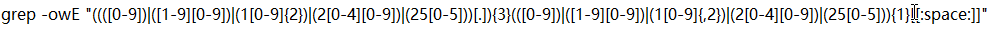grep与正则表达式
grep与正则表达式
1、grep程序
Linux下有文本处理三剑客 -- grep 、sed 、awk
grep : 文本行过滤工具
包含三个命令:grep egrep fgrep,他们是用来惊醒行模式匹配的
egrep = grep -E //使用拓展正则表达式进行匹配
fgrep = fast grep //只是用文件通配符进行匹配
*grep 默认使用正则表达式进行文本匹配
用法:
grep [option] ... PATTERN [文件名]
常见选项(opton):
-E //支持使用拓展的正则表达式(ERE)
-P //使用Perl语言的正则表达式引擎进行搜索(每一种语言的正则表达式引 擎都不相同,甚至sed 、grep 、awk所使用的引擎也不相同)
-f //指定文件
-i //忽略大小写
-o //仅仅输出匹配的内容(默认输出的是匹配到的行)
-n //显示行号
-v //反选
--color=auto // 语法着色
-w // 匹配固定的单词显示所在行
Sed : 文本行编辑器(流编辑器)
awk : 报告生成器(做文本输出格式化)
2、PATTERN -- 正则表达式
作用:
通过一些特殊字符,来表示一类字符内容,然后交给前面的命令来执行;如果使用特殊字符本身的含义就需要‘\’进行转译。
1、1字符匹配
. // 任意一个字符
[] // 匹配范围内的任意一个字符
[^] // 范围外任意一个字符
1、2次数匹配
* // 匹配前面的字符0次到n次
\? // 匹配前面的字符0次到1次
\+ // 匹配前面字符1次到n次
\{m\} // 匹配前面的一个字符m次
\{m,n\} // 匹配前一个字符m到n次
\{0,n\} // 匹配前面的字符0次到n次(0必须加)
\{m,\} // 匹配前面一个字符至少m次
1、3位置锚钉
^ // 锚定行首
$ // 锚定行尾
\b //锚定词首或词尾(用在前面为词首,后面为词尾)
\> // 锚定词尾
\< // 锚定词首
1、4分组
特性:
默认情况下,Linux系统会为分组指定变量,变量的表示形式\1 \2 \3 ...(后向 引用)
abc* // 我们把abc看成一个整体
\(\) // 将里面的看作是一个整体进行匹配
补充:
扩展正则表达式分组用“()”表示;
标准正则表达式中的“\”可以去掉;


*匹配IP地址的正则表达式: