MySQL(01)基础
安装MySQL 5.7
官网下载 :https://dev.mysql.com/downloads/mysql/
以压缩包的方式安装比较方便 , 下载好后, 解压到自定义目录, 添加环境变量 path=文件目录下的bin\
在文件的根目录下(和bin同级)添加一个 my.ini 配置文件 ,文件内容
[mysqld]
basedir=D:\MySQL5.7\mysql-5.7.35-winx64\mysql-5.7.35-winx64\
datadir=D:\MySQL5.7\mysql-5.7.35-winx64\mysql-5.7.35-winx64\data\ data会自动生成,不需要手动创建
port=3306
skip-grant-tables 跳过密码
以管理员身份运行 CMD
安装服务 bin\mysqld -install
初始化数据库文件 mysqld --initialize-insecure --user=mysql 运行后会自动创建data文件
启动mysql net start mysql
进入mysql管理用户 mysql -u root -p 密码为空
设置密码 mysql> update mysql.user set authentication_string=password('55555') where user='root' and Host='localhost';
刷新权限 mysql>flush privileges; my.ini删除最后一句 skip...
重启mysql, 关闭服务net stop mysql , 开启服务 net start mysql
数据库是按照数据结构来组织,存储,和管理数据的仓库
1.数据模型
层次数据结构 参考树状图
优点: 结构清晰 检索效率高
缺点: 结构缺乏灵活性 , 依赖父节点 ,对增删操作限制多,对某个节点的下级层级影响较大
网状数据模型 参考有向图
优点: 没有层次结构那么严格限制. 增删操作对整个模型影响不大
缺点: 结构复杂操作不易
关系数据模型 参考二维表格 ,上面提到的两种是非关系型数据模型
优点: 相对于其他模型更容易理解, 表格之间的增删对其他表格影响较小
缺点: 读写性能上相对较差, 但足以我们去使用
2.数据库系统 DBS
包含: 数据 数据库 DBMS(操作和管理数据库的软件,一般不能直接操作数据库的 , 只能通过数据库软件进行操作)
3.SQL 结构化查询语言
SQL语句不区分大小写, 但字符串区分大小写( " " 和 ' ' 都是表示字符串)
SQL 分类
DQL 数据查询语言 专用于查询数据
DML 数据操作语言 专用于数据的 增 删 改(更新数据)
DDL 数据定义语言 用于创建数据库中的对象(数据库 表 视图 索引 这些都是对象)
DCL 数据控制语言 提交 回滚(撤销) GRANT(授权)
Mysql最大支持 5000万条记录 , 32位 表最大占4GB 64位 表最大占8TB , 支持C/C++ python java perl PHP Ruby等语言的连接
4.术语:
表 存放数据的二维数组
记录(元祖) 表中的一行叫记录
字段(属性) 表中的一列
域 属性的取值范围(比如性别的值 男或女)
冗余 重复的数据(降低了性能 ,提高了数据的安全性)
存储引擎 默认MYISAM(比较旧) 更新的 INNODB(功能更多)
5.常用命令:
显示数据库 show databases; 显示创建的数据库(随时都可以用, 就算已经身处某个数据里了可用于切换数据量)
默认有四个数据库(如果缺少其中一个或者没有需要重新安装,因为Mysql的信息都存在这四个数据库中)
information_schema 数据库信息(保存着MySQL维护的 其他的数据库信息 比如数据库名 表 数据类型等信息)
mysql 保存用户信息 权限设置 关键字等保存在该数据库
performance_schema 收集数据库服务器的性能参数
sys 保存数据库服务器系统的数据
删除数据库 drop databases [数据库名];
进入数据库 use [数据库名];
显示表列 show tables;
查看表的结构 descride [表名];
查看表的字段 show full column from [表名] ;
改密码 updata mysql.user set authentication_string = password("新密码"); 改完密码后要刷新权限 flush privileges;
退出MySQL quit; exit;
命令化管理太费劲了, 所以有了图形化管理工具 navicat 和 MySQL自己的workbench
数据库设计
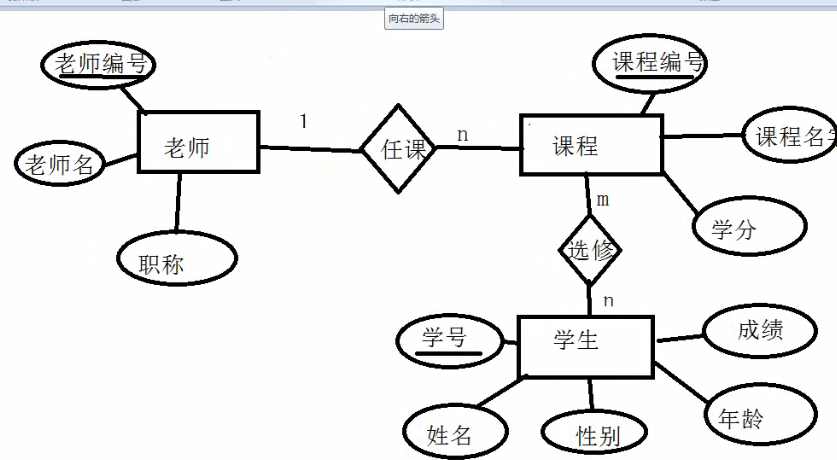
概念结构设计 从需求分析中找到实体和联系比如
学生表(实体是学生)
选修关系
课程表(实体是课程)
任课关系
老师任课表(实体是老师)
联系类型 1对1 (A表中的一行最多只能匹配到B表的一行, 反之亦然)
多对多 (A表中的一行可以匹配到B表中的多行 , 反之亦然)
1对多 (A中的一行可以匹配到B的多行, 但是B中的一行只能匹配到A中的一行)
E-R图: 矩形表示实体
菱形表示联系
椭圆表示实体的属性 (下划线表示主属性)
用线把关系联系起来
表的设计范式 1NF 2NF 3NF BCNF 4NF 5NF
1NF 原子性(每个数据不可再分,保持数据的原子性)过滤 过滤重复属性 比如学生表中出现 年龄 和 出生日期 就是重复属性
2NF 基于1NF上 非主属性必须完全依赖于主属性(没有主属性则创建一个) 比如学生表必须有ID编号
3NF 基于2NF上 所有的非主属性不能依赖于其他的非主属性 顾名思义
BCNF 基于3NF上 非主属性的不能依赖于主属性的子集 主键可能是联合主键(多个属性组合成的)不能依赖于其中某个属性,只能依赖于整体
一般只要求 做到1-3范式就可以了, 不能过分的追求完美, 虽然后面的范式更加健全可是逻辑和管理太庞大了 , 动一张表要牵扯改N张表, 没必要
物理结构设计 将逻辑结构实现在具体环境, 依赖于给定的DBMS和硬件系统
数据库的实施 根据逻辑设计和物理设计的结果, 建立数据库系统,加载数据,调试
数据库的运行和维护 优化数据库的性能, 维护数据库的安全和完整性(有效的数据)


 浙公网安备 33010602011771号
浙公网安备 33010602011771号