
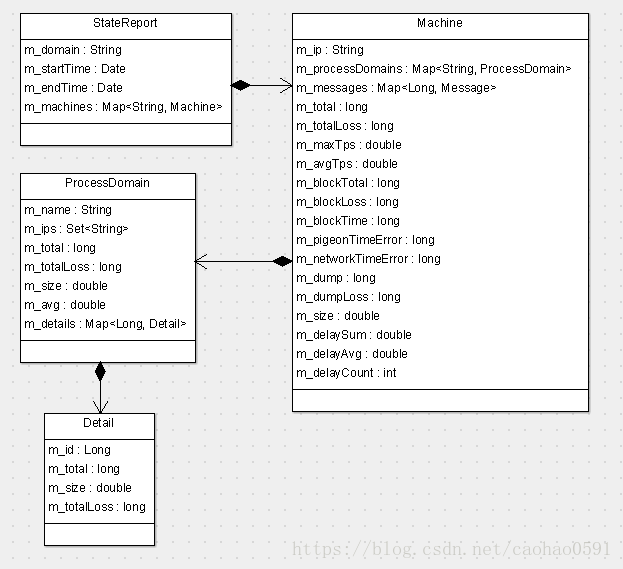
CAT服务端初始化
Cat模块

Cat-client : cat客户端,编译后生成 cat-client-2.0.0.jar ,用户可以通过它来向cat-home上报统一格式的日志信息,可以集成到 mybatis、spring、微服务 dubbo 的监控等等流行框架。
Cat-consumer: 用于实时分析从客户端提供的数据。在实际开发和部署中,Cat-consumer和Cat-home是部署在一个JVM内部,每个CAT服务端都可以作为consumer也可以作为home,这样既能减少整个层级结构,也可以增加系统稳定性。
Cat-core:Cat核心模块
Cat-hadoop : 大数据统计依赖模块。
cat-home:大众点评CAT服务器端主程序,编译安装之后生成 cat-alpha-3.0.0.war 包部署于servlet容器中,我们用的是Tomcat,war包依赖cat-client.jar、cat-consumer.jar, cat-core.jar, cat-hadoop.jar 包,通过web.xml 配置,看到Cat会启动 cat-servlet 和 mvc-servlet , mvc-servlet 是一个类似 spring MVC 的框架,用于处理用户WEB管理平台请求。cat-servlet是CAT服务端监听入口,CAT会在这里开启监听端口,接收处理客户端的日志记录请求,本章主要介绍cat-servlet。


<?xml version="1.0" encoding="UTF-8"?> <web-app xmlns="http://java.sun.com/xml/ns/javaee" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://java.sun.com/xml/ns/javaee http://java.sun.com/xml/ns/javaee/web-app_2_5.xsd" version="2.5"> ... <servlet> <servlet-name>cat-servlet</servlet-name> <servlet-class>com.dianping.cat.servlet.CatServlet</servlet-class> <load-on-startup>1</load-on-startup> </servlet> <servlet> <servlet-name>mvc-servlet</servlet-name> <servlet-class>org.unidal.web.MVC</servlet-class> <init-param> <param-name>cat-client-xml</param-name> <param-value>client.xml</param-value> </init-param> <init-param> <param-name>init-modules</param-name> <param-value>false</param-value> </init-param> <load-on-startup>2</load-on-startup> </servlet> ....
Cat-servlet初始化

图1 - 容器初始化类图
CatServlet 首先会调用父类 AbstractContainerServlet 的init方法做初始化工作, 可以认为这是CatServlet的入口,他主要做了3件事情,首先调用基类HttpServlet的init方法对Servlet进行初始化,然后初始化Plexus容器,最后调用子类initComponents初始化Module模块。
public abstract class AbstractContainerServlet extends HttpServlet { public void init(ServletConfig config) throws ServletException { super.init(config); try { if(this.m_container == null) { this.m_container = ContainerLoader.getDefaultContainer(); } this.m_logger = this.m_container.getLogger(); this.initComponents(config); } catch (Exception var3) { ... } }
plexus - IOC容器
上面讲到init(...)方法在初始化完Servlet之后调用 ContainerLoader.getDefaultContainer() 初始化plexus容器。
注:这里可能大家不太了解plexus,它相当于Spring的IoC容器,但是它和Spring框架不同,它并不是一个完整的,拥有各种组件的大型框架,仅仅是一个纯粹的IoC容器,它的开发者与Maven的开发者是同一拨人,最初开发Maven的时候,Spring并不成熟,所以Maven的开发者决定使用自己维护的IoC容器Plexus,它与Spring在语法和描述方式稍有不同。在Plexus中,有ROLE的概念,相当于Spring中的一个Bean。支持组件生命周期管理。
非JAVA开发者不懂IOC容器?简单来说,IOC容器就相当于一个对象装载器,对象不是由程序员new创建,而是框架在初始化的时候从配置文件中读取需要实例化的类信息,将信息装入一个对象装载器,然后在需要的时候,从对象装载器中找是否存在该类的信息,存在则返回类的对象。
plexus容器是如何工作的呢?就上面的类图来说,
a. AbstractContainerServlet 通过容器工厂ContainerLoader 的 getDefaultContainer方法,该方法会创建 MyPlexusContainer 容器,MyPlexusContainer是接口 PlexusContainer 的实现,MyPlexusContainer在构造函数中会创建组件管理器(ComponentManager),可以认为每个类都是容器中的一个组件,ComponentManager就是用来管理这些组件的,包括他的生命周期,组件在Plexus容器配置文件中配置。
b.组件管理器(ComponentManager)会创建组件模型管理器(ComponentModelManager)以及组件生命周期管理器(ComponentLifecycle),ComponentModelManager用于存储Plexus容器配置文件中的所有component组件信息,它的loadComponentsFromClasspath()方法会扫描各个jar包中存在的plexus容器配置文件,如图2,将xml内容解析之后放入PlexusModel 列表中。
public class ComponentManager { private Map<String, ComponentBox<?>> m_components = new HashMap(); private PlexusContainer m_container; private ComponentLifecycle m_lifecycle; private ComponentModelManager m_modelManager; private LoggerManager m_loggerManager; public ComponentManager(PlexusContainer container, InputStream in) throws Exception { this.m_container = container; this.m_modelManager = new ComponentModelManager(); this.m_lifecycle = new ComponentLifecycle(this); if(in != null) { this.m_modelManager.loadComponents(in); } this.m_modelManager.loadComponentsFromClasspath(); this.m_loggerManager = (LoggerManager)this.lookup(new ComponentKey(LoggerManager.class, (String)null)); this.register(new ComponentKey(PlexusContainer.class, (String)null), container); this.register(new ComponentKey(Logger.class, (String)null), this.m_loggerManager.getLoggerForComponent("")); } }
我们也可以将我们自己写的类交给容器管理,只需要将类配置到容器配置文件中,例如:cat-consumer/src/main/resources/META-INF/plexus/components-cat-consumer.xml, 只要是存在于 META-INF/plexus/ 目录下,并且文件名以"components-" 开头的 ".xml" 文件,都会被 ComponentModelManager 认为是容器配置文件。

图2 - plexus IOC容器类配置文件
c.然后就可以通过lookup方法找到类,并在首次使用的时候实例化,并且xml配置中的该类依赖的其它类也会被一并实例化,另外如果类方法实现了 Initializable 接口,创建对象后会执行类的 initialize() 方法做一些初始化的工作。
if(component instanceof Initializable) { try { ((Initializable)component).initialize(); } catch (Throwable var5) { ComponentModel model = ctx.getComponentModel(); throw new ComponentLookupException("Error when initializing component!", model.getRole(), model.getHint(), var5); } }
模块的加载 - 模型模式
init(...)函数最后会调用CatServlet的initComponents()方法初始化Module模块。

图3 - 模块初始化类图
initComponents()方法首先创建一个模块上下文 DefaultModuleContext对象,该对象拥有plexus容器的指针,以及server.xml、client.xml配置文件信息 ,服务端配置server.xml中有消息存储路径、HDFS上传等一系列配置,由于cat-home默认是服务端也是客户端,也就是说cat-home自身也会被监控,所以我们在这里看到有client.xml配置,配置文件所在目录由环境变量CAT_HOME指定,如果未指定,默认是/data/appdatas/cat。
随后CatServlet创建一个模块初始器 DefaultModuleInitializer,并调用他的execute(ctx)方法创建并初始化模块。
注:DefaultModuleInitializer有一个模块管理器DefaultModelManager m_manager, 读者可能没有看见m_manager的创建过程,实际上,对象在components-foundation-service.xml配置文件中配置的,然后在plexus容器实例化类对象的过程中创建的,后面还有很多对象的属性也是通过plexus容器注入的。比如DefaultModuleManager的m_topLevelModules属性通过以下配置注入。
<component>
<role>org.unidal.initialization.ModuleManager</role>
<implementation>org.unidal.initialization.DefaultModuleManager</implementation>
<configuration>
<topLevelModules>cat-home</topLevelModules>
</configuration>
</component>
上面XML配置显示m_topLevelModules 指定为cat-home,这样DefaultModuleInitializer通过DefaultModelManager的getTopLevelModules()方法获取的就是CatHomeModule模块对象,可以认为cat-home是一个顶层模块,所有Module都包含getDependencies方法,该方法会找到当前模块所依赖的其他模块,并实例化模块,比如下面cat-home就依赖cat-consumer模块,
public class CatHomeModule extends AbstractModule { @Override public Module[] getDependencies(ModuleContext ctx) { return ctx.getModules(CatConsumerModule.ID); } }
从cat-consumer的getDependencies看出他依赖cat-core模块,cat-core模块又依赖cat-client模块,这样子我们就从顶层模块引出了所有依赖的其它模块,在实例化模块的同时调用模块的setup方法安装模块。在所有模块安装完成之后,依次调用模块的execute方法完成初始化,但是初始化顺序则是按照安装顺序反着来的,cat-client -> cat-core -> cat-consumer -> cat-home ,Modules之间的设计使用了典型的模板模式。
cat-home的setup
在上一章讲到模块初始化的时候, 讲到setup安装cat-home模块,对于客户端的请求的监听处理,就是在这里完成的。
@Named(type = Module.class, value = CatHomeModule.ID) public class CatHomeModule extends AbstractModule { @Override protected void setup(ModuleContext ctx) throws Exception { if (!isInitialized()) { File serverConfigFile = ctx.getAttribute("cat-server-config-file"); ServerConfigManager serverConfigManager = ctx.lookup(ServerConfigManager.class); final TcpSocketReceiver messageReceiver = ctx.lookup(TcpSocketReceiver.class); serverConfigManager.initialize(serverConfigFile); messageReceiver.init(); Runtime.getRuntime().addShutdownHook(new Thread() { @Override public void run() { messageReceiver.destory(); } }); } } }
1、读取 server.xml 配置,装进配置管理器(ServerConfigManager)。
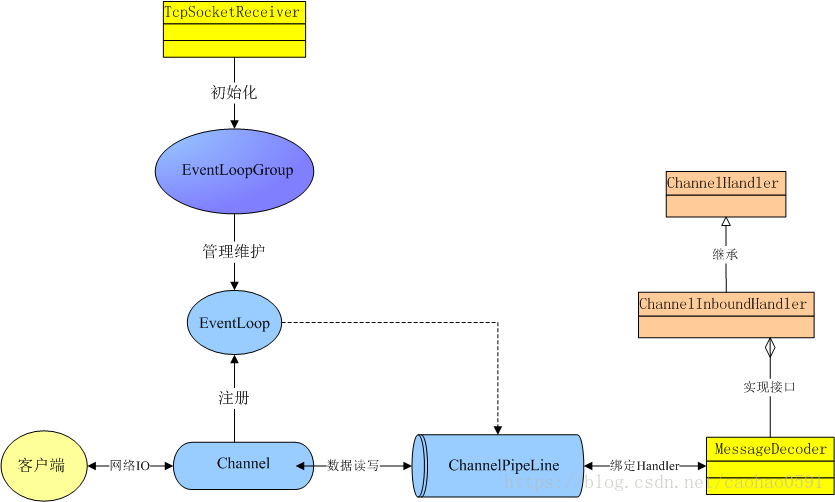
2、创建消息接收器 final TcpSocketReceiver messageReceiver;
3、messageReceiver.init() 初始化服务,采用的经典的 netty reactor 模型。
4、注册一个JVM关闭的钩子,在进程挂掉的时候,执行一些清理现场的代码。
TcpSocketReceiver--- netty reactor 模式的应用
我们来看看CatHomeModule对TcpSocketReceiver的初始化做了什么,如下源码:
public final class TcpSocketReceiver implements LogEnabled { public void init() { try { startServer(m_port); } catch (Throwable e) { m_logger.error(e.getMessage(), e); } } public synchronized void startServer(int port) throws InterruptedException { boolean linux = getOSMatches("Linux") || getOSMatches("LINUX"); int threads = 24; ServerBootstrap bootstrap = new ServerBootstrap(); m_bossGroup = linux ? new EpollEventLoopGroup(threads) : new NioEventLoopGroup(threads); m_workerGroup = linux ? new EpollEventLoopGroup(threads) : new NioEventLoopGroup(threads); bootstrap.group(m_bossGroup, m_workerGroup); bootstrap.channel(linux ? EpollServerSocketChannel.class : NioServerSocketChannel.class); bootstrap.childHandler(new ChannelInitializer<SocketChannel>() { @Override protected void initChannel(SocketChannel ch) throws Exception { ChannelPipeline pipeline = ch.pipeline(); pipeline.addLast("decode", new MessageDecoder()); } }); bootstrap.childOption(ChannelOption.SO_REUSEADDR, true); bootstrap.childOption(ChannelOption.TCP_NODELAY, true); bootstrap.childOption(ChannelOption.SO_KEEPALIVE, true); bootstrap.childOption(ChannelOption.ALLOCATOR, PooledByteBufAllocator.DEFAULT); try { m_future = bootstrap.bind(port).sync(); m_logger.info("start netty server!"); } catch (Exception e) { m_logger.error("Started Netty Server Failed:" + port, e); } } }
1、创建EventLoopGroup对象, EventLoopGroup是用来处理IO操作的多线程事件循环器,m_bossGroup作为一个acceptor负责接收来自客户端的请求,然后分发给m_workerGroup用来所有的事件event和channel的IO。
2、创建ServerBootstrap对象,ServerBootstrap 是一个启动Epoll(非Linux为NIO)服务的辅助启动类,他将设置bossGroup和workerGroup两个多线程时间循环器。
3、接下来的channel()方法设置了ServerBootstrap 的 ChannelFactory,这里传入的参数是EpollServerSocketChannel.class (非Linux为NioServerSocketChannel.class),也就是说这个ChannelFactory创建的就是EpollServerSocketChannel/NioServerSocketChannel的实例。
Channel是Netty的核心概念之一,它是Netty网络通信的主体,他从EventLoopGroup获得一个EventLoop,并注册到该EventLoop,channel生命周期内都和该EventLoop在一起,由它负责对网络通信连接的打开、关闭、连接和读写操作。如果是对于读写事件,执行线程调度pipeline来处理用户业务逻辑。
4、接下来bootstrap.childHandler的目的是添加一个handler,用来监听已经连接的客户端的Channel的动作和状态,传入的 ChannelInitializer重写了initChannel方法,这个方法在Channel被注册到EventLoop的时候会被调用。
5、initChannel会创建ChannelPipeline对象,并调用addLast添加ChannelHandler。有网络请求时,ChannelPipeline会调用ChannelHandler来处理,有ChannelInboundHandler和ChannelOutboundHandler两种,ChannelPipeline会从头到尾顺序调用ChannelInboundHandler处理网络请求内容,从尾到头调用ChannelOutboundHandler处理网络请求内容。这也是Netty用来灵活处理网络请求的机制之一,因为使用的时候可以用多个decoder和encoder进行组合,从而适应不同的网络协议。而且这种类似分层的方式可以让每一个Handler专注于处理自己的任务而不用管上下游,这也是pipeline机制的特点。这跟TCP/IP协议中的五层和七层的分层机制有异曲同工之妙。
在这里,ChannelPipeline添加的 ChannelHandler 是MessageDecoder ,MessageDecoder的祖先类实现了ChannelHandler接口,他本质上还是一个Handler,是网络IO事件具体处理类,当客户端将日志数据上传到服务器之后,会交给MessageDecoder 解码数据,然后进行后续处理。
6、调用 childOption 设置 channel 的参数。
7、最后调用bind()方法启动服务。
关于netty ,我就讲到这里,网上关于netty框架的文章非常多,大家可以自行去查。
消息的解码
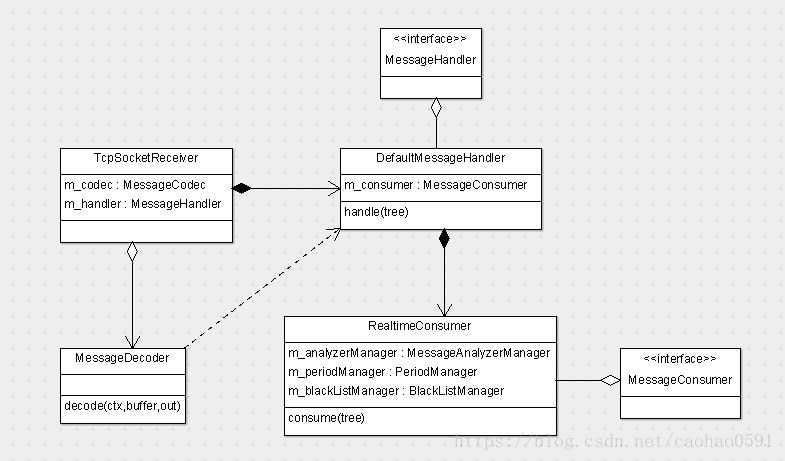
上一章我们讲到Netty将接收到的消息交给 MessageDecoder 去做解码,解码是交由PlainTextMessageCodec对象将接收到的字节码反序列化为MessageTree对象(所有的消息都是由消息树来组织),具体的解码逻辑在这里暂不做详细阐述,在第三章我们会阐述编码过程,解码只是编码的一个逆过程。
解码之后调用 DefaultMessageHandler 的 handle方法对消息进行处理,handle方法就干了一件事情,就是调用 m_consumer.consume(tree) 方法去消费消息树,在消费模块,CAT实现了队列化,异步化,在消息消费章节会详细阐述。
当然netty handler也是支持异步处理的,我们也可以将 DefaultMessageHandler 像 MessageDecoder那样向netty注册handler, 再由netty来做线程池分发。
public class MessageDecoder extends ByteToMessageDecoder { @Override protected void decode(ChannelHandlerContext ctx, ByteBuf buffer, List<Object> out) throws Exception { if (buffer.readableBytes() < 4) { return; } buffer.markReaderIndex(); int length = buffer.readInt(); ... ByteBuf readBytes = buffer.readBytes(length + 4); ... DefaultMessageTree tree = (DefaultMessageTree) m_codec.decode(readBytes); readBytes.resetReaderIndex(); tree.setBuffer(readBytes); m_handler.handle(tree); m_processCount++; ... } }
CAT消息分发大概的架构如下:
分析管理器的初始化
服务器将接收到的消息交给解码器(MessageDecoder)去做解码最后交给具体的消费者(RealtimeConsumer)去消费消息。
RealtimeConsumer 是在什么时候被创建初始化? 在第一章我们讲到,CatHomeModule通过调用setup安装完成之后,会调用 execute 进行初始化的工作, 在execute方法中调用ctx.lookup(MessageConsumer.class) 方法来通过容器实例化RealtimeConsumer。
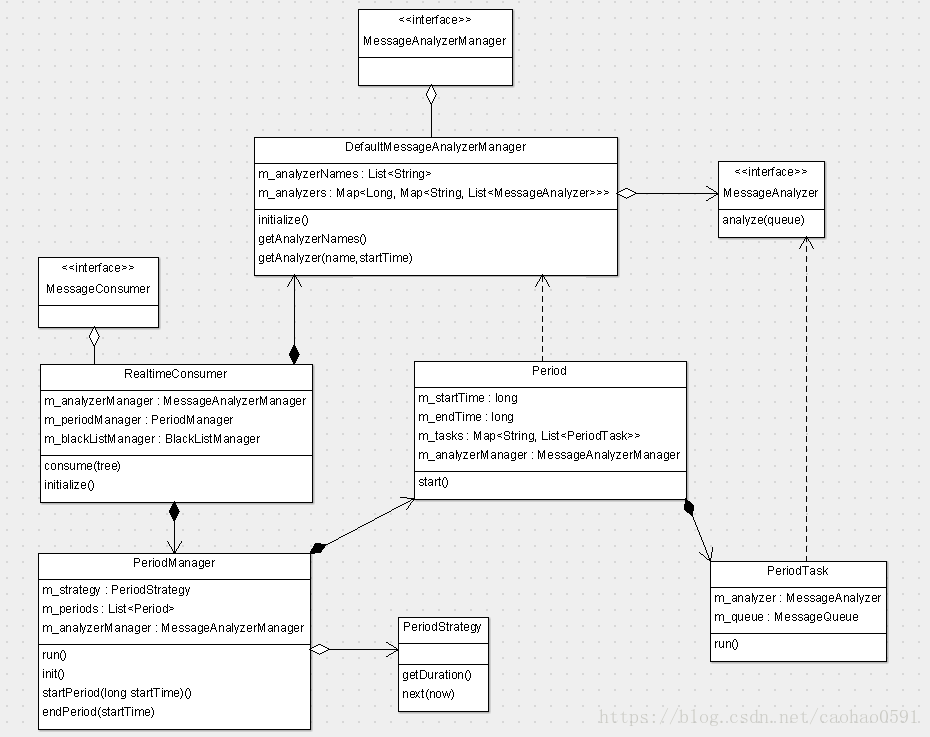
在消费者中,最重要的一个概念就是消息分析器(MessageAnalyzer),所有的消息分析统计,报表创建都是由消息分析器来完成,所有的分析器(MessageAnalyzer)都由消息分析器管理对象(MessageAnalyzerManager)管理,RealtimeConsumer就拥有消息分析器管理对象的指针,在消费者初始化之前,我们会先实例化 MessageAnalyzerManager,然后调用initialize() 方法初始化分析管理器。
public class DefaultMessageAnalyzerManager extends ContainerHolder implements MessageAnalyzerManager, Initializable, LogEnabled { private List<String> m_analyzerNames; private Map<Long, Map<String, List<MessageAnalyzer>>> m_analyzers = new HashMap<Long, Map<String, List<MessageAnalyzer>>>(); @Override public void initialize() throws InitializationException { Map<String, MessageAnalyzer> map = lookupMap(MessageAnalyzer.class); for (MessageAnalyzer analyzer : map.values()) { analyzer.destroy(); } m_analyzerNames = new ArrayList<String>(map.keySet()); ... } }
initialize() 方法通过IOC容器的lookupMap方法,找到所有的消息分析器。一共12个,如下图,然后取出分析器的名字,放到m_analyzerNames 列表里,可以认为每个名字对应一种分析器,不同的分析器都将从不同角度去分析、统计上报的消息,汇总之后生成不同的报表,我们如果有自己的扩展需求,需要对消息做其它处理,也可以添加自己的分析器,只需要符合CAT准则即可。 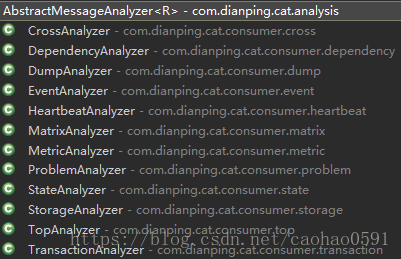
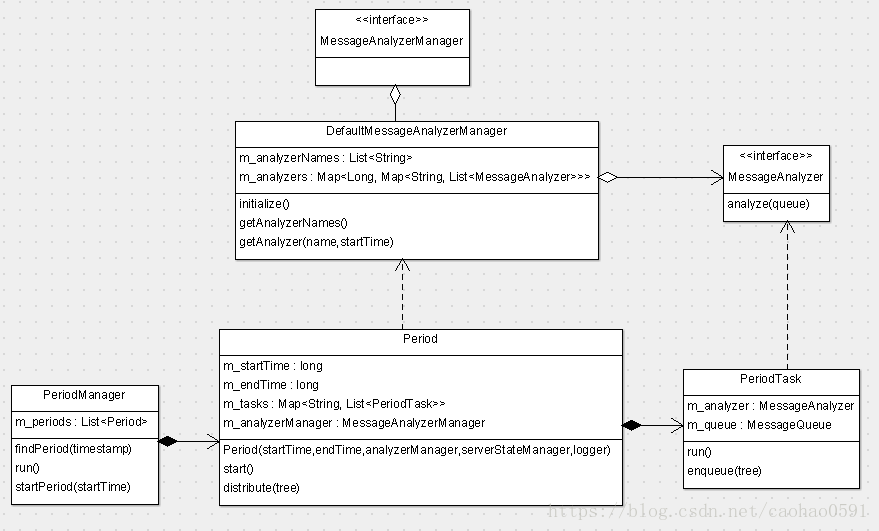
消费者与周期管理器的初始化
消息分析器管理对象初始化之后,RealtimeConsumer 会执行 initialize() 来实现自身的初始化,
public class RealtimeConsumer extends ContainerHolder implements MessageConsumer, Initializable, LogEnabled { @Inject private MessageAnalyzerManager m_analyzerManager; private PeriodManager m_periodManager; @Override public void initialize() throws InitializationException { m_periodManager = new PeriodManager(HOUR, m_analyzerManager, m_serverStateManager, m_logger); m_periodManager.init(); Threads.forGroup("cat").start(m_periodManager); } }
RealtimeConsumer的初始化很简单,仅包含3行代码,它的任务就是实例化并初始化周期管理器(PeriodManager),并将分析器管理对象(MessageAnalyzerManager)的指针传给它,PeriodManager保留分析管理器指针仅仅用于在启动一个Period的时候,将MessageAnalyzerManager的指针传递给Period。
PeriodManager的构造函数中,最核心的工作就是创建一个周期策略对象(PeriodStrategy),每个周期的开始/结束会参考PeriodStrategy的计算结果,变量duration是每个周期的长度,默认是1个小时,而且周期时间是整点时段,例如:1:00-2:00, 2:00-3:00,周期时间是报表的最小统计单元,即分析器产生的每个报表对象,都是当前周期时间内的统计信息。
接下来RealtimeConsumer将会调用 m_periodManager.init() 启动第一个周期,还是上面代码,我们会计算当前时间所处的周期的开始时间,是当前时间的整点时间,比如现在是 13:50, 那么startTime=13:00,然后entTime=startTime + duration 算得结束时间为 14:00, 然后根据起始结束时间来创建 Period 对象,传入分析器的指针。并将周期对象加入到m_periods列表交给PeriodManager管理。最后调用period.start 启动第一个周期。
public class PeriodManager implements Task { private PeriodStrategy m_strategy; private List<Period> m_periods = new ArrayList<Period>(); public PeriodManager(long duration, MessageAnalyzerManager analyzerManager, ServerStatisticManager serverStateManager, Logger logger) { m_strategy = new PeriodStrategy(duration, EXTRATIME, EXTRATIME); m_active = true; m_analyzerManager = analyzerManager; m_serverStateManager = serverStateManager; m_logger = logger; } public void init() { long startTime = m_strategy.next(System.currentTimeMillis()); startPeriod(startTime); } private void startPeriod(long startTime) { long endTime = startTime + m_strategy.getDuration(); Period period = new Period(startTime, endTime, m_analyzerManager, m_serverStateManager, m_logger); m_periods.add(period); period.start(); } }
我们再回到ReatimeConsumer的initialize()初始化方法,第三行代码,Threads.forGroup("cat").start(m_periodManager) 将开启一个周期管理线程,线程执行代码如下run()函数,每隔1秒钟会计算是否需要开启一个新的周期,value>0就开启新的周期, value=0啥也不干,value<0的异步开启一个新线程结束上一个周期。结束线程调用PeriodManager的endPeriod(long startTime)方法完成周期的清理工作,然后将period从m_periods列表移除出去。
public class PeriodManager implements Task { private List<Period> m_periods = new ArrayList<Period>(); @Override public void run() { while (m_active) { try { long now = System.currentTimeMillis(); long value = m_strategy.next(now); if (value > 0) { startPeriod(value); } else if (value < 0) { // last period is over,make it asynchronous Threads.forGroup("cat").start(new EndTaskThread(-value)); } } catch (Throwable e) { Cat.logError(e); } Thread.sleep(1000L); } } private void endPeriod(long startTime) { int len = m_periods.size(); for (int i = 0; i < len; i++) { Period period = m_periods.get(i); if (period.isIn(startTime)) { period.finish(); m_periods.remove(i); break; } } } }
什么是周期?
好了,我们在上两节讲了分析器的初始化,周期管理器的初始化,那么,什么是周期?为什么会有周期?他是如何工作的?
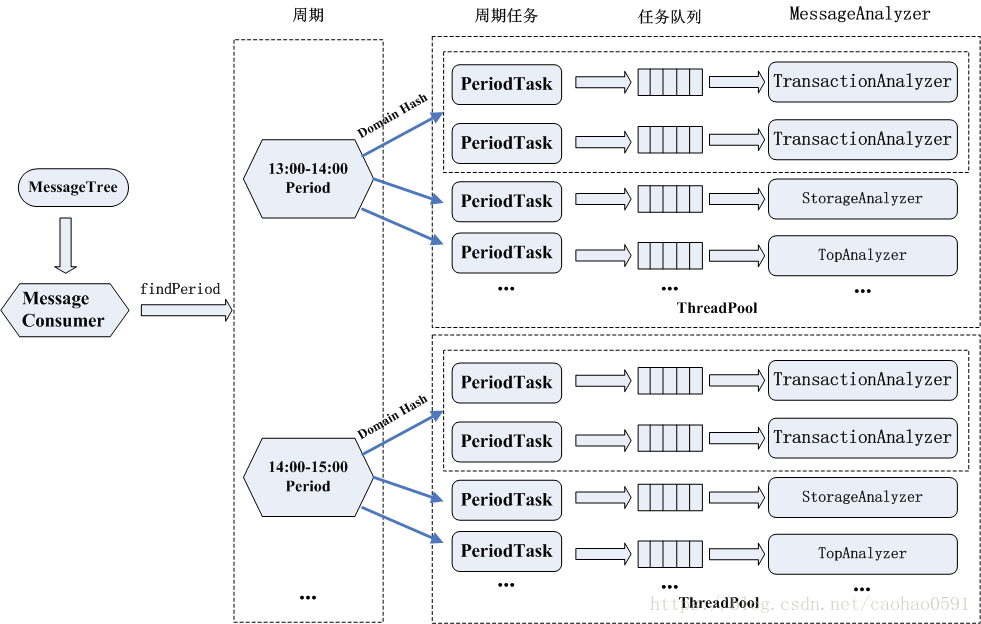
可以认为周期Period就是一个消息分发的控制器,相当于MVC的Controller,受PeriodManager的管理,所有客户端过来的消息,都会根据消息时间戳从PeriodManager中找到消息所属的周期对象(Period),由该周期对象来派发消息给每个注册的分析器(MessageAnalyzer)来对消息做具体的处理。
然而Period并不是直接对接分析器(MessageAnalyzer), 而是通过PeriodTask来与MessageAnalyzer交互,Period类有个成员变量m_tasks, 类型为Map<String, List<PeriodTask>>, Map的key是String类型,表示分析器的名字,比如top、cross、transaction、event等等,我们一共有12种类别的分析器,不过实际处理过程中,CAT作者移除了他认为比较鸡肋的Matrix、Dependency两个分析器,只剩下10个分析器了,如图10。
m_analyzerNames.remove("matrix");
m_analyzerNames.remove("dependency");

图10:参与任务处理的分析器名称
Map的value为List<PeriodTask> 是一个周期任务的列表, 也就是说,每一种类别的分析器,都会有至少一个MessageAnalyzer的实例,每个MessageAnalyzer都由一个对应的PeriodTask来分配任务,MessageAnalyzer与PeriodTask是1对1的关系,每种类别分析器具体有多少个实例由 getAnalyzerCount() 函数决定,默认是 1 个, 但是有些分析任务非常耗时,需要多个线程来处理,保证处理效率,比如 TransactionAnalyzer就是2个。
public class TransactionAnalyzer extends AbstractMessageAnalyzer<TransactionReport> implements LogEnabled { @Override public int getAnalyzerCount() { return 2; } }
消息分发的时候,每一笔消息默认都会发送到所有种类分析器处理,但是同一种类别的分析器下如果有多个MessageAnalyzer实例,采用domain hash 选出其中一个实例安排处理消息,分发算法参考下面源码:
public class Period { private Map<String, List<PeriodTask>> m_tasks; public void distribute(MessageTree tree) { ... String domain = tree.getDomain(); for (Entry<String, List<PeriodTask>> entry : m_tasks.entrySet()) { List<PeriodTask> tasks = entry.getValue(); int length = tasks.size(); int index = 0; boolean manyTasks = length > 1; if (manyTasks) { index = Math.abs(domain.hashCode()) % length; } PeriodTask task = tasks.get(index); boolean enqueue = task.enqueue(tree); ... } ... } }
周期任务-任务队列
上一节我们讲到与MessageAnalyzer交互是由PeriodTask来完成的,那么周期任务PeriodTask在哪里被创建?他怎么与分析器进行交互, 在Period实例化的同时,PeriodTask就被创建了,我们看看Period类的构造函数:
public class Period { private Map<String, List<PeriodTask>> m_tasks; public Period(long startTime, long endTime, MessageAnalyzerManager analyzerManager, ServerStatisticManager serverStateManager, Logger logger) { ... List<String> names = m_analyzerManager.getAnalyzerNames(); m_tasks = new HashMap<String, List<PeriodTask>>(); for (String name : names) { List<MessageAnalyzer> messageAnalyzers = m_analyzerManager.getAnalyzer(name, startTime); for (MessageAnalyzer analyzer : messageAnalyzers) { MessageQueue queue = new DefaultMessageQueue(QUEUE_SIZE); PeriodTask task = new PeriodTask(analyzer, queue, startTime); //加入 m_tasks ... } } } }
构造函数首先获取所有分析器名字,我们说过每个名字对应一种分析器,然后根据分析器名字和周期时间,获取当前周期、该种类分析器所有实例,之前说过,有些类别分析任务逻辑复杂,耗时长,会需要更多的分析线程处理,为每个分析器都创建一个 PeriodTask,并为每一个PeriodTask创建任务队列。客户端消息过来,会由Period分发给所有种类的PeriodTask,同一类分析器下有多个分析器(MessageAnalyzer)的时候,只有一个MessageAnalyzer会被分发,采用domain hash选出这个实例,在这里,分发实际上就是插入PeriodTask的任务队列。
构造函数最后将创建PeriodTask加入m_tasks中。
在Period被实例化之后, 周期管理器(PeriodManager)就调用 period.start() 开启一个周期了,start逻辑很简单, 就是启动period下所有周期任务(PeriodTask)线程。任务线程也非常简单,就是调用自己的分析器的分析函数analyze(m_queue)来处理消息。
public class PeriodTask implements Task, LogEnabled { private MessageAnalyzer m_analyzer; private MessageQueue m_queue; @Override public void run() { try { m_analyzer.analyze(m_queue); } catch (Exception e) { Cat.logError(e); } } }
接下来我们看下分析函数做了什么,下面是源码,只展示了核心逻辑部分,分析程序轮训从PeriodTask传入的任务队列中取出消息,然后调用process处理,具体的处理逻辑就是由process完成的,process是一个抽象函数,具体实现由各种类分析器子类来实现。
当然这里的前提是分析器处在激活状态,并且本周期未结束,结束的定义是当前时间比周期时间+延迟结束时间更晚,延迟结束时间会在后面周期策略章节详细讲解,一旦周期结束,分析器将会把
剩余的消息分析完然后关闭。
public abstract class AbstractMessageAnalyzer<R> extends ContainerHolder implements MessageAnalyzer { protected abstract void process(MessageTree tree); @Override public void analyze(MessageQueue queue) { while (!isTimeout() && isActive()) { MessageTree tree = queue.poll(); if (tree != null) { ... process(tree); ... } } ... } protected boolean isTimeout() { long currentTime = System.currentTimeMillis(); long endTime = m_startTime + m_duration + m_extraTime; return currentTime > endTime; } }
消息分发
消息从客户端发上来,是如何到达PeriodTask的,又是如何分配分析器的?
客户端消息发送到服务端,经过解码之后,就调用 MessageConsumer的 consume() 函数对消息进行消费。源码如下:
public class RealtimeConsumer extends ContainerHolder implements MessageConsumer, Initializable, LogEnabled { @Override public void consume(MessageTree tree) { String domain = tree.getDomain(); String ip = tree.getIpAddress(); if (!m_blackListManager.isBlack(domain, ip)) { long timestamp = tree.getMessage().getTimestamp(); Period period = m_periodManager.findPeriod(timestamp); if (period != null) { period.distribute(tree); } else { m_serverStateManager.addNetworkTimeError(1); } } else { m_black++; if (m_black % CatConstants.SUCCESS_COUNT == 0) { Cat.logEvent("Discard", domain); } } } }
consume函数会首先判断domain和ip是否黑名单,如果是黑名单,丢弃消息,否则,根据消息时间戳,找到对应的周期(Period),交给Period对消息进行分发,分发逻辑前面讲过,Period将消息插入PeriodTask队列,由分析器(MessageAnalyzer)轮训从队列里面取消息进行具体处理,每笔消息默认会被所有类别分析器处理,当同一类别分析器有多个MessageAnalyzer实例的时候,选择其中一个处理,选择算法:
Math.abs(domain.hashCode()) % length
详细的源码可参考章节什么是周期?
周期策略
在创建周期策略对象的时候,会传入3个参数,一个是duration,也就是每个周期的时间长度,默认为1个小时,另外两个extraTime和aheadTime分别表示我提前启动一个周期的时间和延迟结束一个周期的时间,默认都是3分钟,我们并不会卡在整点时间,例如10:00去开启或结束一个周期,因为周期创建是需要消耗一定时间,这样可以避免消息过来周期对象还未创建好,或者消息还没有处理完,就要去结束周期。
当然,即使提前创建了周期对象(Period),并不意味着就会立即被分发消息,只有到了该周期时间才会被分发消息。
下面看看具体的策略方法,我们首先计算当前时间的周期启动时间(startTime),是当前时间的整点时间,比如当前时间是 22:47.123,那么startTime就是 22:00.000,注意这里的时间都是时间戳,单位为毫秒。
接下来判断是否开启当前周期,如果startTime大于上次周期启动时间(m_lastStartTime),说明应该开启新的周期,由于m_lastStartTime初始化为 -1, 所以CAT服务端初始化之后第一个周期会执行到这里,并记录m_lastStartTime。
上面if如果未执行,我们会判断当前时间比起上次周期启动时间是不是已经过了 57 分钟(duration - aheadTime ),即提前3分钟启动下一个周期。
如果上面if还未执行,我们则认为当前周期已经被启动,那么会判断是否需要结束当前周期,即当前时间比起上次周期启动时间是不是已经过了 63 分钟(duration + extraTime),即延迟3分钟关闭上一个周期。
public class PeriodStrategy { public long next(long now) { long startTime = now - now % m_duration; // for current period if (startTime > m_lastStartTime) { m_lastStartTime = startTime; return startTime; } // prepare next period ahead if (now - m_lastStartTime >= m_duration - m_aheadTime) { m_lastStartTime = startTime + m_duration; return startTime + m_duration; } // last period is over if (now - m_lastEndTime >= m_duration + m_extraTime) { long lastEndTime = m_lastEndTime; m_lastEndTime = startTime; return -lastEndTime; } return 0; } }
消息分析器的构建
在周期Period构造函数中,我们会通过m_analyzerManager.getAnalyzer(name, startTime)获取分析器(MessageAnalyzer)列表。getAnalyzer函数源码如下,首先会清理2小时之前的分析器,然后从m_analyzers中获取分析器(MessageAnalyzer),我们先来看看m_analyzers 的结构
Map<Long, Map<String, List<MessageAnalyzer>>>
最外层Map的key的类型为long,代表由startTime对应的周期。value还是一个Map,Map的key类型是String,是分析器的名字,代表一类分析器,value是MessageAnalyzer列表,同一类分析器,至少有一个MessageAnalyzer实例,对于复杂耗时的分析任务,我们通常会开启更多的实例处理。
如果在Map中没有找到我们需要的分析器,我们就创建,创建的过程函数会通过synchronized给map上锁,以保证创建过程map同时只能被一个线程访问,保证了线程安全。
分析器创建之后会被初始化,然后放入m_analyzers中,
public class DefaultMessageAnalyzerManager extends ContainerHolder implements MessageAnalyzerManager, Initializable,LogEnabled { private Map<Long, Map<String, List<MessageAnalyzer>>> m_analyzers = new HashMap<Long, Map<String, List<MessageAnalyzer>>>(); @Override public List<MessageAnalyzer> getAnalyzer(String name, long startTime) { // remove last two hour analyzer Map<String, List<MessageAnalyzer>> temp = m_analyzers.remove(startTime - m_duration * 2); ... Map<String, List<MessageAnalyzer>> map = m_analyzers.get(startTime); if (map == null) { synchronized (m_analyzers) { map = m_analyzers.get(startTime); if (map == null) { map = new HashMap<String, List<MessageAnalyzer>>(); m_analyzers.put(startTime, map); } } } List<MessageAnalyzer> analyzers = map.get(name); if (analyzers == null) { synchronized (map) { analyzers = map.get(name); if (analyzers == null) { analyzers = new ArrayList<MessageAnalyzer>(); MessageAnalyzer analyzer = lookup(MessageAnalyzer.class, name); analyzer.setIndex(0); analyzer.initialize(startTime, m_duration, m_extraTime); analyzers.add(analyzer); int count = analyzer.getAnalyzerCount(); for (int i = 1; i < count; i++) { MessageAnalyzer tempAnalyzer = lookup(MessageAnalyzer.class, name); tempAnalyzer.setIndex(i); tempAnalyzer.initialize(startTime, m_duration, m_extraTime); analyzers.add(tempAnalyzer); } map.put(name, analyzers); } } } return analyzers; } }
我们再来看看分析器的大体结构
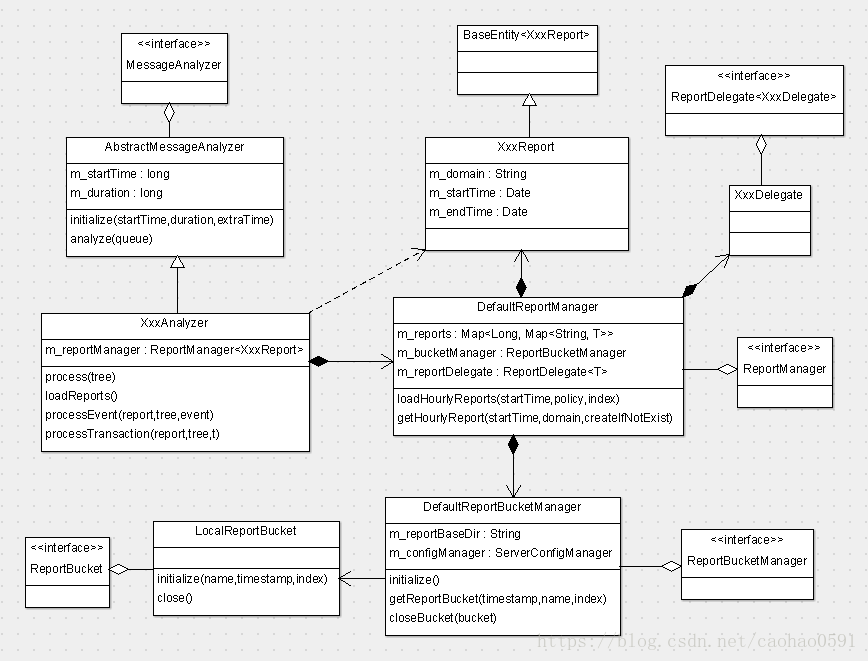
每个分析器都包含有多个报表,报表交由报表管理器(ReportManage)管理,报表在报表管理器中存储结构如下:
Map<Long, Map<String, T>> m_reports
最外层是个Map, key 为long类型,代表的是当前时间周期的报表,value还是一个Map,key类型为String,代表的是不同的domain,一个domain可以理解为一个 Project,value是不同report对象,在分析器处理报表的时候,我们会通过周期管理器(DefaultReportManage)的getHourlyReport方法根据周期时间和domain获取对应的Report。
分析器分析上报的消息之后,生成相应的报表存于Report对象中,报表实体类XxxReport的结构都是由上一章讲的代码自动生成器生成的,配置位于 cat-sonsumer/src/main/resources/META-INFO/dal/model/*.xml 中。
TopAnalyzer
TopAnalyzer分析生成每个周期的报表,不区分domain,所有domain的数据都会汇总到所在周期的domain='cat'的这个报表下去:
getHourlyReport(getStartTime(), Constants.CAT, true);
TopAnalyzer会处理指定Type类型的Event消息,具体有哪些类型会被处理会在 plexus/components-cat-consumer.xml 文件中配置。如下
<implementation>com.dianping.cat.consumer.top.TopAnalyzer</implementation>
<instantiation-strategy>per-lookup</instantiation-strategy>
<configuration>
<errorType>Error,RuntimeException,Exception</errorType>
</configuration>
再来看看TopAnalyzer对Event的处理过程,他会统计当前小时周期内上面类型消息的3个计数。
1、当前小时周期内每分钟,每个domain,也就是每个project的错误计数
2、每个名字对应的错误计数
3、每个IP对应的错误计数
public class TopAnalyzer extends AbstractMessageAnalyzer<TopReport> implements LogEnabled { private void processEvent(TopReport report, MessageTree tree, Event event) { String type = event.getType(); if (m_errorTypes.contains(type)) { String domain = tree.getDomain(); String ip = tree.getIpAddress(); String exception = event.getName(); long current = event.getTimestamp() / 1000 / 60; int min = (int) (current % (60)); Segment segment = report.findOrCreateDomain(domain).findOrCreateSegment(min).incError(); segment.findOrCreateError(exception).incCount(); segment.findOrCreateMachine(ip).incCount(); } } }
EventAnalyzer - 事件发生次数分析
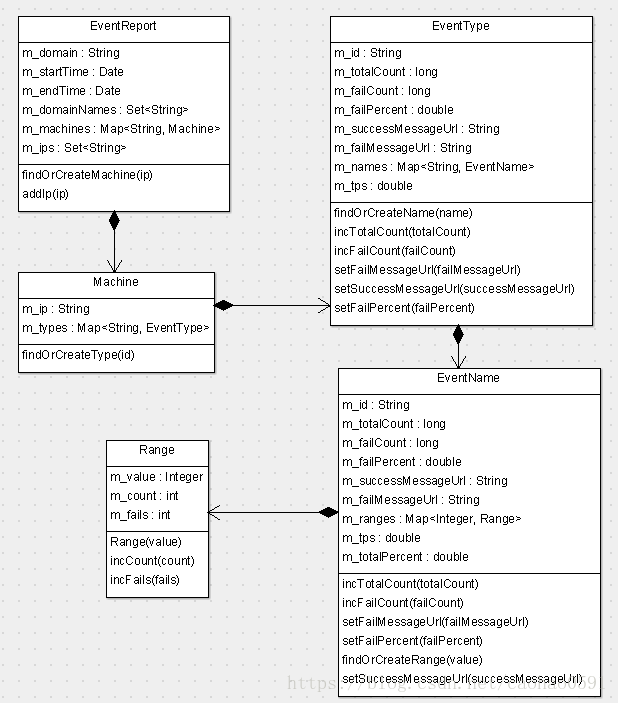
时间分析分析报表会记录Event类型消息的统计汇总信息,每个周期时间,每个domain对应一个EventReport,每个Event报表包含多个Machine对象,按IP区分,注意一下这里的Machine类与后面其它报表的Machine类是有区别的,相同IP下不同类型(Type)的Event信息存在于不同的EventType对象中,EventType记录了该类型消息的总数,失败总数,失败百分比,成功的MessageID,失败的MessageID,tps,以及该类型下各种命名消息。
同一类型但是不同名字(Name)的Event信息存在于不同的EventName对象中,他也会记录该命名消息的总数,失败总数,失败百分比,成功的MessageID,失败的MessageID,tps。
每个EventName对象会存储当前周期时间内,不同类型不同名字的Event消息每分钟的消息总数和失败总数,放在m_ranges字段中。
大家可能疑惑为什么存的成功与失败的MessageID只有一个,而不是一个列表,因为Event报表仅仅只是统计一类事件发生的次数,同类消息做的事情本质上是一样的,所以仅取一条MessageID对应的消息树作为这一类消息的代表。
public class EventAnalyzer extends AbstractMessageAnalyzer<EventReport> implements LogEnabled { private void processEvent(EventReport report, MessageTree tree, Event event, String ip) { int count = 1; EventType type = report.findOrCreateMachine(ip).findOrCreateType(event.getType()); EventName name = type.findOrCreateName(event.getName()); String messageId = tree.getMessageId(); report.addIp(tree.getIpAddress()); type.incTotalCount(count); name.incTotalCount(count); if (event.isSuccess()) { type.setSuccessMessageUrl(messageId); name.setSuccessMessageUrl(messageId); } else { type.incFailCount(count); name.incFailCount(count); type.setFailMessageUrl(messageId); name.setFailMessageUrl(messageId); } type.setFailPercent(type.getFailCount() * 100.0 / type.getTotalCount()); name.setFailPercent(name.getFailCount() * 100.0 / name.getTotalCount()); processEventGrpah(name, event, count); } private void processEventGrpah(EventName name, Event t, int count) { long current = t.getTimestamp() / 1000 / 60; int min = (int) (current % (60)); Range range = name.findOrCreateRange(min); range.incCount(count); if (!t.isSuccess()) { range.incFails(count); } } }
MetricAnalyzer - 业务分析
Metric主要监控业务系统,业务指标,在讲Metric业务报表之前,我们首先讲一下产品线的概念,先看下面类图:

metricProductLine-业务监控是需要配置产品线的,产品线可以认为是一系列project的集合,我们之前说过,每个domain可以认为是一个project,所以产品线也可以认为由多个domain组成,metric产品线的配置文件为 metricProductLine.xml,默认配置如下,最外面是一个company,company下面可以有多条产品线,每条产品线下面又有多个domain。
<?xml version="1.0" encoding="utf-8"?>
<company>
<product-line id="Platform" order="10.0" title="架构" >
<domain id="Cat"/>
<domain id="PumaServer"/>
<domain id="SessionService"/>
</product-line>
</company>
每个domain对应哪条产品线是由产品线配置管理类(ProductLineConfigManager)维护的,产品线配置管理类通过一个Map存储domain id 与 product-line id的映射关系,这些映射关系在产品线配置管理类初始化的时候被创建,通过buildMetricProductLines函数。
除此之外,在初始化函数中,ProductLineConfigManager类还会根据配置初始化ProductLineConfig中指定的其它6中监控类型的产品线,分别是userProductLine-外部监控,applicationProductLine-应用监控,networkProductLine-网络监控,systemProductLine-系统监控,databaseProductLine-数据库监控,cdnProductLine-CDN监控,我们可以在上一章的配置列表中找到这些监控类别的配置。
public class ProductLineConfigManager implements Initializable, LogEnabled { private volatile Map<String, String> m_metricProductLines = new HashMap<String, String>(); private Map<String, String> buildMetricProductLines() { Map<String, String> domainToProductLines = new HashMap<String, String>(); for (ProductLine product : ProductLineConfig.METRIC.getCompany().getProductLines().values()) { for (Domain domain : product.getDomains().values()) { domainToProductLines.put(domain.getId(), product.getId()); } } return domainToProductLines; } @Override public void initialize() throws InitializationException { for (ProductLineConfig productLine : ProductLineConfig.values()) { initializeConfig(productLine); } m_metricProductLines = buildMetricProductLines(); } }
接下来我们看看MetricAnalyzer做了什么事情,他会根据domain获取消息所属的产品线,然后生成对应的业务报表(MetricReport) ,也就是说,一条产品线对应一个业务报表,一个业务报表,一共包含3个维度的统计,总条数、总额度、平均数,我们来看一个客户端的案例。
MessageProducer cat = Cat.getProducer();
Transaction t = cat.newTransaction("URL", "WebPage");
cat.logMetric("payCount", "C", "1");
cat.logMetric("totalfee", "S", "30.5");
cat.logMetric("avgfee", "T", "25.6");
cat.logMetric("order", "S,C", "3,25.6");
Metric event = Cat.getProducer().newMetric("kingsoft", "praise");
event.setStatus("C");
event.addData("3");
event.complete();
status = "C" 表示总条数, 默认加1, "S"表示总额度,"T"表示平均数,"S,C"表示总条数+总金额,logMetric函数的第一个参数 payCount/totalfee/avgfee/order 都是表示的业务名,大家可以看到这里并没有上报type类型,实际上type表示的就是统计到哪条产品线下面,但是我们cat客户端默认会上送domain字段,MetricAnalyzer可以通过根据domain找到对应的产品线,生成相应报表。
然而,我们也可以通过添加type类型对指定产品线做统计,比如案例中的 newMetric("kingsoft", "praise") 调用,我们就指定向 kingsoft 产品线统计,这时候MetricAnalyzer会调用 insertIfNotExsit 函数匹配所有监控类型的 product-line和domain,找到与客户端上报的type、domain匹配的产品线。找到则返回,没有找到的话,会为此新建一条产品线,放入到Metric监控类型中,并更新到数据库。然后为新的产品线创建一个report报表。
public class MetricAnalyzer extends AbstractMessageAnalyzer<MetricReport> implements LogEnabled { private int processMetric(MetricReport report, MessageTree tree, Metric metric) { String group = metric.getType(); String metricName = metric.getName(); String domain = tree.getDomain(); String data = (String) metric.getData(); String status = metric.getStatus(); ConfigItem config = parseValue(status, data); if (StringUtils.isNotEmpty(group)) { boolean result = m_productLineConfigManager.insertIfNotExsit(group, domain); if (!result) { m_logger.error(String.format("error when insert product line info, productline %s, domain %s", group, domain)); } report = findOrCreateReport(group); } if (config != null && report != null) { ... } return 0; } private ConfigItem parseValue(String status, String data) { ConfigItem config = new ConfigItem(); if ("C".equals(status)) { ... } else if ("T".equals(status)) { ... } else if ("S".equals(status)) { ... } else if ("S,C".equals(status)) { ... } else { return null; } return config; } }
接下来我们看下具体报表统计逻辑。
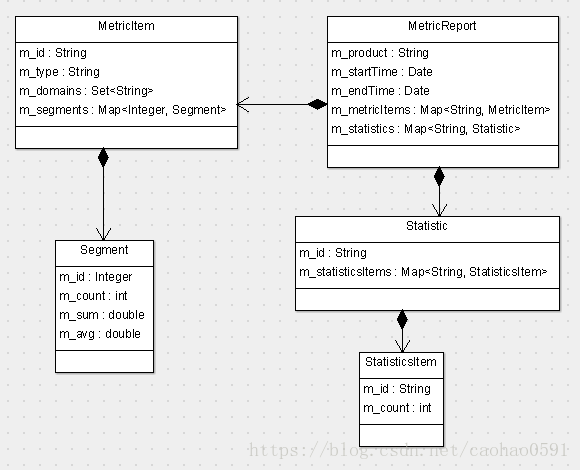
我们知道,每个Metric报表都是一条产品线数据的集合,具体的统计信息记录在 MetricItem 中,domain+METRIC+metricName 用以唯一标识一个MetricItem,MetricItem 的 m_type 字段用于区别统计的维度,所以,我们可以推出, 同一个 domain+metricName 只能用于统计一个维度的数据,Metric报表统计的最小粒度是分钟,MetricItem下每个Segment存储的是每分钟的统计信息。
public class MetricAnalyzer extends AbstractMessageAnalyzer<MetricReport> implements LogEnabled { private int processMetric(MetricReport report, MessageTree tree, Metric metric) { ... ConfigItem config = parseValue(status, data); ... if (config != null && report != null) { long current = metric.getTimestamp() / 1000 / 60; int min = (int) (current % (60)); String key = m_configManager.buildMetricKey(domain, METRIC, metricName); MetricItem metricItem = report.findOrCreateMetricItem(key); metricItem.addDomain(domain).setType(status); updateMetric(metricItem, min, config.getCount(), config.getValue()); config.setTitle(metricName); ProductLineConfig productLineConfig = m_productLineConfigManager.queryProductLine(report.getProduct()); if (ProductLineConfig.METRIC.equals(productLineConfig)) { boolean result = m_configManager.insertMetricIfNotExist(domain, METRIC, metricName, config); ... } } return 0; } private void updateMetric(MetricItem metricItem, int minute, int count, double sum) { Segment seg = metricItem.findOrCreateSegment(minute); seg.setCount(seg.getCount() + count); seg.setSum(seg.getSum() + sum); seg.setAvg(seg.getSum() / seg.getCount()); } }
报表展示配置
统计完成之后, 我们会利用ConfigItem对象为Metric报表首次初始化展示配置,并更新到数据库config表。
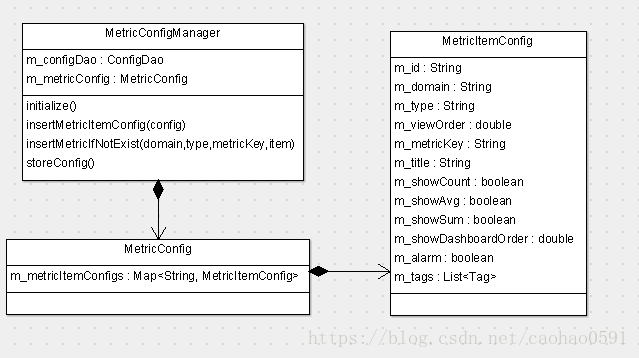
public class MetricConfigManager implements Initializable, LogEnabled { private volatile MetricConfig m_metricConfig; public boolean insertMetricIfNotExist(String domain, String type, String metricKey, ConfigItem item) { String key = buildMetricKey(domain, type, metricKey); MetricItemConfig config = m_metricConfig.findMetricItemConfig(key); if (config != null) { return true; } else { config = new MetricItemConfig(); config.setId(key); config.setDomain(domain); config.setType(type); config.setMetricKey(metricKey); config.setTitle(item.getTitle()); config.setShowAvg(item.isShowAvg()); config.setShowCount(item.isShowCount()); config.setShowSum(item.isShowSum()); m_logger.info("insert metric config info " + config.toString()); return insertMetricItemConfig(config); } } }
ProblemAnalyzer -异常分析
Problem记录整个项目在运行过程中出现的问题,包括一些错误、访问较长的行为。

Problem分析器会通过报表管理器(ReportManager)根据时间和domain,获取对应报表,然后根据IP,找到相应的machine对象,将machine和消息交给问题处理器(ProblemHandler)处理,注意这里的Machine和前面其它报表的Machine不是同一个类。
public class ProblemAnalyzer extends AbstractMessageAnalyzer<ProblemReport> implements LogEnabled, Initializable { public static final String ID = "problem"; @Inject(ID) private ReportManager<ProblemReport> m_reportManager; @Inject private List<ProblemHandler> m_handlers; @Override public void process(MessageTree tree) { String domain = tree.getDomain(); ProblemReport report = m_reportManager.getHourlyReport(getStartTime(), domain, true); report.addIp(tree.getIpAddress()); Machine machine = report.findOrCreateMachine(tree.getIpAddress()); for (ProblemHandler handler : m_handlers) { handler.handle(machine, tree); } } }
CAT默认有DefaultProblemHandler和LongExecutionProblemHandler两个问题处理器,我们可以也定义自己的问题处理器,用于收集我们感兴趣的问题,只需要我们的问题处理器继承自ProblemHandler,并且重写了handle方法,然后在components-cat-consumer.xml中相关模块配置了即可,如下:
<component>
<role>com.dianping.cat.analysis.MessageAnalyzer</role>
<role-hint>problem</role-hint>
<implementation>com.dianping.cat.consumer.problem.ProblemAnalyzer</implementation>
<instantiation-strategy>per-lookup</instantiation-strategy>
<requirements>
...
<requirement>
<role>com.dianping.cat.consumer.problem.ProblemHandler</role>
<field-name>m_handlers</field-name>
<role-hints>
<role-hint>default-problem</role-hint>
<role-hint>long-execution</role-hint>
</role-hints>
</requirement>
</requirements>
</component>
我们先来看看DefaultProblemHandler,他主要用于收集3类Problem,
1、状态不为SUCCESS的事务消息
2、components-cat-consumer.xml中指定errorType类型的Event消息,如下Error、RuntimeException、Exception三种类型消息。
3、heartbeat异常。
<component>
<role>com.dianping.cat.consumer.problem.ProblemHandler</role>
<role-hint>default-problem</role-hint>
<implementation>com.dianping.cat.consumer.problem.DefaultProblemHandler</implementation>
<configuration>
<errorType>Error,RuntimeException,Exception</errorType>
</configuration>
...
</component>
接下来我们看下DefaultProblemHandler处理之后生成的Problem报表的组成结构。

不同IP的Problem消息存储于不同的Machine里面,而且我们还会为不同消息类型、消息名称创建相应的Entity存储消息信息,在Entity中,问题以两种方式存储:
一种是按duration存储,这里的duration指事务执行时间所在的阈值,不过DefaultProblemHandler并不关心duration的不同,所以这里duration全部等于0,我们会在超时调用处理器(LongExecutionProblemHandler)中去做讲解。
另外一种是按线程组来存储,线程组内的消息统计最小粒度为分钟,每个分钟数据统计在Segment中,不管是哪种方式,我们存储的都只是消息树的message_id,而且存储的消息总数有限制,默认每分钟最多只能存储60条消息。
public abstract class ProblemHandler { public static final int MAX_LOG_SIZE = 60; public void updateEntity(MessageTree tree, Entity entity, int value) { Duration duration = entity.findOrCreateDuration(value); List<String> messages = duration.getMessages(); duration.incCount(); if (messages.size() < MAX_LOG_SIZE) { messages.add(tree.getMessageId()); } // make problem thread id = thread group name, make report small JavaThread thread = entity.findOrCreateThread(tree.getThreadGroupName()); if (thread.getGroupName() == null) { thread.setGroupName(tree.getThreadGroupName()); } if (thread.getName() == null) { thread.setName(tree.getThreadName()); } Segment segment = thread.findOrCreateSegment(getSegmentByMessage(tree)); List<String> segmentMessages = segment.getMessages(); segment.incCount(); if (segmentMessages.size() < MAX_LOG_SIZE) { segmentMessages.add(tree.getMessageId()); } } }
LongExecutionProblemHandler
超时调用处理器(LongExecutionProblemHandler)用于监控系统中用时比较长的调用,可以是缓存调用、数据库查询,也可以是一次RPC调用、微服务请求、还可以是一次HTTP请求。超时调用处理器分析的对象仅仅是 Transaction事务类型消息。
public class LongExecutionProblemHandler extends ProblemHandler implements Initializable { private void processTransaction(Machine machine, Transaction transaction, MessageTree tree) { String type = transaction.getType(); if (type.startsWith("Cache.")) { processLongCache(machine, transaction, tree); } else if (type.equals("SQL")) { processLongSql(machine, transaction, tree); } else if (m_configManager.isRpcClient(type)) { processLongCall(machine, transaction, tree); } else if (m_configManager.isRpcServer(type)) { processLongService(machine, transaction, tree); } else if ("URL".equals(type)) { processLongUrl(machine, transaction, tree); } List<Message> messageList = transaction.getChildren(); for (Message message : messageList) { if (message instanceof Transaction) { processTransaction(machine, (Transaction) message, tree); } } } }
超时调用处理器(LongExecutionProblemHandler)会计算事务执行时间,首先查看是否超过了默认阈值设置,每种调用的阈值设置都不同,分4-6个级别,如下,
m_defaultLongServiceDuration = { 50, 100, 500, 1000, 3000, 5000 }
m_defaultLongSqlDuration = { 100, 500, 1000, 3000, 5000 }
m_defaultLongUrlDuration = { 1000, 2000, 3000, 5000 }
m_defalutLongCallDuration = { 100, 500, 1000, 3000, 5000 }
m_defaultLongCacheDuration = { 10, 50, 100, 500 }
在校验完默认阈值之后,还可以根据配置来设置不同domain的超时阈值,在 E:/data/appdatas/cat/server.xml中配置,由ServerConfigManager管理,server.xml所在目录可以通过设置环境变量CAT_HOME指定,如下我配置了 dianping和kingsoft两个domain的超时阈值。
<config local-mode="false" hdfs-machine="false" job-machine="true" alert-machine="false"> ... <consumer> <long-config> <domain name="dianping" url-threshold="30" sql-threshold="15" service-threshold="60"/> <domain name="kingsoft" url-threshold='10' sql-threshold='25' service-threshold='5'/> </long-config> </consumer> ... </config>
超时的事务消息将会被存储到指定machine的entity中,逻辑与DefaultProblemHandler相同,只不过,这里的duration就有了实际意义,问题处理器会根据事务所超出的阈值范围来存储到对应的Duration对象里面去。
自定义自己的问题处理器
TransactionAnalyzer - 事务分析
事务分析器会统计事务(Transaction)类型消息的运行时间,次数,错误次数,当然不是所有Transactionx消息都会被统计,Cache.web、ABTest以及serverFilter配置指定需要过滤的事务消息,会在分析器处理时被丢弃。

统计结果存于TransactionReport,依然是以周期时间和domain来划分不同的报表。
checkForTruncatedMessage ??
相同的domain下的不同IP对应的统计信息依然是存于不同的Machine对象中,截止目前我们已经看到很多报表都包含有Machine类,但是一定注意他们的Machine类都是不同的,可以在cat-consumer/target/generated-sources/dal-model/com/dianping/cat/consumer/ 目录下去查看这些类。
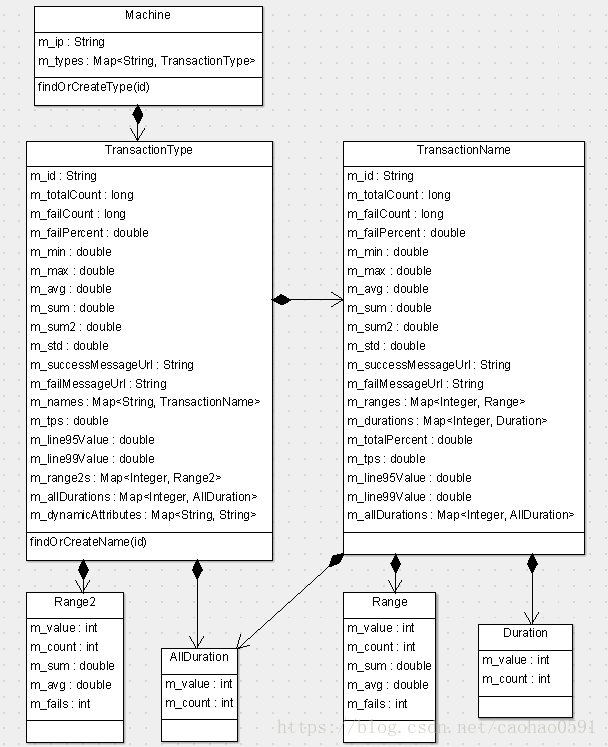
每台机器下面,不同类型的事务统计信息会存于不同的TransactionType对象里,在管理页面上,我们展开指定Type,会看到该Type下所有Name的统计信息,相同Type下的不同名称的统计信息就是分别存在于不同的TransactionName下面,点开每条记录前面的 [:: show ::], 我们将会看到该周期小时内每分钟的统计信息,每分钟的统计存储在 Type 的 Range2对象、Name的Range对象内,实际上Range2和Range对象的代码结构完全一致,除了类名不同,你可以认为他们就是同一个东西。
Type和Name都会统计总执行次数、失败次数、示例链接、最小时间、最大调用时间、平均值、标准差等等信息,同时分析器会选取最近一条消息作为他的示例链接,将messageId存于m_successMessageUrl或者m_failMessageUrl中。
我们会根据一定规则划分几个执行时间区间,将该区间的事务消息总数统计在 AllDuration 和 Duration 对象中。
CrossAnalyzer-调用链分析
在分布式环境中,应用是运行在独立的进程中的,有可能是不同的机器,或者不同的服务器进程。那么他们如果想要彼此联系在一起,形成一个调用链,在Cat中,CrossAnalyzer会统计不同服务之间调用的情况,包括服务的访问量,错误量,响应时间,QPS等,这里的服务主要指的是 RPC 服务,在微服务监控中,这是核心。
在讲 CrossAnalyzer 的处理逻辑之前,我们先看下客户端的埋点的一个模拟情况。
一般情况下不同服务会通过几个ID进行串联。这种串联的模式,基本上都是一样的。在Cat中,我们需要3个ID:
RootId,用于标识唯一的一个调用链
ParentId,父Id是谁?谁在调用我
ChildId,我在调用谁?
那么我们如何传递这些ID?Cat为我们提供了一个内部接口 Cat.Context,但是我们需要自己实现Context,在下面代码中我们首先在before函数中实现了Context 上下文,然后在rpcClient中开启消息事务,并调用 Cat.logRemoteCallClient(context) 去填充Context的这3个MessageID。当然,该函数还记录了一个RemoteCall类型的Event消息。
随后我们用rpcService函数中开启新线程模拟远程RPC服务,并将context上传到 RPC 服务器,在真实环境中,Context是需要跨进程网络传输,因此需要实现序列化接口。
在rpcService中,我们会调用 Cat.logRemoteCallServer(context) 将从rpcClient传过来的Context设置到自己的 Transaction 当中。
随着业务处理逻辑的结束, rpcServer 和 rpcClient 都会分别将自己的消息树上传到CAT服务器分析。
需要注意的是,Service的client和app需要和Call的server以及app对应上,要不然图表是分析不出东西的!
@RunWith(JUnit4.class) public class AppSimulator extends CatTestCase { public Map<String, String> maps = new HashMap<String, String>(); public Cat.Context context; @Before public void before() { context = new Cat.Context() { @Override public void addProperty(String key, String value) { maps.put(key, value); } @Override public String getProperty(String key) { return maps.get(key); } }; } @Test public void simulateHierarchyTransaction() throws Exception { ... //RPC调用开始 rpcClient(); rpcClient2(); ... } protected void rpcClient() { //客户端埋点,Domain为RpcClient,调用服务端提供的Echo服务 Transaction parent = Cat.newTransaction("Call", "CallServiceEcho"); Cat.getManager().getThreadLocalMessageTree().setDomain("RpcClient"); Cat.logEvent("Call.server","localhost"); Cat.logEvent("Call.app","RpcService"); Cat.logEvent("Call.port","8888"); Cat.logRemoteCallClient(context, "RpcClient"); //开启新线程模拟远程RPC服务,将context上传到 RPC 服务器 rpcService(context); parent.complete(); } protected void rpcClient2() { ... //模拟另外一个RpcClient调用Echo服务 rpcService(context, "RpcClient2"); ... } protected void rpcService(final Cat.Context context, final String clientDomain) { Thread thread = new Thread() { @Override public void run() { //服务器埋点,Domain为 RpcService 提供Echo服务 Transaction child = Cat.newTransaction("Service", "Echo"); Cat.getManager().getThreadLocalMessageTree().setDomain("RpcService"); Cat.logEvent("Service.client", localhost); //填客户端地址 Cat.logEvent("Service.app", clientDomain); Cat.logRemoteCallServer(context); //to do your business child.complete(); } }; thread.start(); try { thread.join(); } catch (InterruptedException e) { } } }
接下来我们看看CAT服务器端CrossAnalyzer的逻辑。
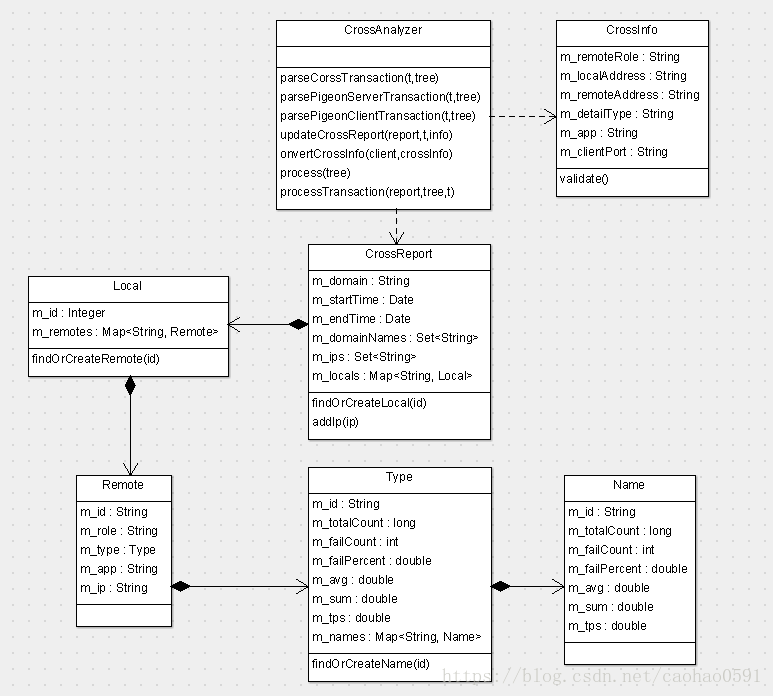
我们依然会为每个周期时间内的每个Domain创建一张报表(CrossReport),然后不同的IP会分配不同的Local对象统计,每个IP又可能会接收来自不同Remote端的调用。
由于这里一个完整的调用链会涉及多个端的多个消息树,我们首先会根据Transaction的类型来判断是RpcService还是RpcClient,如果Type等于PigeonService或Service则该消息来自RpcService,如果Type等于 PigeonCall或Call则来自RpcClient。
先来看看RpcService端消息树的上报处理逻辑,CAT会调用 parsePigeonServerTransaction 函数去填充 CrossInfo 信息,CrossInfo包含的具体内容如下:
localAddress : RpcService的IP地址
remoteAddress : 服务调用者(RpcClient)的IP地址,由type="Service.client" 的Event子消息提供,注意,在处理RpcClient的上报时,我们会根据上报信息中的remoteAddress再次统计该RpcService数据,大家可能会疑惑这里是不是重复统计,事实上他们所处的视角是不一样的,前者是站在服务提供者的视角来统计我完成这次服务所耗费的时间、资源等,而后者则是站在RpcClient视角去统计自己从发出请求到得到结果所需的时长、资源等等,比如这中间就包含网络IO的消耗,这些在后续的报表中会有体现。
app:客户端的Domain, 由type="Service.app"的Event子消息提供。
remoteRole:固定为 Pigeon.Client , 表示远端角色为 Rpc 客户端。
detailType: 固定为 PigeonService , 表示自己角色为 Rpc 服务端。
最后,我们将用CrossInfo信息来更新报表(CrossReport),我们首先根据 localAddress 即 RpcService的 IP 找到或创建 Local对象,然后根据 remoteAddress+remoteRole 找到或创建 Remote 对象,然后统计服务的访问量,错误量,处理时间,QPS。
RpcService提供不只一个服务,不同的服务我们按名字分别统计在不同的Name对象里,比如上面案例,RpcService提供的是Echo服务。
我们再来看看RpcClient端上报处理逻辑,CAT调用parsePigeonClientTransaction函数填充CrossInfo信息,具体如下:
localAddress : RpcClient的IP地址
remoteAddress :服务提供者(RpcService)的地址,由 type="Call.server" 的Event子消息提供。
app:服务提供者的Domain,由type="Call.app" 的Event子消息提供,在统计完RpcClient端数据之后,会通过该属性获取服务提供者的CrossInfo。从RpcClient的视角再次统计RpcService的数据。
port:客户端端口,由 type="Call.port" 的Event子消息提供。
remoteRole:固定为 Pigeon.Server, 表示远端角色为服务提供者。
detailType: 固定为 PigeonCall , 表示自己角色为服务调用者。
然后,我们将用CrossInfo信息来更新报表(CrossReport),也是根据 localAddress 找到Local对象,然后根据 remoteAddress+remoteRole 找到 Remote 对象,进行统计。
接着,我们通过convertCrossInfo函数利用RpcClient的CrossInfo信息去生成服务提供者的CrossInfo信息,这里实际上是为了从RpcClient的视角去统计服务提供者的报表!
public class CrossAnalyzer extends AbstractMessageAnalyzer<CrossReport> implements LogEnabled { private void processTransaction(CrossReport report, MessageTree tree, Transaction t) { CrossInfo crossInfo = parseCorssTransaction(t, tree); if (crossInfo != null && crossInfo.validate()) { updateCrossReport(report, t, crossInfo); String targetDomain = crossInfo.getApp(); if (m_serverConfigManager.isRpcClient(t.getType()) && !DEFAULT.equals(targetDomain)) { CrossInfo serverCrossInfo = convertCrossInfo(tree.getDomain(), crossInfo); if (serverCrossInfo != null) { CrossReport serverReport = m_reportManager.getHourlyReport(getStartTime(), targetDomain, true); updateCrossReport(serverReport, t, serverCrossInfo); } } else { m_errorAppName++; } } ... } }
这里的 serverCrossInfo 被填充了什么数据:
localAddress : RpcClient 的 remoteAddress。
remoteAddress :RpcClient 的 localAddress + clientPort
app:RpcClient 的 Domain。
remoteRole:固定为 Pigeon.Caller, 表示远端角色为服务调用者。
detailType: 固定为 PigeonCall
最后还是用CrossInfo信息来更新报表(CrossReport)。
最后我们看看我们生成了哪些报表数据,3个报表数据,分别是服务调用方 RpcClient和 RpcClient2,以及服务提供方RpcService。

接下来我们看看服务提供方的remotes数据信息,一共3条数据,第1条记录是站在RpcService角度统计服务器完成这2次服务所耗费的时间、资源等,后面2条记录则是站在RpcClient视角去统计自己从发出请求到得到结果所需的时长、资源等等。
第1条记录 duration 为 0.154ms, 第2,3条记录 duration 分别为 1072.62ms、1506.38ms, 两者巨大的时间差一般就是网络 IO 所需的时间,事实上大多数的服务时间的消耗都是在各种IO上。这类服务统称为IO密集型。

StorageAnalyzer --数据库/缓存分析
StorageAnalyzer主要分析一段时间内数据库、Cache访问情况:各种操作访问次数、响应时间、错误次数、长时间访问量等等,当客户端消息过来,StorageAnalyzer首先会分析事务属于数据库操作还是缓存操作,然后进行不同的处理,消息类型如果是SQL则是数据库操作,如果以Cache.memcached开头则认为是缓存操作。

我们首先看看数据库操作的分析过程,下面源码是客户端的案例,这是一个获取cat库config表全部数据的sql查询,我们将数据库操作所有信息都放在一个type="SQL" 的子事务消息中。
@RunWith(JUnit4.class) public class AppSimulator extends CatTestCase { @Test public void simulateHierarchyTransaction() throws Exception { ... Transaction sqlT = cat.newTransaction("SQL", "Select"); //do your SQL query cat.logEvent("SQL.Database", "jdbc:mysql://192.168.20.67:3306/cat"); cat.logEvent("SQL.Method", "select"); cat.logEvent("SQL.Statement", "SELECT", SUCCESS, "select * from cat.config"); sqlT.complete(); ... } }
上面消息上报到服务端之后,分析器将SQL类型子事务取出,调用processSQLTransaction去处理,将结果写入报表StorageReport
processSQLTransaction 首先通过DatabaseParser提取数据库的IP和数据库名称,该信息由type="SQL.Database"的Event子消息提供,该Event消息上报的是数据库连接的URL。
接着我们会获取数据库操作名,type="SQL.Method" 的Event子消息提供,数据库操作分4类,分别是select, update, delete, insert,如果不上报,分析器默认客户端在做select查询。
最后我们会为周期内的每个数据库创建一个Storage报表。并将提取信息放入StorageUpdateParam对象,然后将对象交给StorageReportUpdater来更新Storage报表。
public class StorageAnalyzer extends AbstractMessageAnalyzer<StorageReport> implements LogEnabled { @Inject private DatabaseParser m_databaseParser; @Inject private StorageReportUpdater m_updater; private void processSQLTransaction(MessageTree tree, Transaction t) { String databaseName = null; String method = "select"; String ip = null; String domain = tree.getDomain(); List<Message> messages = t.getChildren(); for (Message message : messages) { if (message instanceof Event) { String type = message.getType(); if (type.equals("SQL.Method")) { method = message.getName().toLowerCase(); } if (type.equals("SQL.Database")) { Database database = m_databaseParser.queryDatabaseName(message.getName()); if (database != null) { ip = database.getIp(); databaseName = database.getName(); } } } } if (databaseName != null && ip != null) { String id = querySQLId(databaseName); StorageReport report = m_reportManager.getHourlyReport(getStartTime(), id, true); StorageUpdateParam param = new StorageUpdateParam(); param.setId(id).setDomain(domain).setIp(ip).setMethod(method).setTransaction(t) .setThreshold(LONG_SQL_THRESHOLD);// .setSqlName(sqlName).setSqlStatement(sqlStatement); m_updater.updateStorageReport(report, param); } } }
数据库与缓存的报表更新逻辑相同,不同ip地址的数据库/缓存的统计信息在不同Machine里面,同时也可能会有不同的Domain访问同一个数据库/缓存,每个Domain的访问都会被单独统计,每个Domain对数据库/缓存不同的操作会统计在不同Operation里,除了当前小时周期的统计汇总外,我们还会用Segment记录每分钟的汇总数据。访问时间超过1秒的数据库操作(缓存是50ms) 会被认为是长时间访问记录。
缓存操作
接下来我们看下缓存的案例,获取memcached中key="uid_1234567"的值,Storage分析器会判断Type是否以"Cache.memcached"开头,如果是,则认为这是一个缓存操作,(这里代码我认为有些稍稍不合理,如果我用的是Redis缓存,我希望上报的Type="Cache.Redis",所以我这里讲源码稍稍做了修改,判断Type如果以"Cache."开头,就认为是缓存)。
@RunWith(JUnit4.class) public class AppSimulator extends CatTestCase { @Test public void simulateHierarchyTransaction() throws Exception { ... Transaction cacheT = cat.newTransaction("Cache.memcached", "get:uid_1234567"); //do your cache operation cat.logEvent("Cache.memcached.server", "192.168.20.67:6379"); cacheT.complete(); ... } }
接下来我们看下Storage分析器的处理逻辑,processCacheTransaction负责分析消息, 事务类型"Cache.memcached"的“Cache.”后面部分将会被提取作为缓存类型,分析器会为每个类型的缓存都创建一个报表,事务名称":"前面部分会被提取作为操作名称,一般缓存有 add,get,hGet,mGet,remove等操作,缓存地址将由type="Cache.memcached.server"的Event子消息提供,最后我们还是将domain、ip、method、事务、阈值等消息放入StorageUpdateParam交由StorageReportUpdater来更新报表,更新逻辑与数据库一致。
public class StorageAnalyzer extends AbstractMessageAnalyzer<StorageReport> implements LogEnabled { @Inject private StorageReportUpdater m_updater; private void processCacheTransaction(MessageTree tree, Transaction t) { String cachePrefix = "Cache."; String ip = "Default"; String domain = tree.getDomain(); String cacheType = t.getType().substring(cachePrefix.length()); String name = t.getName(); String method = name.substring(name.lastIndexOf(":") + 1); List<Message> messages = t.getChildren(); for (Message message : messages) { if (message instanceof Event) { String type = message.getType(); if (type.equals("Cache.memcached.server")) { ip = message.getName(); int index = ip.indexOf(":"); if (index > -1) { ip = ip.substring(0, index); } } } } String id = queryCacheId(cacheType); StorageReport report = m_reportManager.getHourlyReport(getStartTime(), id, true); StorageUpdateParam param = new StorageUpdateParam(); param.setId(id).setDomain(domain).setIp(ip).setMethod(method).setTransaction(t) .setThreshold(LONG_CACHE_THRESHOLD); m_updater.updateStorageReport(report, param); } }
StateAnalyzer
主要是分析CAT服务器自身的异常,他在周期任务运行中,不搜集任何数据,而是在周期结束后,对CAT的整体状况做一个汇总后生成报表,他的报表结构如下。
HeartbeatAnalyzer
分析器HeartbeatAnalyzer用于上报的心跳数据的分析。我们先看看客户端的收集逻辑,CAT客户端在初始化CatClientModule的时候,会开启一个StatusUpdateTask的线程任务,每隔一分钟去收集客户端的心跳状态,通过 Heartbeat 消息上报到客户端,心跳数据以xml格式存在于Heartbeat消息中。
public class CatClientModule extends AbstractModule { @Override protected void execute(final ModuleContext ctx) throws Exception { ... if (clientConfigManager.isCatEnabled()) { // start status update task StatusUpdateTask statusUpdateTask = ctx.lookup(StatusUpdateTask.class); Threads.forGroup("cat").start(statusUpdateTask); ... } } }
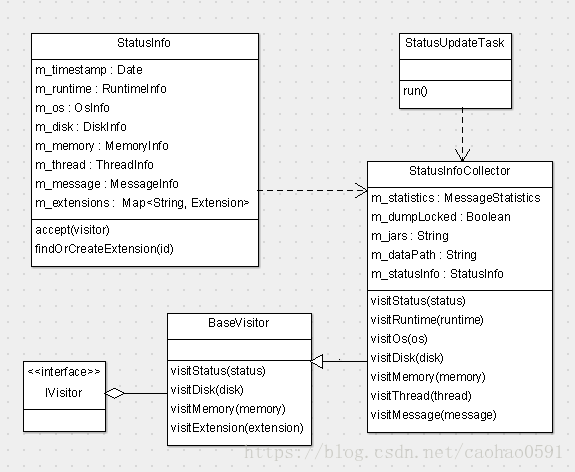
Cat客户端会为Heartbeat消息创建一个System类型事务消息,然后将 Heartbeat 消息放入该事务,信息的收集靠StatusInfoCollector来完成,StatusInfoCollector将收集的数据写入StatusInfo对象,然后StatusUpdateTask将StatusInfo转化成xml之后放到Heartbeat消息数据段上报。
public class StatusUpdateTask implements Task, Initializable { @Override public void run() { //创建类目录, 上报CAT客户端启动信息 ... while (m_active) { long start = MilliSecondTimer.currentTimeMillis(); if (m_manager.isCatEnabled()) { Transaction t = cat.newTransaction("System", "Status"); Heartbeat h = cat.newHeartbeat("Heartbeat", m_ipAddress); StatusInfo status = new StatusInfo(); t.addData("dumpLocked", m_manager.isDumpLocked()); try { StatusInfoCollector statusInfoCollector = new StatusInfoCollector(m_statistics, m_jars); status.accept(statusInfoCollector.setDumpLocked(m_manager.isDumpLocked())); buildExtensionData(status); h.addData(status.toString()); h.setStatus(Message.SUCCESS); } catch (Throwable e) { h.setStatus(e); cat.logError(e); } finally { h.complete(); } t.setStatus(Message.SUCCESS); t.complete(); } //sleep 等待下一次心跳上报 ... } } }
我们上报的XML到底包含哪些数据,我们看下StatusInfo的结构,StatusInfo除了包含上报时间戳之外,还有哪些系统状态信息、附加扩展信息(Extension)会被StatusInfoCollector收集?
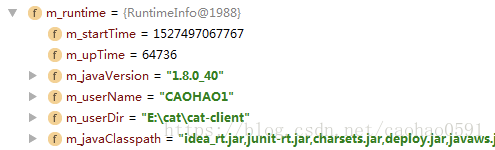
1、运行时数据RuntimeInfo:JAVA版本 java.version、用户名user.name、项目目录user.dir、java类路径等等。
2、操作系统信息 OsInfo,同时创建System附加扩展信息。

3、磁盘信息DiskInfo,磁盘的总量、空闲与使用情况,同时创建Disk附加扩展信息

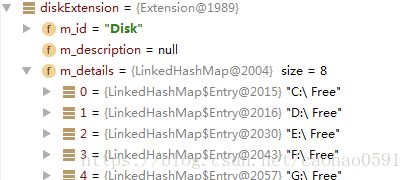
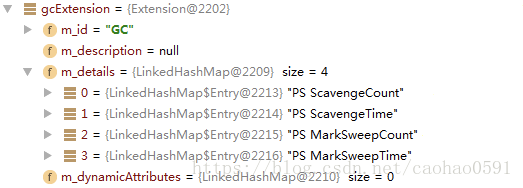
4、内存使用情况MemoryInfo,同时创建垃圾回收扩展信息、JAVA虚拟机堆附加扩展信息


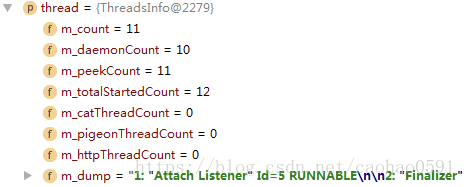
5、线程信息,以及 FrameworkThread 附加扩展信息。

6、Cat使用状态信息

下面我列一个上报的XML数据案例:
<?xml version="1.0" encoding="utf-8"?>
<status timestamp="2018-05-28 16:23:08.625">
<runtime start-time="1527495705011" up-time="114212" java-version="1.8.0_40" user-name="CAOHAO1">
<user-dir>E:\cat\cat-client</user-dir>
<java-classpath>idea_rt.jar,junit-rt.jar,charsets.jar ... </java-classpath>
</runtime>
<os name="Windows 7" arch="amd64" version="6.1" available-processors="4" system-load-average="-1.0" process-time="5881237700" total-physical-memory="8538804224" free-physical-memory="1369870336" committed-virtual-memory="277372928" total-swap-space="17075703808" free-swap-space="4815220736"/>
<disk>
<disk-volume id="C:\" total="77218181120" free="23651565568" usable="23651565568"/>
<disk-volume id="D:\" total="461373435904" free="249596563456" usable="249596563456"/>
...
</disk>
<memory max="1897922560" total="128974848" free="118387592" heap-usage="10961920" non-heap-usage="17081736">
<gc name="PS Scavenge" count="1" time="167"/>
<gc name="PS MarkSweep" count="0" time="0"/>
</memory>
<thread count="11" daemon-count="10" peek-count="11" total-started-count="12" cat-thread-count="0" pigeon-thread-count="0" http-thread-count="0">
<dump>1: "Attach Listener" Id=5 RUNNABLE ... </dump>
</thread>
<message produced="0" overflowed="0" bytes="0"/>
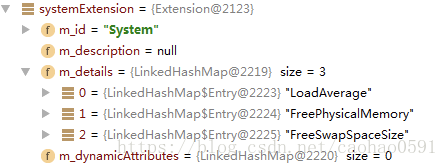
<extension id="System">
<extensionDetail id="LoadAverage" value="-1.0"/>
<extensionDetail id="FreePhysicalMemory" value="1.369247744E9"/>
<extensionDetail id="FreeSwapSpaceSize" value="4.814426112E9"/>
</extension>
<extension id="Disk">
<extensionDetail id="C:\ Free" value="2.3651565568E10"/>
<extensionDetail id="D:\ Free" value="2.49596563456E11"/>
...
</extension>
<extension id="GC">
<extensionDetail id="PS ScavengeCount" value="1.0"/>
<extensionDetail id="PS ScavengeTime" value="167.0"/>
<extensionDetail id="PS MarkSweepCount" value="0.0"/>
<extensionDetail id="PS MarkSweepTime" value="0.0"/>
</extension>
<extension id="JVMHeap">
<extensionDetail id="Code Cache" value="3707200.0"/>
<extensionDetail id="Metaspace" value="1.2053E7"/>
<extensionDetail id="Compressed Class Space" value="1412600.0"/>
<extensionDetail id="PS Eden Space" value="4805792.0"/>
<extensionDetail id="PS Survivor Space" value="5214992.0"/>
<extensionDetail id="PS Old Gen" value="941136.0"/>
</extension>
<extension id="FrameworkThread">
<extensionDetail id="HttpThread" value="0.0"/>
<extensionDetail id="CatThread" value="0.0"/>
<extensionDetail id="PigeonThread" value="0.0"/>
<extensionDetail id="ActiveThread" value="11.0"/>
<extensionDetail id="StartedThread" value="12.0"/>
</extension>
<extension id="CatUsage">
<extensionDetail id="Produced" value="2.0"/>
<extensionDetail id="Overflowed" value="0.0"/>
<extensionDetail id="Bytes" value="1038.0"/>
</extension>
</status>
我们再来看看服务端的分析逻辑,HeartbeatAnalyzer会为每个Domain创建一张心跳报表HeartbeatReport,不同IP的机器心跳数据存在于不同Machine对象里,每分钟的心跳数据都由一个Period对象存储;
HeartbeatAnalyzer首先将XML还原为StatusInfo,然后会用StatusInfo的RuntimeInfo、OsInfo、DiskInfo、MemoryInfo、ThreadInfo、MessageInfo的信息以及Extensions的动态属性m_dynamicAttributes去更新Period的m_extensions。

DumpAnalyzer -- 原始消息LogView存储
DumpAnalyzer 与其它分析器有点不同,它不是为了报表而设计,而是用于原始消息LogView的存储,与报表统计不一样,他的数据量非常大,几年前美团点评每天处理消息就达到1000亿左右,大小大约100TB,单物理机高峰期每秒要处理100MB左右的流量,因为数据量比较大所以存储整体要求就是批量压缩以及随机读,采用队列化、异步化、线程池等技术来保证并发。

当有客户端消息过来,DumpAnalyzer会调用本地消息处理器管理类(LocalMessageBucketManager) 的 storeMessage 方法存储消息,LocalMessageBucketManager是LogView管理的核心类,我们先看一看 LocalMessageBucketManager 对象的初始化函数 initialize() 的处理逻辑:
1、首先获取消息存储的基础路径(m_baseDir),默认是 /data/appdatas/cat/bucket/dump, 在 server.xml 中可以配置,消息在基础路径之内,会根据domain、机器、时间等元素来分门别类的存储。
2、开启 BlockDumper 线程, 将本地消息处理器(LocalMessageBucket)、阻塞队列(BlockingQueue)以及统计信息的指针传入BlockDumper 对象,当内存消息块到达 64K 的时候, 该线程会异步将内存消息块写入数据文件和索引文件。
3、开启LogviewUploader线程,将自己的指针、本地消息处理器、HDFS上传对象(HdfsUploader)以及配置管理器的指针传入LogviewUploader对象,该用于异步将文件上传到 HDFS, 前提是配置了 hdfs 上传配置。
4、开启20个消息压缩线程(本地模式仅2个线程),并为每个线程分配一个阻塞队列,当DumpAnalyzer接收到消息请求,会将消息写入该队列,MessageGzip会轮训从队列取消息处理,注意这里虽然有20个队列,然而正常我们只插入前19个队列,只有在前面入队失败了,消息将会被插入最后那个队列,可以认为最后那个队列是前面队列的一个备用队列。
public class LocalMessageBucketManager extends ContainerHolder implements MessageBucketManager, Initializable, LogEnabled { @Override public void initialize() throws InitializationException { m_baseDir = new File(m_configManager.getHdfsLocalBaseDir(ServerConfigManager.DUMP_DIR)); Threads.forGroup("cat").start(new BlockDumper(m_buckets, m_messageBlocks, m_serverStateManager)); Threads.forGroup("cat").start(new LogviewUploader(this, m_buckets, m_logviewUploader, m_configManager)); if (m_configManager.isLocalMode()) { m_gzipThreads = 2; } for (int i = 0; i < m_gzipThreads; i++) { LinkedBlockingQueue<MessageItem> messageQueue = new LinkedBlockingQueue<MessageItem>(m_gzipMessageSize); m_messageQueues.put(i, messageQueue); Threads.forGroup("cat").start(new MessageGzip(messageQueue, i)); } m_last = m_messageQueues.get(m_gzipThreads - 1); } @Override public void storeMessage(final MessageTree tree, final MessageId id) { boolean errorFlag = true; int hash = Math.abs((id.getDomain() + '-' + id.getIpAddress()).hashCode()); int index = (int) (hash % m_gzipThreads); MessageItem item = new MessageItem(tree, id); LinkedBlockingQueue<MessageItem> queue = m_messageQueues.get(index % (m_gzipThreads - 1)); boolean result = queue.offer(item); ... } }
当DumpAnalyzer接收到消息请求,会调用storeMessage(...) 函数处理消息,如上源码,函数会根据domain和客户端ip将消息均匀分配到那19个阻塞队列(LinkedBlockingQueue)中,然后MessageGzip会轮询从队列获取消息数据,调用gzipMessage(item)函数处理,每处理 10000 条消息,MessageGzip会上报一条Gzip压缩线程监控记录。
我们再看看最核心的 gzipMessage(MessageItem item) 函数的处理逻辑,CAT根据日期,周期小时,domain,客户端地址,服务端地址创建存储路径和文件,包含数据文件和索引文件, 例如 20180611/15/Cat-127.0.01-127.0.01、20180611/15/Cat-127.0.01-127.0.01.idx ,从前面可以看出Message-ID的前3段可以确定唯一的索引文件,每条消息的存储由本地消息处理器(LocalMessageBucket)控制,LocalMessageBucket 的 storeMessage(...)方法会将消息信息写入消息块(MessageBlock)对象存放在内存中,当MessageBlock数据块大小达到 64K 时,将内存数据(MessageBlock) 放入阻塞队列 (m_messageBlocks),异步写入文件,并清空内存MessageBlock。LocalMessageBucket 有个字段 m_blockSize 用于记录消息块总大小,注意这里的 64K 是压缩前的消息块总大小。
public class MessageGzip implements Task { private void gzipMessage(MessageItem item) { MessageId id = item.getMessageId(); String name = id.getDomain() + '-' + id.getIpAddress() + '-' + m_localIp; String path = m_pathBuilder.getLogviewPath(new Date(id.getTimestamp()), name); LocalMessageBucket bucket = m_buckets.get(path); if (bucket == null) { synchronized (m_buckets) { bucket = m_buckets.get(path); if (bucket == null) { bucket = (LocalMessageBucket) lookup(MessageBucket.class, LocalMessageBucket.ID); bucket.setBaseDir(m_baseDir); bucket.initialize(path); m_buckets.put(path, bucket); } } } DefaultMessageTree tree = (DefaultMessageTree) item.getTree(); ByteBuf buf = tree.getBuffer(); MessageBlock block = bucket.storeMessage(buf, id); if (block != null) { if (!m_messageBlocks.offer(block)) { m_serverStateManager.addBlockLoss(1); } } } }
从上代码可以看出,当 storeMessage(...) 返回不为空的消息块(MessageBlock)时,则认为内存数据已经达到64K,需要写入文件,MessageGzip将消息块推入阻塞队列m_messageBlocks, BlockDumper线程会对队列进行消费, 它在实例化的时候会创建一个执行线程池 m_executors,然后 BlockDumper 线程轮询从阻塞队列取消息块(MessageBlock),为每个消息块创建一个块写入任务(FlushBlockTask),并将任务提交给执行线程池执行。FlushBlockTask实际会调用BlockDumper的flushBlock(block)函数将MessageBlock写入文件。

最终写入操作,还是得由LocalMessageBucket的MessageBlockWriter来完成,接下来我们介绍下本地消息处理器(LocalMessageBucket),它是一个控制消息数据读写的对象,数据在内存中的载体是消息块(MessageBlock),LocalMessageBucket 在gzipMessage(...)被首次实例化、初始化,初始化过程中会创建一个消息块(MessageBlock)、消息块读处理对象(MessageBlockReader)、消息块写处理对象(MessageBlockWriter)、、缓冲区以及缓冲区压缩流。
MessageBlock 包含4个信息:文件路径、数据缓冲区、每条ID的序列号、每条消息数据的大小(压缩前)。
消息块读处理对象负责消息的读取操作。
消息块写处理对象则负责数据文件、索引文件的写入操作,他会维护一个文件游标偏移量,记录压缩消息块(MessageBlock)在数据文件中的起始位置,即图2中块地址,下面是具体的写逻辑,先写索引文件,CAT先获取消息块中消息总条数,为每个Message-ID都写一个索引记录,每条消息的索引记录长度都是48bits,索引根据Message-ID的第四段(序列号)来确定索引的位置,比如消息Message-ID为ShopWeb-0a010680-375030-2,这条消息ID对应的索引位置为2*48bits的位置,48bits索引包含32bits的块地址 和 16bits 的块内偏移地址,前者记录压缩消息块(MessageBlock)在数据文件中的偏移位置,由于消息块包含多条消息,我们需要16bits来记录消息在消息块中的位置,注意这里指解压后的消息块。写完索引文件再写入数据文件,每一段压缩数据,前4位都是压缩块的大小,后面才是消息块的实际数据。
public class MessageBlockWriter { private RandomAccessFile m_indexFile; private RandomAccessFile m_dataFile; private int m_blockAddress; public synchronized void writeBlock(MessageBlock block) throws IOException { int len = block.getBlockSize(); byte[] data = block.getData(); int blockSize = 0; for (int i = 0; i < len; i++) { int seq = block.getIndex(i); int size = block.getSize(i); m_indexFile.seek(seq * 6L); m_indexFile.writeInt(m_blockAddress); m_indexFile.writeShort(blockSize); blockSize += size; } m_dataFile.writeInt(data.length); m_dataFile.write(data); m_blockAddress += data.length + 4; } }
CAT读取消息的时候,首先根据Message-ID的前面三段确定唯一的索引文件,在根据Message-ID第四段确定此Message-ID索引位置,根据索引文件的48bits读取数据文件的内容,然后将数据文件进行GZIP解压,在根据块内偏移地址读取出真正的消息内容。

一定得注意的是,同一台客户端机器产生的Message-ID的第四段,即当前小时的顺序递增号,在当前小时内一定不能重复,因为在服务端,CAT会为每个客户端IP、每个小时的原始消息存储都创建一个索引文件,每条消息的索引记录在索引文件内的偏移位置是由顺序递增号决定的,一旦顺序号重复生成,那么该小时的重复索引数据将会被覆盖,导致我们无法通过索引找到原始消息数据。
上传HDFS
自定义分析器与报表
周期结束

我们从消息分发章节知道,RealtimeConsumer在初始化的时候,会启动一个线程,每隔1秒钟就去从判断是否需要开启或结束一个周期(Period),如下源码,如果 value < 0 的时候,就会启动一个周期结束线程,线程会调用endPeriod函数,找到需要结束的周期,完成周期的结束以及清理工作,并将周期对象从PeriodManager中移除。
public class PeriodManager implements Task { private List<Period> m_periods = new ArrayList<Period>(); @Override public void run() { while (m_active) { try { long now = System.currentTimeMillis(); long value = m_strategy.next(now); if (value > 0) { startPeriod(value); } else if (value < 0) { // last period is over,make it asynchronous Threads.forGroup("cat").start(new EndTaskThread(-value)); } } ... } } private void endPeriod(long startTime) { int len = m_periods.size(); for (int i = 0; i < len; i++) { Period period = m_periods.get(i); if (period.isIn(startTime)) { period.finish(); m_periods.remove(i); break; } } } private class EndTaskThread implements Task { public void run() { endPeriod(m_startTime); } } } ---------------------
我们知道,周期是由许多的周期任务(PeriodTask)构成,所以事实上,一个周期的结束,就是周期内所有周期任务的结束,每个周期任务对应着一个任务队列和一个消息分析器(MessageAnalyzer),归根结底是对MessageAnalyzer的结束。
public class PeriodTask implements Task, LogEnabled { private MessageAnalyzer m_analyzer; public void finish() { try { m_analyzer.doCheckpoint(true); m_analyzer.destroy(); } catch (Exception e) { Cat.logError(e); } } }
doCheckpoint 我们似曾相识,在CatHomeModule初始化的最后,我们会向虚拟机注册shutdownhook,保证在虚拟机关闭时,未被正常结束的周期会被RealtimeConsumer结束,RealtimeConsumer.doCheckpoint与上面正常结束周期所做的工作是一样的,都是调用分析器的doCheckpoint方法,唯一的区别是,分析器doCheckpoint函数的传入的atEnd参数不同,表示周期是否在到期后正常结束的。
Runtime.getRuntime().addShutdownHook(new Thread() { @Override public void run() { consumer.doCheckpoint(); } });
分析器的结束 -- 报表持久化
分析器的结束实际上就是报表的持久化的一个过程,分析器处理消息的过程中,我们一共形成了9个报表,图1展示了这9个报表的结构:
我们知道每个周期的消息分析器(MessageAnalyzer)的结束都是在doCheckpoint来实现的,实际运行中一共有10种消息分析器参与消息分析工作,那么不同类别的分析器,他的结束逻辑都是一样的吗?
除了几个特殊的分析器(如Metric、Dump)之外,其它消息分析器结束逻辑都同下面源码,调用storeHourlyReports方法存储报表,所有报表都会被存到文件,atEnd 和 localMode 参数决定我们是否将报表存到数据库。
其中State报表有点特殊,因为State是对CAT本身的监控,在周期任务(PeriodTask)运行过程中并没有收集任何数据,而是在doCheckpoint的时候对CAT消息监控情况汇总生成的一个报表,所以调用storeHourlyReports之前,他需要首先收集State报表数据。
public class XxxAnalyzer extends AbstractMessageAnalyzer<XxxReport> implements LogEnabled { private ReportManager<XxxReport> m_reportManager; public synchronized void doCheckpoint(boolean atEnd) { if (atEnd && !isLocalMode()) { m_reportManager.storeHourlyReports(getStartTime(), StoragePolicy.FILE_AND_DB, m_index); } else { m_reportManager.storeHourlyReports(getStartTime(), StoragePolicy.FILE, m_index); } } }
我们先详细剖析storeHourlyReports 的过程,然后再看看几个特殊的分析器的结束逻辑。storeHourlyReports 首先将该分析器生成的所有报表都取出,然后我们会校验报表的domain名称是否合法,不合法的报表将被移除,在序列化之前,我们会调用ReportDelegate.beforeSave(...)方法做一些预处理的工作。不同种类的报表,预处理所做的工作是不同的,后续我们分别讲解,做完预处理的工作之后,我们就正式持久化了,支持文件和数据库两种持久化方式,我们会根据传入的序列化策略(StoragePolicy) 来选择需要进行哪种序列化,一般来说,如果是正常的周期结束,数据会持久化到文件和数据库,如果是JVM Shutdown导致的结束,只持久化到文件,两种持久化的细节后续我们也会分别详细讲解。
public class DefaultReportManager<T> extends ContainerHolder implements ReportManager<T>, Initializable, LogEnabled { @Override public void storeHourlyReports(long startTime, StoragePolicy policy, int index) { Map<String, T> reports = m_reports.get(startTime); ReportBucket bucket = null; try { if (reports != null) { //校验、移除不合法Domain名字的报表 ... m_reportDelegate.beforeSave(reports); if (policy.forFile()) { bucket = m_bucketManager.getReportBucket(startTime, m_name, index); try { storeFile(reports, bucket); } finally { m_bucketManager.closeBucket(bucket); } } if (policy.forDatabase()) { storeDatabase(startTime, reports); } } } catch (Throwable e) { //报告异常 ... } finally { cleanup(startTime); t.complete(); if (bucket != null) { m_bucketManager.closeBucket(bucket); } } } }
报表预处理
在继续讲解序列化之前,我们来说一说报表的预处理工作(beforeSave),各报表的预处理逻辑,有相同、也有异同的地方,Top、State报表预处理不做任何事情,其它报表都有处理逻辑,以Transaction报表的预处理工作为例,分为两个部分。
第一部分是将所有Transaction报表的domain都收集起来,写入报表的成员变量 m_domainNames,这样每个报表都会知道一共都有哪些domain参与监控, 从图1的报表结构来看,Heartbeat、Event、Problem、Cross报表也包含m_domainNames字段,事实上这些报表的预处理也确实会收集所有domain。其中Heartbeat和Cross的预处理仅仅包含这部分逻辑。
第二部分是聚合报表,所谓聚合,就是创建一个命名为ALL的聚合报表,将同一个Domain下不同IP地址的数据汇总起来,写到报表ALL的同一个Machine对象内,Machine的ip不再是地址,而是Domain名,所有Domain数据都汇总到ALL报表的不同Machine下。因为现在服务端几乎都是采用集群,有可能10几台机器上运行着同一个项目,这时我们可以通过聚合报表去站在项目角度去看待统计结果,报表的聚合大量采用了访问者模式。
也不是所有类型的事务都会参与聚合,配置 all-report-config 会指定哪些事务会参与聚合,如下默认type="URL"的事务,这是因为通常URL是代表一个项目的接口对外服务的最完整链路耗时,从以下配置可以看到,除了Transaction消息之外,Event消息也会参与聚合,逻辑与Transaction大同小异,在此不再赘述。
<all-config>
<report id="transaction">
<type id="URL">
<name id="*"></name>
</type>
</report>
<report id="event">
<type id="URL">
<name id="*"></name>
</type>
<type id="SQL">
<name id="*"></name>
</type>
</report>
</all-config>
Problem有一个独有的预处理流程,就是通过ProblemReportFilter对象将长时URL访问(long-url)的记录总数控制在100条之内,防止长时访问数量过多,导致报表数据过大。
Storage报表的预处理只有一个 updateStorageIds 调用,他的功能和Transaction预处理第一部分类似,也是让每个Storage报表都知道目前有哪些数据库/缓存在被访问、监控,我们知道Storage报表的ID是由 数据库/缓存名 + 类型(SQL/Cache) 组成,updateStorageIds会将所有数据库/缓存名收集,然后写入StorageReport的成员变量m_ids。
下面将所有报表持久化的预处理做了一个汇总,放在一个函数内,呈现在以下伪代码中:
public class XxxDelegate implements ReportDelegate<XxxReport> { @Override public void beforeSave(Map<String, XxxReport> reports) { //Top、State不干任何事直接返回 return; //storage 仅有下面 updateStorageIds 步骤,完成后返回。 for (StorageReport report : reports.values()) { m_reportUpdater.updateStorageIds(report.getId(), reports.keySet(), report); } //Problem、Transaction、Event、Heartbeat、Cross都有的步骤 for (XxxReport report : reports.values()) { Set<String> domainNames = report.getDomainNames(); domainNames.clear(); domainNames.addAll(reports.keySet()); } //报表聚合,Transaction、Event 独有 if (reports.size() > 0) { TransactionReport all = createAggregatedReport(reports); reports.put(all.getDomain(), all); } //Problem独有,控制long-url消息量。 ProblemReportFilter problemReportURLFilter = new ProblemReportFilter(); for (Entry<String, ProblemReport> entry : reports.entrySet()) { ProblemReport report = entry.getValue(); problemReportURLFilter.visitProblemReport(report); } } }
报表的文件存储 -- 重入锁
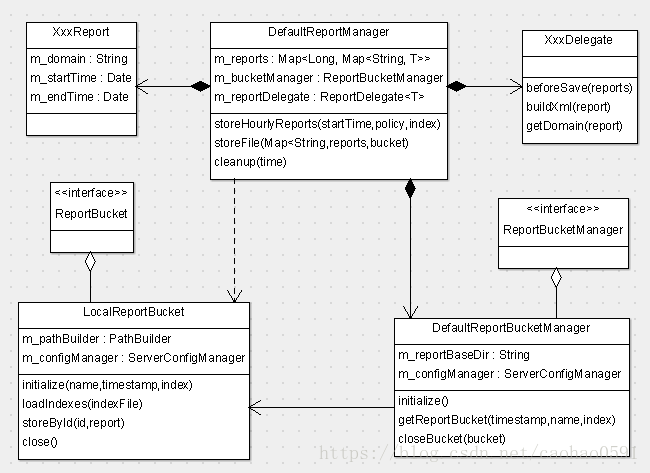
在做完预处理之后,所有报表都将被持久化到文件,在DefaultReportManager调用storeFile存储文件之前,我们先调用 m_bucketManager.getReportBucket(...) 来创建并初始化ReportBucket,文件的读写相关操作都封装于ReportBucket里面,文件的读写同步采用重入锁(ReentrantLock)保证读写安全。
public class LocalReportBucket implements ReportBucket, LogEnabled { @Override public void initialize(String name, Date timestamp, int index) throws IOException { m_baseDir = m_configManager.getHdfsLocalBaseDir("report"); m_writeLock = new ReentrantLock(); m_readLock = new ReentrantLock(); String logicalPath = m_pathBuilder.getReportPath(name, timestamp, index); File dataFile = new File(m_baseDir, logicalPath); File indexFile = new File(m_baseDir, logicalPath + ".idx"); if (indexFile.exists()) { loadIndexes(indexFile); } final File dir = dataFile.getParentFile(); if (!dir.exists() && !dir.mkdirs()) { throw new IOException(String.format("Fail to create directory(%s)!", dir)); } m_logicalPath = logicalPath; m_writeDataFile = new BufferedOutputStream(new FileOutputStream(dataFile, true), 8192); m_writeIndexFile = new BufferedOutputStream(new FileOutputStream(indexFile, true), 8192); m_writeDataFileLength = dataFile.length(); m_readDataFile = new RandomAccessFile(dataFile, "r"); } }
报表存储基础路径(m_baseDir)在配置 server.xml 中指定,每个分析器实例都会最终生成若干个报表,我们会为这个分析器产生的这些报表生成一个数据文件和报表索引文件,存于逻辑路径(logicalPath )下,逻辑路径以日期/小时/index来划分,例如:20180604/15/1/report-cross , 20180604为日期, 15为下午3点的周期,1是分析器实例index,之前说过有些分析器处理过程复杂,可能会有多个实例,例如Cross、Event、Problem、Transaction报表, 数据文件名取 m_baseDir + logicalPath, 索引文件是在数据文件名加上 ".idx" 后缀,如下:
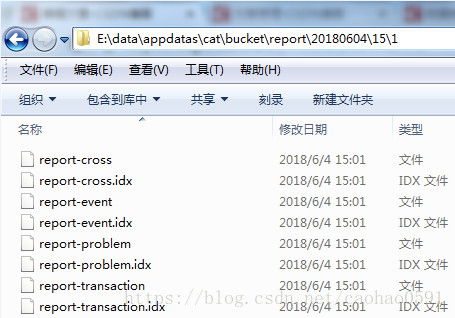
数据文件存储该分析器下所有转化为xml格式的报表数据,索引文件是对数据文件内报表的一个位置索引,比如 report-problem.idx索引文件内容如下,每一行都记录一个报表名称和报表在数据文件的起始位置。
RpcService 0
Cat 1388
RpcClient2 4600
RpcClient 5807
现在再来看看storeFile的逻辑就非常简单了, 获取domain,将报表对象转化为xml数据,最后调用storeById将xml写入数据文件和索引文件。
public class DefaultReportManager<T> extends ContainerHolder implements ReportManager<T>, Initializable, LogEnabled { private void storeFile(Map<String, T> reports, ReportBucket bucket) { for (T report : reports.values()) { try { String domain = m_reportDelegate.getDomain(report); String xml = m_reportDelegate.buildXml(report); bucket.storeById(domain, xml); } catch (Exception e) { Cat.logError(e); } } } }
报表的数据库存储
如果是正常的周期结束之后,发起的持久化,而不是由于虚拟机关闭引起的,数据除了被持久化到文件之外,还会被持久化到数据库。

所有的数据库持久化逻辑都在 storeDatabase(...) 方法中完成,每个分析器中的每个报表的描述信息,都会被插入数据库report表中,在程序中,HourlyReport实体与该表对应,如图3, 报表具体内容会通过m_reportDelegate.buildBinary(report)转化成二进制数据,然后插入数据库report_content 表,在程序中,HourlyReportContent实体与该表对应,如图4,report_content 表的主键来自report的主键。
public class DefaultReportManager<T> extends ContainerHolder implements ReportManager<T>, Initializable, LogEnabled { @Inject private HourlyReportDao m_reportDao; @Inject private HourlyReportContentDao m_reportContentDao; private void storeDatabase(long startTime, Map<String, T> reports) { Date period = new Date(startTime); String ip = NetworkInterfaceManager.INSTANCE.getLocalHostAddress(); for (T report : reports.values()) { try { String domain = m_reportDelegate.getDomain(report); HourlyReport r = m_reportDao.createLocal(); r.setName(m_name); r.setDomain(domain); r.setPeriod(period); r.setIp(ip); r.setType(1); m_reportDao.insert(r); int id = r.getId(); byte[] binaryContent = m_reportDelegate.buildBinary(report); HourlyReportContent content = m_reportContentDao.createLocal(); content.setReportId(id); content.setContent(binaryContent); m_reportContentDao.insert(content); m_reportDelegate.createHourlyTask(report); } catch (Throwable e) { Cat.getProducer().logError(e); } } } }
CREATE TABLE `report` ( `id` int(11) NOT NULL AUTO_INCREMENT, `type` tinyint(4) NOT NULL COMMENT '报表类型, 1/xml, 9/binary 默认1', `name` varchar(20) NOT NULL COMMENT '报表名称', `ip` varchar(50) DEFAULT NULL COMMENT '报表来自于哪台机器', `domain` varchar(50) NOT NULL COMMENT '报表项目', `period` datetime NOT NULL COMMENT '报表时间段', `creation_date` datetime NOT NULL COMMENT '报表创建时间', PRIMARY KEY (`id`), KEY `IX_Domain_Name_Period` (`domain`,`name`,`period`), KEY `IX_Name_Period` (`name`,`period`), KEY `IX_Period` (`period`) ) ENGINE=InnoDB AUTO_INCREMENT=18497 DEFAULT CHARSET=utf8 ROW_FORMAT=COMPRESSED COMMENT='用于存放实时报表信息,处理之后的结果'; CREATE TABLE `report_content` ( `report_id` int(11) NOT NULL COMMENT '报表ID', `content` longblob NOT NULL COMMENT '二进制报表内容', `creation_date` datetime NOT NULL COMMENT '创建时间', PRIMARY KEY (`report_id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8 ROW_FORMAT=COMPRESSED COMMENT='小时报表二进制内容';
定时任务生产者
数据库的持久化完成标志着一个完整周期的结束,CAT实时处理报表都是产生小时级别统计,小时级报表中会带有最低分钟级别粒度的统计,在数据库持久化完成之后,我们会调用 m_reportDelegate.createHourlyTask(report) 创建一些定时任务,去创建小时模式、天模式、周模式、月模式等等粒度更粗的视图,为什么这里还会创建小时任务,因为在集群情况下,同一周期下的多张报表可能分散在几台CAT服务器上,这时我们创建小时定时任务去合并报表形成小时视图。
但是,针对不同报表、不同domain,创建的定时任务也不同,有些可能小时模式、天模式、周模式、月模式视图定时任务都有,有些也可能只创建天任务,在解释完以下几个domain的描述之后我们看下定时任务的列表:
crashLogDomain:客户端崩溃日志埋点,默认有:AndroidCrashLog/iOSCrashLog/MerchantAndroidCrashLog/MerchantIOSCrashLog/ApolloAndroidCrashLog/ApolloIOSCrashLog/TVAndroidCrashLog
serverFilterDomain:配置serverFilter中过滤的domain,默认有:空/PhoenixAgent/cat-agent/All/FrontEnd/paas/SMS-RECEIVER
validateDomain:非ServerFilterLog 和 非CrashLog
ALL:聚合报表,Transaction和Event特有。
*:所有domain

State比较特殊,他会创建比较多的定时任务,我们单独列在下面: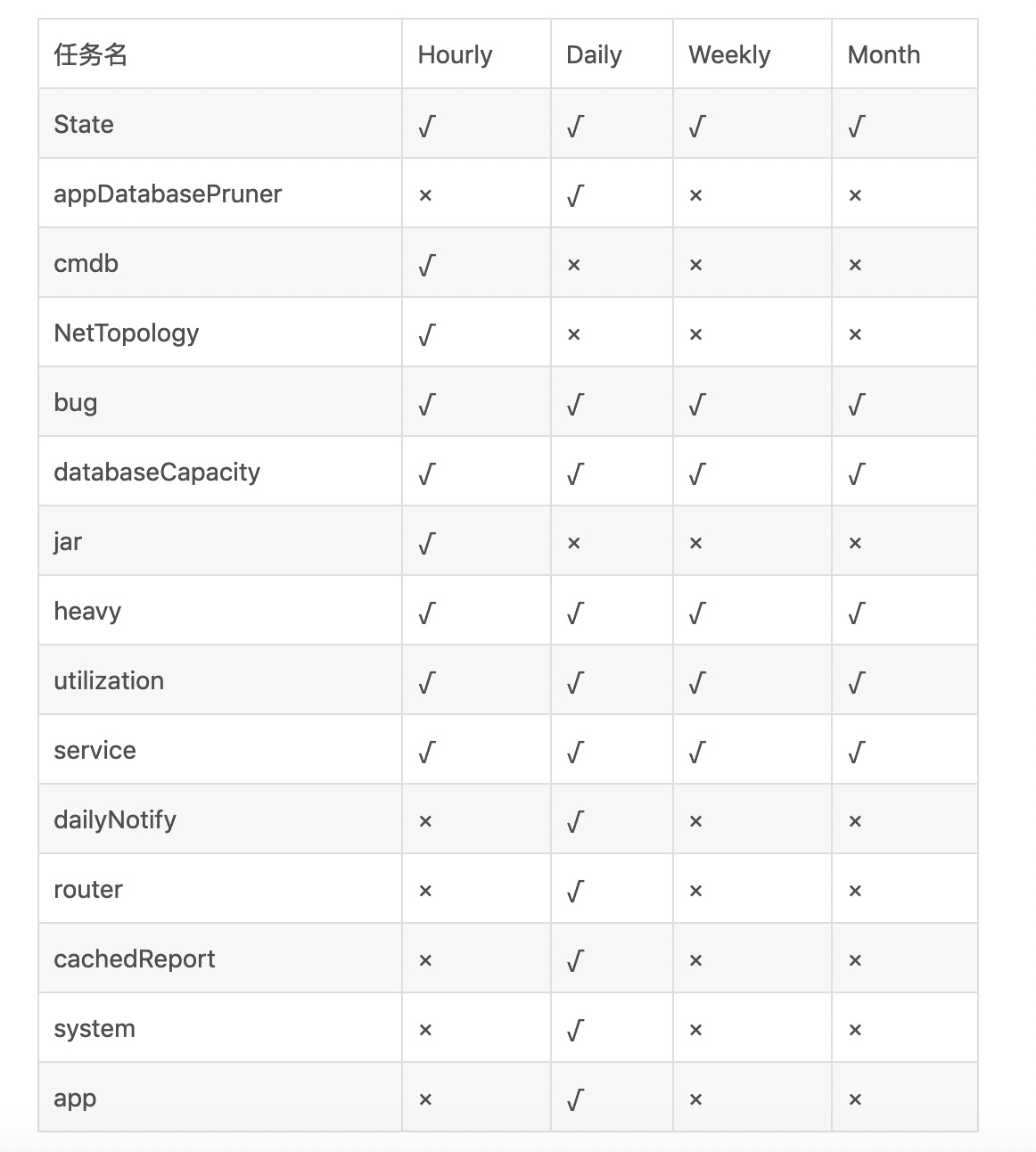
定时任务在 TaskManager.createTask(...) 中生产,这里就是将需要执行的定时任务插入数据库task表中,以供消费者(TaskConsumer)到时候去表里取定时任务然后执行,表字段如下:
TABLE `task` ( `id` int(11) NOT NULL AUTO_INCREMENT, `producer` varchar(20) NOT NULL COMMENT '任务创建者ip', `consumer` varchar(20) DEFAULT NULL COMMENT '任务执行者ip', `failure_count` tinyint(4) NOT NULL COMMENT '任务失败次数', `report_name` varchar(20) NOT NULL COMMENT '报表名称, transaction, problem...', `report_domain` varchar(50) NOT NULL COMMENT '报表处理的Domain信息', `report_period` datetime NOT NULL COMMENT '报表时间', `status` tinyint(4) NOT NULL COMMENT '执行状态: 1/todo, 2/doing, 3/done 4/failed', `task_type` tinyint(4) NOT NULL DEFAULT '1' COMMENT '0表示小时任务,1表示天任务', `creation_date` datetime NOT NULL COMMENT '任务创建时间', `start_date` datetime DEFAULT NULL COMMENT '开始时间, 这次执行开始时间', `end_date` datetime DEFAULT NULL COMMENT '结束时间, 这次执行结束时间', PRIMARY KEY (`id`), UNIQUE KEY `task_period_domain_name_type` (`report_period`,`report_domain`,`report_name`,`task_type`) ) ENGINE=InnoDB AUTO_INCREMENT=42594 DEFAULT CHARSET=utf8 COMMENT='后台任务';
其中producer就是生产定时任务的机器IP,stauts是执行状态,这里TaskManager作为生产者插入的记录状态都是todo=1,task_type指的任务类别,包含下面4种类别:
0-小时任务,有小时任务需求的在生产者中都会被创建,合并CAT服务器集群的多台机器的小时报表。
1-天任务, 对于有天任务需求的,会在当天创建前一天的天视图,
2-周任务,有周任务需求的会创建上周六到这周五的周视图,
3-月任务,有月任务需求的会在每月1号创建上个月的月视图。
当然由于task表的report_period, report_domain, report_name, task_type 是联合唯一键,所以,同一个类型、周期、domain、名称的定时任务,只会插入一条。
public class TaskManager { @Inject private TaskDao m_taskDao; private static final int STATUS_TODO = 1; public static final int REPORT_HOUR = 0; public static final int REPORT_DAILY = 1; public static final int REPORT_WEEK = 2; public static final int REPORT_MONTH = 3; public boolean createTask(Date period, String domain, String name, TaskCreationPolicy prolicy) { try { if (prolicy.shouldCreateHourlyTask()) { createHourlyTask(period, domain, name); } Calendar cal = Calendar.getInstance(); cal.setTime(period); int hour = cal.get(Calendar.HOUR_OF_DAY); cal.add(Calendar.HOUR_OF_DAY, -hour); Date currentDay = cal.getTime(); if (prolicy.shouldCreateDailyTask()) { createDailyTask(new Date(currentDay.getTime() - ONE_DAY), domain, name); } if (prolicy.shouldCreateWeeklyTask()) { int dayOfWeek = cal.get(Calendar.DAY_OF_WEEK); if (dayOfWeek == 7) { createWeeklyTask(new Date(currentDay.getTime() - 7 * ONE_DAY), domain, name); } } if (prolicy.shouldCreateMonthTask()) { int dayOfMonth = cal.get(Calendar.DAY_OF_MONTH); if (dayOfMonth == 1) { cal.add(Calendar.MONTH, -1); createMonthlyTask(cal.getTime(), domain, name); } } return true; } catch (DalException e) { Cat.logError(e); return false; } } }
定时任务消费者

我们再次回到CatHomeModule的初始化函数中,有如下一段代码,它会读取server.xml中的配置 job-machine="true",用于指定是否开启定时任务消费者线程。
if (serverConfigManager.isJobMachine()) {
DefaultTaskConsumer taskConsumer = ctx.lookup(DefaultTaskConsumer.class);
Threads.forGroup("cat").start(taskConsumer);
}
线程会每隔1分钟轮训从数据库取状态为todo的定时任务,以及consumer为本机ip,然后状态为doing的定时任务,即上次处理失败,需要重试的,将任务状态都修改为 doing,然后调用 processTask处理定时任务,如果处理失败则间隔一段时间后重试,注意,这里的间隔会阻塞任务线程,超过最大重试次数,状态标为failed,成功则标为done。
public abstract class TaskConsumer implements org.unidal.helper.Threads.Task { @Override public void run() { String localIp = getLoaclIp(); while (running) { if (checkTime()) { Task task = findDoingTask(localIp); if (task == null) { task = findTodoTask(); } boolean again = false; if (task != null) { task.setConsumer(localIp); if (task.getStatus() == TaskConsumer.STATUS_DOING || updateTodoToDoing(task)) { int retryTimes = 0; while (!processTask(task)) { retryTimes++; if (retryTimes < MAX_TODO_RETRY_TIMES) { taskRetryDuration(); } else { updateDoingToFailure(task); again = true; break; } } if (!again) { updateDoingToDone(task); } } } else { taskNotFoundDuration(); //sleep 2 min } } else { Thread.sleep(60 * 1000); } } this.stopped = true; } }
processTask(...)处理的核心是将Task交给ReportFacade去构建视图,我们可以认为ReportFacade是一个视图构建工厂,工厂在初始化的时候,从plexus配置中读取所有的任务构建器(TaskBuilder),并将他们装入ReportFacade的成员变量m_reportBuilders中,TaskBuilder是一个接口,有4个方法,buildHourlyTask、buildDailyTask、buildWeeklyTask、buildMonthlyTask,我们从图3可以看到该接口一共有24个实现,当有定时任务交付时,ReportFacade会根据任务名找到具体的任务构建类,然后根据任务是小时、天、周还是月分别调用以上4个方法。
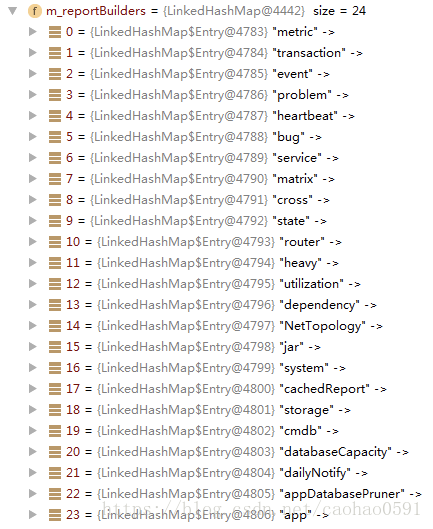
---------------------
作者:曹号
来源:CSDN
原文:https://blog.csdn.net/caohao0591/article/details/80207771
版权声明:本文为博主原创文章,转载请附上博文链接!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号