
爬取B站的文章并存入csv表
前言:
对于一个网站的图片、文字音视频等,如果我们一个个的下载,不仅浪费时间,而且很容易出错。Python爬虫帮助我们获取需要的数据,这个数据是可以快速批量的获取。
工具使用:
开发工具: Visual Studio
开发环境:python-3.9.7-amd64, Windows10
使用工具包:
1 2 3 4 5 6 | import requestsfrom lxml import etreeimport os# 下载进度条from tqdm import tqdmimport csv |
项目思路解析:
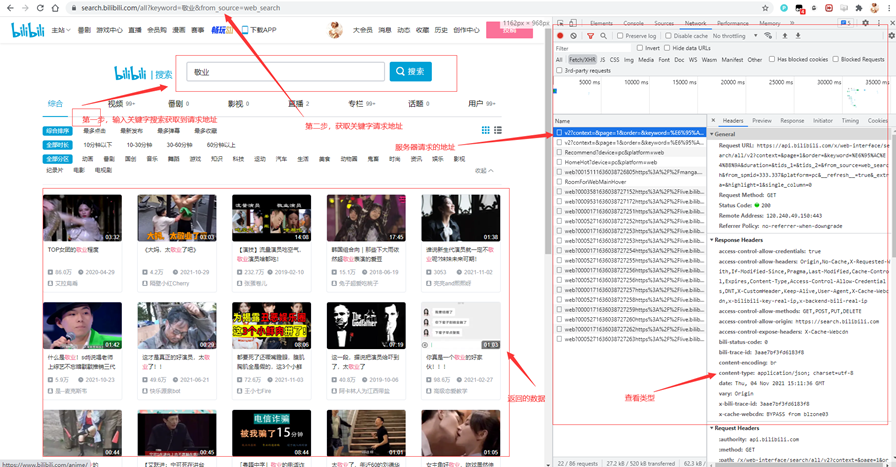
这里拿到请求地址https://search.bilibili.com/article?keyword=敬业&page=1,然后定位自己需要的元素
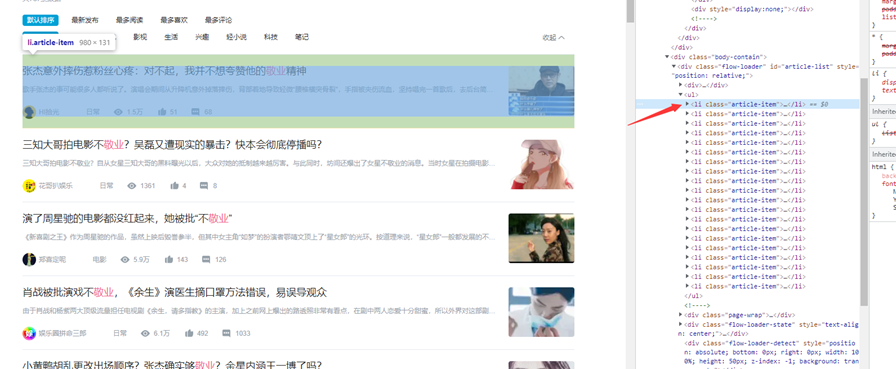
Li标签里面就是我们需要的数据,然后我们定位到关键词里标题,最后以此类推元素的代码位置。
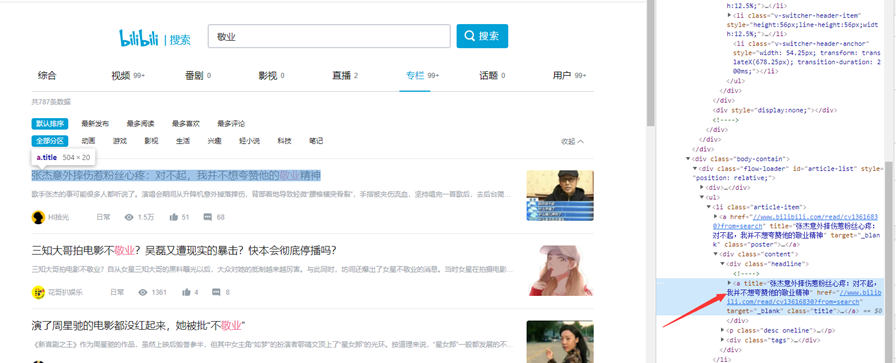
代码如下:
这里的关键字可以后期代码输入,不用写死数据,便于不用频繁的修改代码。

还有这里的页数,也是可以用代码进行抓完全部网页数据,这里为了演示就把数据写死了,只爬取两页数据。
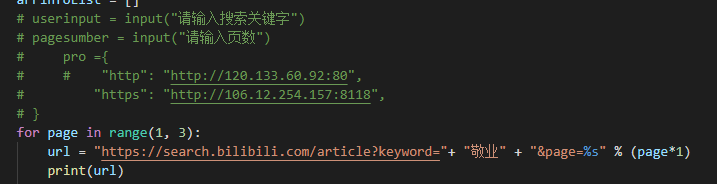
以下是元素(例如:标题,热度的数据)定位的代码
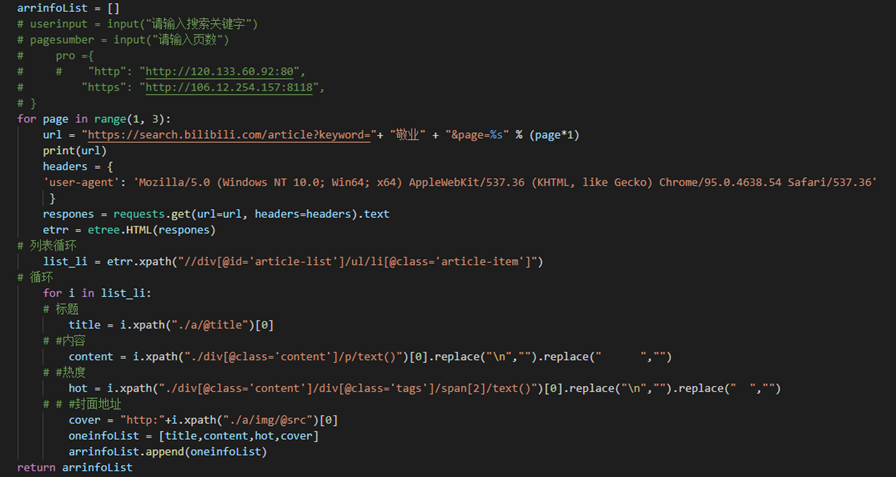
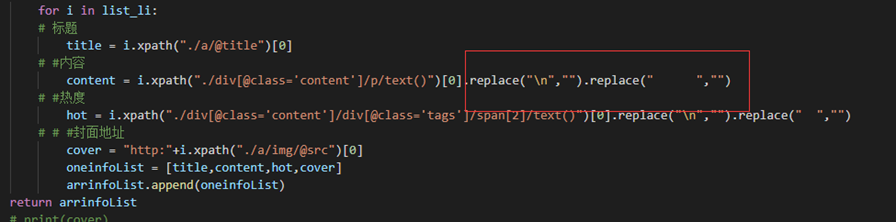
这里的replace是为了清除不需要的数据,方便于后面的数据分析。
拿完数据,我们就要把数据进行存储化,存入csv表。
这里是建立一个文件夹,用于存放csv表
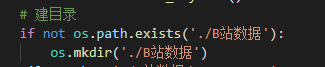
Csv存入的地址的名字

书写csv的表头

意思是csv的表头

项目完整代码:
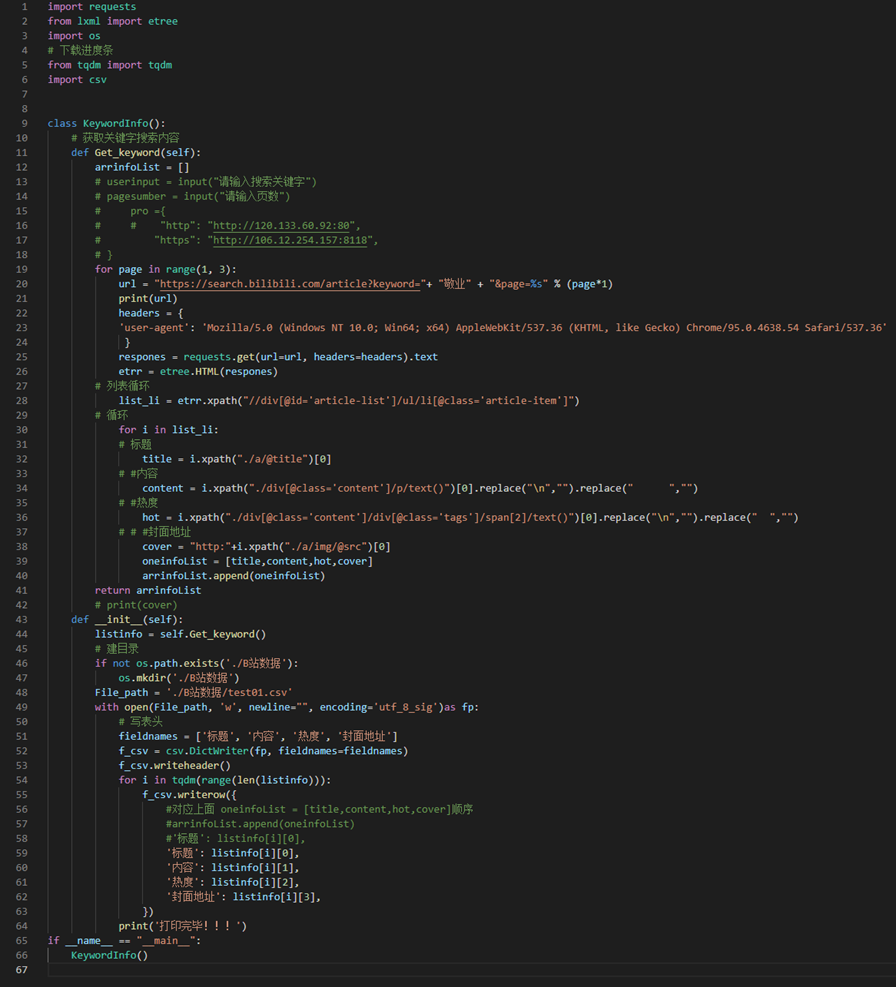
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 | import requestsfrom lxml import etreeimport os# 下载进度条from tqdm import tqdmimport csvclass KeywordInfo(): # 获取关键字搜索内容 def Get_keyword(self): arrinfoList = [] # userinput = input("请输入搜索关键字") # pagesumber = input("请输入页数") # pro ={ # # "http": "http://120.133.60.92:80", # "https": "http://106.12.254.157:8118", # } for page in range(1, 3): url = "https://search.bilibili.com/article?keyword="+ "敬业" + "&page=%s" % (page*1) print(url) headers = { 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.54 Safari/537.36' } respones = requests.get(url=url, headers=headers).text etrr = etree.HTML(respones) # 列表循环 list_li = etrr.xpath("//div[@id='article-list']/ul/li[@class='article-item']") # 循环 for i in list_li: # 标题 title = i.xpath("./a/@title")[0] # #内容 content = i.xpath("./div[@class='content']/p/text()")[0].replace("\n","").replace(" ","") # #热度 hot = i.xpath("./div[@class='content']/div[@class='tags']/span[2]/text()")[0].replace("\n","").replace(" ","") # # #封面地址 cover = "http:"+i.xpath("./a/img/@src")[0] oneinfoList = [title,content,hot,cover] arrinfoList.append(oneinfoList) return arrinfoList # print(cover) def __init__(self): listinfo = self.Get_keyword() # 建目录 if not os.path.exists('./B站数据'): os.mkdir('./B站数据') File_path = './B站数据/test01.csv' with open(File_path, 'w', newline="", encoding='utf_8_sig')as fp: # 写表头 fieldnames = ['标题', '内容', '热度', '封面地址'] f_csv = csv.DictWriter(fp, fieldnames=fieldnames) f_csv.writeheader() for i in tqdm(range(len(listinfo))): f_csv.writerow({ #对应上面 oneinfoList = [title,content,hot,cover]顺序 #arrinfoList.append(oneinfoList) #'标题': listinfo[i][0], '标题': listinfo[i][0], '内容': listinfo[i][1], '热度': listinfo[i][2], '封面地址': listinfo[i][3], }) print('打印完毕!!!')if __name__ == "__main__": KeywordInfo() |
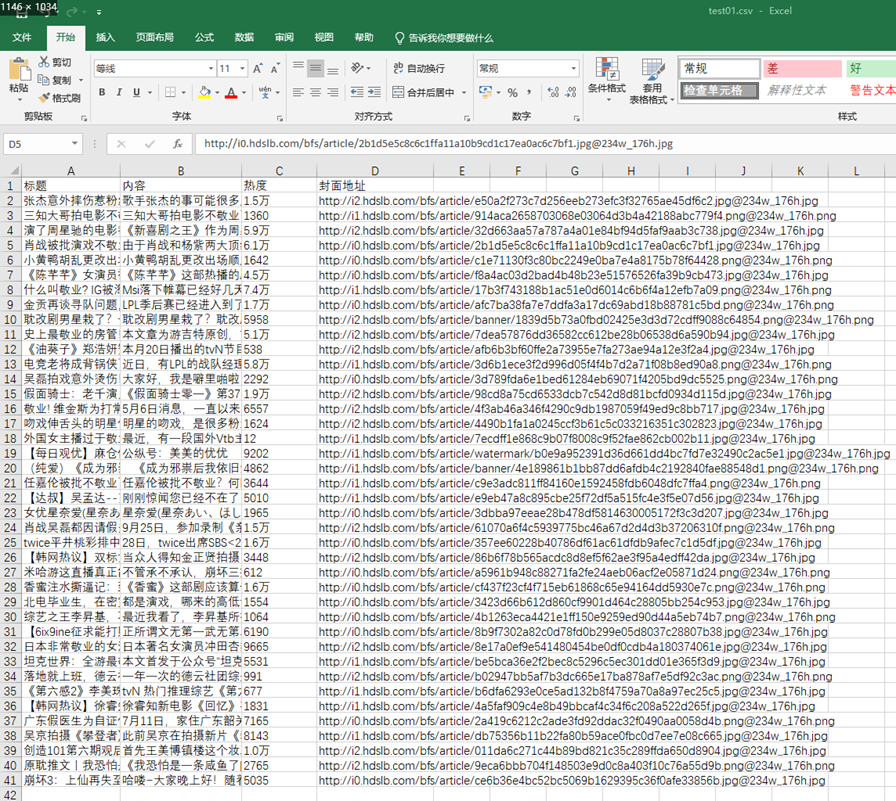
程序运行结果:



1 https://search.bilibili.com/article?keyword=敬业&page=1 2 3 https://search.bilibili.com/article?keyword=敬业&page=2 4 5 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 40/40 [00:00<00:00, 40108.09it/s] 6 7 打印完毕!!!
参考:https://blog.csdn.net/lucky_shi/article/details/105172283


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:基于图像分类模型对图像进行分类
· go语言实现终端里的倒计时
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 25岁的心里话
· 闲置电脑爆改个人服务器(超详细) #公网映射 #Vmware虚拟网络编辑器
· 零经验选手,Compose 一天开发一款小游戏!
· 因为Apifox不支持离线,我果断选择了Apipost!
· 通过 API 将Deepseek响应流式内容输出到前端