
kubernets理论基础笔记1
容器基础理论
由于同一个宿主机上的所有容器都共享其底层操作系统( 内核 空间), 这就使得 容器在体积上要比传统的虚拟机小得多. 另外启动容器无须启动整个操作系统,所以容器部署和启动的速度更快,开销更小,也更容易迁移.事实上容器赋予了应用程序超强的可移植能力。
Docker可以将几乎任何应用程序及其依赖的运行环境都打包成一个轻量级,可移植,自包含的容器,并能够运行于支持Docker容器引擎的所有操作系统上
chroot环境对文件系统,网络和用户的访问都实现了虚拟化.在实施方面存在着不少局限性,当它与Namespaces和CGroups等技术结合在一起后,才让这种隔离方法从构想变为了现实
Docker在LXC项目的基础上从文件系统, 网络互联到进程隔离 等方面对容器技术进行了进一步的封装,极大地简化了容器的创建和维护过程
Docker本身非常适合用于管理单个容器,一旦开始使用越来越多的容器封装和运行应用程序,必将会导致其管理和编排 变得越来越困难.最终,用户不得不对容器实施分组,以便跨所有容器提供网络、 安全、 监控等服务.于是以Kubernetes为代表的容器编排系统应运而生
同一Pod中的容器共享网络名称空间和存储资源,这些容器可经由本地回环节口lo直接通信,但彼此之间又在Mount、 User及PID等名称空间上保持了隔离
Kubernetes的ConfigMap实现了配置数据与Docker镜像解耦,需要时仅对配置做出变更而无须重新构建Docker镜像为应用开发部署带来很大的灵活性
docker使用环境变量为不同的环境定制配置这样就得在容器启动时将值传入配置,且无法在运行时修改
ConfigMap和Secret能够以环境变量或存储卷的方式接入到Pod资源的容器中还可以实现在容器运行时候自动更新配置信息
kubernetes基础概念
控制器
是一种管理Pod生命周期的资源抽象
使用控制器之后就不再需要手动管理Pod对象了用户只需要声明应用的期望状态控制器就会自动对其进行进程管理Kubernetes中集群级别的大多数功能都是由几个被称为控制器的进程执行实现 的,这几个进程被集成于kube-controller-manager守护进程中.由控制器完成的 功能主要包括生命周期功能和API业务逻辑
存储卷
存储卷(Volume)是独立于容器文件系统之外的存储空间,常用于扩展容器的 存储空间并为它提供持久存储能力。Kubernetes集群上的存储卷大体可分为临时卷、 本地卷和网络卷临时卷和本地卷通常用于数据缓存,持久化的数据则需要放置于持久卷
Annotation
Annotation(注解)是另一种附加在对象之上的键值类型的数据,但它拥有更大的 数据容量.Annotation常用于将各种非标识型元数据(metadata)附加到对象上,但它不能用于标识和选择对象通常也不会被Kubernetes直接使用, 其主要目的是方便工具或用户的阅读及查找等
核心附件
KubeDNS:在Kubernetes集群中调度运行提供DNS服务的Pod
Dashboard:基于Web的UI
Heapster:容器和节点的性能监控与分析系统
Ingress Controller:是在应用层实现的HTTP(S)负载均衡机制
网络类型
1.主机网络
用于各主机之间的通信,例如Master与各Node之间的通信.此地址配置于Kubernetes集群构建之前,它并不能由Kubernetes管理.管理员需要于集群构建之前自行确定其地址配置及管理方式
2.Pod网络
它是一个虚拟网络用于为各Pod对象设定IP地址等网络参数它需要在构建 Kubernetes集群时由管理员进行定义而后在创建Pod对象时由其自动完成各 网络参数的动态配置
Kubernetes的网络模型要求其各Pod对象的IP地址位于同一网络平面内(同一 IP 网段)可以是一个比较大的网络段
3.Service网络
Service网络在Kubernetes集群创建时予以指定,而各Service的地址则在用户创建Service时予以动态配置
Service网络知识
1.ClusterIP类型 仅用于集群内部通信
2.NodePort类型 接入集群外部请求的NodePort类型,它工作于每个节点的主机IP之上
3.LoadBalancer类型的Service
它可以把外部请求负载均衡至多个Node的主机IP的NodePort之上
集群外部的一个负载均衡器,即可将用户请求负载均衡至集群中的部分或者所有节点.它通常是由Cloud Provider自动创建并提供的软件负载均衡器
Service字段解析
1. IP:当前Service对象的ClusterIP
2. Port:暴露的端口,即当前Service用于接收并响应请求的端口
3. TargetPort:容器中的用于暴露的目标端口,由ServicePort路由请求至此 端口
4. NodePort:当前Service的NodePort它是否存在有效值与Type字段中的类型相关
kubernetes资源管理
现代的容器技术被设计用来运行单个进程(包括子进程)时,该进程在容器中PID名称空间中的进程号为1,可直接接收并处理信号,于是,在此进程终止时容器即终止退出
绝大多数场景中都应该于一个容器中仅运行一个进程,它将日志信息直接输出至容器的标准输出,支持用户直接使用命令( kubectl logs)进行获取,这也是Docker及Kubernetes使用容器的标准方式.
分别运行于各自容器的进程之间无法实现基于IPC的通信机制,此时容器间的隔离机制对于依赖于此类通信方式的进程来说却又成了阻碍.Pod对象是一组容器的集合这些容器共享Network、UTS及IPC名称空间. 因此具有相同的域名、 主机名和网络接口,并可通过IPC直接通信
一个Pod对象中的多个容器必须运行于同一工作节点之上
声明式对象配置并不直接指明要进行的对象管理操作,而是提供配置清单文件给Kubernetes系统,并委托系统跟踪活动对象的状态变动.资源对象的创建、 删除及修改操作全部通过唯一的命令apply来完成,并且每次操作时,提供给命令的配置信息都将保存于对象的注解信息( kubectl.kubernetes.io/ last-applied- configuration)中,并通过对比检查活动对象的当前状态、 注解中的配置信息及资源清单中的配置信息三方进行变更合并,从而实现仅修改变动字段的高级补丁机制
Pod创建流程
所有的kubernetes组件都使用watch机制来跟踪检查API Server上相关变化
1.用户通过kubectl或者其他客户端提交Pod Spec给API Server
2.API Server把Pod相关信息写入etcd中,写入完成后API Server会返回确认信息至客户端
3.API Server开始反映etcd中状态变化
4.scheduler通过watch到API Server有新Pod创建但是还没有被绑定的信息
5.scheduler会为这个新Pod挑选一个合适的节点并且更新Pod对象后把数据写回到API Server中
6.节点上的kubelet组件watch到API Server中有nodeName是自己的新Pod对象就会调用本机上的docker启动容器 并将容器启动的结果写入API Server中
7.API Server将kubelet提交来的信息写入etcd中
8.API Server在成功写入etcd后会将确认信息返回kubelet
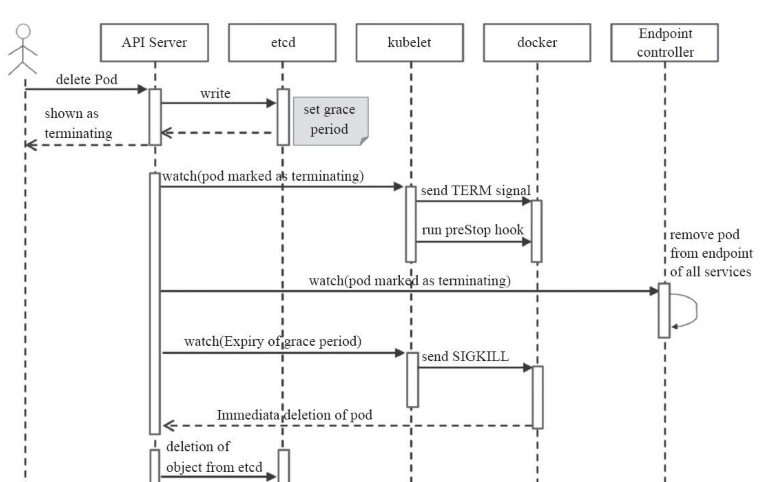
Pod的终止过程
当用户提交删除请求之后,系统就会进行强制删除操作的宽限期倒计时,并将TERM 信息发送给Pod对象的每个容器中的主进程.宽限期倒计时结束后,这些进程将收到强制终止的KILL信号,Pod对象随即也将由API Server 删除
1.用户提交删除Pod请求
2.API Server将会给30秒宽限期,宽限期后把Pod状态变成Terminating状态
3.kubelet组件watch到Pod的状态变成Terminating后启动Pod的关闭过程1.发送TERM信息给容器中的主进程 2.宽限期后发送Kill信号给容器主进程强制关闭
4.端口控制器watch到Pod关闭会自动将所有匹配到此Pod的Service中的对应的端点地址移除
TCP探测和HTTP探测的不同
基于TCP的存活性探测( TCPSocketAction) 用于向容器的特定端口发起TCP请求并尝试建立连接进行结果判定,连接建立成功即为通过检测.相比较来说它比基于HTTP的探测要更高效、更节约资源,但精准度略低,毕竟连接建立成功未必意味着页面资源可用
存活性探测和就绪性探测的不同作用
存活性探测失败会不断的重启Pod中的容器
就绪性探测不会杀死或重启容器以保证其健康性,而是通知其尚未就绪,并触发依赖于其就绪状态的操作(从Service对象中移除此Pod对象)以确保不会有客户端请求接入此Pod对象
就绪性探测在Pod运行期间也有价值,例如Pod A依赖到的PodB因网络故障等 原因而不可用时PodA上的服务应该转为未就绪状态,以免无法向客户端提供完整的 响应
未定义就绪性探测的Pod对象在Pod进入“ Running” 状态后将立即就绪,在容器需要时间进行初始化的场景中,在应用真正就绪之前必然无法正常响应客户端请求.因此生产实践中,必须为关键性Pod资源中的容器定义就绪性探测机制
cpu和内存设置
对于压缩型的资源CPU来说,未定义其请求用量以确保其最小的可用资源时,它可能会被其他的Pod资源压缩至极低的水平,甚至会达到Pod不能够被调度运行的境地。 而对于非压缩型资源来说,内存资源在任何原因导致的紧缺情形下都有可能导致相关的进程被杀死。因此在Kubernetes系统上运行关键型业务相关的Pod 时必须使用requests属性为容器定义资源的确保可用量
容器的资源需求requests仅能达到为其保证可用的最少资源量的目的,它 并不会限制容器的可用资源上限,因此对因应用程序自身存在Bug 等多种原因而导致的系统资源被长时间占用的情况则无计可施,这就需要通过limits属性为容器定义资源的最大可用量
容器的可见资源
虽然容器可用资源受限于requests和limits的定义,但容器中可见的资源量依然是节点级别的可用总量

造成的问题:
典型的是在Pod中运行Java应用程序时,若未使用“- Xmx” 选项指定JVM的堆内存可用总量,它默认会设置为主机内存总量的一个空间比例(如 30%),这会导致容器中的应用程序申请内存资源时将会达到上限而转为OOM Killed
在Pod中运行的nginx应用在配置参数worker_ processes的值为“auto”时,主进程 会创建与Pod中能够访问到的CPU核心数相同数量的worker进程.若Pod的实际可用CPU核心远低于主机级别的数量时,那么这种设置在较大的并发访问负荷下会导致严重的 资源竞争,并将带来更多的内存资源消耗.一个较为妥当的解决方案是使用Downward API
Pod的服务质量级别
因为Kubernetes允许节点资源对limits的过载使用,这意味着节点无法同时满足 其上的所有Pod对象以资源满载的方式运行.所以在内存资源紧缺时应该以何种次序先后终止哪些Pod对象.Kubernetes无法自行对此做出决策,它需要借助于Pod 对象的优先级完成判定.根据Pod对象的requests和limits属性Kubernetes将Pod对象归类到BestEffort、 Burstable和Guaranteed三个服务质量(Quality of Service,QoS)类别
Guaranteed:
每个容器都为CPU资源设置了具有相同值的requests和limits 属性,以及每个容器都为内存资源设置了具有相同值的requests和limits属性的 Pod资源会自动归属于此类别,这类Pod资源具有最高优先级
Burstable:
至少有一个容器设置了CPU或内存资源的requests属性,具有中等优先级
BestEffort:
未为任何一个容器设置requests或limits属性的Pod资源将自动 归属于此类别,它们的优先级为最低级别
Pod控制器组成部分
标签选择器
期望的Pod的副本数量
DaemonSet的副本是个固定值1,所以不需要指定Pod副本数
DaemonSet默认确保每个工作节点上运行一个Pod副本,也可以设置成部分工作节点
只有必须将Pod对象运行于固定的几个节点并且需要先于其他Pod启动时,才有必要使用DaemonSet控制器,否则就应该使用Deployment控制器
DaemonSet并不是基于期望的副本数来控制Pod资源数量,而是基于节点数量但 template是必选字段.Node-Selector字段的值为空,表示它需要运行于集群中的每个节点之上
Pod模板
Pod控制器原理
ReplicaSet的副本数量,标签选择器甚至是Pod模板都可以随时按需进行修改,不过仅改动期望的副本数量会对现存的Pod副本产生直接影响.修改标签选择器可能会使得现有的Pod副本的标签变得不再匹配,此时ReplicaSet控制器要做的不过是不再计入它们而已,并不会删除原来控制的Pod
在创建完成后ReplicaSet也不会再关注Pod对象中的实际内容,因此Pod模板的改动 也只会对后来新建的Pod副本产生影响.之前创建的Pod不会进行任何修改
确保自己控制下的Pod健康运行,探测到由其管控的Pod对象因其所在的工作节点故障而不可用时自动请求由调度器于其他工作节点创建缺失的Pod副本
Pod标签的修改
修改Pod资源的标签即可将其从控制器的管控之下移出,当然,修改后的标签如果又能被其他控制器资源的标签选择器所命中,则此时它又成了隶属于另一控制器的副本.如果修改其标签后的Pod对象不再隶属于任何控制器,那么它就将成为自主式Pod,与此前手动直接创建的Pod对象的特性相同,即误删除或所在的工作节点故障都会造成其永久性的消失
改动Pod模板的定义对已经创建完成的活动对象无效,但在用户逐个手动关闭其旧 版本的Pod资源后就能以新代旧,实现控制器下应用版本的滚动升级
本文来自博客园,作者:不懂123,转载请注明原文链接:https://www.cnblogs.com/yxh168/p/12550011.html

