Hadoop(九)Hadoop IO之Compression和Codecs
阅读目录(Content)
前言
前面一篇介绍了Java怎么去查看数据块的相关信息和怎么去查看文件系统。我们只要知道怎么去查看就行了!接下来我分享的是Hadoop的I/O操作。
在Hadoop中为什么要去使用压缩(Compression)呢?接下来我们就知道了。
一、压缩(Compression)概述
1.1、压缩的好处
减少储存文件所需要的磁盘空间,并加速数据在网络和磁盘上的传输。这两个在大数据处理大龄数据时相当重要!
1.2、压缩格式总结
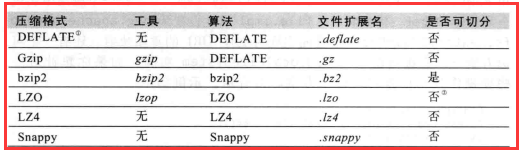
Hadoop对前面三种有默认集成,有就是说Hadoop支持DEFLATE、Gzip、bzip2三种压缩格式。而后面三种Hadoop没有支持,要用的话要自己去官网
下载相应的源码去编译加入到Hadoop才能用。
注意:
1)这里我要说的是“是否分割”,当我们一个文件去压缩即使有非常好的压缩算法,但是它的大小还是超过了一个数据块的大小,这时就涉及到分割了。
所以说在以后的压缩我们大多数情况下会使用bzip2。
2)Gzip和bzip2比较时,bzip2的压缩率(压缩之后的大小除以源文件的大小)要小,所以说bzip2的压缩效果好。而这里就会压缩和解压缩的时候浪费更多的时间。
就是我们常说的“用时间换取空间”。
二、编解码器(Codec)概述
codec实现了一种压缩-加压缩算法(意思就是codec使用相关的算法对数据进行编解码)。在Hadoop中,一个对CompressionCodec接口的实现代表一个codec。
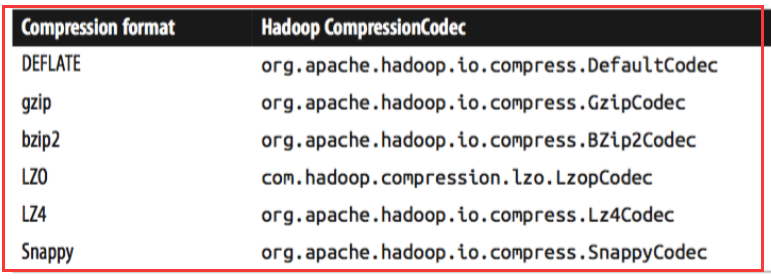
对于不同的压缩算法有不同的编解码器
我们要对一个文件进行压缩需要编码器,对一个压缩文件进行解压需要解码器。那我们怎么样去获取编解码器呢?
有两种方式:
一是:根据扩展名让程序自己去选择相应的编解码器。比如说:我在本地有一个文件是 user.txt我们通过-Dinput=user.txt去上传这个文件到集群,
在集群中我们把它指定到-Doutput=/user.txt.gz.。这是我们程序的相关的类会根据你的扩展名(这里是.gz)获取相应的压缩编解码器。
在Hadoop中有一个CompressionCodecFactory会根据扩展名获取相应的编解码器对象 。
二是:我们自己去指定编解码器。为什么要去指定呢?比如说,我在本地有一个文件是user.txt.gz,其实这个压缩文件是使用的是bzip2的压缩算法压缩的。
(因为我自己去更改了它的扩展名),所以这时候就要自己去指定编解码器。
三、Java编程实现文件的压缩与解压缩
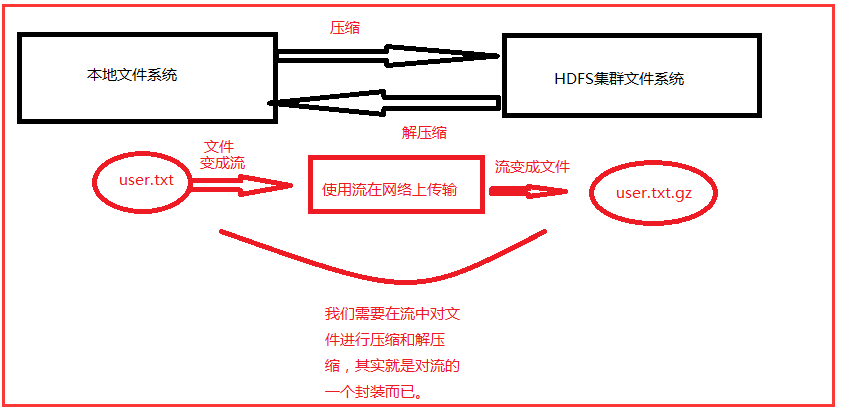
3.1、原理分析
在我们把本地的文件上传的集群的时候,到底是哪里需要压缩,哪里需要解压缩,在哪里压缩?这都是需要明白,下面画一张图给大家理解:
3.2、相关类和方法
在Hadoop中关于压缩和解压缩的包、接口和类:
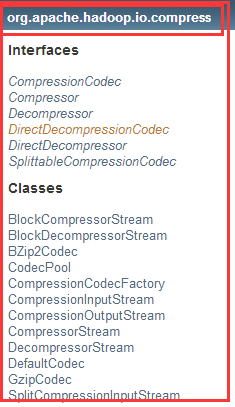
1)CompressionCodec接口中

2)CompressionCodecFactory类

第一个是:根据文件的文件名后缀找到相应的压缩编解码器
第二个是:为编解码器的标准类名找到相关的压缩编解码器。
第三个是:为编解码器的标准类名或通过编解码器别名找到相关的压缩编解码器。
3.3、Java将本地文件压缩上传到集群当中
1)核心代码

import java.net.URI;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.LocalFileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;
import org.apache.hadoop.io.compress.BZip2Codec;
import org.apache.hadoop.io.compress.CompressionCodec;
import org.apache.hadoop.io.compress.CompressionCodecFactory;
import org.apache.hadoop.io.compress.CompressionOutputStream;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
public class WriteDemo_0010
extends Configured implements Tool{
@Override
public int run(String[] args) throws Exception{
Configuration conf=getConf();
String input=conf.get("input");
String output=conf.get("output");
LocalFileSystem lfs=
FileSystem.getLocal(conf);
FileSystem rfs=
FileSystem.get(
URI.create(output),conf);
FSDataInputStream is=
lfs.open(new Path(input));
FSDataOutputStream os=
rfs.create(new Path(output));
CompressionCodecFactory ccf=
new CompressionCodecFactory(conf);
//把路径传进去,根据指定的后缀名获取编解码器
CompressionCodec codec=
ccf.getCodec(new Path(output));
CompressionOutputStream cos=
codec.createOutputStream(os);
System.out.println(
codec.getClass().getName());
IOUtils.copyBytes(is,cos,1024,true);
//close
return 0;
}
public static void main(String[] args) throws Exception{
System.exit(
ToolRunner.run(
new WriteDemo_0010(),args));
}
}
2)测试
将IEDA中打好的jar包上传到Linux中(安装了HDFS集群的客户端的服务器中)执行:

结果:
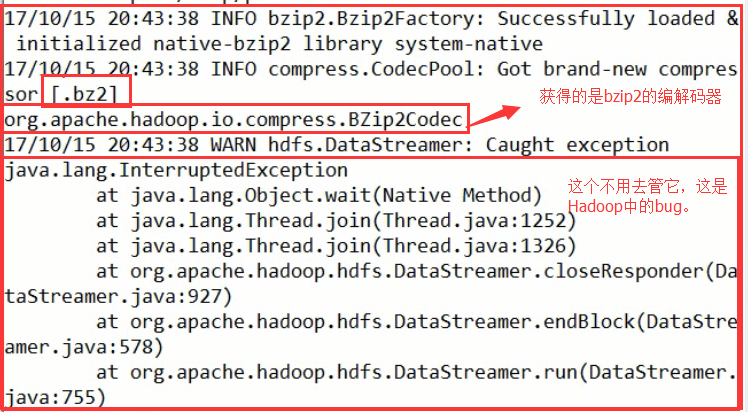
我们可以从前面的那种表中可以看的出来,获取到了相应的编解码器。
再次测试:

结果:

3.4、Java将集群文件解压缩到本地
1)核心代码
import java.net.URI;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.LocalFileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;
import org.apache.hadoop.io.compress.CompressionCodec;
import org.apache.hadoop.io.compress.CompressionCodecFactory;
import org.apache.hadoop.io.compress.CompressionInputStream;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
public class ReadDemo_0010
extends Configured
implements Tool{
@Override
public int run(String[] args) throws Exception{
Configuration conf=getConf();
String input=conf.get("input");
String output=conf.get("output");
FileSystem rfs=
FileSystem.get(
URI.create(input),conf);
LocalFileSystem lfs=
FileSystem.getLocal(conf);
FSDataInputStream is=
rfs.open(new Path(input));
FSDataOutputStream os=
lfs.create(new Path(output));
CompressionCodecFactory factory=
new CompressionCodecFactory(conf);
CompressionCodec codec=
factory.getCodec(new Path(input));
CompressionInputStream cis=
codec.createInputStream(is);
IOUtils.copyBytes(cis,os,1024,true);
return 0;
}
public static void main(String[] args) throws Exception{
System.exit(
ToolRunner.run(
new ReadDemo_0010(),args));
}
}
2)测试

结果:

查看结果:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号