

自己动手做简易搜索引擎
搜索引擎是指根据一定的策略、运用特定的计算机程序从互联网上搜集信息,在对信息进行组织和处理后,为用户提供检索服务,将用户检索相关的信息展示给用户的系统。搜索引擎包括全文索引、目录索引、元搜索引擎、垂直搜索引擎、集合式搜索引擎、门户搜索引擎与免费链接列表等。百度和谷歌等是搜索引擎的代表。
如今网络的发展让我们的生活变得越来越丰富,但也带来了很多不便,要在偌大的网海中寻找我们需要的资料和数据,那简直就是一场灾难,更多的是无从下手。正如我们无法很快甚至无法从一个大型商场中找到我们想要的东东一样。(截止2012年06月30日,中国网民市场达到5.38亿,而域名注册数超过873万,实存网站250万。)在检索信息的时候,我个人比较喜欢百度,最初的原因是因为该网站的名字通俗易懂,简洁明了(其实是自己记忆力比较差,几乎只能记住类似www.baidu.com这样的网址,所以。。。),可能这也是当时百度创始人-李彦宏当时的初衷吧!不过后来并不是单纯的认为它简单明了,更重要的是他的设计更适合中国人的习惯吧,搜索到的结果总是那么的准确,于是总有人说,’有事没事找百度‘。百度的简洁也让其速度大大提升,这一系列的好处都在吸引着我去使用它。
说了这么多, 我相信大家日常生活中可能多多少少的接触过百度之类的网站吧,像我们这样搞计算机专业的估计更为频繁吧!其实,百度就是一个搜索引擎,我们每天都在使用搜索引擎,大家有没有思考过他到底是怎么工作的啊?
为了后期新项目的实施和搜索引擎原理的研究与探索,我决定制作一个简单的小型的搜索引擎,制作搜索引擎是一个很神奇的过程,为了整个项目的实施和部署,我先了解到我们平时使用搜索引擎搜到的东西其实并不是从网络上搜索到的,记得初二时我第一次使用电脑,打开百度搜索东西,当时看到百度上边统计的搜索使用的时间竟然是毫秒级的,瞬间就凌乱了,怎么会呢,我算了算,从我点击搜索键开始到结果出来总共用了大概5秒的时间(当时使用的是无线网卡),这么慢,怎么会是毫秒级呢,再说了,我搜索时需要搜索好多网站才能得到我想要的东西,饶一道圈后怎么会才使用不到一秒呢?当时就是这么疑惑,不过由于能力有限,没能仔细去研究。现在才知道,其实搜索引擎只是在对自己数据库中数据进行搜索查询和更新的,而我们在百度上看到的结果其实并不是网络上的,而是百度实现一条一条的下载下来,然后仔细研究分析等等,最后放到数据库中,等到我们使用百度进行搜索信息的时候,百度的工作只是从自己的数据库中检索到与我们所输入的信息最匹配的信息,然后显示到网页中来向我们展示搜索结果。
现在我们在来看百度,使用百度搜索信息的时候,我们不能只是输入一些个词语,而是经常输入一句话,百度是如何理解它的?这里就考虑到了一个分词,百度的中文分词技术,之前看过一篇博士论文上解释到,如果在百度上搜索 ’古希腊肉‘ 时,我们搜到的不是古希腊肉,因为没有这个东西,我们搜到的是关于古希腊的信息 ,而不是古希 腊肉,里边没有腊肉的信息,而且百度中的相关搜索也是一堆与古希腊有关的搜索提示,这说明了百度搜索引擎在搜索时对我们输入的数据进行了前向最大中文分词算法。当我们搜索 ’*安定军山‘时,百度却将此分词为‘* 安 定军山’,在此看来百度采用的算法也采用了人名和地名优先的算法,当然,百度的算法我们也不容易参透。这里讲这些主要是指搜索引擎在工作时需要一个分词技术,将一段生涩难懂的句子切成一个个比较容易理解的词语或短语,然后才会搜索数据库。
这时我们可能会疑惑数据库中的数据难道要人来一条一条的下载,导入吗?这个问题不用想,肯定不是了,除非百度老总有点傻,这里我会提到蜘蛛的概念,其实蜘蛛并不是一个陌生词,在我们的概念中可能蜘蛛只是一种生物,而且我们也都见过,甚至玩过,但是对于网络搜索引擎来说,蜘蛛并不是一种生物,而是一个小机器人,它负责没日没夜的通过链接在网络上爬行, 网页中的链接就好像是蜘蛛的网一样,蜘蛛不停的爬来爬去,同时从网页中提取关键字,重要信息,网址,然后将数据保存起来供用户查询。这样数据也有了,整个项目就可以部署了。
---对于搜索引擎来说,要抓取互联网上所有的网页几乎是不可能的,从公布的数据来看,容量最大的搜索引擎也不过是抓取了整个网页数量的百分之四十左右。这其中的原因一方面是抓取技术的瓶颈,无法遍历所有的网页,有许多网页无法从其它网页的链接中找到;另一个原因是存储技术和处理技术的问题,如果按照每个页 面的平均大小为20K计算(包含图片),100亿网页的容量是100×2000G字节,即使能够存储,下载也存在问题(按照一台机器每秒下载20K计算,需要340台机器不停的下载一年时间,才能把所有网页下载完毕)---
根据上边的分析,我已经有了大概的轮廓,已经可以开始编写我的搜索引擎了,这里我想到的是先制作一个简单的搜索引擎,只需要实现基本功能即可,项目中我使用了java进行开发,集成环境为My Eclipse,也就是蜘蛛和分词使用了java语言,网站前台使用了java ee的struts2框架,数据库采用开源数据库mysql,创建了一张建大你的数据表,简单记录数据信息,数据表如下图所示:

排序仅靠点击率做依靠(实际中一定不会这样写),先拍一只蜘蛛到网络上爬行检索网页信息,然后保存到这张表中,我已经收录了大约300个网页。
我的网站前台简单模仿百度 ,如图:
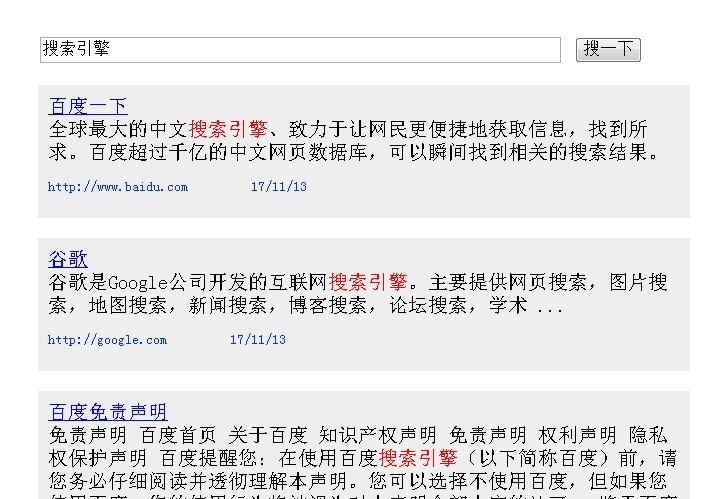
搜索结果:
具体程序解析就暂时不再说明(不早了,回家睡觉),有空再接着阐述,有需要讨论的可以联系我哦!
洛阳师范学院 信息技术学院
杨浩瑞 2013年11月18日记
我的网址是:http://www.yxxrui.cn

