

MySQL优化---Count优化、limit优化、Update优化
一、limit优化
这里我有一张表tb_sku 里面有400w条数据,以这个表作为案例对象

1. 未优化案例
select * from tb_sku limit 0,10; 可以看出耗时几乎为0,一下子就完成了
(2)查询起始索引100w后的10条记录
select * from tb_sku limit 1000000,10; 这里耗时要3秒多,需要的时间变长了
(3) 查询起始索引300w后的10条记录
select * from tb_sku limit 3000000,10; 这里耗时几乎翻倍,要11秒多。所以越往后需要的时间就越多。
通过测试我们会看到,越往后,分页查询效率越低,这就是分页查询的问题所在。 因为,当在进行分页查询时,如果执行 limit 2000000,10 ,此时需要 MySQL 排序前 2000010 记 录,仅仅返回 2000000 - 2000010 的记录,其他记录丢弃,查询排序的代价非常大 。
优化思路 : 一般分页查询时,通过创建 覆盖索引 能够比较好地提高性能,可以通过覆盖索引加子查询形式进行优化。
二、 limit大分页问题的性能优化方法
(1)利用表的覆盖索引来加速分页查询
MySQL的查询完全命中索引的时候,称为覆盖索引,是非常快的。因为查询只需要在索引上进行查找之后可以直接返回,而不用再回表拿数据。
在我们的例子中,我们知道id字段是主键,自然就包含了默认的主键索引。现在让我们看看利用覆盖索引的查询效果如何。
select id from test limit 1000000, 20 ; //0.2秒
那么如果我们也要查询所有列,如何优化?
优化的关键是要做到让MySQL每次只扫描20条记录,我们可以使用limit n,这样性能就没有问题,因为MySQL只扫描n行。我们可以先通过子查询先获取起始记录的id,然后根据Id拿数据:
select * from test where id>=(select id from test limit 1000000,1) limit 20;
(2)延迟关联(覆盖索引 + JOIN)
和上述的子查询做法类似,我们通过先扫描出对应的主键,然后再回表查询出对应的列,极大的减少了MySQL对数据页的扫描。
即先利用limit分页查询找到所需记录的主键(比如ID)生成派生表,再通过主键作为连接条件与原表进行join连接。
select a.* from test a inner join (select id from test limit 1000000,20) b on a.id=b.id;
注意:如果不使用ORDER BY对主键或者索引字段进行排序,结果集返回不稳定(如某次返回1,2,3,另外的一次返回2,1,3)。
(3)用上次分页的最大id优化(效果最好,推荐使用)
优化思路是使用某种变量记录上一次数据的位置,下次分页时直接从这个变量的位置开始扫描,从而避免MySQL扫描大量的数据再抛弃的操作。
例如:先找到上次分页的最大ID,然后利用id上的索引来查询:
select * from test where id>1000000 limit 100 ;
说明:优化方法中所有的例子都是基于id为主键这个前提,不能使用索引字段,否则会出现返回数据记录数不对的情况。
三、count优化
select count(*) from tb_user ;

MyISAM 引擎把一个表的总行数存在了磁盘上,因此执行 count(*) 的时候会直接返回这个 数,效率很高; 但是如果是带条件的count,MyISAM也慢。 InnoDB 引擎就麻烦了,它执行 count(*) 的时候,需要把数据一行一行地从引擎里面读出 来,然后累积计数。 我们都知道MySQL一般主要用到的引擎就是InnoDB 引擎,如果说要大幅度提升InnoDB 表的 count 效率,主要的优化思路:自己计数 ( 可以借助于 redis 这样的数据库进行, 但是如果是带条件的 count 又比较麻烦了 ) 。所以下面我们要进一步了解count聚合函数的使用。 count用法 count() 是一个聚合函数,对于返回的结果集,一行行地判断,如果 count 函数的参数不是 NULL ,累计值就加 1 ,否则不加,最后返回累计值。 用法: count ( * )、 count (主键)、 count (字段)、 count (数字)

注意: count(null)为0 ==》值为Null的时候都不计数,只要值不为Null其它的都计1,比如count(-1)和count(1)结果一致,
只不过count(-1)是在每一行维护着一个-1的值, 后面对齐进行累计数量,count(1)是在每一行维护一个1的值
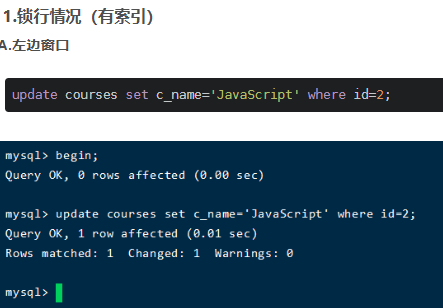
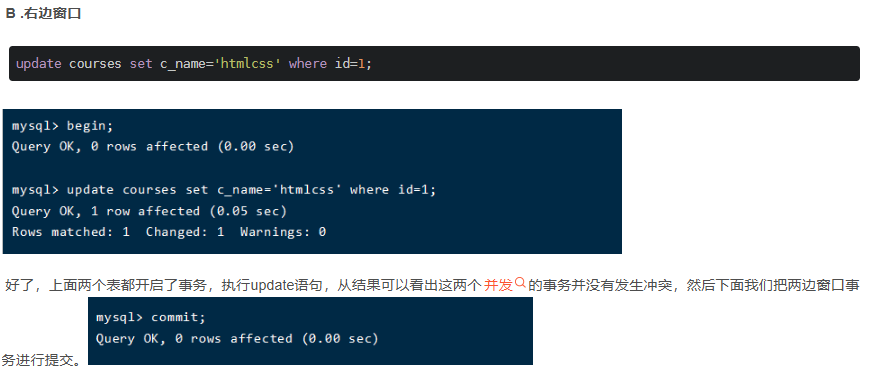
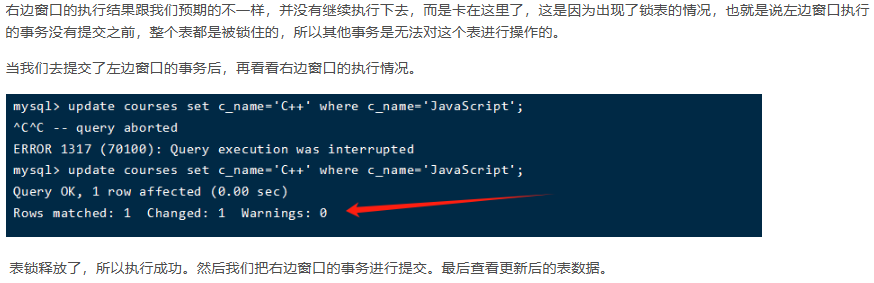
四、update优化




来源:https://blog.csdn.net/m0_73633088/article/details/137779994


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· AI编程工具终极对决:字节Trae VS Cursor,谁才是开发者新宠?
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!