
Spark应用程序-Shuffle写流程
Shuffle的写流程
ShuffleMapTask类中的runTask方法中含有一个写处理器:
shuffleWriterProcessor
它执行写操作的启动操作,即执行write方法,在write方法方法中还含有一个Shuffle管理器:
val manager = SparkEnv.get.shuffleManager
shuffleManager早期是HashShuffleManager,现在是SortShuffleManager。接下来查看一下SortShuffleManager中的getWriter方法,该方法的主要作用是获取给定分区的writer对象。其中一共包含三种类型的ShuffleWriter对象,不同的处理器对应不同的写对象。
| 处理器 | 写对象 | 使用条件 |
|---|---|---|
| SerializedShuffleHandle | UnsafeShuffleWriter | 1、序列化规则支持重定位操作(Java序列化不支持,Kryo支持)2、不能使用预聚合 3、如果下游的分区数量小于等于16777216 |
| BypassMergeSortShuffleHandle | BypassMergeSortShuffleWriter | 1、不能使用预聚合 2、其下游的分区数量小于等于阈值(默认200,可配) |
| BaseShuffleHandle | SortShuffleWriter | 其他情况 |
在getWriter方法中,是通过模式匹配根据处理器的类型创建对应的写对象,
handle match {
case unsafeShuffleHandle: SerializedShuffleHandle[K @unchecked, V @unchecked] =>
new UnsafeShuffleWriter(
env.blockManager,
context.taskMemoryManager(),
unsafeShuffleHandle,
mapId,
context,
env.conf,
metrics,
shuffleExecutorComponents)
case bypassMergeSortHandle: BypassMergeSortShuffleHandle[K @unchecked, V @unchecked] =>
new BypassMergeSortShuffleWriter(
env.blockManager,
bypassMergeSortHandle,
mapId,
env.conf,
metrics,
shuffleExecutorComponents)
case other: BaseShuffleHandle[K @unchecked, V @unchecked, _] =>
new SortShuffleWriter(
shuffleBlockResolver, other, mapId, context, shuffleExecutorComponents)
}
那么这三种具体类型的处理器如何获得呢?
可以知道,在getWriter方法中,它的第一个参数就是某一个具体的处理器"handle: ShuffleHandle",而getWriter方法是在write方法中调用的,那么传入getWriter方法中的具体的处理器对象也就在write方法中先得到,其为:
dep.shuffleHandle
它的定义为:
val shuffleHandle: ShuffleHandle = _rdd.context.env.shuffleManager.registerShuffle(
shuffleId, this)
registerShuffle方法正是用来注册shuffle处理器的,所以继续查看它的实现细节:
override def registerShuffle[K, V, C](
shuffleId: Int,
dependency: ShuffleDependency[K, V, C]): ShuffleHandle = {
if (SortShuffleWriter.shouldBypassMergeSort(conf, dependency)) {
// If there are fewer than spark.shuffle.sort.bypassMergeThreshold partitions and we don't
// need map-side aggregation, then write numPartitions files directly and just concatenate
// them at the end. This avoids doing serialization and deserialization twice to merge
// together the spilled files, which would happen with the normal code path. The downside is
// having multiple files open at a time and thus more memory allocated to buffers.
new BypassMergeSortShuffleHandle[K, V](
shuffleId, dependency.asInstanceOf[ShuffleDependency[K, V, V]])
} else if (SortShuffleManager.canUseSerializedShuffle(dependency)) {
// Otherwise, try to buffer map outputs in a serialized form, since this is more efficient:
new SerializedShuffleHandle[K, V](
shuffleId, dependency.asInstanceOf[ShuffleDependency[K, V, V]])
} else {
// Otherwise, buffer map outputs in a deserialized form:
new BaseShuffleHandle(shuffleId, dependency)
}
}
该方法内部根据不同的条件创建不同的handle,其中第一个条件是:
if (SortShuffleWriter.shouldBypassMergeSort(conf, dependency))
能不能忽略归并排序?所以继续查看这个条件的细节,看一看怎么个忽略。
def shouldBypassMergeSort(conf: SparkConf, dep: ShuffleDependency[_, _, _]): Boolean = {
// We cannot bypass sorting if we need to do map-side aggregation.
if (dep.mapSideCombine) {
false
} else {
val bypassMergeThreshold: Int = conf.get(config.SHUFFLE_SORT_BYPASS_MERGE_THRESHOLD)
dep.partitioner.numPartitions <= bypassMergeThreshold
}
}
1、可以看出如果需要进行map端聚合(预聚合),那么不能忽略归并排序,那么就返回false,也就是说如果想要创建BypassMergeSortShuffleHandle类型的处理器,则不能进行预聚合。
2、第二个条件分支中,有一个忽略归并排序的阈值,这个值是从一个配置文件中读取的,其默认值为200:
private[spark] val SHUFFLE_SORT_BYPASS_MERGE_THRESHOLD =
ConfigBuilder("spark.shuffle.sort.bypassMergeThreshold")
.doc("In the sort-based shuffle manager, avoid merge-sorting data if there is no " +
"map-side aggregation and there are at most this many reduce partitions")
.version("1.1.1")
.intConf
.createWithDefault(200)
也就是说,依赖当中(下游)的分区器的分区数要小于阈值200,才能创建BypassMergeSortShuffleHandle处理器。
第二个条件是:
else if (SortShuffleManager.canUseSerializedShuffle(dependency))
判断下游依赖是否可以使用序列化的Shuffle。
def canUseSerializedShuffle(dependency: ShuffleDependency[_, _, _]): Boolean = {
val shufId = dependency.shuffleId
val numPartitions = dependency.partitioner.numPartitions
if (!dependency.serializer.supportsRelocationOfSerializedObjects) {
log.debug(s"Can't use serialized shuffle for shuffle $shufId because the serializer, " +
s"${dependency.serializer.getClass.getName}, does not support object relocation")
false
} else if (dependency.mapSideCombine) {
log.debug(s"Can't use serialized shuffle for shuffle $shufId because we need to do " +
s"map-side aggregation")
false
} else if (numPartitions > MAX_SHUFFLE_OUTPUT_PARTITIONS_FOR_SERIALIZED_MODE) {
log.debug(s"Can't use serialized shuffle for shuffle $shufId because it has more than " +
s"$MAX_SHUFFLE_OUTPUT_PARTITIONS_FOR_SERIALIZED_MODE partitions")
false
} else {
log.debug(s"Can use serialized shuffle for shuffle $shufId")
true
}
}
(1)判断当前的序列化规则是否支持序列化的重定位,如果支持则可以使用序列化的Shuffle,如果不支持则不能使用,Java是不支持序列化重定位的,但是Kryo支持。
(2)如果支持预聚合,也不能使用序列化的Shuffle;
(3)如果下游的分区数量大于16777216,也不能使用。
上述两种条件都不满足时,则创建的是BaseShuffleHandle处理器。
假设此时匹配的是BaseShuffleHandle类型的处理器,那么对应创建的写对象就是SortShuffleWriter,那么writer.write方法就执行的是SortShuffleWriter中的write方法,
/** Write a bunch of records to this task's output */
override def write(records: Iterator[Product2[K, V]]): Unit = {
sorter = if (dep.mapSideCombine) {
new ExternalSorter[K, V, C](
context, dep.aggregator, Some(dep.partitioner), dep.keyOrdering, dep.serializer)
} else {
// In this case we pass neither an aggregator nor an ordering to the sorter, because we don't
// care whether the keys get sorted in each partition; that will be done on the reduce side
// if the operation being run is sortByKey.
new ExternalSorter[K, V, V](
context, aggregator = None, Some(dep.partitioner), ordering = None, dep.serializer)
}
sorter.insertAll(records)
// Don't bother including the time to open the merged output file in the shuffle write time,
// because it just opens a single file, so is typically too fast to measure accurately
// (see SPARK-3570).
val mapOutputWriter = shuffleExecutorComponents.createMapOutputWriter(
dep.shuffleId, mapId, dep.partitioner.numPartitions)
sorter.writePartitionedMapOutput(dep.shuffleId, mapId, mapOutputWriter)
val partitionLengths = mapOutputWriter.commitAllPartitions()
mapStatus = MapStatus(blockManager.shuffleServerId, partitionLengths, mapId)
}
该方法会先顶一个排序器,对插入的数据进行排序,排序的目的是为了能够更好的定位索引文件和数据文件中的信息,以供下游的Task读取。排序完成之后,就会将分区中的信息写出去,然后最终提交分区。
其中sorter用什么样的排序器会有一个判断,
sorter = if (dep.mapSideCombine) {
new ExternalSorter[K, V, C](
context, dep.aggregator, Some(dep.partitioner), dep.keyOrdering, dep.serializer)
} else {
new ExternalSorter[K, V, V](
context, aggregator = None, Some(dep.partitioner), ordering = None, dep.serializer)
}
如果依赖支持预聚合功能,则在创建排序器对象ExternalSorter的时候会传入aggregator和ordering这两个参数,不支持的话,则会将这两个参数设置为None。定义完排序器之后,则会插入数据。
sorter.insertAll(records)
查看insertAll的源码:
def insertAll(records: Iterator[Product2[K, V]]): Unit = {
// TODO: stop combining if we find that the reduction factor isn't high
val shouldCombine = aggregator.isDefined
if (shouldCombine) {
// Combine values in-memory first using our AppendOnlyMap
val mergeValue = aggregator.get.mergeValue
val createCombiner = aggregator.get.createCombiner
var kv: Product2[K, V] = null
val update = (hadValue: Boolean, oldValue: C) => {
if (hadValue) mergeValue(oldValue, kv._2) else createCombiner(kv._2)
}
while (records.hasNext) {
addElementsRead()
kv = records.next()
map.changeValue((getPartition(kv._1), kv._1), update)
maybeSpillCollection(usingMap = true)
}
} else {
// Stick values into our buffer
while (records.hasNext) {
addElementsRead()
val kv = records.next()
buffer.insert(getPartition(kv._1), kv._1, kv._2.asInstanceOf[C])
maybeSpillCollection(usingMap = false)
}
}
}
shouldCombine的值表示是否定义了预聚合器,其中定义了预聚合器和没有定义预聚合器分别使用了两种数据结构来存放溢写之前存放在内存中的数据。
//有预聚合功能时
@volatile private var map = new PartitionedAppendOnlyMap[K, C]
//没有预聚合功能时
@volatile private var buffer = new PartitionedPairBuffer[K, C]
根据insertAll中的源码可以看出,当有预聚合功能时,则会现在map端对相同key的数据进行预聚合,过程就是依据key获取分区,然后对相同key的数据进行value的聚合。之后进行判断是否可能进行溢写磁盘的操作。
如果没有预聚合功能,则使用的就是数组buffer,根据数据的key获取分区,然后直接将key和value放入buffer。最后一步也是进行判断是否进行溢写磁盘的操作。所以在shuffle的过程中,有一个从内存溢写数据到磁盘的过程,溢写时会先生成临时文件,然后临时文件会进行合并生成我们的索引文件和数据文件。
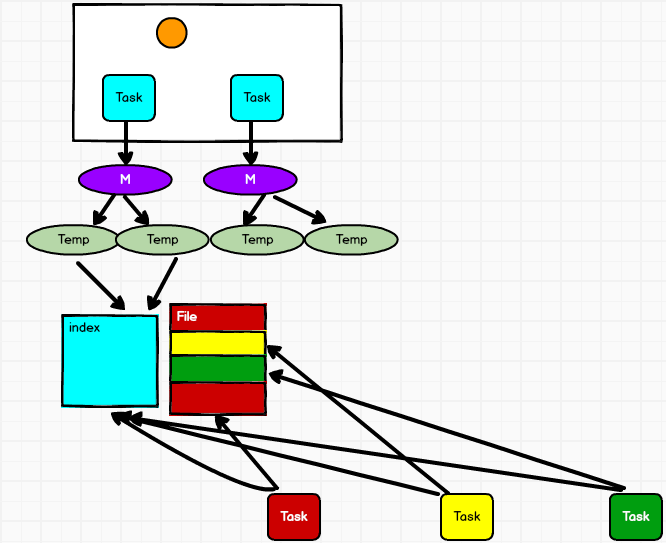
在溢写数据执行maybeSpillCollection()方法的时候,会有一个参数usingMap:
(1)预聚合时
maybeSpillCollection(usingMap = true)
(2)没有预聚合时
maybeSpillCollection(usingMap = false)
这个参数决定了在溢写数据的时候,创建什么样的数据结构:
//如果需要,将当前的内存收集溢出到磁盘上
private def maybeSpillCollection(usingMap: Boolean): Unit = {
var estimatedSize = 0L
if (usingMap) {
estimatedSize = map.estimateSize()
if (maybeSpill(map, estimatedSize)) {
map = new PartitionedAppendOnlyMap[K, C]
}
} else {
estimatedSize = buffer.estimateSize()
if (maybeSpill(buffer, estimatedSize)) {
buffer = new PartitionedPairBuffer[K, C]
}
}
if (estimatedSize > _peakMemoryUsedBytes) {
_peakMemoryUsedBytes = estimatedSize
}
}
如果usingMap为true,也就是有预聚合功能时,则创建map结构;如果usingMap为false,则没有预聚合功能,则创建buffer结构。
无论哪种结构,在实际的溢写之前,都会先估计当前数据结构所占内存的大小,然后执行maybeSpill方法判断当前是否需要溢写。
protected def maybeSpill(collection: C, currentMemory: Long): Boolean = {
var shouldSpill = false
if (elementsRead % 32 == 0 && currentMemory >= myMemoryThreshold) {
// Claim up to double our current memory from the shuffle memory pool
val amountToRequest = 2 * currentMemory - myMemoryThreshold
val granted = acquireMemory(amountToRequest)
myMemoryThreshold += granted
// If we were granted too little memory to grow further (either tryToAcquire returned 0,
// or we already had more memory than myMemoryThreshold), spill the current collection
shouldSpill = currentMemory >= myMemoryThreshold
}
shouldSpill = shouldSpill || _elementsRead > numElementsForceSpillThreshold
// Actually spill
if (shouldSpill) {
_spillCount += 1
logSpillage(currentMemory)
spill(collection)
_elementsRead = 0
_memoryBytesSpilled += currentMemory
releaseMemory()
}
shouldSpill
}
传入的参数就是一个集合,以及这个集合所占内存的大小。首先会判断当前读取的元素数量是否是32的倍数,同时当前集合所占内存的大小是否大于等于一个内存阈值则会强制溢写。如果元素读取数量大于元素读取的阈值也会强制溢写。
默认的内存阈值大小为5M:
private[spark] val SHUFFLE_SPILL_INITIAL_MEM_THRESHOLD =
ConfigBuilder("spark.shuffle.spill.initialMemoryThreshold")
.internal()
.doc("Initial threshold for the size of a collection before we start tracking its " +
"memory usage.")
.version("1.1.1")
.bytesConf(ByteUnit.BYTE)
.createWithDefault(5 * 1024 * 1024)
当shouldSpill为true时,则会进行实际的溢写操作,先将集合数据溢写出,然后释放内存。也就是说溢写操作并不一定会有,所以临时文件也不一定会有,只当内存不够用时,才需要进行溢写操作,生成临时文件。否则可以直接将数据从内存写出到数据文件。
观察数据如何进行溢写:
override protected[this] def spill(collection: WritablePartitionedPairCollection[K, C]): Unit = {
val inMemoryIterator = collection.destructiveSortedWritablePartitionedIterator(comparator)
val spillFile = spillMemoryIteratorToDisk(inMemoryIterator)
spills += spillFile
}
方法内部会有一个内存迭代器,同时参数是一个比较器,这是一个key比较器,也就是说对于数据的排序除了有分区的排序,还有相同分区内的数据依据key进行排序。
之后将内存中迭代器的内容溢出到磁盘上的临时文件中,即执行spillMemoryIteratorToDisk方法。
private[this] def spillMemoryIteratorToDisk(inMemoryIterator: WritablePartitionedIterator)
: SpilledFile = {
//创建临时文件
val (blockId, file) = diskBlockManager.createTempShuffleBlock()
…………
//创建向磁盘写数据的写对象
val writer: DiskBlockObjectWriter =
blockManager.getDiskWriter(blockId, file, serInstance, fileBufferSize, spillMetrics)
…………
// Flush the disk writer's contents to disk, and update relevant variables.
// The writer is committed at the end of this process.
def flush(): Unit = {
val segment = writer.commitAndGet()
batchSizes += segment.length
_diskBytesSpilled += segment.length
objectsWritten = 0
}
…………
}
在创建向磁盘写数据的写对象时,会传入一个fileBufferSize参数,它表示从内存向临时文件写数据时有一个缓冲区,这个缓冲区的默认大小是32K。然后执行flush方法,将写对象的内容刷写到磁盘。
再次回到SortShuffleWriter的write方法,当执行完sorter.insertAll(records)方法以后,会继续向下执行以下代码:
val mapOutputWriter = shuffleExecutorComponents.createMapOutputWriter(
dep.shuffleId, mapId, dep.partitioner.numPartitions)
sorter.writePartitionedMapOutput(dep.shuffleId, mapId, mapOutputWriter)
val partitionLengths = mapOutputWriter.commitAllPartitions()
mapStatus = MapStatus(blockManager.shuffleServerId, partitionLengths, mapId)
查看writePartitionedMapOutput方法
def writePartitionedMapOutput(
shuffleId: Int,
mapId: Long,
mapOutputWriter: ShuffleMapOutputWriter): Unit = {
var nextPartitionId = 0
if (spills.isEmpty) {
// Case where we only have in-memory data
…………
} else {
// We must perform merge-sort; get an iterator by partition and write everything directly.
for ((id, elements) <- this.partitionedIterator) {
…………
if (elements.hasNext) {
for (elem <- elements) {
partitionPairsWriter.write(elem._1, elem._2)
}
}
} {
if (partitionPairsWriter != null) {
partitionPairsWriter.close()
}
}
nextPartitionId = id + 1
}
}
……
}
该方法首先会判断有没有溢写,如果没有溢写则直接操作内存中的数据即可。如果有溢写,则必须执行归并排序,通过分区获取迭代器,然后获取partitionPairsWriter对象。其中查看以下分区迭代器partitionedIterator:
def partitionedIterator: Iterator[(Int, Iterator[Product2[K, C]])] = {
val usingMap = aggregator.isDefined
val collection: WritablePartitionedPairCollection[K, C] = if (usingMap) map else buffer
if (spills.isEmpty) {
// Special case: if we have only in-memory data, we don't need to merge streams, and perhaps
// we don't even need to sort by anything other than partition ID
if (ordering.isEmpty) {
// The user hasn't requested sorted keys, so only sort by partition ID, not key
groupByPartition(destructiveIterator(collection.partitionedDestructiveSortedIterator(None)))
} else {
// We do need to sort by both partition ID and key
groupByPartition(destructiveIterator(
collection.partitionedDestructiveSortedIterator(Some(keyComparator))))
}
} else {
// Merge spilled and in-memory data
merge(spills, destructiveIterator(
collection.partitionedDestructiveSortedIterator(comparator)))
}
}
该方法的作用时返回对写入此对象的所有数据进行迭代的迭代器,该数据按分区分组,并由请求的聚合器聚合。然后,对于每个分区,我们在其内容上都有一个迭代器,并且这些迭代器应按顺序进行访问。
其中,会判断有没有溢写,如果有溢写则会进行合并操作,分别将溢写出的临时文件和内存中的数据进行合并。
private def merge(spills: Seq[SpilledFile], inMemory: Iterator[((Int, K), C)])
: Iterator[(Int, Iterator[Product2[K, C]])] = {
val readers = spills.map(new SpillReader(_))
val inMemBuffered = inMemory.buffered
(0 until numPartitions).iterator.map { p =>
val inMemIterator = new IteratorForPartition(p, inMemBuffered)
val iterators = readers.map(_.readNextPartition()) ++ Seq(inMemIterator)
if (aggregator.isDefined) {
// Perform partial aggregation across partitions
(p, mergeWithAggregation(
iterators, aggregator.get.mergeCombiners, keyComparator, ordering.isDefined))
} else if (ordering.isDefined) {
// No aggregator given, but we have an ordering (e.g. used by reduce tasks in sortByKey);
// sort the elements without trying to merge them
(p, mergeSort(iterators, ordering.get))
} else {
(p, iterators.iterator.flatten)
}
}
}
当支持排序的时候,就会执行归并排序mergeSort。
private def mergeSort(iterators: Seq[Iterator[Product2[K, C]]], comparator: Comparator[K])
: Iterator[Product2[K, C]] = {
…………
// Use the reverse order (compare(y,x)) because PriorityQueue dequeues the max
val heap = new mutable.PriorityQueue[Iter]()(
(x: Iter, y: Iter) => comparator.compare(y.head._1, x.head._1))
heap.enqueue(bufferedIters: _*) // Will contain only the iterators with hasNext = true
new Iterator[Product2[K, C]] {
override def hasNext: Boolean = heap.nonEmpty
override def next(): Product2[K, C] = {
if (!hasNext) {
throw new NoSuchElementException
}
val firstBuf = heap.dequeue()
val firstPair = firstBuf.next()
if (firstBuf.hasNext) {
heap.enqueue(firstBuf)
}
firstPair
}
}
}
归并排序是通过创建一个优先级队列对象形成一个堆,以堆排序的方式实现的。
经过sorter.writePartitionedMapOutput方法将内存数据和磁盘文件数据合并以后,继续向下执行:
val partitionLengths = mapOutputWriter.commitAllPartitions()
@Override
public long[] commitAllPartitions() throws IOException {
…………
File resolvedTmp = outputTempFile != null && outputTempFile.isFile() ? outputTempFile : null;
blockResolver.writeIndexFileAndCommit(shuffleId, mapId, partitionLengths, resolvedTmp);
return partitionLengths;
}
此处会找到已有的数据文件,然后传入到writeIndexFileAndCommit方法中,更新索引文件并提交:
def writeIndexFileAndCommit(
shuffleId: Int,
mapId: Long,
lengths: Array[Long],
dataTmp: File): Unit = {
val indexFile = getIndexFile(shuffleId, mapId)
val indexTmp = Utils.tempFileWith(indexFile)
try {
val dataFile = getDataFile(shuffleId, mapId)
// There is only one IndexShuffleBlockResolver per executor, this synchronization make sure
// the following check and rename are atomic.
synchronized {
val existingLengths = checkIndexAndDataFile(indexFile, dataFile, lengths.length)
if (existingLengths != null) {
// Another attempt for the same task has already written our map outputs successfully,
// so just use the existing partition lengths and delete our temporary map outputs.
System.arraycopy(existingLengths, 0, lengths, 0, lengths.length)
if (dataTmp != null && dataTmp.exists()) {
dataTmp.delete()
}
} else {
// This is the first successful attempt in writing the map outputs for this task,
// so override any existing index and data files with the ones we wrote.
val out = new DataOutputStream(new BufferedOutputStream(new FileOutputStream(indexTmp)))
Utils.tryWithSafeFinally {
// We take in lengths of each block, need to convert it to offsets.
var offset = 0L
out.writeLong(offset)
for (length <- lengths) {
offset += length
out.writeLong(offset)
}
} {
out.close()
}
if (indexFile.exists()) {
indexFile.delete()
}
if (dataFile.exists()) {
dataFile.delete()
}
if (!indexTmp.renameTo(indexFile)) {
throw new IOException("fail to rename file " + indexTmp + " to " + indexFile)
}
if (dataTmp != null && dataTmp.exists() && !dataTmp.renameTo(dataFile)) {
throw new IOException("fail to rename file " + dataTmp + " to " + dataFile)
}
}
}
} finally {
if (indexTmp.exists() && !indexTmp.delete()) {
logError(s"Failed to delete temporary index file at ${indexTmp.getAbsolutePath}")
}
}
}
在方法内部,会先获取已有的数据文件和索引文件,并根据已有的索引文件生成一个临时索引文件,然后判断索引文件和数据文件是否相互匹配,如果匹配那么说明已经有Task成功写出map端输出了,此时将传入的临时数据文件删除即可。否则遍历传入的分区长度数组依据分区内每个块的长度修改临时索引文件的偏移量。
最后会删除早期索引文件和数据文件,最后将临时索引文件和临时数据文件改名为索引文件和数据文件。
