spark、standalone集群 (2)集群zookeeper 热备
测试 cmd
spark-examples-1.6.0-hadoop2.6.0.jar spark 2.0以后 就没有这个 jar。需要下载
./bin/spark-submit --class org.apache.spark.examples.SparkPi --master spark://sparknode1:7077 ./lib/spark-examples-1.6.0-hadoop2.6.0.jar 10
./bin/spark-shell --master spark://sparknode1:7077
http://mirrors.cnnic.cn/apache/zookeeper/
1.下载 zookeeper 3.3.6
tar zxvf 解压到目录(与spark平级,可以自定义)
2.创建目录data logs

3.在data下创建文件 myid (各自 格式都可以,我是txt)
4.cd /conf复制 zoo_sample.cfg
cp zoo_sample.cfg zoo.cfg
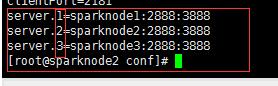
vi zoo.cfg 修改 新增

5. myid 文件内容 与下图 1,2,3...一致
(集群务服sparknode1(server.1),中myid的值为 1)
(集群务服sparknode1(server.2),中myid的值为 2)...
6.把解压 后的zookeeper 上传到 每一台 集群服务器上
修改对应服务启的 myid文件内容
7.每一台的zookeeper
cd /zookeeper.3.3.6/bin
./zkServer.sh start
./zkServer.sh status
8.开始整合 spark
修改 spark/conf/spark-env.sh

9.启动 cd /sbin
./start-all.sh
10.测试备用主节点
修改一下worker 节点为 master,
sparknode2服务器

启动 主节点 ./start-master.sh (sparknode2服务器)
11.页面查看


杀死 sparknode1 master 进程,

等一段时间,1-2分钟,,,查看sparknode2 页面,是否把 主节点 激活


 浙公网安备 33010602011771号
浙公网安备 33010602011771号