

大数据 - 框架 - Hadoop
Hadoop技术生态的组成部分:
- Hadoop Common:支持Hadoop其他模块的通用工具
- HDFS:分布式文件系统,提供了高吞吐量的数据访问(最初始模块之一)
- YARN:作业调度和资源管理的框架
- MapReduce:基于YARN的大数据分布式计算框架(最初始模块之一)
HDFS
利用多个商业硬件构成存储集群,利用namenode进行数据的存储控制,具有支持超大文件、存储灵活、可靠性高等特定,面对大量数据存储的时候,能够高效地工作。(但在处理大量小数据、需要进行低延迟数据访问和需要多用户访问写入等场景下,任存在不足。)其主要的组件如下:
-
- Namenode: 管理者,负责文件系统的命名,记录所有文件和目录。同时,它还负责临时保存块的位置信息。
- Datanode: 工作者,是文件系统的工作节点,根据需要存储并检索数据库,定期向namenode发送存储块,namenode则负责记录如何重建文件。
当通过文件系统接口访问数据,其实质是在于namenode和datanode进行交互,namenode像是大脑对神经的反馈进行综合处理,datanode则像是末梢神经。
MapReduce
- 编程模型:Map阶段、Reduce阶段
- 数据处理引擎:MapTask、ReduceTask
- 运行时环境分两种:
- (MR1): JobTracker(资源管理和作业控制)和TaskTracker(接受JT命令并具体执行)
- (MR2): 是运行于YARN之上的计算框架,YARN(资源管理与调度)和ApplicationMaster(作业控制)。
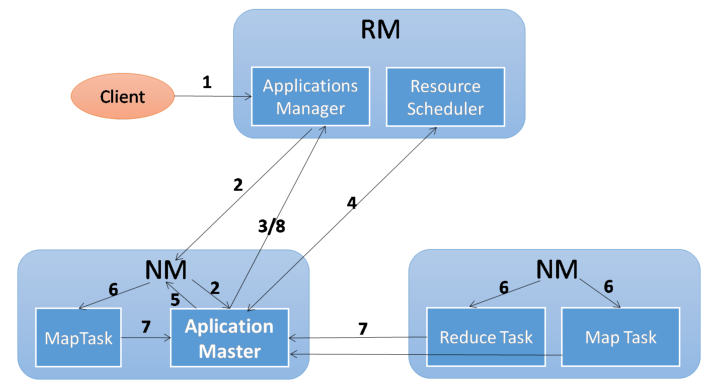
YARN
- 基本构造:
- ResourceManager:全局的资源管理器,负责整个集群的资源管理、分配与调度。
- Scheduler(调度器),纯调度器,默认下是Fair Scheduler
- NodeManager:对每一个slave上的资源和任务做管理
- 1) 定时的向RM汇报HearBeat(资源的使用情况和Container的运行状态)
- 2) 接受来自AM的启动/停止的请求
- Container:资源分配单位(MRv1中Slot),动态分配。
- ApplicationMaster:每个APP都会包含一个AM,AM的功能包括:
- 1) 向RM申请资源(用Container资源抽象)
- 2) 将任务做进一步的分配
- 3) 与NM通信启动/停止任务
- 4) 跟踪每一个Task的运行状态(包括Failed后的操作)
- 运行模式:
参考:
- Hadoop : https://hadoop.apache.org/
- MapReduce:http://hadoop.apache.org/docs/r1.2.1/mapred_tutorial.html
- HDFS:https://hadoop.apache.org/docs/current/hadoop-project-dist/hadoop-hdfs/HdfsDesign.html
- HBase(开源的非关系型分布式数据库(NoSQL)VS. HDFS,它参考了谷歌的BigTable,用Java):
- Google三篇论文:(若如下网址无法打开,可复制此连接自行下载:https://files.cnblogs.com/files/yxmings/Bigdata_platform%EF%BC%9AGoogle%E4%B8%89%E7%AF%87%E8%AE%BA%E6%96%87.zip)
- GFS:http://static.googleusercontent.com/media/research.google.com/zh-CN//archive/gfs-sosp2003.pdf
- MapReduce:http://static.googleusercontent.com/media/research.google.com/zh-CN//archive/mapreduce-osdi04.pdf
- BigTable:http://static.googleusercontent.com/media/research.google.com/zh-CN//archive/bigtable-osdi06.pdf
记录有用的信息和数据,并分享!

