Hadoop(十三)分析MapReduce程序
阅读目录(Content)
- 一、写一个MapReduce程序例子
- 1.1、数据准备
- 1.2、需求分析
- 1.3、编写一个解析类解析天气数据
- 1.4、编写一个MapReduce程序求1992I年的最高温度
- 1.5、使用Maven打包Jar包上传到Hadoop客户端的Linux服务器中
- 二、分析上面MapReduce程序
前言
刚才发生了悲伤的一幕,本来这篇博客马上就要写好的,花了我一晚上的时间。但是刚才电脑没有插电源就没有了。很难受!想哭,但是没有办法继续站起来。
前面的一篇博文中介绍了什么是MapReduce,这一篇给大家详细的分享一下MapReduce的运行原理。
一、写一个MapReduce程序例子
1.1、数据准备
准备要处理的数据(假定数据已经存放在hdfs的/data目录下)
$> hdfs dfs -ls /data
看到测试数据目录。天气数据目录/data/weather,专利数据目录/data/patent。
若没有,则自行将数据上传到上述目录基本步骤如下:
$> hdfs dfs -mkdir /data
$> hdfs dfs -mkdir /data/weather
$> hdfs dfs -put ~/weather/999999-99999-1992 /data/weather
天气数据格式:
每行一条记录,记录了年份,气象站编号,温度及数据质量
014399999999999 1992 012912004+11900+163700FM-13+9999KGWU
V0200601N00871220001CN0100001N9+026+02201101531ADDAG12001AY101061AY201061GF103991031021004501999999MD1110081
+9999MW1151SA1+2789UA1M030159999UG1080250809REMSYN02922233 00278 20303 308// 40805
数据分析:
(0, 15)气象站编号
(15,19)年份
(87, 92) 检查到的温度,如果为+9999则表示没有检测到温度
(92, 93)温度数据质量,为【01459】表示该温度是合理温度
1.2、需求分析
1)需求
以/data/weather/999999-99999-1992数据,请计算出每个气象站检测到的最高气温(这个程序也可以计算每年的最高温度)
2)分析
1.3、编写一个解析类解析天气数据
WeatherRecordParser
 WeatherRecordParser
WeatherRecordParser1.4、编写一个MapReduce程序求1992I年的最高温度
MaxTemperatureByYear_0010
MaxTemperatureByYear_00101.5、使用Maven打包Jar包上传到Hadoop客户端的Linux服务器中
1)执行测试

2)查询作业进度

我们可以通过Yarn集群的Web控制页面:http://ip:8088去查看作业的进度(ip是resourcemanager所在的ip)
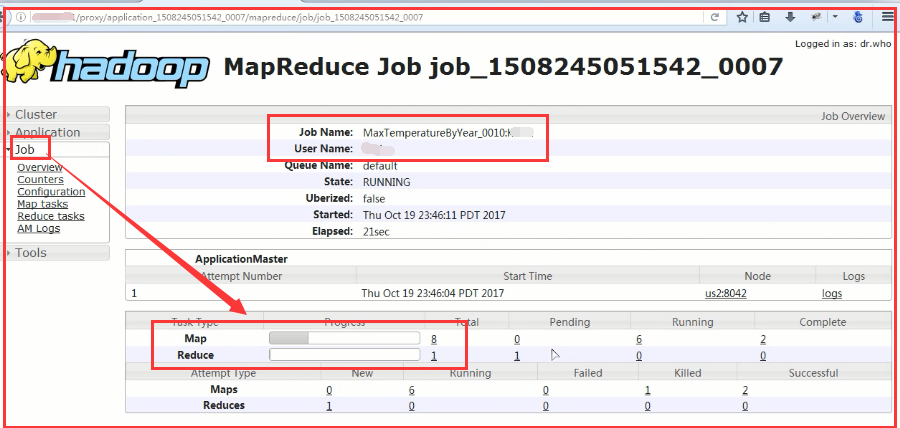
3)作业执行完成
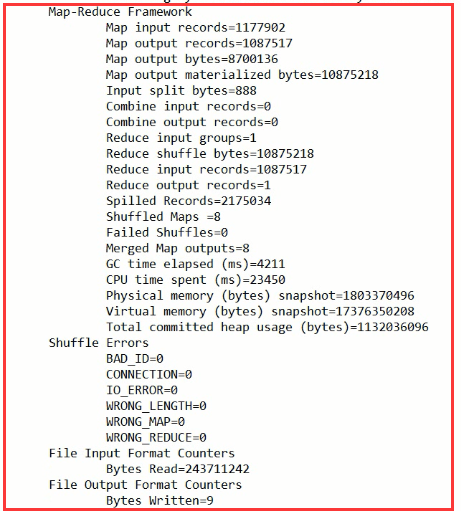
我们可以去查看执行文件:发现1992年的最高温度是605

二、分析上面MapReduce程序
1.1、查看作业历史服务器
我们通过http://ip:8088去 查看在执行完成MapReduce程序后的历史记录
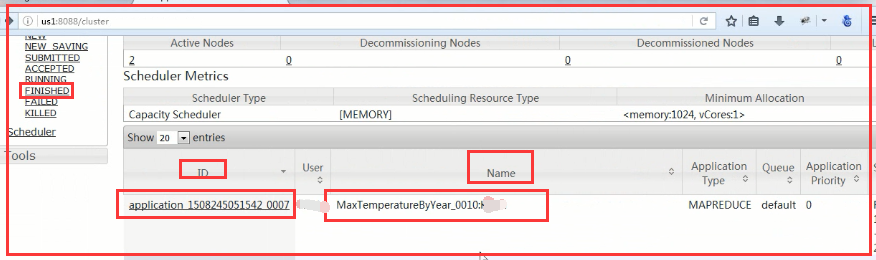
在最右边有一个history的按钮:

查看历史:
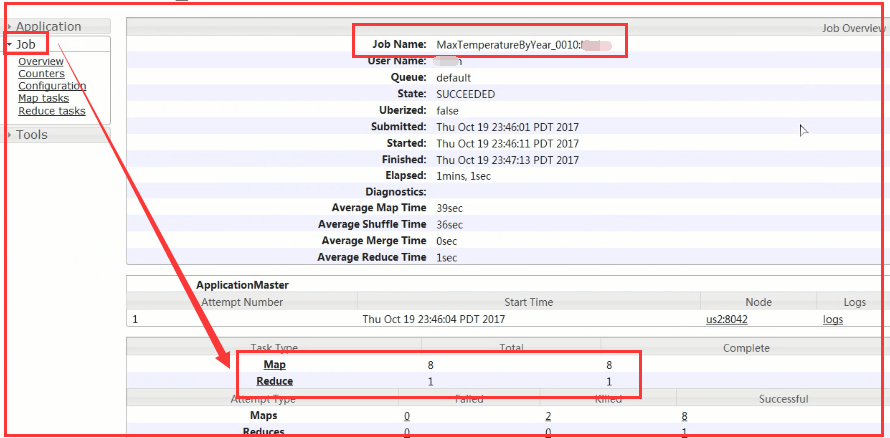
我们发现在刚才执行的MapReduce程序中,map有8个在并行执行,而reduce只有1个在执行,为什么呢?
分析:
查看1992年数据的详细信息:
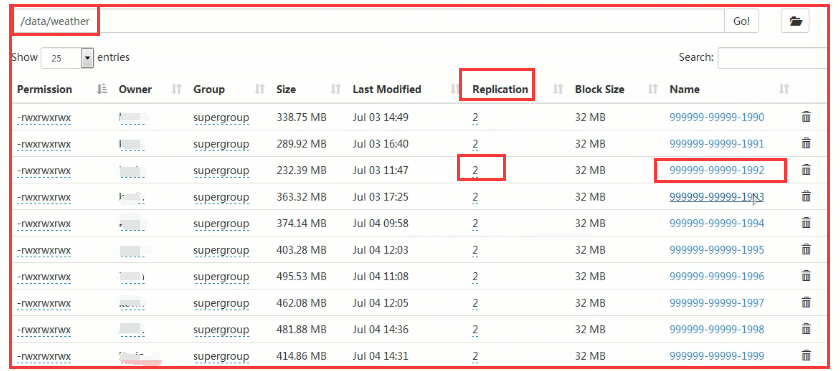
查看详细信息:
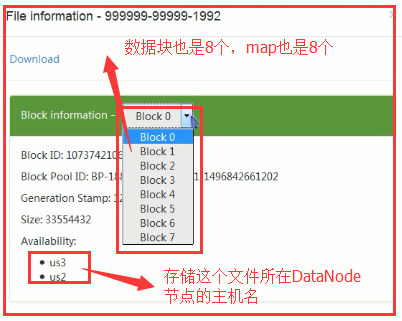
所以说map 的个数是和你的数据块的个数有关系的。reduce的个数默认是1个。
那我们也想修改reduce的个数,怎么办?
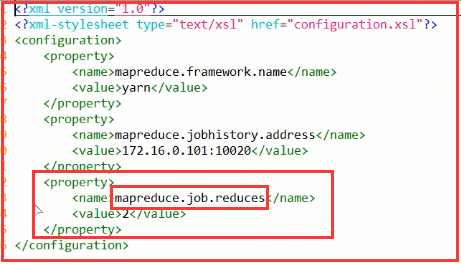
1)通过修改配置文件
修改配置为:
2)通过程序去修改

3)通过命令行参数去指定(这个后面在介绍)
2.2、经过洗牌后的数据怎么选择reduce
1)假设我们有一个HDFS集群有4个节点分别是us1,us2,us3,us4。Yarn集群的主节点在分配资源的时候,当你客户端将作业提交的时候,resourcemanager在分配资源(或者说分配作业)的时候,
尽量将应用程序分发到有数据的节点上。
比如:在我们下面这个集群中有4个节点,数据存储在us1,us2,us3中。在resourcemanager分发作业到集群上的时候,尽量将作业分发到有数据的节点上,也就是会分发到us1,us2,us3中。
(这样就避免了节点与节点的数据传输),当然在资源特别紧张的时候,us4页有可能有map任务。但是一般不会去分配。
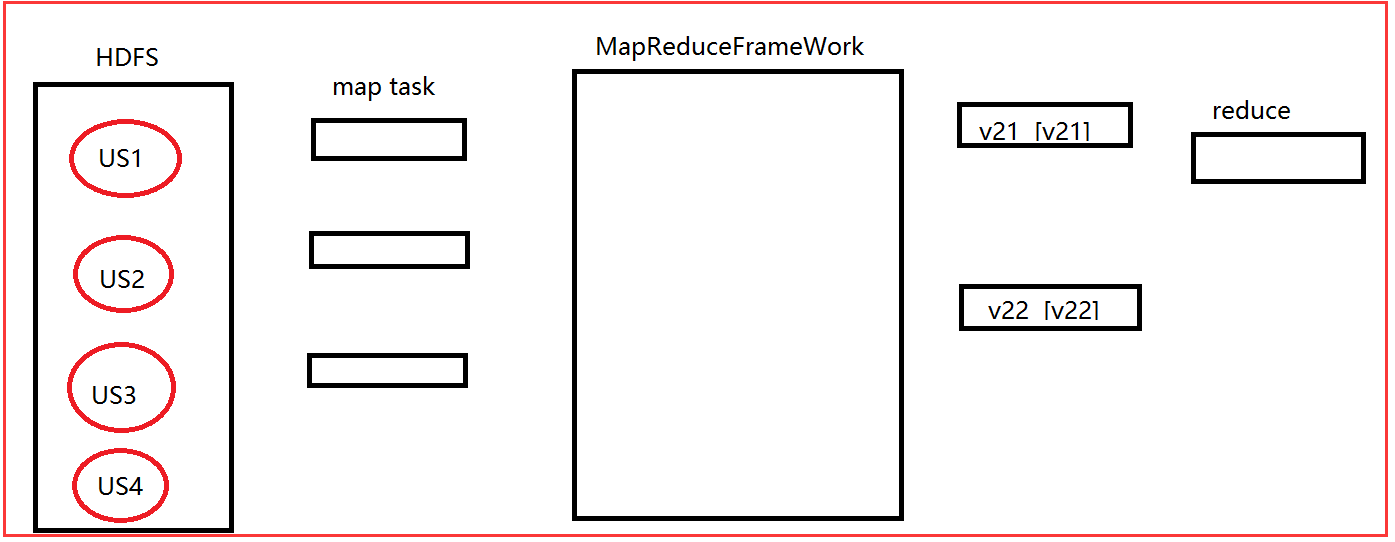
2)那么在us1,us2,us3中都至少有一个map任务,当map输出后经过洗牌,会根据key值得不同生成很多组以key不同的数据,假如生成了 v21 [v21]和v22 [v22]这两组数据。
我们知道前面的map是并行执行的(多个map同时运行,因为处理的数据在不同的数据块),当我们的reduce为默认的时候是有1个。当我们这里的运行的时候,是有一个reduce所以不可能是并行。
问题:我们的reduce只有一个,而又两组数据那么哪个先执行呢?
解决:Hadoop是这样规定的,我们对数据进行分组是根据key值来分组的。那么Hadoop会让这一系列的key去比较大小,最小的先进入执行,执行完成后,按照从小到大去执行。
比如:我们这里有两组数据key值分别为k21,k22,如果k21<k22,那么k21先执行,执行完成之后再执行k22。
3)当reduce任务执行完成之后会生成一个文件:part-r-00000。
比如在我们上面那个程序中生成的存放结果的文件:
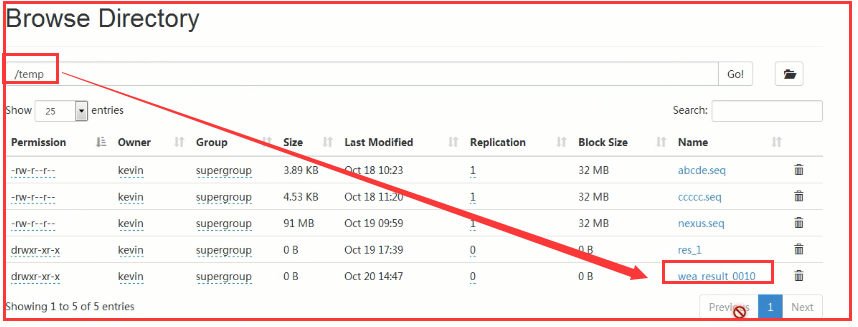
点击查看:

我们查看到这里有两个文件:
第一个文件_SUCCESS:当MapReduce执行成功会产生这个文件,如果失败就没有这个文件。
第二个文件:用来存放执行结果。
4)reduce默认情况下是一个,我们可以通过更改集群配置或程序设置或命令行参数指定来修改reduce的个数。
假如:我们有2个reduce,也有2组数据。那么reduce就可以 进行并行计算了。
问题:两组数据,2个reduce。到底哪组数据进入哪个reduce呢?
解决: Hadoop会让每一组数据的key值得hash值去和reduce的个数取余,余数是几那么就进入哪个reduce。
当然前提是给reduce编号(编号是Hadoop内部自己会去编)。
比如:我们2个reduce编号分别为0和1,v21生成的hash值为3,通过3/2取余为1,说明它进入到编号为1的reduce中。
而v22生成的hash值为4,说明它进入编号为0的reduce中。
但是如果我们v22生成的hash值是5呢?那么它也会进入编号为1的reduce中。导致0号reduce没有任何数据。
那么就相当于编号为0的reduce什么事情都没有干,但是当reduce任务执行完成之后,一个reduce会生成一个文件。
第一个reduce生成的是part-r-00000,第二个则是part-r-00001(后面的00000和00001就是reduce的编号)
注意:
即使reduce没有处理任何的数据也会生成一个文件,只不过文件大小为0。所以说当我们的程序设置了多少个reduce就会产生多少个文件。
2.3、洗牌过程
我们来看一下上图中那个shuffle(洗牌)干了什么事情?
其实很简单就是做了一个分组的功能。
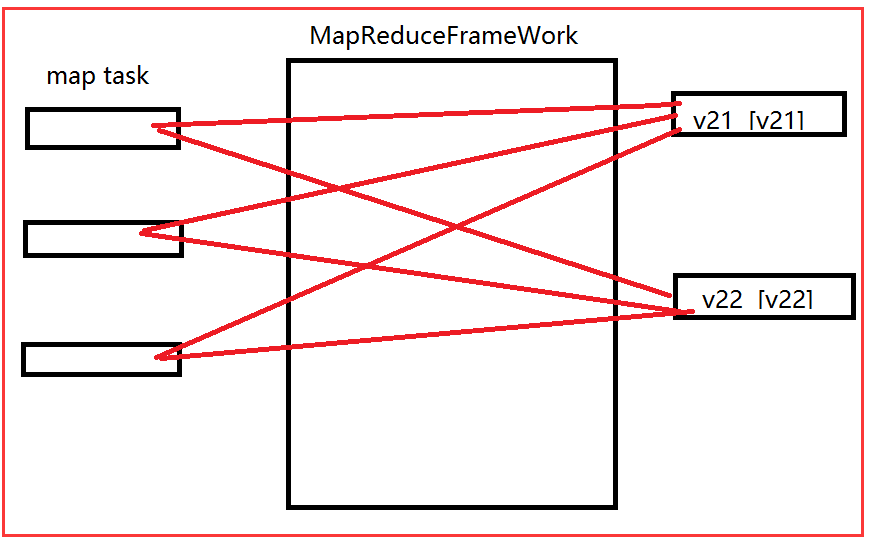
这三个节点中的map都有可能产生k21和k22,它需要把key值相同的合并起来,形成 k21 [k22](类似集合一样的value)这样的数据。
前面我们说了resourcemanager在分发 作业的时候,会将作业尽量分发到有数据的节点上。
其实还有就是:
运行作业的节点尽可能的要求它所处理的数据来自于自己所在的节点上。
比如说我们上面的那个例子:us1,us2,us3都是有数据的节点,
问题:
那有没有可能us1中处理的数据来自于us2中?
分析:
1)我们的map(map中是map方法在处理数据)在处理数据的时候,是一行一行处理的。
2)我们的数据分块是默认128MB一块(可以自行设置)。比如下图中的是一个文件,以32MB分为一个数据块,
这个文件的大小是80MB那么就会分成3个数据块。
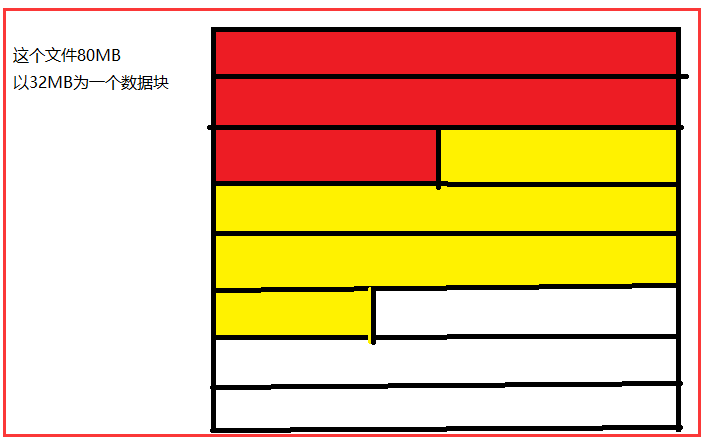
3)当我们分块的时候,我们并不能保证它按照完整的行来进行数据分块。数据分块之后不同的数据块可能会分到不同的节点上。
我们从上图可以看出,红色数据块为32MB,由2行半的数据组成。而黄色数据块也为32MB,它也不是完整的行。
那我们红色数据块的数据会用一个map去处理(因为我们知道一个数据块尽量会用一个map去处理),黄颜色也会用一个map去处理。
前面我们就说了map处理数据的时候,一次是处理一行的。
问题:
在红色数据块中处理时候的时候,处理前两行没有问题,当处理到第三行是不能构成一行,怎么办?
解决:
在红颜色数据块中,Hadoop会将标记向后移动,直至处理的数据是一个整行的数据。黄颜色的map的处理数据的时候,发现第一行的数据不是从
一行的开始位置去处理的数据,它也会去移动到下一行的开始处理数据。
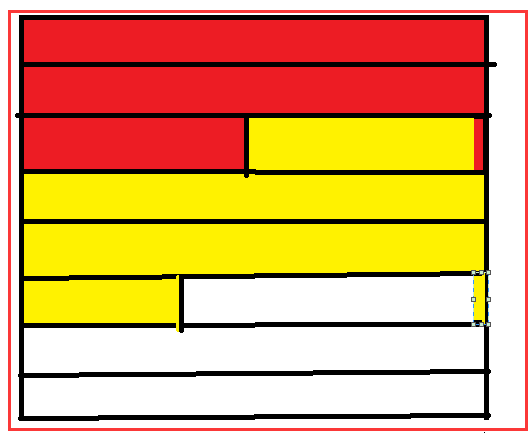
4)那么我们知道不同的数据块可能会存储到不同的 节点上。 在这里中假设红颜色和黄颜色的数据块在不同的节点上。
那么红颜色数据块的map就要去黄颜色的节点上去读取数据了。
总结:一个map处理的数据不一定都来自于自己的节点上。但resourcemanager在分配作业的时候会尽量让这个map处理的数据来自于本节点。
2.4、数据分片与数据分组
1)数据分片
我们把进入map端的数据叫做数据分片。每一个数据块进入MapReudce中的map程序的时候,我们把它叫做数据分片。
那什么样的数据是一个数据分片?HDFS集群上的一个数据块的数据对应我们所说的数据分片。
也就是每一个数据分片由每一个map任务去处理。
2)数据分组
数据进过洗牌之后分成不同的组形成数据的过程叫做数据分组。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号