

使用Requests模块进行微博爬虫教程【网络请求分析文档】
 一份爬取微博相关的接口文档,实现仅用requests模块对微博进行爬虫
一份爬取微博相关的接口文档,实现仅用requests模块对微博进行爬虫
写在前面
- 该文档是某课程实验需要而整理的,各个接口分析仅凭我个人理解,各个参数以及数据的含义也只是我个人的推测,如有错误的地方,欢迎在评论区或私信指正。
- 使用
Python对微博进行爬虫的方法有很多,Github上也有很多大神做好的爬虫程序可以拆箱即用。做这个接口分析只是我的个人爱好,另外我比较懒,不想研究怎样使用Selenium等框架,所以整理出一份可以仅仅使用Requests模块实现爬虫效果的文档,读者可以根据自己的需求进行使用。 - 文档内容都是我在浏览器中查看网络请求自行分析出来的,整理不易,转载请标明出处。
请求热搜
对web站请求如下URL即可
Method='GET'
https://weibo.com/ajax/statuses/hot_band
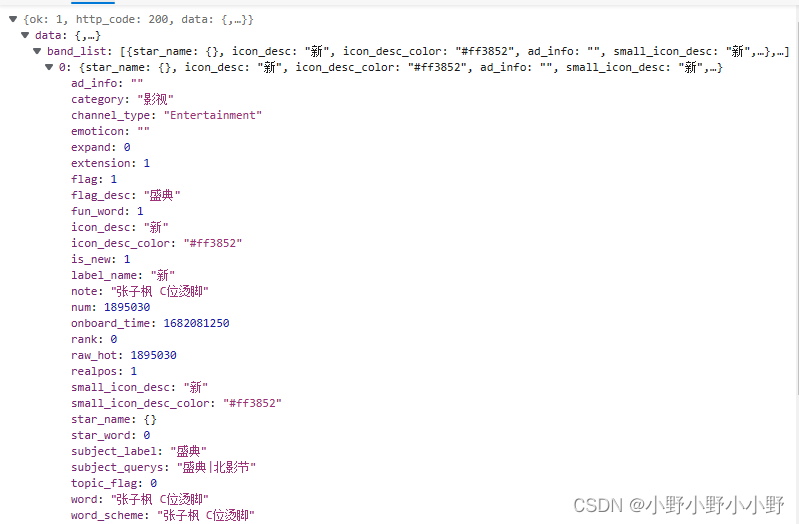
获得的数据如上图所示,band_list即为热搜列表,一条数据中包含了一些热搜的主要信息category是热搜包含内容的分类;note是词条内容;num大概是某个衡量热度的值(浏览量等等...),可以num越大的词条排的位置越靠前;其他信息可以按照类似的方法以及它的字面意思分析一下...
获取某个热搜下的内容
Method='GET'
https://m.weibo.cn/api/container/getIndex?containerid=231522type%3D1%26t%3D10%26q%3D%23词条的文字内容%23&luicode=10000011&lfid=100103type%3D38%26q%3D词条的文字内容%26t%3D0&page_type=searchall&page=页号
从请求热搜部分获得到的数据中包含word或note属性,将文本内容填入以上URL中即可,同时还可以指定页号。
以 https://m.weibo.cn/api/container/getIndex?containerid=231522type%3D1%26t%3D10%26q%3D%23中国星辰%23&luicode=10000011&lfid=100103type%3D38%26q%3D中国星辰%26t%3D0&page_type=searchall&page=1 这个URL举例,请求到的内容如下图所示:
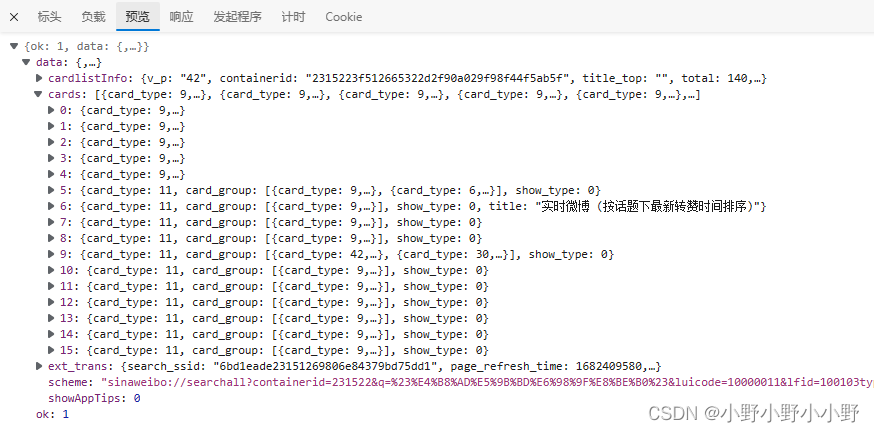
一般微博的内容都放在card_type为9的卡片中,通过循环遍历提取出card_type为9的卡片即可。
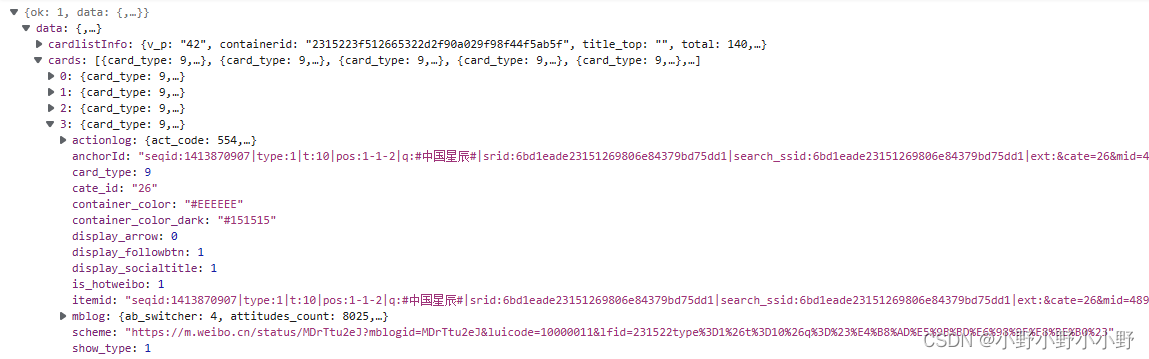
如上是其中一张卡片,对它分析:一般内容都存在mblog属性下,包含的内容非常多。
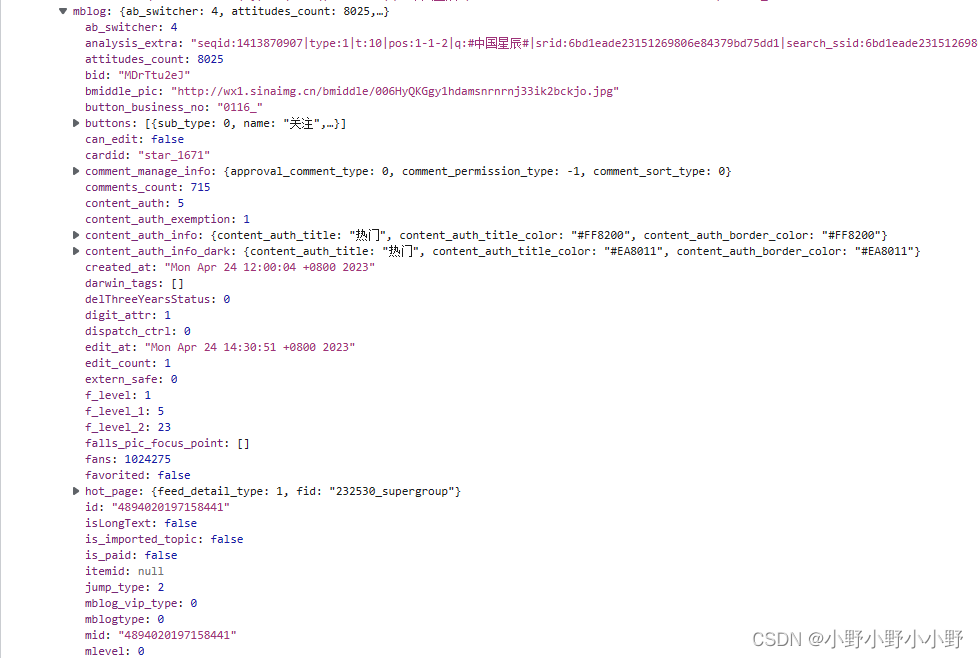

-
最重要的是
id和mid,这是这条微博的标识(貌似这两个值通常是相同的,用一个就可以了)。 -
isLongText是一个很重要的标志位,因为微博展示的时候对于很长的文本内容会做折叠,在末尾会显示"...展开全文"等样式。只有用户点击了这个链接才会再请求完整内容。这个标志位如果是false,那么想提取微博的文本内容直接拿这个卡片的text属性即可。如果它是true,那么text中就不包含文本的全部内容,需要请求另外的API接口,通过id即可获得到全部的文本内容,详见获取长微博的完整文本内容。 -
pic_flag代表这条微博是否包含了图片内容,值为1说明包含了图片,为0说明不含图片,相应地pic_num表示这条微博包含的图片数量,由此可以再看到pic_ids或pics,这两个属性包含的都是这条微博里图片的id,根据这些id即可请求相应的API接口获得到图片,详见获取图片。(建议:实际观察中发现,有些接口返回的数据中可能没有
pic_flag,所以使用pic_num是否为0来判断可能更稳一些)
另外,下面这个接口能根据微博ID获得一些信息,大部分与上面的数据内容类似:
Method='GET'
https://weibo.com/ajax/statuses/show?id=微博ID
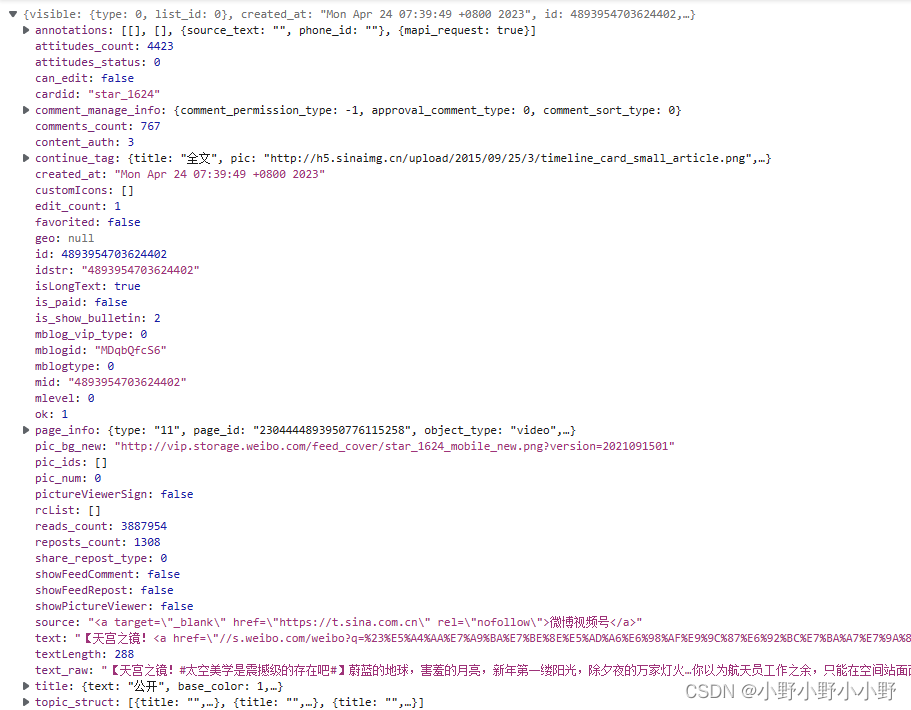
注意:有一点值得注意,如何判断一条微博是纯文本、含图片还是含视频呢?目前我的分析是这样的:这里获得的数据包,page_info只会出现在含视频的微博中,而对于纯文本和图片的微博是不含这个数据的。
于是可以采用这样的逻辑:含有page_info的是视频微博,不含page_info而pic_num不为0的为图片微博,不含page_info且pic_num为0的是纯文本的微博。
获取长文本
Method='GET'
https://m.weibo.cn/statuses/extend?id=微博ID
在获得卡片数据后,得到最重要的信息就是id,这应该是一条微博的唯一标识。获得id后填入上述URL即可获得到新的信息:
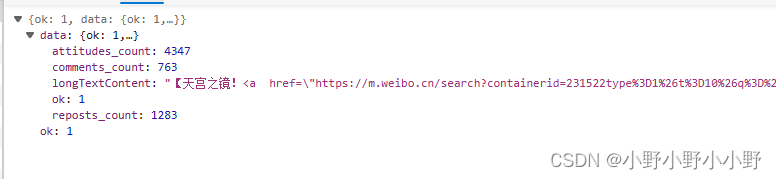
可以看到里面包含了longTextContext,这就是这条微博所有文本内容。另外三个属性分别是这条微博的点赞、评论、转发数量。
获取图片
第一种方法:
Method='GET'
https://wx4.sinaimg.cn/orj360/图片ID
如上所示,将服务器返回的内容保存即可。
另外一种方法(更推荐):
Method='GET'

如上图所示,在之前获得的card中,pics字段下直接包含着图片的URL,所以可以直接提取出这个URL进行图片获取。
更推荐使用第二种方法,因为上面那个根据ID请求图片是我自己分析得到的,不确定是不是每个ID都能在那个域下获得,而它包含的URL是准确的图片位置,只需再次请求就可以获得。
获取评论
获取评论分为获取第一组评论和获取后续评论。
第一部分
获取第一组评论的接口如下:
Method='GET'
https://weibo.com/ajax/statuses/buildComments?is_reload=1&id=4894355107612311&is_show_bulletin=2&is_mix=0&count=10&uid=5508233899&fetch_level=0
获取第一组评论的参数如下:
params = {
'is_reload': 1, # 是否重新加载数据到页面
'id': 4894355107612311, # 微博文章的id,可以在搜索页面中获得
'is_show_bulletin': 2,
'is_mix': 0,
'count': 10, # 推测是获取每页评论条数,但实际上返回的数据可能不是这个数量
'uid': 5508233899, # 发布这篇微博的用户id,根据测试这个参数可以不带
'fetch_level':0
}
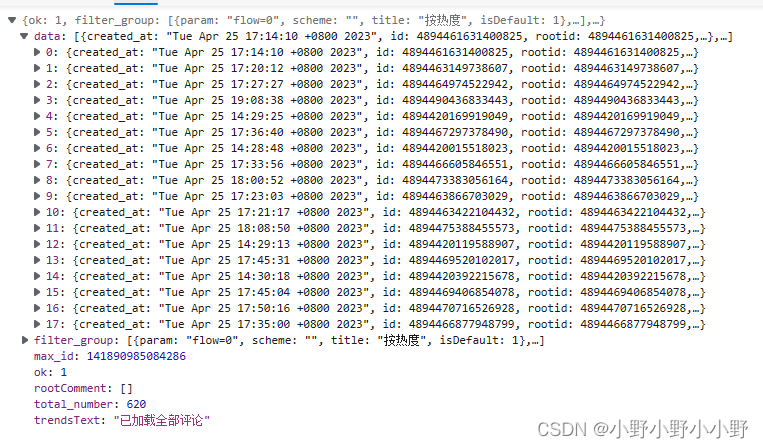
上图为请求到的数据,data是包含着一些评论的列表,从中可以获得到评论的各种信息。
max_id对于后续请求非常重要!!!
后续部分
获取后续评论的接口如下:
Method='GET'
https://weibo.com/ajax/statuses/buildComments?flow=0&is_reload=1&id=4894419260540402&is_show_bulletin=2&is_mix=0&max_id=138317572852662&count=20&uid=1878335471&fetch_level=0
获取后续评论的参数如下:
params = {
'flow': 0, # 根据什么获取,0为热度,1为发布时间
'is_reload': 1, # 是否重新加载数据到页面
'id': 4894419260540402, # 微博文章的id
'is_show_bulletin': 2,
'is_mix': 0,
'max_id': 138317572852662, # 用来控制页数的,这个可以在上一个数据包的响应的max_id
'count': 20, # 推测是获取每页评论条数
'uid': 1878335471, # 发布这篇微博的用户id,根据测试这个参数可以不带
'fetch_level':0
}
相较于“获取第一组评论”,这里的请求参数新增了flow,另外就是非常重要的max_id,这个参数是根据上一个响应数据得到的,也就是说要想继续请求数据,必须知道上一次响应数据中的max_id并拿来作为这次请求的参数。
注意:对于评论数较少的微博,请求完之后貌似返回的max_id是0,这可以作为评论是否爬完的标志。
获取某个用户的微博
分为请求第一部分和后续部分:
第一部分
第一部分URL如下:
Method='GET'
https://weibo.com/ajax/statuses/mymblog?uid=用户ID&page=1&feature=0
注意 :该请求需要添加请求头信息,其中需要附带cookie,获得方法是在浏览器控制台中查看网络请求,然后将请求头的cookie复制下来。另外要注意,cookie是有生命周期的,超过时间限制之后需要更新cookie。该请求如果不加cookie请求结果将不包含信息。
请求得到的响应数据如下所示:
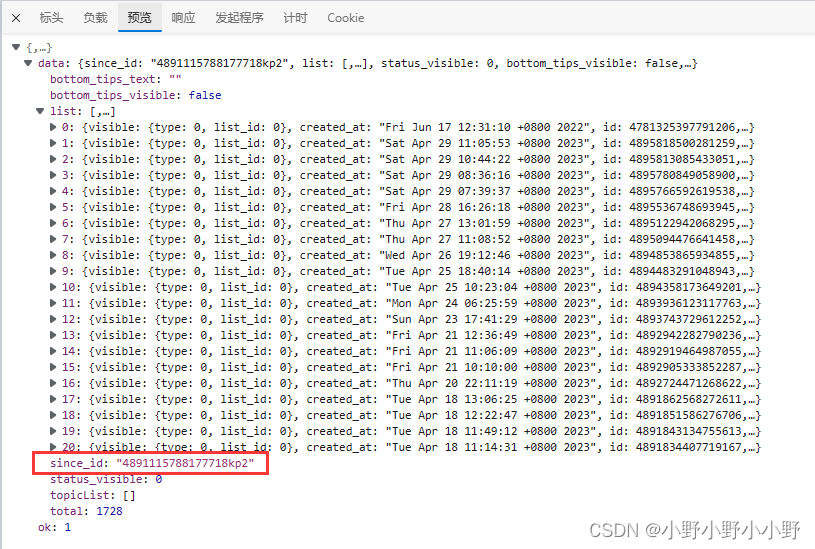
这里有一个后续请求需要使用到的参数since_id需要保存下来。然后list中包含的就是第一部分的各条微博内容。
补充 :经过测试,since_id可以不加,后续只改page就可以了。
后续部分
后续部分请求URL如下:
Method='GET'
https://weibo.com/ajax/statuses/mymblog?uid=用户ID&page=页号&feature=0&since_id=前一次请求的响应数据中的since_id
获取完全部微博的判断依据:看某次请求之后list是否为空了。(有的用户微博非常多,所以不建议一直获取完)
只改page就可以了。
后续部分
后续部分请求URL如下:
Method='GET'
https://weibo.com/ajax/statuses/mymblog?uid=用户ID&page=页号&feature=0&since_id=前一次请求的响应数据中的since_id
获取完全部微博的判断依据:看某次请求之后list是否为空了。(有的用户微博非常多,所以不建议一直获取完)


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· Manus的开源复刻OpenManus初探
· AI 智能体引爆开源社区「GitHub 热点速览」
· C#/.NET/.NET Core技术前沿周刊 | 第 29 期(2025年3.1-3.9)
· 从HTTP原因短语缺失研究HTTP/2和HTTP/3的设计差异