Bag of word based image retrieval
主要参考维基百科Bag of Word
在DLP领域里,bow(bag of word)是一个稀疏的向量,向量的每个元素记录词的出现次数,相当于对每篇文章都关于词典做词的直方图统计。同样的道理用在computer vision领域,图像由一些基础的特征构成,每幅图像就是对这些特征的一个统计分布,在做图像分类时会假设相似图像他们的特征统计分布也符合一定的模型。于是从这句话里就可以把以bow模型的图像分类问题分解成以下几步:
1.1 特征检测; 1.2 特征描述;1.3 码本生成(bow向量)
2.1 生成模型(Generative model)2.2 判别模型(Discriminate model)
1. 基于BoW模型的图像表达
在这里可以给bow进行一个简单的定义:图像独立特征的统计表达。【Histogram representation based on independent features】
1.1 特征检测
Content based image indexing and retrieval(CBIR)对特征提取进行了详细的介绍,这里需要指出的是特征检测是一个很初级的概念,得到具有区别性的区域,我们通常能写出显示形式的特征已经涉及到了特征表达部分。
1.2 特征表达
对于特征区域进行描述的方法称为特征表达,一个好的描述子应该具有强度/旋转/尺度/放射变化不变性。比较出名的就是SIFT算子,将每个特征块转换为128维的特征向量,而每幅图像就是一系列SIFT特征向量的集合。
1.3 码本生成
在BoW最后一步就是把SIFT特征向量用一个码元表示,就像是一个word。由于特征向量128维度,每个维度哪怕量化为8bit,最后的马元组合数也是8的128次方,过于巨大,所以一般的方式是对所有图像的SIFT特征进行K-means聚类,K即是最后的码本集合大小,码元就是聚类的中心,图像上的SIFT采用最近邻的方式映射到聚类中心。最后整幅图像就被表达为SIFT聚类中心(码元)的统计分布。
- 关于聚类这一点,在NLP也有一定的体现,只是不是用k-means的方法,而是stemming word得到一个词干作为码元,进行词干的统计。
- 以单个单词构成的码本维度大概是170,000个,去掉废弃词统计为100,000左右,但stem后应该只有10K左右吧(根据自己实验里遇到的情况,不一定正确)。
- 图像的BoW可以自己人工设定,一般在1K量级,视情况而定。
2. 基于BoW模型的分离器学习和识别
在我们得到一幅图像的表达后,就会考虑其在这种特征空间下具有什么样的分布特性,并根据分布特性设计分类器实现分类和识别。对应BoW模型的分类方法主要分为生成模型和判别模型两大主流。
2.1 生成模型
朴素贝叶斯模型,因为其简单有效,常常被用来作为baseline的方法。
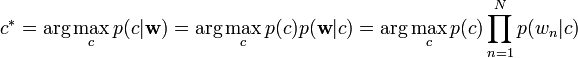
层次贝叶斯模型
由于朴素贝叶斯在一副图像包含了几个不同主题的情况下不能取得很好的效果,于是提出其他拓展,如潜语义分析 Probabilistic latent semantic analysis (pLSA)和主题模型 latent Dirichlet allocation (LDA)是比较著名的用作出来多主题的方法。
2.2 判别模型
由于图像被表达为BoW,所以适合适用于文档的判别模型都可以用来对图像的BoW进行分类。常见的有SVM和AdaBoost.
下一篇见BoW(SIFT/SURF/...)+SVM/KNN的OpenCV 实现

 浙公网安备 33010602011771号
浙公网安备 33010602011771号