

pyQuery库
pyQuery 也是做筛选的一个库
一般引用 from pyquery import pyQuery as pq 常规用法
1、字符串初始化
html = ''' <div> <ul> <li class="item-0">first item</li> <li class="item-1"><a href="link2.html">second item</a></li> <li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li> <li class="item-1 active"><a href="link4.html">fourth item</a></li> <li class="item-0"><a href="link5.html">fifth item</a></li> </ul> </div> ''' from pyquery import PyQuery as pq doc = pq(html) print(doc('li'))
返回一个 py对象 doc
结果 返回一个 doc中的所有 li标签


<li class="item-0">first item</li> <li class="item-1"><a href="link2.html">second item</a></li> <li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li> <li class="item-1 active"><a href="link4.html">fourth item</a></li> <li class="item-0"><a href="link5.html">fifth item</a></li>
2、url 网址初始化
from pyquery import PyQuery as pq doc = pq(url='http://www.baidu.com') print(doc('head'))
3、文件初始化
from pyquery import PyQuery as pq doc = pq(filename='demo.html') print(doc('li'))
4、CSS选择器
例如 .list(空格).item-0.active 表示 list类中的(嵌套)同时包含 item-0和 active类的标签
li.siblings() 表示 返回 li标签的所有 同等级的标签(除了 li本身)
5、查找元素
可以用 find查询,例如 item =doc('.list') lis =item.find('li') 来查询 list类下的 li标签
父元素 container = items.parent() 查询得到上一级标签
6、遍历元素
html = ''' <div class="wrap"> <div id="container"> <ul class="list"> <li class="item-0">first item</li> <li class="item-1"><a href="link2.html">second item</a></li> <li class="item-2 active"><a href="link3.html"><span class="bold">third item</span></a></li> <li class="item-3 active"><a href="link4.html">fourth item</a></li> <li class="item-4"><a href="link5.html">fifth item</a></li> </ul> </div> </div> ''' from pyquery import PyQuery as pq doc = pq(html) li = doc('.item-2.active') print(li)
from pyquery import PyQuery as pq doc = pq(html) lis = doc('li').items() print(type(lis)) for li in lis: print(li)
items() 生成器 python基础有写
遍历出 lis的元素
<class 'generator'> <li class="item-0">first item</li> <li class="item-1"><a href="link2.html">second item</a></li> <li class="item-2 active"><a href="link3.html"><span class="bold">third item</span></a></li> <li class="item-3 active"><a href="link4.html">fourth item</a></li> <li class="item-4"><a href="link5.html">fifth item</a></li>
7、获取信息
a.sttr('helf) 或者 a.attr.helf
from pyquery import PyQuery as pq doc = pq(html) a = doc('.item-2.active a') print(a) print(a.attr('href')) print(a.attr.href)
结果如下
<a href="link3.html"><span class="bold">third item</span></a> link3.html link3.html
取到 a标签 然后在 a标签中查询 href属性,如果没用那么显示 None ,不会去别的地方找
8、获取内容
from pyquery import PyQuery as pq doc = pq(html) a = doc('.item-2.active a') print(a) print(a.text())
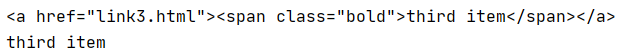
结果如上 会显示 a标签包括子标签内的所有内容,例如
<li class="item-2 active"><a href="link3.html">hello world<span class="bold">third item</span></a></li>
则会显示 hello world 和 thied item 2个
9、DOM操作
removeClass addClass
from pyquery import PyQuery as pq doc = pq(html) li = doc('.item-2.active') print(li) li.removeClass('active') print(li) li.addClass('active') print(li)

删除 对象li中 li的标签 中 class的 active属性
再添加 class active属性
attr css
from pyquery import PyQuery as pq doc = pq(html) li = doc('.item-2.active') print(li) li.attr('name', 'link') print(li) li.css('font-size', '14px') print(li)
可以添加 name属性和 font-size属性
remove
html = ''' <div class="wrap"> Hello, World <p>This is a paragraph.</p> </div> ''' from pyquery import PyQuery as pq doc = pq(html) wrap = doc('.wrap') print(wrap.text()) wrap.find('p').remove() print(wrap.text()) #Hello, World This is a paragraph. #Hello, World
只取到div标签下的内容,除掉子标签的内容
10、伪类选择器
from pyquery import PyQuery as pq doc = pq(html) li = doc('li:first-child') print(li) # <li class="item-0">first item</li> li = doc('li:last-child') print(li) # <li class="item-4"><a href="link5.html">fifth item</a></li> li = doc('li:nth-child(2)') print(li) # <li class="item-1"><a href="link2.html">second item</a></li> li = doc('li:gt(2)') print(li) # <li class="item-3 active"><a href="link4.html">fourth item</a></li> # <li class="item-4"><a href="link5.html">fifth item</a></li> li = doc('li:nth-child(2n)') print(li) # <li class="item-1"><a href="link2.html">second item</a></li> # <li class="item-3 active"><a href="link4.html">fourth item</a></li> li = doc('li:contains(second)') print(li) # <li class="item-1"><a href="link2.html">second item</a></li>
其中 child是从 0开始
contains(xxx) 为包含 xxx内容的标签
