MapReduce源码分析--MapTask阶段
MapTask类继承自Task类,负责Map阶段的数据处理流程,它最主要的方法就是run(),这个方法用于执行当前的Map阶段的任务。作为命名作业的一部分运行此任务。此方法在子进程中执行,是调用用户提供的map,reduce等方法的方法。在这个run方法中,首先会发送task任务报告,与父进程做交流 :
TaskReporter reporter = startReporter(umbilical);
判断用的是新的MapReduceAPI还是旧的API ,waitForCompletion()就用submit()方法设置了使用NewAPI,而此时就使用它。
boolean useNewApi = job.getUseNewMapper();
根据新老API选择对应的方法来执行map任务:
if (useNewApi) {
runNewMapper(job, splitMetaInfo, umbilical, reporter);
} else {
runOldMapper(job, splitMetaInfo, umbilical, reporter);
}
一般会会在Job类的提交提交阶段,设置使用新API,新的API调用的就是runNewMapper()方法:
在这个方法中会实例化mapper对象、Inputformat对象、InputSplit对象、RecordReader对象:
// make a mapper
org.apache.hadoop.mapreduce.Mapper<INKEY,INVALUE,OUTKEY,OUTVALUE> mapper =
(org.apache.hadoop.mapreduce.Mapper<INKEY,INVALUE,OUTKEY,OUTVALUE>)
ReflectionUtils.newInstance(taskContext.getMapperClass(), job);
// make the input format
org.apache.hadoop.mapreduce.InputFormat<INKEY,INVALUE> inputFormat =
(org.apache.hadoop.mapreduce.InputFormat<INKEY,INVALUE>)
ReflectionUtils.newInstance(taskContext.getInputFormatClass(), job);
// rebuild the input split
org.apache.hadoop.mapreduce.InputSplit split = null;
split = getSplitDetails(new Path(splitIndex.getSplitLocation()),
splitIndex.getStartOffset());
LOG.info("Processing split: " + split);
org.apache.hadoop.mapreduce.RecordReader<INKEY,INVALUE> input =
new NewTrackingRecordReader<INKEY,INVALUE>
(split, inputFormat, reporter, taskContext);
mapper实例化的对象就是我们自己根据自身的实际业务编写的xxxMapper类对象,
InputFormat是一个抽象类,它主要负责创建输入分片,并将它们分割成记录。
public abstract class InputFormat<K, V> {
public abstract
List<InputSplit> getSplits(JobContext context
) throws IOException, InterruptedException;
public abstract
RecordReader<K,V> createRecordReader(InputSplit split,
TaskAttemptContext context
) throws IOException,
InterruptedException;
}
InputFormat实例化对象默认会是TextInputFormat类对象,这个是默认的InputFormat实现类,它的切片机制是对任务按照文件规划切片,不管文件大小,都会是一个单独的切片。它的读取文件的模式按行读取每一条记录,每一条记录的键是存储该行在整个文件中的起始字节偏移量,LongWritable类型。value是读取的当前行的内容。
RecordReader也是一个抽象类,它就是记录上的迭代器,主要负责从一个分片中读取一条条记录,然后将记录生成一个个键值对(key/value),再将键值对传递给我们在mapper中重写的map方法,也就是作为map方法的输入。
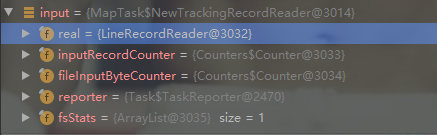
对于TextInputFormat类,它创建读取记录的ReadRecorder对象是如上图所示的LineRecordReader,如下面的代码所示。
public class TextInputFormat extends FileInputFormat<LongWritable, Text> {
@Override
public RecordReader<LongWritable, Text>
createRecordReader(InputSplit split,
TaskAttemptContext context) {
String delimiter = context.getConfiguration().get(
"textinputformat.record.delimiter");
byte[] recordDelimiterBytes = null;
if (null != delimiter)
recordDelimiterBytes = delimiter.getBytes(Charsets.UTF_8);
return new LineRecordReader(recordDelimiterBytes);
}
@Override
protected boolean isSplitable(JobContext context, Path file) {
final CompressionCodec codec =
new CompressionCodecFactory(context.getConfiguration()).getCodec(file);
if (null == codec) {
return true;
}
return codec instanceof SplittableCompressionCodec;
}
}
当我们想要根据实际的业务需求自定义InputFormat的时候,最核心的工作就是要重写上面这两个方法,并且根据实际情况自定义个ReadRecorder类,改写读取记录以及生成key-value的方式。比如,面临处理大量小文件的场景,此时,就需要有相应解决方案。可以自定义InputFormat实现小文件的合并。
在执行每个map task时,无论map方法中执行什么逻辑,最终都是要把输出写到磁盘上。如果没有reduce阶段,则直接输出到hdfs上,如果有有reduce作业,则每个map方法的输出在写磁盘前线在内存中缓存。而无论输出到哪里,都需要创建对应的数据收集器来对map阶段处理之后的数据进行数据的收集操作。下面就是进行判断,当前job是否存在ReduceTask,如果不存在创建NewDirectOutputCollector对象;存在,则创建NewOutputCollector对象。
// get an output object
if (job.getNumReduceTasks() == 0) {
output =
new NewDirectOutputCollector(taskContext, job, umbilical, reporter);
} else {
output = new NewOutputCollector(taskContext, job, umbilical, reporter);
}
确定好数据收集器之后,继续向下执行。会创建mapcontext对象,将当前MapTask的读取记录对象、写出记录对象、切片对象等传入mapcontext类的实现类对象。然后创建mapperContext,它们主要是来跟踪map任务中task的状态,记录一下job的配置信息、以及执行的上下午信息,避免信息混乱。
org.apache.hadoop.mapreduce.MapContext<INKEY, INVALUE, OUTKEY, OUTVALUE>
mapContext =
new MapContextImpl<INKEY, INVALUE, OUTKEY, OUTVALUE>(job, getTaskID(),
input, output,
committer,
reporter, split);
org.apache.hadoop.mapreduce.Mapper<INKEY,INVALUE,OUTKEY,OUTVALUE>.Context
mapperContext =
new WrappedMapper<INKEY, INVALUE, OUTKEY, OUTVALUE>().getMapContext(
mapContext);
继续向下执行,input.initialize(split, mapperContext)方法是初始化ReadRecorder对象,将当前切片对象和mapper上下午对象传入其中,为输入做准备。
try {
input.initialize(split, mapperContext);
mapper.run(mapperContext);
mapPhase.complete();
setPhase(TaskStatus.Phase.SORT);
statusUpdate(umbilical);
input.close();
input = null;
output.close(mapperContext);
output = null;
}
mapper.run()方法开启了读取记录的操作,它会从切片中一条一条的读取记录到map方法中,这个map方法就是我们自定义的xxxMapper类中重写的map方法。context对象包含了readrecorder对象从切片中读取的记录。getCurrentKey、getCurrentValue方法即可获得一条记录的key和value。这个mapper是哪个对象呢?其实它就是我们在自定编写的驱动类里面通过job.setMapperClass(xxxxMapper.class)设置的。
public void run(Context context) throws IOException, InterruptedException {
setup(context);
try {
while (context.nextKeyValue()) {
map(context.getCurrentKey(), context.getCurrentValue(), context);
}
} finally {
cleanup(context);
}
}
进行自己编写的map方法处理以后,最后会将处理的数据写出,即:
context.write(k,v);
此处调用的write方法实际实在TaskInputOutputContextImpl对象调用的output.write方法:
/**
* Generate an output key/value pair.
*/
public void write(KEYOUT key, VALUEOUT value
) throws IOException, InterruptedException {
output.write(key, value);
}
这个output对象是在MapTask类中实例化的收集器对象,如下图所示。
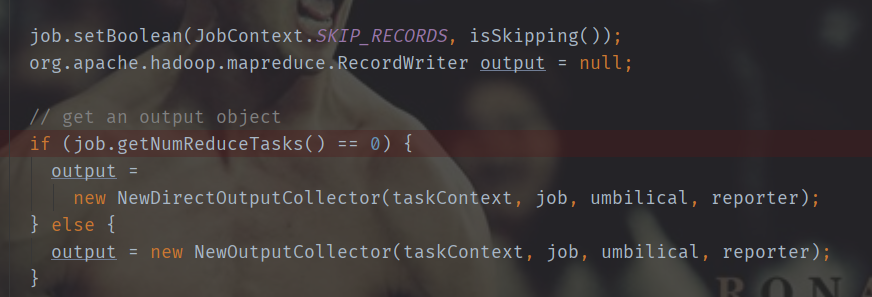
NewOutputCollector是一个MapTask的内部类,这个类主要就是负责当map处理完数据以后,负责收集map输出的数据到环形缓冲区,其中包含了总的分区数量、收集器等关键信息。
private class NewOutputCollector<K,V>
extends org.apache.hadoop.mapreduce.RecordWriter<K,V> {
private final MapOutputCollector<K,V> collector;
private final org.apache.hadoop.mapreduce.Partitioner<K,V> partitioner;
private final int partitions;
@SuppressWarnings("unchecked")
NewOutputCollector(org.apache.hadoop.mapreduce.JobContext jobContext,
JobConf job,
TaskUmbilicalProtocol umbilical,
TaskReporter reporter
) throws IOException, ClassNotFoundException {
collector = createSortingCollector(job, reporter);
partitions = jobContext.getNumReduceTasks();
if (partitions > 1) {
partitioner = (org.apache.hadoop.mapreduce.Partitioner<K,V>)
ReflectionUtils.newInstance(jobContext.getPartitionerClass(), job);
} else {
partitioner = new org.apache.hadoop.mapreduce.Partitioner<K,V>() {
@Override
public int getPartition(K key, V value, int numPartitions) {
return partitions - 1;
}
};
}
}
@Override
public void write(K key, V value) throws IOException, InterruptedException {
collector.collect(key, value,
partitioner.getPartition(key, value, partitions));
}
@Override
public void close(TaskAttemptContext context
) throws IOException,InterruptedException {
try {
collector.flush();
} catch (ClassNotFoundException cnf) {
throw new IOException("can't find class ", cnf);
}
collector.close();
}
}
可以看出,首先定义了收集器对象变量、分区对象变量、表示总分区数量的变量。下面是获取当前任务,总共的分区数量:
partitions = jobContext.getNumReduceTasks();
如果分区数量大于1的话,那么就需要将不同的键值对依据定义的分区规则分配到不同的分区当中,如果不大于1,那么就只有一个分区,所有的输出都会到一个分区里面。分区的数量决定了ReduceTask的数量,也决定了最终的输出文件有多少个。
简单的概括一下分为以下几个过程:
(1)Read阶段:MapTask通过用户编写的RecordReader,从输入InputSplit中解析出一个个key/value。
(2)Map阶段:该节点主要是将解析出的key/value交给用户编写map()函数处理,并产生一系列新的key/value。
(3)Collect收集阶段:在用户编写map()函数中,当数据处理完成后,一般会调用OutputCollector.collect()输出结果。在该函数内部,它会将生成的key/value分区(调用Partitioner),并写入一个环形内存缓冲区中。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号