Java-进阶篇【集合(Collection、数据结构、List、泛型深入)(Set、Collections、Map、集合嵌套)不可变集合、Stream流、异常 [自动保存的]】---06
1:数组 和 集合 的特点
集合和数组类似,都是容器。
数组的特点:可以支持对象 + 基本数据类型
数组定义完成并启动后,类型确定、长度固定【后面再加元素不能操作】
不适合元素的个数和类型不确定的业务场景,更不适合做需要增删数据操作【增删数据的时候都需要放弃原有数组或者移位,数据量大或者元素个数不确定不适应数组】
数组的功能也比较的单一,处理数据的能力并不是很强大
适合场景:
业务数据个数固定,而且都是存储同一批数据类型的时候,可以采用数组进行存储
集合的特点:只支持数据对象【引用类型数据】,不支持基本数据类型【存储基本数据类型需要使用包装类】
集合的大小不固定,启动后可以动态变化,类型也可以选择不固定。集合更像气球。
集合非常适合元素个数不能确定,且需要做元素的增删操作的场景。
同时,集合提供的种类特别的丰富,功能也是非常强大的,开发中集合用的更多
适合场景:
数据格式不确定,需要进行增删元素操作的适合 【购物车】
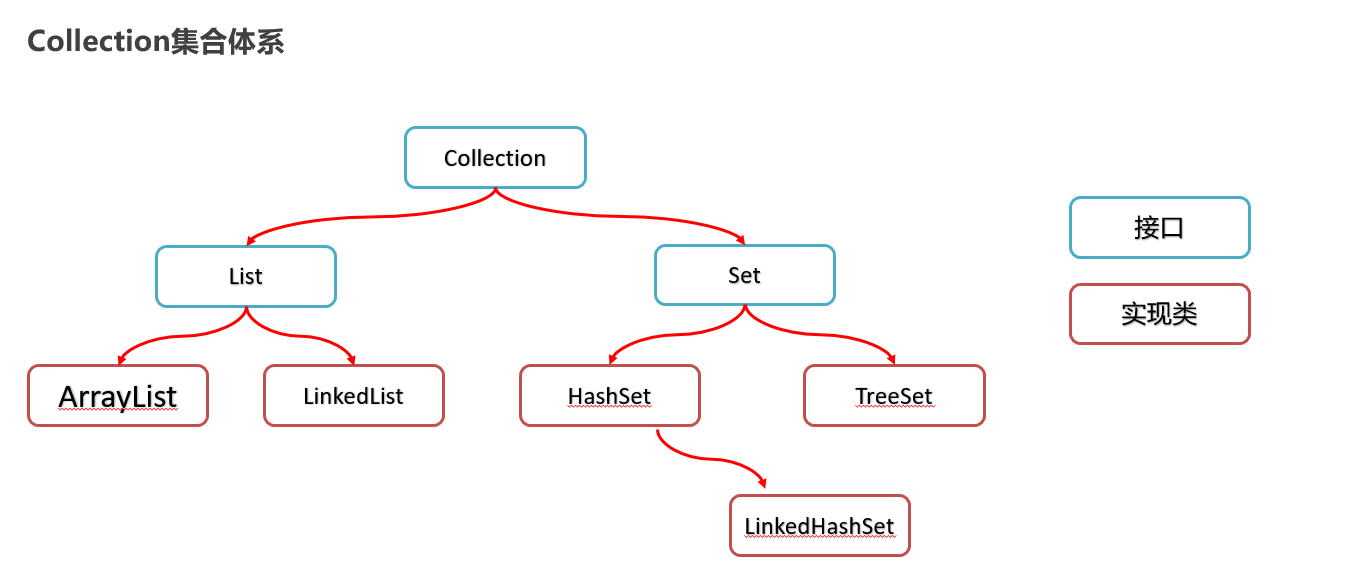
2:集合类体系结构 + 集合对泛型的支持
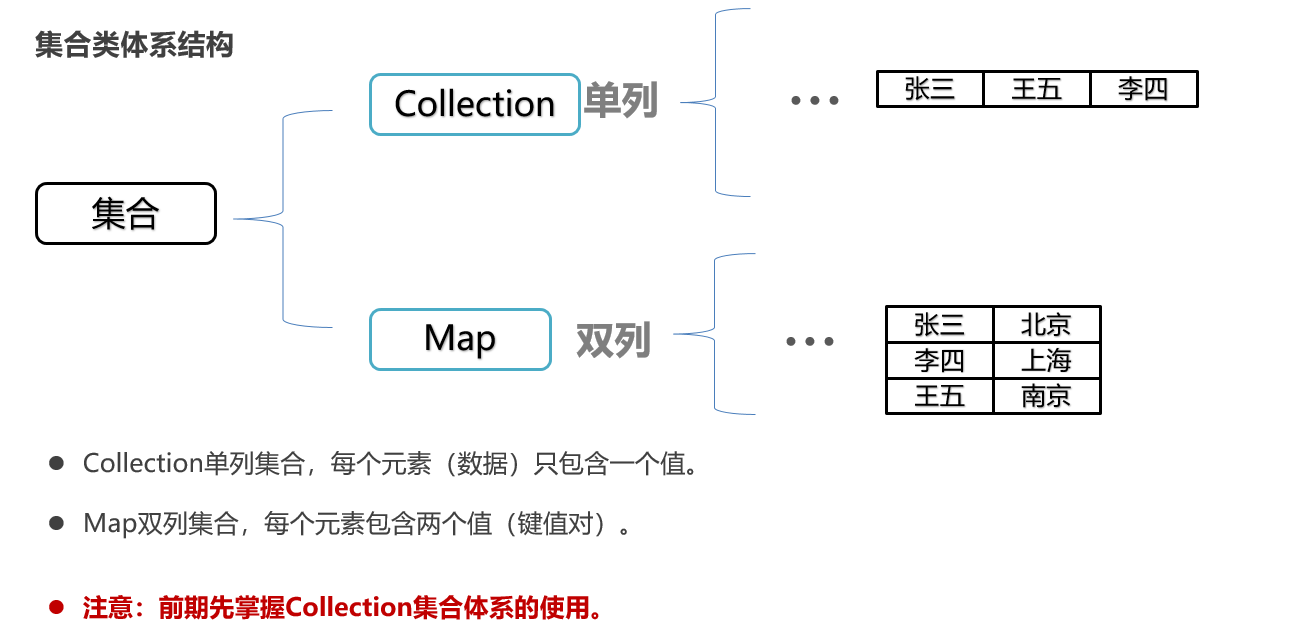
Collection:一个接口【支持泛型】
List:接口,继承Collecthion
Set:接口,继承Collecthion
ArrayList:实现类
package com.itheima.d1_collection; import java.util.ArrayList; import java.util.Collection; import java.util.HashSet; /** 目标:明确Collection集合体系的特点 */ public class CollectionDemo1 { public static void main(String[] args) { // 有序 可重复 有索引 List家族 Collection list = new ArrayList(); list.add("Java"); list.add("Java"); list.add("Mybatis"); list.add(23); list.add(23); list.add(false); list.add(false); System.out.println(list); // 无序 不重复 无索引 Set家族 Collection list1 = new HashSet(); list1.add("Java"); list1.add("Java"); list1.add("Mybatis"); list1.add(23); list1.add(23); list1.add(false); list1.add(false); System.out.println(list1); System.out.println("-----------------------------"); // Collection<String> list2 = new ArrayList<String>(); Collection<String> list2 = new ArrayList<>(); // JDK 7开始之后后面类型申明可以不写 list2.add("Java"); // list2.add(23); list2.add("黑马"); // 集合和泛型不支持基本数据类型,只能支持引用数据类型 // Collection<int> list3 = new ArrayList<>(); Collection<Integer> list3 = new ArrayList<>(); list3.add(23); list3.add(233); list3.add(2333); Collection<Double> list4 = new ArrayList<>(); list4.add(23.4); list4.add(233.0); list4.add(233.3); } }
泛型:【集合不会存储任何类型元素,java定义集合适合希望你能确定需要存储的数据类型,集合支持泛型】
集合都是泛型的形式,可以在编译阶段约束集合只能操作某种数据类型: Collection<String> lists = new ArrayList<String>(); Collection<String> lists = new ArrayList<>(); // JDK 1.7开始后面的泛型类型申明可以省略不写 注意:集合和泛型都只能支持引用数据类型,不支持基本数据类型,所以集合中存储的元素都认为是对象。 Collection<int> lists = new ArrayList<>(); // 不支持 如果集合中要存储基本类型的数据怎么办? // 存储基本类型使用包装类 Collection<Integer> lists = new ArrayList<>(); Collection<Double> lists = new ArrayList<>();
3:Collection 集合 常用的API
Collection集合 : Collection是单列集合的祖宗接口,它的功能是全部单列集合都可以继承使用的 public boolean add(E e) 把指定的对象添加到集合中
public void clear() 清空集合中所有的元素 public boolean remove(E e) 把给定的对象在当前集合中删除 public boolean contains(Object obj) 判断当前集合中是否包含给定的对象 public boolean isEmpty() 判断当前集合是否为空 public int size() 返回集合中元素的个数。 public Object[] toArray() 把集合中的元素,存储到数组中
package com.itheima.d2_collection_api; import java.util.ArrayList; import java.util.Arrays; import java.util.Collection; /** 目标:Collection集合的常用API. Collection是集合的祖宗类,它的功能是全部集合都可以继承使用的,所以要学习它。 Collection API如下: - public boolean add(E e): 把给定的对象添加到当前集合中 。 - public void clear() :清空集合中所有的元素。 - public boolean remove(E e): 把给定的对象在当前集合中删除。 - public boolean contains(Object obj): 判断当前集合中是否包含给定的对象。 - public boolean isEmpty(): 判断当前集合是否为空。 - public int size(): 返回集合中元素的个数。 - public Object[] toArray(): 把集合中的元素,存储到数组中。 小结: 记住以上API。 */ public class CollectionDemo { public static void main(String[] args) { // HashSet:添加的元素是无序,不重复,无索引。【如果元素重复 add添加元素的时候会返回false失败】 Collection<String> c = new ArrayList<>(); // 1.添加元素, 添加成功返回true。 c.add("Java"); c.add("HTML"); System.out.println(c.add("HTML")); c.add("MySQL"); c.add("Java"); System.out.println(c.add("天马")); System.out.println(c); // [Java, HTML, HTML, MySQL, Java, 黑马] // 2.清空集合的元素。 // c.clear(); // System.out.println(c); // 3.判断集合是否为空 是空返回true,反之。 // System.out.println(c.isEmpty()); // 4.获取集合的大小。 System.out.println(c.size()); // 5.判断集合中是否包含某个元素。【精准匹配】 System.out.println(c.contains("Java")); // true System.out.println(c.contains("java")); // false System.out.println(c.contains("天马")); // true // 6.删除某个元素:如果有多个重复元素默认删除前面的第一个!【通过元素值删除,不能通过索引,索引只有list集合才支持。现在使用的是Collection 类型定义的集合,不支持索引删除】 System.out.println(c.remove("java")); // false System.out.println(c); System.out.println(c.remove("Java")); // true System.out.println(c); // 7.把集合转换成数组 [HTML, HTML, MySQL, Java, 黑马] Object[] arrs = c.toArray(); System.out.println("数组:" + Arrays.toString(arrs)); System.out.println("----------------------拓展----------------------"); Collection<String> c1 = new ArrayList<>(); c1.add("java1"); c1.add("java2"); Collection<String> c2 = new ArrayList<>(); c2.add("赵敏"); c2.add("殷素素"); // addAll把c2集合的元素全部倒入到c1中去。 c1.addAll(c2); System.out.println(c1); System.out.println(c2); } }
4:Collection 集合 的遍历 迭代器、foreach、lambada
迭代器遍历概述: 遍历就是一个一个的把容器中的元素访问一遍。 迭代器在Java中的代表是Iterator,迭代器是集合的专用的遍历方式【不能用来遍历数组】 Collection集合获取迭代器: Iterator<E> iterator() 返回集合中的迭代器对象,该迭代器对象默认指向当前集合的0索引 Iterator中的常用方法: boolean hasNext() 询问当前位置是否有元素存在,存在返回true ,不存在返回false E next() 获取当前位置的元素,并同时将迭代器对象移向下一个位置,注意防止取出越界 1、迭代器的默认位置在哪里。 Iterator<E> iterator():得到迭代器对象,默认指向当前集合的索引0 2、迭代器如果取元素越界会出现什么问题。 会出现NoSuchElementException异常
Collection集合:不支持下标去循环,只支持上面三种

package com.itheima.d3_collection_traversal; import java.util.ArrayList; import java.util.Collection; import java.util.Iterator; /** 目标:Collection集合的遍历方式。 什么是遍历? 为什么开发中要遍历? 遍历就是一个一个的把容器中的元素访问一遍。 开发中经常要统计元素的总和,找最值,找出某个数据然后干掉等等业务都需要遍历。 Collection集合的遍历方式是全部集合都可以直接使用的,所以我们学习它。 Collection集合的遍历方式有三种: (1)迭代器。 (2)foreach(增强for循环)。 (3)JDK 1.8开始之后的新技术Lambda表达式(了解) a.迭代器遍历集合。 -- 方法: public Iterator iterator(): 获取集合对应的迭代器,用来遍历集合中的元素的 boolean hasNext():判断是否有下一个元素,有返回true ,反之。 E next():获取下一个元素值! --流程: 1.先获取当前集合的迭代器 Iterator<String> it = lists.iterator(); 2.定义一个while循环,问一次取一次。 通过it.hasNext()询问是否有下一个元素,有就通过 it.next()取出下一个元素。 小结: 记住代码。 */ public class CollectionDemo01 { public static void main(String[] args) { ArrayList<String> lists = new ArrayList<>(); lists.add("赵敏"); lists.add("小昭"); lists.add("素素"); lists.add("灭绝"); System.out.println(lists); // [赵敏, 小昭, 素素, 灭绝] // it // 1、得到当前集合的迭代器对象。 Iterator<String> it = lists.iterator(); // String ele = it.next(); // System.out.println(ele); // System.out.println(it.next()); // System.out.println(it.next()); // System.out.println(it.next()); // System.out.println(it.next()); // NoSuchElementException 出现无此元素异常的错误 // 2、定义while循环 while (it.hasNext()){ String ele = it.next(); System.out.println(ele); } System.out.println("-----------------------------"); } }
增强for循环/foreach: for(元素数据类型 变量名 : 数组或者Collection集合) { //在此处使用变量即可,该变量就是元素 } 增强for循环:既可以遍历集合也可以遍历数组。
JDK5之后出现,内部原理也是一个Iterator迭代器,相当于迭代器简写【遍历集合是这样的】
实现了Iterable接口的类才可以使用迭代器和增强for,Collection接口已经实现了iterable接口 Collection<String> list = new ArrayList<>(); ... for(String ele : list) { System.out.println(ele); } 1、增强for可以遍历哪些容器? 既可以遍历集合也可以遍历数组。 2、增强for的关键是记住它的遍历格式 for(元素数据类型 变量名 : 数组或者Collection集合) { //在此处使用变量即可,该变量就是元素 }
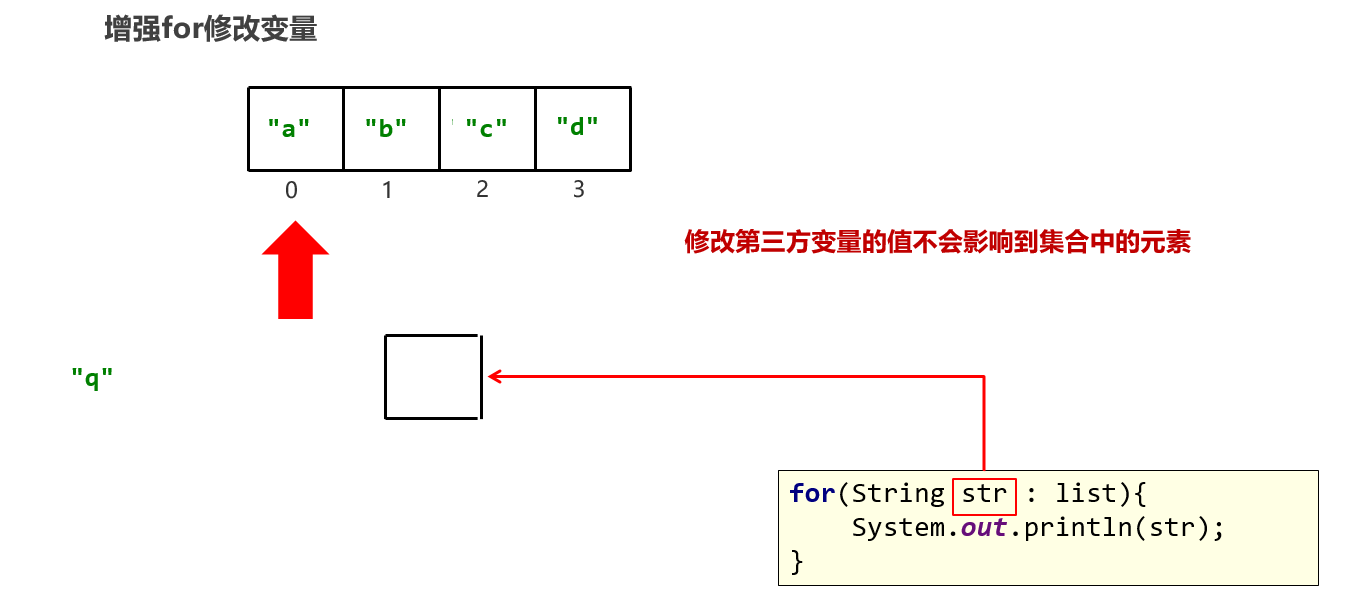
package com.itheima.d3_collection_traversal; import java.util.ArrayList; import java.util.Arrays; import java.util.Collection; /** 目标:Collection集合的遍历方式。 什么是遍历? 为什么开发中要遍历? 遍历就是一个一个的把容器中的元素访问一遍。 开发中经常要统计元素的总和,找最值,找出某个数据然后干掉等等业务都需要遍历。 Collection集合的遍历方式是全部集合都可以直接使用的,所以我们学习它。 Collection集合的遍历方式有三种: (1)迭代器。 (2)foreach(增强for循环)。 (3)JDK 1.8开始之后的新技术Lambda表达式。 b.foreach(增强for循环)遍历集合。 foreach是一种遍历形式,可以遍历集合或者数组。 foreach遍历集合实际上是迭代器遍历集合的简化写法。 foreach遍历的关键是记住格式: for(被遍历集合或者数组中元素的类型 变量名称 : 被遍历集合或者数组){ } */ public class CollectionDemo02 { public static void main(String[] args) { Collection<String> lists = new ArrayList<>(); // foreach 遍历 集合 lists.add("赵敏"); lists.add("小昭"); lists.add("殷素素"); lists.add("周芷若"); System.out.println(lists); // [赵敏, 小昭, 殷素素, 周芷若] // ele for (String ele : lists) { System.out.println(ele); } System.out.println("------------------"); double[] scores = {100, 99.5 , 59.5}; // foreach 遍历数组 for (double score : scores) { System.out.println(score); // if(score == 59.5){ // score = 100.0; // 修改无意义,不会影响数组的元素值。 // } } System.out.println(Arrays.toString(scores)); } }
Lambda表达式遍历集合 得益于JDK 8开始的新技术Lambda表达式,提供了一种更简单、更直接的遍历集合的方式。 Collection结合Lambda遍历的API default void forEach(Consumer<? super T> action): 结合lambda遍历集合
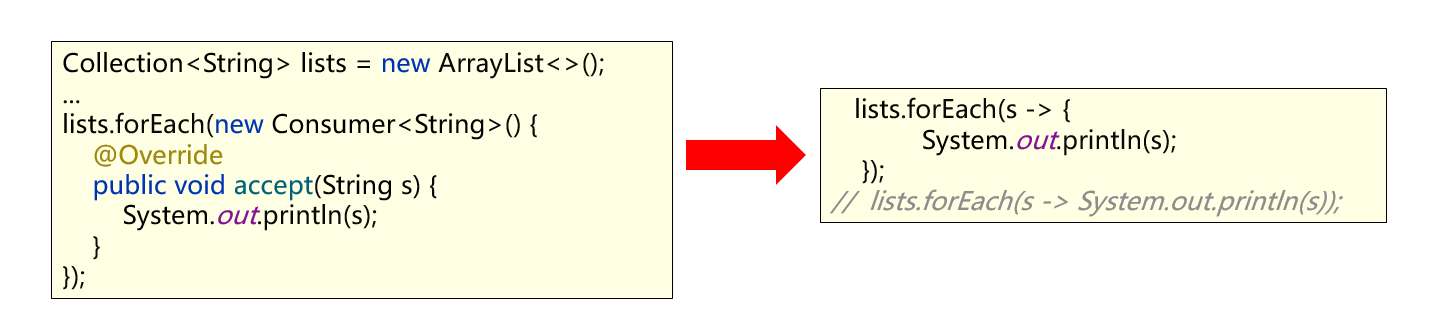
package com.itheima.d3_collection_traversal; import java.util.ArrayList; import java.util.Collection; import java.util.function.Consumer; /** 目标:Collection集合的遍历方式。 什么是遍历? 为什么开发中要遍历? 遍历就是一个一个的把容器中的元素访问一遍。 开发中经常要统计元素的总和,找最值,找出某个数据然后干掉等等业务都需要遍历。 Collection集合的遍历方式是全部集合都可以直接使用的,所以我们学习它。 Collection集合的遍历方式有三种: (1)迭代器。 (2)foreach(增强for循环)。 (3)JDK 1.8开始之后的新技术Lambda表达式。 c.JDK 1.8开始之后的新技术Lambda表达式。 */ public class CollectionDemo03 { public static void main(String[] args) { Collection<String> lists = new ArrayList<>(); lists.add("赵敏"); lists.add("小昭"); lists.add("殷素素"); lists.add("周芷若"); System.out.println(lists); // [赵敏, 小昭, 殷素素, 周芷若] // s lists.forEach(new Consumer<String>() { // 类似把这个 对象交给 forEach参数后面来回调,列表每个参数循环调用这个 方法 @Override public void accept(String s) { System.out.println(s); } }); // lists.forEach(s -> { // System.out.println(s); // }); // lists.forEach(s -> System.out.println(s) ); lists.forEach(System.out::println ); } }
5:Collection 集合存储自定义类型的对象

package com.itheima.d4_collection_object; import java.util.ArrayList; import java.util.Collection; public class TestDemo { public static void main(String[] args) { // 1、定义一个电影类 // 2、定义一个集合对象存储3部电影对象 Collection<Movie> movies = new ArrayList<>(); movies.add(new Movie("《你好,李焕英》", 9.5, "张小斐,贾玲,沈腾,陈赫")); movies.add(new Movie("《唐人街探案》", 8.5, "王宝强,刘昊然,美女")); movies.add(new Movie("《刺杀小说家》",8.6, "雷佳音,杨幂")); System.out.println(movies); // 3、遍历集合容器中的每个电影对象 for (Movie movie : movies) { System.out.println("片名:" + movie.getName()); System.out.println("得分:" + movie.getScore()); System.out.println("主演:" + movie.getActor()); } } } class Movie { private String name; private double score; private String actor; public Movie() { } public Movie(String name, double score, String actor) { this.name = name; this.score = score; this.actor = actor; } public String getName() { return name; } public void setName(String name) { this.name = name; } public double getScore() { return score; } public void setScore(double score) { this.score = score; } public String getActor() { return actor; } public void setActor(String actor) { this.actor = actor; } @Override public String toString() { return "Movie{" + "name='" + name + '\'' + ", score=" + score + ", actor='" + actor + '\'' + '}'; } }
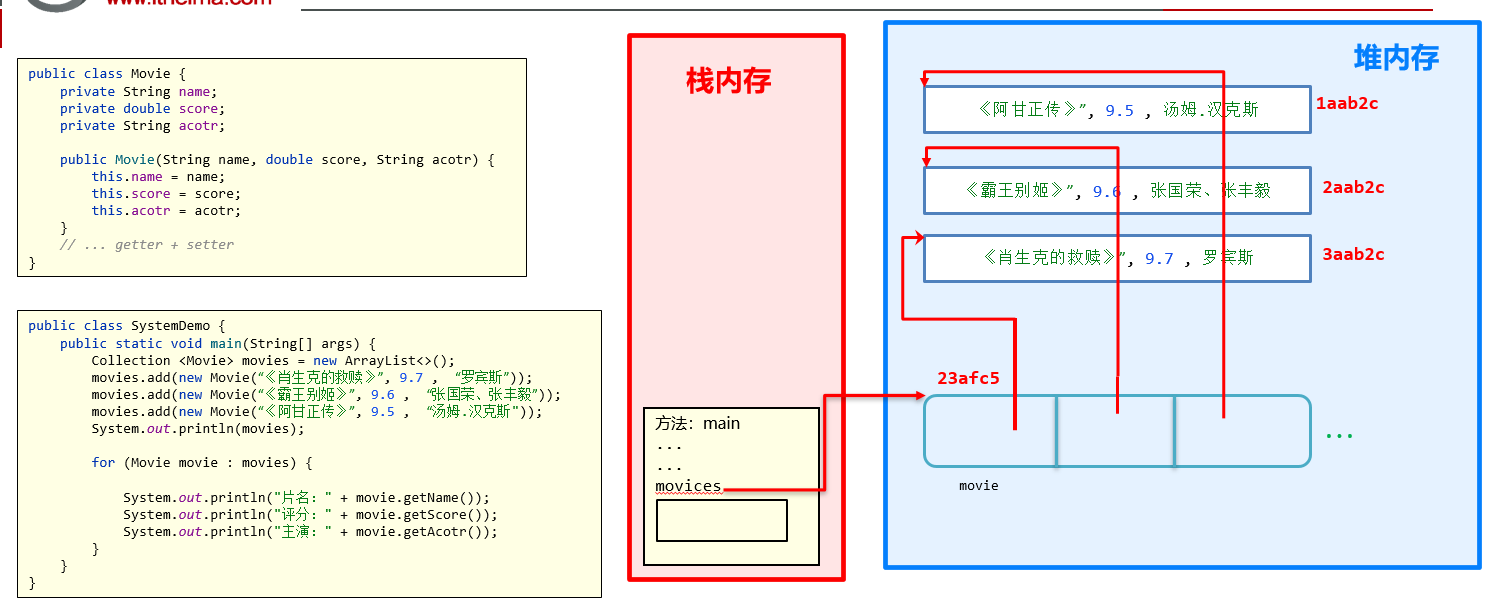
6:常见的数据结构 之 栈 队列
数据结构概述:
数据结构是计算机底层存储、组织数据的方式。是指数据相互之间是以什么方式排列在一起的。
通常情况下,精心选择的数据结构可以带来更高的运行或者存储效率
常见的数据结构:
栈
队列
数组
链表
二叉树
二叉查找树
平衡二叉树
红黑树
…
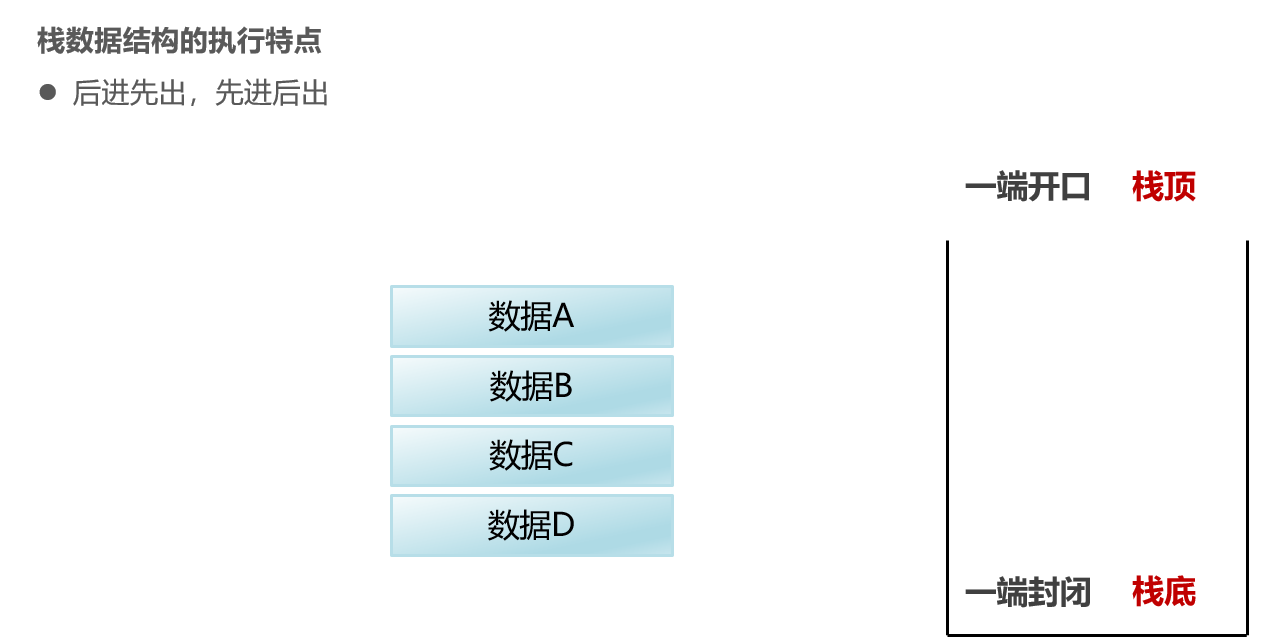
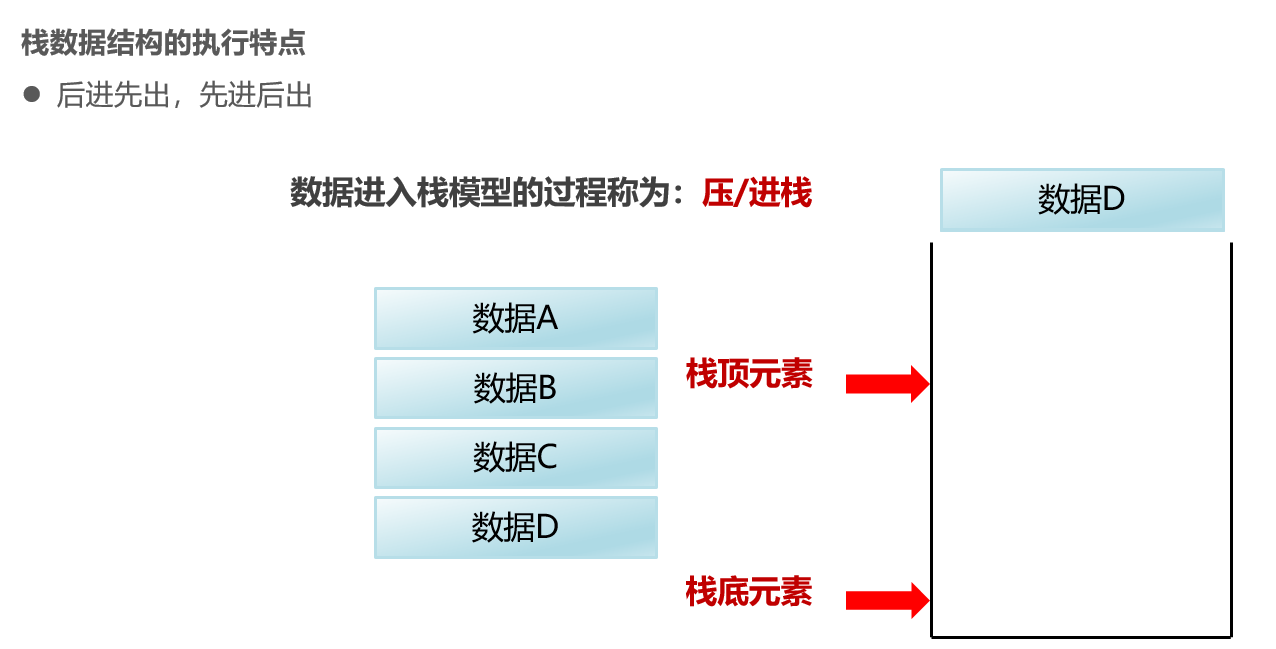
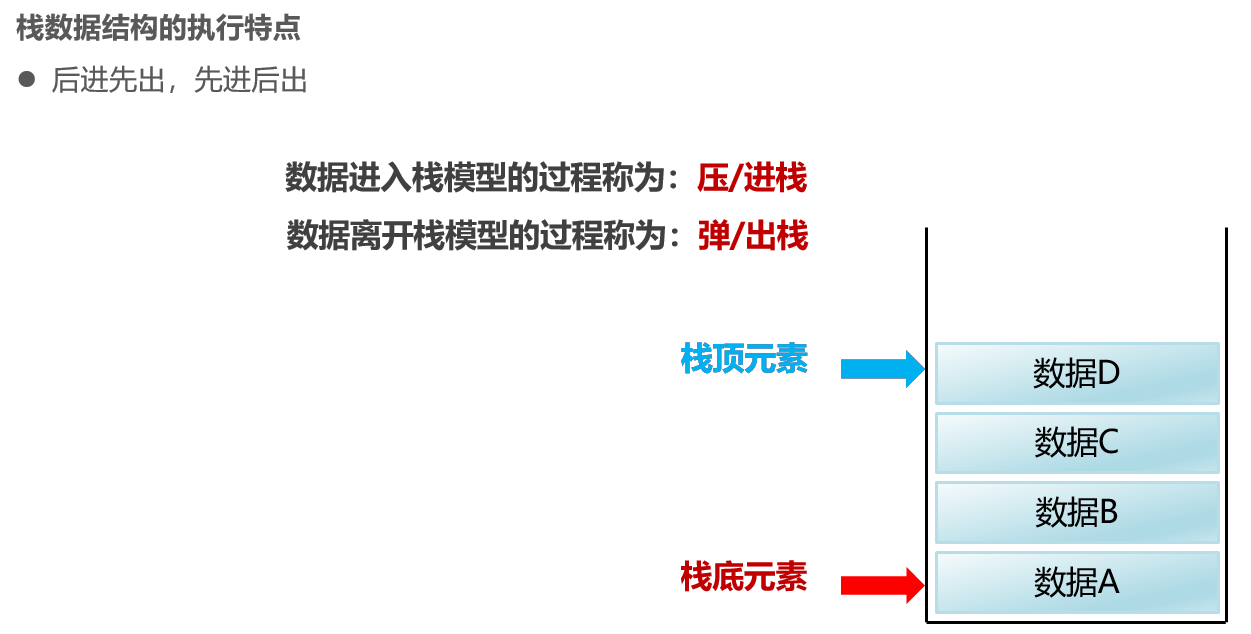
栈:后进先出,先进后出
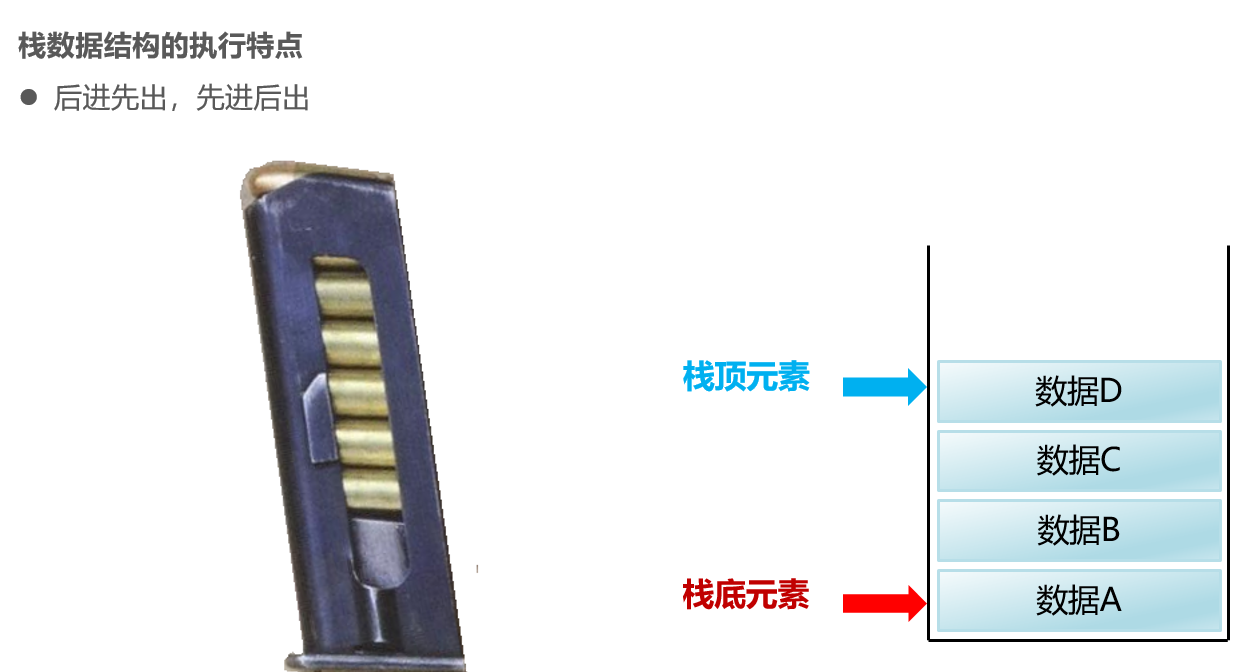
队列:先进先出,后进后出【后端入,前端出】




7:常见的数据结构 之 数组【Arrylist】
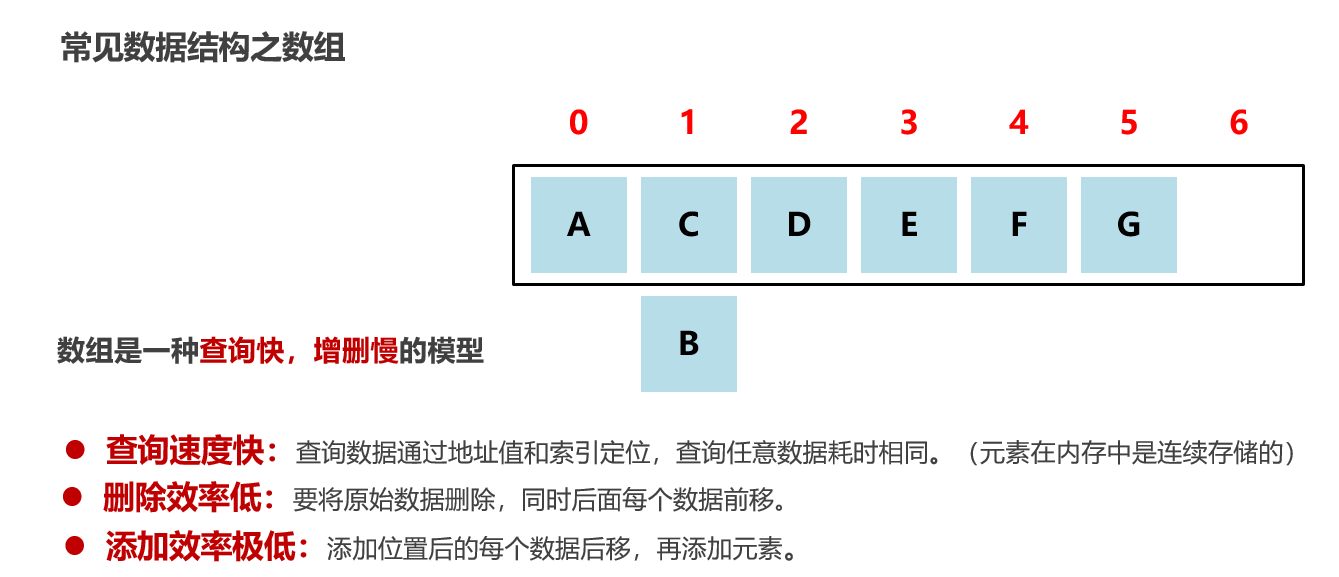
常见数据结构之数组:
底层是内存中一块连续区域,一个挨着一个 【每个房间大小固定,存储1个数据,有标号】
根据索引查询数据速度快【起始地址加按照单位长度】【元素再内存中连续存储的 查询arr[3]和arr[3000]速度一样的】,根据值查询元素速度并不快【遍历查询】
删除效率低,添加元素效率低
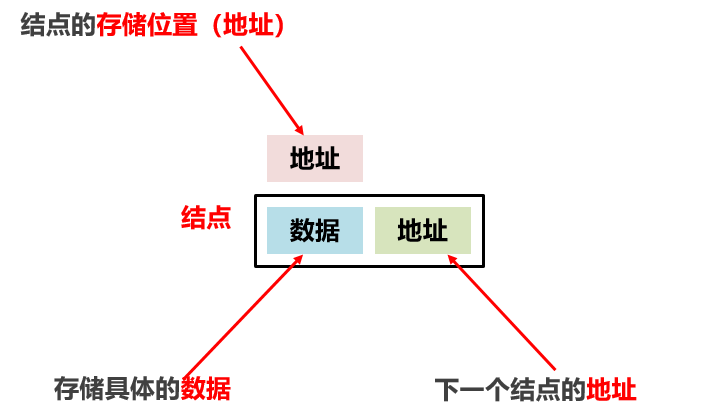
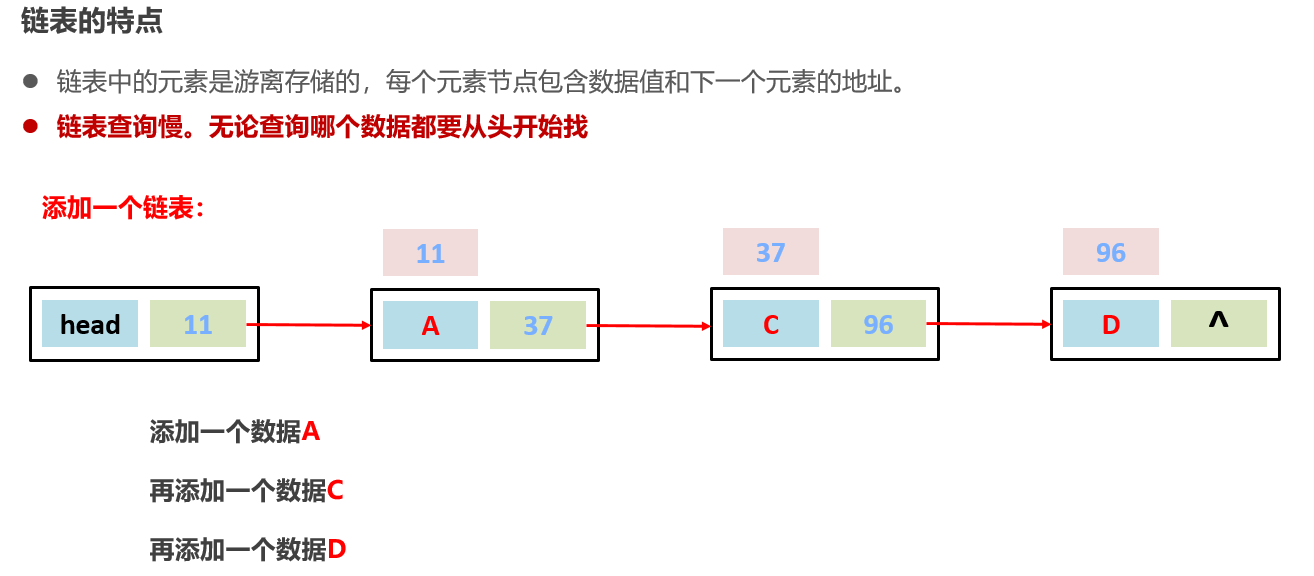
8:常见的数据结构 之 链表【一般使用双向链表】
链表中的元素是在内存中不连续存储的,每个元素节点包含数据值和下一个元素的地址。【游离存储】
查询速度慢:
无聊查询那个数据都是遍历查找,从头到尾,有索引查询也慢【比如查找arr[100],100这个元素在哪里只有99知道,因为存储地址离散的】
链表插入和删除数据相对来说快:【找位置的过程也慢,只是增删这一下快】
增删首尾的元素特别快【增删内部某个节点元素找元素过程相对来说快】
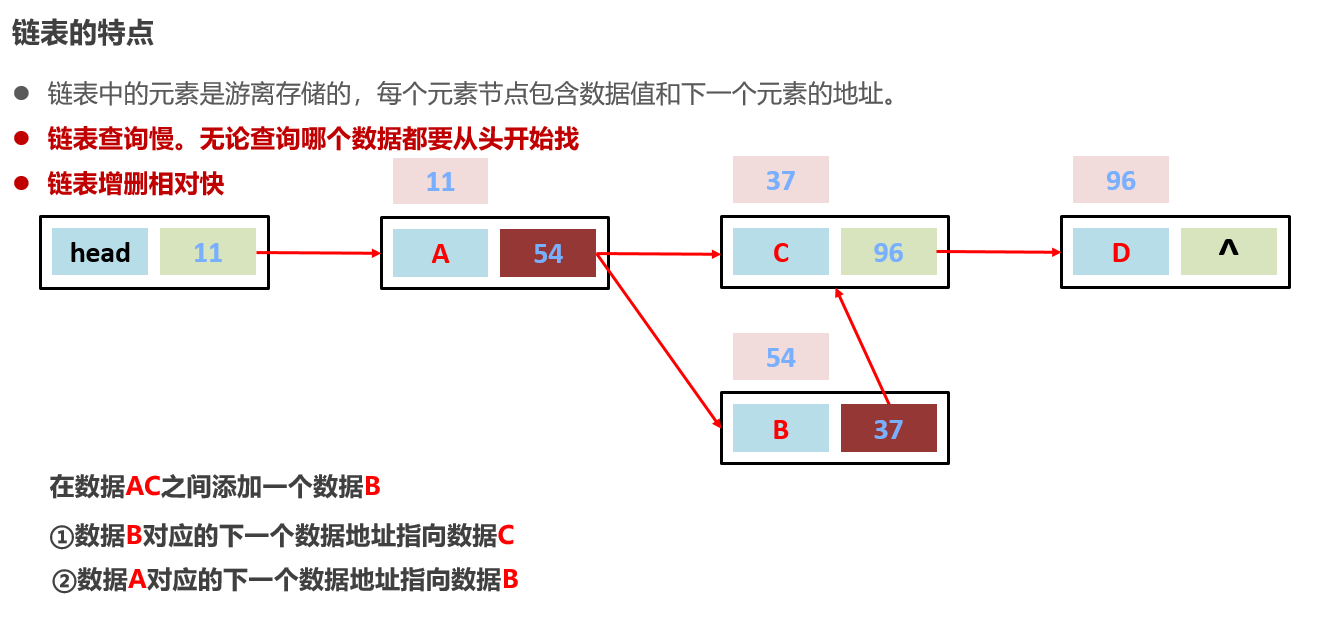
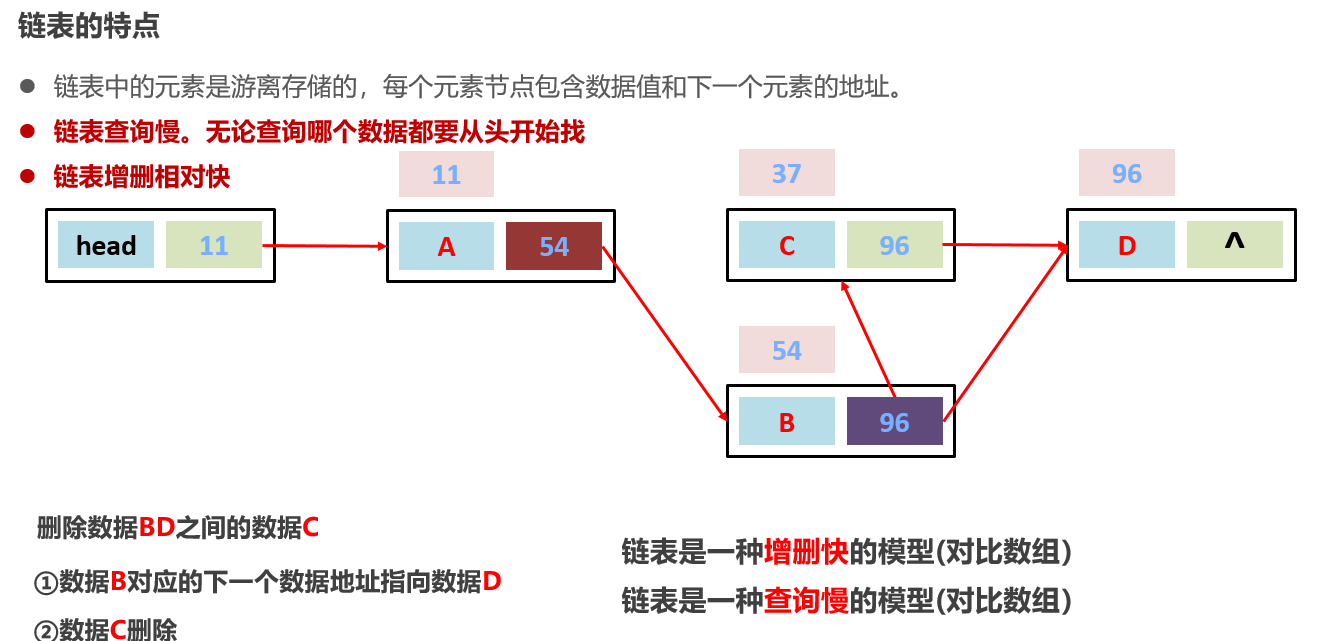
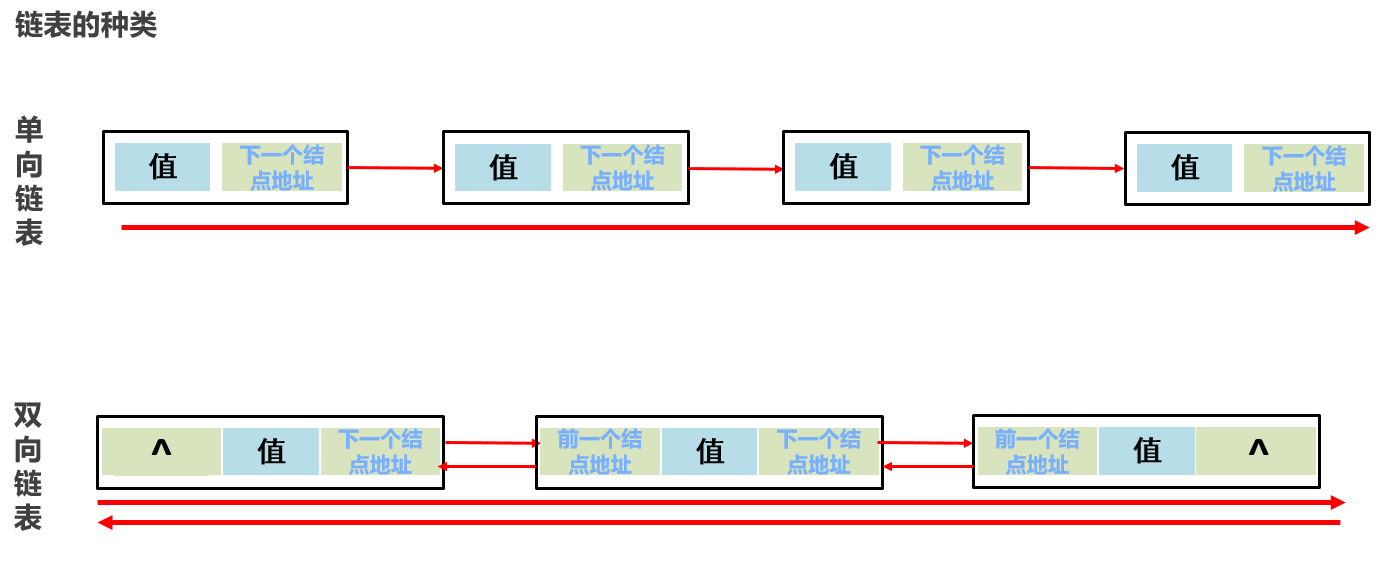
9:常见的数据结构 之 二叉树

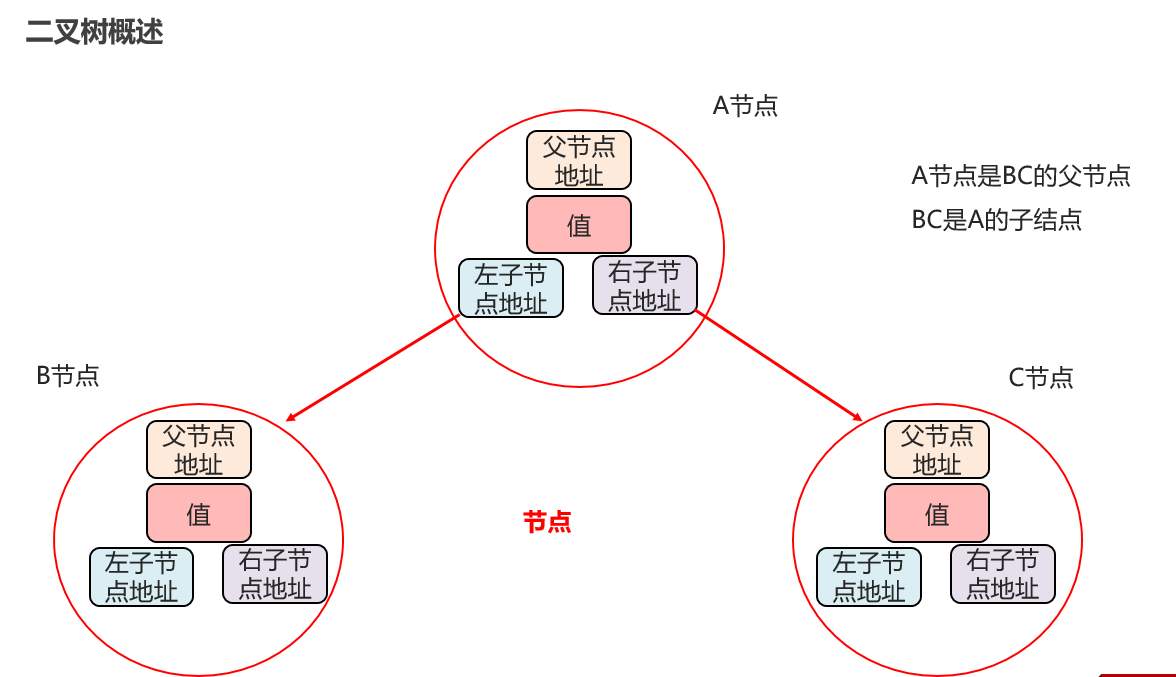
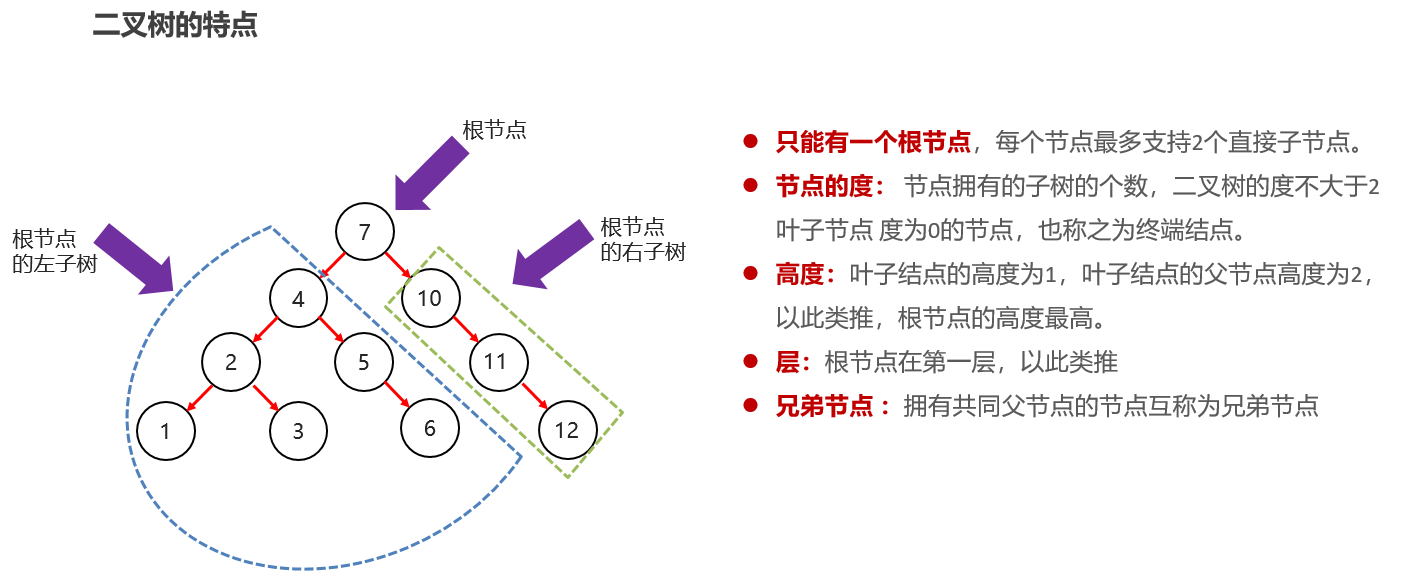
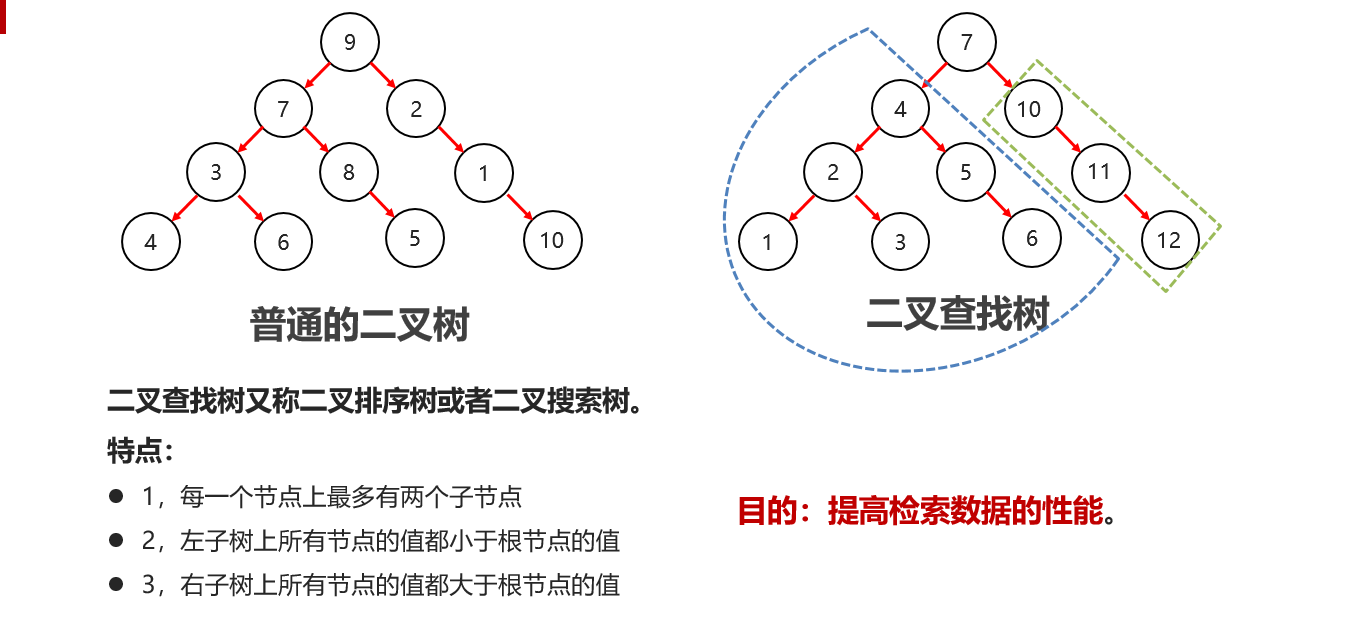
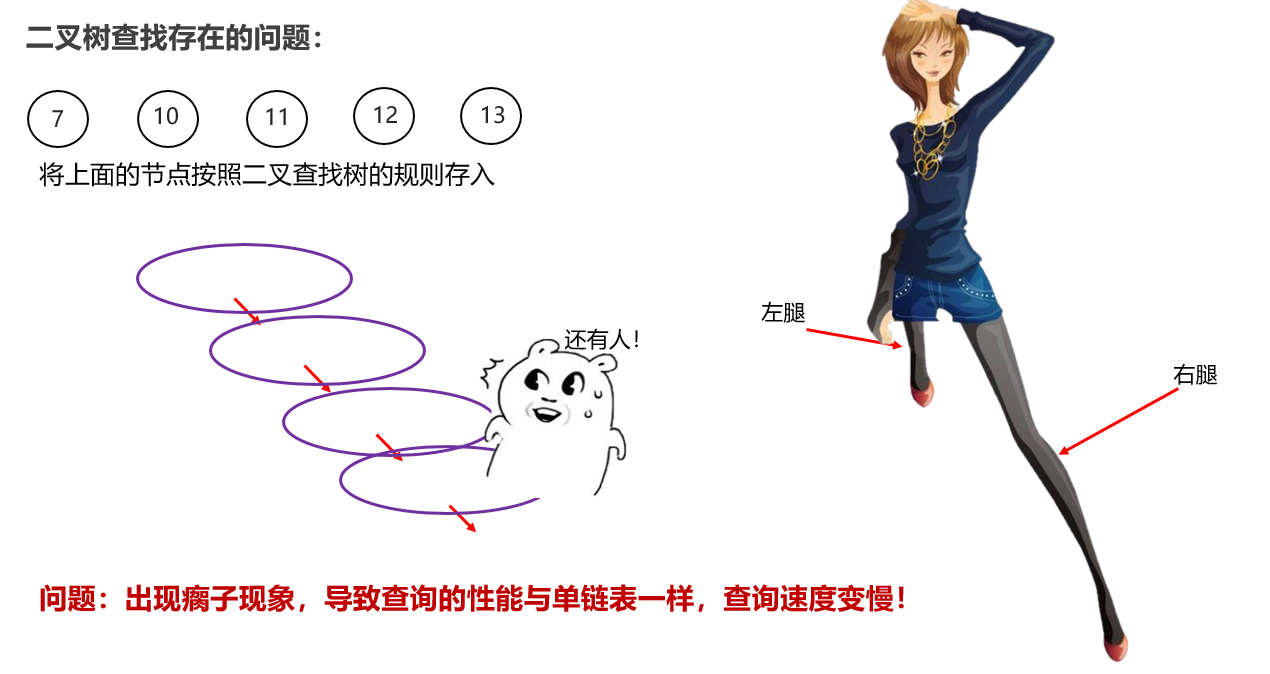
一般使用二叉查找树:小的往左边走,大的右边走【二叉排序树,二叉搜索树】【普通二叉树排序乱的,没有使用价值】
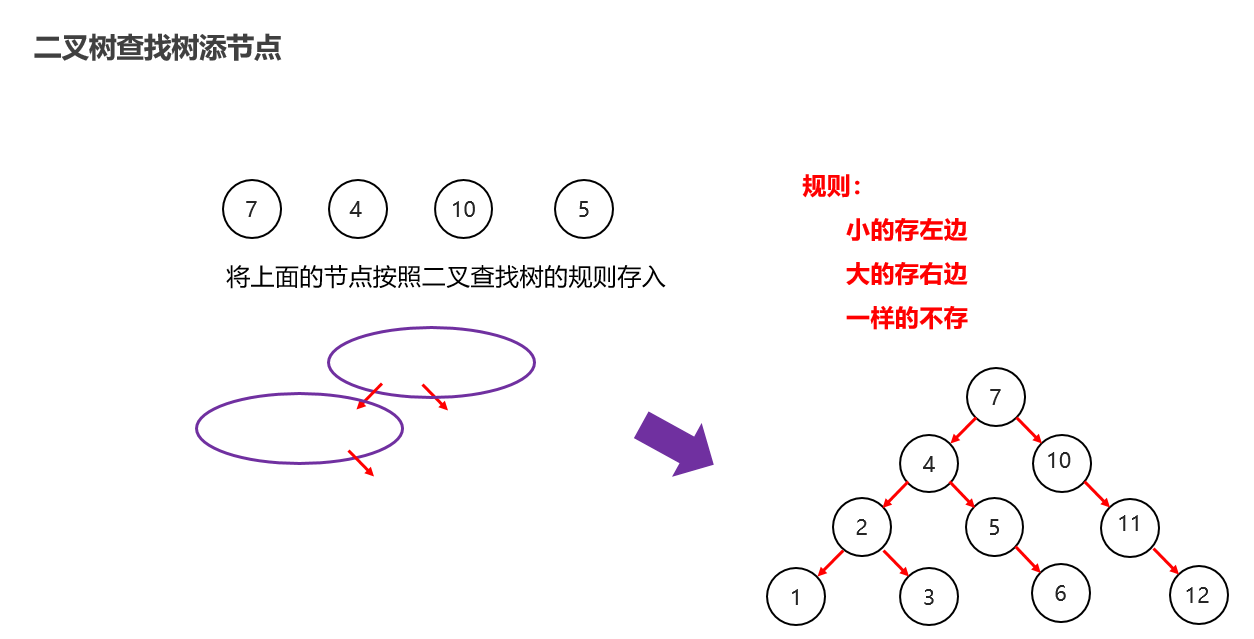
二叉查找树:增删改查都比较速度快【重点】
10:常见的数据结构 之 平衡二叉树
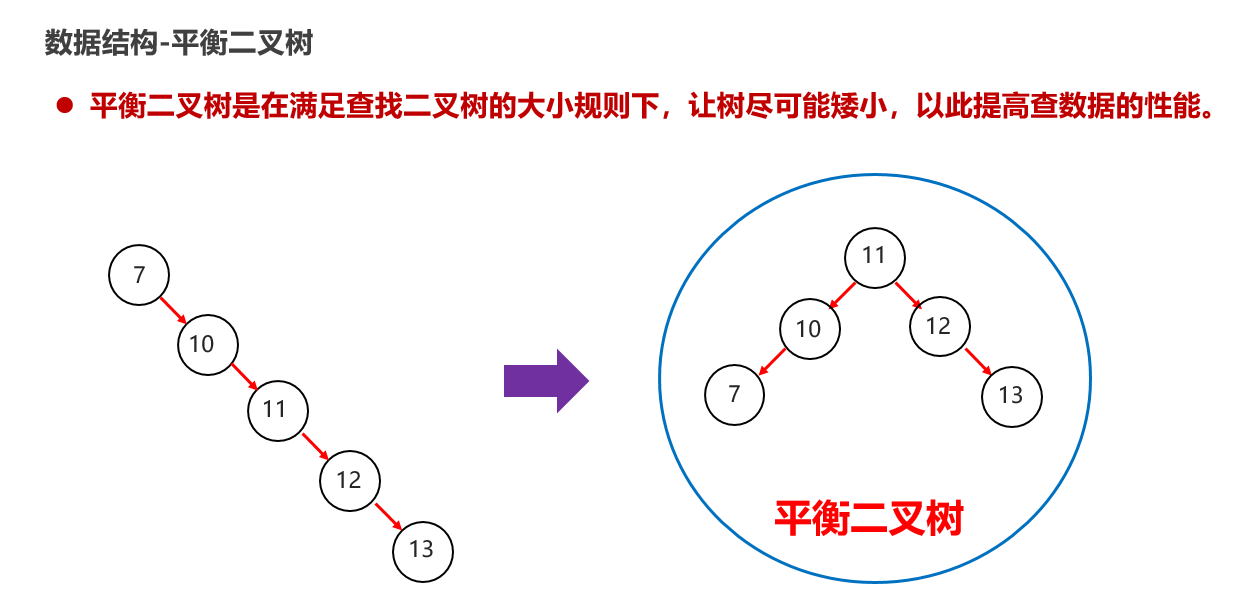
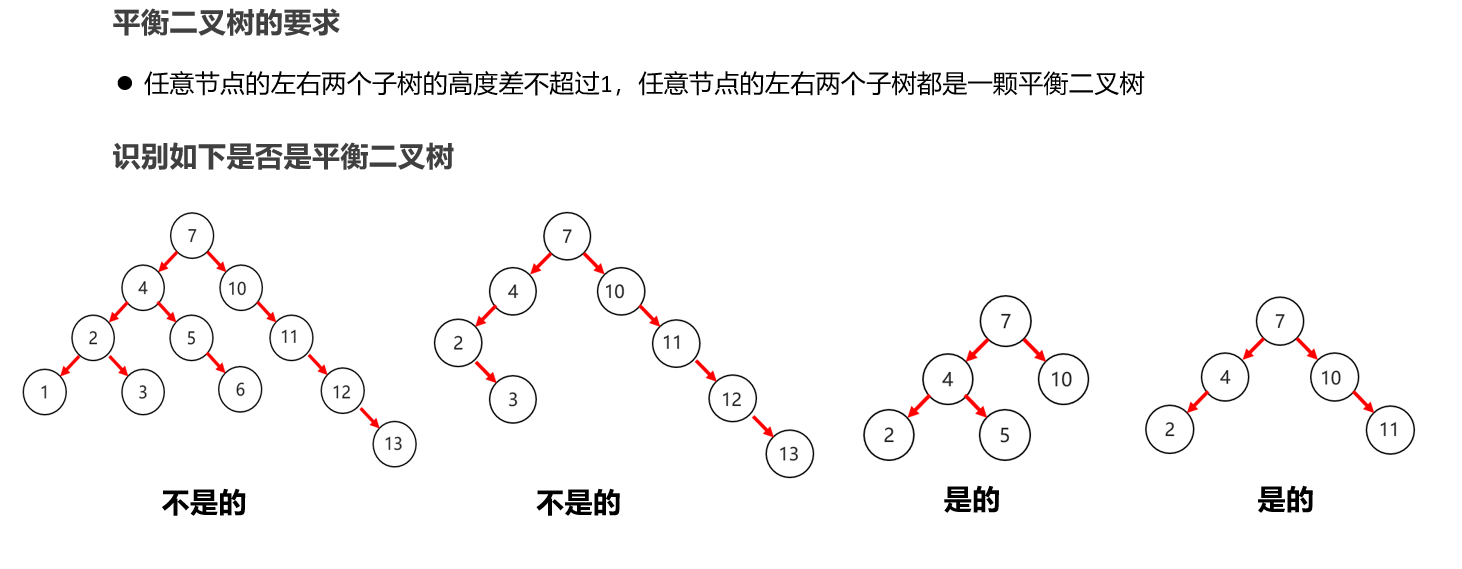
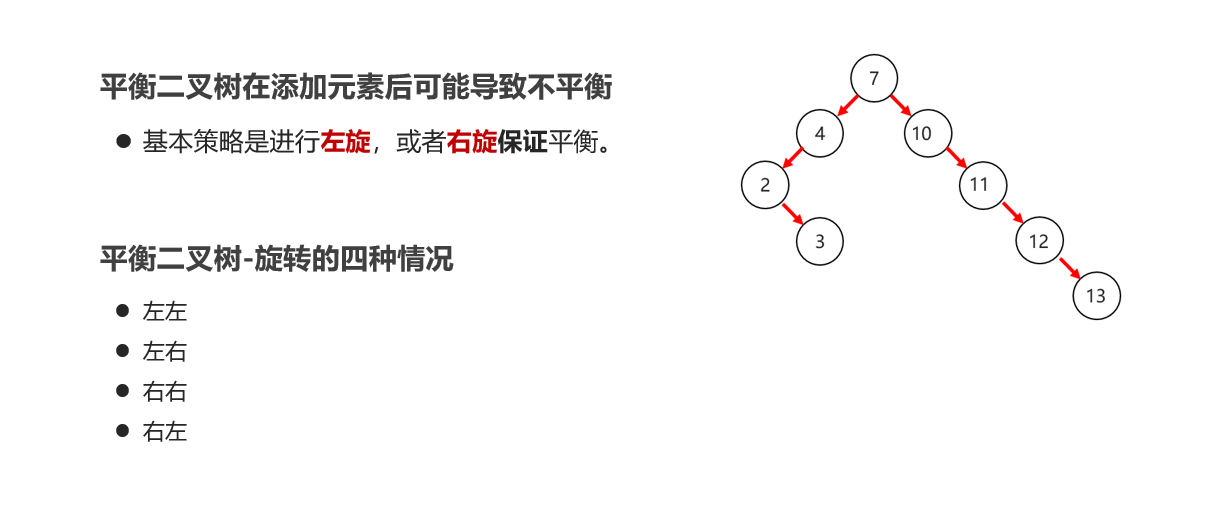
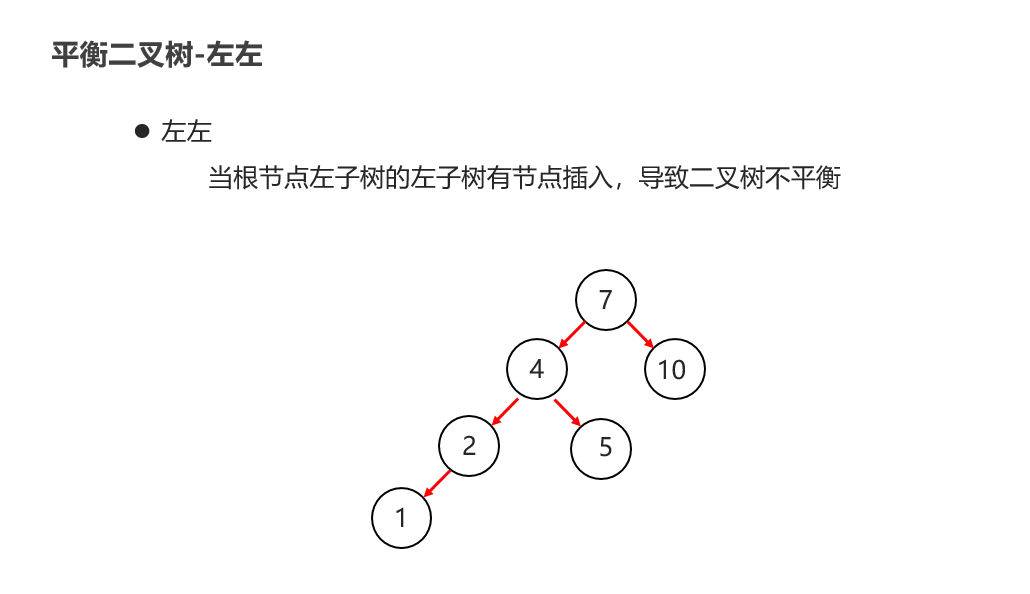
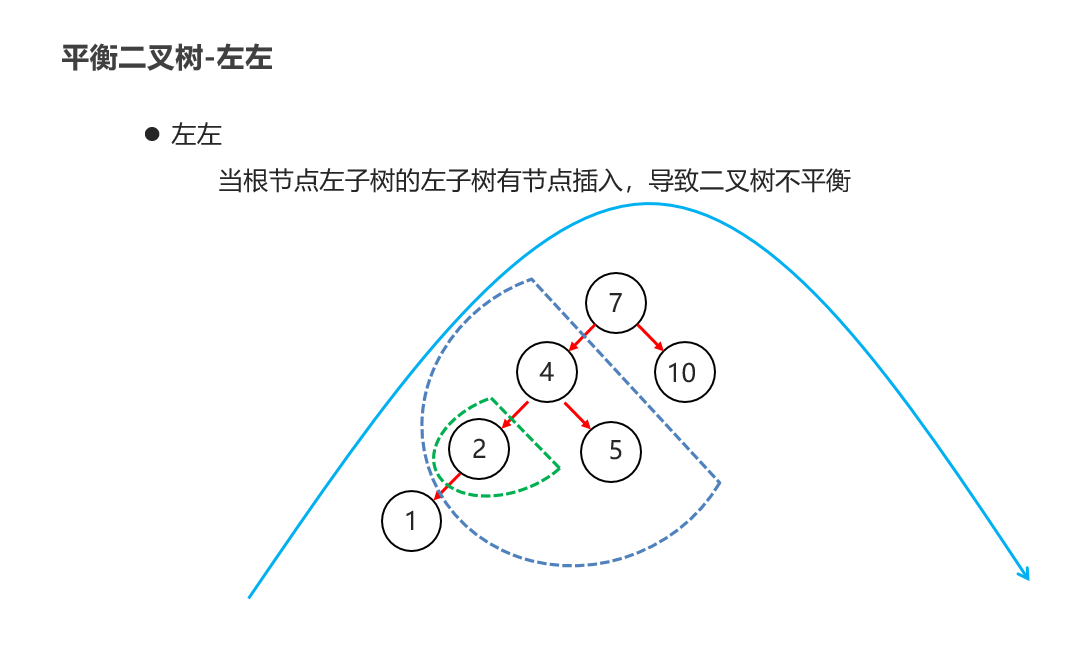
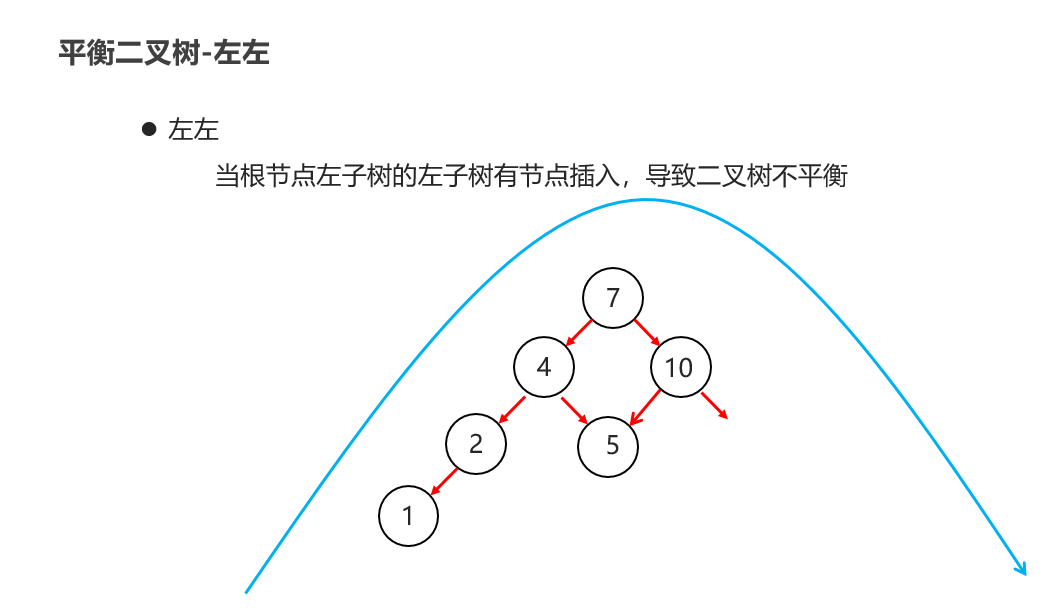
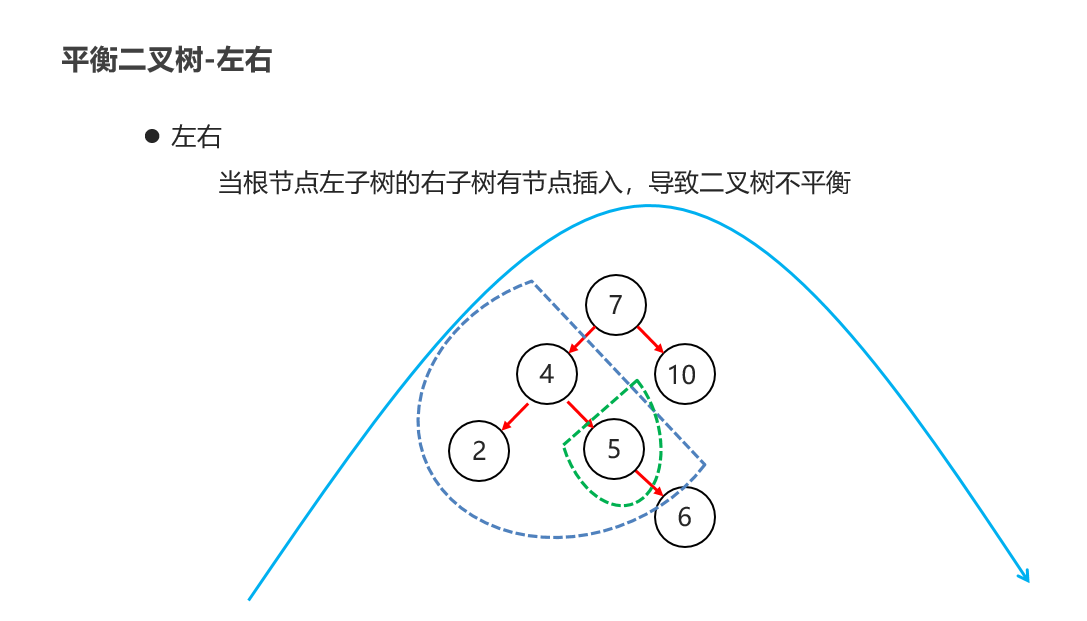
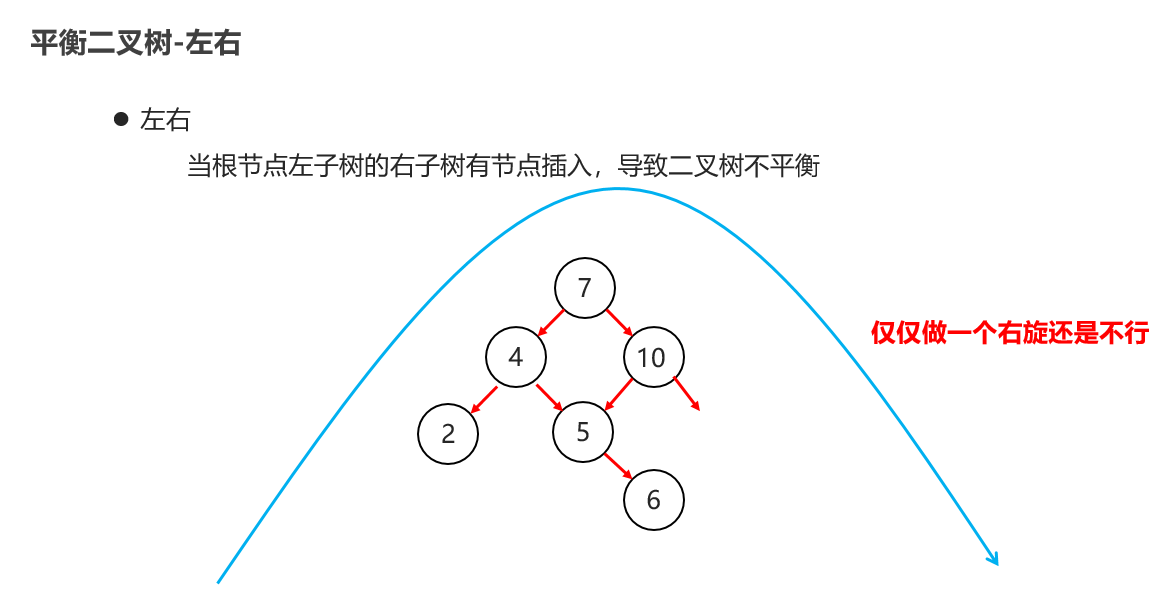
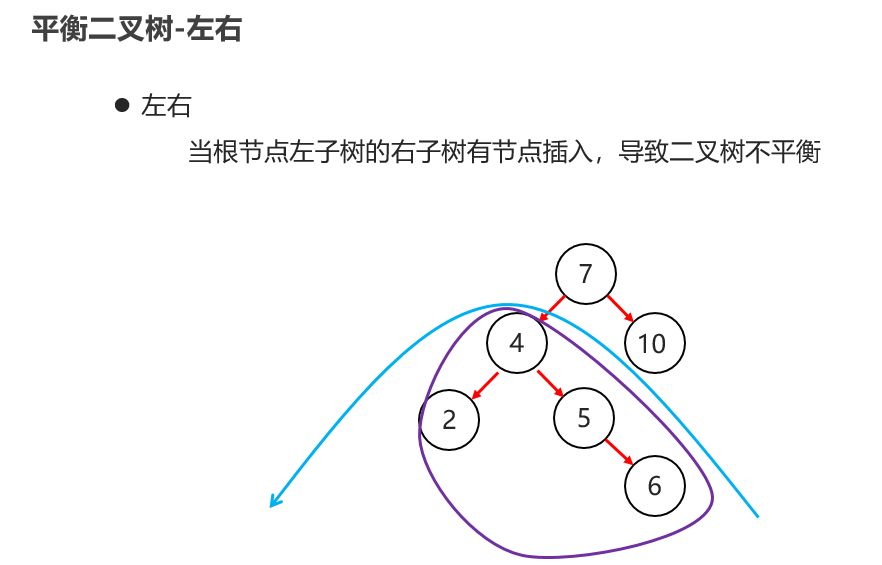
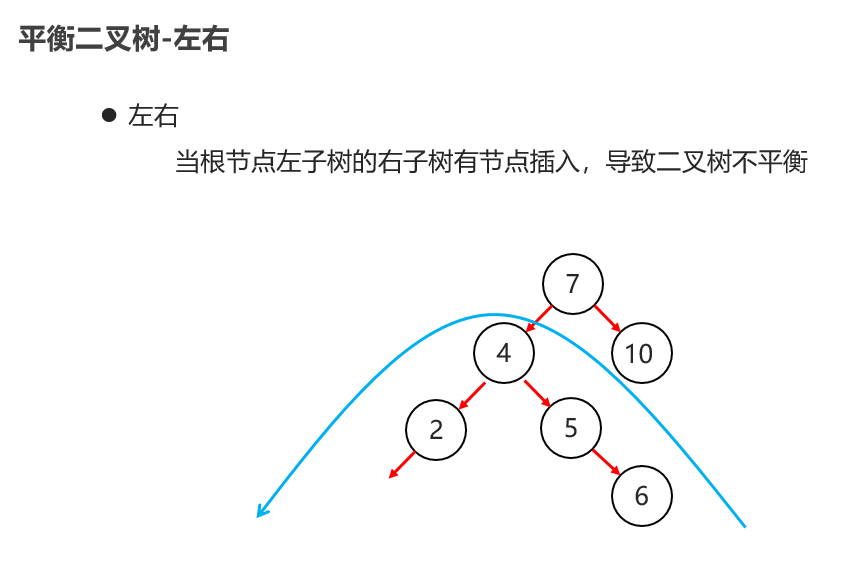
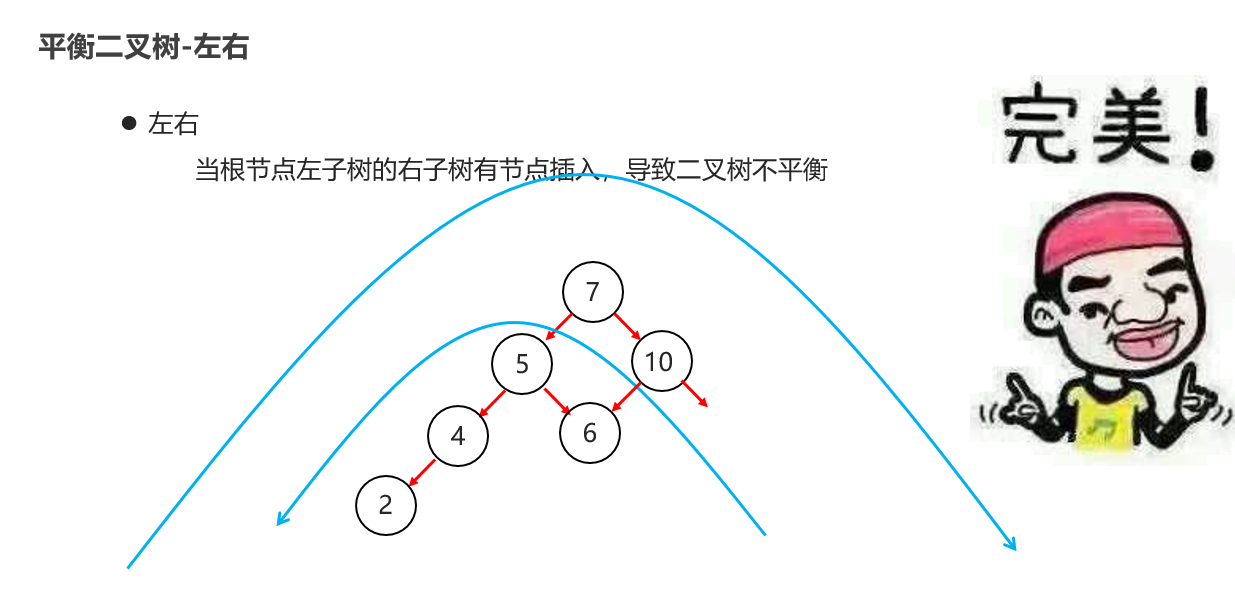
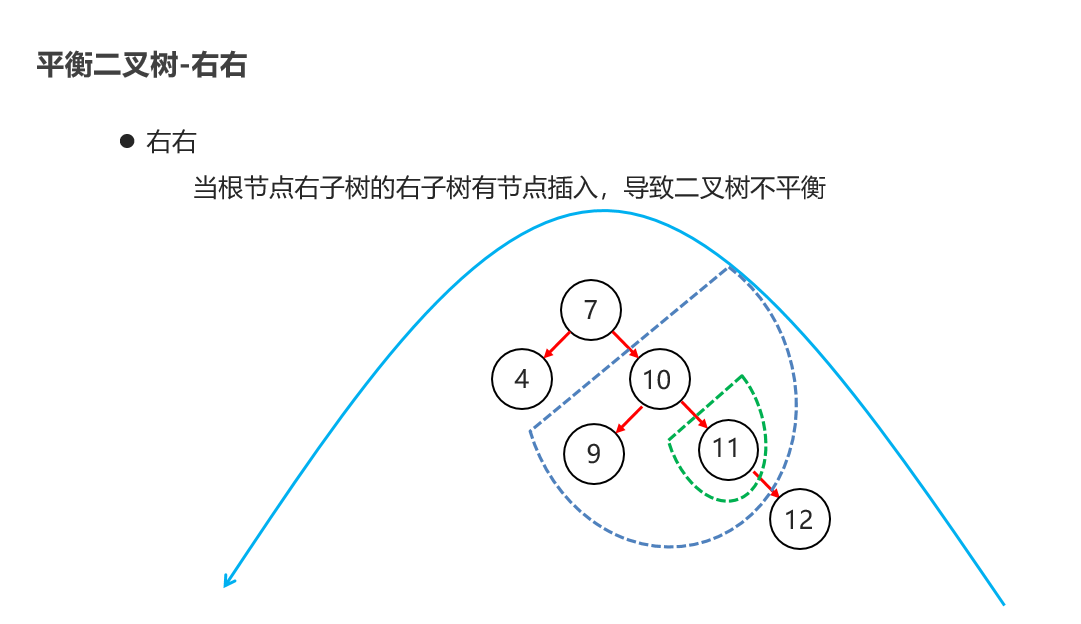
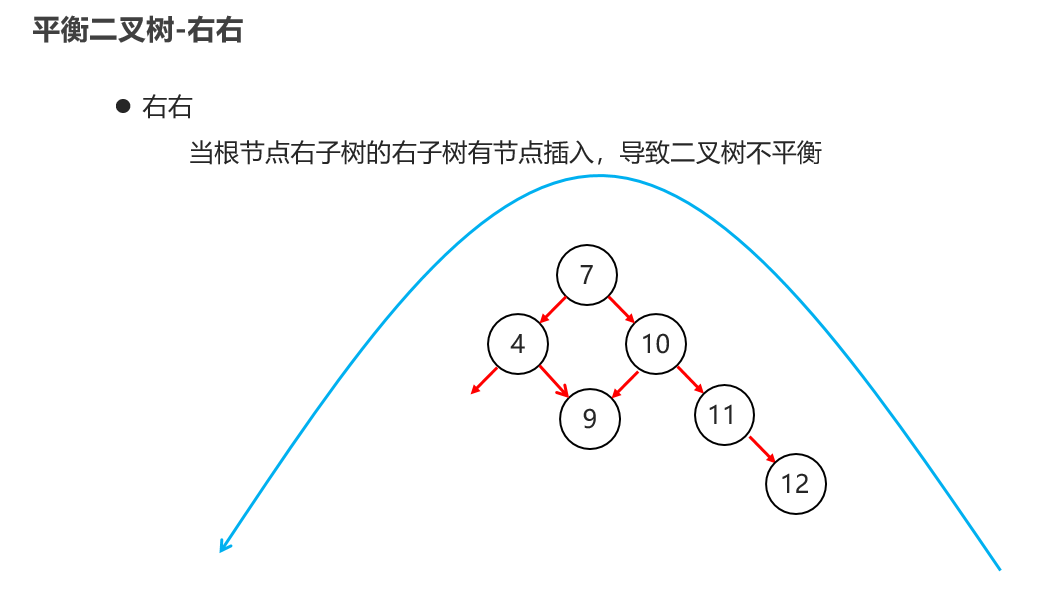

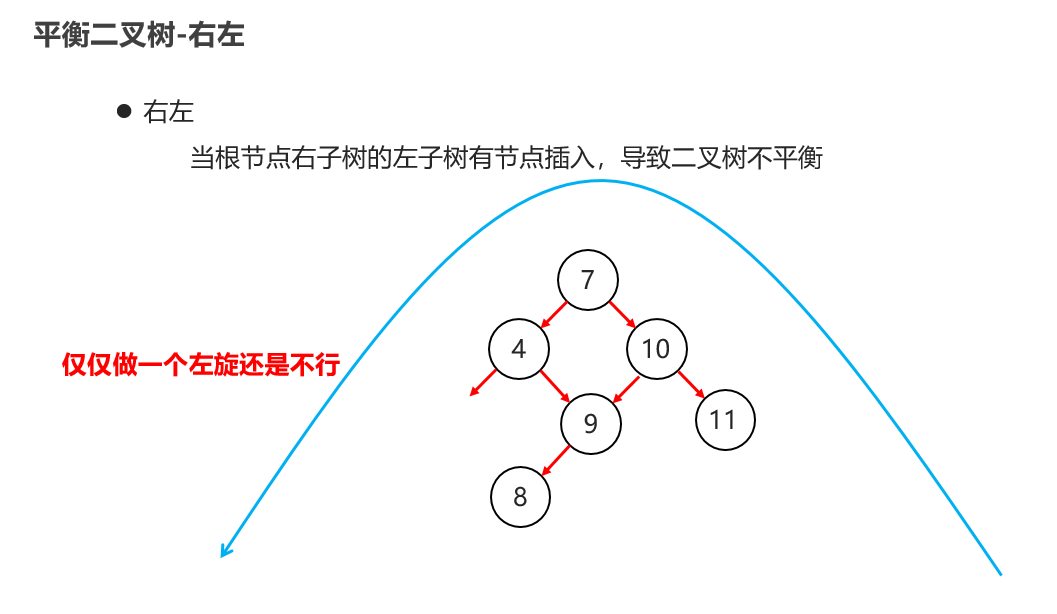
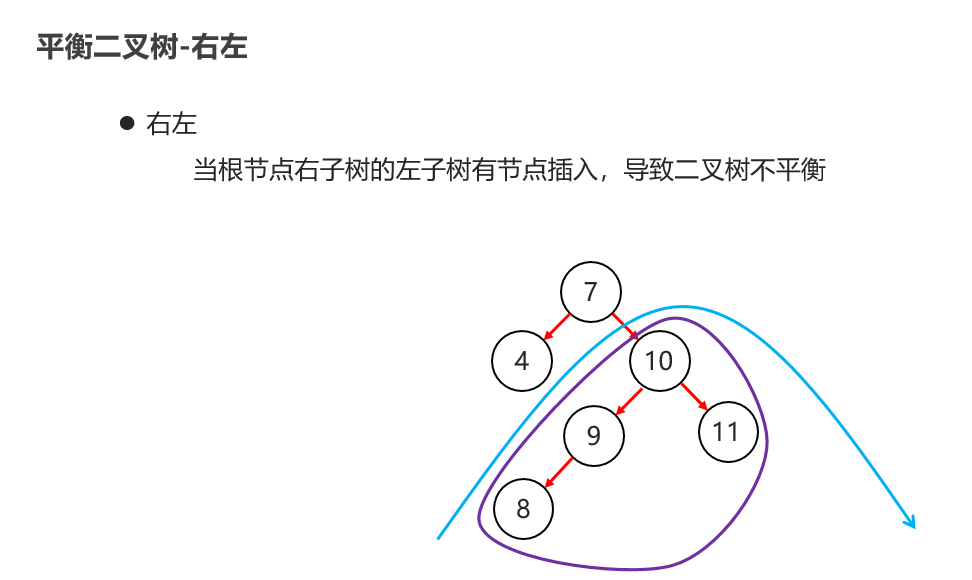

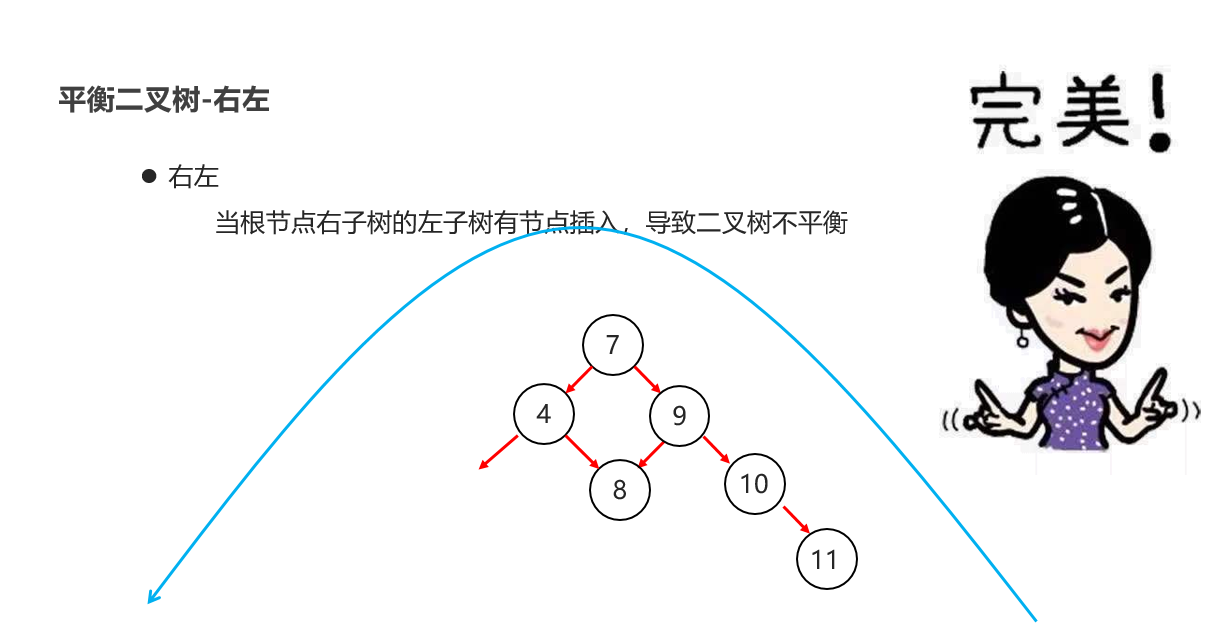
11:常见的数据结构 之 红黑二叉树
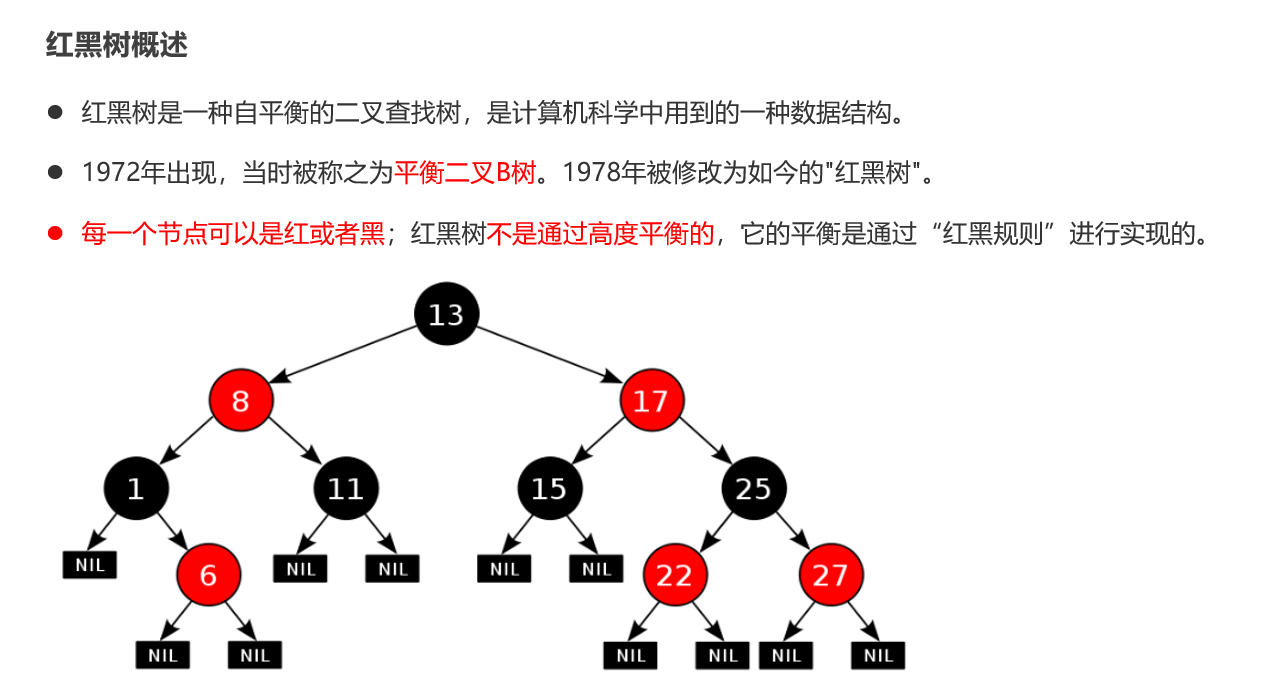
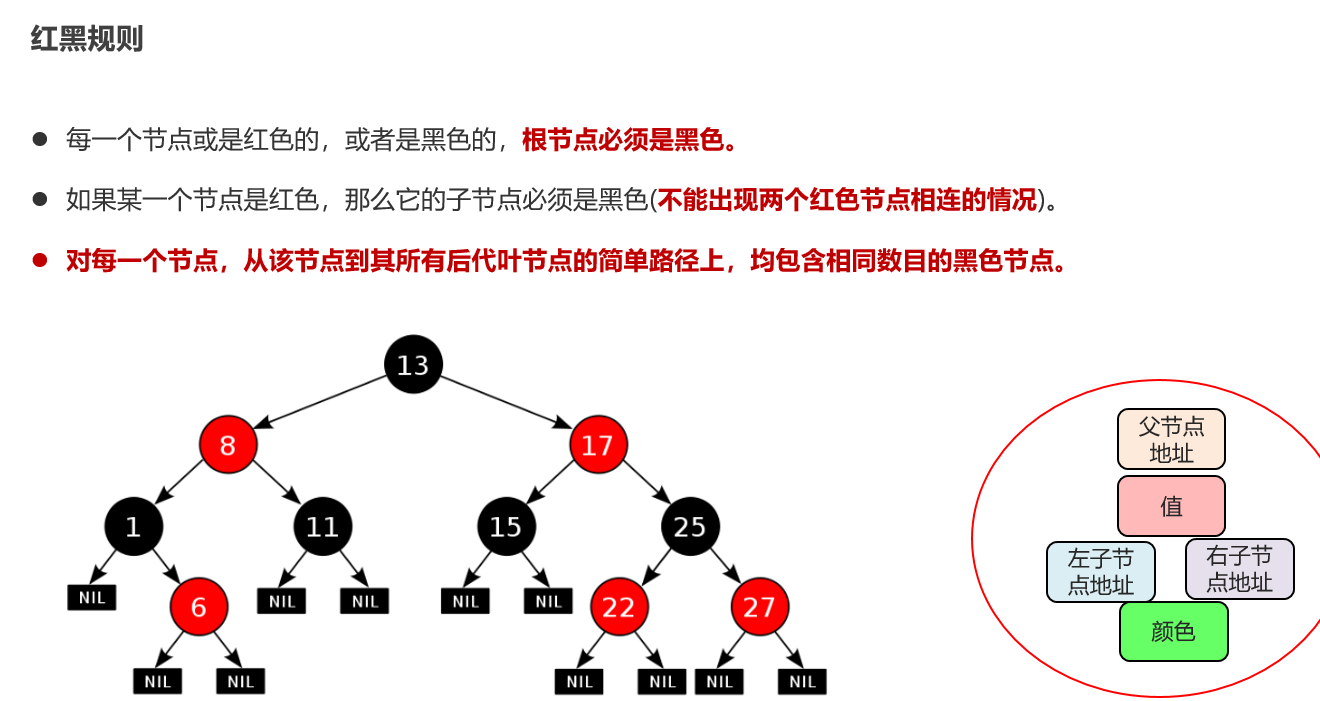
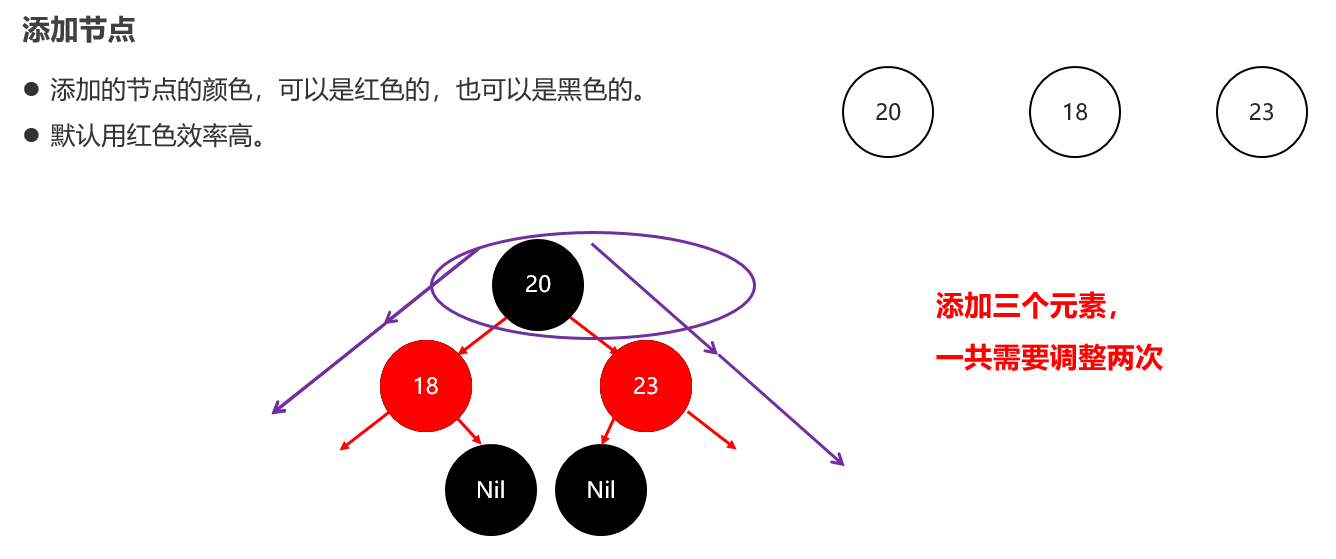
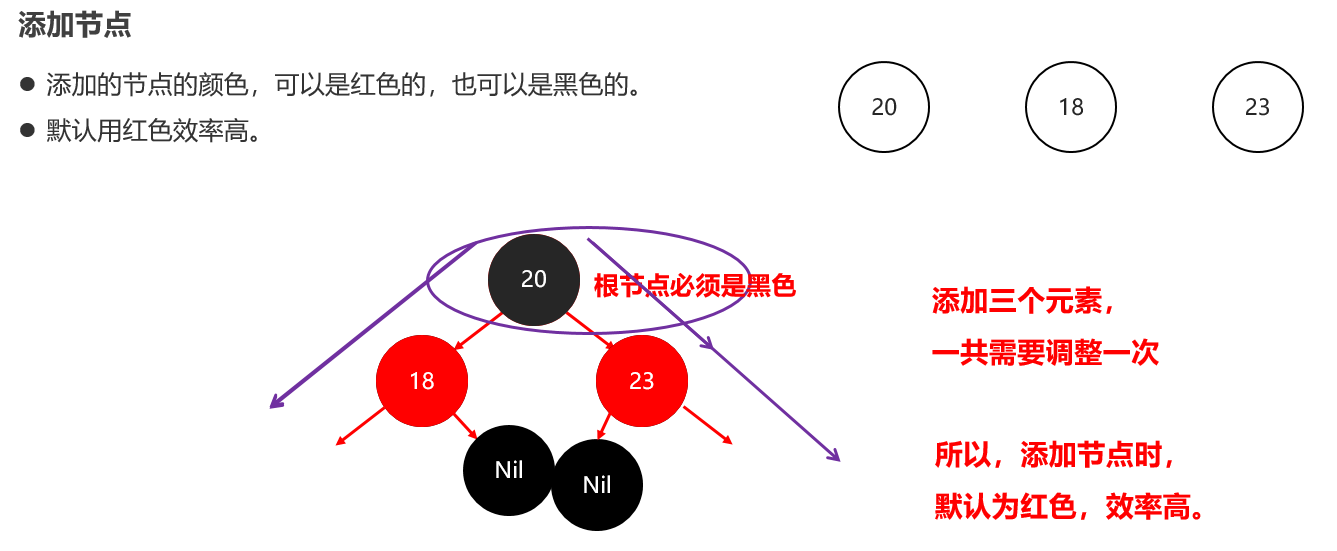
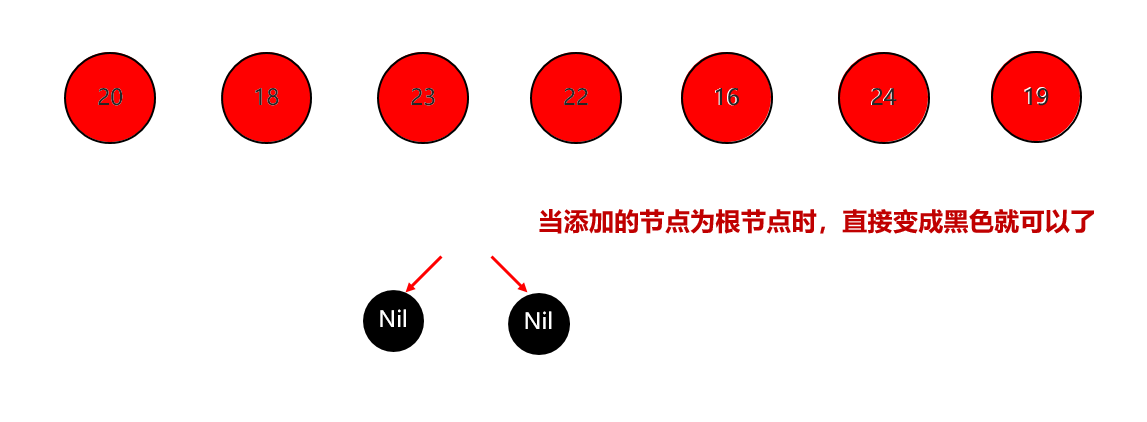
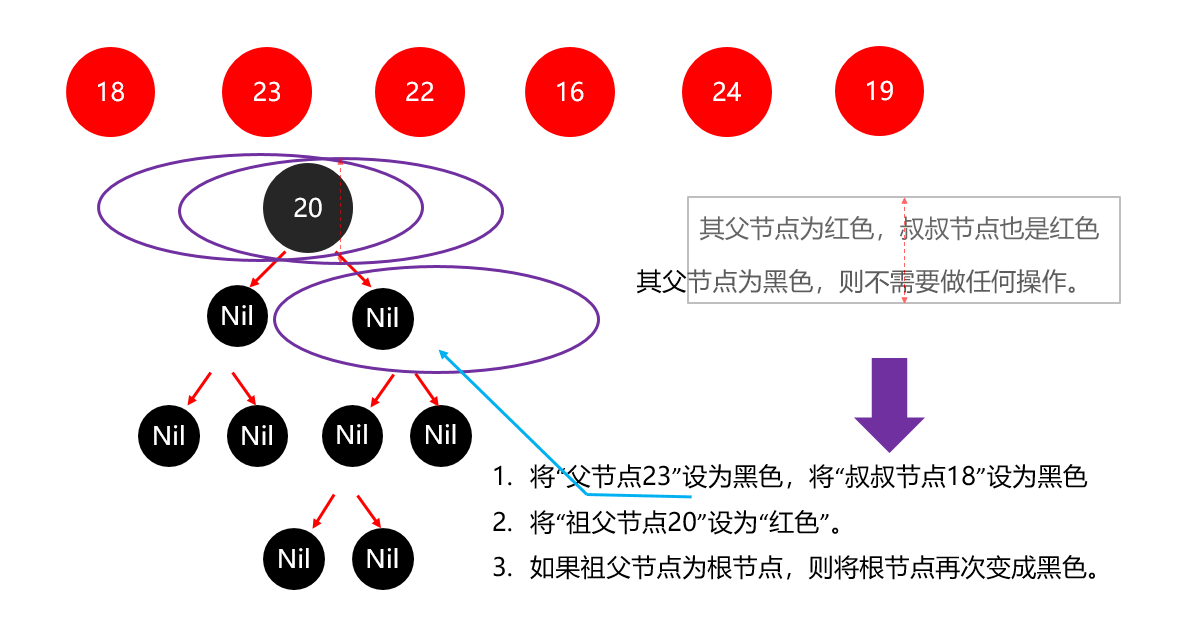
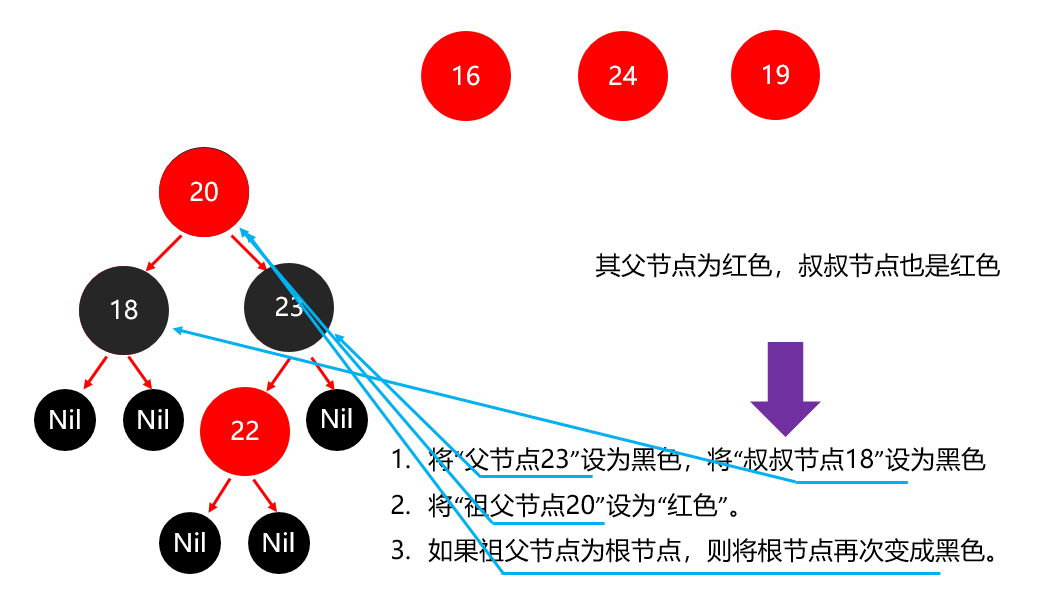
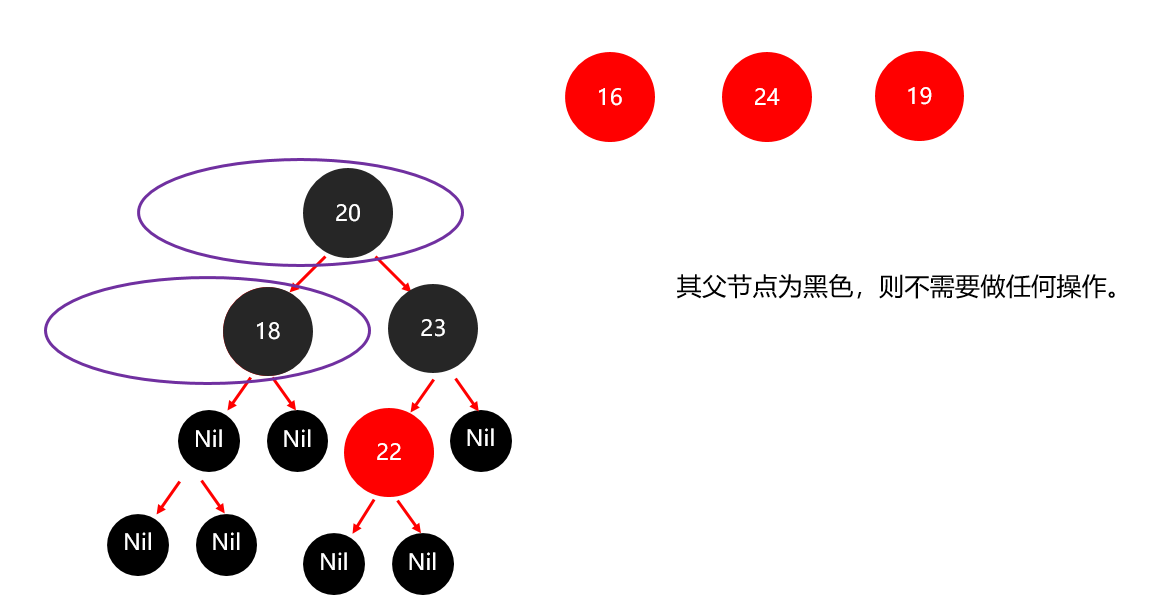
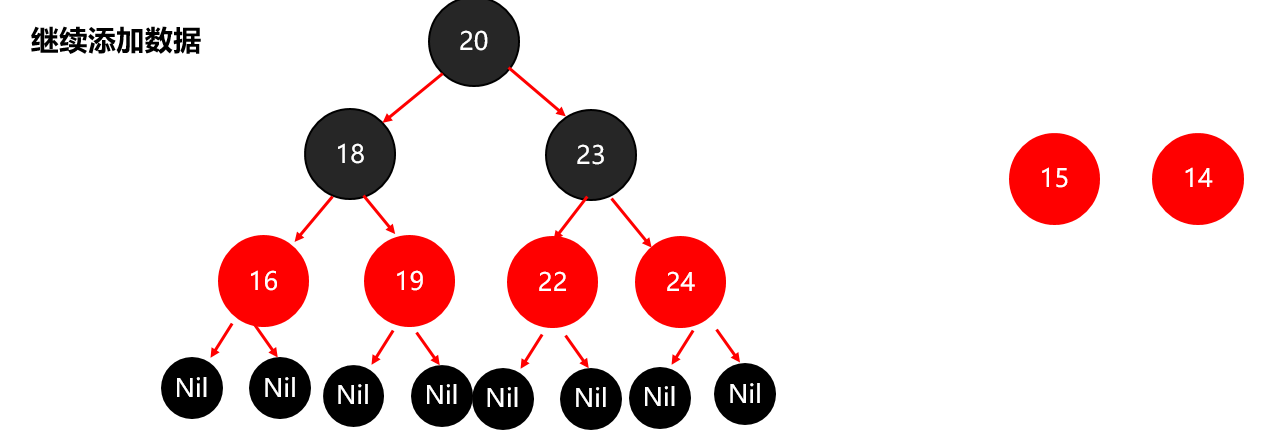
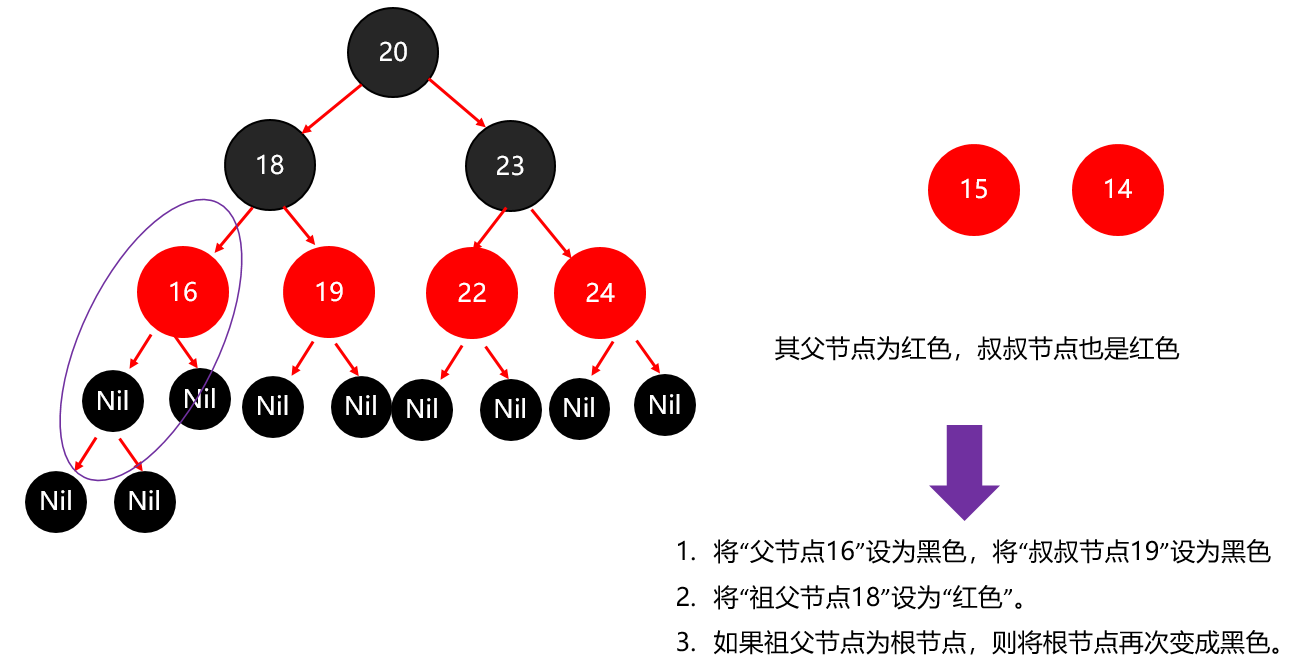
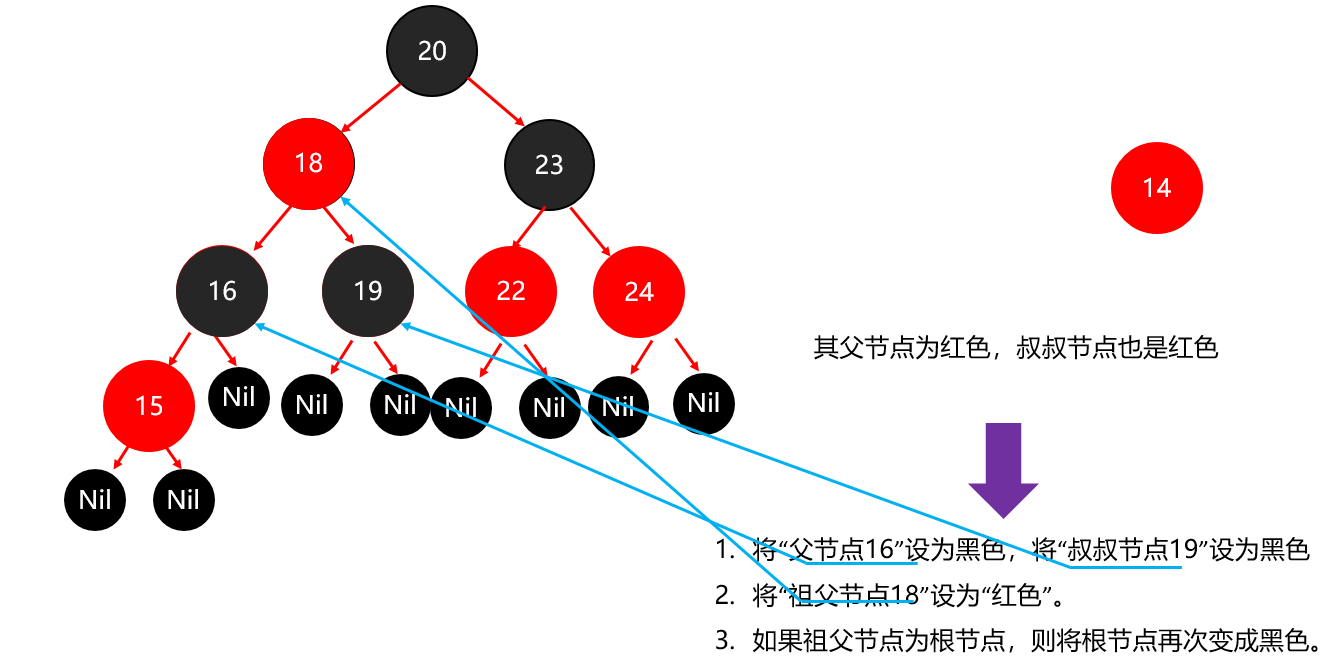
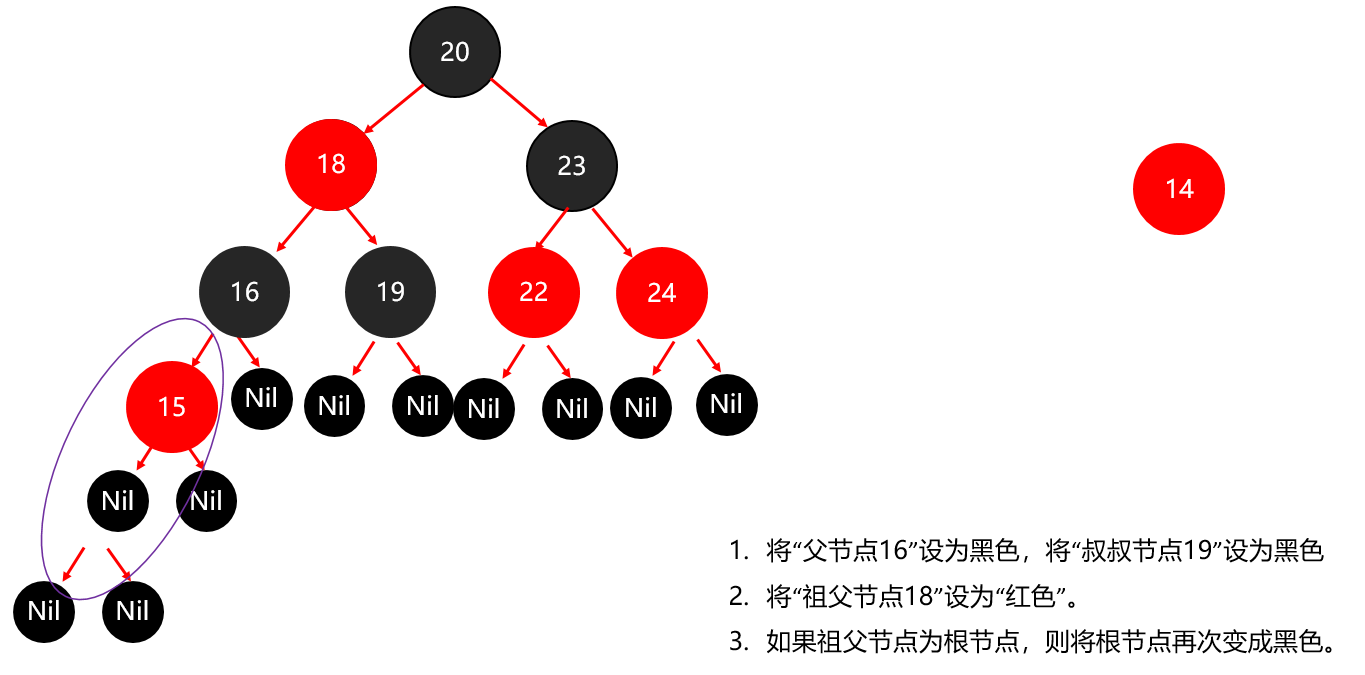
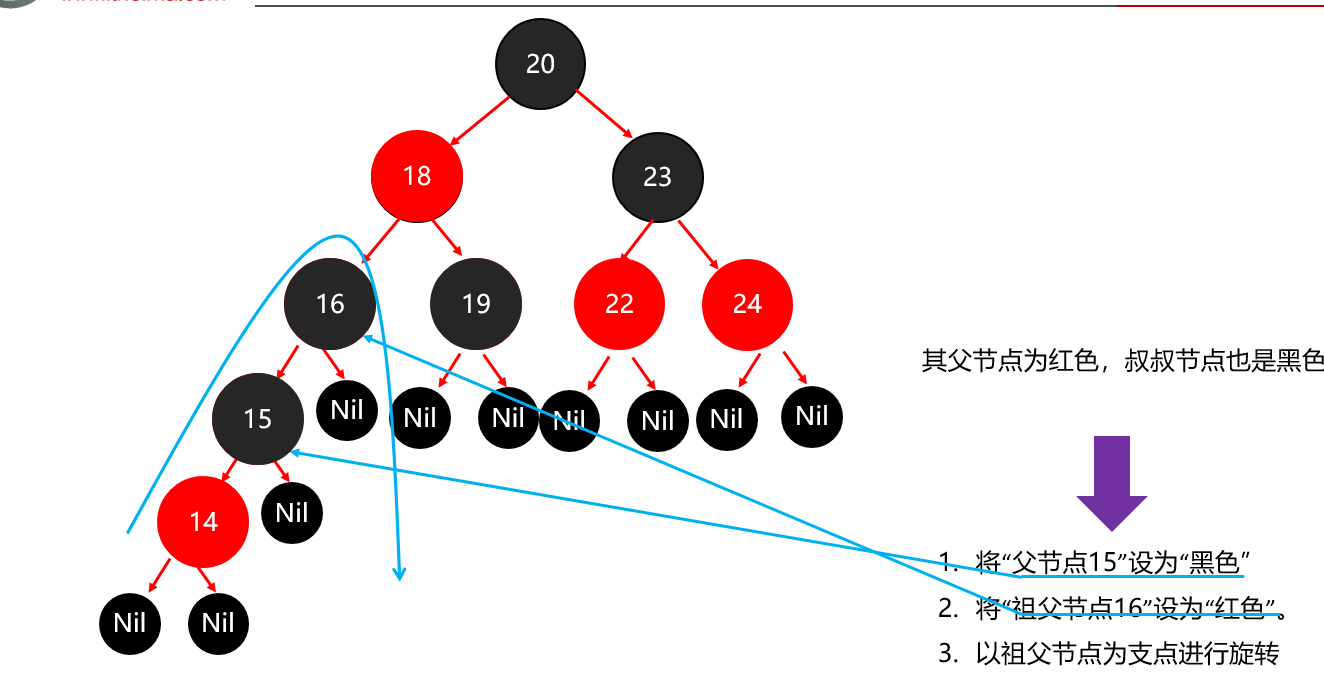
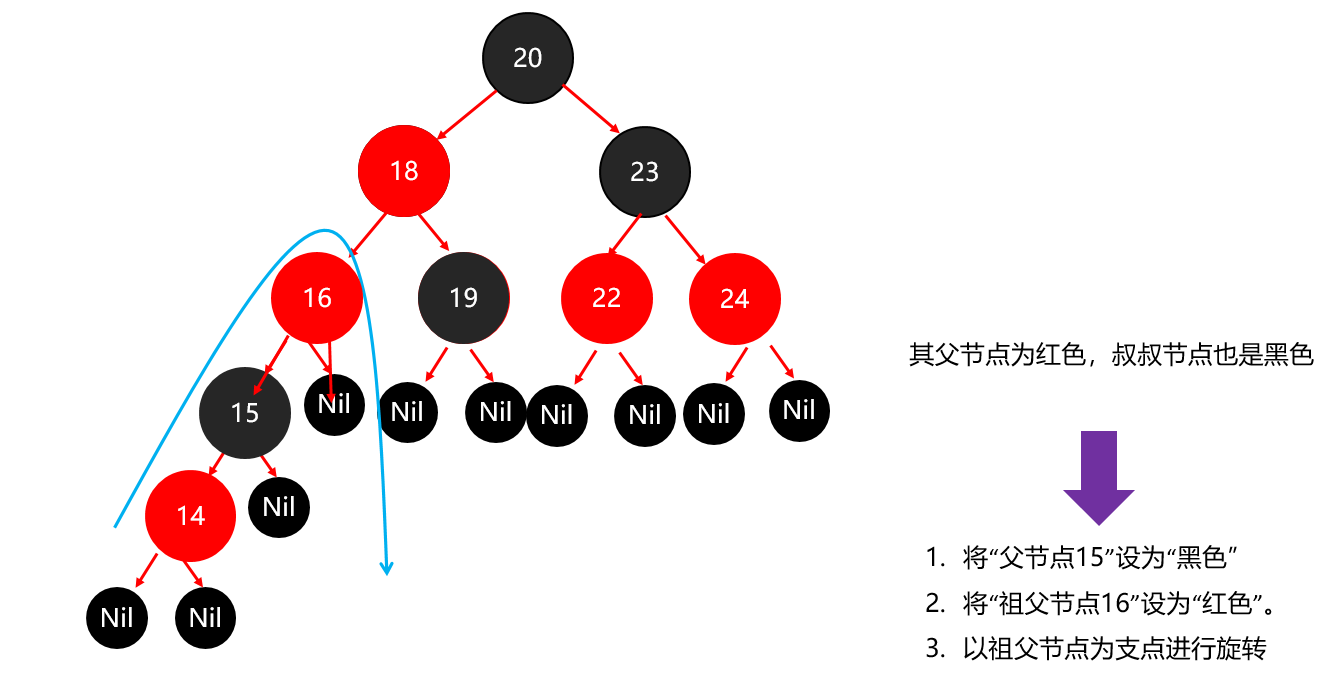
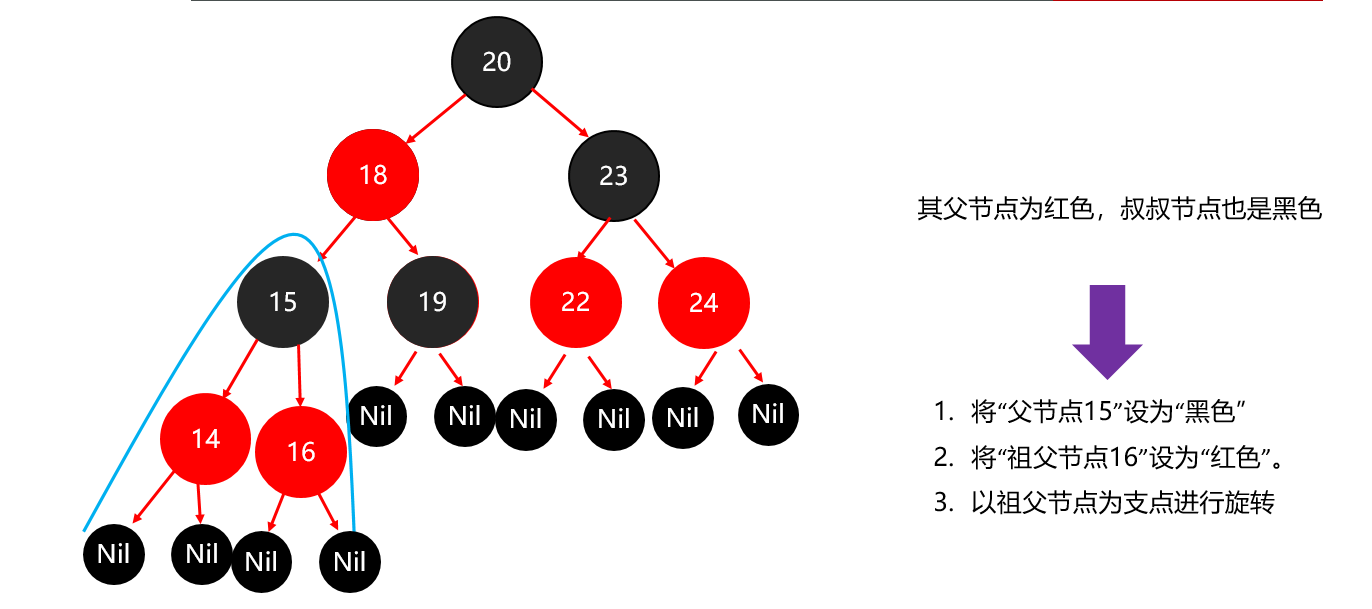
红黑树小结 红黑树不是高度平衡的,它的平衡是通过"红黑规则"进行实现的 规则如下: 每一个节点或是红色的,或者是黑色的,根节点必须是黑色 如果一个节点没有子节点或者父节点,则该节点相应的指针属性值为Nil,这些Nil视为叶节点,每个叶节点(Nil)是黑色的; 如果某一个节点是红色,那么它的子节点必须是黑色(不能出现两个红色节点相连的情况) 对每一个节点,从该节点到其所有后代叶节点的简单路径上,均包含相同数目的黑色节点。 红黑树增删改查的性能都很好 各种数据结构的特点和作用是什么样的 队列:先进先出,后进后出。 栈:后进先出,先进后出。 数组:内存连续区域,查询快,增删慢。 链表:元素是游离的,查询慢,首尾操作极快。 二叉树:永远只有一个根节点, 每个结点不超过2个子节点的树。 查找二叉树:小的左边,大的右边,但是可能树很高,查询性能变差。 平衡查找二叉树:让树的高度差不大于1,增删改查都提高了。 红黑树(就是基于红黑规则实现了自平衡的排序二叉树
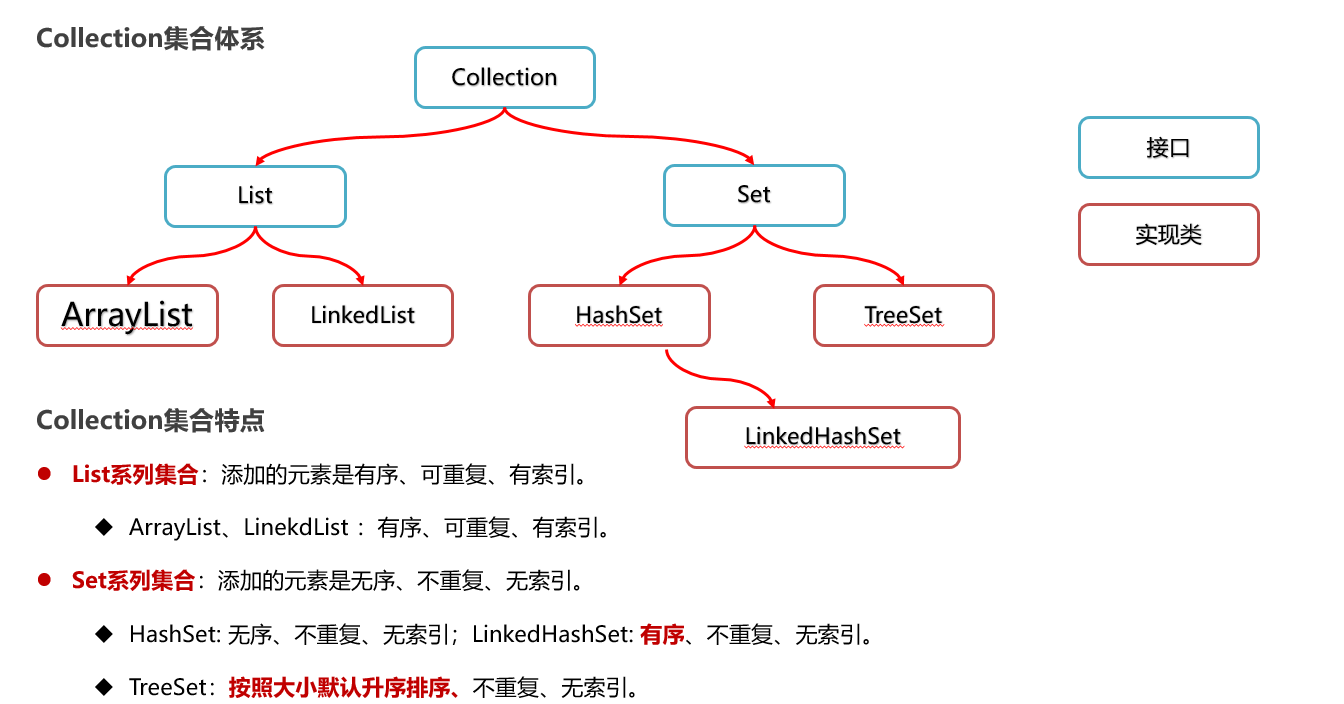
12:List 集合体系
List系列集合特点:
ArrayList、LinekdList :有序【添加顺序,有索引】,可重复,有索引
有序:存储和取出的元素顺序一致
有索引:可以通过索引操作元素
可重复:存储的元素可以重复
ArrayList:底层是基于数组实现的,根据索引定位快,增删相对慢
LinekList:底层是基于双链表实现的,元素查询慢,增删首位元素非常快
List集合特有方法 List集合因为支持索引,所以多了很多索引操作的独特api,其他Collection的功能List也都继承了。
void add(int index,E element) 在此集合中的指定位置插入指定的元素 E remove(int index) 删除指定索引处的元素,返回被删除的元素 E set(int index,E element) 修改指定索引处的元素,返回被修改的元素 E get(int index) 返回指定索引处的元素
package com.itheima.d5_collection_list; import java.util.ArrayList; import java.util.Collection; import java.util.LinkedList; import java.util.List; /** 目标:ArrayList集合。 Collection集合的体系 Collection<E>(接口) / \ Set<E>(接口) List<E>(接口) / \ / \ \ HashSet<E>(实现类) TreeSet<E>(实现类) LinkedList<E>(实现类) Vector(线程安全) ArrayList<E>(实现类) / LinkedHashSet<E>(实现类) Collection集合体系的特点: Set系列集合: 添加的元素,是无序,不重复,无索引的。 -- HashSet:添加的元素,是无序,不重复,无索引的。 -- LinkedHashSet:添加的元素,是有序,不重复,无索引的。 List系列集合:添加的元素,是有序,可重复,有索引的。 -- LinkedList: 添加的元素,是有序,可重复,有索引的。 -- ArrayList: 添加的元素,是有序,可重复,有索引的。 -- Vector 是线程安全的,速度慢,工作中很少使用。 1、List集合继承了Collection集合的全部功能,"同时因为List系列集合有索引", 2、因为List集合多了索引,所以多了很多按照索引操作元素的功能: 3、ArrayList实现类集合底层基于数组存储数据的,查询快,增删慢! - public void add(int index, E element): 将指定的元素,添加到该集合中的指定位置上。 - public E get(int index):返回集合中指定位置的元素。 - public E remove(int index): 移除列表中指定位置的元素, 返回的是被移除的元素。 - public E set(int index, E element):用指定元素替换集合中指定位置的元素,返回更新前的元素值。 小结: ArrayList集合的底层是基于数组存储数据。查询快,增删慢!(相对的) */ public class ListDemo01 { public static void main(String[] args) { // 1.创建一个ArrayList集合对象: // List:有序,可重复,有索引的。 ArrayList<String> list = new ArrayList<>(); // 一行经典代码! list.add("Java"); list.add("Java"); list.add("HTML"); list.add("HTML"); list.add("MySQL"); list.add("MySQL"); // 2.在某个索引位置插入元素。 list.add(2, "黑马"); System.out.println(list); // 3.根据索引删除元素,返回被删除元素 System.out.println(list.remove(1)); System.out.println(list); // 4.根据索引获取元素:public E get(int index):返回集合中指定位置的元素。 System.out.println(list.get(1)); // 5.修改索引位置处的元素: public E set(int index, E element) System.out.println(list.set(1, "传智教育")); System.out.println(list); } }
List集合遍历方式:
迭代器
增强for循环
Lambda表达式
for循环(因为List集合存在索引)
package com.itheima.d5_collection_list; import java.util.ArrayList; import java.util.Iterator; import java.util.List; /** 拓展:List系列集合的遍历方式有:4种。 List系列集合多了索引,所以多了一种按照索引遍历集合的for循环。 List遍历方式: (1)for循环。(独有的,因为List有索引)。 (2)迭代器。 (3)foreach。 (4)JDK 1.8新技术。 */ public class ListDemo02 { public static void main(String[] args) { List<String> lists = new ArrayList<>(); lists.add("java1"); lists.add("java2"); lists.add("java3"); /** (1)for循环。 */ System.out.println("-----------------------"); for (int i = 0; i < lists.size(); i++) { String ele = lists.get(i); System.out.println(ele); } /** (2)迭代器。 */ System.out.println("-----------------------"); Iterator<String> it = lists.iterator(); while (it.hasNext()){ String ele = it.next(); System.out.println(ele); } /** (3)foreach */ System.out.println("-----------------------"); for (String ele : lists) { System.out.println(ele); } /** (4)JDK 1.8开始之后的Lambda表达式 */ System.out.println("-----------------------"); lists.forEach(s -> { System.out.println(s); }); } }
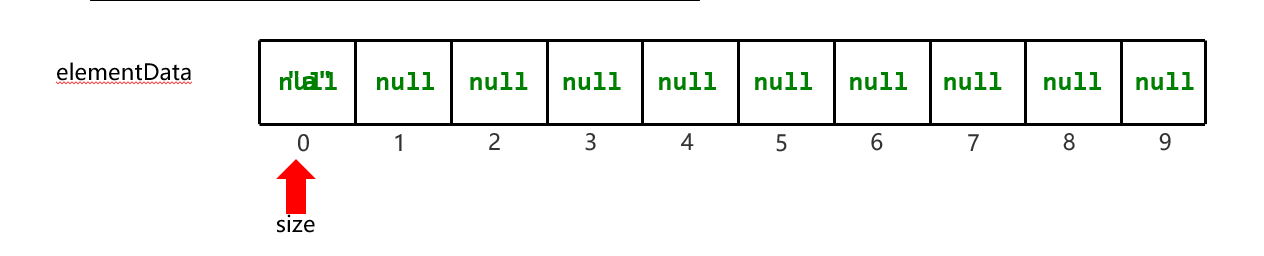
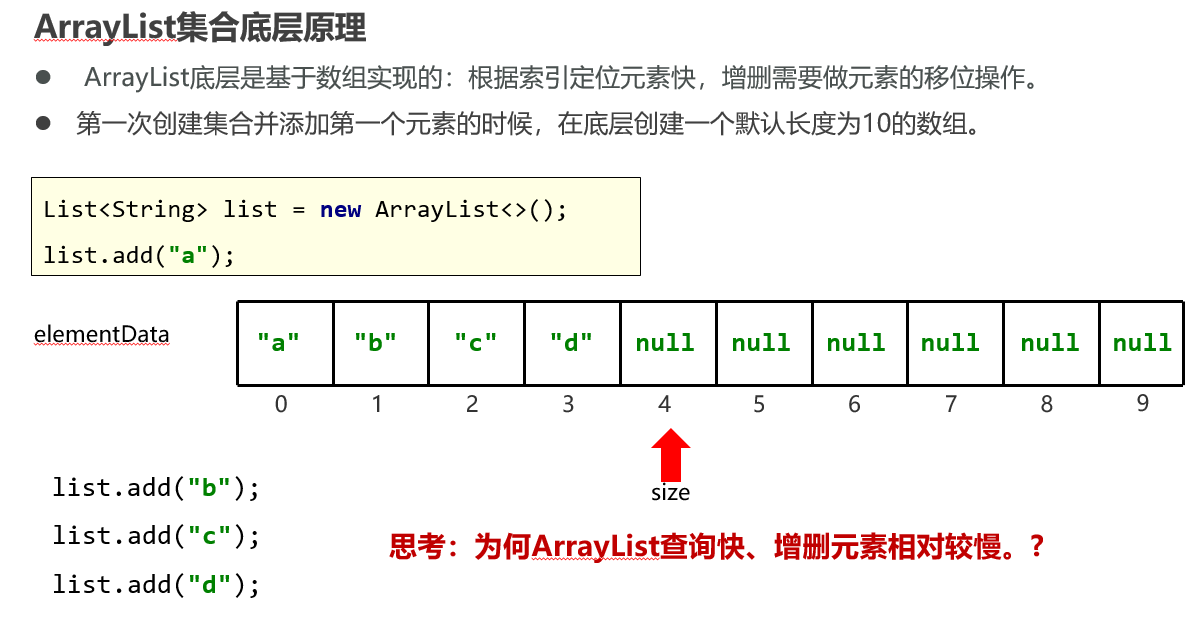
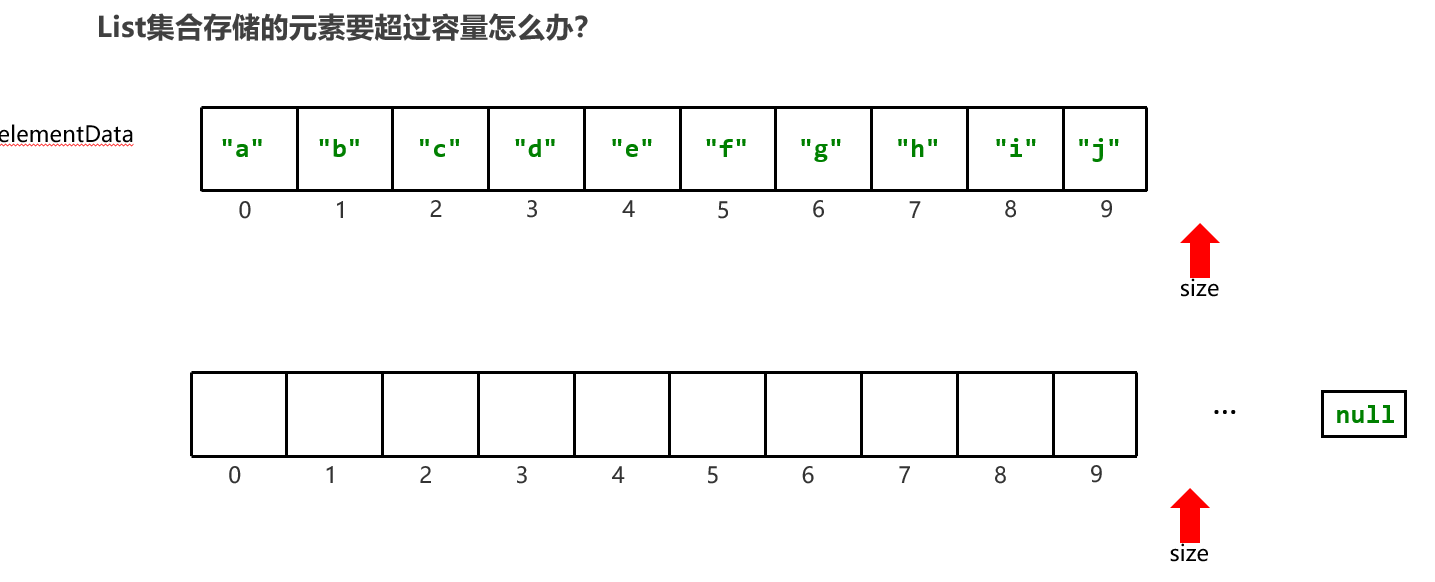
ArrayList集合底层原理: ArrayList底层是基于数组实现的:根据索引定位元素快,增删需要做元素的移位操作。 第一次创建集合并添加第一个元素的时候,在底层创建一个默认长度为10的数组。 List<String> list = new ArrayList<>(); list.add("a");
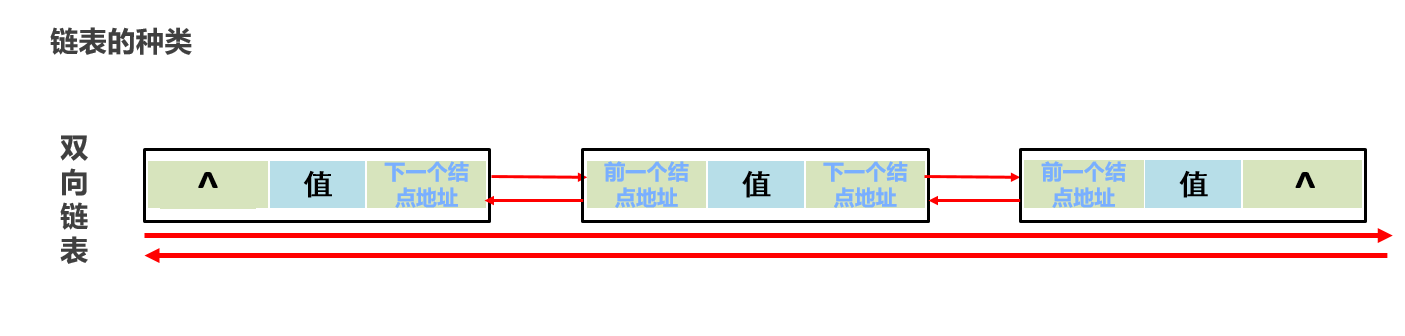
LinkedList的特点: 底层数据结构是双链表,查询慢,首尾操作的速度是极快的,所以多了很多首尾操作的特有API。
LinkedList集合的特有功能: public void addFirst(E e) 在该列表开头插入指定的元素 public void addLast(E e) 将指定的元素追加到此列表的末尾 public E getFirst() 返回此列表中的第一个元素 public E getLast() 返回此列表中的最后一个元素 public E removeFirst() 从此列表中删除并返回第一个元素 public E removeLast() 从此列表中删除并返回最后一个元素
package com.itheima.d5_collection_list; import java.util.LinkedList; import java.util.List; /** 目标:LinkedList集合。 Collection集合的体系: Collection<E>(接口) / \ Set<E>(接口) List<E>(接口) / / \ \ HashSet<E>(实现类) LinkedList<E>(实现类) Vector(实现类) ArrayList<E>(实现类) / LinkedHashSet<E>(实现类) Collection集合体系的特点: Set系列集合: 添加的元素,是无序,不重复,无索引的。 -- HashSet:添加的元素,是无序,不重复,无索引的。 -- LinkedHashSet:添加的元素,是有序,不重复,无索引的。 List系列集合:添加的元素,是有序,可重复,有索引的。 -- LinkedList: 添加的元素,是有序,可重复,有索引的。 -- Vector: 添加的元素,是有序,可重复,有索引的。线程安全(淘汰了) -- ArrayList: 添加的元素,是有序,可重复,有索引的。 LinkedList也是List的实现类:底层是基于双链表的,增删比较快,查询慢!! LinkedList是支持双链表,定位前后的元素是非常快的,增删首尾的元素也是最快的 所以LinkedList除了拥有List集合的全部功能还多了很多操作首尾元素的特殊功能: - public void addFirst(E e):将指定元素插入此列表的开头。 - public void addLast(E e):将指定元素添加到此列表的结尾。 - public E getFirst():返回此列表的第一个元素。 - public E getLast():返回此列表的最后一个元素。 - public E removeFirst():移除并返回此列表的第一个元素。 - public E removeLast():移除并返回此列表的最后一个元素。 - public E pop():从此列表所表示的堆栈处弹出一个元素。 - public void push(E e):将元素推入此列表所表示的堆栈。 小结: LinkedList是支持双链表,定位前后的元素是非常快的,增删首尾的元素也是最快的。 所以提供了很多操作首尾元素的特殊API可的实以做栈和队列现。 如果查询多而增删少用ArrayList集合。(用的最多的) 如果查询少而增删首尾较多用LinkedList集合。 */ public class ListDemo03 { public static void main(String[] args) { // LinkedList可以完成队列结构,和栈结构 (双链表) // 1、做一个队列: LinkedList<String> queue = new LinkedList<>(); // 入队 queue.addLast("1号"); queue.addLast("2号"); queue.addLast("3号"); System.out.println(queue); // 出队 // System.out.println(queue.getFirst()); System.out.println(queue.removeFirst()); System.out.println(queue.removeFirst()); System.out.println(queue); // 2、做一个栈 LinkedList<String> stack = new LinkedList<>(); // 入栈 压栈 (push) 就是包装了一层 addfrist 操作 stack.push("第1颗子弹"); stack.push("第2颗子弹"); stack.push("第3颗子弹"); stack.push("第4颗子弹"); System.out.println(stack); // 出栈 弹栈 pop System.out.println(stack.pop()); System.out.println(stack.pop()); System.out.println(stack.pop()); System.out.println(stack); } }
13:集合的并发修改异常问题
从集合中的一批元素中找出某些数据并删除,如何操作?是否存在问题呢 ?
问题引出:
当我们从集合中找出某个元素并删除的时候可能出现一种并发修改异常问题。
哪些遍历存在问题?
迭代器遍历集合且直接用集合删除元素的时候可能出现。
增强for循环遍历集合且直接用集合删除元素的时候可能出现。
哪种遍历且删除元素不出问题
迭代器遍历集合但是用迭代器自己的删除方法操作可以解决。
使用for循环遍历并删除元素不会存在这个问题。【从后往前遍历删除】
package com.itheima.d6_collection_update_delete; import java.util.ArrayList; import java.util.Iterator; import java.util.List; /** 目标:研究集合遍历并删除元素可能出现的:并发修改异常问题。 */ public class Test { public static void main(String[] args) { // 1、准备数据 ArrayList<String> list = new ArrayList<>(); list.add("黑马"); list.add("Java"); list.add("Java"); list.add("赵敏"); list.add("赵敏"); list.add("素素"); System.out.println(list); // [黑马, Java, Java, 赵敏, 赵敏, 素素] // it // 需求:删除全部的Java信息。 // a、迭代器遍历删除 Iterator<String> it = list.iterator(); // while (it.hasNext()){ // String ele = it.next(); // if("Java".equals(ele)){ // // 删除Java // // list.remove(ele); // 集合删除会出毛病【报错,删除后指针前移,跳过第二个java,导致第二个没有删除成功,源码抛出这种报错】 // it.remove(); // 删除迭代器所在位置的元素值(没毛病)【源码内部会维护,每次删除后游标不会跳到下一个元素】【两个java都会被删除】 // } // } // System.out.println(list); // b、foreach遍历删除 (会出现问题,这种无法解决的,foreach不能边遍历边删除,会出bug)【这种也会报错,底层也是迭代器遍历,但是迭代器藏起来了取不到,无法解决】 // for (String s : list) { // if("Java".equals(s)){ // list.remove(s); // } // } // c、lambda表达式(会出现问题,这种无法解决的,Lambda遍历不能边遍历边删除,会出bug)lambda底层也是迭代器,也无法解决这种报错 // list.forEach(s -> { // if("Java".equals(s)){ // list.remove(s); // } // }); // d、for循环(边遍历边删除集合没毛病,但是必须从后面开始遍历删除才不会出现漏掉应该删除的元素) for (int i = list.size() - 1; i >= 0 ; i--) { String ele = list.get(i); if("Java".equals(ele)){ list.remove(ele); } } System.out.println(list); } }
14:泛型深入了解
泛型概述: 泛型:是JDK5中引入的特性,可以在编译阶段约束操作的数据类型,并进行检查。 泛型的格式:<数据类型>; 注意:泛型只能支持引用数据类型。 集合体系的全部接口和实现类都是支持泛型的使用的。 泛型的好处: 统一数据类型。 把运行时期的问题提前到了编译期间,避免了强制类型转换可能出现的异常,因为编译阶段类型就能确定下来。 泛型可以在很多地方进行定义: 类后面 泛型类 方法申明上 泛型方法 接口后面 泛型接口
package com.itheima.d7_genericity; import java.util.ArrayList; import java.util.List; /** 目标:泛型的概述。 什么是泛型? 泛型就是一个标签:<数据类型> 泛型可以在编译阶段约束只能操作某种数据类型。 注意: JDK 1.7开始之后后面的泛型申明可以省略不写 小结: 泛型就是一个标签。 泛型可以在编译阶段约束只能操作某种数据类型。 泛型只能支持引用数据类型。 */ public class GenericityDemo { public static void main(String[] args) { List<String> list = new ArrayList<>(); list.add("Java"); list.add("Java2"); // list.add(23); List<String> list1 = new ArrayList(); list1.add("Java"); // list1.add(23.3); // list1.add(false); list1.add("Spring"); // for (Object o : list1) { // String ele = (String) o;// 因为list1假设存储了各种类型,字符串,浮点型,这里需要string进行强转【强转风险,可能强转不了,double转不了String】
//【使用泛型,编译阶段定死数据类型,后面不存在强转问题,如下面直接接收String,识别全部都是字符串】 // System.out.println(ele); // } for (String s : list1) { System.out.println(s); } System.out.println("---------------------"); // 存储任意类型的元素【开发规范,就算存储的是各种类型数据也需要带 object 泛型,运行时候不需要检测类型,优化性能】 List<Object> list2 = new ArrayList<>(); list2.add(23); list2.add(23.3); list2.add("Java"); // List<int> list3 = new ArrayList<>(); // 不支持基本数据类型,只支持引用数据类型 List<Integer> list3 = new ArrayList<>(); } }
15:自定义泛型类
泛型类的概述: 定义类时同时定义了泛型的类就是泛型类。 泛型类的格式:修饰符 class 类名<泛型变量>{ } 范例:public class MyArrayList<T> { } 此处泛型变量T可以随便写为任意标识,常见的如E、T、K、V等。 作用:编译阶段可以指定数据类型,类似于集合的作用。 课程案例导学: 模拟ArrayList集合自定义一个集合MyArrayList集合,完成添加和删除功能的泛型设计即可。 泛型类的原理: 把出现泛型变量的地方全部替换成传输的真实数据类型。 1、泛型类的核心思想: 把出现泛型变量的地方全部替换成传输的真实数据类型 2、泛型类的作用 编译阶段约定操作的数据的类型,类似于集合的作用。
MyArrayList<String> list = new MyArrayList<>(); 初始化的时候把 String这个参数传递给类的 E 变量了
后面的方法 public void add(E e){ 自然固定了需要传递 String类型参数,因为E是String 【只能操作字符串了】
package com.itheima.d8_genericity_class; import java.util.ArrayList; public class Test { public static void main(String[] args) { // 需求:模拟ArrayList定义一个MyArrayList ,关注泛型设计 MyArrayList<String> list = new MyArrayList<>(); list.add("Java"); list.add("Java"); list.add("MySQL"); list.remove("MySQL"); System.out.println(list); MyArrayList<Integer> list2 = new MyArrayList<>(); list2.add(23); list2.add(24); list2.add(25); list2.remove(25); System.out.println(list2); } } class MyArrayList<E> { private ArrayList lists = new ArrayList(); public void add(E e){ lists.add(e); } public void remove(E e){ lists.remove(e); } @Override public String toString() { return lists.toString(); } }
15:自定义泛型 方法
泛型方法的概述: 定义方法时同时定义了泛型的方法就是泛型方法。 泛型方法的格式:修饰符 <泛型变量> 方法返回值 方法名称(形参列表){} public <T> void show(T t) { } 作用:方法中可以使用泛型接收一切实际类型的参数,方法更具备通用性。 课程案例导学: 给你任何一个类型的数组,都能返回它的内容。也就是实现Arrays.toString(数组)的功能! 泛型方法的原理: 把出现泛型变量的地方全部替换成传输的真实数据类型。 1、泛型方法的核心思想: 把出现泛型变量的地方全部替换成传输的真实数据类型 2、泛型方法的作用 方法中可以使用泛型接收一切实际类型的参数,方法更具备通用性
package com.itheima.d9_genericity_method; /** 目标:自定义泛型方法。 什么是泛型方法? 定义了泛型的方法就是泛型方法。 泛型方法的定义格式: 修饰符 <泛型变量> 返回值类型 方法名称(形参列表){ } 注意:方法定义了是什么泛型变量,后面就只能用什么泛型变量。 泛型类的核心思想:是把出现泛型变量的地方全部替换成传输的真实数据类型。 需求:给你任何一个类型的数组,都能返回它的内容。Arrays.toString(数组)的功能! 小结: 泛型方法可以让方法更灵活的接收数据,可以做通用技术! */ public class GenericDemo { public static void main(String[] args) { String[] names = {"小璐", "蓉容", "小何"}; printArray(names); Integer[] ages = {10, 20, 30}; printArray(ages); Integer[] ages2 = getArr(ages); String[] names2 = getArr(names); } public static <T> T[] getArr(T[] arr){ // 直接返回数组,返回这个T类型数据 void 替换成 T[],这样返回什么类型的数据不需要强转,直接传递就行 return arr; } public static <T> void printArray(T[] arr){ // T:接收一切类型的数组【这里的泛型表示接收一切类型的数组】【外部传进来是啥就算啥类型】 if(arr != null){ StringBuilder sb = new StringBuilder("["); for (int i = 0; i < arr.length; i++) { sb.append(arr[i]).append(i == arr.length - 1 ? "" : ", "); } sb.append("]"); System.out.println(sb); }else { System.out.println(arr); } } }
16:自定义 泛型 接口
泛型接口的概述: 使用了泛型定义的接口就是泛型接口。 泛型接口的格式:修饰符 interface 接口名称<泛型变量>{} 范例: public interface Data<E>{} 作用:泛型接口可以让实现类选择当前功能需要操作的数据类型 课程案例导学 教务系统,提供一个接口可约束一定要完成数据(学生,老师)的增删改查操作 泛型接口的原理: 实现类可以在实现接口的时候传入自己操作的数据类型,这样重写的方法都将是针对于该类型的操作。 1、泛型接口的作用 泛型接口可以约束实现类,实现类可以在实现接口的时候传入自己操作的数据类型这样重写的方法都将是针对于该类型的操作
泛型接口:约定实现类的功能,而且同时可以由实现类具体增删改查操作的数据类型
如下:TeacherData 类实例化后只能 add 操作 Teacher 类型的的数据
package com.itheima.d10_genericity_interface; public interface Data<E> { void add(E e); // 使用泛型接口,可以添加任何类型,老师类型,学生类型,而不是固定某个类型 void delete(int id); void update(E e); E queryById(int id); }
package com.itheima.d10_genericity_interface; public class StudentData implements Data<Student>{ @Override public void add(Student student) { } @Override public void delete(int id) { } @Override public void update(Student student) { } @Override public Student queryById(int id) { return null; } }
package com.itheima.d10_genericity_interface; public class TeacherData implements Data<Teacher>{ // 泛型传递 老师类型 @Override public void add(Teacher teacher) { } @Override public void delete(int id) { } @Override public void update(Teacher teacher) { } @Override public Teacher queryById(int id) { return null; } }
package com.itheima.d10_genericity_interface; public class Teacher { }
package com.itheima.d10_genericity_interface; public class Student { }
17:泛型 的通配符 ,上下限
泛型通配符:案例导学: 开发一个极品飞车的游戏,所有的汽车都能一起参与比赛。 通配符:? ? 可以在“使用泛型”的时候代表一切类型。 E T K V 是在定义泛型的时候使用的。 虽然BMW和BENZ都继承了Car但是ArrayList<BMW>和ArrayList<BENZ>与ArrayList<Car>没有关系的!! 泛型的上下限: ? extends Car: ?必须是Car或者其子类 泛型上限 ? super Car : ?必须是Car或者其父类 泛型下限
package com.itheima.d11_genericity_limit; import java.util.ArrayList; /** 目标:泛型通配符。? 需求:开发一个极品飞车的游戏,所有的汽车都能一起参与比赛。 注意: 虽然BMW和BENZ都继承了Car 但是ArrayList<BMW>和ArrayList<BENZ>与ArrayList<Car>没有关系的!! 通配符:? ?可以在“使用泛型”的时候代表一切类型。 E T K V 是在定义泛型的时候使用的。 泛型的上下限: ? extends Car : ?必须是Car或者其子类 泛型上限 ? super Car :?必须是Car或者其父类 泛型下限 小结: 通配符:? ?可以在“使用泛型”的时候代表一切类型。 */ public class GenericDemo { public static void main(String[] args) { ArrayList<BMW> bmws = new ArrayList<>(); bmws.add(new BMW()); bmws.add(new BMW()); bmws.add(new BMW()); go(bmws); ArrayList<BENZ> benzs = new ArrayList<>(); benzs.add(new BENZ()); benzs.add(new BENZ()); benzs.add(new BENZ()); go(benzs); ArrayList<Dog> dogs = new ArrayList<>(); dogs.add(new Dog()); dogs.add(new Dog()); dogs.add(new Dog()); // go(dogs); } /** 所有车比赛
这里 的 泛型传递car类型也不能处理 BENZ 和 BMW 两种类型的数据:
宝马和奔驰虽然是Car的子类,但是现在不是作为独立参数类型,而是一个ArrayList集合组成的二元类型,宝马的集合,奔驰的集合
不是单独的奔驰和宝马, ArrayList<BMW> 和 ArrayList<BENZ> 和 ArrayList<Car> 三者没有关系【三种不同类型】,就算 BMW是Car的子类
*/ public static void go(ArrayList<? extends Car> cars){ } } class Dog{ } class BENZ extends Car{ } class BMW extends Car{ } // 父类 class Car{ }
18:Set 类型集合
Set系列集合特点:
无序:存取顺序不一致
不重复:可以去除重复
无索引:没有带索引的方法,所以不能使用普通for循环遍历,也不能通过索引来获取元素
Set集合实现类特点:
HashSet : 无序、不重复、无索引。
LinkedHashSet:有序【添加顺序,先加的元素在前面,后加的元素在后面】、不重复、无索引
TreeSet:排序【默认大小升序排序】、不重复、无索引。
Set集合的功能上基本上与Collection的API一致。
package com.itheima.d1_collection_set; import java.util.HashSet; import java.util.Set; public class SetDemo1 { public static void main(String[] args) { // 看看Set系列集合的特点: HashSet LinkedHashSet TreeSet // Set<String> sets = new HashSet<>(); // 一行经典代码 无序不重复,无索引 // Set<String> sets = new LinkedHashSet<>(); // 有序 不重复 无索引 sets.add("MySQL"); sets.add("MySQL"); sets.add("Java"); sets.add("Java"); sets.add("HTML"); sets.add("HTML"); sets.add("SpringBoot"); sets.add("SpringBoot"); System.out.println(sets); } }
19:HashSet 类型集合
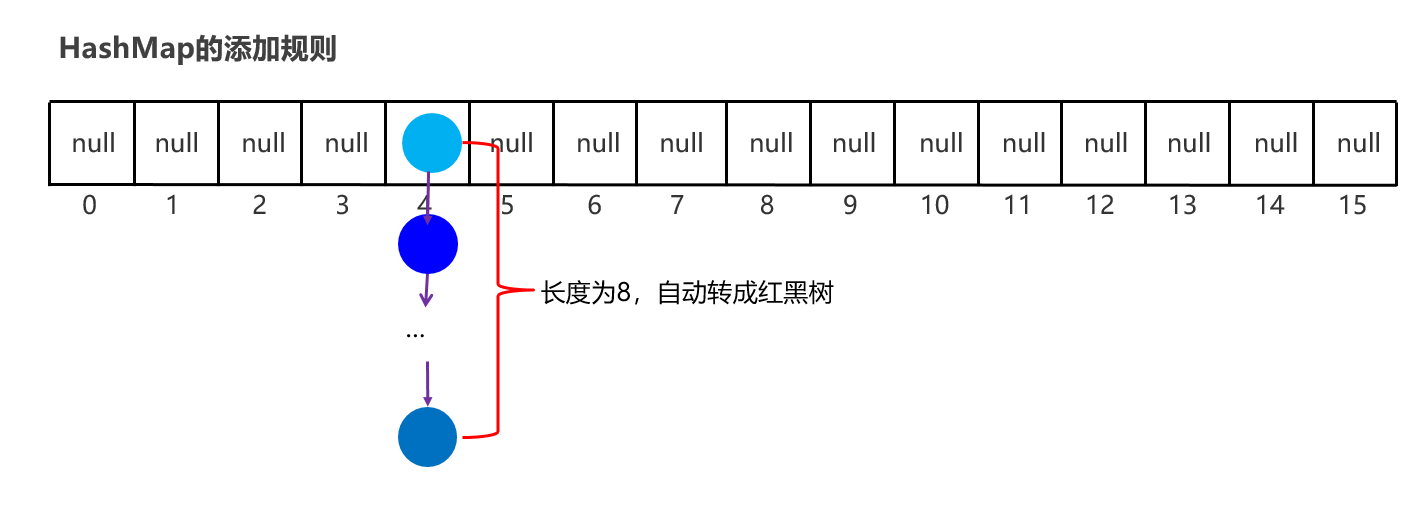
HashSet底层原理: HashSet集合底层采取 哈希表 存储的数据。 哈希表是一种对于增删改查数据性能都较好的结构。 哈希表的组成: JDK8之前的,底层使用数组+链表组成 JDK8开始后,底层采用数组+链表+红黑树组成。 在了解哈希表之前需要先理解哈希值的概念: 哈希值:是JDK根据对象的地址,按照某种规则算出来的int类型的数值。【地址 映射成整形的值来给我们用】【每个对象都有地址,所以每个对象都有hash值】 Object类的API public int hashCode():返回对象的哈希值 对象的哈希值特点: 同一个对象多次调用hashCode()方法返回的哈希值是相同的 默认情况下,不同对象的哈希值是不同的。
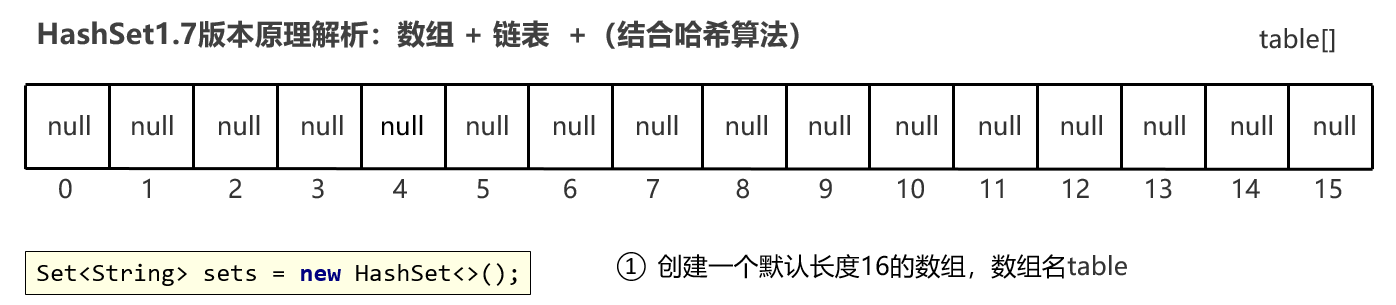



JDK1.8版本开始HashSet原理解析
底层结构:哈希表(数组、链表、红黑树的结合体)
当挂在元素下面的数据过多时,查询性能降低,从JDK8开始后,当链表长度超过8的时候,自动转换为红黑树
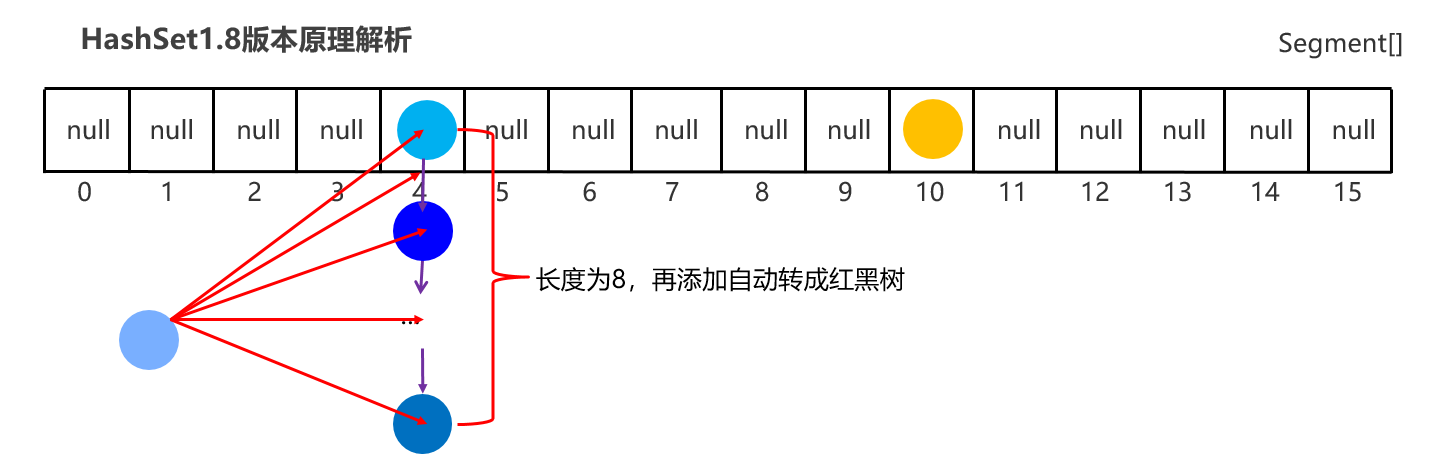
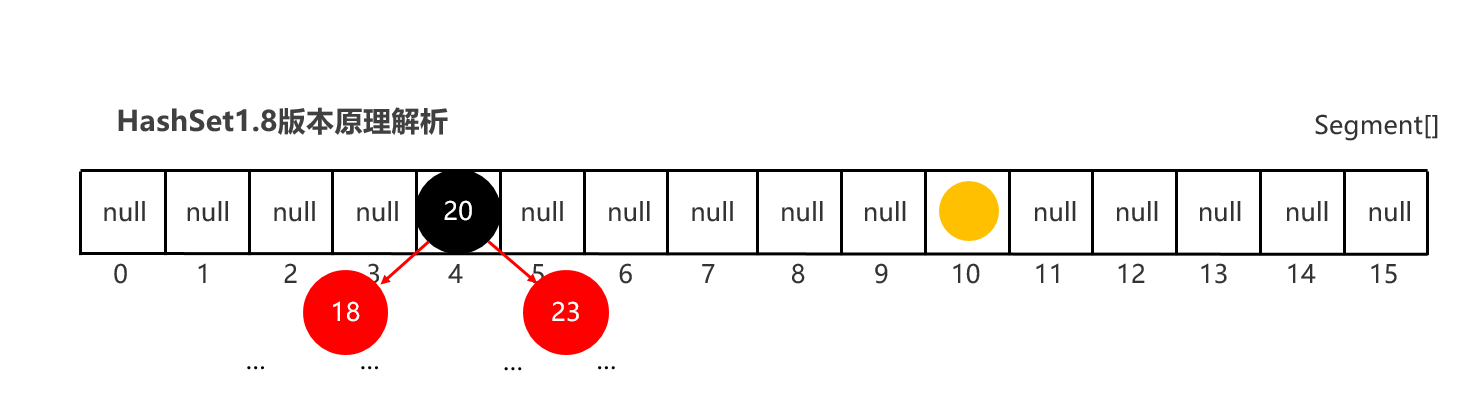
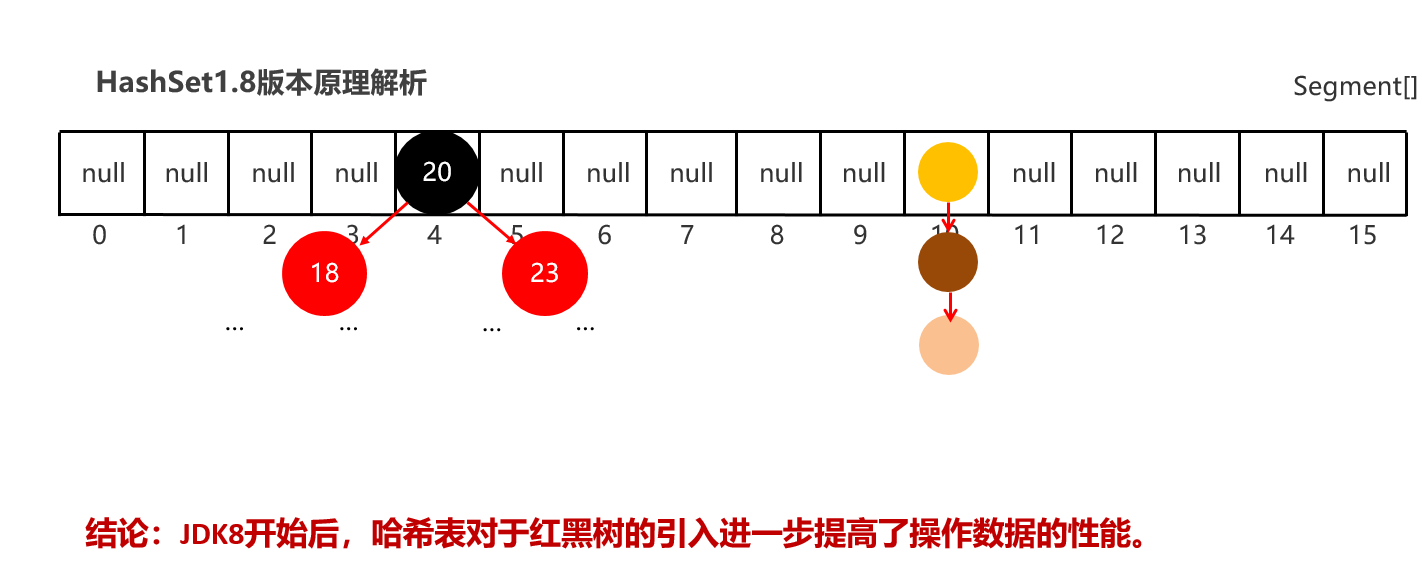
1:Set集合的底层原理是什么样的 JDK8之前的,哈希表:底层使用数组+链表组成 JDK8开始后,哈希表:底层采用数组+链表+红黑树组成。 2:哈希表的详细流程 创建一个默认长度16,默认加载因为0.75的数组,数组名table 根据元素的哈希值跟数组的长度计算出应存入的位置 判断当前位置是否为null,如果是null直接存入,如果位置不为null,表示有元素, 则调用equals方法比较属性值,如果一样,则不存,如果不一样,则存入数组。 当数组存满到16*0.75=12时,就自动扩容,每次扩容原先的两倍
20:HashSet 类型集合去重复原理解析
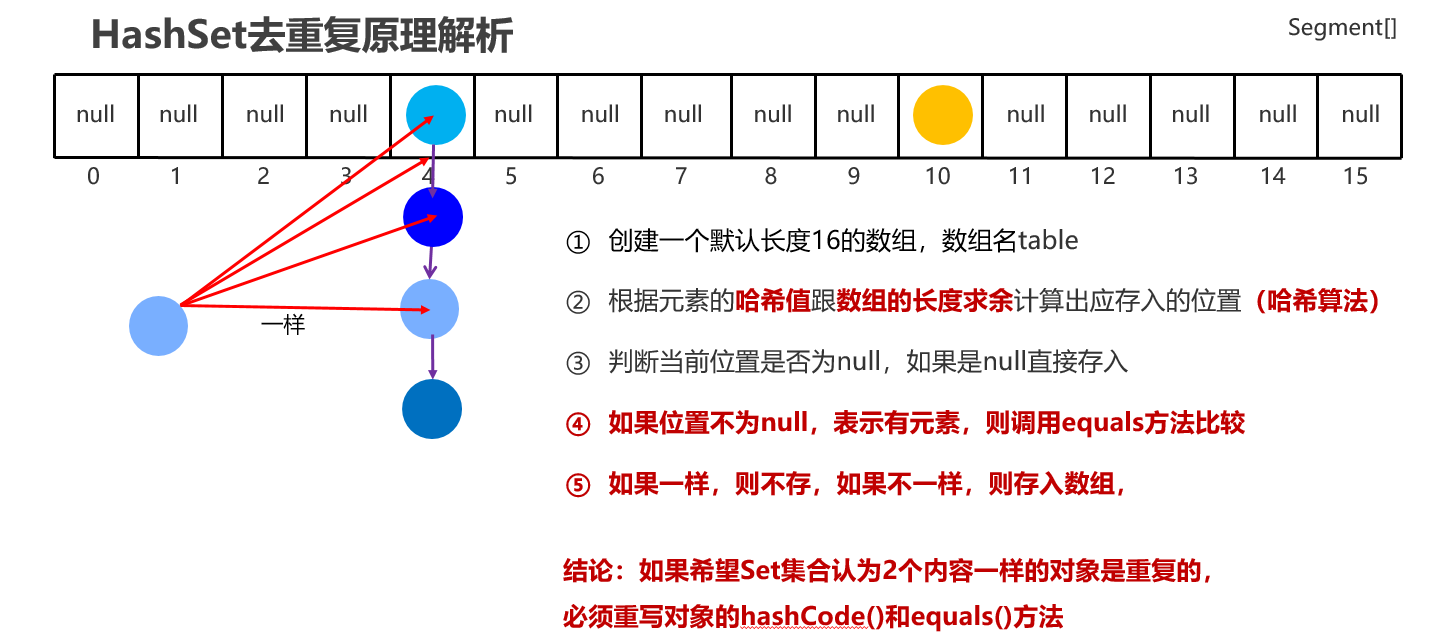

package com.itheima.d1_collection_set; import java.util.Objects; public class Student { private String name; private int age; private char sex; public Student() { } public Student(String name, int age, char sex) { this.name = name; this.age = age; this.sex = sex; } public String getName() { return name; } public void setName(String name) { this.name = name; } public int getAge() { return age; } public void setAge(int age) { this.age = age; } public char getSex() { return sex; } public void setSex(char sex) { this.sex = sex; } /** 只要2个对象内容一样,结果一定是true * @param o * @return */ @Override public boolean equals(Object o) { if (this == o) return true; if (o == null || getClass() != o.getClass()) return false; Student student = (Student) o; return age == student.age && sex == student.sex && Objects.equals(name, student.name); } /** s1 = new Student("无恙", 20, '男') s2 = new Student("无恙", 20, '男') s3 = new Student("周雄", 21, '男') */ @Override public int hashCode() { return Objects.hash(name, age, sex); } @Override public String toString() { return "Student{" + "name='" + name + '\'' + ", age=" + age + ", sex=" + sex + '}'; } }
package com.itheima.d1_collection_set; import java.util.HashSet; import java.util.Set; /** 目标:让Set集合把重复内容的对象去掉一个(去重复) */ public class SetDemo3 { public static void main(String[] args) { // Set集合去重复原因:先判断哈希值算出来的存储位置是否相同 再判断equals Set<Student> sets = new HashSet<>(); Student s1 = new Student("无恙", 20, '男'); Student s2 = new Student("无恙", 20, '男'); Student s3 = new Student("周雄", 21, '男'); System.out.println(s1.hashCode()); System.out.println(s2.hashCode()); System.out.println(s3.hashCode()); sets.add(s1); sets.add(s2); sets.add(s3); System.out.println(sets); } }
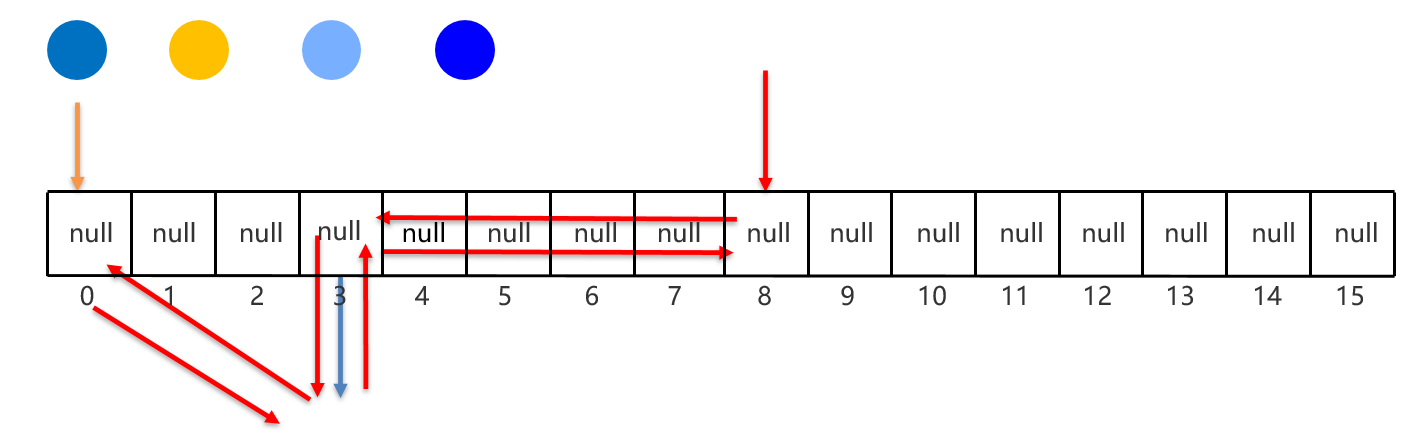
21:LinkedHashSet 实现类
LinkedHashSet集合概述和特点
有序、不重复、无索引。
这里的有序指的是保证存储和取出的元素顺序一致
原理:底层数据结构是依然哈希表,只是每个元素又额外的多了一个双链表的机制记录存储的顺序
每个元素需要记录位置信息
package com.itheima.d1_collection_set; import java.util.LinkedHashSet; import java.util.Set; public class SetDemo4 { public static void main(String[] args) { // 看看Set系列集合的特点: HashSet LinkedHashSet TreeSet Set<String> sets = new LinkedHashSet<>(); // 有序 不重复 无索引 sets.add("MySQL"); sets.add("MySQL"); sets.add("Java"); sets.add("Java"); sets.add("HTML"); sets.add("HTML"); sets.add("SpringBoot"); sets.add("SpringBoot"); System.out.println(sets); }
22:TreeSet 集合 排序
TreeSet集合概述和特点:
不重复、无索引、可排序
可排序:按照元素的大小默认升序(有小到大)排序。
TreeSet集合底层是基于红黑树的数据结构实现排序的,增删改查性能都较好。
注意:TreeSet集合是一定要排序的,可以将元素按照指定的规则进行排序。
TreeSet集合默认的规则:
对于数值类型:Integer , Double,官方默认按照大小进行升序排序。
对于字符串类型:默认按照首字符的编号升序排序。
对于自定义类型如 Student 对象,TreeSet 无法直接排序。
结论:想要使用TreeSet存储自定义类型,需要制定排序规则
自定义排序规则:
TreeSet集合存储对象的的时候有2种方式可以设计自定义比较规则
方式一:
让自定义的类(如学生类)实现Comparable接口重写里面的compareTo方法来定制比较规则。
方式二:
TreeSet集合有参数构造器,可以设置Comparator接口对应的比较器对象,来定制比较规则。
两种方式中,关于返回值的规则:
如果认为第一个元素大于第二个元素返回正整数即可。
如果认为第一个元素小于第二个元素返回负整数即可。
如果认为第一个元素等于第二个元素返回0即可,此时Treeset集合只会保留一个元素,认为两者重复。
注意:如果TreeSet集合存储的对象有实现比较规则,集合也自带比较器,默认使用集合自带的比较器排序。
package com.itheima.d1_collection_set; import java.util.Set; import java.util.TreeSet; /** 目标:观察TreeSet对于有值特性的数据如何排序。 学会对自定义类型的对象进行指定规则排序 */ public class SetDemo5 { public static void main(String[] args) { Set<Integer> sets = new TreeSet<>(); // 不重复 无索引 可排序 sets.add(23); sets.add(24); sets.add(12); sets.add(8); System.out.println(sets); Set<String> sets1 = new TreeSet<>(); // 不重复 无索引 可排序 sets1.add("Java"); sets1.add("Java"); sets1.add("angela"); sets1.add("天马"); sets1.add("Java"); sets1.add("About"); sets1.add("Python"); sets1.add("UI"); sets1.add("UI"); System.out.println(sets1); System.out.println("------------------------------"); // 方式二:集合自带比较器对象进行规则定制 【优先使用集合自带的比较器,就近原则】 // // Set<Apple> apples = new TreeSet<>(new Comparator<Apple>() { // @Override // public int compare(Apple o1, Apple o2) { // // return o1.getWeight() - o2.getWeight(); // 升序 // // return o2.getWeight() - o1.getWeight(); // 降序 // // 注意:浮点型建议直接使用Double.compare进行比较 // // return Double.compare(o1.getPrice() , o2.getPrice()); // 升序 // return Double.compare(o2.getPrice() , o1.getPrice()); // 降序 // } // }); Set<Apple> apples = new TreeSet<>(( o1, o2) -> Double.compare(o2.getPrice() , o1.getPrice()) ); apples.add(new Apple("红富士", "红色", 9.9, 500)); apples.add(new Apple("青苹果", "绿色", 15.9, 300)); apples.add(new Apple("绿苹果", "青色", 29.9, 400)); apples.add(new Apple("黄苹果", "黄色", 9.8, 500)); System.out.println(apples); } }
package com.itheima.d1_collection_set; public class Apple implements Comparable<Apple>{ private String name; private String color; private double price; private int weight; public Apple() { } public Apple(String name, String color, double price, int weight) { this.name = name; this.color = color; this.price = price; this.weight = weight; } public String getName() { return name; } public void setName(String name) { this.name = name; } public String getColor() { return color; } public void setColor(String color) { this.color = color; } public double getPrice() { return price; } public void setPrice(double price) { this.price = price; } public int getWeight() { return weight; } public void setWeight(int weight) { this.weight = weight; } @Override public String toString() { return "Apple{" + "name='" + name + '\'' + ", color='" + color + '\'' + ", price=" + price + ", weight=" + weight + '}'; } /** 方式一:类自定义比较规则 o1.compareTo(o2) * @param o * @return */ @Override public int compareTo(Apple o) { // 按照重量进行比较的 return this.weight - o.weight ; // 去重重量重复的元素 // return this.weight - o.weight >= 0 ? 1 : -1; // 保留重量重复的元素 } }
1:TreeSet集合的特点是怎么样的? 可排序、不重复、无索引 底层基于红黑树实现排序,增删改查性能较好 2:TreeSet集合自定义排序规则有几种方式 2种。类实现Comparable接口,重写比较规则。 集合自定义Comparator比较器对象,重写比较规则。
23:Colection 体系特点,使用场景总结
1:如果希望元素可以重复,又有索引,索引查询要快? 用ArrayList集合,基于数组的。(用的最多) 2. 如果希望元素可以重复,又有索引,增删首尾操作快? 用LinkedList集合,基于【双】链表的。 3. 如果希望增删改查都快,但是元素不重复、无序、无索引。 用HashSet集合,基于哈希表的。 4. 如果希望增删改查都快,但是元素不重复、有序、无索引。 用LinkedHashSet集合,基于哈希表和双链表。 5. 如果要对对象进行排序。 用TreeSet集合,基于红黑树。后续也可以用List集合实现排序。
24:可变参数
可变参数 可变参数用在形参中可以接收多个数据。 可变参数的格式:数据类型 ... 参数名称 可变参数的作用: 接收参数非常灵活,方便。可以不接收参数,可以接收1个或者多个参数,也可以接收一个数组 可变参数在方法内部本质上就是一个数组。 可变参数的注意事项: 1.一个形参列表中可变参数只能有一个 2.可变参数必须放在形参列表的最后面

package com.itheima.d2_params; import java.util.Arrays; /** 目标:可变参数。 可变参数用在形参中可以接收多个数据。 可变参数的格式:数据类型...参数名称 可变参数的作用: 传输参数非常灵活,方便。 可以不传输参数。 可以传输一个参数。 可以传输多个参数。 可以传输一个数组。 可变参数在方法内部本质上就是一个数组。 可变参数的注意事项: 1.一个形参列表中可变参数只能有一个!! 2.可变参数必须放在形参列表的最后面!! 小结: 记住。 */ public class MethodDemo { public static void main(String[] args) { sum(); // 1、不传参数 sum(10); // 2、可以传输一个参数 sum(10, 20, 30); // 3、可以传输多个参数 sum(new int[]{10, 20, 30, 40, 50}); // 4、可以传输一个数组 } /** 注意:一个形参列表中只能有一个可变参数,可变参数必须放在形参列表的最后面 * @param nums */ public static void sum( int...nums){ // 注意:可变参数在方法内部其实就是一个数组。 nums System.out.println("元素个数:" + nums.length); System.out.println("元素内容:" + Arrays.toString(nums)); } }
25:集合工具类 Collections
Collections集合工具类: java.utils.Collections:是集合工具类 作用:Collections并不属于集合,是用来操作集合的工具类 Collections常用的API: public static <T> boolean addAll(Collection<? super T> c, T... elements) 给集合对象批量添加元素 public static void shuffle(List<?> list) 打乱List集合元素的顺序 Collections排序相关API:使用范围:只能对于List集合的排序 sort 排序方式1: public static <T> void sort(List<T> list) 将集合中元素按照默认规则排序 注意:本方式不可以直接对自定义类型的List集合排序,除非自定义类型实现了比较规则Comparable接口。 排序方式2: public static <T> void sort(List<T> list,Comparator<? super T> c) 将集合中元素按照指定规则排序
Treeset默认排序。list使用Collection工具来进行排序的
package com.itheima.d3_collections; import java.util.*; /** 目标:Collections工具类的使用。 java.utils.Collections:是集合工具类 Collections并不属于集合,是用来操作集合的工具类。 Collections有几个常用的API: - public static <T> boolean addAll(Collection<? super T> c, T... elements) 给集合对象批量添加元素! - public static void shuffle(List<?> list) :打乱集合顺序。 - public static <T> void sort(List<T> list):将集合中元素按照默认规则排序。 - public static <T> void sort(List<T> list,Comparator<? super T> c):将集合中元素按照指定规则排序。 */ public class CollectionsDemo01 { public static void main(String[] args) { List<String> names = new ArrayList<>(); // 集合 //names.add("楚留香"); //names.add("胡铁花"); //names.add("张无忌"); //names.add("陆小凤"); Collections.addAll(names, "楚留香","胡铁花", "张无忌","陆小凤"); // 使用 Collections 工具类。集合里使用的是String,添加的元素是String或者String的子类 System.out.println(names); // 2、public static void shuffle(List<?> list) :只能打乱 List 集合顺序【set本身就无序的,无法打乱】【list基于数组,坑位移动一下就行】 Collections.shuffle(names); System.out.println(names); // 3、 public static <T> void sort(List<T> list):将集合中元素按照默认规则排序。 (排值特性的元素)【遍历后随机索引】【只能对list集合进行排序,set不行】 List<Integer> list = new ArrayList<>(); Collections.addAll(list, 12, 23, 2, 4); System.out.println(list); Collections.sort(list); System.out.println(list); } }
package com.itheima.d3_collections; import java.util.*; /** 目标:引用数据类型的排序。 字符串按照首字符的编号升序排序! 自定义类型的比较方法API:Collections - public static <T> void sort(List<T> list): 将集合中元素按照默认规则排序。 对于自定义的引用类型的排序人家根本不知道怎么排,直接报错! - public static <T> void sort(List<T> list,Comparator<? super T> c): 将集合中元素按照指定规则排序,自带比较器 */ public class CollectionsDemo02 { public static void main(String[] args) { List<Apple> apples = new ArrayList<>(); // 可以重复! apples.add(new Apple("红富士", "红色", 9.9, 500)); apples.add(new Apple("青苹果", "绿色", 15.9, 300)); apples.add(new Apple("绿苹果", "青色", 29.9, 400)); apples.add(new Apple("黄苹果", "黄色", 9.8, 500)); // Collections.sort(apples); // 方法一:可以的,Apple类已经重写了比较规则 compare 方法【可以进行排序】 // System.out.println(apples); // 方式二:sort方法自带比较器对象 // Collections.sort(apples, new Comparator<Apple>() { // @Override // public int compare(Apple o1, Apple o2) { // return Double.compare(o1.getPrice() , o2.getPrice()); // 按照价格排序!! // } // }); Collections.sort(apples, ( o1, o2) -> Double.compare(o1.getPrice() , o2.getPrice()) ); System.out.println(apples); } }
package com.itheima.d3_collections; public class Apple implements Comparable<Apple>{ private String name; private String color; private double price; private int weight; public Apple() { } public Apple(String name, String color, double price, int weight) { this.name = name; this.color = color; this.price = price; this.weight = weight; } public String getName() { return name; } public void setName(String name) { this.name = name; } public String getColor() { return color; } public void setColor(String color) { this.color = color; } public double getPrice() { return price; } public void setPrice(double price) { this.price = price; } public int getWeight() { return weight; } public void setWeight(int weight) { this.weight = weight; } @Override public String toString() { return "Apple{" + "name='" + name + '\'' + ", color='" + color + '\'' + ", price=" + price + ", weight=" + weight + '}'; } /** 方式一:类自定义比较规则 o1.compareTo(o2) * @param o * @return */ @Override public int compareTo(Apple o) { // 按照重量进行比较的 return this.weight - o.weight ; // List集存储相同大小的元素 会保留!和set不同【底层实现原理差别,set会去重,list不会去重】 } }
26:简单案例 斗地主

package com.itheima.d4_collection_test; public class Card { private String size; // 点数 private String color; // 花色 private int index; // 牌的真正大小 public Card(){ } public Card(String size, String color, int index) { this.size = size; this.color = color; this.index = index; } public String getSize() { return size; } public void setSize(String size) { this.size = size; } public String getColor() { return color; } public void setColor(String color) { this.color = color; } public int getIndex() { return index; } public void setIndex(int index) { this.index = index; } @Override public String toString() { return size + color; } }
package com.itheima.d4_collection_test; import java.util.*; /** 目标:斗地主游戏的案例开发。 业务需求分析: 斗地主的做牌, 洗牌, 发牌, 排序(拓展知识), 看牌。 业务: 总共有54张牌。 点数: "3","4","5","6","7","8","9","10","J","Q","K","A","2" 花色: "♠", "♥", "♣", "♦" 大小王: "👲" , "🃏" 点数分别要组合4种花色,大小王各一张。 斗地主:发出51张牌,剩下3张作为底牌。 功能: 1.做牌。 2.洗牌。 3.定义3个玩家 4.发牌。 5.排序(拓展,了解,作业) 6.看牌 */ public class GameDemo { /** 1、定义一个静态的集合存储54张牌对象 */ public static List<Card> allCards = new ArrayList<>(); /** 2、做牌:定义静态代码块初始化牌数据 */ static { // 3、定义点数:个数确定,类型确定,使用数组 String[] sizes = {"3","4","5","6","7","8","9","10","J","Q","K","A","2"}; // 4、定义花色:个数确定,类型确定,使用数组 String[] colors = {"♠", "♥", "♣", "♦"}; // 5、组合点数和花色 int index = 0; // 记录牌的大小 for (String size : sizes) { index++; for (String color : colors) { // 6、封装成一个牌对象。 Card c = new Card(size, color, index); // 7、存入到集合容器中去 allCards.add(c); } } // 8 大小王存入到集合对象中去 "👲" , "🃏" Card c1 = new Card("" , "🃏", ++index); Card c2 = new Card("" , "👲",++index); Collections.addAll(allCards , c1 , c2); System.out.println("新牌:" + allCards); } public static void main(String[] args) { // 9、洗牌 Collections.shuffle(allCards); System.out.println("洗牌后:" + allCards); // 10、发牌(定义三个玩家,每个玩家的牌也是一个集合容器) List<Card> linhuchong = new ArrayList<>(); List<Card> jiumozhi = new ArrayList<>(); List<Card> renyingying = new ArrayList<>(); // 11、开始发牌(从牌集合中发出51张牌给三个玩家,剩余3张作为底牌) // allCards = [🃏, A♠, 5♥, 2♠, 2♣, Q♣, 👲, Q♠ ... // i 0 1 2 3 4 5 6 7 % 3 for (int i = 0; i < allCards.size() - 3; i++) { // 先拿到当前牌对象 Card c = allCards.get(i); if(i % 3 == 0) { // 请阿冲接牌 linhuchong.add(c); }else if(i % 3 == 1){ // 请阿鸠 jiumozhi.add(c); }else if(i % 3 == 2){ // 请盈盈接牌 renyingying.add(c); } } // 12、拿到最后三张底牌(把最后三张牌截取成一个子集合) List<Card> lastThreeCards = allCards.subList(allCards.size() - 3 , allCards.size()); // 13、给玩家的牌排序(从大到小 可以自己先试试怎么实现)【打牌需要排序】 sortCards(linhuchong); sortCards(jiumozhi); sortCards(renyingying); // 14、输出玩家的牌: System.out.println("啊冲:" + linhuchong); System.out.println("啊鸠:" + jiumozhi); System.out.println("盈盈:" + renyingying); System.out.println("三张底牌:" + lastThreeCards); } /** 给牌排序 * @param cards */ private static void sortCards(List<Card> cards) { // cards = [J♥, A♦, 3♥, 🃏, 5♦, Q♥, 2♥ Collections.sort(cards, new Comparator<Card>() { @Override public int compare(Card o1, Card o2) { // o1 = J♥ // o2 = A♦ // 知道牌的大小,才可以指定规则 return o2.getIndex() - o1.getIndex(); } }); } }
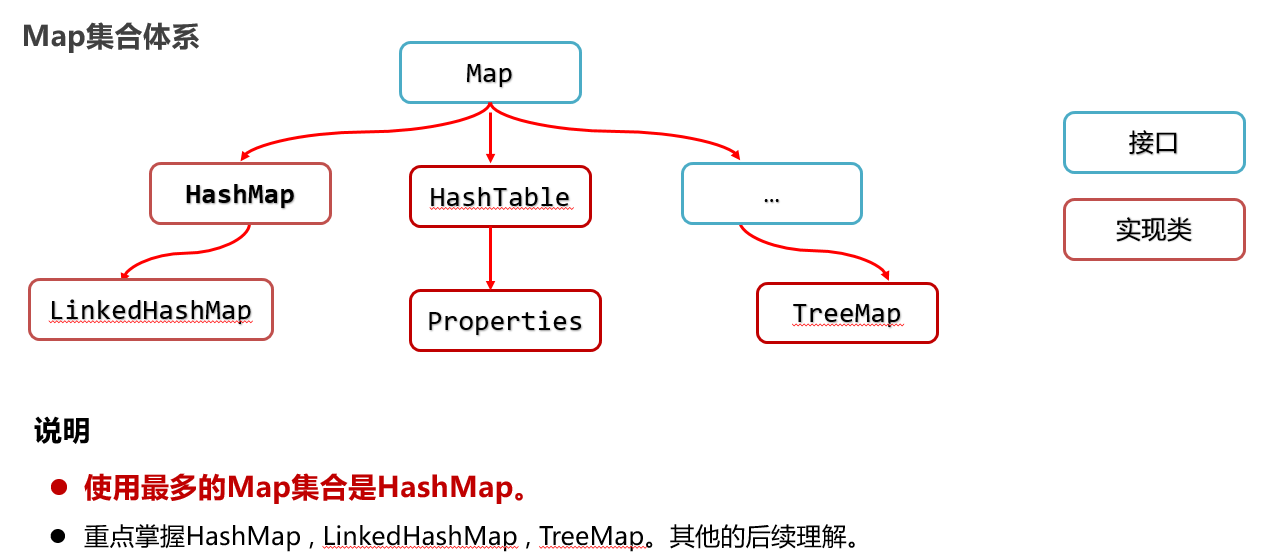
27:Map集合体系 【不属于:Collection集合】【键值对集合】【python中的字典】
Map集合概述和使用: Map集合是一种双列集合,每个元素包含两个数据。 Map集合的每个元素的格式:key=value(键值对元素)。 Map集合也被称为“键值对集合”。 Map集合整体格式: Collection集合的格式: [元素1,元素2,元素3..] Map集合的完整格式:{key1=value1 , key2=value2 , key3=value3 , ...}


28:Map集合体系 特点
Map集合体系特点:
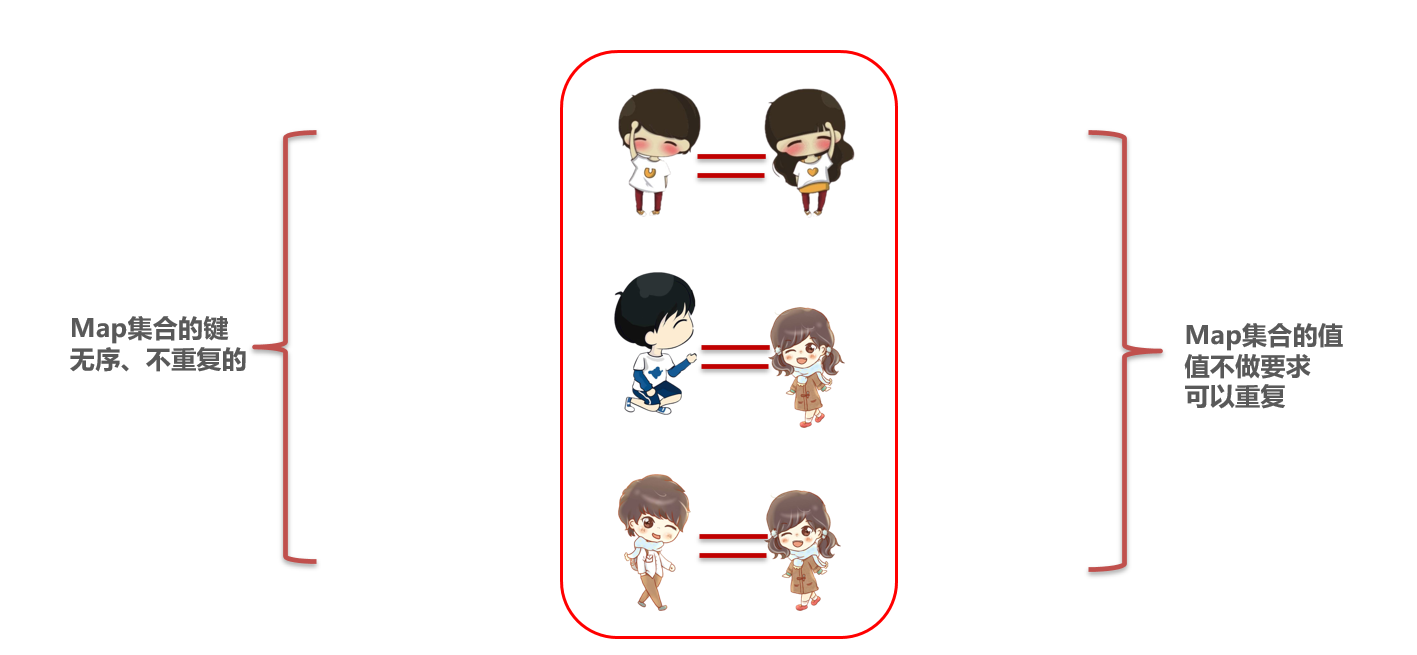
Map集合的特点都是由键决定的。
Map集合的键是无序,不重复的,无索引的,值不做要求(可以重复)。
Map集合后面重复的键对应的值会覆盖前面重复键的值。
Map集合的键值对都可以为null。
Map集合实现类特点:
HashMap:元素按照 键 是无序,不重复,无索引,值不做要求。(与Map体系一致)
LinkedHashMap:元素按照键是有序,不重复,无索引,值不做要求。
TreeMap:元素按照建是排序,不重复,无索引的,值不做要求。
package com.itheima.d5_map; import java.util.HashMap; import java.util.LinkedHashMap; import java.util.Map; /** 目标:认识Map体系的特点:按照键无序,不重复,无索引。值不做要求。 */ public class MapDemo1 { public static void main(String[] args) { // 1、创建一个Map集合对象 // Map<String, Integer> maps = new HashMap<>(); // 一行经典代码 Map<String, Integer> maps = new LinkedHashMap<>(); maps.put("鸿星尔克", 3); maps.put("Java", 1); maps.put("枸杞", 100); maps.put("Java", 100); // 覆盖前面的数据【键不能重复】 maps.put(null, null); System.out.println(maps); } }
29:Map集合 常用 API
Map集合 :Map是双列集合的祖宗接口,它的功能是全部双列集合都可以继承使用的。 Map API如下: V put(K key,V value) 添加元素 V remove(Object key) 根据键删除键值对元素 void clear() 移除所有的键值对元素 boolean containsKey(Object key) 判断集合是否包含指定的键 boolean containsValue(Object value) 判断集合是否包含指定的值 boolean isEmpty() 判断集合是否为空 int size() 集合的长度,也就是集合中键值对的个数
package com.itheima.d6_map_api; import java.util.Collection; import java.util.HashMap; import java.util.Map; import java.util.Set; /** 目标:Map集合的常用API(重点中的重点) - public V put(K key, V value): 把指定的键与指定的值添加到Map集合中。 - public V remove(Object key): 把指定的键 所对应的键值对元素 在Map集合中删除,返回被删除元素的值。 - public V get(Object key) 根据指定的键,在Map集合中获取对应的值。 - public Set<K> keySet(): 获取Map集合中所有的键,存储到Set集合中。 - public Set<Map.Entry<K,V>> entrySet(): 获取到Map集合中所有的键值对对象的集合(Set集合)。 - public boolean containKey(Object key):判断该集合中是否有此键。 - public boolean containValue(Object value):判断该集合中是否有此值。 */ public class MapDemo { public static void main(String[] args) { // 1.添加元素: 无序,不重复,无索引。 Map<String , Integer> maps = new HashMap<>(); maps.put("iphoneX",10); maps.put("娃娃",20); maps.put("iphoneX",100);// Map集合后面重复的键对应的元素会覆盖前面重复的整个元素! maps.put("huawei",100); maps.put("生活用品",10); maps.put("手表",10); // {huawei=100, 手表=10, 生活用品=10, iphoneX=100, 娃娃=20} System.out.println(maps); // 2.清空集合 // maps.clear(); // System.out.println(maps); // 3.判断集合是否为空,为空返回true ,反之! System.out.println(maps.isEmpty()); // 4.根据键获取对应值:public V get(Object key) Integer key = maps.get("huawei"); System.out.println(key); System.out.println(maps.get("生活用品")); // 10 System.out.println(maps.get("生活用品2")); // null // 5.根据键删除整个元素。(删除键会返回键的值) System.out.println(maps.remove("iphoneX")); System.out.println(maps); // 6.判断是否包含某个键 ,包含返回true ,反之 System.out.println(maps.containsKey("娃娃")); // true System.out.println(maps.containsKey("娃娃2")); // false System.out.println(maps.containsKey("iphoneX")); // false // 7.判断是否包含某个值。 System.out.println(maps.containsValue(100)); // System.out.println(maps.containsValue(10)); // System.out.println(maps.containsValue(22)); // // {huawei=100, 手表=10, 生活用品=10, 娃娃=20} // 8.获取全部键的集合:public Set<K> keySet() map【无序不重复,无索引】 返回的本质是一个 hashset Set<String> keys = maps.keySet(); System.out.println(keys); System.out.println("------------------------------"); // 9.获取全部值的集合:Collection<V> values(); 返回的是Collction集合,不是set了,因为set不重复,返回的值相同那么就直接消失了【丢值】 Collection<Integer> values = maps.values(); System.out.println(values); // 10.集合的大小 System.out.println(maps.size()); // 4 // 11.合并其他Map集合。(拓展) Map<String , Integer> map1 = new HashMap<>(); map1.put("java1", 1); map1.put("java2", 100); Map<String , Integer> map2 = new HashMap<>(); map2.put("java2", 1); map2.put("java3", 100); map1.putAll(map2); // 把集合map2的元素拷贝一份到map1中去 System.out.println(map1); System.out.println(map2); } }
30:Map集合 遍历三种方式
Map集合的遍历方式有:3种。 方式一:键找值的方式遍历:先获取Map集合全部的键,再根据遍历键找值。 方式二:键值对的方式遍历,把“键值对“看成一个整体,难度较大。 方式三:JDK 1.8开始之后的新技术:Lambda表达式。
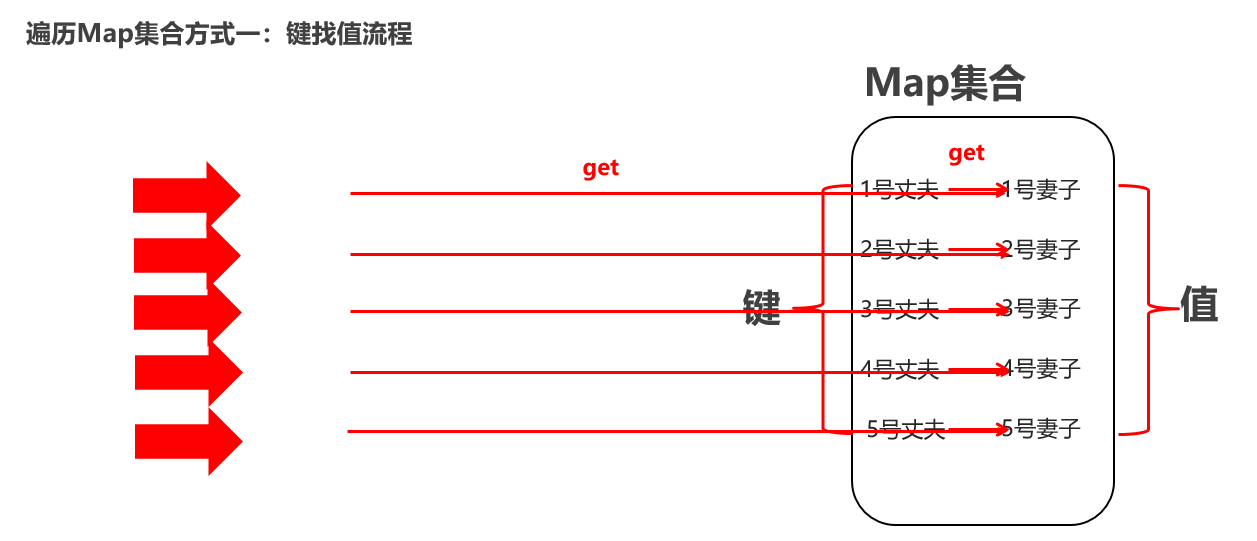
Map集合的遍历方式一:键找值 先获取Map集合的全部键的Set集合。 遍历键的Set集合,然后通过键提取对应值。 键找值涉及到的API: Set<K> keySet() 获取所有键的集合 V get(Object key) 根据键获取值
package com.itheima.d7_map_traversal; import java.util.HashMap; import java.util.Map; import java.util.Set; /** 目标:Map集合的遍历方式一:键找值 Map集合的遍历方式有:3种。 (1)“键找值”的方式遍历:先获取Map集合全部的键,再根据遍历键找值。 (2)“键值对”的方式遍历:难度较大。 (3)JDK 1.8开始之后的新技术:Lambda表达式。(暂时了解) a.“键找值”的方式遍历Map集合。 1.先获取Map集合的全部键的Set集合。 2.遍历键的Set集合,然后通过键找值。 小结: 代码简单,需要记住! */ public class MapDemo01 { public static void main(String[] args) { Map<String , Integer> maps = new HashMap<>(); // 1.添加元素: 无序,不重复,无索引。 maps.put("娃娃",30); maps.put("iphoneX",100); maps.put("huawei",1000); maps.put("生活用品",10); maps.put("手表",10); System.out.println(maps); // maps = {huawei=1000, 手表=10, 生活用品=10, iphoneX=100, 娃娃=30} // 1、键找值:第一步:先拿到集合的全部键。 Set<String> keys = maps.keySet(); // 2、第二步:遍历每个键,根据键提取值 for (String key : keys) { int value = maps.get(key); System.out.println(key + "===>" + value); } } }
Map集合的遍历方式二:键值对 先把Map集合转换成Set集合,Set集合中每个元素都是键值对实体类型了。 遍历Set集合,然后提取键以及提取值。 键值对涉及到的API: Set<Map.Entry<K,V>> entrySet() 获取所有键值对对象的集合 K getKey() 获得键 V getValue() 获取值
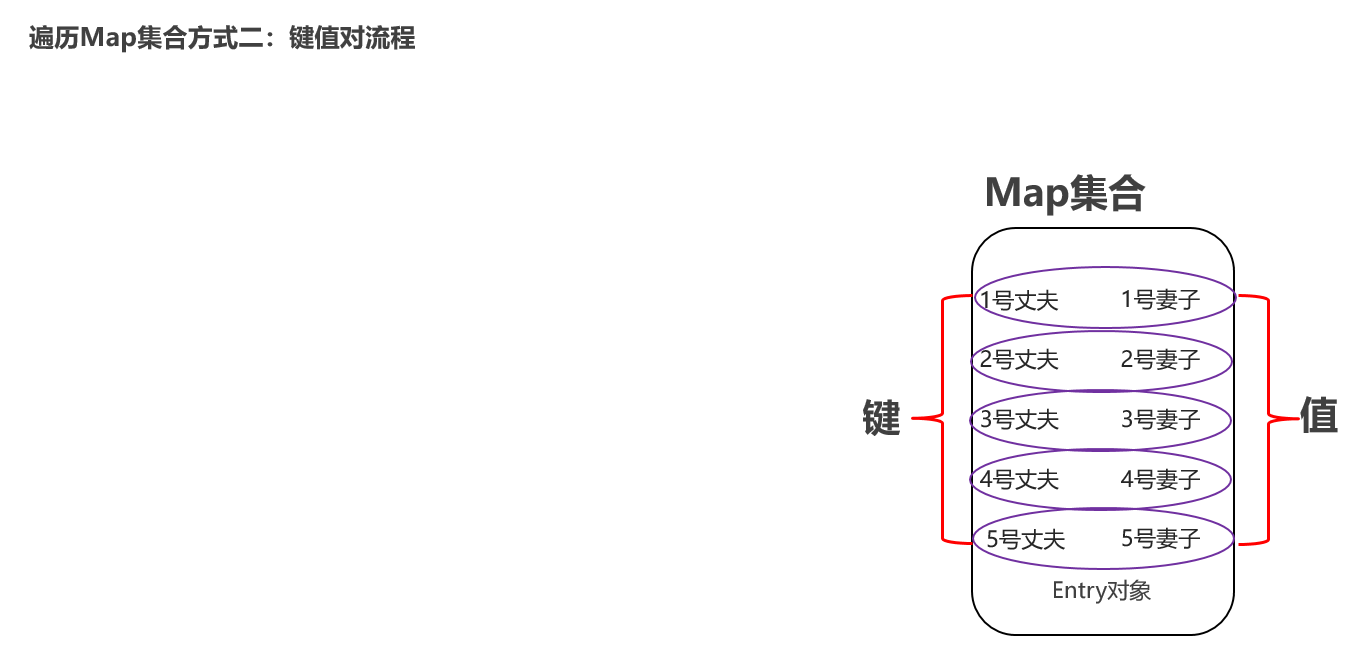
package com.itheima.d7_map_traversal; import java.util.HashMap; import java.util.Map; import java.util.Set; /** 目标:Map集合的遍历方式。 Map集合的遍历方式有:3种。 (1)“键找值”的方式遍历:先获取Map集合全部的键,再根据键找值。 (2)“键值对”的方式遍历:难度较大。 (3)JDK 1.8开始之后的新技术:Lambda表达式。 b.“键值对”的方式遍历: 1.把Map集合转换成一个Set集合:Set<Map.Entry<K, V>> entrySet(); 2.此时键值对元素的类型就确定了,类型是键值对实体类型:Map.Entry<K, V> 3.接下来就可以用foreach遍历这个Set集合,类型用Map.Entry<K, V> */ public class MapDemo02 { public static void main(String[] args) { Map<String , Integer> maps = new HashMap<>(); // 1.添加元素: 无序,不重复,无索引。 maps.put("娃娃",30); maps.put("iphoneX",100); maps.put("huawei",1000); maps.put("生活用品",10); maps.put("手表",10); System.out.println(maps); // maps = {huawei=1000, 手表=10, 生活用品=10, iphoneX=100, 娃娃=30} /** maps = {huawei=1000, 手表=10, 生活用品=10, iphoneX=100, 娃娃=30} 👇 使用foreach遍历map集合.发现Map集合的键值对元素直接是没有类型的。所以不可以直接foreach遍历集合。 👇 可以通过调用Map的方法 entrySet 把Map集合转换成Set集合形式 maps.entrySet(); 👇 Set<Map.Entry<String,Integer>> entries = maps.entrySet(); [(huawei=1000), (手表=10), (生活用品=10), (iphoneX=100), (娃娃=30)] entry 👇 此时可以使用foreach遍历 */ // 1、把Map集合转换成Set集合 Map集合不可以遍历,需要转换成Set ctrl + alt + v 键自动补全
// Entry 是一个接口,创建接口类的实体对象,封装键值数据,对象丢到底层set集合里去 【键值封装成一个对象封装到 set里,这个简直对象是Entry接口的实现类对象】 Set<Map.Entry<String, Integer>> entries = maps.entrySet(); // 2、开始遍历 for(Map.Entry<String, Integer> entry : entries){ String key = entry.getKey(); int value = entry.getValue(); System.out.println(key + "====>" + value); } } }
Map集合的遍历方式三:lambda表达式 得益于JDK 8开始的新技术Lambda表达式,提供了一种更简单、更直接的遍历集合的方式。 Map结合Lambda遍历的API: default void forEach(BiConsumer<? super K, ? super V> action) 结合lambda遍历Map集合
forEach内部使用的是 EntrySet 方式进行遍历的,源码内部使用的第二中方式,内部遍历,每次遍历值之后回调 BiConsumer 对象里重写的方法
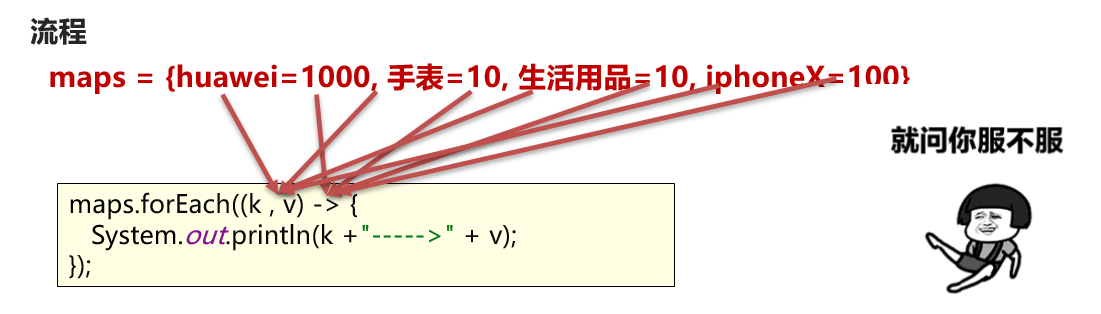
package com.itheima.d7_map_traversal; import java.util.HashMap; import java.util.Map; import java.util.function.BiConsumer; /** 目标:Map集合的遍历方式。 Map集合的遍历方式有:3种。 (1)“键找值”的方式遍历:先获取Map集合全部的键,再根据键找值。 (2)“键值对”的方式遍历:难度较大。 (3)JDK 1.8开始之后的新技术:Lambda表达式。 c.JDK 1.8开始之后的新技术:Lambda表达式。(暂时了解) */ public class MapDemo03 { public static void main(String[] args) { Map<String , Integer> maps = new HashMap<>(); // 1.添加元素: 无序,不重复,无索引。 maps.put("娃娃",30); maps.put("iphoneX",100);// Map集合后面重复的键对应的元素会覆盖前面重复的整个元素! maps.put("huawei",1000); maps.put("生活用品",10); maps.put("手表",10); System.out.println(maps); // maps = {huawei=1000, 手表=10, 生活用品=10, iphoneX=100, 娃娃=30} // maps.forEach(new BiConsumer<String, Integer>() { // @Override // public void accept(String key, Integer value) { // System.out.println(key + "--->" + value); // } // }); maps.forEach((k, v) -> { System.out.println(k + "--->" + v); }); } }
31:Map集合 简单案例练习

package com.itheima.d8_map_test; import java.util.*; /** 需求:统计投票人数 */ public class MapTest1 { public static void main(String[] args) { // 1、把80个学生选择的数据拿进来。 String[] selects = {"A" , "B", "C", "D"}; StringBuilder sb = new StringBuilder(); Random r = new Random(); for (int i = 0; i < 80; i++) { sb.append(selects[r.nextInt(selects.length)]); } System.out.println(sb); // 2、定义一个Map集合记录最终统计的结果: A=30 B=20 C=20 D=10 键是景点 值是选择的数量 Map<Character, Integer> infos = new HashMap<>(); // // 3、遍历80个学生选择的数据 for (int i = 0; i < sb.length(); i++) { // 4、提取当前选择景点字符 char ch = sb.charAt(i); // 5、判断Map集合中是否存在这个键 if(infos.containsKey(ch)){ // 让其值 + 1 infos.put(ch , infos.get(ch) + 1); }else { // 说明此景点是第一次被选 infos.put(ch , 1); } } // 4、输出集合 System.out.println(infos); } }
32:Map 集合的实现类 HashMap
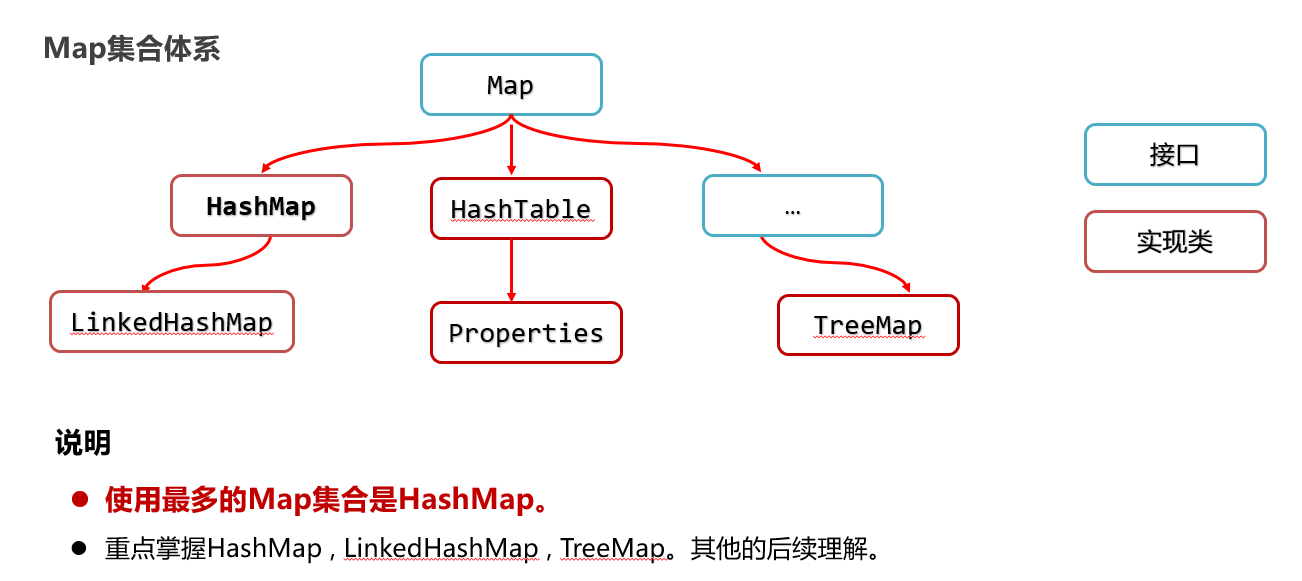
HashMap的特点: HashMap是Map里面的一个实现类。特点都是由键决定的:无序、不重复、无索引 【HashMap底层也是哈希表结构的】
也是 hashCode【算地址】 和 equals【比较内容】 方法保证键的唯一
如果键要存储的是自定义对象,那么需要重写 hashCode 和equals 方法保证值的唯一
基于Hash表,增删改查的性能都比较优秀【链表 + 数组 + 红黑二叉树】 没有额外需要学习的特有方法,直接使用Map里面的方法就可以了。 HashMap 跟 HashSet 底层原理是一模一样的,都是哈希表结构,只是HashMap的每个元素包含两个值而已。 实际上:Set 系列集合的底层就是 Map 实现的,只是Set集合中的元素只要键数据,不要值数据而已 public HashSet() { map = new HashMap<>(); }
HashMap键值作为一个整体放到链表某个位置,跟HashSet原理一样
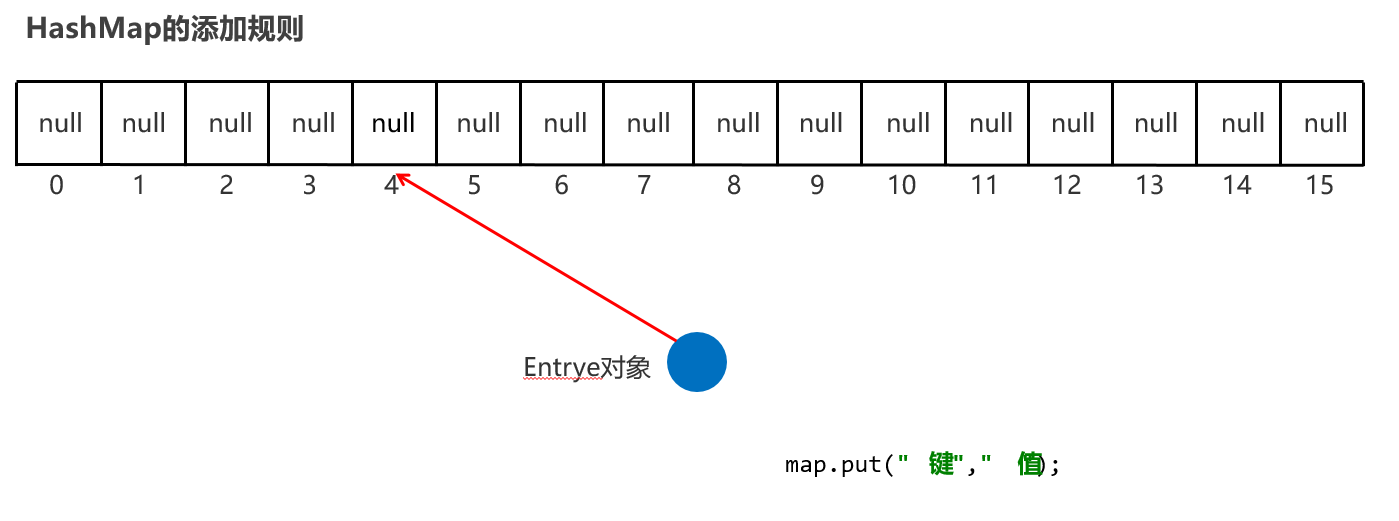
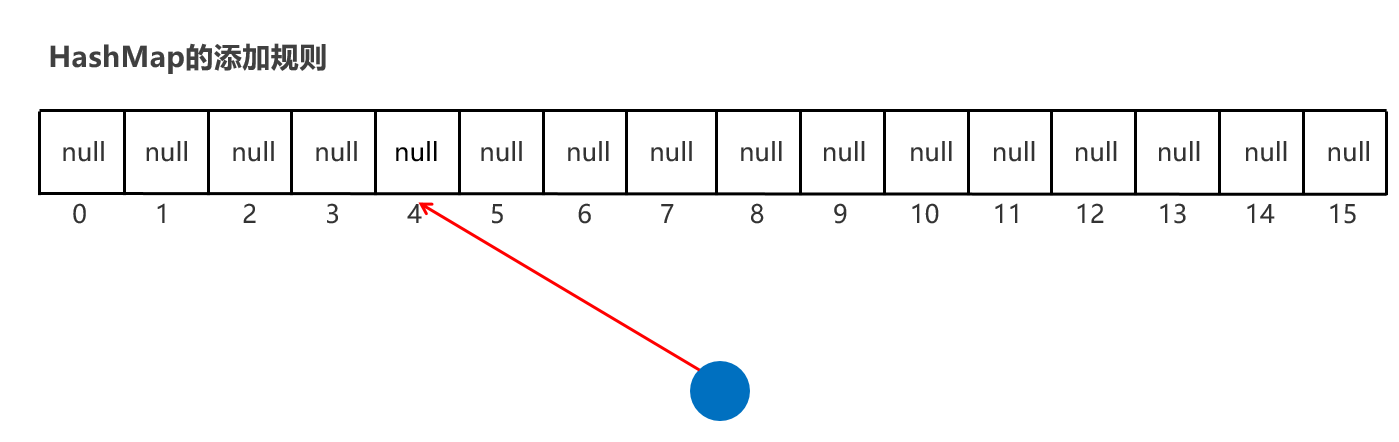
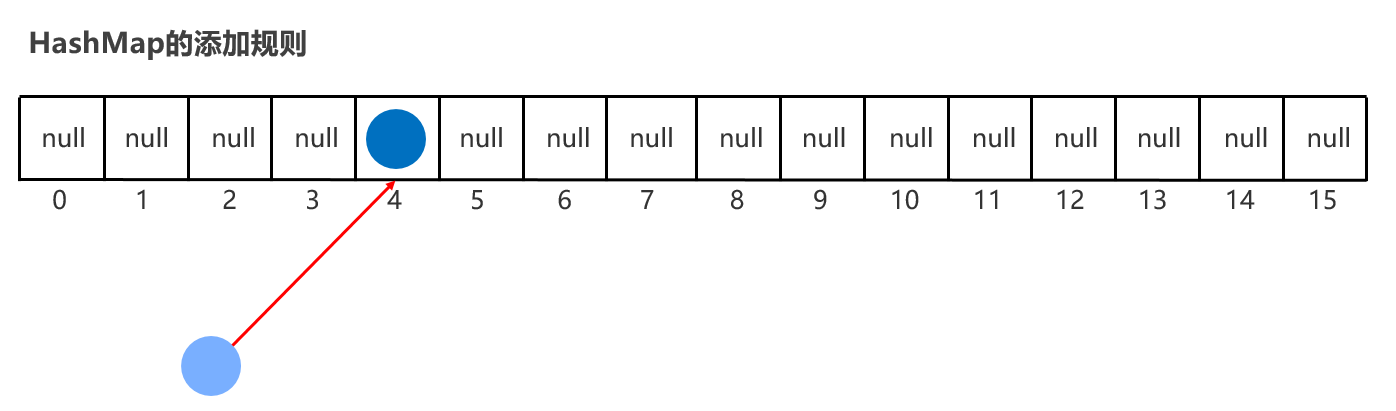
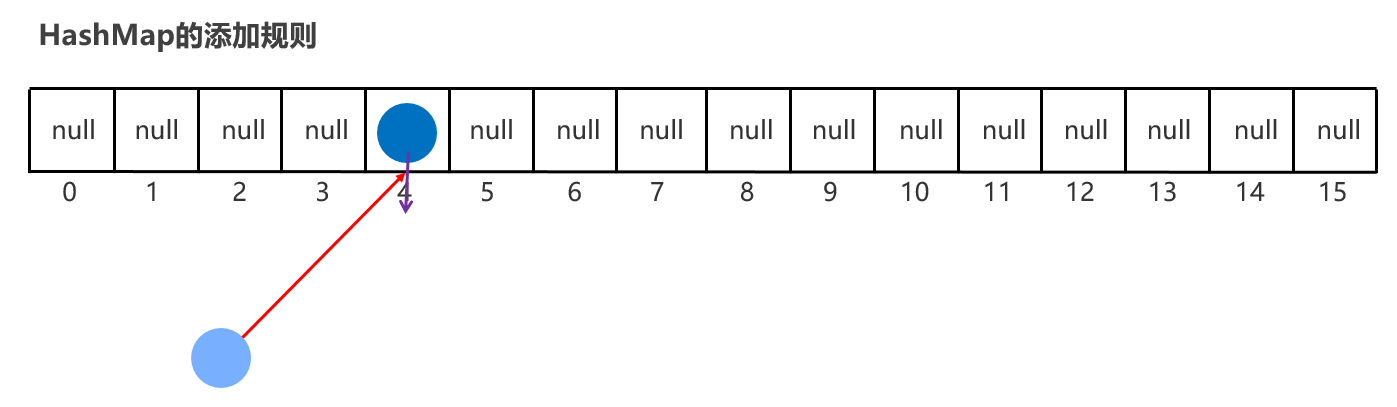
package com.itheima.d9_map_impl; import com.itheima.d1_collection_set.Student; import java.util.HashMap; import java.util.Map; public class HashMapDemo1 { public static void main(String[] args) { // Map集合是根据键去除重复元素 Map<Student, String> maps = new HashMap<>(); Student s1 = new Student("无恙", 20, '男'); Student s2 = new Student("无恙", 20, '男'); Student s3 = new Student("周雄", 21, '男'); maps.put(s1, "北京"); maps.put(s2, "上海"); maps.put(s3, "广州"); System.out.println(maps); } }
33:Map 集合的实现类 LinkedHashMap
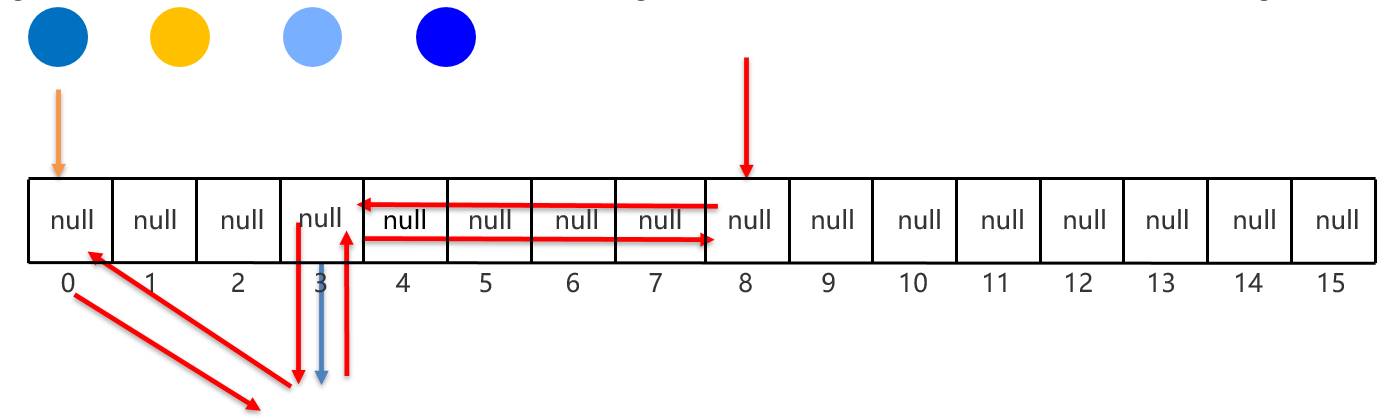
LinkedHashMap集合概述和特点:
由键决定:有序【添加顺序】、不重复、无索引。
这里的有序指的是保证存储和取出的元素顺序一致
原理:底层数据结构是依然哈希表,只是每个键值对元素又额外的多了一个双链表的机制记录存储的顺序【双链表记录上个元素地址和下个元素地址】
package com.itheima.d9_map_impl; import java.util.LinkedHashMap; import java.util.Map; import java.util.TreeSet; /** 目标:认识Map体系的特点:按照键无序,不重复,无索引。值不做要求。 */ public class LinkedHashMapDemo2 { public static void main(String[] args) { // 1、创建一个Map集合对象 Map<String, Integer> maps = new LinkedHashMap<>(); maps.put("鸿星尔克", 3); maps.put("Java", 1); maps.put("枸杞", 100); maps.put("Java", 100); // 覆盖前面的数据 maps.put(null, null); System.out.println(maps); } }
34:Map 集合的实现类 TreeMap
TreeMap集合概述和特点
由键决定特性:不重复、无索引、可排序
可排序:按照键数据的大小默认升序(有小到大)排序。只能对键排序。
注意:TreeMap集合是一定要排序的,可以默认排序,也可以将键按照指定的规则进行排序
TreeMap跟TreeSet一样底层原理是一样的。
TreeMap集合自定义排序规则有2种
类实现 Comparable 接口,重写比较规则。
集合自定义 Comparator 比较器对象,重写比较规则。
TreeMap集合的特点是怎么样的?
根据键可排序、不重复、无索引
底层基于红黑树实现排序,增删改查性能较好
TreeMap集合自定义排序规则有几种方式
2种。
类实现Comparable接口,重写比较规则。
集合自定义Comparator比较器对象,重写比较规则。
package com.itheima.d9_map_impl; import com.itheima.d1_collection_set.Apple; import java.util.Comparator; import java.util.Map; import java.util.TreeMap; public class TreeMapDemo3 { public static void main(String[] args) { Map<Integer, String> maps1 = new TreeMap<>(); maps1.put(13 , "王麻子"); maps1.put(1 , "张三"); maps1.put(3 , "县长"); System.out.println(maps1); // TreeMap集合自带排序。 可排序 不重复(只要大小规则一样就认为重复) 无索引 Map<Apple, String> maps2 = new TreeMap<>(new Comparator<Apple>() { @Override public int compare(Apple o1, Apple o2) { return Double.compare(o2.getPrice() , o1.getPrice()); // 按照价格降序排序! } }); maps2.put(new Apple("红富士", "红色", 9.9, 500), "山东" ); maps2.put(new Apple("青苹果", "绿色", 15.9, 300), "广州"); maps2.put(new Apple("绿苹果", "青色", 29.9, 400), "江西"); maps2.put(new Apple("黄苹果", "黄色", 9.8, 500), "湖北"); System.out.println(maps2); } }
Map集合实现类特点:
HashMap:元素按照键是无序,不重复,无索引,值不做要求,基于哈希表(与Map体系一致)
LinkedHashMap:元素按照键是有序,不重复,无索引,值不做要求,基于哈希表
TreeMap:元素只能按照键排序,不重复,无索引的,值不做要求,可以做排序
35:集合的嵌套【集合中的元素又是一个集合】

package com.itheima.d9_map_impl; import java.util.*; /** 需求:统计投票人数 */ public class MapTest4 { public static void main(String[] args) { // 1、要求程序记录每个学生选择的情况。 // 使用一个Map集合存储。 Map<String, List<String>> data = new HashMap<>(); // 2、把学生选择的数据存入进去。 List<String> selects = new ArrayList<>(); Collections.addAll(selects, "A", "C"); data.put("罗勇", selects); List<String> selects1 = new ArrayList<>(); Collections.addAll(selects1, "B", "C" , "D"); data.put("胡涛", selects1); List<String> selects2 = new ArrayList<>(); Collections.addAll(selects2 , "A", "B", "C" , "D"); data.put("刘军", selects2); System.out.println(data); // 3、统计每个景点选择的人数。 Map<String, Integer> infos = new HashMap<>(); // {} // 4、提取所有人选择的景点的信息。 Collection<List<String>> values = data.values(); System.out.println(values); // values = [[A, B, C, D], [B, C, D], [A, C]] // value for (List<String> value : values) { for (String s : value) { // 有没有包含这个景点 if(infos.containsKey(s)){ infos.put(s, infos.get(s) + 1); }else { infos.put(s , 1); } } } System.out.println(infos); } }
36:不可变集合对象
什么是不可变集合? 不可变集合,就是不可被修改的集合。 集合的数据项在创建的时候提供,并且在整个生命周期中都不可改变。否则报错。 为什么要创建不可变集合? 如果某个数据不能被修改,把它防御性地拷贝到不可变集合中是个很好的实践。 或者当集合对象被不可信的库调用时,不可变形式是安全的。 如何创建不可变集合? 在List、Set、Map接口中,都存在of方法,可以创建一个不可变的集合。 static <E> List<E> of(E…elements) 创建一个具有指定元素的List集合对象 static <E> Set<E> of(E…elements) 创建一个具有指定元素的Set集合对象 static <K , V> Map<K,V> of(E…elements) 创建一个具有指定元素的Map集合对象 这个集合不能添加,不能删除,不能修改
package com.itheima.d1_unchange_collection; import java.util.HashMap; import java.util.List; import java.util.Map; import java.util.Set; /** 目标:不可变集合。 */ public class CollectionDemo { public static void main(String[] args) { // 1、不可变的List集合 List<Double> lists = List.of(569.5, 700.5, 523.0, 570.5); // lists.add(689.0); // lists.set(2, 698.5); // System.out.println(lists); double score = lists.get(1); System.out.println(score); // 2、不可变的Set集合 Set<String> names = Set.of("迪丽热巴", "迪丽热九", "马尔扎哈", "卡尔眨巴" ); // names.add("三少爷"); System.out.println(names); // 3、不可变的Map集合 Map<String, Integer> maps = Map.of("huawei",2, "Java开发", 1 , "手表", 1); // maps.put("衣服", 3); System.out.println(maps); } }
37:Stream 流 了解
什么是Stream流? 在Java 8中,得益于Lambda所带来的函数式编程, 引入了一个全新的Stream流概念。 目的:用于简化集合和数组操作的 API。 Stream流式思想的核心: 1:先得到集合或者数组的Stream流(就是一根传送带) 2:把元素放上去 3:然后就用这个Stream流简化的API来方便的操作元素。

package com.itheima.d2_stream; import java.util.ArrayList; import java.util.Collections; import java.util.List; /** 目标:初步体验Stream流的方便与快捷 */ public class StreamTest { public static void main(String[] args) { List<String> names = new ArrayList<>(); Collections.addAll(names, "张三丰","张无忌","周芷若","赵敏","张强"); System.out.println(names); // // // 1、从集合中找出姓张的放到新集合 // List<String> zhangList = new ArrayList<>(); // for (String name : names) { // if(name.startsWith("张")){ // zhangList.add(name); // } // } // System.out.println(zhangList); // // // 2、找名称长度是3的姓名 // List<String> zhangThreeList = new ArrayList<>(); // for (String name : zhangList) { // if(name.length() == 3){ // zhangThreeList.add(name); // } // } // System.out.println(zhangThreeList); // 3、使用Stream实现的 names.stream().filter(s -> s.startsWith("张")).filter(s -> s.length() == 3).forEach(s -> System.out.println(s)); } }
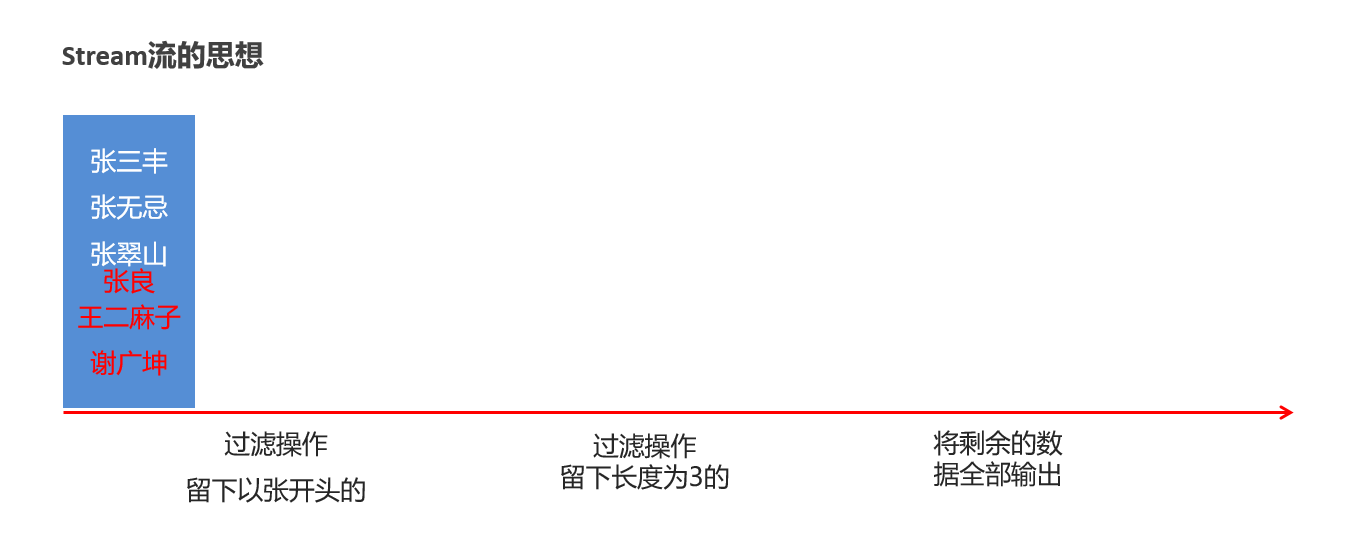

1、Stream流的作用是什么,结合了什么技术? 简化集合、数组操作的API。结合了Lambda表达式。 2、说说Stream流的思想和使用步骤。 先得到集合或者数组的Stream流(就是一根传送带)。 把元素放上去。 然后就用这个Stream流简化的API来方便的操作元素。
37:Stream 流 的获取
Stream操作集合或者数组的第一步是先得到Stream流,然后才能使用流的功能。 集合获取Stream流的方式:可以使用Collection接口中的默认方法stream()生成流 default Stream<E> stream() 获取当前集合对象的Stream流 数组获取Stream流的方式:ArryList public static <T> Stream<T> stream(T[] array) 获取当前数组的Stream流 public static<T> Stream<T> of(T... values) 获取当前数组/可变数据的Stream流 Stream流的三类方法 获取Stream流: 创建一条流水线,并把数据放到流水线上准备进行操作 中间方法: 流水线上的操作。一次操作完毕之后,还可以继续进行其他操作。 终结方法: 一个Stream流只能有一个终结方法,是流水线上的最后一个操作
package com.itheima.d2_stream; import java.util.*; import java.util.stream.Stream; /** 目标:Stream流的获取 Stream流式思想的核心: 是先得到集合或者数组的Stream流(就是一根传送带) 然后就用这个Stream流操作集合或者数组的元素。 然后用Stream流简化替代集合操作的API. 集合获取流的API: (1) default Stream<E> stream(); 小结: 集合获取Stream流用: stream(); 数组:Arrays.stream(数组) / Stream.of(数组); */ public class StreamDemo02 { public static void main(String[] args) { /** --------------------Collection集合获取流------------------------------- */ Collection<String> list = new ArrayList<>(); Stream<String> s = list.stream(); /** --------------------Map集合获取流------------------------------- */ Map<String, Integer> maps = new HashMap<>(); // 键流 Stream<String> keyStream = maps.keySet().stream(); // 值流 Stream<Integer> valueStream = maps.values().stream(); // 键值对流(拿整体) Stream<Map.Entry<String,Integer>> keyAndValueStream = maps.entrySet().stream(); /** ---------------------数组获取流------------------------------ */ String[] names = {"赵敏","小昭","灭绝","周芷若"}; Stream<String> nameStream = Arrays.stream(names); Stream<String> nameStream2 = Stream.of(names); } }
38:Stream 流 常用的API【中间操作】
Stream流的常用API(中间操作方法) Stream<T> filter(Predicate<? super T> predicate) 用于对流中的数据进行过滤。 Stream<T> limit(long maxSize) 获取前几个元素 Stream<T> skip(long n) 跳过前几个元素 Stream<T> distinct() 去除流中重复的元素。依赖(hashCode和equals方法) static <T> Stream<T> concat(Stream a, Stream b) 合并a和b两个流为一个流 注意: 中间方法也称为非终结方法,调用完成后返回新的Stream流可以继续使用,支持链式编程。 在Stream流中无法直接修改集合、数组中的数据【不影响原来集合数据】
Stream流的常见终结操作方法:【终结方法没有返回Stream流对象】 void forEach(Consumer action) 对此流的每个元素执行遍历操作 long count() 返回此流中的元素数 注意:终结操作方法,调用完成后流就无法继续使用了,原因是不会返回Stream了
package com.itheima.d2_stream; import java.util.ArrayList; import java.util.Arrays; import java.util.List; import java.util.function.Consumer; import java.util.function.Function; import java.util.function.Predicate; import java.util.stream.Stream; /** 目标:Stream流的常用API forEach : 逐一处理(遍历) count:统计个数 -- long count(); filter : 过滤元素 -- Stream<T> filter(Predicate<? super T> predicate) limit : 取前几个元素 skip : 跳过前几个 map : 加工方法 concat : 合并流。 */ public class StreamDemo03 { public static void main(String[] args) { List<String> list = new ArrayList<>(); list.add("张无忌"); list.add("周芷若"); list.add("赵敏"); list.add("张强"); list.add("张三丰"); list.add("张三丰"); // Stream<T> filter(Predicate<? super T> predicate) list.stream().filter(s -> s.startsWith("张")).forEach(s -> System.out.println(s)); long size = list.stream().filter(s -> s.length() == 3).count(); System.out.println(size); // list.stream().filter(s -> s.startsWith("张")).limit(2).forEach(s -> System.out.println(s)); list.stream().filter(s -> s.startsWith("张")).limit(2).forEach(System.out::println); // 上面的简化模式 list.stream().filter(s -> s.startsWith("张")).skip(2).forEach(System.out::println); // map加工方法: 第一个参数原材料 -> 第二个参数是加工后的结果。 如有:new Function<String【入参类型】, String【返回类型】> // 给集合元素的前面都加上一个:黑马的: list.stream().map(s -> "黑马的:" + s).forEach(a -> System.out.println(a)); // 需求:把所有的名称 都加工成一个学生对象。 list.stream().map(s -> new Student(s)).forEach(s -> System.out.println(s)); // list.stream().map(Student::new).forEach(System.out::println); // 构造器引用 方法引用 // 合并流。同一类型的流合并,使用一样的泛型类型,这里是String,不同类型的流合并,需要使用object。不同类型流里元素类型的共同的父类 Stream<String> s1 = list.stream().filter(s -> s.startsWith("张")); Stream<String> s2 = Stream.of("java1", "java2"); // public static <T> Stream<T> concat(Stream<? extends T> a, Stream<? extends T> b) Stream<String> s3 = Stream.concat(s1 , s2); s3.distinct().forEach(s -> System.out.println(s)); } }
39:Stream 流 综合应用

package com.itheima.d2_stream; import java.math.BigDecimal; import java.math.RoundingMode; import java.util.ArrayList; import java.util.List; import java.util.stream.Stream; public class StreamDemo04 { public static double allMoney ; public static double allMoney2 ; // 2个部门去掉最高工资,最低工资的总和 public static void main(String[] args) { List<Employee> one = new ArrayList<>(); one.add(new Employee("猪八戒",'男',30000 , 25000, null)); one.add(new Employee("孙悟空",'男',25000 , 1000, "顶撞上司")); one.add(new Employee("沙僧",'男',20000 , 20000, null)); one.add(new Employee("小白龙",'男',20000 , 25000, null)); List<Employee> two = new ArrayList<>(); two.add(new Employee("武松",'男',15000 , 9000, null)); two.add(new Employee("李逵",'男',20000 , 10000, null)); two.add(new Employee("西门庆",'男',50000 , 100000, "被打")); two.add(new Employee("潘金莲",'女',3500 , 1000, "被打")); two.add(new Employee("武大郎",'女',20000 , 0, "下毒")); // 1、开发一部的最高工资的员工。(API) max 这个api:自定义比较器 // 指定大小规则了 // Employee e = one.stream().max((e1, e2) -> Double.compare(e1.getSalary() + e1.getBonus(), e2.getSalary() + e2.getBonus())) // .get(); // System.out.println(e); Topperformer t = one.stream().max((e1, e2) -> Double.compare(e1.getSalary() + e1.getBonus(), e2.getSalary() + e2.getBonus())) .map(e -> new Topperformer(e.getName(), e.getSalary() + e.getBonus())).get(); System.out.println(t); // 2、统计平均工资,去掉最高工资和最低工资 排序后去掉最高最低再求和 one.stream().sorted((e1, e2) -> Double.compare(e1.getSalary() + e1.getBonus(), e2.getSalary() + e2.getBonus())) .skip(1).limit(one.size() - 2).forEach(e -> { // 求出总和:剩余员工的工资总和 allMoney += (e.getSalary() + e.getBonus()); }); System.out.println("开发一部的平均工资是:" + allMoney / (one.size() - 2)); // 3、合并2个集合流,再统计 Stream<Employee> s1 = one.stream(); Stream<Employee> s2 = two.stream(); Stream<Employee> s3 = Stream.concat(s1 , s2); s3.sorted((e1, e2) -> Double.compare(e1.getSalary() + e1.getBonus(), e2.getSalary() + e2.getBonus())) .skip(1).limit(one.size() + two.size() - 2).forEach(e -> { // 求出总和:剩余员工的工资总和 allMoney2 += (e.getSalary() + e.getBonus()); }); // BigDecimal 精准计算类 BigDecimal a = BigDecimal.valueOf(allMoney2); BigDecimal b = BigDecimal.valueOf(one.size() + two.size() - 2); System.out.println("开发部的平均工资是:" + a.divide(b,2, RoundingMode.HALF_UP)); } }
package com.itheima.d2_stream; public class Employee { private String name; private char sex; private double salary; private double bonus; private String punish; // 处罚信息 public Employee(){ } public Employee(String name, char sex, double salary, double bonus, String punish) { this.name = name; this.sex = sex; this.salary = salary; this.bonus = bonus; this.punish = punish; } public String getName() { return name; } public void setName(String name) { this.name = name; } public char getSex() { return sex; } public void setSex(char sex) { this.sex = sex; } public double getSalary() { return salary; } public void setSalary(double salary) { this.salary = salary; } public double getBonus() { return bonus; } public void setBonus(double bonus) { this.bonus = bonus; } public String getPunish() { return punish; } public void setPunish(String punish) { this.punish = punish; } public double getTotalSalay(){ return salary * 12 + bonus; } @Override public String toString() { return "Employee{" + "name='" + name + '\'' + ", sex=" + sex + ", salary=" + salary + ", bonus=" + bonus + ", punish='" + punish + '\'' + '}'+"\n"; } }
package com.itheima.d2_stream; public class Topperformer { private String name; private double money; // 月薪 public Topperformer() { } public Topperformer(String name, double money) { this.name = name; this.money = money; } public String getName() { return name; } public void setName(String name) { this.name = name; } public double getMoney() { return money; } public void setMoney(double money) { this.money = money; } @Override public String toString() { return "Topperformer{" + "name='" + name + '\'' + ", money=" + money + '}'; } }
40:收集 Stream 流
Stream流的收集操作:收集Stream流的含义:就是把Stream流操作后的结果数据转回到集合或者数组中去。 Stream流:方便操作集合/数组的手段。 集合/数组:才是开发中的目的。 Stream流的收集方法: R collect(Collector collector) 开始收集Stream流,指定收集器 Collectors工具类提供了具体的收集方式: public static <T> Collector toList() 把元素收集到List集合中 public static <T> Collector toSet() 把元素收集到Set集合中 public static Collector toMap(Function keyMapper , Function valueMapper) 把元素收集到Map集合中
package com.itheima.d2_stream; import java.util.*; import java.util.function.IntFunction; import java.util.stream.Collectors; import java.util.stream.Stream; /** 目标:收集Stream流的数据到 集合或者数组中去。 */ public class StreamDemo05 { public static void main(String[] args) { List<String> list = new ArrayList<>(); list.add("张无忌"); list.add("周芷若"); list.add("赵敏"); list.add("张强"); list.add("张三丰"); list.add("张三丰"); Stream<String> s1 = list.stream().filter(s -> s.startsWith("张")); List<String> zhangList = s1.collect(Collectors.toList()); // 可变集合 返回了一个ArryList zhangList.add("java1"); System.out.println(zhangList); // List<String> list1 = s1.toList(); // 得到不可变集合 // list1.add("java"); // System.out.println(list1); // 注意注意注意:“流只能使用一次” Stream<String> s2 = list.stream().filter(s -> s.startsWith("张")); Set<String> zhangSet = s2.collect(Collectors.toSet()); System.out.println(zhangSet); Stream<String> s3 = list.stream().filter(s -> s.startsWith("张")); // Object[] arrs = s3.toArray(); // 这样就可以直接收集成数组,下面的方式也可以 String[] arrs = s3.toArray(String[]::new); // 可以不管,拓展一下思维!! 一定要把 流里面的数据输出成字符串数组,如左这样操作 【声明一个对象告诉最终结果类型】 System.out.println("Arrays数组内容:" + Arrays.toString(arrs)); } }
String[] arrs = s3.toArray(new IntFunction<String[]>() { @Override public String[] apply(int value) { return new String[value]; } });
扩展知识:调用 toArray 方法先去遍历流里每个数据,遍历数据就会知道数据总长度。把长度传递给 value
然后 new String[0]; 创建一个固定长度数组,创建一个字符串数组,把流里元素遍历到字符串里存储起来,把数组返回
这样声明一个返回结果是字符串数组
stream.toList 流对象可以直接调用转换了【返回一个不可变的集合】,不需要使用 Collectors.toList【返回一个可变集合】这样的工具类也可以操作了
使用还是有差别
41:异常概述、体系
什么是异常? 异常是程序在“编译”或者“执行”的过程中可能出现的问题,注意:语法错误不算在异常体系中。 比如:数组索引越界、空指针异常、 日期格式化异常,等… 为什么要学习异常? 异常一旦出现了,如果没有提前处理,程序就会退出JVM虚拟机而终止. 研究异常并且避免异常,然后提前处理异常,体现的是程序的安全, 健壮性
package com.itheima.d3_exception; /** 目标:异常的概念和体系。 什么是异常? 异常是程序在"编译"或者"执行"的过程中可能出现的问题。 异常是应该尽量提前避免的。 异常可能也是无法做到绝对避免的,异常可能有太多情况了,开发中只能提前干预!! 异常一旦出现了,如果没有提前处理,程序就会退出JVM虚拟机而终止,开发中异常是需要提前处理的。 研究异常并且避免异常,然后提前处理异常,体现的是程序的安全, 健壮性!!! Java会为常见的代码异常都设计一个类来代表。 异常的体系: Java中异常继承的根类是:Throwable。 Throwable(根类,不是异常类) / \ Error Exception(异常,需要研究和处理) / \ 编译时异常 RuntimeException(运行时异常) Error : 错误的意思,严重错误Error,无法通过处理的错误,一旦出现,程序员无能为力了, 只能重启系统,优化项目。 比如内存奔溃,JVM本身的奔溃。这个程序员无需理会。 Exception:才是异常类,它才是开发中代码在编译或者执行的过程中可能出现的错误, 它是需要提前处理的。以便程序更健壮! Exception异常的分类: 1.编译时异常:继承自Exception的异常或者其子类,编译阶段就会报错, 必须程序员处理的。否则代码编译就不能通过!! 2.运行时异常: 继承自RuntimeException的异常或者其子类,编译阶段是不会出错的,它是在 运行时阶段可能出现,运行时异常可以处理也可以不处理,编译阶段是不会出错的, 但是运行阶段可能出现,还是建议提前处理!! 小结: 异常是程序在编译或者运行的过程中可能出现的错误!! 异常分为2类:编译时异常,运行时异常。 -- 编译时异常:继承了Exception,编译阶段就报错,必须处理,否则代码不通过。 -- 运行时异常:继承了RuntimeException,编译阶段不会报错,运行时才可能出现。 异常一旦真的出现,程序会终止,所以要研究异常,避免异常,处理异常,程序更健壮!! */ public class ExceptionDemo { public static void main(String[] args) { int[] arr = {10, 20, 40}; System.out.println(arr[0]); System.out.println(arr[1]); System.out.println(arr[2]); System.out.println(arr[3]); System.out.println("-----------程序截止---------"); } }
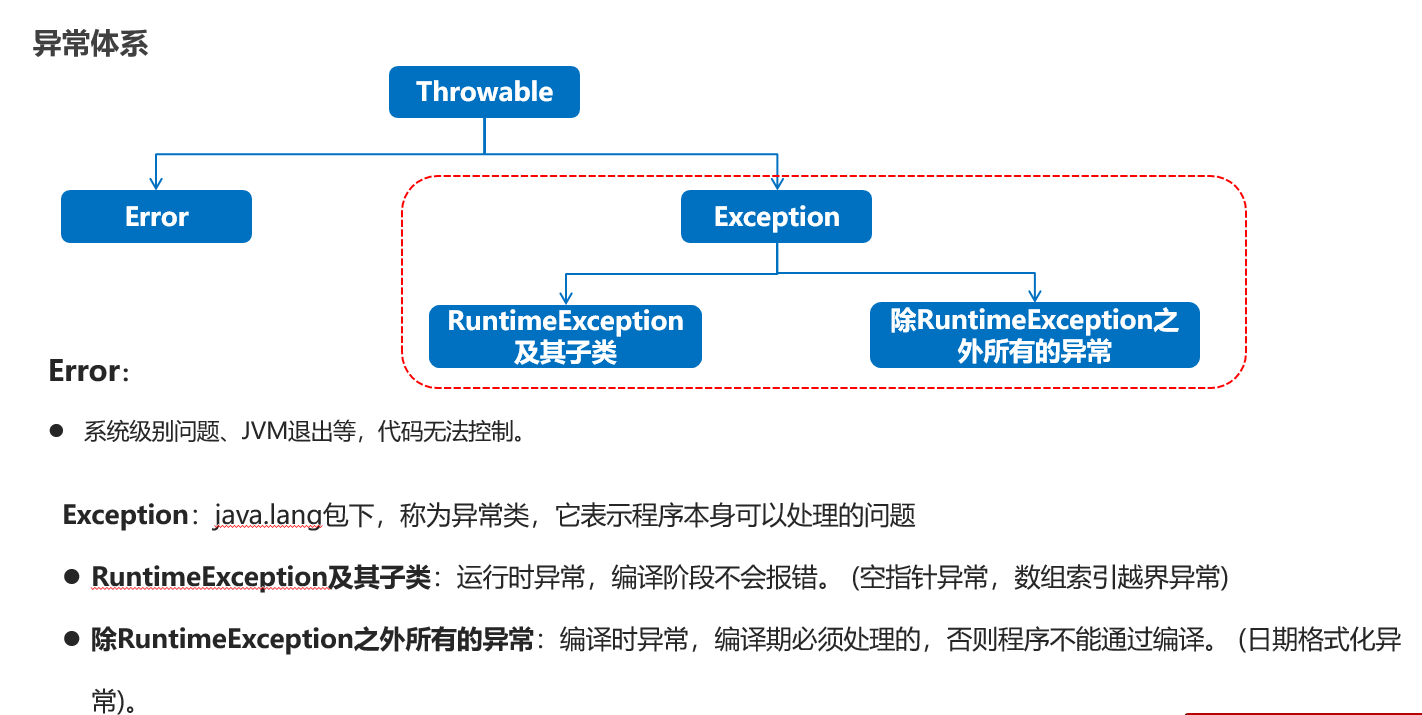

异常是什么?
异常是代码在编译或者执行的过程中可能出现的错误。
异常分为几类?
编译时异常、运行时异常。
编译时异常:没有继承RuntimeExcpetion的异常,编译阶段就会出错。
运行时异常:继承自RuntimeException的异常或其子类,编译阶段不报错,运行可能报错。
学习异常的目的?
避免异常的出现,同时处理可能出现的异常,让代码更稳健
42:常见的运行时异常
运行时异常:直接继承自RuntimeException或者其子类,编译阶段不会报错,运行时可能出现的错误。
运行时异常示例:
数组索引越界异常: ArrayIndexOutOfBoundsException
空指针异常 : NullPointerException,直接输出没有问题,但是调用空指针的变量的功能就会报错。
数学操作异常:ArithmeticException
类型转换异常:ClassCastException
数字转换异常: NumberFormatException
运行时异常:一般是程序员业务没有考虑好或者是编程逻辑不严谨引起的程序错误,自己的水平有问题!
package com.itheima.d4_exception_runtimeException; /** 拓展: 常见的运行时异常。(面试题) 运行时异常的概念: 继承自RuntimeException的异常或者其子类, 编译阶段是不会出错的,它是在运行时阶段可能出现的错误, 运行时异常编译阶段可以处理也可以不处理,代码编译都能通过!! 1.数组索引越界异常: ArrayIndexOutOfBoundsException。 2.空指针异常 : NullPointerException。 直接输出没有问题。但是调用空指针的变量的功能就会报错!! 3.类型转换异常:ClassCastException。 4.迭代器遍历没有此元素异常:NoSuchElementException。 5.数学操作异常:ArithmeticException。 6.数字转换异常: NumberFormatException。 小结: 运行时异常继承了RuntimeException ,编译阶段不报错,运行时才可能会出现错误! */ public class ExceptionDemo { public static void main(String[] args) { System.out.println("程序开始。。。。。。"); /** 1.数组索引越界异常: ArrayIndexOutOfBoundsException。*/ int[] arr = {1, 2, 3}; System.out.println(arr[2]); // System.out.println(arr[3]); // 运行出错,程序终止 /** 2.空指针异常 : NullPointerException。直接输出没有问题。但是调用空指针的变量的功能就会报错!! */ String name = null; System.out.println(name); // null // System.out.println(name.length()); // 运行出错,程序终止 /** 3.类型转换异常:ClassCastException。 */ Object o = 23; // String s = (String) o; // 运行出错,程序终止 /** 5.数学操作异常:ArithmeticException。 除数不能为 0 */ //int c = 10 / 0; /** 6.数字转换异常: NumberFormatException。 */ //String number = "23"; String number = "23aabbc"; Integer it = Integer.valueOf(number); // 运行出错,程序终止 System.out.println(it + 1); System.out.println("程序结束。。。。。"); } }
43:常见的编译时异常
编译时异常:不是RuntimeException或者其子类的异常,编译阶就报错,必须处理,否则代码不通过。 编译时异常示例: String date = "2015-01-12 10:23:21"; SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss"); Date d = sdf.parse(date); System.out.println(d); 如上:日期解析异常 ParseException 编译时异常的作用是什么: 是担心程序员的技术不行,在编译阶段就爆出一个错误, 目的在于提醒不要出错! 编译时异常是可遇不可求。遇到了就遇到了呗。 编译时异常的特点 编译时异常:继承自Exception的异常或者其子类 编译阶段报错,必须处理,否则代码不通过
package com.itheima.d5_exception_javac; import java.text.ParseException; import java.text.SimpleDateFormat; import java.util.Date; /** 目标:常见的编译时异常认识。 编译时异常:继承自Exception的异常或者其子类,没有继承RuntimeException "编译时异常是编译阶段就会报错", 必须程序员编译阶段就处理的。否则代码编译就报错!! 编译时异常的作用是什么: 是担心程序员的技术不行,在编译阶段就爆出一个错误, 目的在于提醒! 提醒程序员这里很可能出错,请检查并注意不要出bug。 编译时异常是可遇不可求。遇到了就遇到了呗。 了解: */ public class ExceptionDemo { public static void main(String[] args) throws ParseException { String date = "2015-01-12 10:23:21"; // 创建一个简单日期格式化类: SimpleDateFormat sdf = new SimpleDateFormat("yyyy/MM-dd HH:mm:ss"); // 解析字符串时间成为日期对象 Date d = sdf.parse(date); // System.out.println(d); } }
44:异常的默认处理流程
默认会在出现异常的代码那里自动的创建一个异常对象:ArithmeticException 【默认创建】
异常会从方法中出现的点这里抛出给调用者,调用者最终抛出给JVM虚拟机。
虚拟机接收到异常对象后,先在控制台直接输出异常栈信息数据。
直接从当前执行的异常点干掉当前程序。
后续代码没有机会执行了,因为程序已经死亡

package com.itheima.d6_exception_default; /** 目标:异常的产生默认的处理过程解析。(自动处理的过程!) (1)默认会在出现异常的代码那里自动的创建一个异常对象:ArithmeticException。 (2)异常会从方法中出现的点这里抛出给调用者,调用者最终抛出给JVM虚拟机。 (3)虚拟机接收到异常对象后,先在控制台直接输出异常栈信息数据。 (4)直接从当前执行的异常点干掉当前程序。 (5)后续代码没有机会执行了,因为程序已经死亡。 小结: 异常一旦出现,会自动创建异常对象,最终抛出给虚拟机,虚拟机 只要收到异常,就直接输出异常信息,干掉程序!! 默认的异常处理机制并不好,一旦真的出现异常,程序立即死亡! */ public class ExceptionDemo { public static void main(String[] args) { System.out.println("程序开始。。。。。。。。。。"); chu(10, 0); System.out.println("程序结束。。。。。。。。。。"); } public static void chu(int a , int b){ System.out.println(a); System.out.println(b); int c = a / b; System.out.println(c); } }
45:编译时异常处理机制
编译时异常是编译阶段就出错的,所以必须处理,否则代码根本无法通过
编译时异常的处理形式有三种:
出现异常直接抛出去给调用者,调用者也继续抛出去【和默认处理方式一致】
出现异常自己捕获处理,不麻烦别人。
前两者结合,出现异常直接抛出去给调用者,调用者捕获处理。
ctrl + alt + t 键:idea各种快捷补全

package com.itheima.d7_exception_handle; import java.io.FileInputStream; import java.io.FileNotFoundException; import java.io.InputStream; import java.text.ParseException; import java.text.SimpleDateFormat; import java.util.Date; /** 目标:编译时异常的处理方式一。 编译时异常:编译阶段就会报错,一定需要程序员处理的,否则代码无法通过!! 抛出异常格式: 方法 throws 异常1 , 异常2 , ..{ } 建议抛出异常的方式:代表可以抛出一切异常, 方法 throws Exception{ } 方式一: 在出现编译时异常的地方层层把异常抛出去给调用者,调用者最终抛出给JVM虚拟机。 JVM虚拟机输出异常信息,直接干掉程序,这种方式与默认方式是一样的。 虽然可以解决代码编译时的错误,但是一旦运行时真的出现异常,程序还是会立即死亡! 这种方式并不好! 小结: 方式一出现异常层层跑出给虚拟机,最终程序如果真的出现异常,程序还是立即死亡!这种方式不好! */ public class ExceptionDemo01 { // public static void main(String[] args) throws ParseException, FileNotFoundException { // System.out.println("程序开始。。。。。"); // parseTime("2011-11-11 11:11:11"); // System.out.println("程序结束。。。。。"); // } // // public static void parseTime(String date) throws ParseException, FileNotFoundException {
// 这种需要抛出多个可能出现异常写法不优雅,直接抛出 Exception 一个异常就行 // SimpleDateFormat sdf = new SimpleDateFormat("yyyy/MM-dd HH:mm:ss"); // Date d = sdf.parse(date); // System.out.println(d); // // InputStream is = new FileInputStream("E:/meinv.jpg"); // } public static void main(String[] args) throws Exception { System.out.println("程序开始。。。。。"); parseTime("2011-11-11 11:11:11"); System.out.println("程序结束。。。。。"); } public static void parseTime(String date) throws Exception { SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss"); Date d = sdf.parse(date); System.out.println(d); InputStream is = new FileInputStream("E:/meinv.jpg"); } }

package com.itheima.d7_exception_handle; import java.io.FileInputStream; import java.io.FileNotFoundException; import java.io.InputStream; import java.text.ParseException; import java.text.SimpleDateFormat; import java.util.Date; /** 目标:编译时异常的处理方式二。 方式二:在出现异常的地方自己处理,谁出现谁处理。 自己捕获异常和处理异常的格式:捕获处理 try{ // 监视可能出现异常的代码! }catch(异常类型1 变量){ // 处理异常 }catch(异常类型2 变量){ // 处理异常 }... 监视捕获处理异常企业级写法: try{ // 可能出现异常的代码! }catch (Exception e){ e.printStackTrace(); // 直接打印异常栈信息 } Exception可以捕获处理一切异常类型! 小结: 第二种方式,可以处理异常,并且出现异常后代码也不会死亡。 这种方案还是可以的。 但是从理论上来说,这种方式不是最好的,上层调用者不能直接知道底层的执行情况! */ public class ExceptionDemo02 { public static void main(String[] args) { System.out.println("程序开始。。。。"); parseTime("2011-11-11 11:11:11"); System.out.println("程序结束。。。。"); } public static void parseTime(String date) { try { SimpleDateFormat sdf = new SimpleDateFormat("yyyy/MM-dd HH:mm:ss"); Date d = sdf.parse(date); System.out.println(d); InputStream is = new FileInputStream("E:/meinv.jpg"); } catch (Exception e) { e.printStackTrace(); // 打印异常栈信息 } } // public static void parseTime(String date) { // try { // SimpleDateFormat sdf = new SimpleDateFormat("yyyy/MM-dd HH:mm:ss"); // Date d = sdf.parse(date); // System.out.println(d); // // InputStream is = new FileInputStream("E:/meinv.jpg"); // } catch (FileNotFoundException|ParseException e) { // e.printStackTrace(); // 打印异常栈信息 // } // } // public static void parseTime(String date) { // try { // SimpleDateFormat sdf = new SimpleDateFormat("yyyy/MM-dd HH:mm:ss"); // Date d = sdf.parse(date); // System.out.println(d); // // InputStream is = new FileInputStream("E:/meinv.jpg"); // } catch (FileNotFoundException e) { // e.printStackTrace(); // 打印异常栈信息 // } catch (ParseException e) { // e.printStackTrace(); // } // } // public static void parseTime(String date) { // try { // SimpleDateFormat sdf = new SimpleDateFormat("yyyy/MM-dd HH:mm:ss"); // Date d = sdf.parse(date); // System.out.println(d); // } catch (ParseException e) { // // 解析出现问题 // System.out.println("出现了解析时间异常哦,走点心!!"); // } // // try { // InputStream is = new FileInputStream("E:/meinv.jpg"); // } catch (FileNotFoundException e) { // System.out.println("您的文件根本就没有啊,不要骗我哦!!"); // } // } }

出现异常自己处理,没有抛出去,上层调用者不知道底层执行情况
1:解决方案1:捕获到错误 使用 return 返回一个信息给上层调用者
2:异常处理方式 3 【让上层调用者知道底层执行情况,来决定要不要做其他事情】
package com.itheima.d7_exception_handle; import java.io.FileInputStream; import java.io.InputStream; import java.text.ParseException; import java.text.SimpleDateFormat; import java.util.Date; /** 目标:编译时异常的处理方式三。 方式三: 在出现异常的地方把异常一层一层的抛出给最外层调用者, 最外层调用者集中捕获处理!!(规范做法) 小结: 编译时异常的处理方式三:底层出现的异常抛出给最外层调用者集中捕获处理。 这种方案最外层调用者可以知道底层执行的情况,同时程序在出现异常后也不会立即死亡,这是 理论上最好的方案。 虽然异常有三种处理方式,但是开发中只要能解决你的问题,每种方式都又可能用到!! */ public class ExceptionDemo03 { public static void main(String[] args) { System.out.println("程序开始。。。。"); try { parseTime("2011-11-11 11:11:11"); System.out.println("功能操作成功~~~"); } catch (Exception e) { e.printStackTrace(); System.out.println("功能操作失败~~~"); } System.out.println("程序结束。。。。"); } public static void parseTime(String date) throws Exception { SimpleDateFormat sdf = new SimpleDateFormat("yyyy、MM-dd HH:mm:ss"); Date d = sdf.parse(date); System.out.println(d); InputStream is = new FileInputStream("D:/meinv.jpg"); } }
1、异常处理的总结 在开发中按照规范来说第三种方式是最好的:底层的异常抛出去给最外层,最外层集中捕获处理 实际应用中,只要代码能够编译通过,并且功能能完成,那么每一种异常处理方式似乎也都是可以的。
46:运行时异常处理机制
运行时异常的处理形式
运行时异常编译阶段不会出错,是运行时才可能出错的,所以编译阶段不处理也可以。
按照规范建议还是处理:建议在最外层调用处集中捕获处理即可。
package com.itheima.d8_exception_handle_runtime; /** 目标:运行时异常的处理机制。 可以不处理,编译阶段又不报错。 按照理论规则:建议还是处理,只需要在最外层捕获处理即可
运行时候异常,chu 方法 不需要 throws 抛出异常【默认抛出】
编译时候异常需要手动 throws 跑出去【不抛就报错】 */ public class Test { public static void main(String[] args) { System.out.println("程序开始。。。。。。。。。。"); try { chu(10, 0); } catch (Exception e) { e.printStackTrace(); } System.out.println("程序结束。。。。。。。。。。"); } public static void chu(int a , int b) { // throws RuntimeException{ System.out.println(a); System.out.println(b); int c = a / b; System.out.println(c); } }

package com.itheima.d8_exception_handle_runtime; import java.util.Scanner; /** 需求:需要输入一个合法的价格为止 要求价格大于 0 */ public class Test2 { public static void main(String[] args) { Scanner sc = new Scanner(System.in); while (true) { try { System.out.println("请您输入合法的价格:"); String priceStr = sc.nextLine(); // 转换成double类型的价格 double price = Double.valueOf(priceStr); // 判断价格是否大于 0 if(price > 0) { System.out.println("定价:" + price); break; }else { System.out.println("价格必须是正数~~~"); } } catch (Exception e) { System.out.println("用户输入的数据有毛病,请您输入合法的数值,建议为正数~~"); } } } }
47:自定义异常
自定义异常的必要? Java无法为这个世界上全部的问题提供异常类。 如果企业想通过异常的方式来管理自己的某个业务问题,就需要自定义异常类了。 自定义异常的好处: 可以使用异常的机制管理业务问题,如提醒程序员注意。 同时一旦出现bug,可以用异常的形式清晰的指出出错的地方。 自定义异常的分类 1、自定义编译时异常 定义一个异常类继承Exception. 重写构造器 在出现异常的地方用throw new 自定义对象抛出, 作用:编译时异常是编译阶段就报错,提醒更加强烈,一定需要处理!! 2、自定义运行时异常 定义一个异常类继承RuntimeException. 重写构造器。 在出现异常的地方用throw new 自定义对象抛出! 作用:提醒不强烈,编译阶段不报错!!运行时才可能出现!!
package com.itheima.d9_exception_custom; /** 目标:自定义异常(了解) 引入:Java已经为开发中可能出现的异常都设计了一个类来代表. 但是实际开发中,异常可能有无数种情况,Java无法为 这个世界上所有的异常都定义一个代表类。 假如一个企业如果想为自己认为的某种业务问题定义成一个异常 就需要自己来自定义异常类. 需求:认为年龄小于0岁,大于200岁就是一个异常。 自定义异常: 自定义编译时异常. a.定义一个异常类继承Exception. b.重写构造器。 c.在出现异常的地方用throw new 自定义对象抛出! 编译时异常是编译阶段就报错,提醒更加强烈,一定需要处理!! 自定义运行时异常. a.定义一个异常类继承RuntimeException. b.重写构造器。 c.在出现异常的地方用throw new 自定义对象抛出! 提醒不强烈,编译阶段不报错!!运行时才可能出现!! */ public class ExceptionDemo { public static void main(String[] args) { // try { // checkAge(-34); // } catch (ItheimaAgeIlleagalException e) { // e.printStackTrace(); // } try { checkAge2(-23); } catch (Exception e) { e.printStackTrace(); } } public static void checkAge2(int age) { if(age < 0 || age > 200){ // 抛出去一个 运行时 异常对象给调用者 // throw :在方法内部直接创建一个异常对象,并从此点抛出 // throws : 用在方法申明上的,抛出方法内部的异常 throw new ItheimaAgeIlleagalRuntimeException(age + " is illeagal!"); }else { System.out.println("年龄合法:推荐商品给其购买~~"); } } public static void checkAge(int age) throws ItheimaAgeIlleagalException { if(age < 0 || age > 200){ // 抛出去一个 编译时 异常对象给调用者 // throw :在方法内部直接创建一个异常对象,并从此点抛出 // throws : 用在方法申明上的,抛出方法内部的异常 throw new ItheimaAgeIlleagalException(age + " is illeagal!"); }else { System.out.println("年龄合法:推荐商品给其购买~~"); } } }
package com.itheima.d9_exception_custom; /** 自定义的编译时异常 1、继承Exception 2、重写构造器 */ public class ItheimaAgeIlleagalException extends Exception{ public ItheimaAgeIlleagalException() { } public ItheimaAgeIlleagalException(String message) { super(message); } }
package com.itheima.d9_exception_custom; /** 自定义的编译时异常 1、继承RuntimeException 2、重写构造器 */ public class ItheimaAgeIlleagalRuntimeException extends RuntimeException{ public ItheimaAgeIlleagalRuntimeException() { } public ItheimaAgeIlleagalRuntimeException(String message) { super(message); } }

 浙公网安备 33010602011771号
浙公网安备 33010602011771号