KafKa生产者-分区
生产者(producer)采用推(push)模式将消息发布到broker,每条消息都被追加(append)到分区(patition)中,属于顺序写磁盘(顺序写磁盘效率比随机写内存要高,保障kafka吞吐率)。消息发送时都被发送到一个topic,其本质就是一个目录,而topic是由一些Partition Logs(分区日志)组成,其组织结构如下图所示:
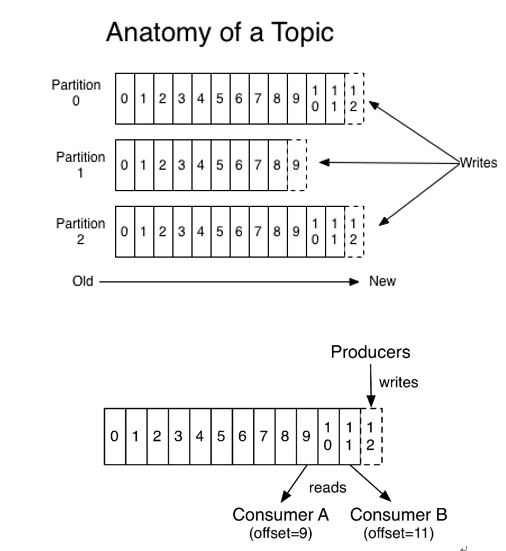
可以看出,每个Partition中的消息都是有序的,生产的消息被不断追加到Partition log上,其中的每一个消息都被赋予了一个唯一的offset值。每个分区内部也独立地维护了一个从0开始的offset值,offset只保证区内有序,即生产顺序和消费顺序一致。
1、分区的原因
(1)方便在集群中扩展,每个Partition可以通过调整以适应它所在的机器,而一个topic又可以有多个Partition组成,因此整个集群就可以适应任意大小的数据了;
(2)可以提高并发度,因为可以以Partition为单位读写了。
2、分区的方式
生产者向broker发送数据,需要将要发送的数据封装成一个ProducerRecord对象,ProducerRecord这个类含有多个重载的构造方法,每一种构造方法都有不同的参数,也就代表了不同的分区方法。
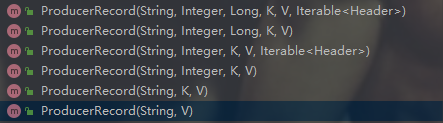
通过观察源码发现,这几种构造方法最终执行的都是上图的第一个构造方法,只不过在各自方法内部调用时,自身没有包含的参数在调用第一个构造方法的时候都设置为了null,这些重载的含有不同参数的构造方法调用第一个方法,第一个方法会根据传进来的参数值为成员变量赋值,没有值的则赋值为null,我们来看一下第一个构造方法的源码:
public ProducerRecord(String topic, Integer partition, Long timestamp, K key, V value, Iterable<Header> headers) { if (topic == null) throw new IllegalArgumentException("Topic cannot be null."); if (timestamp != null && timestamp < 0) throw new IllegalArgumentException( String.format("Invalid timestamp: %d. Timestamp should always be non-negative or null.", timestamp)); if (partition != null && partition < 0) throw new IllegalArgumentException( String.format("Invalid partition: %d. Partition number should always be non-negative or null.", partition)); this.topic = topic; this.partition = partition; this.key = key; this.value = value; this.timestamp = timestamp; this.headers = new RecordHeaders(headers); }
由代码可知,该方法对ProducerRecord对象做一个初始化的处理,将各个参数赋值给对应的成员变量,其中有的成员变量可能会被赋值为null。这些信息既有消息的的元数据,也有实际要发布的数据。会通过一个生产者对象,调用send方法发送。下面是KafkaProducer的send方法的源码:
send方法是通过异步的方式将record发送到主题的,其最终调用的也是第二个send方法
/** * Asynchronously send a record to a topic. Equivalent to <code>send(record, null)</code>. * See {@link #send(ProducerRecord, Callback)} for details. */ @Override public Future<RecordMetadata> send(ProducerRecord<K, V> record) { return send(record, null); } …… @Override public Future<RecordMetadata> send(ProducerRecord<K, V> record, Callback callback) { // intercept the record, which can be potentially modified; this method does not throw exceptions ProducerRecord<K, V> interceptedRecord = this.interceptors == null ? record : this.interceptors.onSend(record); return doSend(interceptedRecord, callback); }
观察第二个send方法发现,它会先判断是否有拦截器对象,如果没有就直接返回doSend方法的返回值,如果有拦截器对象则会去执行拦截器对象的onSend方法。这里继续观察探索doSend方法,这个方法是异步发送消息的主题的具体实现:
可看出该方法会依次将key和value进行序列化操作,然后计算一下分区,然后根据record的主题和partition函数返回的分区构建一个TopicPartition对象,最终这个对象会和时间戳信息、序列化之后的key、value等信息一起追加到accumulator这个线程共享变量中,等待sender线程将accumulator中的消息发送给broker
private Future<RecordMetadata> doSend(ProducerRecord<K, V> record, Callback callback) { TopicPartition tp = null; try { …… byte[] serializedKey; try { serializedKey = keySerializer.serialize(record.topic(), record.headers(), record.key()); } catch (ClassCastException cce) { throw new SerializationException("Can't convert key of class " + record.key().getClass().getName() + " to class " + producerConfig.getClass(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG).getName() + " specified in key.serializer"); } byte[] serializedValue; try { serializedValue = valueSerializer.serialize(record.topic(), record.headers(), record.value()); } catch (ClassCastException cce) { throw new SerializationException("Can't convert value of class " + record.value().getClass().getName() + " to class " + producerConfig.getClass(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG).getName() + " specified in value.serializer"); } int partition = partition(record, serializedKey, serializedValue, cluster); tp = new TopicPartition(record.topic(), partition); setReadOnly(record.headers()); Header[] headers = record.headers().toArray(); int serializedSize = AbstractRecords.estimateSizeInBytesUpperBound(apiVersions.maxUsableProduceMagic(), compressionType, serializedKey, serializedValue, headers); ensureValidRecordSize(serializedSize); long timestamp = record.timestamp() == null ? time.milliseconds() : record.timestamp(); log.trace("Sending record {} with callback {} to topic {} partition {}", record, callback, record.topic(), partition); // producer callback will make sure to call both 'callback' and interceptor callback Callback interceptCallback = this.interceptors == null ? callback : new InterceptorCallback<>(callback, this.interceptors, tp); if (transactionManager != null && transactionManager.isTransactional()) transactionManager.maybeAddPartitionToTransaction(tp); RecordAccumulator.RecordAppendResult result = accumulator.append(tp, timestamp, serializedKey, serializedValue, headers, interceptCallback, remainingWaitMs); if (result.batchIsFull || result.newBatchCreated) { log.trace("Waking up the sender since topic {} partition {} is either full or getting a new batch", record.topic(), partition); this.sender.wakeup(); } return result.future; // handling exceptions and record the errors; // for API exceptions return them in the future, // for other exceptions throw directly } catch(){ …… } }
进一步分析partition函数,这个函数用于计算给定的record的分区,如果record的分区给定了,那么就直接返回给定的分区值,如果没有则会调用已经配置好的分区类去计算分区。
private int partition(ProducerRecord<K, V> record, byte[] serializedKey, byte[] serializedValue, Cluster cluster) { Integer partition = record.partition(); return partition != null ? partition : partitioner.partition( record.topic(), record.key(), serializedKey, record.value(), serializedValue, cluster); }
直接进一步分析分区类是如何计算分区的,源码如下:
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) { List<PartitionInfo> partitions = cluster.partitionsForTopic(topic); int numPartitions = partitions.size(); if (keyBytes == null) { int nextValue = nextValue(topic); List<PartitionInfo> availablePartitions = cluster.availablePartitionsForTopic(topic); if (availablePartitions.size() > 0) { int part = Utils.toPositive(nextValue) % availablePartitions.size(); return availablePartitions.get(part).partition(); } else { // no partitions are available, give a non-available partition return Utils.toPositive(nextValue) % numPartitions; } } else { // hash the keyBytes to choose a partition return Utils.toPositive(Utils.murmur2(keyBytes)) % numPartitions; } }
可以看出,计算分区的规则如下:
(1)给定分区值的时候,直接将指明的分区值作为partition值;
(2)没有指明partition值,但是有key,则会将key的hash值与主题的分区数进行取模运算,得到partition值;
(3)既没有partition值,也没有key,则在第一次调用时随机生成一个整数(后面每次调用在这个整数上自增),将这个值与 topic 可用的 partition 总数取余得到 partition 值,也就是常说的 round-robin 算法。
需要说明的是,Kafka的Producer发送消息采用的是异步发送的方式。在消息发送的过程中,涉及到了两个线程 main线程和Sender线程 ,以及一个线程共享变量 RecordAccumulator。main线程将消息发送给 RecordAccumulator,Sender线程不断从RecordAccumulator中拉取消息发送到 Kafka broker。
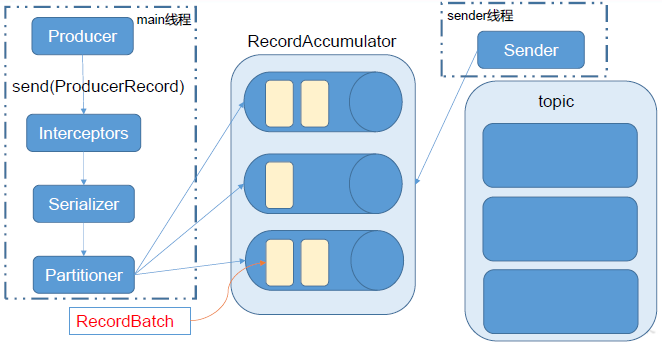
这也就对应了上面为何会将主题、分区、头信息、时间戳添加到RecordAccumulator变量。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号