Heap - Part I
1. 系统内存布局
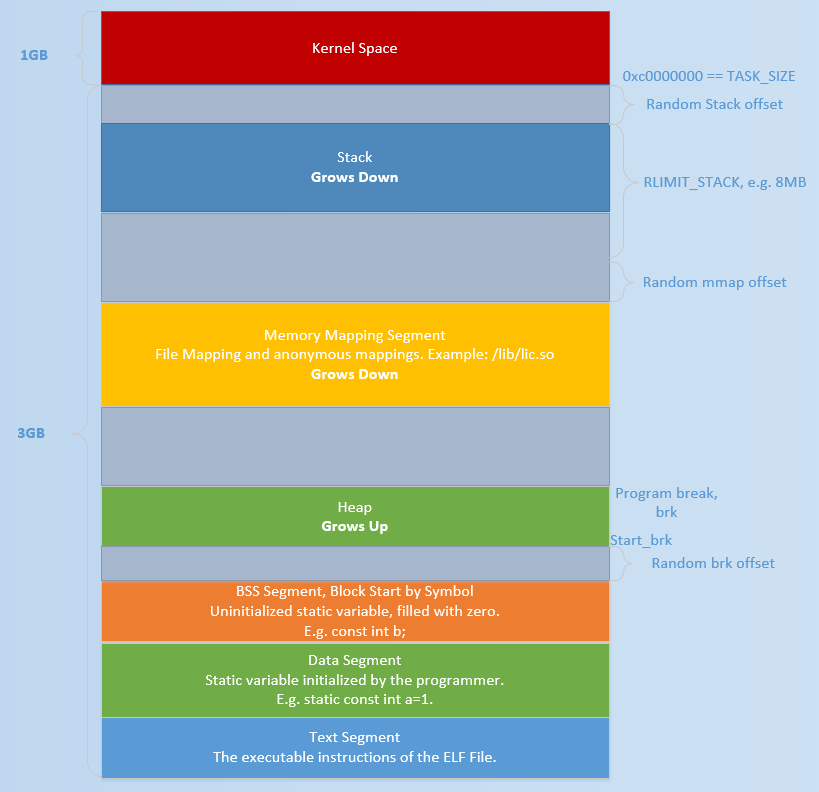
Linux 系统在装载 elf 格式的程序文件时,会调用 loader 把可执行文件中的各个段依次载入到从某一地址开始的空间中(载入地址取决 link editor(ld)和机器地址位数,在 32 位机器上是 0x8048000,即 128M 处)。如下图所示,以 32 位机器为例,首先被载入的是.text 段,然后是.data 段,最后是.bss 段。这可以看作是程序的开始空间。程序所能访问的最后的地址是 0xbfffffff,也就是到 3G 地址处,3G 以上的 1G 空间是内核使用的,应用程序不可以直接访问。
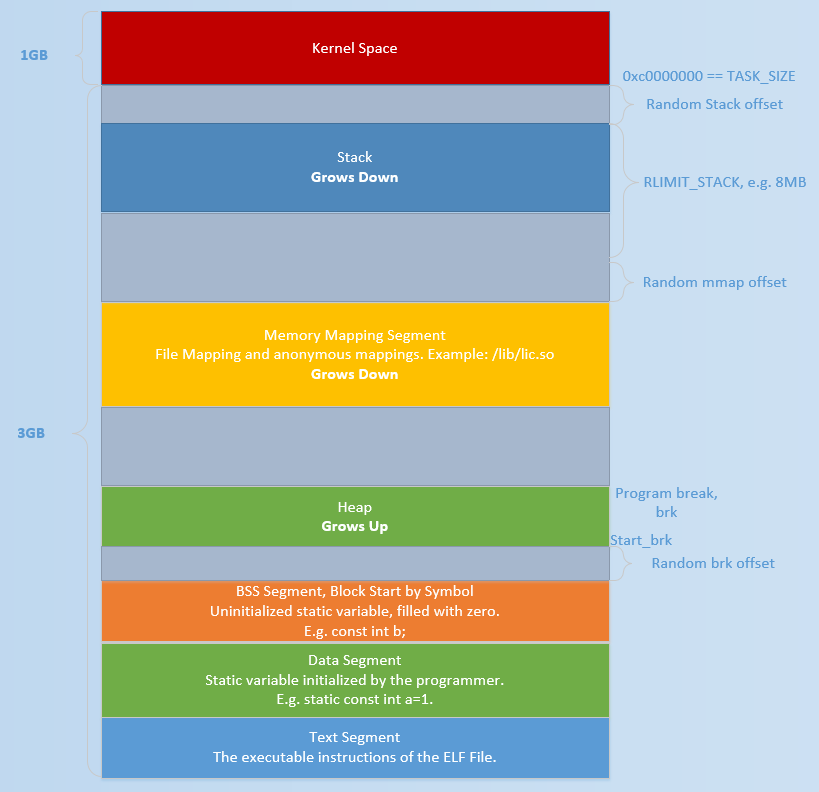
32位系统内存布局
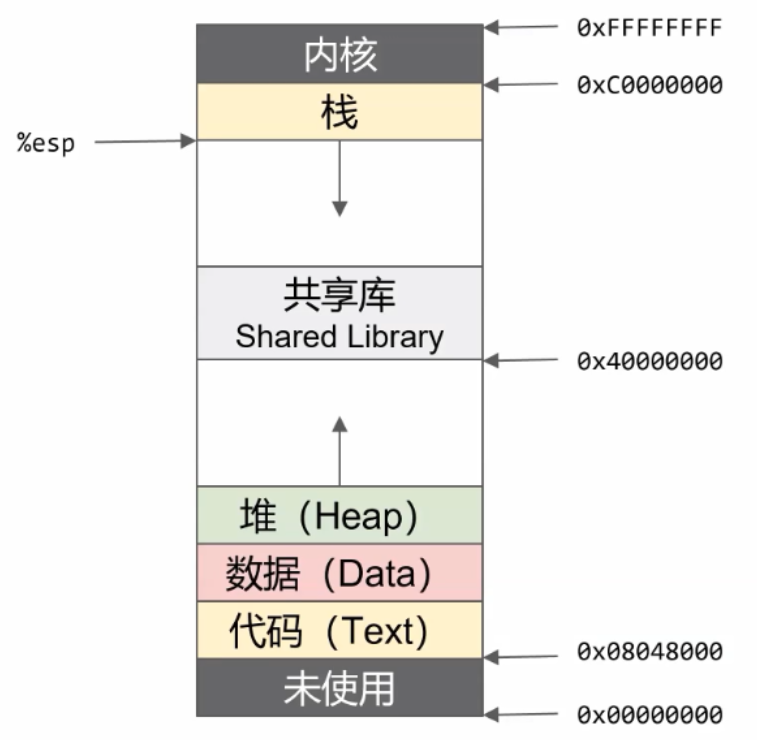
32位系统内存布局
-
bss段可看作data段的一部分。
-
.bss 段与栈之间的空间是空闲的,空闲空间被分成两部分:
-
一部分为 Heap(堆)。
- ASLR 关闭时,两者指向 data/bss 段的末尾,也就是
end_data - ASLR 开启时,两者指向 data/bss 段的末尾加上一段随机 brk 偏移
- ASLR 关闭时,两者指向 data/bss 段的末尾,也就是
-
一部分为mmap 映射区域。
- mmap 映射区域一般从 TASK_SIZE/3 的地方开始,但在不同的 Linux 内核和机器上,mmap 区域的开始位置一般是不同的。
-
-
Heap 和 mmap 区域都可以供用户自由使用,但是它在刚开始的时候并没有映射到内存空间内,是不可访问的。在向内核请求分配该空间之前,对这个空间的访问会导致segmentation fault。用户程序可以直接使用系统调用来管理 heap 和 mmap 映射区域,但更多的时候程序都是使用 C 语言提供的 malloc()和 free()函数来动态的分配和释放内存。Stack区域是唯一不需要映射,用户却可以访问的内存区域。
2. 堆和堆管理器
2.1 什么是堆
在程序运行过程中,Heap可以提供动态分配的内存,允许程序申请大小未知的内存。Heap其实就是程序虚拟地址空间的一块连续的线性区域,它由低地址向高地址方向增长。
2.2堆vs栈
-
栈通常用于为函数分配固定大小的局部内存。从高地址往低地址走。
-
堆是可以根据运行时的需要进行动态分配和释放的内存,大小可变。从低地址往高地址走。
-
malloc/new
-
free/delete
2.3 堆vs堆管理器
-
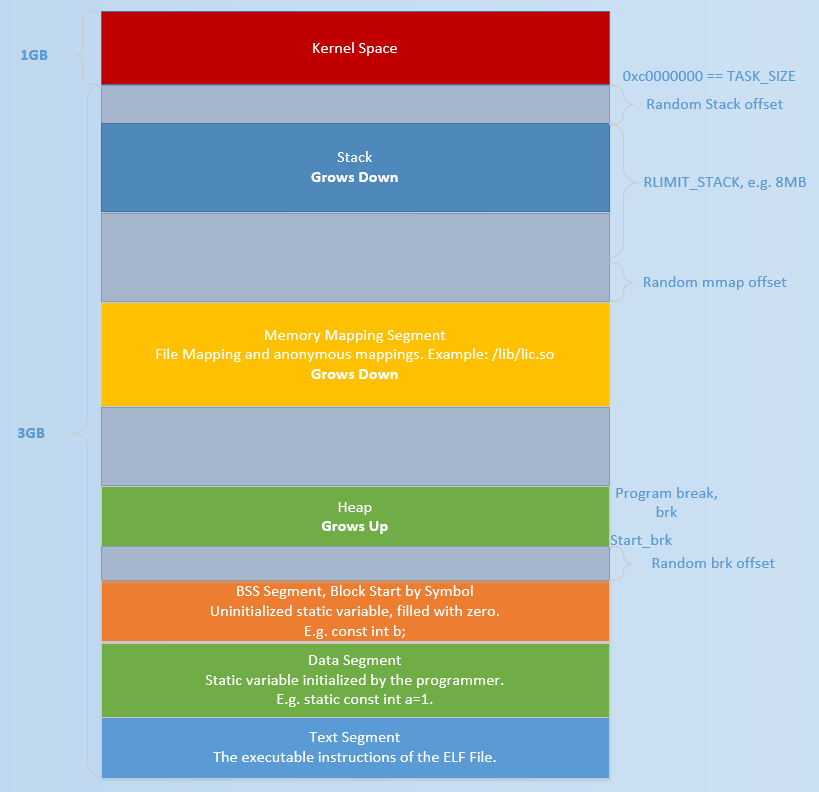
堆是虚拟地址空间中的一块连续的线性区域,是下图中绿色的部分(Heap)。
-
堆管理器并不是由操作系统实现,即不是处于下图Kernel Space(红色区域)中,而是存在于动态链接库中的一段代码,由libc.so.6链接库实现,即存在于黄色区域中。
-
堆管理器的功能就是管理堆,即管理这段绿色的区域(Heap)。
-
堆管理器介于程序和操作系统之间,作为动态内存管理的中间人。
- 响应程序的申请内存请求,向操作系统申请内存,然后将其返回给程序;
- 管理用户所释放的内存,适时归还给操作系统。
-
堆管理器封装了一些系统调用,为用户提供方便的动态内存分配接口的同时,力求高效地管理由系统调用申请来的内存。
- 申请内存的系统调用
- brk
- mmap
- 申请内存的系统调用
堆管理器的实现重点关注内存块的组织和管理方式,尤其是空闲内存块
- 如何提高分配和释放效率
- 如何降低碎片化,提高空间利用率
举例:浏览器的DOM树通常分配在堆上
- 堆管理器的实现算法影响堆分配网页加载和动态效果速度
- 堆管理器的实现算法影响浏览器对内存的使用效率
堆管理器将Heap视为一组不同大小的块(block)的集合来维护。每个块就是一个连续的虚拟内存片(chunk),要么是已分配的(Allocated Chunk),要么是空闲的(Free Chunk)。
- Allocated Chunk显示地保留,供应用程序使用
- Free Chunk可用来分配,保持空闲,直到它被释放,这种释放要么是应用程序显式执行的,要么是被内存分配器自身隐式地执行的。
堆管理器有两种基本风格(显示和隐式)。
-
相同之处:两种风格都要求应用显式地分配块。
-
不同之处:它们的不同之处在于由哪个实体来负责释放已分配的块。
- 显式管理器(explicit allocator),要求应用显式地释放任何已分配的块,如C的malloc程序包的显式分配器(malloc和free函数),C++的new和delete操作。
- 隐式管理器(implicit allocator),又叫垃圾收集器(garbage collection),如Java、Lisp之类的高级语言就依赖垃圾搜集器来释放已分配的块。
2.4 常见堆管理(分配)器
-
dlmalloc(Doug Lea Malloc) – 第一个被广泛使用的通用动态内存管理器;
-
ptmalloc2 - glibc
- 基于dlmalloc fork出来,在2006年增加了多线程支持
-
jemalloc - FreeBSD、Firefox、Android
-
tcmalloc - Google Chrome
-
libumem - Solaris
-
Windows 10 - segment heap
3. glibc的堆管理
我在学的时候,总是想先看一下大概的过程是怎样的,可先看到的资料大都是讲到哪里就直接讲所有细节,我自己觉得一上来直接看详细过程总是感觉学的费劲,看不下去。所以按照我自己的想法,在这里我只是介绍简单化的堆管理的整体,细节在下一篇介绍。
3.1 ptmalloc2的多线程支持
历史:ptmalloc2 基于 dlmalloc 开发,其引入了多线程支持,于 2006 年发布。发布之后,ptmalloc2 整合进了 glibc 源码,此后其所有修改都直接提交到了 glibc malloc 里。因此,ptmalloc2 的源码和 glibc malloc 的源码有很多不一致的地方。(1996 年出现的 dlmalloc 只有一个主分配区,该分配区为所有线程所争用,1997 年发布的 ptmalloc 在 dlmalloc 的基础上引入了非主分配区的概念。)
-
不同的线程维护不同的堆,称为per thread arena
-
主线程创建的堆,称为 main arena
-
Arena数量收到CPU核数的限制
- 32位:arena数量上限 = 2 * 核数
- 64位:arena数量上限 = 8 * 核数
3.2 内存块(chunk)
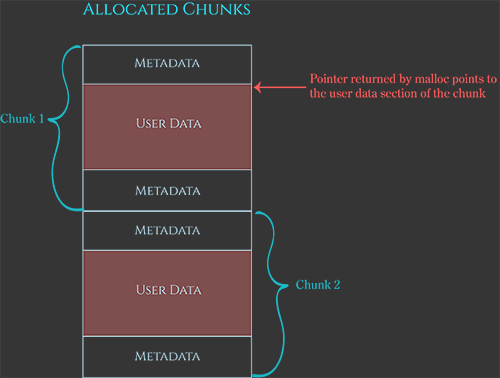
假设一个程序员通过malloc请求 10 byte的内存。为了满足这个请求,堆管理器需要做的不仅仅是找到一个随机的可写的10 byte 大小的内存区域。堆管理器还需要存储这个分配区相关的元数据(metadata),这个metadata存储在程序员能够利用的10byte内存区域的边上。
堆管理器需要确保分配的内存8byte对齐(32位系统)或者16byte对齐(64位系统)。
分配元数据和对齐填充的字节存储在malloc返回给程序员的内存区域边上。由于这个原因,堆管理器在内部分配的“chunk”内存比程序员最初要求的稍大。 当程序员要求10byte的内存时,堆管理器会找到或创建一个新的内存块,该内存块足以存储10byte的空间以及metadata和对齐填充字节。 然后,堆管理器将此chunk标记为“已分配”,并返回指向chunk内对齐的10byte“user data”区域的指针,程序员将其视为malloc调用的返回值。
1.内存对齐(Data Structure Alignment)是什么?
内存对齐,或者说字节对齐,是一个数据类型所能存放的内存地址的属性(Alignment is a property of a memory address)。
这个属性是一个无符号整数,并且这个整数必须是2的N次方(1、2、4、8、……、1024、……)。
当我们说,一个数据类型的内存对齐为8时,意思就是指这个数据类型所定义出来的所有变量,其内存地址都是8的倍数。
所以,堆管理器分配的内存8byte对齐(32位系统)或者16byte对齐(64位系统)指的就是分配的内存的起始地址都是8/16的倍数。
- 为什么要内存对齐?
原因有两种:
a. 并不是每一个硬件平台都能够随便访问任意位置的内存的。不少平台的CPU,比如Alpha、IA-64、MIPS还有SuperH架构,若读取的数据是未对齐的(比如一个4字节的int在一个奇数内存地址上),将拒绝访问,或抛出硬件异常。
b. 性能原因。考虑到CPU处理内存的方式(32位的x86 CPU,一个时钟周期可以读取4个连续的内存单元,即4字节),使用字节对齐将会提高系统的性能(也就是CPU读取内存数据的效率。比如CPU每次读数据都是从偶数地址开始读的,可你把一个int放在奇数内存位置上,想把这4个字节读出来,32位CPU就需要两次。但对齐之后一次就可以了)。
内存对齐相关资料:
C++的杂七杂八:关于内存对齐的那些事 https://orzz.org/about-data-structure-alignment/
C语言字节对齐问题详解 https://www.cnblogs.com/clover-toeic/p/3853132.html
内存对齐与补齐 字节对齐与结构体大小 https://www.cnblogs.com/kira2will/p/3655094.html
3.3 chunk的分配策略
我们首先来看一看经过高度简化的分配chunk的策略,这是对堆管理器所做的大部分工作。我将在后面详细解释每一个步骤。
- 如果有一个先前释放的内存chunk,并且该chunk足够大以满足请求,则堆管理器将使用该块进行新的分配;
- 否则,如果堆顶部有可用空间,则堆管理器将从顶部的可用空间分配一个新块并使用它;
- 否则,堆管理器将请求内核向堆的末端添加新内存,然后从这个新分配的内存空间中分配一个新块;
- 如果这些策略都失败了,则分配失败,并且malloc返回NULL。
3.3.1 从先前释放的chunk分配
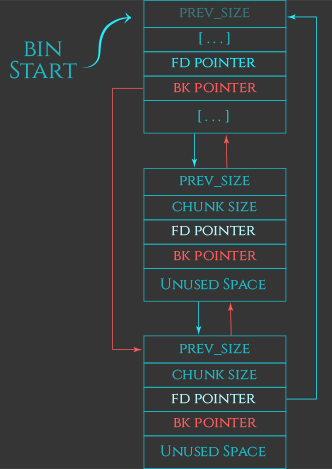
从概念上讲,分配先前释放的chunk非常简单,当内存被传递回空闲状态时,堆管理器会在一系列成为称为“bins”的不同链表中跟踪这些释放的chunk。当发出分配内存的请求时,堆管理器会在这些bins中搜索一个足够大的空闲chunk来服务该请求。如果它找到了一个,则可以从bin中删除这个chunk,将其标记为已分配,然后将指向该chunk的“user data”区域的指针作为malloc的返回值返回给程序员。
出于性能原因,有几种不同类型的bins:
- fast bins
- unsorted bin
- small bins
- large bins
- per-thread tcache
将在后面详细介绍它们。
3.3.2 从堆的顶部分配
如果没有可用的空闲chunk可以服务于分配请求,堆管理器就必须从顶部构造一个新的chunk。为此,堆管理器首先查看堆顶端的空闲空间(有时称为top chunk或者remainder chunk),看看那里是否有足够的空间。如果有,堆管理器将在此空闲空间中生成一个新chunk。如下图所示,top chunk分裂为两部分,一部分变成chunk 7 用于分配,另一部分变成新的top chunk。

3.3.3 请求内核向堆的末端添加新内存
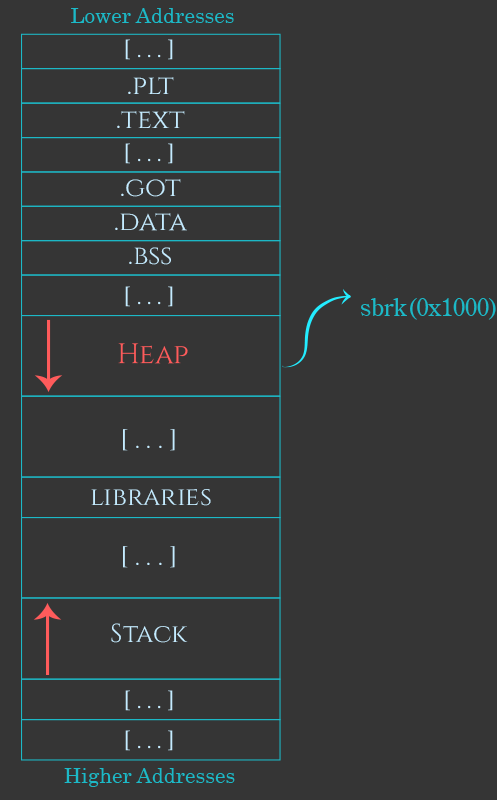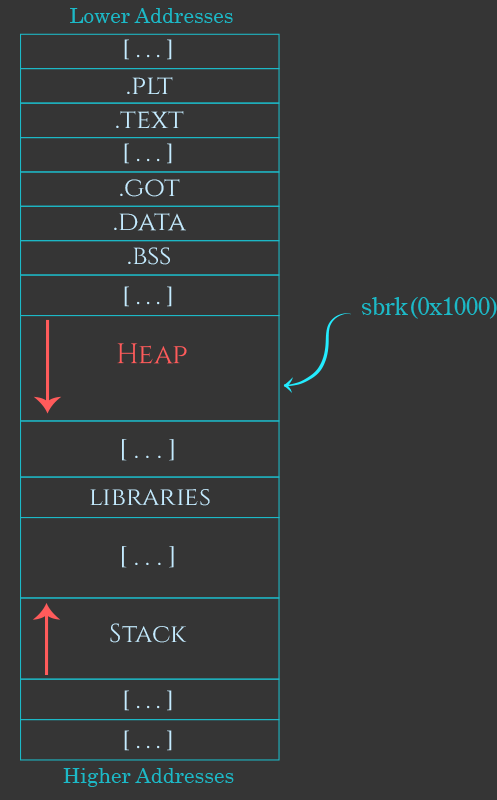
堆顶部的可用空间用完后,堆管理器将不得不请求内核在堆末尾添加更多内存。
在初始堆上,堆管理器通过调用sbrk要求内核在堆末尾分配更多的内存。 在大多数基于Linux的系统上,此函数在内部使用“ brk”这个系统调用。 这个系统调用的名称让人困惑,它最初的意思是“更改程序中断位置”,这是一种复杂的说法,它表示在程序加载到内存之后,相应的内存区域会增加更多的内存。 由于这是堆管理器创建初始堆的地方,因此,在这里brk的作用是在程序的初始堆末尾分配更多的内存。
最终,使用sbrk扩展堆将失败——堆最终将增长得太大,以至于进一步扩展将导致其与进程地址空间中的其他内容发生冲突,例如内存映射,共享库或线程的栈区域。 一旦堆达到这一步,堆管理器将调用mmap将新的非连续内存attach到初始程序堆中。
如果mmap也失败,则该进程将无法再分配任何内存,并且malloc返回NULL。
通过mmap进行堆外分配
很大的分配请求在堆管理器中会得到特殊处理。通过直接调用mmap在堆外分配这些大的chunk,并在chunk中的元数据里进行相应的标记。随后,当这些巨大的分配通过调用free返回给堆管理器时,堆管理器通过munmap将整个mmaped区域释放回给系统。
以上有部分内容是翻译自 https://azeria-labs.com/heap-exploitation-part-1-understanding-the-glibc-heap-implementation/
4. malloc、sbrk和free函数
此处描述这几个函数的功能,具体分配内存细节将在后面描述。
4.1 malloc函数
#include<stdlib.h>
void *malloc(size_t size);
在32位系统中size_t是4字节的,而在64位系统中,size_t是8字节的。
-
返回值
-
成功分配:malloc函数返回一个指针,指向大小为至少size字节的内存块,这个块会为可能包含在这个块内的任何数据对象做对齐。对齐依赖于编译代码在32位模式还是在64位模式中运行。
- 32位:malloc返回的块的地址总是8的倍数;
- 64位:malloc返回的块的地址总是16的倍数。
-
失败:如果malloc遇到问题(比如程序要求的内存块比可用的虚拟内存还要大),那么它就返回NULL,并设置errno。
-
-
不进行初始化
- malloc不初始化它返回的内存。
- 若想初始化的动态内存,可使用calloc。calloc是一个基于malloc的瘦包装函数,它将分配的内存初始化为零。
- 想要改变一个以前已分配块的大小,可以使用realloc函数。
4.2 sbrk函数
#include<unistd.h>
void *sbrk(intptr_t incr);
-
功能
- 通过将内核的brk指针增加incr来扩展和收缩堆。
-
返回值
- 成功:返回旧的brk指针
- 失败:返回-1,并将errno设置为ENOMEM。
-
参数
- 如果incr为正,扩展。
- 如果incr为0,那么sbrk就返回brk的当前值;
- 如果incr为负,收缩,返回值(brk的旧值)指向距新堆顶向上abs(incr)字节处
4.3 free函数
#include<stdlib.h>
void free(void *ptr);
4.4 案例分析
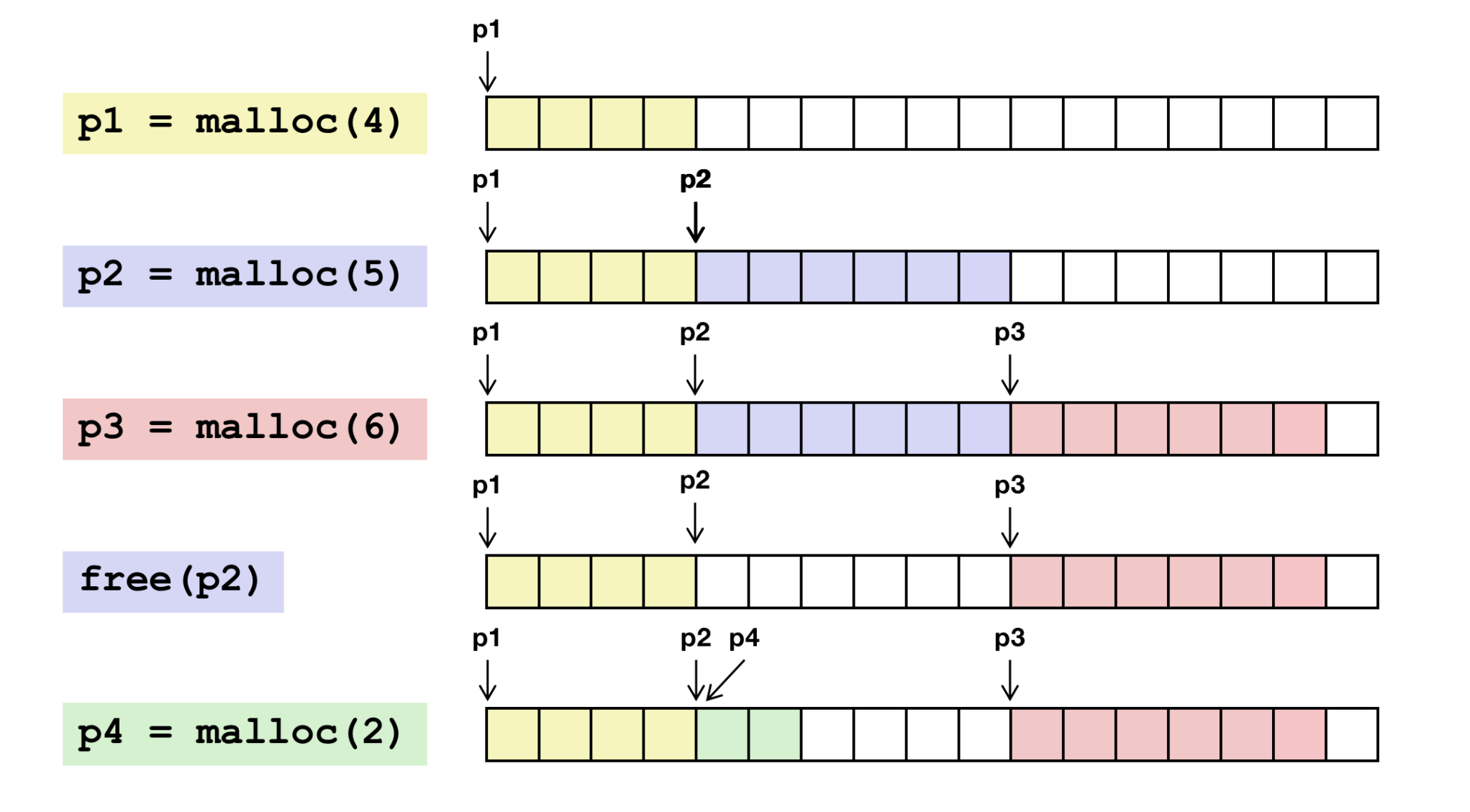
初始:堆是由一个大小为16个字的、双字对齐的、空闲的块组成的(假设分配器返回的块是8字节双字边界对齐的)。每个方框代表了一个4字节的字。
-
初始:堆是由一个大小为16个字的、双字对齐的、空闲的块组成的。
-
程序请求一个4字的块。
malloc的响应是:从空闲块的前部切出一个4字的块,并返回一个指向这个块的第一字的指针。
-
程序请求一个5字的块。
malloc的响应是:从空闲块的前部分配一个6字的块。
-
程序请求一个6字的块。
malloc的响应是:从空闲块的前部切出一个6字的块。
-
程序释放步骤3中分配的6字的块。
注意:在调用free返回之后,指针p2仍然指向被释放了的块。应用有责任在它被一个新的malloc调用重新初始化之前,不再使用p2。
-
程序请求一个2字的块。
在这种情况下,malloc分配在前一步中被释放了的块的一部分,并返回一个指向这个新块的指针
- 程序请求一个5字的块时,malloc为什么分配了6个字?
malloc在块里填充了一个额外的字,是为了保持空闲块是双字边界对齐的。
5. brk和mmap函数
内存分配背后的系统调用:malloc本质上是通过系统调用brk或者mmap实现的。
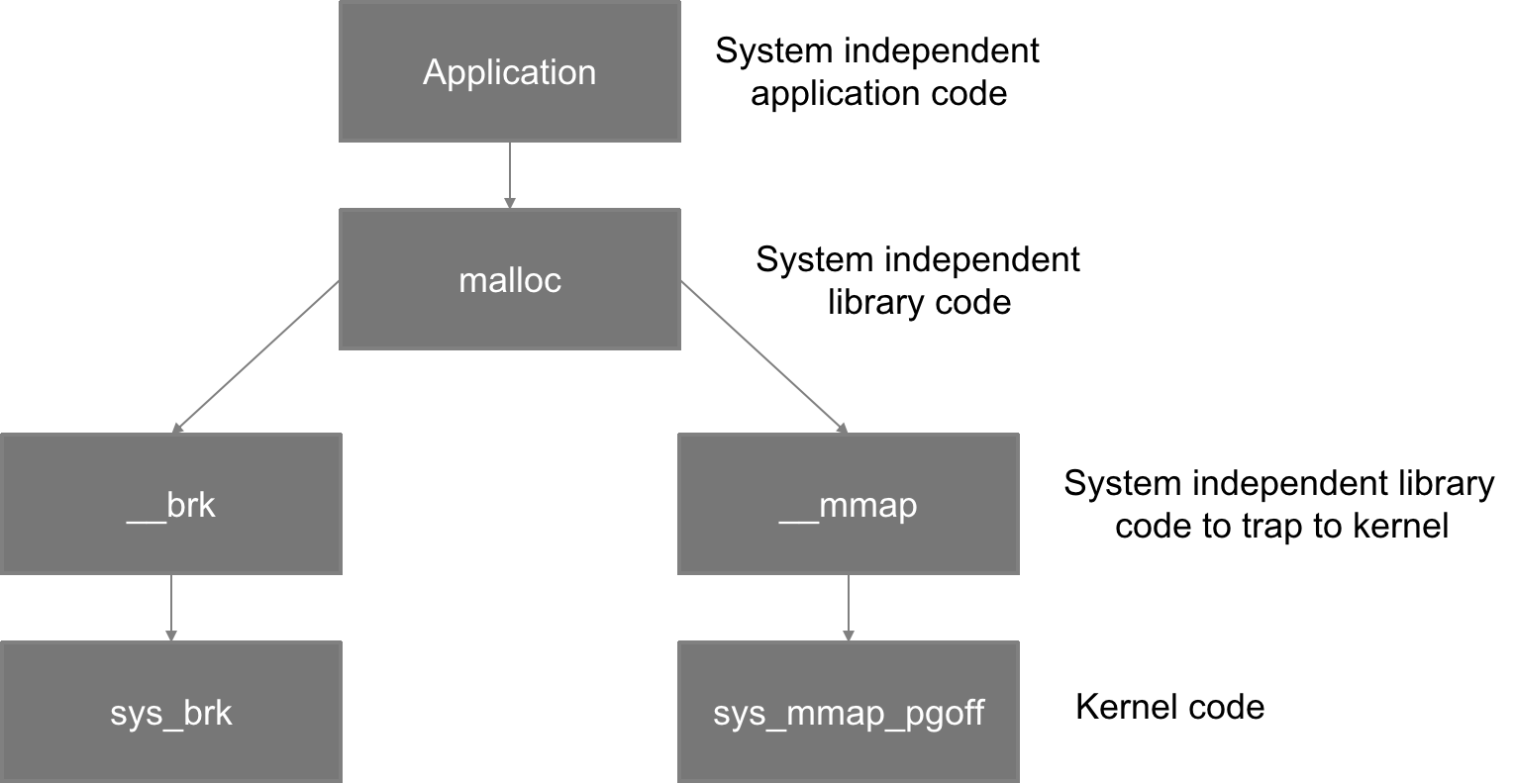
Heap 操作函数主要有两个:
- brk()为系统调用
- sbrk()为 C 库函数。
系统调用通常提供一种最小功能,而库函数通常提供比较复杂的功能。glibc 的 malloc 函数族(realloc,calloc 等)就调用 sbrk()函数将数据段的下界移动,sbrk()函数在内核的管理下将虚拟地址空间映射到内存,供 malloc()函数使用。
内核数据结构 mm_struct 中的成员变量:
- start_code 和 end_code,是进程代码段的起始和终止地址
- start_data 和 end_data,是进程数据段的起始和终止地址
- start_stack,是进程栈段起始地址
- start_brk,是进程动态内存分配起始地址(堆的起始地址)
- brk(堆的当前最后地址),就是动态内存分配当前的终止地址。
5.1 brk
C 语言的动态内存分配基本函数是malloc(),在 Linux 上的实现是通过内核的 brk 系统调用。brk()是一个非常简单的系统调用,只是简单地改变 mm_struct 结构的成员变量 brk 的值。即通过增加 brk 的大小来向操作系统申请内存。
初始时,堆的起始地址 start_brk 以及堆的当前末尾 brk 指向同一地址。根据是否开启 ASLR,两者的具体位置会有所不同,具体效果如上面系统内存布局图所示。
- 不开启 ASLR 保护时,start_brk 以及 brk 会指向 data/bss 段的结尾。
- 开启 ASLR 保护时,start_brk 以及 brk 也会指向同一位置,只是这个位置是在 data/bss 段结尾后的随机偏移处。
这两个函数的定义如下:
#include <unistd.h>
int brk(void *addr);
void *sbrk(intptr_t increment);
5.1.1 实验
实验环境:Ubuntu 16.04 x64
- brk_example.c
#include <stdio.h>
#include <unistd.h>
#include <sys/types.h>
int main()
{
void *curr_brk, *tmp_brk = NULL;
printf("Welcome to sbrk example:%d\n", getpid());
/* sbrk(0) gives current program break location */
tmp_brk = curr_brk = sbrk(0);
printf("Program Break Location1:%p\n", curr_brk);
getchar();
/* brk(addr) increments/decrements program break location */
brk(curr_brk+4096);
curr_brk = sbrk(0);
printf("Program break Location2:%p\n", curr_brk);
getchar();
brk(tmp_brk);
curr_brk = sbrk(0);
printf("Program Break Location3:%p\n", curr_brk);
getchar();
return 0;
}
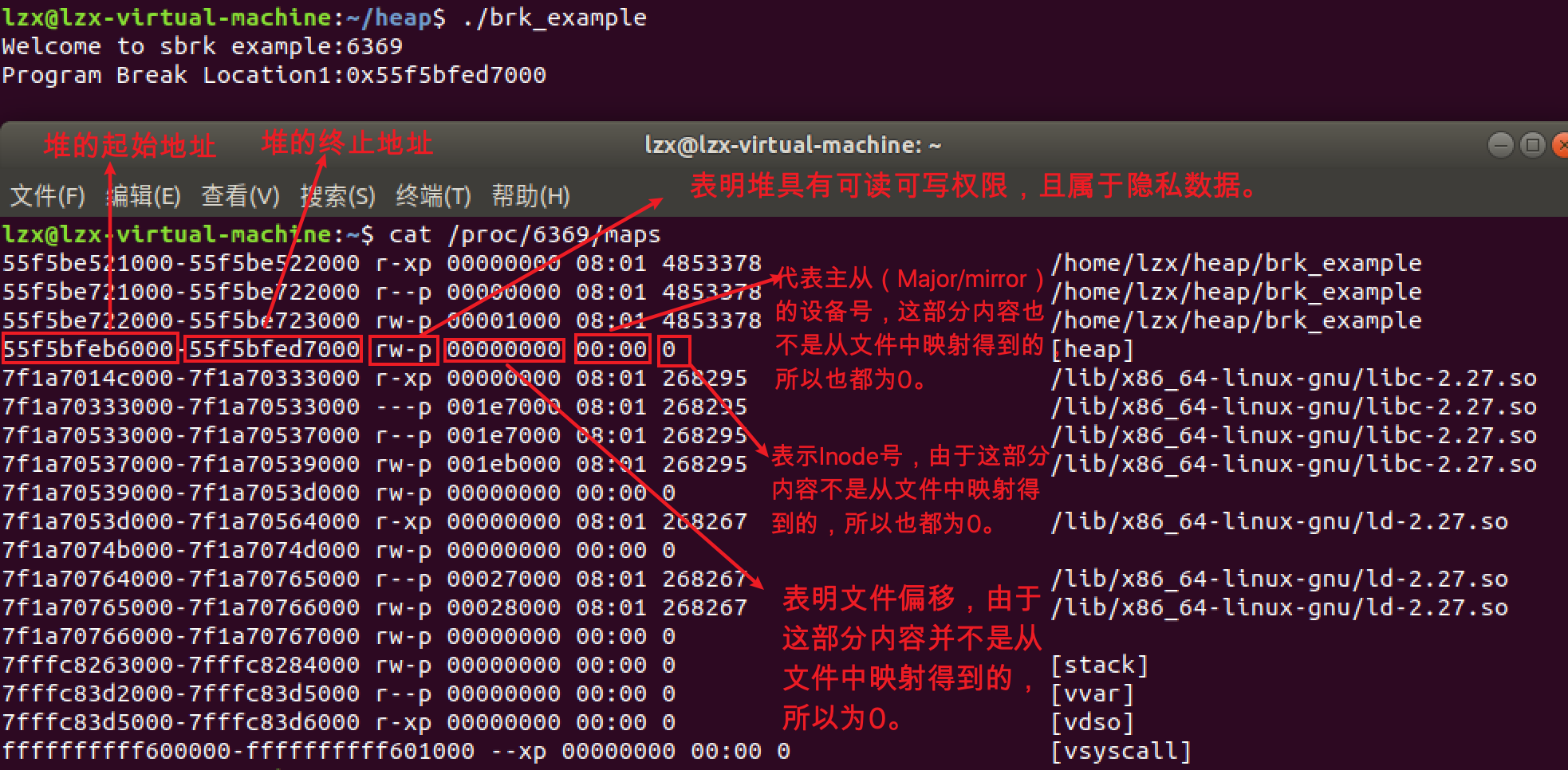
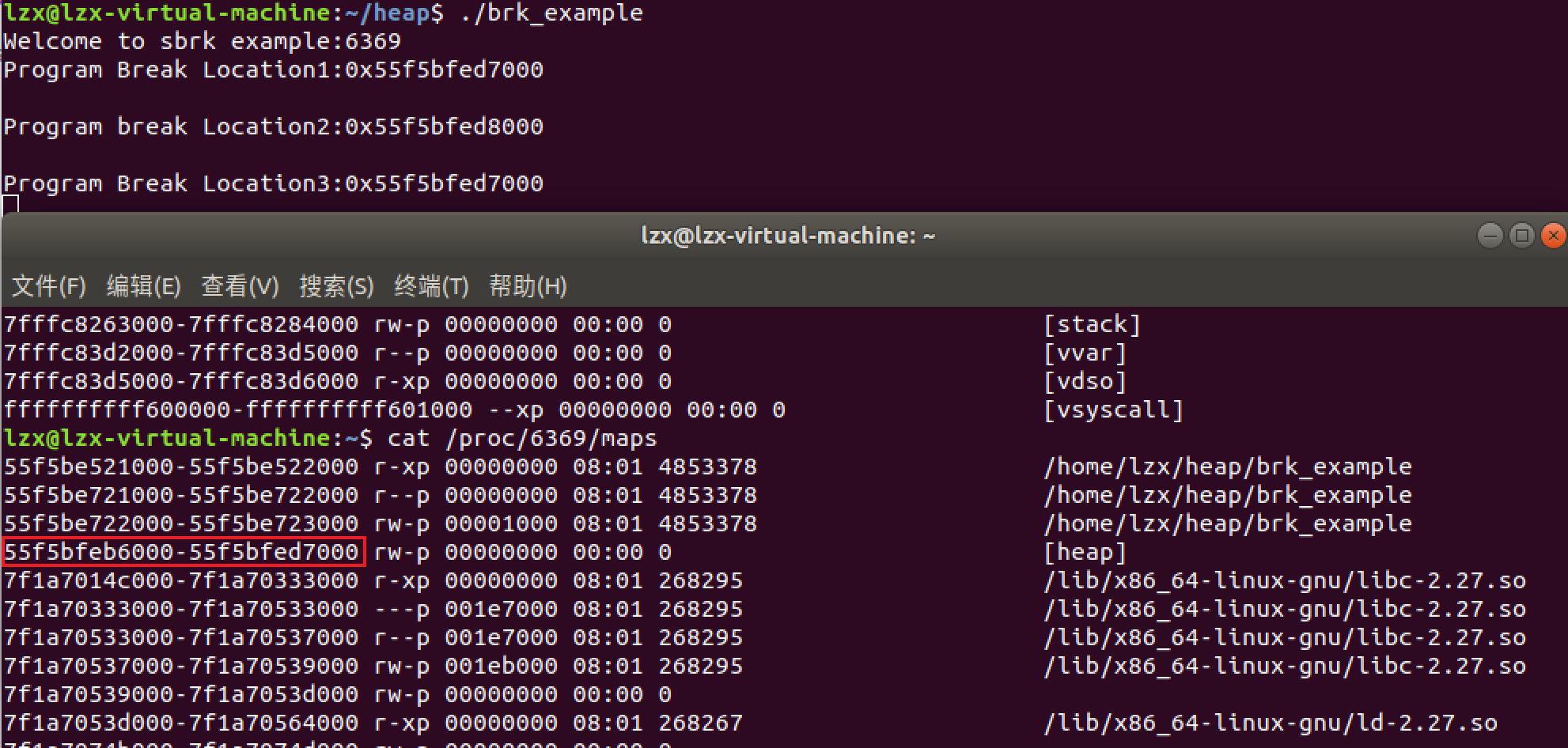
步骤一:第一次调用 brk() 之前,brk的值为:brk = 0x55f5bfed7000
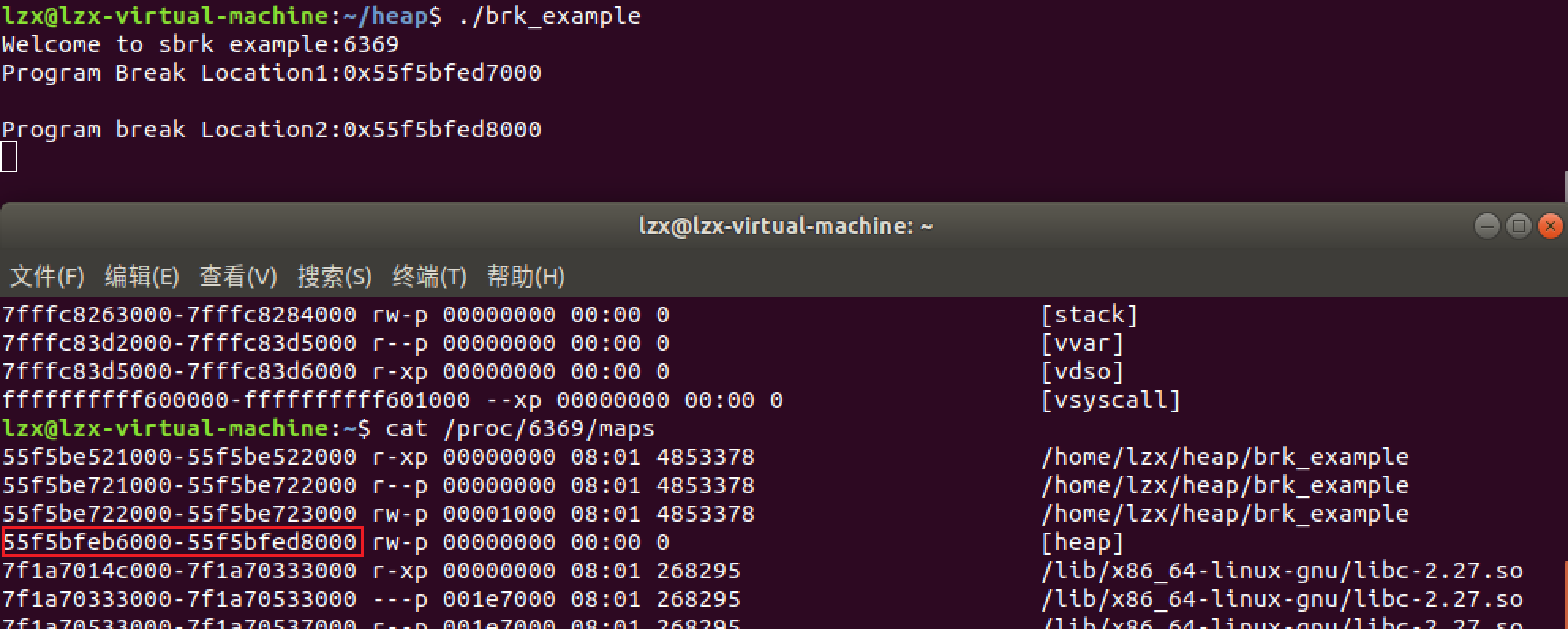
步骤二:第一次调用brk()之后,brk的值为:brk = 0x55f5bfed8000
brk(curr_brk+4096); 增加了4096 Byte,所以堆的终止地址由0x55f5bfed7000变为了0x55f5bfed8000。
步骤三:第二次调用brk()之后,brk的值为:brk = 0x55f5bfed7000
5.2 mmap
- mmap()函数将一个文件或者其它对象映射进内存。文件被映射到多个页上,如果文件的大小不是所有页的大小之和,最后一个页不被使用的空间将会清零。
- munmap 执行相反的操作,删除特定地址区域的对象映射。
malloc 会使用 mmap 来创建独立的匿名映射段。匿名映射的目的主要是可以申请以 0 填充的内存,并且这块内存仅被调用进程所使用。
函数定义如下:
#include <sys/mman.h>
void *mmap(void *start, size_t length, int prot, int flags, int fd, off_t offset);
int munmap(void *start, size_t length);
下面介绍这两个函数在 ptmalloc 中用到的功能:
参数:
-
start:映射区的开始地址。
-
length:映射区的长度。
-
prot:期望的内存保护标志,不能与文件的打开模式冲突。是以下的某个值,可以通过or 运算合理地组合在一起。Ptmalloc 中主要使用了如下的几个标志:
- PROT_EXEC:页内容可以被执行,ptmalloc 中没有使用
- PROT_READ:页内容可以被读取,ptmalloc 直接用 mmap 分配内存并立即返回给用户时设置该标志
- PROT_WRITE:页可以被写入,ptmalloc 直接用 mmap 分配内存并立即返回给用户时设置该标志
- PROT_NONE:页不可访问,ptmalloc 用 mmap 向系统“批发”一块内存进行管理时设置该标志
-
flags:指定映射对象的类型,映射选项和映射页是否可以共享。它的值可以是一个或者多个以下位的组合体
- MAP_FIXED:使用指定的映射起始地址,如果由 start 和 len 参数指定的内存区重叠于现存的映射空间,重叠部分将会被丢弃。如果指定的起始地址不可用,操作将会失败。并且起始地址必须落在页的边界上。Ptmalloc 在回收从系统中“批发”的内存时设置该标志。
- MAP_PRIVATE:建立一个写入时拷贝的私有映射。内存区域的写入不会影响到原文件。这个标志和以上标志是互斥的,只能使用其中一个。Ptmalloc每次调用mmap都设置该标志。
- MAP_NORESERVE:不要为这个映射保留交换空间。当交换空间被保留,对映射区修改的可能会得到保证。当交换空间不被保留,同时内存不足,对映射区的修改会引起段违例信号。Ptmalloc 向系统“批发”内存块时设置该标志。
- MAP_ANONYMOUS:匿名映射,映射区不与任何文件关联。Ptmalloc 每次调用 mmap都设置该标志。
-
fd:有效的文件描述词。如果 MAP_ANONYMOUS 被设定,为了兼容问题,其值应为-1。
-
offset:被映射对象内容的起点。
5.2.1 实验
实验环境:Ubuntu 16.04 x32
注:该实验在64位Ubuntu系统未成功,在32位Ubuntu系统成功。
- mmap_example.c
#include <stdio.h>
#include <sys/mman.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <unistd.h>
#include <stdlib.h>
void static inline errExit(const char* msg)
{
printf("%s failed. Exiting the process\n", msg);
exit(-1);
}
int main()
{
int ret = -1;
printf("Welcome to private anonymous mapping example::PID:%d\n", getpid());
printf("Before mmap\n");
getchar();
char* addr = NULL;
addr = mmap(NULL, (size_t)132*1024, PROT_READ|PROT_WRITE, MAP_PRIVATE | MAP_ANONYMOUS, -1, 0);
if (addr == MAP_FAILED)
errExit("mmap");
printf("After mmap\n");
getchar();
/* Unmap mapped region. */
ret = munmap(addr, (size_t)132*1024);
if(ret == -1)
errExit("munmap");
printf("After munmap\n");
getchar();
return 0;
}
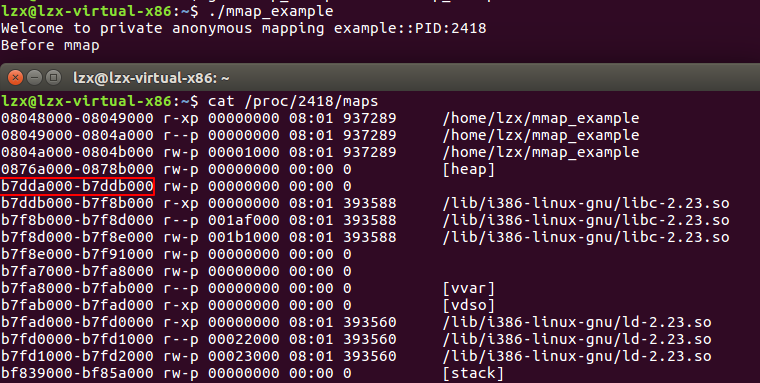
步骤一:调用mmap()之前,紧邻着heap段的mmap段的低地址是0xb7dda000,此时内存中有这些mmap段:
- .so 文件的 mmap 段
- vvar的 mmap 段
- vdso的 mmap 段
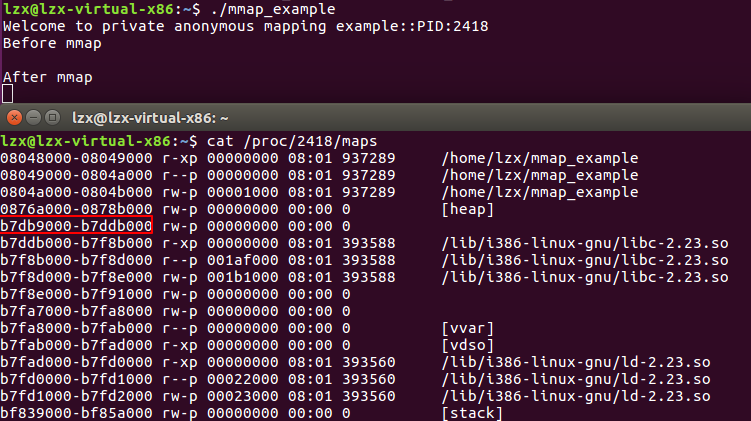
步骤二:调用mmap之后,mmap段发生了什么?mmap函数映射区长度是否对应mmap段发生的变化?
- 申请的内存与已经存在的内存段结合在了一起构成了 0xb7db9000 到 0xb7dda000 的 mmap 段。
- 是。 0xb7dda000 - 0xb7db9000 == 132*1024
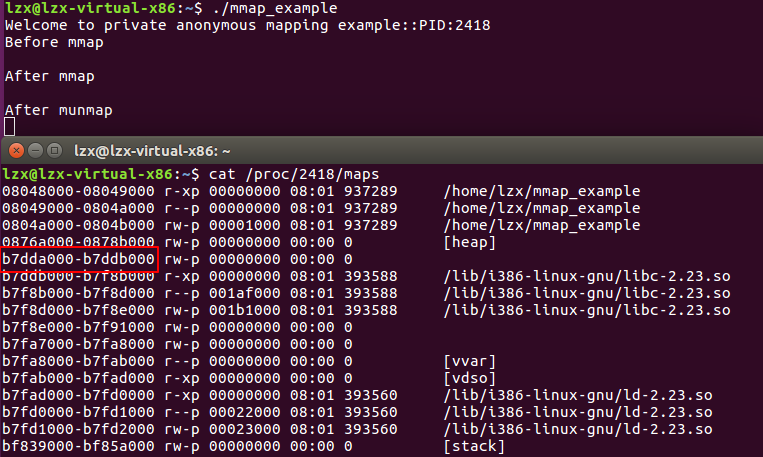
步骤三:调用munmap之后,内存段发生了什么变化?
- 原来申请的内存段已经没有了,内存段又恢复成原来的样子。
6. 动态分配内存的原因
通过两段代码的比较,思考来得出结论。
- 1.c
#include<stdio.h>
#define MAXN 15213
int array[MAXN];
int main(){
int i,n;
scanf("%d",&n);
if(n>MAXN){
printf("Input file too big");
}
for(i = 0; i < n; i++){
scanf("%d",&array[i]);
}
exit(0);
}
- 程序的输入是什么?
整数n和接下来要存储到数组中的n个整数。
- MAXN的值与机器上可用的虚拟内存的实际数量有没有关系?
没有。
- 如果还是使用硬编码的大小来分配数组,当想存储的整数个数n比MAXN更大时,该怎么做?
用一个更大的MAXN值来重新编译这个程序。
- 2.c
#include<stdio.h>
int main(){
int *array,i,n;
scanf("%d",&n);
array = (int*) Malloc(n * sizeof(int));
for(i = 0; i < n; i++){
scanf("%d",&array[i]);
}
free(array);
exit(0);
}
- 该程序是如何分配数组大小的?
在已知了n的值之后,动态地分配这个数组。
- 此时数组的最大值和可用的虚拟内存大小的有没有关系?如果有,是怎样的关系?
有。数组的最大值由可用的虚拟内存数量来限制。
- 程序使用动态内存分配的原因是什么?
经常直到程序实际运行时,才知道某些数据结构的大小。
参考资料
- https://www.bilibili.com/video/BV14i4y1V7rw
- https://azeria-labs.com/heap-exploitation-part-1-understanding-the-glibc-heap-implementation/
- https://ctf-wiki.github.io/ctf-wiki/pwn/linux/glibc-heap/heap_overview-zh/
- ...
由于有些资料是以前查的,不可考了,如果有没列上的,敬请谅解。
同样发布在我的语雀上:https://www.yuque.com/u1499710/fgcf17/wwt1zo
