方法,compare方法就是分组的逻辑,最后在Drive人类中设置一下这个分组排序类即可。
job.setGroupingComparatorClass(xxx.class)
查看这段设置代码的源码:
public void setOutputValueGroupingComparator(
Class<? extends RawComparator> theClass) {
setClass(JobContext.GROUP_COMPARATOR_CLASS,
theClass, RawComparator.class);
}
可以看出,这个设置也正是对应了上面的JobConf类中的getOutputValueGroupingComparator方法中首先要检测获取的JobContext.GROUP_COMPARATOR_CLASS属性值。如果该属性值在Driver中设置了,那么就直接得到比较器对象,无需后面的利用数据的key的类型对象得到比较器对象了。
这也就是说为何要在Reduce端,对从各个MapTask拉取的数据进行一次全局的排序,这样也是为了方便将同一组的数据放入一个reduce方法中。
二、key的相关数据类型源码分析
1、Text
下面来查看一下Text数据类型的与比较器相关部分的代码:
如果map输出的key是Text类型,那么调用的comparator.compare方法实际就是Text类中的compare方法:
/** A WritableComparator optimized for Text keys. */
public static class Comparator extends WritableComparator {
public Comparator() {
super(Text.class);
}
@Override
public int compare(byte[] b1, int s1, int l1,
byte[] b2, int s2, int l2) {
int n1 = WritableUtils.decodeVIntSize(b1[s1]);
int n2 = WritableUtils.decodeVIntSize(b2[s2]);
return compareBytes(b1, s1+n1, l1-n1, b2, s2+n2, l2-n2);
}
}
compareBytes方法是WritableComparator中的一个静态方法,可见对于Text类型(二进制数据)的key,其排序规则是按照字典序来排的:
/** Lexicographic order of binary data. */
public static int compareBytes(byte[] b1, int s1, int l1,
byte[] b2, int s2, int l2) {
return FastByteComparisons.compareTo(b1, s1, l1, b2, s2, l2);
}
public static int compareTo(byte[] b1, int s1, int l1, byte[] b2, int s2,
int l2) {
return LexicographicalComparerHolder.BEST_COMPARER.compareTo(
b1, s1, l1, b2, s2, l2);
}
2、IntWritable
/** A Comparator optimized for IntWritable. */
public static class Comparator extends WritableComparator {
public Comparator() {
super(IntWritable.class);
}
@Override
public int compare(byte[] b1, int s1, int l1,
byte[] b2, int s2, int l2) {
int thisValue = readInt(b1, s1);
int thatValue = readInt(b2, s2);
return (thisValue<thatValue ? -1 : (thisValue==thatValue ? 0 : 1));
}
}
3、自定义bean对象
对于自定义的bean对象,reduce端在对数据进行分组的时候,会先依据bean创建一个比较器,当执行到comparator.compare方法时,此时首先调用的就是WritableComparator自带的compare方法,即下面源码中的第一个compare方法,在这个compare方法的最后返回的是compare(key1, key2)的执行结果。
@Override
public int compare(byte[] b1, int s1, int l1, byte[] b2, int s2, int l2) {
try {
buffer.reset(b1, s1, l1); // parse key1
key1.readFields(buffer);
buffer.reset(b2, s2, l2); // parse key2
key2.readFields(buffer);
buffer.reset(null, 0, 0); // clean up reference
} catch (IOException e) {
throw new RuntimeException(e);
}
return compare(key1, key2); // compare them
}
/** Compare two WritableComparables.
*
* <p> The default implementation uses the natural ordering, calling {@link
* Comparable#compareTo(Object)}. */
@SuppressWarnings("unchecked")
public int compare(WritableComparable a, WritableComparable b) {
return a.compareTo(b);
}
而compare(key1, key2)就是上面源码中的第二个compare方法,它的参数是两个WritableComparable类型的对象。其内部调用的正是我们自定义的bean对象重写的compareTo方法。
三、自定义WritableComparator
当然自定义分组,也可以通过自定义一个类继承WritableComparator来实现。继承这个类,需要将分组的逻辑重写在compare方法中,然后在Driver类中进行设置。
而且一定需要注意的是,一定要写一个构造方法,在这个构造方法中调用一下父类构造方法,并向父类构造方法传入我们数据的key的类型。如下面所示。
public class GroupComparator extends WritableComparator {
public GroupComparator() {
super(OrderBean.class,true);
}
@Override
public int compare(WritableComparable a, WritableComparable b) {
OrderBean abean = (OrderBean)a;
OrderBean bbean = (OrderBean)b;
int result;
if (abean.getId() > bbean.getId()){
result = 1;
}else if (abean.getId() < bbean.getId()){
result = -1;
}else {
result = 0;
}
return result;
}
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号