

python开发基础篇:六:多线程
1:线程学习参考文档 https://www.cnblogs.com/Eva-J/articles/8306047.html

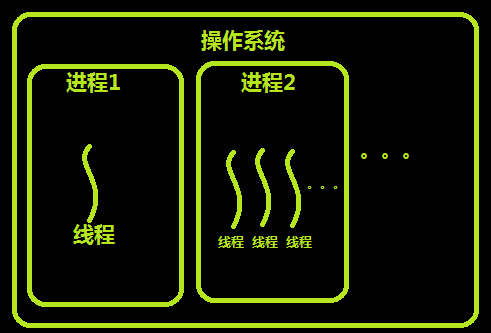
进程:
进程的概念,程序并不能单独运行,只有将程序装载到内存中,系统为它分配资源(内存,栈等)才能运行,而这种执行的程序就称之为进程。
程序和进程的区别就在于:程序是指令的集合,它是进程运行的静态描述文本;进程是程序的一次执行活动,属于动态概念。
在多道编程中,我们允许多个程序同时加载到内存中,在操作系统的调度下,可以实现并发地执行。这是这样的设计,大大提高了CPU的利用率。
进程的出现让每个用户感觉到自己独享CPU,因此,进程就是为了在CPU上实现多道编程而提出的。
多道程序设计可以让我们一边听音乐一边写world,同时干好几件事情,单核cpu也能同时做好几件事情,进程交替执行,看上去多个程序并发
进程切换问题:
切换进程,资源切换问题,两个进程需要记录进程的状态,以及内存存储了哪些东西:为了资源分配以及内存状态的保存切换才 出现了进程的概念
多道系统才需要考虑内存分配资源和资源切换的问题,单道系统不需要考虑进程的事情,就一个程序在内存中运行
多进程就是为了实现多道编程实现的
进程:
执行中的程序,机器中资源分配的最小单位
线程:
线程是轻量级的进程
人上课:听 + 写 + 看屏幕
进程在一个时间点只能做一个事情,使用进程实现人上课这个事情需要开启3个进程来完成三件事,3个进程分别听,写,看屏幕
但是开辟线程很浪费资源和时间
进程和线程的关系:
进程包含着线程
进程是资源分配的最小单位,线程才是CPU调度的最小单位.
每一个进程中至少有一个线程
进程只做数据存储,只关心和他相关的资源(共用文件,共用全局变量,数据,内存本质上是通的)
线程负责使用数据来执行代码
线程不能独立存在,线程一定实在进程里面,线程要是想执行需要依靠数据,数据存储在进程中,线程中本质上只存储和它自己执行直接相关的数据
线程与进程的区别可以归纳为以下4点: 1:地址空间和其它资源(如打开文件):进程间相互独立,同一进程的各线程间共享。某进程内的线程在其它进程不可见 2:通信:进程间通信IPC,线程间可以直接读写进程数据段(如全局变量)来进行通信——需要进程同步和互斥手段的辅助,以保证数据的一致性。 3:调度和切换:线程上下文切换比进程上下文切换要快得多。 4:在多线程操作系统中,进程不是一个可执行的实体,真正被cpu执行的其实是线程而不是进程
1:多进程 开启进程的时间长(建内存,存数据,分配资源等事情)
开启线程的时间非常短(不需要建内存啥的)
2:cpu在进程之间切换 慢(切换重新读内存,资源什么的)
cpu在线程之间切换 快(不需要重新读取资源了,直接切了执行就行)
如果两个任务 需要共享内存 又想实现异步 需要开启多线程
如果两个任务 需要数据隔离(比如qq和微信) 又想实现异步 需要开启多进程
多线程的好处:
线程轻量级,且同一个进程之间的多个线程资源是共享的
进程间通信IPC:
基于网络或者基于文件通信的
cpu实际上调度的是线程
编译型语言:
一般可以一个进程内多个线程可以同时在多个cpu里面跑,和进程一样在不同cpu上运行
python:
由于全局解释器锁一个进程内多个线程没有真正实现并发,同一时间只能一个线程真正在cpu运行
可并发执行是线程自己本身的特点,线程可以同时利用多个cpu并发执行的,只是python上不行
python全局解释器锁:
python语言运行在解释器上,解释器从上到下解释代码,解释器读取程序的时候,拿到一个数据
由于线程之间数据共享,两个线程同时去访问进程里面的这个数据,就出现了数据不安全的问题,这时候只能把数据上锁---
这样麻烦,每保护一个数据必须就给这个数据上一个锁,
所以解释器为了不出现上面数据不安全的情况:cpython解释器没有给数据资源上锁,
线程1只要想要被cpu执行,那么线程1在被cpu调度的这里上一把锁,然后线程1调度数据被cpu执行,执行完了之后线程1解锁
然后线程1陷入等待cpu的状态,第2个线程去上锁,拿数据,被cpu执行,解锁------这样造成同一时间只会有一个线程被cpu调用执行
-----GIL:全局解释器锁:实现同一时间只会有一个线程被cpu执行
早期都是单核机器,单核机器没有这个问题,只有一个线程被cpu调度
现在都是多核机器,python就有了这个问题,
假设4个cpu,就算python一个进程开了多个线程也只能使用一个cpu
随机使用4个cpu中的一个来执行线程,但是这4个cpu同一时刻只能有一个线程进来执行,
因为全局解释器锁的原因,一个进程多个线程只放一个线程进来给cpu执行
多个进程之间的调度可以使用不同的cpu,进程之间没有关联,数据不共享,
同一个进程之间的两个线程由于全局解释器锁同一时间只能有一个线程出去给cpu调用 -----这就是python当作多线程的缺陷
GIL:全局解释器锁(cpython解释器自己加上的)
是解释器的问题,和python编程语言没有关系,是解释器在调度的时候自己加的锁,为了数据的安全
去掉CIL还需要保证数据安全加很多细粒度的锁(想要保护的数据都加锁)这样的效率还不如GIL,
细粒度的加锁让只有一个线程能访问到数据,剩下的线程仍然在等,还是有等待的时间
程序中最终解决的:io阻塞浪费时间
同步:
异步:
计算型任务:
不涉及任何io读写操作,没有任何等待和阻塞,都是计算的任务,做计算都需要依赖cpu运行----不适合python多线程来编写,可以使用多进程来解决
高io阻塞任务:
inpt,读文件,写文件,等待网络,accept,recv,print这些读写操作都是io阻塞任务(爬虫,网页编程,socket)----使用python多线程
解释型语言:
很难实现一个进程内多个线程真正的并发,因为不知道线程执行的这一行代码只会还有什么代码
没有办法像java那种编译新语言,编译后把所有代码都读取到,这样就知道线程之间如何调度的
可以在解释器这一层再去做一些操作,python这种解释型语言不行,不知道下一行代码执行啥,
多线程在不同cpu上并发的话就会出现这种资源抢占的的问题---导致数据不安全
所有的解释型语言基本都有这个问题,php等都是一样
开启线程也需要成本的,只是成本非常低
内存中的线程
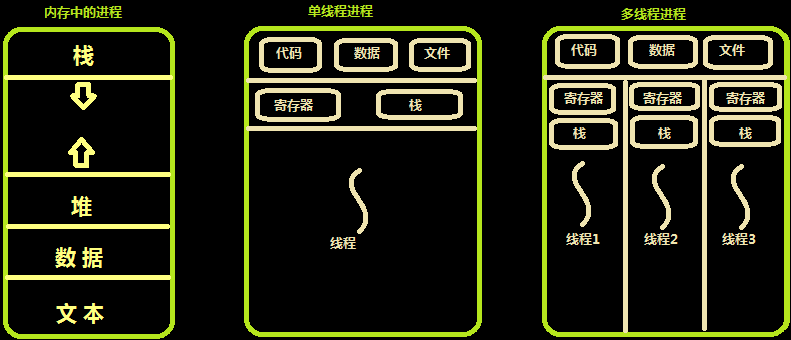
线程之间共享:代码,数据,文件
每一个线程还是都要有有自己的寄存器和栈,寄存器和栈不共享的
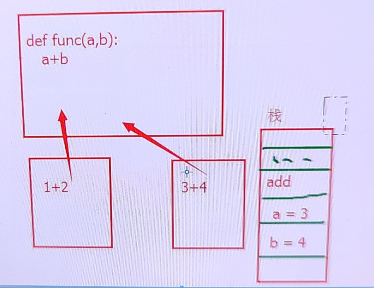
如下一段代码
def func(a, b):
a + b
假设2个或者多个线程都执行func这段代码,
线程1传参数a = 1,b = 2
线程2传参数a = 3,b = 4
这2个线程共享这段代码,代码从进程里读出来的,进程级别的数据,
而线程1的 1+ 2和线程2的 3+4这两个操作应该在线程里就完成了,这两个操作是线程独立完成的
这两个操作需要借助线程各自的栈来执行,栈是存储数据的,寄存器也是存储数据的
栈可能先存储一些进程里的数据或者代码进来,
线程1执行a+b的操作,线程执行add操作,栈存储执行的指令先存储个add,再存储一个a=1 再存储一个b=2
线程里1+2的操作实际上是线程里往栈里存储这样一些数据,然后交给cpu去执行,cpu从栈里读取数据再去操作
所有栈这个特有的数据只能属于线程自己,因为线程1的栈和线程2的栈存储的数据都不同,各自所有的
线程来讲也有他简单存储的他每一步操作所需要的代码独立的空间,
线程共享的只是代码以及进程当中一些全局的变量,
线程里开一个小的空间去存储一些简单的操作和只属于我这个线程的变量,线程的空间的开辟消耗的时间相对开启一个进程来说是很少的
使用多线程去开启高计算型的在cpython解释器下去执行python代码其实是有屏障的----
线程更加的轻量级,是cpu调度的最小单位
进程是资源分配的最小单位
进程之间资源不共享,而线程之间资源共享,因为资源分配给进程的,而线程又属于线程,所有分配给进程的资源线程都可以共享
开启线程的时空开销都比开启进程要小,且cpu在线程之间切换比cpu在进程之间切换快
这就是为什么是有多线程的原因
2:python线程模块 thread、threading和Queue 一般都使用threading模块,更高级
一个程序当中可以同时开启多进程+多线程
# 多线程的开启和join的使用 from threading import Thread import os import time def func(): time.sleep(1) print("hello world", os.getpid()) if __name__ == '__main__': t_l = [] for i in range(10): t = Thread(target=func) t_l.append(t) t.start() [t.join() for t in t_l] print(os.getpid()) 主线程执行print(os.getpid()),子线程执行func函数 如果不加join,那么主线程和子线程的执行是异步的,主线程print(os.getpid())不会等待子线程执行才去执行 如果希望主线程等待子线程结束才执行print(os.getpid()): 如上[t.join() for t in t_l],这样实现了多线程并发效果了,又能和主线程实现同步而不是异步了 主线程现在和几个子线程是同步的, 主线程执行到开启子线程完成后在join处阻塞等待并发的子线程执行完成后再执行主进程 相当于主线程运行过程中插入了子线程并发过程----这就是join的效果
开启线程的第二种class类方式 计算开启线程数量 多个子线程 共享这个 数据 方法1: from threading import Thread import os import time class MyThread(Thread): count = 0 # 静态属性计数线程开启的次数,类和所有这个类实例化对象共享的 # 每开启一次线程都会调用start,调用start实际上都会调用run方法,所有下面每次调用一次run方法让类的静态属性count+1就行 def run(self): MyThread.count += 1 time.sleep(1) print("hello world", os.getpid()) if __name__ == '__main__': for i in range(10): t = MyThread() t.start() print(t.count) # 打印:10,开启了10个线程 方法2:__new__构造方法 from threading import Thread import os import time class MyThread(Thread): __count = 0 def __new__(cls, *args, **kwargs): cls.__count += 1 return super().__new__(cls) def run(self): time.sleep(1) print("hello world", os.getpid()) def obj_count(self): return self.__count if __name__ == '__main__': for i in range(10): t = MyThread() t.start() print(t.obj_count()) # 10
使用class类来创建线程:给run方法传递参数需要依赖init方法 from threading import Thread import os import time class MyThread(Thread): count = 0 # 静态属性计数线程开启的次数,类和所有这个类实例化对象共享的 def __init__(self, arg1, arg2): super().__init__() self.arg1 = arg1 self.arg2 = arg2 # 每开启一次线程都会调用start,调用start实际上都会调用run方法,所有下面每次调用一次run方法让类的静态属性count+1就行 def run(self): MyThread.count += 1 time.sleep(1) print(f"hello world:{self.name}:{self.arg1}:{self.arg2}:{os.getpid()}") if __name__ == '__main__': for i in range(10): t = MyThread(i, i*"*") t.start() print(t.count) # 打印:10,开启了10个线程 1:开启线程使用类的继承方式开启 2:类的继承方式开启线程给线程中传参,在实例化类的时候添加一个init方法,init方法需要实现父类的init方法 3:类里面的静态变量直接被多个线程共享,只有线程共享数据的时候静态变量一定是共享的,对各对象共享一个类而已
上面的MyThread自己重构的类还有一些属于自己的属性:
self.name:线程的名字,python解释器执行的时候起的名字,线程模块做好的事情,这个线程名字可以自己修改
所以使用类方式开启多线程可以使用self对象拿到很多属性,函数方式开启线程属性拿不到
threading.currentThread():查看线程名和线程id import threading def func(i): info = threading.currentThread() # threading.currentThread()返回一个对象,查看对象属性和方法 print(info) # <Thread(Thread-1, started 11512)> print(i, info.getName(), info.ident) # 0 Thread-1 11512 for i in range(10): t = threading.Thread(target=func, args=(i,)) t.start() <Thread(Thread-1, started 5640)> Thread-1:线程名 started 5640:线程id(ident)
threading.enumerate():返回正在运行着的线程列表 import threading import time def func(i): time.sleep(1) info = threading.currentThread() # threading.currentThread()返回一个对象,查看对象属性和方法 print(info) # <Thread(Thread-1, started 11512)> print(i, info.getName(), info.ident) # 0 Thread-1 11512 for i in range(10): t = threading.Thread(target=func, args=(i,)) t.start() print(threading.enumerate()) # 返回正在运行着的线程列表 # [<_MainThread(MainThread, started 10472)>, <Thread(Thread-1, started 11172)>, # <Thread(Thread-2, started 4032)>, <Thread(Thread-3, started 14324)>, # <Thread(Thread-4, started 11164)>, <Thread(Thread-5, started 10552)>, # <Thread(Thread-6, started 17272)>, <Thread(Thread-7, started 21808)>, # <Thread(Thread-8, started 1812)>, <Thread(Thread-9, started 21396)>, # <Thread(Thread-10, started 10788)>] # 返回11个,1个主线程和开的10个子线程
threading.activeCount():返回正在运行的线程的个数 import threading import time def func(i): time.sleep(1) info = threading.currentThread() # threading.currentThread()返回一个对象,查看对象属性和方法 print(info) # <Thread(Thread-1, started 11512)> print(i, info.getName(), info.ident) # 0 Thread-1 11512 for i in range(10): t = threading.Thread(target=func, args=(i,)) t.start() print(threading.activeCount()) # 11 返回正在运行的线程的个数
3:socket多线程
server.py from threading import Thread import socket def func(conn): conn.send(b"hello") ret = conn.recv(1024).decode("utf8") print(ret) conn.close() if __name__ == '__main__': sk = socket.socket() sk.bind(("127.0.0.1", 9999)) sk.listen() while 1: conn, addr = sk.accept() t = Thread(target=func, args=(conn, )) t.start() sk.close()
client.py import socket sk = socket.socket() sk.connect(("127.0.0.1", 9999)) ret = sk.recv(1024).decode("utf8") print(ret) msg = input(">>>>>>>") sk.send(msg.encode('utf8')) sk.close()
4:守护线程 t.setDaemon(True)
from threading import Thread import time def func(): print("开始执行子线程") time.sleep(3) print("子线程执行完毕") if __name__ == '__main__': t = Thread(target=func) t.setDaemon(True) # 把t这个线程设置成为守护线程 # 进程模块设置守护进程是一个属性:p.daemon = True, # 线程这里设置是一个方法:t.setDaemon(True) t.start() t2 = Thread(target=func) t2.start() t2.join() # 主进程等待t2子线程结束 t2.join():主进程等待t2子线程结束,执行着这一行代码才算主线程结束,主进程一直在这里等着的 先打印的是t1的,如果t2的先打印的话,那么主进程也结束了,那么t1守护线程被强制终止打印不出来的 守护线程/进程 守护线程/进程都是等待主线程/进程中的代码执行完毕,主进程代码执行完毕的一瞬间守护线程就结束了 是主线程/进程的代码执行完毕而不是主线程/进程结束 没有加t2.join的话情况如下: 但是守护线程结束不意味着主线程结束,主线程还在等着t2子线程结束, t2执行完毕,主线程也执行结束了, 加了t2.join的话情况如下: t2.join等待t2结束是最后一句话,执行完了这句话主线程代码才结束, t2线程需要先执行完毕才会主线程执行 t2.join -> 主线程代码执行完毕 -> 守护线程结束
5:线程 lock同步锁,解决线程里不安全的并发
多线程里的数据也不安全:
主进程的存储共享数据,线程从主进程当中读取数据一定要经过cpu,cpu执行到线程某行代码也是cpu去读取数据
时间片轮到某个线程,cpu从进程中读取数据,多个线程,线程1,线程2,线程3.....从主进程中读取数据
由于GIL全局解释器锁,这个主进程中的多个线程不可能真正的并发,线程1轮转cpu运行,线程2就会闲置进不去
假设线程中运行代码temp = temp - 1,主进程中的数据temp = 4,
计算机中线程运行n = temp,temp = n - 1,先从主进程当中读取temp = 4,放在线程1的寄存器里,
寄存器存储着4,1,sub减法,线程1刚从主进程中拿到这些数据放到自己线程里的寄存器的时候还没计算完时间片轮转到线程2了,
然后时间片轮转的时候线程1的数据和运行状态保存起来,然后线程2进来也做temp = temp - 1的操作,也从进程中读取数据,这时候temp还是4
然后线程2做和线程1一样的操作,4,1,sub这些数据存储到线程2的寄存器里,这之后可能线程2没有轮转马上计算完sub减法了,那么temp-1变成3个,然后把3写回到主进程的temp里了
这时候主进程的temp = 3了,时间片轮转给线程1,线程l执行sub减法,这时候还是temp = 4,减去1,temp = 3,线程1运行后temp还是3又写入主进程里了
这样2个线程减了2次,temp还是等于3----------数据不安全
同一时间几个线程虽然只有一个线程能使用cpu,但是仍然造成线程里的数据不安全------
GIL锁和数据安全没有关系,CIL锁只是锁线程的,只让同一时间只有一个线程能访问cpu,并不能保证数据安全,
GIL是给线程加的一把锁,让同一时间只有一个线程能访问cpu,必须线程拿到钥匙才能出去访问cpu,时间片执行完了就还钥匙,别的线程又能拿钥匙进去执行了----线程加锁
CIL锁是锁线程的,普通的lock锁是锁数据的
# 不安全的并发实例 from threading import Thread import time def func(): global n temp = n # 从进程中获取n放在线程当中自己的寄存器里了, # 创造时间片轮转的机会,造成不安全的并发,取了n然后碰巧时间片轮转 time.sleep(0.01) n = temp-1 # 得到结果在存回进程中,因为修改的是一个global的数据,数据需要存回进程 n = 100 t_lis = [] for i in range(100): t = Thread(target=func) t_lis.append(t) t.start() [t.join() for t in t_lis] print(n) # 98或者99 在线程中取数据之后sleep睡一下,对这个n减了100次,结果不等于0,并发不安全 这种情况下只能选择线程加锁 from threading import Thread def func(): global n temp = n n = temp-1 n = 100 t_lis = [] for i in range(100): t = Thread(target=func) t_lis.append(t) t.start() [t.join() for t in t_lis] print(n) # 0 假设没有sleep每个线程取数据后睡上0.01s看上去数据是安全的,打印0,因为程序执行比较快
# 解决不安全的并发:线程加锁 from threading import Thread from threading import Lock import time def func(): global n lock.acquire() temp = n time.sleep(0.01) n = temp - 1 lock.release() if __name__ == '__main__': n = 100 lock = Lock() t_lis = [] for i in range(100): t = Thread(target=func) t_lis.append(t) t.start() [t.join() for t in t_lis] print(n) # 0
1:GIL不是锁数据而是锁线程
2:多线程中特殊情况(获取全局变量,然后做一些操作,然后把这个变量又赋值给全局变量会出现问题),任然要多数据加锁
3:加锁之后程序执行慢,现在的执行速度和同步加了join的效果差不多,sleep睡的0.01s完全没有被复用起来,一个个程序轮流睡0.01s,这个例子搞多线程没什么意义
6:死锁 解决死锁使用Rlock
科学家吃面问题: 科学家吃到面需要两个东西:1:筷子 2:面
左边是面右边是叉子,同时拿到叉子和面才能开始吃
一把叉子,一盘面,拿到叉子和面的科学家吃一口轮转被人了,别人也需要叉子和面才能吃
4个科学家多线程取拿叉子和面,为了避免叉子和面被多个人拿着,需要加锁,
筷子加锁
面加锁
某个人拿到叉子和面吃面的时候别的线程不能冲进来还拿叉子和面,所以加锁
from threading import Thread from threading import Lock import time kz = Lock() # 筷子的锁 m = Lock() # 面的锁 def eat(name): kz.acquire() print(f"{name}:拿到筷子了") m.acquire() print(f"{name}:拿到面了") print(f"{name}:吃面了") m.release() kz.release() def eat2(name): m.acquire() print(f"{name}:拿到面了") time.sleep(0.1) kz.acquire() print(f"{name}:拿到筷子了") print(f"{name}:吃面了") kz.release() m.release() t1 = Thread(target=eat, args=('李二狗1',)) t1.start() t2 = Thread(target=eat2, args=('李二狗2',)) t2.start() t3 = Thread(target=eat, args=('李二狗3',)) t3.start() t4 = Thread(target=eat2, args=('李二狗4',)) t4.start() 上面代码死锁: 李二狗2:拿到面了不撒手,想要拿筷子 李二狗3:拿到筷子了不撒手,想要面 一个拿着面,一个人拿着筷子,两个人都不撒手都想吃----死锁 程序就卡住了执行不下去了 使用场景: 数据n和数据m都需要被多线程使用到,这是毫无关系的两个数据资源,所以需要使用两把锁保证多线程的数据安全 在不同的线程中恰好多这两数据进行操作,一个线程拿到一把锁,另外一个线程拿到另外一把锁 ----死锁
lock:互斥锁,就一把钥匙,拿到一把钥匙,又来一个人想要拿钥匙实不会再给这个人钥匙的 Rlock:递归锁,在同一个线程或者进程可以被多次acquire,一个线程acquire后其他线程再acquire就会阻塞,
这个线程acquire多次就需要release多次别的线程才能acquire上锁进来操作数据 # 互斥锁lock from threading import Lock lock = Lock() lock.acquire() lock.acquire() print(123) lock.release() lock.release() 代码阻塞在第二个acquire # 递归锁RLock from threading import RLock lock = RLock() # 递归锁,同一个地方允许别人对他进行多次accquire lock.acquire() lock.acquire() print(123) lock.release() lock.release() 代码不会阻塞,打印123,
在多线程并发的情况下,同一个线程中 如果出现多次acquire就可能产生死锁线程现象,使用Rlock递归锁就能避免死锁
使用递归锁多个线程也只能使用一把递归锁,多次acquire是一把锁acquire这样才不会出问题,否则仍然两把锁使用的话还是可能产生死锁
还是可能一个人拿到一把,另外一个人拿到一把,使用一把锁才可能拿到锁别人就代码阻塞进不来了
# 使用递归锁解决科学家吃面死锁问题 from threading import Thread from threading import RLock import time kz = m = RLock() # 同一吧锁 def eat(name): kz.acquire() print(f"{name}:拿到筷子了") m.acquire() print(f"{name}:拿到面了") print(f"{name}:吃面了") m.release() kz.release() def eat2(name): m.acquire() print(f"{name}:拿到面了") time.sleep(0.1) kz.acquire() print(f"{name}:拿到筷子了") print(f"{name}:吃面了") kz.release() m.release() t1 = Thread(target=eat, args=('李二狗1',)) t1.start() t2 = Thread(target=eat2, args=('李二狗2',)) t2.start() t3 = Thread(target=eat, args=('李二狗3',)) t3.start() t4 = Thread(target=eat2, args=('李二狗4',)) t4.start() 递归锁: 递归锁能在一个线程多次acquire, 只要线程1 acquire一次,别的线程不能再acquire拿到锁了,别的线程需要等待这个线程1 归还全部的钥匙才能拿到钥匙上锁 递归锁这里让线程1从kz.acquire()执行到最后面的kz.release()结束,别的线程才能进
7:信号量 Semaphore:一把锁可以设置多把钥匙
from threading import Semaphore sem = Semaphore(5) # 一把锁有5把钥匙 sem.acquire() sem.acquire() sem.acquire() sem.acquire() sem.acquire() print(5) sem.acquire() # 阻塞在这里,只有5把钥匙 print(6)
from threading import Semaphore from threading import Thread import time import random def func(n, sem): sem.acquire() print(f"thread-{n} start") time.sleep(random.random()) print(f"thread-{n} done") sem.release() sem = Semaphore(5) for i in range(20): Thread(target=func, args=(i, sem)).start() 信号量: 保证同一时间只能有几个线程在并发执行,假设信号量设置5,那么最大同时并发5个线程,其他的想执行遇到acquire就阻塞 着5个线程中有一个释放了锁那么马上又可能进来一个线程,就是一直最大保证5个线程并发执行锁住的代码 信号量和线程池有什么区别 相同点: 在信号量acquire之后,和线程池一样,只能同时在执行的只能有n个(n要么是线程池的个数,要么就是Semaphore的参数) 不同点: 1:开的线程数不一样,线程池来说,一共只开5个线程,5个线程轮询执行任务, 而Semaphore信号量有几个任务就开几个线程,只不过不能不能同时执行,受到锁的限制 对有信号量限制的程序来说,可以同时执行很多线程吗? 可以,信号量只是限制加锁和解锁中间的代码的最大并发数量,而加锁和解锁以外的代码没有被锁住, 起20个线程,加锁和解锁以外的代码还是20个线程高并发,只有在加锁和解锁中的代码才会出现有锁的5个5个并发的问题 线程池来说不管加锁还是不加锁,最终只能有5个线程在运行,而是使用信号量20个线程都能运行起来 只不过最多5个线程执行信号量加锁的代码而已 信号量的特点:信号量实际上并不影响线程或者进程的并发,只是在加锁的接端进行流量(卡着5个5个的执行限制
8:事件 Event:可以限制阻塞非阻塞的锁
event事件内部有一个flge标志 刚刚创建的时候flage = False
wait()遇到flge=Flase就阻塞等着,如果遇到flge=True就不会阻塞
set() False——>True
clear() True——False
连接mysql数据库 需求如下: 连接3次数据库 每0.5s连接一次 创建一个事件来标志数据库的连接情况 如果连接成功,就显示成功, 否则就报错 from threading import Event from threading import Thread import time import random def conn_sql(): # 连接数据库 count = 0 while not e.is_set(): # 判断事件e的标志flag是False还是True,如果是False就进来 if count >= 3: raise TimeoutError # 连接3次还不成功,主动抛出连接超时异常 print(f"尝试连接第{count + 1}次") count += 1 e.wait(0.5) # 如果连接不成功只阻塞0.5s,默认一直阻塞 print("连接sql成功") # 检测数据库的连接是否正常 def check_conn(): # 模拟连接检测的时间 time.sleep(random.randint(1, 3)) e.set() # 如果数据通的就告诉事件的标志数据可以连接, # 如果检测时间之内检测好了那么收到信号就能直接连接成功了,否则就连接不成功 e = Event() check = Thread(target=check_conn) check.start() conn = Thread(target=conn_sql) conn.start() 尝试连接3次sql,如果都没连接成功就是失败了,否则就是连接成功了
9:定时器 Timer
from threading import Timer def hello(): print("hello world") t = Timer(1, hello) 定时开启一个线程,执行一个任务, 两个参数 参数1:定时多久之后,单位是s 参数2:要执行的任务,函数名 等待s秒之后才开启线程
10:条件 Condition
条件condition = 锁lock + wait 的功能 condition就算con.acquire()拿到钥匙也会一直在con.wait()阻塞等着,等着一个信号给他,信号是con.notify给他的 con.notify:传递信号,notify只能接收数字参数,必须接收整数, notify(1)告诉对方可以放行一个线程, notify(n)可以放行n个线程 notify:放行几个线程,解除几个线程的阻塞 notify_all():全部放行 acquire,release,join,notify,notify_all:条件一共5个方法 import threading def run(n): con.acquire() # 拿锁 con.wait() # 等着,等信号这里才放行 print(f"run the thread: {n}") con.release() if __name__ == '__main__': con = threading.Condition() # 条件 for i in range(10): t = threading.Thread(target=run, args=(i,)) t.start() while 1: inp = input(">>>>>") # 输入几个数字就放行几个信号 if inp == "q": break con.acquire() # condition里面的锁是递归锁 if inp == "all": con.notify_all() else: con.notify(int(inp)) con.release()
11:队列 Queue
multiprocessing模块一个Queue队列模块,这个队列涉及到IPC通信,进程直之间的通信 queue模块一个Queue队列模块,线程之间安全的通信数据 Queue普通队列:先进先出 import queue q = queue.Queue() # 数据多线程内使用安全的,这个队列自带锁 q.get() q.put() q.qsize() LifoQueue:后进先出(类似栈的机制) import queue lfq = queue.LifoQueue() lfq.put(1) lfq.put(2) lfq.put(3) lfq.put(4) print(lfq.get()) # 4 print(lfq.get()) # 3 print(lfq.get()) # 2 print(lfq.get()) # 1 PriorityQueue:优先级队列,值越小越优先,值相同就先进先出 import queue pq = queue.PriorityQueue() pq.put((10, "a")) pq.put((5, "b")) pq.put((15, "c")) pq.put((2, "d")) print(pq.get()) # (2, 'd') print(pq.get()) # (5, 'b') print(pq.get()) # (10, 'a') print(pq.get()) # (15, 'c') 先进后出,先进后出:栈 线程版本的生产者消费者模型:多线程 + Queue队列就行了
12:线程池 concurrent.futures.ThreadPoolExecutor
concurrent.futures:线程池和进程池,是用来做池操作的模块 开启线程也需要成本,只是成本比开启进程低很多 高I/O的请假下,开多线程 开线程也需要成本,所以也不能开启任意多个线程 所以使用到线程池
futures.ThreadPoolExecutor():开线程池
futures.ProcessPoolExecutor():开进程池
futures.ThreadPoolExecutor:线程池的使用 1:submit:提交任务 2:res.result:获取返回值,结果对象.result获取结果 3:thread_pool.shutdown:close+join,不让再往线程池提交任务并且阻塞主线程在这里等待线程池运行结束
4:map:迭代提交多个任务 from concurrent import futures import time import random def func(n): print(n) time.sleep(random.randint(1, 3)) return n*n thread_pool = futures.ThreadPoolExecutor(5) # 进程池: cpu个数 + 1 # 线程池默认线程数: cpu个数 * 5 4核开启20个线程问题不大 可以自己填写参数设置线程数,不设置使用默认的值 res_lis = [] for i in range(10): ret = thread_pool.submit(func, i) # print(ret.result()) # 这样打印出内容程序变成同步的了.一个任务提交到线程池运行完得到结果后才提交下一个任务 res_lis.append(ret) thread_pool.shutdown() # 等于:close+join close不让再往线程池提交任务,还join阻塞在这里等待所有任务执行完 print([res.result() for res in res_lis]) # [0, 1, 4, 9, 16, 25, 36, 49, 64, 81] # 这样获取结果才能让程序异步又能得到程序执行的结果,全部提交完任务后获取一个结果对象,任务提交完后才一次性取获取10个任务的结果 # 现在10个任务提交到5个线程池里还是并发的,被5个线程池执行,后面统一拿结果 # res.result()阻塞是为了等待任务执行完得到结果,任务执行完拿到结果的时候可能其他线程还在执行着的,可以拿到结果就打印,也可以多个任务全部执行完了打印结果 # 10个人任务放到线程池里取运行 # submit方法:合并了创建线程对象和start的功能 # 先执行5个,所以运行一开始就打印5个,然后后面哪个任务先执行完了就再放进来一个任务再执行
线程池的map方法提交执行任务:
1:map不支持操作返回值,
2:map天生异步执行任务,
3:第2个参数接收可迭代对象的数据,迭代出来的每一个对象的参数传递给func函数来充当参数执行任务 from concurrent import futures import time import random def func(n): print(n) time.sleep(random.randint(1, 3)) return n * n thread_pool = futures.ThreadPoolExecutor(5) thread_pool.map(func, range(10))
线程池futures.ThreadPoolExecutor设置回调函数:add_done_callback from concurrent import futures import time import random def func(n): print(n) time.sleep(random.randint(1, 3)) return n * n def call_back(args): print(args.result()) thread_pool = futures.ThreadPoolExecutor(5) thread_pool.submit(func, 1).add_done_callback(call_back) func执行后return返回的值返回给回调函数 call_back了.被args接收,args获取这个值需要.result获取
多线程实现生产者消费者模式: from threading import Thread import time import random import queue q = queue.Queue() def produce(food): for i in range(20): q.put(f"{food}:{i + 1}") time.sleep(random.random()) def consumer(name): while 1: food = q.get() if food is None: q.put(None) break time.sleep(1) print(f"{name}消费了一个:{food}") p1 = Thread(target=produce, args=("包子",)) p1.start() p2 = Thread(target=produce, args=("馒头",)) p2.start() c1 = Thread(target=consumer, args=("李一狗",)) c1.start() c2 = Thread(target=consumer, args=("李二狗",)) c2.start() c3 = Thread(target=consumer, args=("李三狗",)) c3.start() p1.join() p2.join() q.put(None)
13:进程池 concurrent.futures.ProcessPoolExecutor
ProcessPoolExecutor进程池和ThreadPoolExecutor操作都一模一样--------进程池
concurrent.futures这个模块统一了入口和方法,用法完全一样,简化了操作,降低了学习的时间成本
concurrent.futures.ProcessPoolExecutor:进程池模块实现爬取网页 from concurrent import futures import requests def get_url(url): ret = requests.get(url) ret.encoding = "utt8" return {"url": url, "status_code": ret.status_code, "content": ret.text } def parser(dic): dic = dic.result() print(dic['url'], dic["status_code"], len(dic["content"])) if __name__ == '__main__': process_pool = futures.ProcessPoolExecutor(5) url_l = ["https://www.baidu.com/", "https://www.sogou.com/", "https://www.hao123.com/", "https://www.jd.com/", "https://www.taobao.com/"] for url in url_l: process_pool.submit(get_url, url).add_done_callback(parser) process_pool.shutdown()
分类:
Python篇【基础语法+进阶】


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· Docker 太简单,K8s 太复杂?w7panel 让容器管理更轻松!