Hadoop(七)HDFS容错机制详解
阅读目录(Content)
前言
HDFS(Hadoop Distributed File System)是一个分布式文件系统。它具有高容错性并提供了高吞吐量的数据访问,非常适合大规模数据集上的应用,它提供了一个高度容错性和高吞吐量的海量数据存储解决方案。
优点是:
高吞吐量访问:HDFS的每个Block分布在不同的Rack上,在用户访问时,HDFS会计算使用最近和访问量最小的服务器给用户提供。
由于Block在不同的Rack上都有备份,所以不再是单数据访问,所以速度和效率是非常快的。另外HDFS可以并行从服务器集群中读写,增加了文件读写的访问带宽。
高容错性:系统故障是不可避免的,如何做到故障之后的数据恢复和容错处理是至关重要的。
HDFS通过多方面保证数据的可靠性,多份复制并且分布到物理位置的不同服务器上,数据校验功能、后台的连续自检数据一致性功能都为高容错提供了可能。
线性扩展:因为HDFS的Block信息存放到NameNode上,文件的Block分布到DataNode上,当扩充的时候仅仅添加DataNode数量,系统可以在不停止服务的情况下做扩充,不需要人工干预。
一、HDFS容错机制

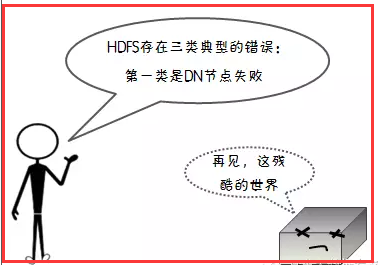
1.1、故障类型(三类故障)
1)节点失败
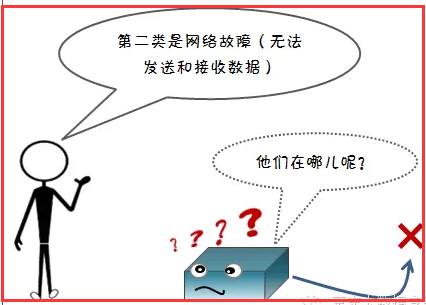
2)网络故障
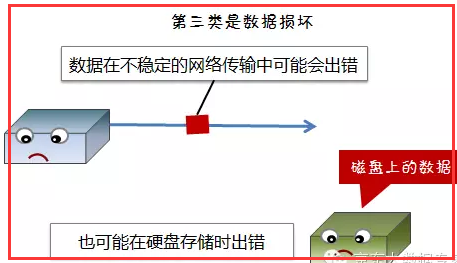
3)数据损坏(脏数据)
1.2、故障检测机制
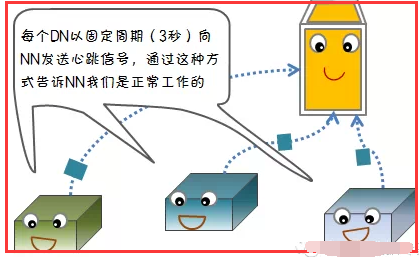
1)节点失败检测机制

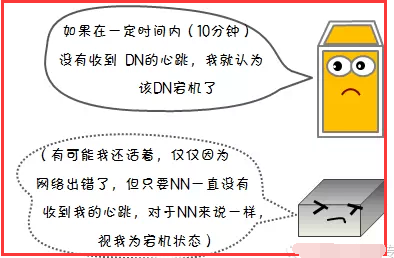
2)通信故障检测机制

3)数据错误检测机制


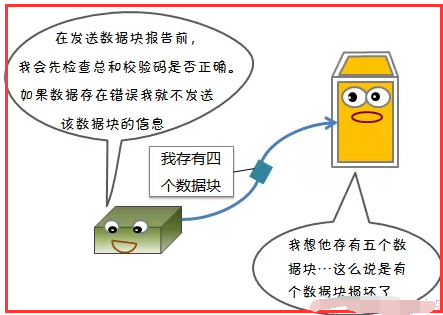
1.3、回复:心跳信息和数据块报告
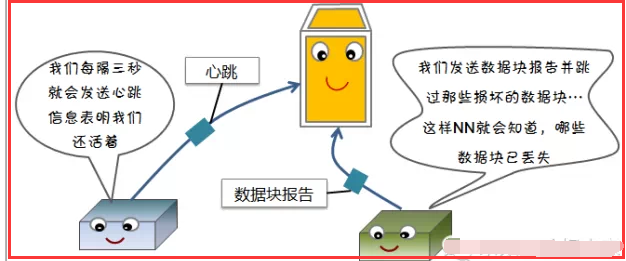
HDFS存储理念是以最少的钱买最烂的机器并实现最安全、难度高的分布式文件系统(高容错性低成本)。
从上可以看出,HDFS认为机器故障是种常态,所以在设计时充分考虑到单个机器故障,单个磁盘故障,单个文件丢失等情况。
1.4、读写容错
1)写容错
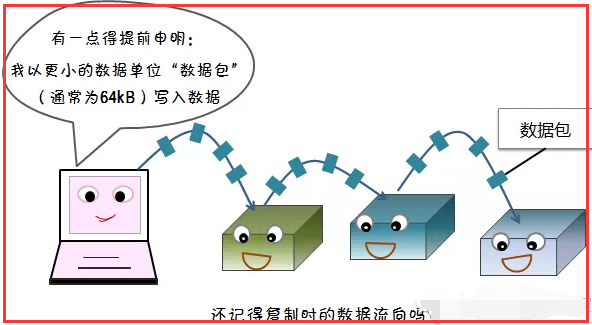
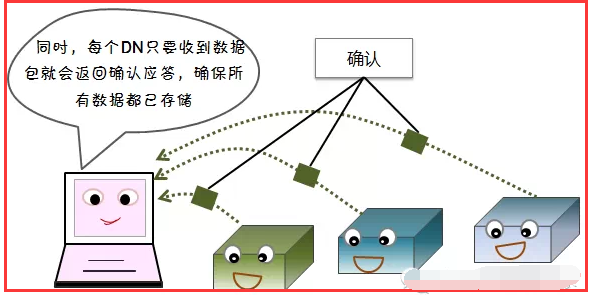
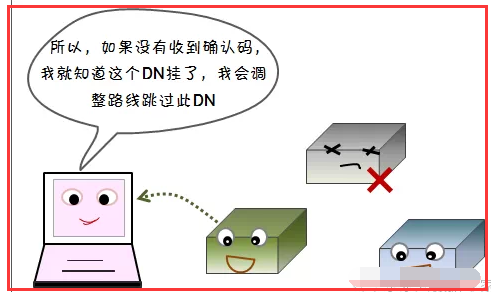
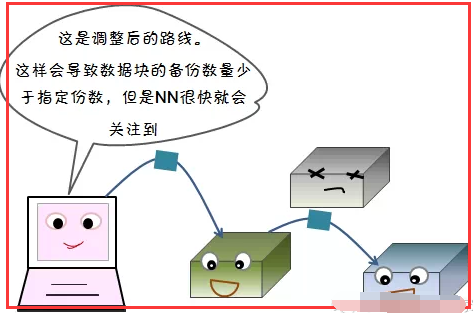
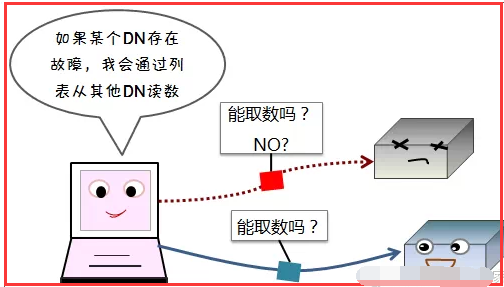
2)读容错

1.5、数据节点(DN)失效
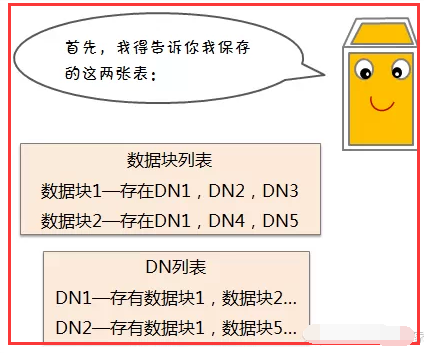
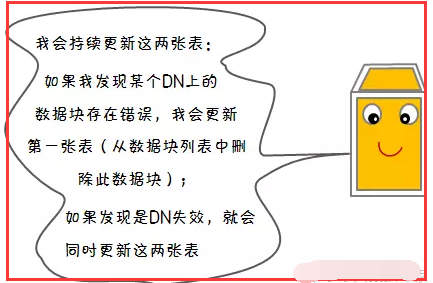


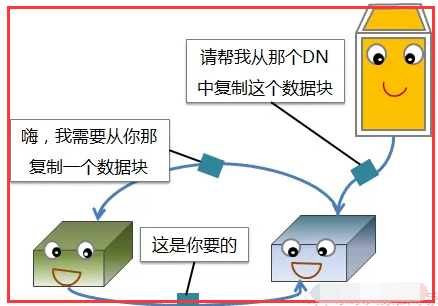

二、HDFS备份规则

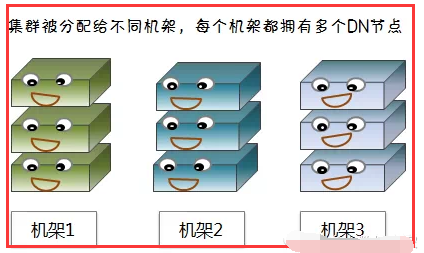
1)机架与数据节点
2)副本放置策略

数据块的第一个副本优先放在写入数据块的客户端所在的节点上,但是如果这个客户端上的数据节点空间不足或者是当前负载过重,则应该从该数据节点所在的机架中选择一个合适的数据节点作为本地节点。
如果客户端上没有一个数据节点的话,则从整个集群中随机选择一个合适的数据节点作为此时这个数据块的本地节点。

HDFS的存放策略是将一个副本存放在本地机架节点上,另外两个副本放在不同机架的不同节点上。
这样集群可在完全失去某一机架的情况下还能存活。同时,这种策略减少了机架间的数据传输,提高了写操作的效率,因为数据块只存放在两个不同的机架上,
减少了读取数据时需要的网络传输总带宽。这样在一定程度上兼顾了数据安全和网络传输的开销。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号