
可视化工具-kafka manager 与cerebro
一:可视化工具
生产环境上已经装了常用的基建,比如Kafka和ES等,但是这些基建的日常监控与运行情况却不直观,因此我们需要一些开源的可视化工具,方便我们去管理,
比如 kafka-manager 和 cerebro
二:kafka-manager
# kafka manager docker安装 docker pull sheepkiller/kafka-manager:latest docker run -d --rm --name kafka-manager -p 9401:9000 --net mynetwork --ip 172.18.0.49 -e ZK_HOSTS="172.18.0.37:2181" sheepkiller/kafka-manager:latest
直接在浏览器通过外网ip+端口号,直接访问kafka-manager
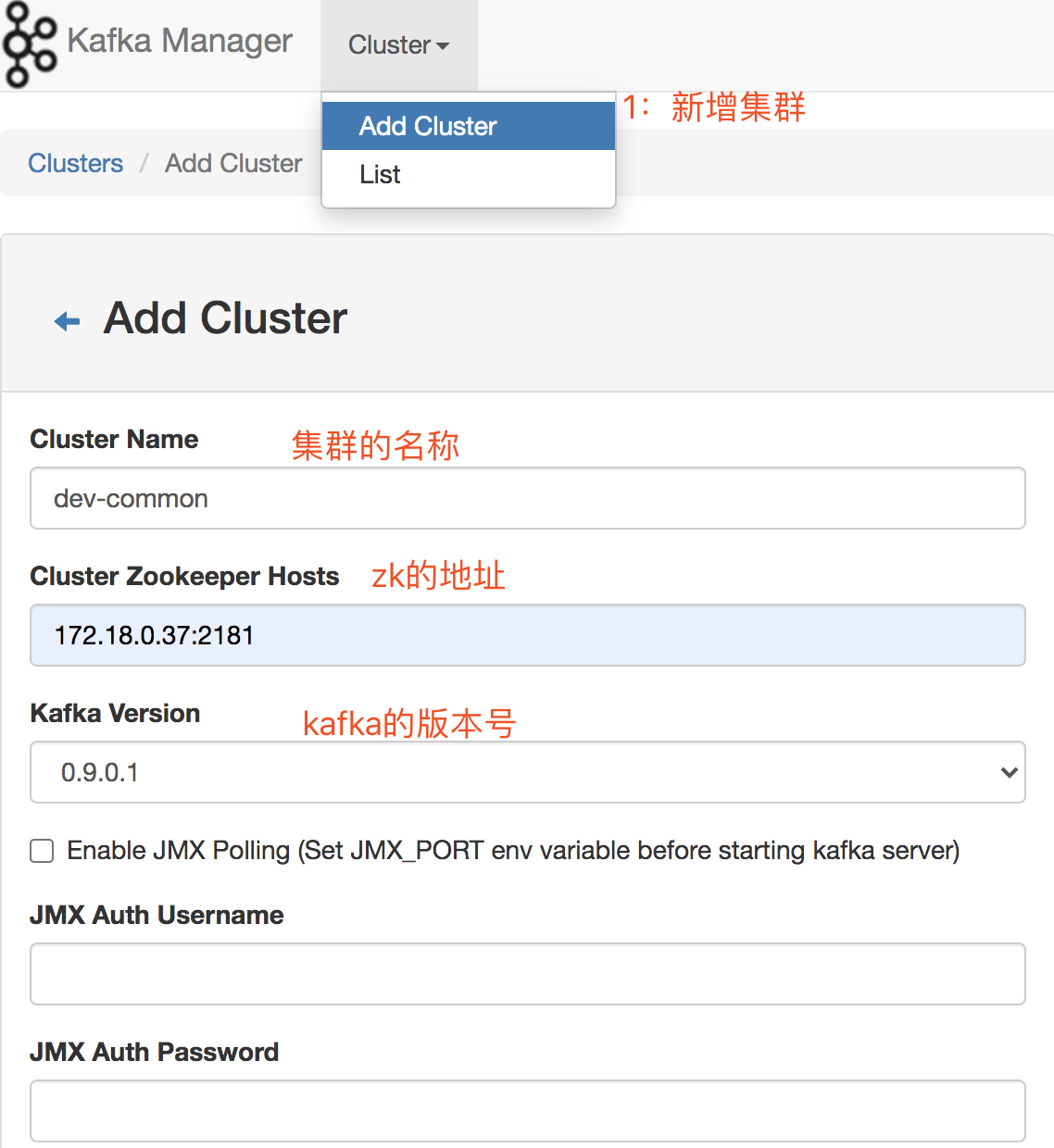
1:新增集群
2:进入集群
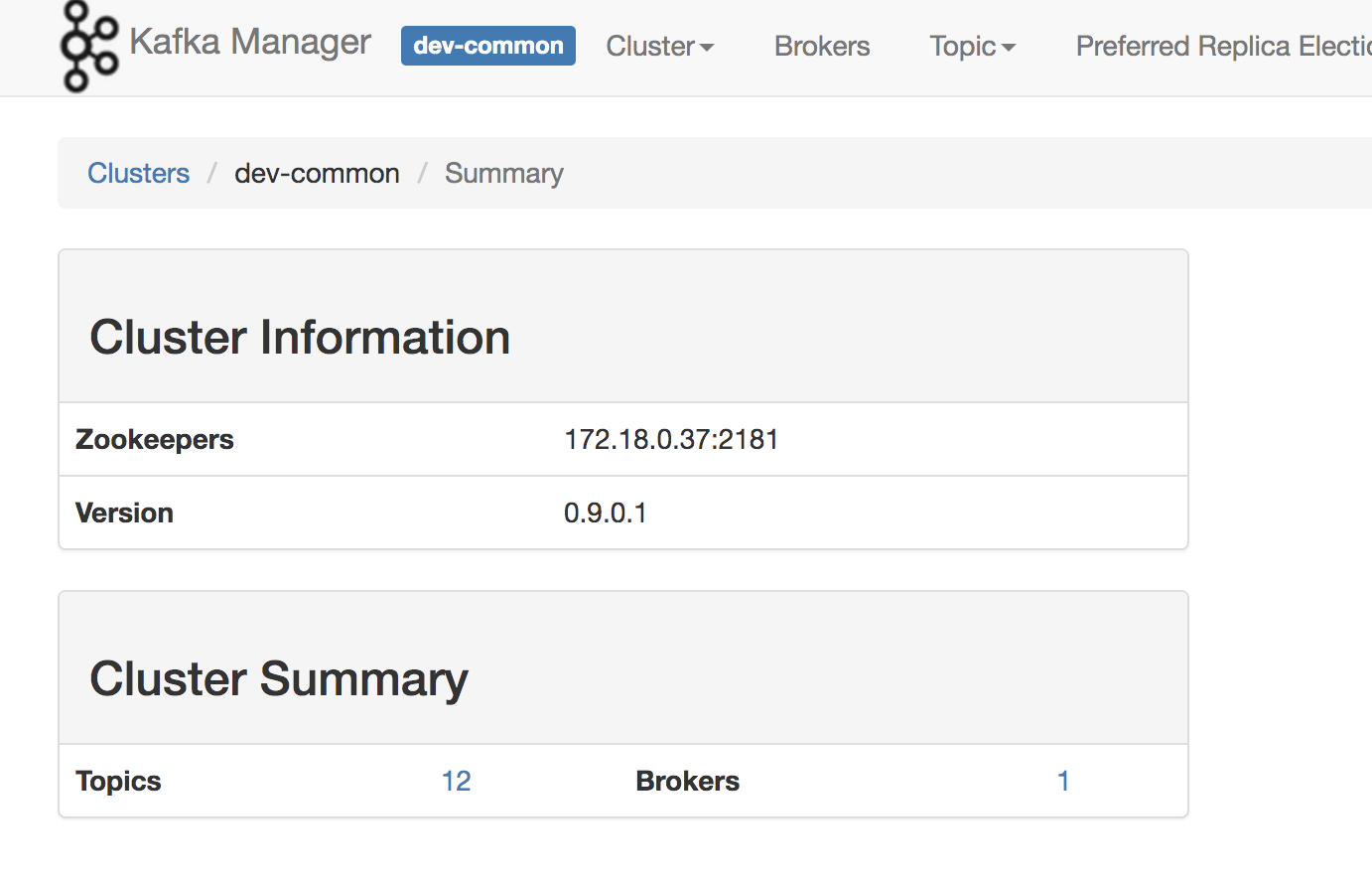
可以查看具体的主题
3:查询Topic信息
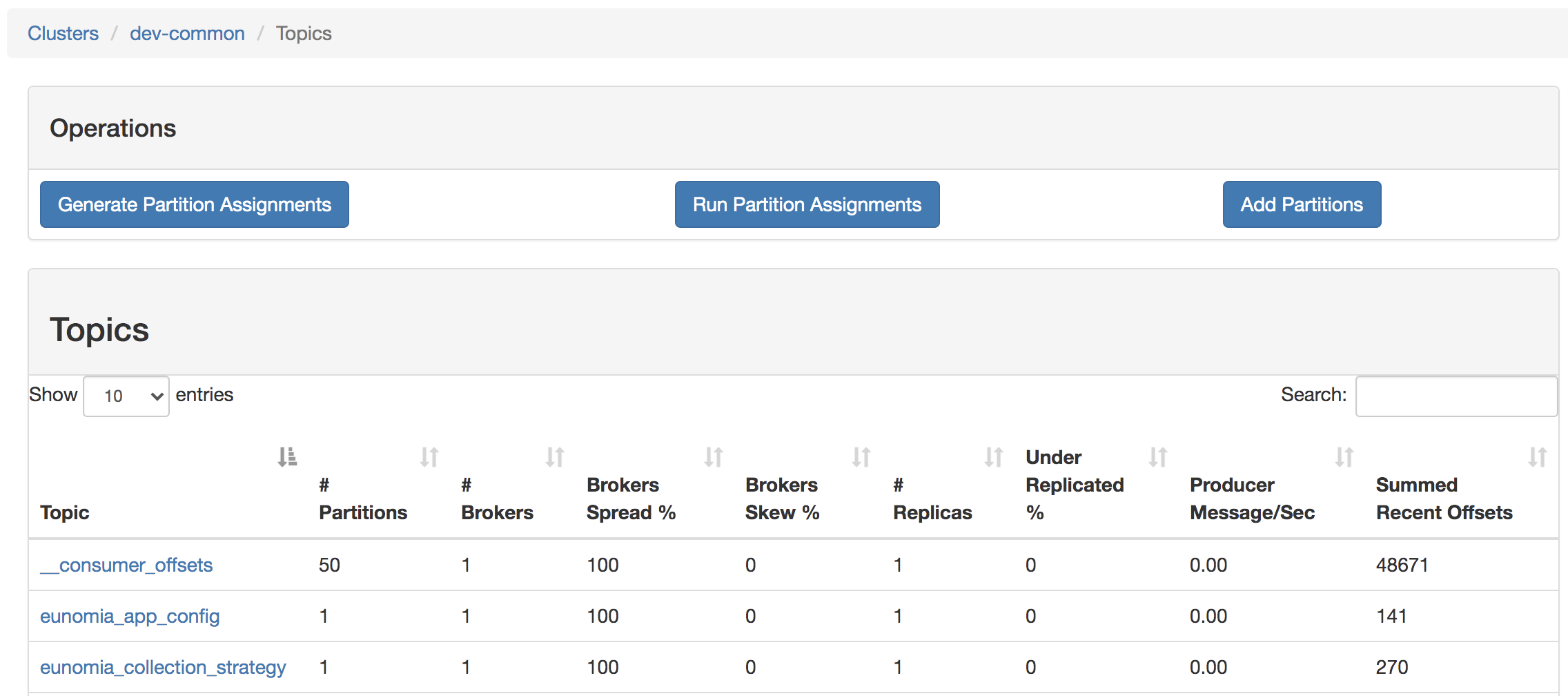
下面三个参数对于衡量 topic 的稳定性有重要的影响:
Broker Skew: 反映 broker 的 I/O 压力,broker 上有过多的副本时,相对于其他 broker ,该 broker 频繁的从 Leader 分区 fetch 抓取数据,磁盘操作相对于其他 broker 要多,
Broker Skew: 反映 broker 的 I/O 压力,broker 上有过多的副本时,相对于其他 broker ,该 broker 频繁的从 Leader 分区 fetch 抓取数据,磁盘操作相对于其他 broker 要多,
如果该指标过高,说明 topic 的分区均不不好,topic 的稳定性弱;
Broker Leader Skew:数据的生产和消费进程都至于 Leader 分区打交道,如果 broker 的 Leader 分区过多,该 broker 的数据流入和流出相对于其他 broker 均要大,
Broker Leader Skew:数据的生产和消费进程都至于 Leader 分区打交道,如果 broker 的 Leader 分区过多,该 broker 的数据流入和流出相对于其他 broker 均要大,
该指标过高,说明 topic 的分流做的不够好;
Under Replicated: 该指标过高时,表明 topic 的数据容易丢失,数据没有复制到足够的 broker 上。
Under Replicated: 该指标过高时,表明 topic 的数据容易丢失,数据没有复制到足够的 broker 上。
三:ES可视化工具-cerebro
# cerebro docker安装 docker pull lmenezes/cerebro:latest docker run -d --name cerebro -p 19000:9000 --net mynetwork --ip 172.18.0.59 lmenezes/cerebro:latest
同样通过外网ip+端口号访问,页面显示信息如下图
只需要输入ElasticSearch的URL,成功连接即可显示如下图所示信息。由于cerebro运行在容器中,直接输入localhost:9200即使通过浏览器能够访问也可能无法连接,
需要保证的是在cerebro的容器中能够访问到的URL,我这里使用的本机的IP http://172.16.0.53:9200 访问。
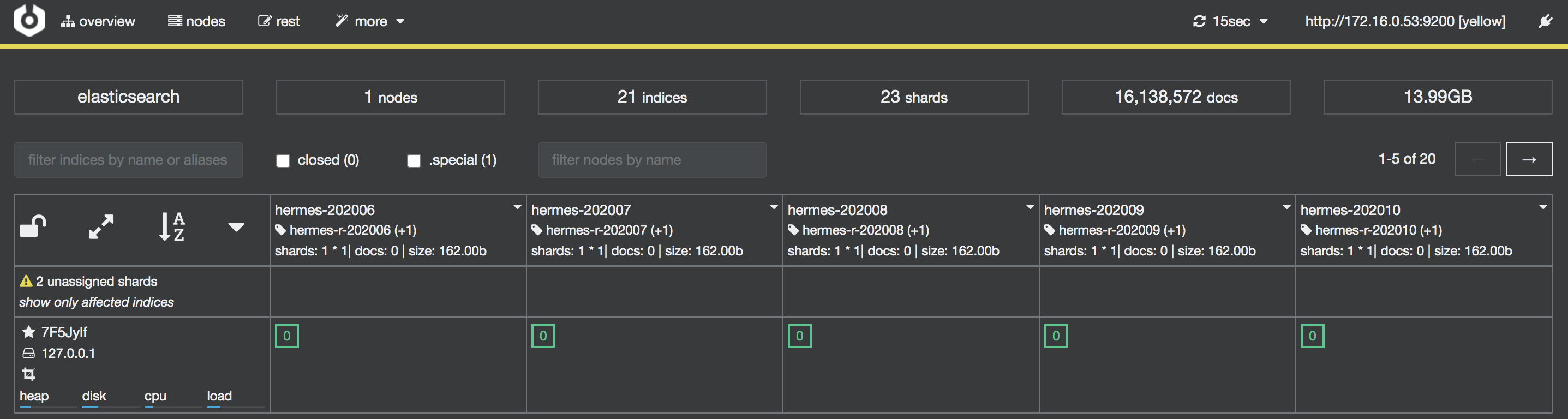
cerebro 就可以使用了。
四:参考文献
==================================================================
勇气是,尽管你感到害怕,但仍能迎难而上。
尽管你感觉痛苦,但仍能直接面对。
向前一步,也许一切都会不同。
==================================================================

