

Java定时任务解决方案学习笔记
前言——理论基础学习
小顶堆
|
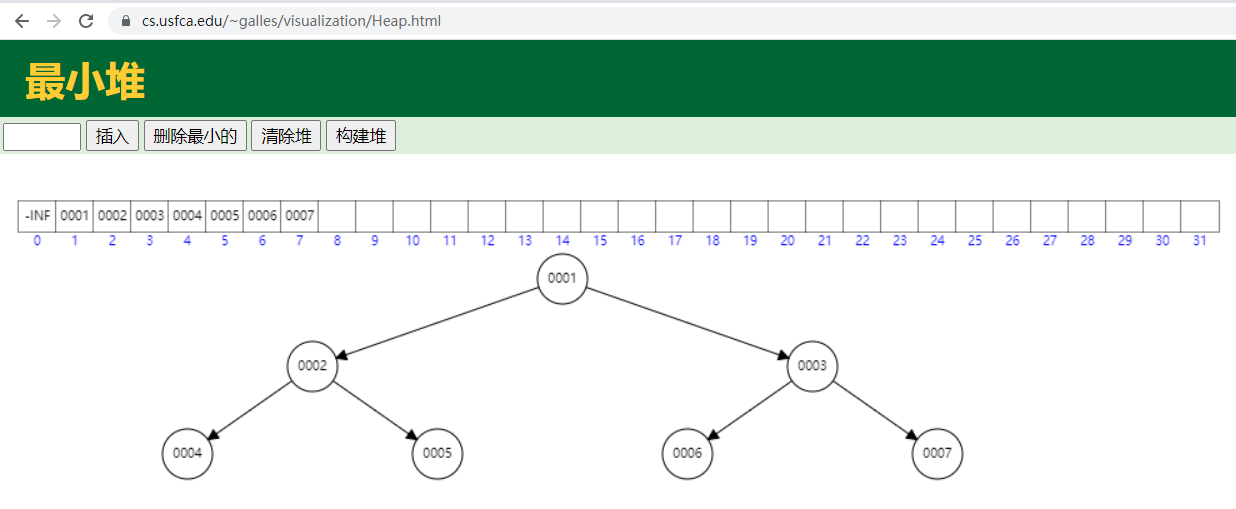
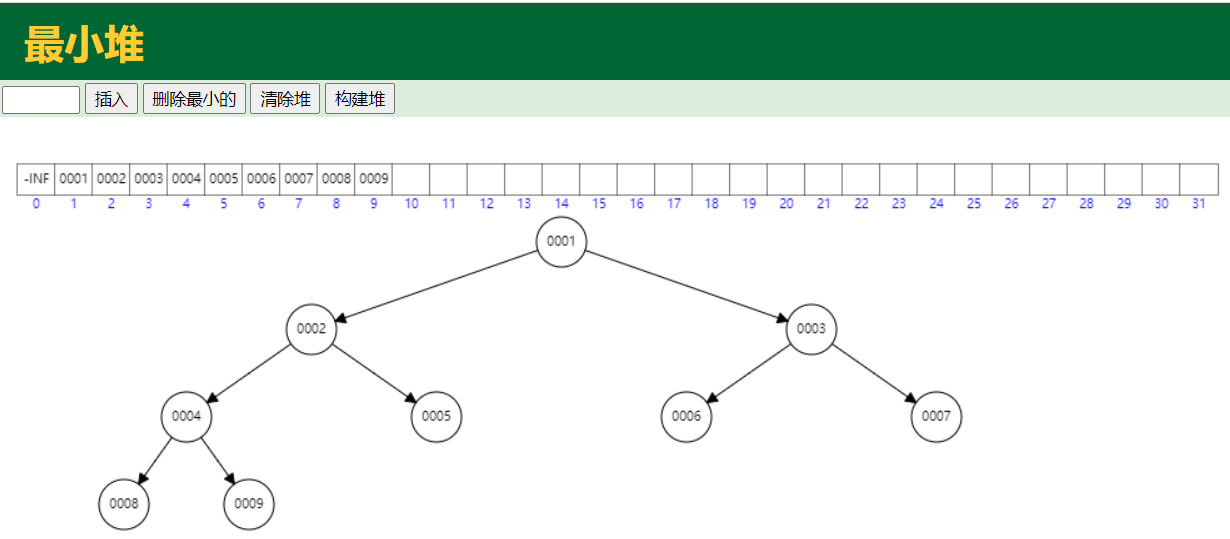
数据结构——堆【在线堆可视化地址:https://www.cs.usfca.edu/~galles/visualization/Heap.html】 堆是一种特殊的树,只要满足以下两个条件,它就是一个堆: ①、堆是一棵完整二叉树; ②、堆中某个节点的值总是不大于或不小于其父节点的值。 其中,我们把根节点最大的堆叫做大顶堆,根节点最小的堆叫做小顶堆。 满二叉树:所有层都达到最大节点数
完全二叉树:除了最后一层外其他层都达到最大节点数,且最后一层节点都靠左排列
定时任务就是用小顶堆的方式触发任务的,每个节点都是一个包含执行时间的定时任务Job,根节点是最近要执行的定时任务Job(最近即到期时间最短)。 二叉树只是一个逻辑结构,Java中没有与二叉树对应的存储结构。在Java中存储二叉树可以采用数组的方式或链表的方式,这里使用的是数组来存储。原因是小顶堆二叉树相当于一个队列,数组就可以从上往下、从左往右进行存储节点数据,可以很快的通过下标定位元素。 小顶堆插入元素:插入尾部,然后上浮,可以在https://www.cs.usfca.edu/~galles/visualization/Heap.html体验元素的插入;如果timer中放入一个新的任务,结合小顶堆的插入元素特性,会根据任务的到期时间判断大小然后上浮。 小顶堆删除元素:先把堆顶的元素取走,然后把尾部(最大的元素)元素放到堆顶再下沉,和上浮相反,这个同样可以在前面的链接中体验,有很清晰的动画效果演示。 上浮或下沉都叫做堆化,就是为了满足堆的特性。 |
时间轮算法
|
由于小顶堆存在问题,比如树中存的元素太多,每次在删除堆顶元素时都要做下沉操作,而定时任务取任务是一个很频繁的操作,而且上浮或下沉都会比对没必要比对的节点,这样会特别耗费性能,刚好时间轮算法可以避免这个问题。 简单的时间轮使用链表或数组实现时间轮,可以想象成一块钟表,每一个时间轮就是一个数组,假设每个小时都是一个元素,则每个元素都对应一个链表,链表就是需要执行的任务集合,这样就可以一次性取出来,就避免了小顶堆耗费性能的情况。这是一个简单的时间轮,存在一个问题:钟表是12个时间刻度,程序不知道这是凌晨一点还是下午一点,为了解决这个问题程序可以把刻度加到24,但是如果遇到月、年不同的维度计算,那刻度又更加复杂了,因此出现了round型时间轮。 round型时间轮还是12个刻度,任务上记录一个round,遍历到了就把round减去1,当round为0时说明时间到了,取出执行,但是这需要遍历所有的任务,效率较低,因此出现了分层时间轮。 分层时间轮使用多个不同时间维度的轮,比如天轮记录几点执行、月轮记录几号执行,高维的时间轮遍历到了就把任务取出来放到天轮里,就可以实现几号几点执行任务,这样就避免了遍历所有的轮,cron表达式就是使用的分层时间轮。 |
一、JDK定时器timer
package com.example.quartztest;
import java.util.Date;
import java.util.Timer;
/**
* @description: 定时任务timer使用演示
* @author: YangWanYi
* @create: 2022-06-23 17:32
**/
public class TimerTest {
public static void main(String[] args) {
// timer执行任务调度是基于绝对时间的,做不到每周一这样的时间执行,而且运行时异常会导致timer线程终止
Timer timer = new Timer(); // 创建一个timer对象 这时任务就已经启动了
for (int i = 0; i < 2; i++) {
TimerTask timerTask = new TimerTask("timeTask" + i); // TimerTask以小顶堆的方式存放在TaskQueue中
/*
schedule 真正的执行时间取决于上一个任务的结束时间 这种很有可能会丢任务 即该执行的时间没执行
scheduleAtFixedRate 严格按照预设时间执行 不管上一次任务是否执行结束 这种执行时间会乱
上面的问题是因为单线程任务阻塞导致的,可以在任务实现类中用线程池执行任务来解决
*/
// timer.schedule(timerTask, new Date(), 1000 * 2); // 添加任务 这里设定任务距离上一次执行完毕后间隔2S再次执行
timer.scheduleAtFixedRate(timerTask, new Date(), 1000 * 2); // 添加任务 这里设定任务不管上一次是否执行结束 距离上一次开始执行时间2S后都会再次执行
}
}
}
/**
* 定时任务类
*/
class TimerTask extends java.util.TimerTask {
// 任务名称
String taskName;
public TimerTask(String taskName) {
this.taskName = taskName;
}
@Override
public void run() {
try {
System.out.println("taskName:" + taskName + ",startTime:" + new Date());
Thread.sleep(1000 * 3); // 任务执行3S
System.out.println("taskName:" + taskName + ",endTime:" + new Date());
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
二、定时任务线程池
package com.example.quartztest.pool;
import java.util.Date;
import java.util.concurrent.Executors;
import java.util.concurrent.ScheduledExecutorService;
import java.util.concurrent.TimeUnit;
/**
* @description: 定时任务线程池 对timer的缺陷做了些优化
* @author: YangWanYi
* @create: 2022-06-23 18:06
**/
public class ScheduleThreadPoolTest {
public static void main(String[] args) {
/*
ScheduledThreadPoolExecutor的特点:
1、使用多线程执行任务,不会相互阻塞
2、如果线程失活,会新建线程执行任务(线程抛异常,任务会被丢弃,需要做捕获处理)
3、DelayedWorkQueue:小顶堆、无界队列
①、在定时线程池中,最大线程数是没有意义的
②、执行时间距离当前时间越近的任务在队列的前面
③、用于添加ScheduleFutureTask(继承自FutureTask,实现RunnableScheduledFuture接口),提供异步执行的能力,并且可以返回执行结果
④、线程池中的线程从DelayQueue中获取ScheduleFutureTask,然后执行任务
⑤、实现了Delayed接口,可以通过getDelay方法获取延迟时间
4、Leader-Follower模式:
解释:譬如现在有一堆等待执行的任务(一般待执行的任务是存放在一个队列中排好序),而所有的工作线程中只会有一个是leader线程,其他的都是follower线程。
只有leader线程能执行任务,而剩下的follower线程则处于休眠状态。当leader线程在拿到任务后执行任务前,就会变成follower线程,同时会选出一个新的leader线程。
如果此时有下一个任务,就是这个新的leader线程来执行了,并往复这个过程。
当之前那个执行任务的线程执行完毕时,会判断如果此时已经没有任务了或者有任务但是其他的线程是leader线程,自己就会休眠。如果此时有任务但是没有leader线程,那自己就会重新成为leader线程来执行任务。
好处:避免没必要的唤醒和阻塞,这样更加有效且节省资源
5、应用场景:适用于多个后台线程执行周期性任务,同时为了满足资源管理的需求而限制后台线程数量
SingleThreadScheduledExecutor的特点:
1、相当于单线程的ScheduledThreadPoolExecutor
2、应用场景:适用于需要单个后台线程执行周期任务,同时需要保证任务顺序执行
*/
ScheduledExecutorService scheduledThreadPool = Executors.newScheduledThreadPool(5);// 定义5个线程数
for (int i = 0; i < 2; i++) {
// scheduledThreadPool.schedule(new Task("task-" + i), 0, TimeUnit.SECONDS); // 延迟时间为0 表示立即执行 没有间隔时间 表示只执行一次
scheduledThreadPool.scheduleAtFixedRate(new Task("task-" + i), 0, 1000 * 2, TimeUnit.SECONDS); // 延迟时间为0 表示立即执行 执行间隔时间2S
}
}
}
/**
* 定义任务逻辑
*/
class Task implements Runnable {
// 任务名称
String taskName;
public Task(String taskName) {
this.taskName = taskName;
}
@Override
public void run() {
try {
System.out.println("taskName:" + taskName + ",startTime:" + new Date());
Thread.sleep(1000 * 3); // 任务执行3S
System.out.println("taskName:" + taskName + ",endTime:" + new Date());
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
三、定时任务框架——quartz
quartz官网:http://www.quartz-scheduler.org/
1、原生使用示例
Job类
package com.example.quartztest.quartz;
import org.quartz.*;
import org.quartz.impl.StdSchedulerFactory;
/**
* @description: 测试定时任务
* @author: YangWanYi
* @create: 2022-06-24 14:20
**/
public class TestJob {
public static void main(String[] args) {
JobDetail jobDetail = JobBuilder.newJob(MyJob.class)
.withIdentity("jobName01", "groupName01") // 在调度器中任务名称不能重复,必须唯一
.usingJobData("job", "jobDetail") // 存值
.usingJobData("name", "jobDetail") // 存值
.usingJobData("jobDetailCount", 0) // 存值
.build();
// 创建触发器
Trigger trigger = TriggerBuilder. newTrigger()
.withIdentity("triggerName01", "group01")
.usingJobData("trigger", "trigger") // 存值
.usingJobData("name", "trigger") // 存值
.usingJobData("count", 0) // 存值
.startNow() // 立即启动
.withSchedule( // 触发策略
SimpleScheduleBuilder.simpleSchedule().withIntervalInSeconds(1) // 间隔1S执行
.repeatForever()) // 一直重复执行
.build();
// 创建调度器
try {
Scheduler scheduler = StdSchedulerFactory.getDefaultScheduler(); // 获取默认的schedule
scheduler.scheduleJob(jobDetail, trigger);
scheduler.start(); // 启动
} catch (SchedulerException e) {
e.printStackTrace();
System.out.println("调度器创建失败");
}
}
}
启动类
package com.example.quartztest.quartz;
import org.quartz.*;
import org.quartz.impl.StdSchedulerFactory;
/**
* @description: 测试定时任务
* @author: YangWanYi
* @create: 2022-06-24 14:20
**/
public class TestJob {
public static void main(String[] args) {
JobDetail jobDetail = JobBuilder.newJob(MyJob.class)
.withIdentity("jobName01", "groupName01") // 在调度器中任务名称不能重复,必须唯一
.usingJobData("job", "jobDetail") // 存值
.usingJobData("name", "jobDetail") // 存值
.usingJobData("jobDetailCount", 0) // 存值
.build();
// 创建触发器
Trigger trigger = TriggerBuilder. newTrigger()
.withIdentity("triggerName01", "group01")
.usingJobData("trigger", "trigger") // 存值
.usingJobData("name", "trigger") // 存值
.usingJobData("count", 0) // 存值
.startNow() // 立即启动
.withSchedule( // 触发策略
SimpleScheduleBuilder.simpleSchedule().withIntervalInSeconds(1) // 间隔1S执行
.repeatForever()) // 一直重复执行
.build();
// 创建调度器
try {
Scheduler scheduler = StdSchedulerFactory.getDefaultScheduler(); // 获取默认的schedule
scheduler.scheduleJob(jobDetail, trigger);
scheduler.start(); // 启动
} catch (SchedulerException e) {
e.printStackTrace();
System.out.println("调度器创建失败");
}
}
}
2、各组件介绍
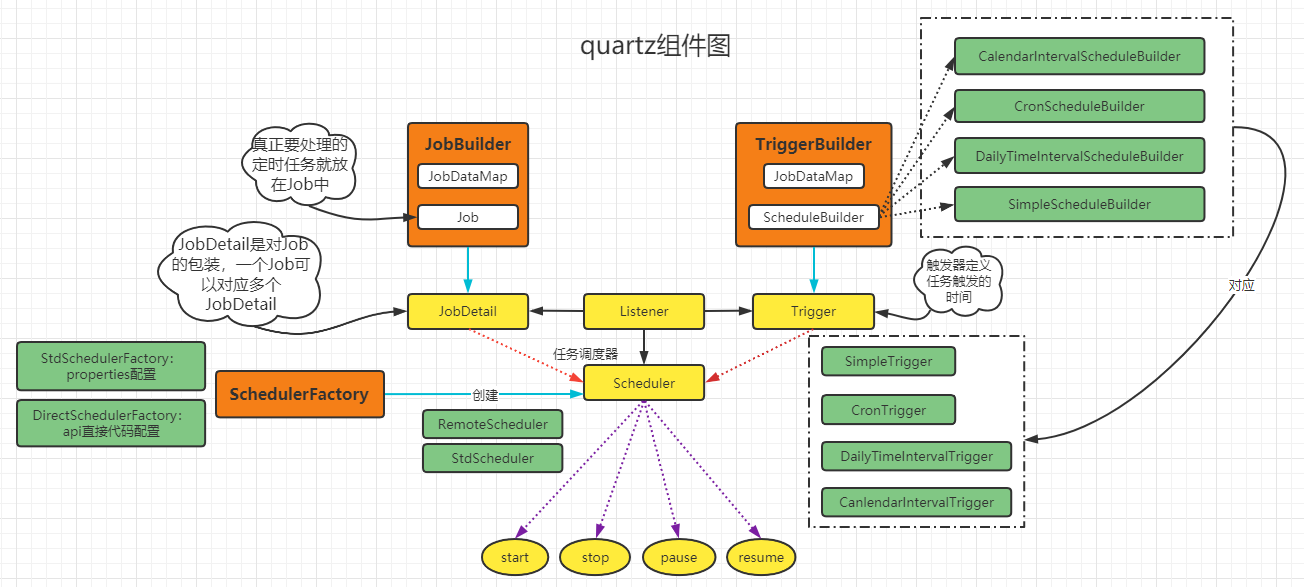
①、JobDataMap:保存任务实例的状态信息。其中jobDetail默认只在Job被添加到调度程序(任务执行计划表)的时候,存储一次关于该任务的状态信息数据,可以使用注解@PersistJobDataAfterExecution标明在一个任务执行完毕后就存储一次;trigger表示任务被多个触发器引用的时候。根据不同的触发时机,可以提供不同的输入条件。
②、Job:封装成JobDetail的属性。@DisallowConcurrentExecution注解表示禁止并发地执行同一个job(JobDetail)定义的多个实例。@PersistJobDataAfterExecution注解表示持久化JobDetail中的JobDataMap(对trigger中的dataMap无效),如果一个任务不是持久化的,当没有触发器关联它的时候,Quartz会从schedule中删除它。如果一个任务请求恢复,一般是该任务在执行期间发送了系统崩溃或者其他关闭进程的操作,当服务再次启动的时候,会再次执行该任务,此时,JobExecutionContext.isRecovering()会返回true。
③、Trigger:触发器,指定执行时间、开始时间和结束时间等。
优先级:同时触发的trigger之间才会比较优先级;如果trigger是可恢复的,在恢复后再调度时,优先级不变。
misfire:错过触发。
判断misfire的条件:job到达触发时间没有被执行;被执行的延迟时间超过了Quartz配置的misfireThreshold阀值(阀值的意思就是如果设置了阀值为20,那么应该在8点整执行的任务到8点20才执行,这也是可以的。但是如果阀值是5,应该在8点整执行的任务到8点20才执行,那么这个任务就会被判定为错过触发了)。
misfire的原因:当job达到触发时间时,所有线程都被其他job占用,没有可用的线程;在job需要触发的时间点,schedule停止了(可能是意外停止);job使用了@DisallowConcurrentExecution注解,job不能并发执行,当达到下一个job执行点的时候,上一个任务还没有完成;job指定了过去的开始执行时间,例如当前时间是12点00分00秒,指定了开始时间为11点00分00秒。
策略:默认使用的是MISFIRE_INSTRUCTION_SMART_POLICY策略;
SimpleTrigger:now*相关的策略,会立即执行第一个misfire的任务,同时会修改startTime和repeatCount,因此会重新计算finalFireTime,原计划执行时间会被打乱;next*相关的策略,不会立即执行misfire的任务,也不会修改startTime和repeatCount,因此finalFireTime也不会改变,misfire也还是按照原计划执行。
CronTrigger:MISFIRE_INSTRUCTION_IGNORE_MISFIRE_POLICY表示Quartz不会判断发生了misfire,立即执行所有发生了misfire的任务,然后按照原计划执行,比如:10:15分立即执行9:00和10:00的任务,然后等待下一个任务在11:00执行,后续按照原计划执行;MISFIRE_INSTRUCTION_FIRE_ONCE_NOW表示立即执行第一个发生misfire的任务,忽略其他发生misfire的任务,然后按照原计划继续执行,比如在10:15立即执行9:00的任务,忽略10:00的任务。然后等待下一个任务在11:00执行,后续按照原计划执行;MISFIRE_INSTRUCTION_DO_NOTHING表示所有发生misfire的任务都会忽略,只按照原计划继续执行。
calendar:用于排除时间段。
SimpleTrigger:具体时间点,指定间隔重复执行。
CronTrigger:cron表达式。
④、Scheduler:调度器,基于trigger的设定执行job。
SchedulerFactory:创建Scheduler。创建方式:DirectSchedulerFactory(在代码里定制Scheduler参数)、StdSchedulerFactory(读取classpath下的quartz.properties配置来实例化Scheduler)。
JobStore:存储运行时信息的,包括Trigger、Scheduler、JobDetail、业务锁等。实现方式:RAMJobStore(内存实现,默认使用)、JobStoreTX(JDBC,事务由Quartz管理)、JobStoreCMT(JDBC,使用容器事务)、ClusteredJobStore(集群实现)、TerracottaJobStore(Terracotta中间件)。
ThreadPool:SimpleThreadPool(默认使用)和自定义线程池。
3、组件关系架构分析
4、监听器及插件
// TODO
5、quartz集群
任务数量很多的时候,可以使用quartz集群让更多的节点来分担任务,以提高系统的吞吐能力。
quartz集群中,节点之间互相不通信,所以是通过数据库来保证集群的,在数据库中记录集群的信息,每一个节点都访问同一个数据库,这样来保证集群之间互相协调处理任务。
quartz集群中,每个节点处理一种任务,比如一个JobDetail会分配给一个节点,而不是一个JobDetail前部分在节点A执行,后部分在节点B执行。也就是说每个Job会完整地在某个节点中运行。
6、springboot整合quartz
①、添加依赖
<!--quartz启动器依赖-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-quartz</artifactId>
</dependency>
<!--mysql-->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.29</version>
</dependency>
<!--orm-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jpa</artifactId>
</dependency>
②、数据库表
数据库表由quartz官方提供,不同的版本SQL脚本有一点出入,但具体差异不大。SQL脚本可以在quartz官网http://www.quartz-scheduler.org/downloads/下载,这里我已经下载了2.3.0版。

解压下载后的压缩包,在目录\quartz-2.3.0-SNAPSHOT\src\org\quartz\impl\jdbcjobstore中找到SQL脚本,这里有很多SQL脚本,我用的MySQL,所以直接复制tables_mysql.sql就行。

把tables_mysql.sql粘贴到项目的resources目录下。
可以修改表名,但是一定要保证每一张表的前缀一致。
③、springboot的配置文件application.yml
server:
port: 10003
spring:
application:
name: quartz-test
datasource:
url: jdbc:mysql://127.0.0.1:3306/quartz-center?useUnicode=true&characterEncoding=utf-8&useSSL=false&serverTimezone=Asia/Shanghai&autoReconnect=true&failOverReadOnly=false
driver-class-name: com.mysql.cj.jdbc.Driver
username: root
password: 123456
initial-size: 10 # 初始化大小
min-idle: 10 # 最小空闲数
max-active: 20 # 最大活跃数
max-wait: 60000 # 配置获取连接等待超时的时间
time-between-eviction-runs-millis: 60000 # 配置间隔多久才进行一次检测,检测需要关闭的空闲连接,单位是毫秒
min-evictable-idle-time-millis: 300000 # 指定一个空闲连接最少空闲多久后可被清除,单位是毫秒
test-while-idle: true # 当连接空闲时,是否执行连接测试
test-on-borrow: false # 当从连接池借用连接时,是否测试该连接
test-on-return: false # 在连接归还到连接池时是否测试该连接
filters: config,wall,stat # 配置监控统计拦截的filters,去掉后监控界面sql无法统计,'wall'用于防火墙
poolPreparedStatements: true # 打开PSCache,并且指定每个连接上PSCache的大小
MaxPoolPreparedStatementPerConnectionSize: 20
maxOpenPreparedStatements: 50
# 通过connectProperties属性来打开mergeSql功能;慢SQL记录
connectionProperties: druid.stat.slowSqlMillis=500;druid.stat.logSlowSql=true;config.decrypt=false
quartz:
job-store-type: jdbc
jdbc:
# 自动初始化数据库
initialize-schema: always # always never
④、spring-quartz.properties
在resources目录下创建文件spring-quartz.properties,内容属性可以参考官方文档http://www.quartz-scheduler.org/documentation/quartz-2.3.0/configuration/。
我的配置如下:
# ----------------配置JobStore Begin----------------
# JobDataMaps是否都设置为String类型,默认false.需要限制都为String的时候设置为true
org.quartz.jobStore.useProperties=false
# 表的前缀,默认是QRTZ_
org.quartz.jobStore.tablePrefix=QRTZ_
# 是否加入集群
org.quartz.jobStore.isClustered=true
# 集群调度实例失效的检查时间间隔 单位ms
org.quartz.jobStore.clusterCheckinInterval=5000
# 事务托管 当设置为“true”时,该属性告诉 Quartz在非托管 JDBC 连接上调用setTransactionIsolation(Connection.TRANSACTION_READ_COMMITTED) 。这有助于防止某些数据库(例如 DB2)在高负载和“持久”事务下发生锁定超时。
org.quartz.jobStore.txIsolationLevelReadCommitted=true
# 数据保存方式为数据库持久化
org.quartz.jobStore.class=org.quartz.impl.jdbcjobstore.JobStoreTX
# 数据库代理类 一般org.quartz.impl.jdbcjobstore.StdJDBCDelegate可以满足大部分数据库
org.quartz.jobStore.driverDelegateClass=org.quartz.impl.jdbcjobstore.StdJDBCDelegate
# ----------------配置Scheduler Begin----------------
# 调度标识名 集群中每一个节点实例都必须使用相同的名称
org.quartz.scheduler.instanceName=ClusterQuartz
# ID设置为自动获取 集群中每一个节点必须唯一
org.quartz.scheduler.instanceId=AUTO
# ----------------配置ThreadPool Begin----------------
# 线程池的实现类 一般使用SimpleThreadPool就可以满足几乎所有用户的需求
org.quartz.threadPool.class=org.quartz.simpl.SimpleThreadPool
# 指定线程数 一般设置为1~100之间的整数 根据系统资源配置
org.quartz.threadPool.threadCount=5
# 设置线程的优先级 可以是Thread.MIN_PRIORITY(即1)和Thread.MAX_PRIORITY(即10)之间的任何整数
org.quartz.threadPool.threadPriority=5
⑤、任务类
package com.example.quartztest.springbootquartz;
import org.quartz.DisallowConcurrentExecution;
import org.quartz.JobExecutionContext;
import org.quartz.PersistJobDataAfterExecution;
import org.springframework.scheduling.quartz.QuartzJobBean;
import java.util.Date;
/**
* @description: 任务类 处理任务逻辑
* @author: YangWanYi
* @create: 2022-06-25 15:52
**/
// 禁止并发地执行同一个Job(JobDetail)定义的多个实例
@DisallowConcurrentExecution
/*
把jobDataMap持久化 哪怕每次schedule创建不同的jobDetail实例 jobDetail值都会更新 对trigger的dataMap无效
如果一个任务不是持久化的,即没有加这个注解,那么当没有触发器关联这个任务时,Quartz就会从Schedule中删除这个任务。
*/
@PersistJobDataAfterExecution
public class MyQuartzJob extends QuartzJobBean {
@Override
protected void executeInternal(JobExecutionContext jobExecutionContext) {
try {
Thread.sleep(1000 * 2);
System.out.println(jobExecutionContext.getScheduler().getSchedulerInstanceId()); // 打印调度器的实例ID
System.out.println("任务名称:" + jobExecutionContext.getJobDetail().getKey().getName()); // 打印任务名称
System.out.println("任务执行时间:" + new Date());
} catch (Exception e) {
e.printStackTrace();
}
}
}
⑥、调度器配置类
package com.example.quartztest.springbootquartz;
import org.quartz.Scheduler;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.beans.factory.config.PropertiesFactoryBean;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.core.io.ClassPathResource;
import org.springframework.scheduling.concurrent.ThreadPoolTaskExecutor;
import org.springframework.scheduling.quartz.SchedulerFactoryBean;
import javax.sql.DataSource;
import java.io.IOException;
import java.util.Properties;
import java.util.concurrent.Executor;
/**
* @description: 调度器配置类 调度器实例只要一个就够了 所以需要建一个配置类把调度器放在IOC容器中 作为一个bean保存起来
* @author: YangWanYi
* @create: 2022-06-25 16:01
**/
@Configuration
public class SchedulerConfig {
@Autowired
private DataSource dataSource;
@Bean("Scheduler")
public Scheduler getScheduler() throws IOException {
return this.getSchedulerFactoryBean().getScheduler();
}
@Bean
public SchedulerFactoryBean getSchedulerFactoryBean() throws IOException {
SchedulerFactoryBean factory = new SchedulerFactoryBean();
factory.setSchedulerName("cluster_scheduler"); // 调度器名称 不设置也可以
factory.setDataSource(dataSource); // 设置数据源
factory.setApplicationContextSchedulerContextKey("application"); // 设置SchedulerFactoryBean在IOC中的key 可以不设置
factory.setQuartzProperties(this.getQuartzProperties()); // 设置配置文件
factory.setTaskExecutor(this.getSchedulerThreadPool()); // 设置任务执行器 线程池
factory.setStartupDelay(5); // 设置执行延迟时间 不设置就是立即执行
return factory;
}
@Bean
public Properties getQuartzProperties() throws IOException {
PropertiesFactoryBean propertiesFactoryBean = new PropertiesFactoryBean();
propertiesFactoryBean.setLocation(new ClassPathResource("/spring-quartz.properties")); // 设置文件路径
propertiesFactoryBean.afterPropertiesSet(); // 调用此方法才会真正地读取配置文件
return propertiesFactoryBean.getObject();
}
@Bean
public Executor getSchedulerThreadPool() {
ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor();
executor.setCorePoolSize(Runtime.getRuntime().availableProcessors()); // 设置核心线程数为处理器的核心数
executor.setMaxPoolSize(Runtime.getRuntime().availableProcessors()); // 设置最大线程数
executor.setQueueCapacity(Runtime.getRuntime().availableProcessors()); // 设置队列容量
return executor;
}
}
⑦、springboot容器启动监听类,在这个监听中自动启动任务调度;也可以通过实现CommandLineRunner类来启动任务调度。
package com.example.quartztest.springbootquartz;
import org.quartz.*;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.beans.factory.annotation.Qualifier;
import org.springframework.context.ApplicationListener;
import org.springframework.context.event.ContextRefreshedEvent;
import org.springframework.stereotype.Component;
/**
* @description: springboot容器启动监听 在这个监听中自动启动任务调度
* @author: YangWanYi
* @create: 2022-06-25 16:41
**/
@Component
public class StartApplicationListener implements ApplicationListener<ContextRefreshedEvent> { // 监听容器启动事件 当spring发布ContextRefreshedEvent这个事件时,表示spring的IOC容器已经启动成功了
// 注入调度器
@Qualifier("Scheduler")
@Autowired
private Scheduler scheduler;
/**
* 在这个监听方法中开启调度
*
* @param contextRefreshedEvent
*/
@Override
public void onApplicationEvent(ContextRefreshedEvent contextRefreshedEvent) {
TriggerKey triggerKey = TriggerKey.triggerKey("trigger01", "group01");
try {
Trigger trigger = this.scheduler.getTrigger(triggerKey); // 在调度器中获取触发器
if (null == trigger) { // 如果调度器中没有触发器再new一个 这样是为了保证触发器在调度器中是唯一的 因为同一个策略的触发器只需要一个实例就够了
trigger = TriggerBuilder.newTrigger()
.withIdentity(triggerKey) // 设置key
.withSchedule(CronScheduleBuilder.cronSchedule("0/10 * * * * ?")) // cron表达式 10S执行一次
.build();
JobDetail jobDetail = JobBuilder.newJob(MyQuartzJob.class) // 把定时任务传进去
.withIdentity("job01", "group01") // 设置key
.build();
this.scheduler.scheduleJob(jobDetail, trigger);
this.scheduler.start(); // 开始调度
}
} catch (SchedulerException e) {
e.printStackTrace();
}
}
}
