Job提交流程源码和切片源码详解
Job提交流程源码分析
1、提交作业到集群,然后等待作业完成
boolean res = job.waitForCompletion(true);
2、将Job提交到集群中,执行此方法说明此时Job尚未运行
public boolean waitForCompletion(boolean verbose
) throws IOException, InterruptedException,
ClassNotFoundException {
if (state == JobState.DEFINE) {
submit();
}
……
}
3、在submit方法内部,会先进行一些合法性判断,然后设置使用最新的API,再执行connect方法建立连接。
public void submit()
throws IOException, InterruptedException, ClassNotFoundException {
ensureState(JobState.DEFINE);
setUseNewAPI();
connect();
……
}
4、进入到connect方法内部,查看其底层的代码
private synchronized void connect()
throws IOException, InterruptedException, ClassNotFoundException {
if (cluster == null) {
cluster =
ugi.doAs(new PrivilegedExceptionAction<Cluster>() {
public Cluster run()
throws IOException, InterruptedException,
ClassNotFoundException {
return new Cluster(getConfiguration());
}
});
}
}
在connect方法内部,创建了一个Cluster对象,即集群对象如果为null,那就创建一个集群对象。创建这个集群对象的时候,传入的是getConfiguration方法,该方法返回的是Configuration对象,其包含了各种的Hadoop配置文件。

它会调用重载的构造方法:
public Cluster(InetSocketAddress jobTrackAddr, Configuration conf)
throws IOException {
this.conf = conf;
this.ugi = UserGroupInformation.getCurrentUser();
initialize(jobTrackAddr, conf);
}
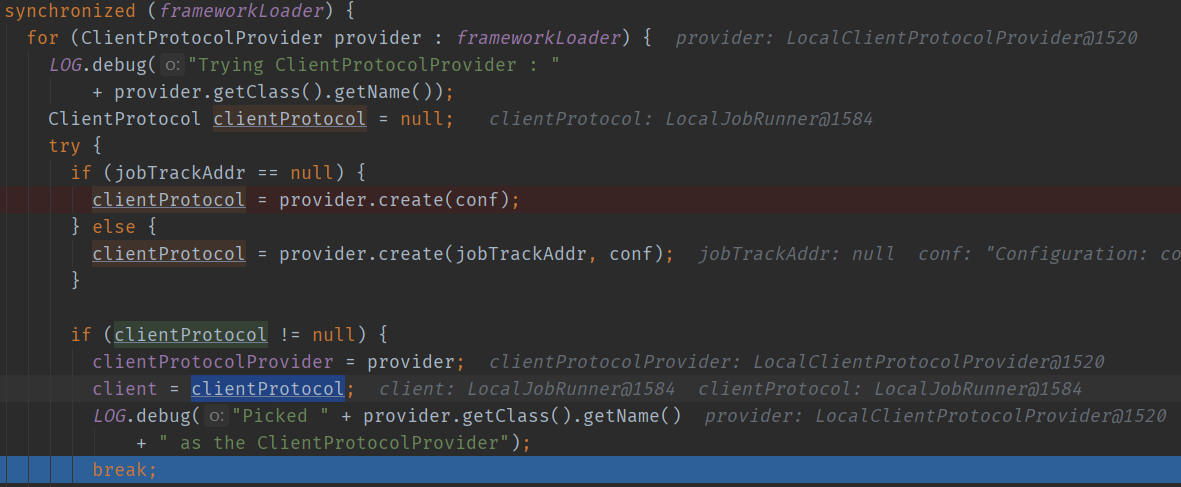
该重载的方法内部执行了initialize方法,该方法进行初始化,唯一任务是确定客户端通信协议提供者,并通过该对象的create方法构造客户端通信协议对象实例client。核心目的也就是要判断当前客户端是本地客户端还是Yarn客户端。
private void initialize(InetSocketAddress jobTrackAddr, Configuration conf)
throws IOException {
synchronized (frameworkLoader) {
for (ClientProtocolProvider provider : frameworkLoader) {
……
ClientProtocol clientProtocol = null;
try {
if (jobTrackAddr == null) {
clientProtocol = provider.create(conf);
} else {
clientProtocol = provider.create(jobTrackAddr, conf);
}
if (clientProtocol != null) {
clientProtocolProvider = provider;
client = clientProtocol;
……
break;
}
else {
……
}
}
catch (Exception e) {
……
}
}
}
if (null == clientProtocolProvider || null == client) {
throw new IOException(
…………
}
}
其中frameworkLoader是对ClientProtocolProvider进行反射得到的。
private static ServiceLoader<ClientProtocolProvider> frameworkLoader =
ServiceLoader.load(ClientProtocolProvider.class);
Cluster客户端通信协议clientProtocol实例,要么是Yarn模式下的YARNRunner,要么是Local模式下的LocalRunner。
5、上述过程是客户端与集群的连接过程,主要包括创建提交Job的代理,确定当前客户端时本地客户端还是Yarn客户端,那么下面的任务就是提交Job了,该任务是在submit方法内部执行完connect方法以后执行的。
public void submit()
throws IOException, InterruptedException, ClassNotFoundException {
……
final JobSubmitter submitter =
getJobSubmitter(cluster.getFileSystem(), cluster.getClient());
status = ugi.doAs(new PrivilegedExceptionAction<JobStatus>() {
public JobStatus run() throws IOException, InterruptedException,
ClassNotFoundException {
return submitter.submitJobInternal(Job.this, cluster);
}
});
state = JobState.RUNNING;
LOG.info("The url to track the job: " + getTrackingURL());
}
首先要创建提交Job的实例submitter:
public JobSubmitter getJobSubmitter(FileSystem fs,
ClientProtocol submitClient) throws IOException {
return new JobSubmitter(fs, submitClient);
}
传入的是集群的文件系统对象以及客户端对象。如果是本地模式,那么就是本地文件系统对象和LocalClient对象。如果是Yarn模式,那么就是HDFS文件系统对象和YarnClient。
然后继续执行submitter.submitJobInternal(Job.this, cluster),submitJobInternal方法内部的代码如下:
JobStatus submitJobInternal(Job job, Cluster cluster)
throws ClassNotFoundException, InterruptedException, IOException {
……
//创建给集群提交数据的Stag路径
Path jobStagingArea = JobSubmissionFiles.getStagingDir(cluster, conf);
……
//创建jobid,并创建job提交到集群的目录
JobID jobId = submitClient.getNewJobID();
job.setJobID(jobId);
Path submitJobDir = new Path(jobStagingArea, jobId.toString());
JobStatus status = null;
…………
//拷贝jar包到集群
copyAndConfigureFiles(job, submitJobDir);
Path submitJobFile = JobSubmissionFiles.getJobConfPath(submitJobDir);
//计算切片,生成切片规划文件
int maps = writeSplits(job, submitJobDir);
conf.setInt(MRJobConfig.NUM_MAPS, maps);
…………
// Write job file to submit dir
writeConf(conf, submitJobFile);
…………
status = submitClient.submitJob(
jobId, submitJobDir.toString(), job.getCredentials());
…………
}
从上到下,顺序对上面的源码进行分析:
(1)创建给集群提交数据的Stag路径 (客户端缓存目录)
Path jobStagingArea = JobSubmissionFiles.getStagingDir(cluster, conf);
这个路径是临时的,数据上传到集群以后,该路径的文件夹会被删除,如下图所示的是在本地模式下执行完此行代码所生成的目录:
(2)获取jobid,并创建job路径,该路径下要存放的是该job相关的一些文件,包括切片文件、job.xml,以及相关jar包等。
JobID jobId = submitClient.getNewJobID();
job.setJobID(jobId);
Path submitJobDir = new Path(jobStagingArea, jobId.toString());
如图所示:


(3)拷贝Jar包到集群。
private void copyAndConfigureFiles(Job job, Path jobSubmitDir)
throws IOException {
JobResourceUploader rUploader = new JobResourceUploader(jtFs);
rUploader.uploadFiles(job, jobSubmitDir);
…………
}
继续查看uploadFiles方法的内部源码:
public void uploadFiles(Job job, Path submitJobDir) throws IOException {
Configuration conf = job.getConfiguration();
short replication =
(short) conf.getInt(Job.SUBMIT_REPLICATION,
Job.DEFAULT_SUBMIT_REPLICATION);
…………
// get all the command line arguments passed in by the user conf
String files = conf.get("tmpfiles");
String libjars = conf.get("tmpjars");
String archives = conf.get("tmparchives");
String jobJar = job.getJar();
…………
submitJobDir = jtFs.makeQualified(submitJobDir);
submitJobDir = new Path(submitJobDir.toUri().getPath());
FsPermission mapredSysPerms =
new FsPermission(JobSubmissionFiles.JOB_DIR_PERMISSION);
FileSystem.mkdirs(jtFs, submitJobDir, mapredSysPerms);
Path filesDir = JobSubmissionFiles.getJobDistCacheFiles(submitJobDir);
Path archivesDir = JobSubmissionFiles.getJobDistCacheArchives(submitJobDir);
Path libjarsDir = JobSubmissionFiles.getJobDistCacheLibjars(submitJobDir);
// add all the command line files/ jars and archive
// first copy them to jobtrackers filesystem
………
}
该方法就是上传和配置与当前传递的作业相关的文件、lib包、job包以及archives。将它们上传到集群的指定客户端缓存目录下,submitJobDir变量存储的就是job在集群中的提交目录。
可以看到这些相关文件的客户端缓存目录均是在对应的jobid目录下:

(4)计算切片,生成切片规划文件
int maps = writeSplits(job, submitJobDir);
conf.setInt(MRJobConfig.NUM_MAPS, maps);
//public static final String NUM_MAPS = "mapreduce.job.maps";
查看writeSplits的底层源码:
private int writeSplits(org.apache.hadoop.mapreduce.JobContext job,
Path jobSubmitDir) throws IOException,
InterruptedException, ClassNotFoundException {
JobConf jConf = (JobConf)job.getConfiguration();
int maps;
if (jConf.getUseNewMapper()) {
maps = writeNewSplits(job, jobSubmitDir);
} else {
maps = writeOldSplits(jConf, jobSubmitDir);
}
return maps;
}
调用的应该是writeNewSplits方法,继续查看:
private <T extends InputSplit>
int writeNewSplits(JobContext job, Path jobSubmitDir) throws IOException,
InterruptedException, ClassNotFoundException {
Configuration conf = job.getConfiguration();
InputFormat<?, ?> input =
ReflectionUtils.newInstance(job.getInputFormatClass(), conf);
List<InputSplit> splits = input.getSplits(job);
T[] array = (T[]) splits.toArray(new InputSplit[splits.size()]);
// sort the splits into order based on size, so that the biggest
// go first
Arrays.sort(array, new SplitComparator());
JobSplitWriter.createSplitFiles(jobSubmitDir, conf,
jobSubmitDir.getFileSystem(conf), array);
return array.length;
}
该方法首先会根据反射得到一个InputFormat对象,然后通过这个InputFormat实例,调用getSplits方法,该方法是一个抽象方法,其作用是获取一个在逻辑上拆分job输入文件的集合,这个集合的长度就是writeNewSplits方法的返回值,也就是切片数量。其中在writeNewSplits方法的内部,还会将逻辑上拆分输入文件的集合先转换为数组,然后再进行排序,依据拆分文件的大小进行排序,目的是为优先生成大的拆分文件。所以writeNewSplits方法有两个任务,一个是计算切片数量,一个是生成切片规划文件。
框架默认的读取InputFormat是TextInputFormat:

(5)向Stag路径写XML配置文件
writeConf(conf, submitJobFile);
查看它的源码:
private void writeConf(Configuration conf, Path jobFile)
throws IOException {
// Write job file to JobTracker's fs
FSDataOutputStream out =
FileSystem.create(jtFs, jobFile,
new FsPermission(JobSubmissionFiles.JOB_FILE_PERMISSION));
try {
conf.writeXml(out);
} finally {
out.close();
}
}
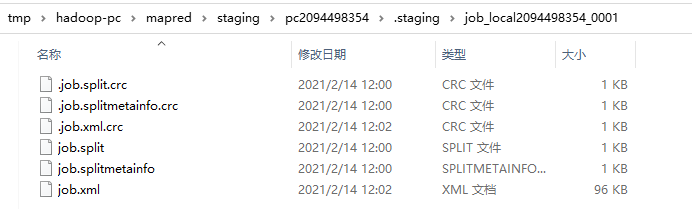
jtFs是文件系统对象,jobFile是xml文件的路径,第三个参数是Job文件的权限。生产的xml文件或存到该目录下:
(6)提交Job,返回提交状态
status = submitClient.submitJob(
jobId, submitJobDir.toString(), job.getCredentials());
提交完job以后,在stag路径下的对应的jobid文件夹就会被删除。

Job提交流程图:
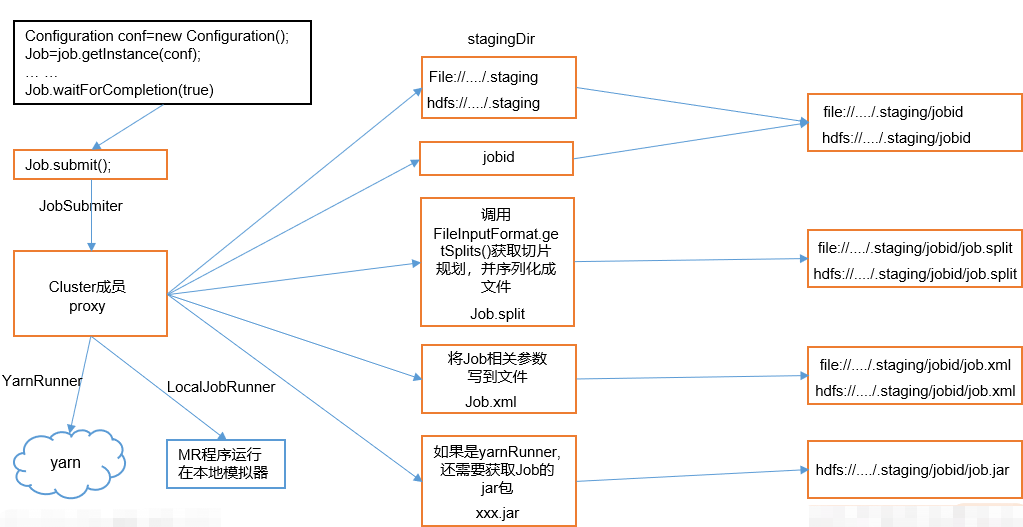
可以看出无论是本地客户端还是Yarn客户端,在向集群提交数据之前,都会先创建一个客户端缓存目录,将要提交的数据,以及与job相关的配置文件、jar包都放入到这个客户端缓存目录的对应jobid目录下,当任务正式提交以后,这个joid目录就会被删除。
FileInputFormat切片源码解析
因为Hadoop2.7.2使用的是新的Mapper,所以进行切片调用的应该是新的切片方法:
int writeNewSplits(JobContext job, Path jobSubmitDir) throws IOException,
InterruptedException, ClassNotFoundException {
Configuration conf = job.getConfiguration();
InputFormat<?, ?> input =
ReflectionUtils.newInstance(job.getInputFormatClass(), conf);
List<InputSplit> splits = input.getSplits(job);
T[] array = (T[]) splits.toArray(new InputSplit[splits.size()]);
// sort the splits into order based on size, so that the biggest
// go first
Arrays.sort(array, new SplitComparator());
JobSplitWriter.createSplitFiles(jobSubmitDir, conf,
jobSubmitDir.getFileSystem(conf), array);
return array.length;
}
FileInputFormat采用的是TextInputFormat,即框架默认的读取格式。

进入到核心方法getSplits中,查看它的底层逻辑,在这个方法中首先有两个变量:
long minSize = Math.max(getFormatMinSplitSize(), getMinSplitSize(job));
long maxSize = getMaxSplitSize(job);
其中minSize的值是getFormatMinSplitSize和getMinSplitSize这两个方法的返回值的最大值,其中getFormatMinSplitSize方法的返回值是1:
protected long getFormatMinSplitSize() {
return 1;
}
getMinSplitSize方法是,如果第一个参数设置了值,那么就返回第一个参数对应设置的值,如果没有设置值,就返回默认值1,此处没有设置值,所以返回值是1:
public static long getMinSplitSize(JobContext job) {
return job.getConfiguration().getLong(SPLIT_MINSIZE, 1L);
}
public static final String SPLIT_MINSIZE =
"mapreduce.input.fileinputformat.split.minsize";
所以minSize的值为1。getMaxSplitSize方法逻辑如下:
public static long getMaxSplitSize(JobContext context) {
return context.getConfiguration().getLong(SPLIT_MAXSIZE,
Long.MAX_VALUE);
}
与上面的getMinSplitSize方法原理类似,如果设置了SPLIT_MAXSIZE这个参数值,就返回它的值,否则返回long的最大值:9223372036854775807,所以maxSize的值为9223372036854775807。
继续向下执行getSplits方法中的逻辑,
// generate splits
List<InputSplit> splits = new ArrayList<InputSplit>();
List<FileStatus> files = listStatus(job);
for (FileStatus file: files) {
Path path = file.getPath();
long length = file.getLen();
if (length != 0) {
BlockLocation[] blkLocations;
if (file instanceof LocatedFileStatus) {
blkLocations = ((LocatedFileStatus) file).getBlockLocations();
} else {
FileSystem fs = path.getFileSystem(job.getConfiguration());
blkLocations = fs.getFileBlockLocations(file, 0, length);
}
if (isSplitable(job, path)) {
long blockSize = file.getBlockSize();
long splitSize = computeSplitSize(blockSize, minSize, maxSize);
long bytesRemaining = length;
while (((double) bytesRemaining)/splitSize > SPLIT_SLOP) {
int blkIndex = getBlockIndex(blkLocations, length-bytesRemaining);
splits.add(makeSplit(path, length-bytesRemaining, splitSize,
blkLocations[blkIndex].getHosts(),
blkLocations[blkIndex].getCachedHosts()));
bytesRemaining -= splitSize;
}
if (bytesRemaining != 0) {
int blkIndex = getBlockIndex(blkLocations, length-bytesRemaining);
splits.add(makeSplit(path, length-bytesRemaining, bytesRemaining,
blkLocations[blkIndex].getHosts(),
blkLocations[blkIndex].getCachedHosts()));
}
} else { // not splitable
splits.add(makeSplit(path, 0, length, blkLocations[0].getHosts(),
blkLocations[0].getCachedHosts()));
}
} else {
//Create empty hosts array for zero length files
splits.add(makeSplit(path, 0, length, new String[0]));
}
}
可以看出TextInputFormat是按照一个文件为整体进行切片的,而非是按照数据集整体:
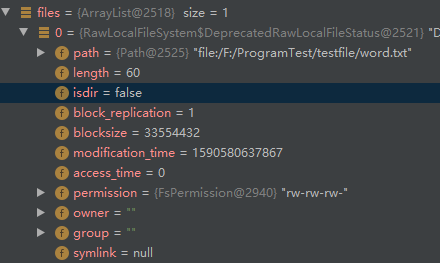
for (FileStatus file: files)
files存储了要参与job计算的所有文件,即指定文件夹下的所有文件,它是一个ArrayList类型的变量:

继续向下执行
Path path = file.getPath();
long length = file.getLen();
if (length != 0) {
BlockLocation[] blkLocations;
if (file instanceof LocatedFileStatus) {
blkLocations = ((LocatedFileStatus) file).getBlockLocations();
} else {
FileSystem fs = path.getFileSystem(job.getConfiguration());
blkLocations = fs.getFileBlockLocations(file, 0, length);
}
首先获取一下当前要切片的文件的基本信息,在文件系统的路径、长度等,然后再依据文件的长度、文件对象获取当前文件在数据块中的位置。

接下来就是判断当前的数据是否可以切分
if (isSplitable(job, path))
查看如何判断一个文件是否可以切割:
protected boolean isSplitable(JobContext context, Path file) {
final CompressionCodec codec =
new CompressionCodecFactory(context.getConfiguration()).getCodec(file);
if (null == codec) {
return true;
}
return codec instanceof SplittableCompressionCodec;
}
首先定义了一个编解码对象,将当前文件传入了进去,然后如果当前文件没有任何的编解码,那么就是可以切割的,如果有对应的编解码,那么这个编解码对象如果属于SplittableCompressionCodec类型,那么文件也是可以切割的,否则就不可以切割。
也就是对于一个文件,可以被切割的满足的条件是:
1、本身没有被压缩
2、采用的压缩方式是SplittableCompressionCodec或者其子类

当前文件如果可以切分,那么会继续向下执行:
long blockSize = file.getBlockSize();
long splitSize = computeSplitSize(blockSize, minSize, maxSize);
首先获取文件块大小,在Yarn模式下,块的大小默认是128M,但是在本地模式上,块的默认大小是32M(hadoop2.x版本,1.x版本是64M)。
然后计算切片大小splitSize:
protected long computeSplitSize(long blockSize, long minSize,
long maxSize) {
return Math.max(minSize, Math.min(maxSize, blockSize));
}
blockSize是块大小,此时是32M,minSize为1,maxSize为long的最大值。
那么切片大小的计算方式是:
(1)首先获取块大小和maxSize的之间的最小值,也就是32M
(2)然后获取minSize和块大小之间的最大值,也就是32M
所以最终切片的大小就是32M。所以切片的大小默认就是块的大小。
继续向下执行:
long bytesRemaining = length;
while (((double) bytesRemaining)/splitSize > SPLIT_SLOP) {
int blkIndex = getBlockIndex(blkLocations, length-bytesRemaining);
splits.add(makeSplit(path, length-bytesRemaining, splitSize,
blkLocations[blkIndex].getHosts(),
blkLocations[blkIndex].getCachedHosts()));
bytesRemaining -= splitSize;
}
首先获取当前文件的长度,然后进行一个计算:
((double) bytesRemaining)/splitSize > SPLIT_SLOP
判断当前文件的长度除以块的大小是否大于1.1,也就是说判断当前文件的大小是否大于块大小的1.1倍,如果大于那么就进行切片,否则直接执行下一步。
将文件剩下的所有内容放入一个分片中。
if (bytesRemaining != 0) {
int blkIndex = getBlockIndex(blkLocations, length-bytesRemaining);
splits.add(makeSplit(path, length-bytesRemaining, bytesRemaining,
blkLocations[blkIndex].getHosts(),
blkLocations[blkIndex].getCachedHosts()));
}
对所有的文件切片完成以后,最终返回的是一个ArrayList,其中的每一个元素都代表一个切片,包含了切分的文件以及切片起始位置和长度。
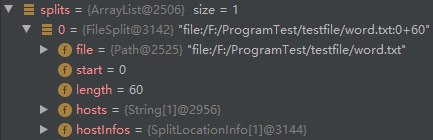
最终切片任务得以完成,在writeNewSplits方法中也将获取一个切片集合:
List<InputSplit> splits = input.getSplits(job);
该集合的大小也就是切片的数量。
在writeNewSplits方法中的以下代码执行完毕以后:
T[] array = (T[]) splits.toArray(new InputSplit[splits.size()]);
// sort the splits into order based on size, so that the biggest
// go first
Arrays.sort(array, new SplitComparator());
JobSplitWriter.createSplitFiles(jobSubmitDir, conf,
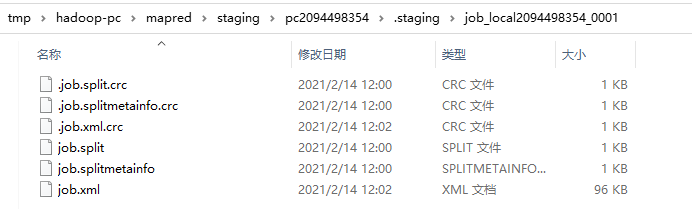
jobSubmitDir.getFileSystem(conf), array);
便会在客户端缓存目录中生产以下临时文件,包括了切片的元数据信息、切片文件、以及校验文件等。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号