KafKa的架构
KafKa是一个分布式的基于发布/订阅模式的消息队列(Message Queue),“消息队列”是在消息的传输过程中保存消息的容器。消息队列主要包括两种模式:
1、点对点模式
这种模式,对于消费者和消息来说是一对一的,消息的生产者生产消息发送到队列中,然后消息的消费者从队列中取出消息,然后消费,消息被消费以后,队列中不会再存储该消息,所以消费者不能消费到已经被消费的消息,也就是说对于一个消息而言,只能被一个消费者消费。该模式支持存在多个消费者,但是一个消息不能被多个消费者同时消费。
2、发布/订阅模式
在这种模式下,消费者消费完数据以后,不会清除消息,生产者将生产的消息发布到主题中,可以同时有多个消费者消费该消息,只要订阅了该主题的消费者,都会消费到主题中的消息。这种模式下,消费者获取消息的方式有两种:
(1)将消息”推“给消费者,”推“的速度由队列决定。
在此种模式下,消息队列推送数据的速度相同,不同的消费者接收处理数据的速度则可能不一样,对于处理速度大于MQ推送速度的消费者,则会造成资源的浪费;对于处理速度小于MQ推送速度的消费者,则可能会造成消费者的崩溃。
(2)消费者主动拉取数据,消费速度由消费者自己决定(Kafka属于此种模式)
这种模式下,消费者根据自身的处理速度去拉取数据,每个消费者需要维护一个常用轮询,检测MQ中是否有数据。
KafKa的基础架构

集群中各个组件的介绍:
1)Producer :消息生产者,就是向kafka broker 发消息的客户端;
2)Consumer :消息消费者,向kafka broker 取消息的客户端;
3)Consumer Group (CG):消费者组,由多个consumer 组成。消费者组内每个消费者负
责消费不同分区的数据,一个分区只能由一个组内消费者消费;消费者组之间互不影响。所
有的消费者都属于某个消费者组,即消费者组是逻辑上的一个订阅者。
4)Broker :一台kafka 服务器就是一个broker。一个集群由多个broker 组成。一个broker
可以容纳多个topic。
5)Topic :可以理解为一个队列,生产者和消费者面向的都是一个topic;
6)Partition:为了实现扩展性,一个非常大的topic 可以分布到多个broker(即服务器)上,
一个topic 可以分为多个partition,每个partition 是一个有序的队列;
7)Replica:副本,为保证集群中的某个节点发生故障时,该节点上的partition 数据不丢失,且kafka仍然能够继续工作 kafka提供了副本机制,一个 topic的每个分区都有若干个副本,这些副本中有一个 leader和若干个 follower。
8)leader 每个分区多个副本的“主”,生产者发送数据的对象,以及消费者消费数据的对
象都是 leader。
9)follower 每个分区多个副本中的“从”,实时从 leader中同步数据,保持和 leader数据
的同步。 leader发生故障时,某个 follower会成为新的 follower。
在Topic中设置分区是提高了KafKa集群的负载能力以及并发度。一个Topic中的分区,只能被同一个消费者组里的一个消费者消费,设置消费者组作为一个逻辑上的订阅者,可以提高消费者这边的消费能力。比较理想的情况是,消费者组中的消费者数量等于一个Topic中的分区数量。
还有一个需要说明的是,为了能够让意外宕机的消费者能够在重启后重新接着之前消费的数据的位置进行消费,或者是其他消费者替代挂掉的消费者接着它之前消费到数据的位置进行消费,需要保存一个消费的消息的位置信息offset,这个信息在kafka0.9版本之前存储在zookeeper中,在0.9版本之后存储在了kafka本地,为什么会这么做呢?
一方面,消费者需要和kafka集群保持连接,同时也需要和zookeeper保持连接,由于消费者拉取数据的速度较快,所以需要频繁地和zk打交道,会造成整体效率的低下。另一方面,消费者高并发的请求,本身对zk也会有不好的影响。
在kafka中并没有记录说明集群的相关信息,那么系统是如何知道哪些机器构成了集群了的呢?
这就是通过zookeeper,同一个集群中的kafka连接的是同一套zookeeper,同时集群中的每一个broker都会拥有一个全局唯一的id,这些节点都会找zookeeper进行注册(拿着唯一的id),比如我们通过zookeeper来查看一下:

可以看出,kafka集群的每个节点是通过zookeeper知道和哪些机器在同一个集群中。前提是,在配置的时候,要将同一集群的所有节点都配置成同一套zookeeper集群。zookeeper帮助KafKa组建集群,许多KafKa信息都要存到zookeeper,这些信息可以看作是kafka的元数据。其中就包括了topic相关信息(有几个topic,topic的名字,topic有几个分区、有几个副本、每一个分区的leader是谁,副本在哪台机器上等信息),如下图所示:
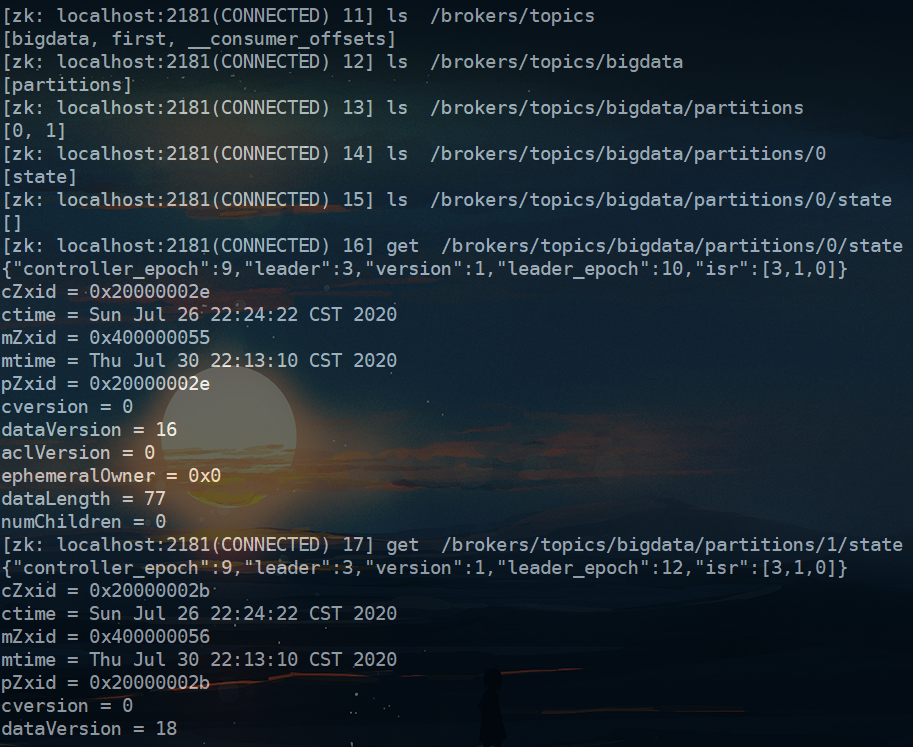
对于某一分区而言,副本数=leader + 所有的follower;leader和follower不会在同一台机器上。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号