HDFS的一些常用Shell操作
记录一下常用的HDFS的Shell操作命令,它们基本上与Linux命令相同,只不过使用的时候书写需要多点格式。
一定要先给hadoop添加了环境变量,才能像我下面这样在每个命令前面写上“hadoop fs”,当然也可以使用“hdfs dfs”作为前缀,但是使用这个前缀的时候必须在hadoop的根据录下,否则会提示找不到或者无法加载主类。而第一种,因为配置了全局环境变量,所以可以在任何位置使用。
那我们开始吧:
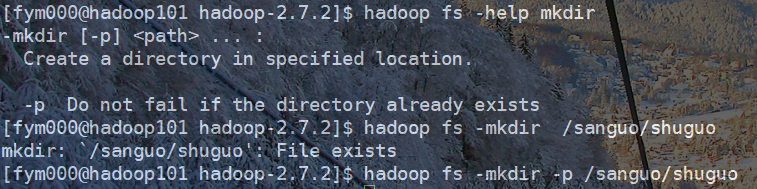
hadoop fs -mkdir -p <path>...
加上参数p,那么如果想要创建的文件夹存在了也不会返回错误提示,如果不加参数p,那么文件夹已存在时再执行上述命令,那么会返回失败提示。
hadoop fs -moveFromLocal <localsrc> <dst>
Same as -put, except that the source is deleted after it's copied. 将本地的源文件剪切到HDFS集群上边去。
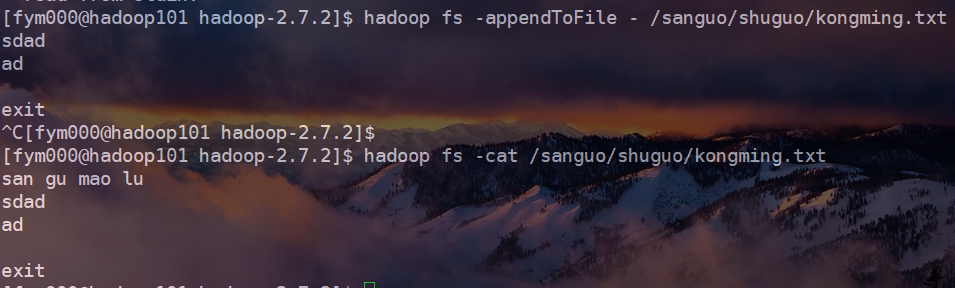
hadoop fs -appendToFile <localsrc> <dst>
将所有给定本地文件的内容追加到给定目的文件。 如果目的文件不存在,则将创建它。 如果本地源文件为“-”,则从标准输入中读取输入。(执行一个shell命令行时通常会自动打开三个标准文件,即标准输入文件(stdin),通常对应终端的键盘;标准输出文件(stdout)和标准错误输出文件(stderr),这两个文件都对应终端的屏幕。进程将从标准输入文件中得到输入数据,将正常输出数据输出到标准输出文件,而将错误信息送到标准错误文件中。)
将本地源文件内容追加到目的文件:

将标准输入的内容追加到目的文件,输入结束的时候按“ctrl+c”:
hadoop fs -cp [-f] [-p | -p[topax]] <src> ... <dst>
将与文件模式<src>匹配的文件复制到目标位置。复制多个文件时,目标位置必须是目录。
If -p is specified with no <arg>, then preserves timestamps, ownership, permission.
hadoop fs -mv <src> ... <dst>
将与指定的文件模式匹配的源文件移动到目的位置处。当移动多个文件的时候,目的位置必须是一个文件夹。
hadoop fs -get [-p] [-ignoreCrc] [-crc] <src> ... <localdst>
将与指定的文件模式匹配的源文件复制到本地指定的位置。复制后,源文件依旧被保留。使用参数“-p”时,会保留访问和修改时间,所有权和模式。
hadoop fs -getmerge [-nl] <src> <localdst>
获取目录中与源文件模式匹配的所有文件,然后合并并将它们整理为本地fs上的一个文件。
参数 -nl 表示在每个文件的末尾添加换行符。
hadoop fs -put [-f] [-p] [-l] <localsrc> ... <dst>
从本地文件系统中复制文件到集群中。如果没有添加参数“-f”,同时文件在集群中已经存在了,那么就会复制失败。如果添加了参数“-f”,那么在目的文件已经存在的时候会重写已经存在的文件。
参数-l表示,允许DataNode将文件延迟保存到磁盘。 强制复制因子为1。此标志将导致耐久性降低。
hadoop fs -tail [-f] <file>
Show the last 1KB of the file。
-f Shows appended data as the file grows.
hadoop fs -rm [-f] [-r|-R] [-skipTrash] <src> ...
-f 如果该文件不存在,则不显示诊断消息或修改退出状态以反映错误。
-[rR] 递归删除文件夹
hadoop fs -rmdir [--ignore-fail-on-non-empty] <dir> ...
删除每个目录参数指定的目录条目(如果为空)
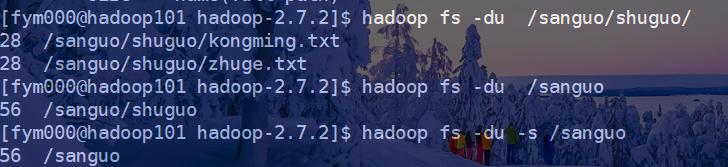
hadoop fs -du [-s] [-h] <path> ...
显示与指定文件模式匹配的文件使用的空间量(以字节为单位)。
-s 显示给定路径下总的大小,而不是每个单独文件的大小
-h 以易于人类阅读的方式(而不是字节数)格式化文件的大小。
请注意,没有-s选项,它仅显示目录深一层的总大小。
hadoop fs -setrep <path>
设置指定文件的副本数量,这里指定的副本数量是否真的有那么多还是需要看集群DataNode的数量,这里的这个副本数只是记录在NameNode的元数据中。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号