python开发基础篇:三
1:python中包的使用 模块+包详解:https://www.cnblogs.com/Eva-J/articles/7292109.html
1:什么是包 把解决一类问题的模块放在同一个文件夹里:这就是包 2:python2 只有带上 init.py文件的文件夹才能是一个包 python3没有这个文件也无所谓,也不会出问题
1:使用os模块创建一个目录结构 import os os.makedirs('glance/api') # 创建目录 os.makedirs('glance/cmd') os.makedirs('glance/db') l = [] l.append(open('glance/__init__.py', 'w')) # open函数可以打开创建文件夹,open函数返回文件句柄 # 文件句柄放到l列表里了,为了关闭 l.append(open('glance/api/__init__.py', 'w')) l.append(open('glance/api/policy.py', 'w')) l.append(open('glance/api/versions.py', 'w')) l.append(open('glance/cmd/__init__.py', 'w')) l.append(open('glance/cmd/manage.py', 'w')) l.append(open('glance/db/models.py', 'w')) l.append(open('glance/db/__init__.py', 'w')) map(lambda f: f.close(), l)
2:包的注意事项 1.关于包相关的导入语句也分为import和from ... import ...两种, 但是无论哪种,无论在什么位置,在导入时都必须遵循一个原则: 凡是在导入时带点的,点的左边都必须是一个包,否则非法。 可以带有一连串的点,如item.subitem.subsubitem,但都必须遵循这个原则。 2.对于导入后,再使用时就没有这种限制了, 点的左边可以是包,模块,函数,类(它们都可以用点的方式调用自己的属性)。 3.对比import item 和from item import name的应用场景: 如果我们想直接使用name那必须使用后者。
3:import XXX:使用很多点导入包里面的文件: 凡是在导入时带点的,点的左边都必须是一个包,否则非法。 点的左边可以是包,模块,函数,类(它们都可以用点的方式调用自己的属性)。 从包中import一个模块 import glance.api.policy # 很多 .导入 glance.api.policy.get() # 这样才能执行policy模块的get方法 import glance.api.policy as pl # 使用as重命名也是可以的--长的时候 pl.get()
4:from xxx import xxx :导入包的模块 from glance.api import policy # 这种直接导入policy整个模块 policy.get() # from glance.api import policy.get # 这样写法报错,import后面导入的不能加点 . ,只能是名字 from glance.api.policy import get # 这种是直接导入模块的方法,但是这个内存空间再定义get就会出问题 get()
5:把路径放在sys.path里那就直接import sys.path.append('./dir') 相对路径写法 sys.path.insert(0,r'E:\\Users\ywt\PycharmProjects\Python_Development\day21\dir') 绝对路径写法 import sys sys.path.insert(0, r'E:\Users\ywt\PycharmProjects\Python_Development\day21\dir') print(sys.path) from glance.api import policy policy.get()
# 因为glance文件就在dir下面,所以找glance.api下的policy文件直接就通过sys.path里的路径找到了,可以直接导入
下面就是dir下面glance文件目录和模块内容
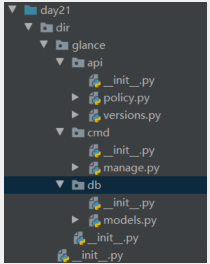
上面文件目录中的内容
api/__init__.py from . import policy,versions api/policy.py def get(): print('from policy.py') versions.py def create_resource(conf): print('from version.py: ',conf) cmd/__init__.py 内容为空 cmd/manage.py def main(): print('from manage.py') db/__init__.py 内容为空 db/models.py def register_models(engine): print('from models.py: ',engine) galance/__init__.py from . import api # import sys # print(sys.path) dir/__init__.py from . import glance
6:import glance:不能直接导入包来使用 模块导入相当于执行了py文件,导入一个包没得执行,没有py文件 导入模块执行导入的模块,而导入一个包默认执行包里的init.py文件,没有执行里面包里的其他py文件 如果想import一个包glance就能使用glance文件里的所有模块 执行包里面的全部的py文件,需要在glance的init里面 把下面几个包和文件再导入进来,然后再在最底层的文件夹impot导入文件 如果是py2版本,没有init不能从glance里面import导入包和文件 py3没有init也能导入文件,但是是有缺陷的, # 现在import glance的时候执行glance里面的init:就会执行from glance import api,cmd,db # 然后导入api包的时候执行api里面的init,就会执行:from glance.api import policy,versions # 现在policy和versions等模块都被当前模块导入了,就能够执行里面的函数和方法 如下: import glance glance.api.policy.get() from glance.api.policy import get # 这样导入就算没init文件也没有问题 # 上面的都是使用绝对路径导入模块,不能挪动,但是直观
下面是glance文件目录的整体架构和模块内容
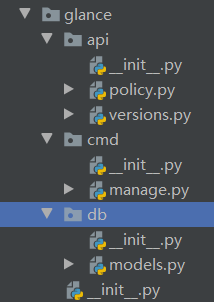
api/__init__.py from glance.api import policy, versions # 不会报错,因为init和policy在同一个路径下 api/policy.py def get(): print('from policy.py') api/versions.py def create_resource(conf): print('from version.py: ',conf) cmd/__init__.py None cmd/manage.py def main(): print('from manage.py') db/__init__.py None db/models.py def register_models(engine): print('from models.py: ',engine) glance/__init__.py print('glance init') from glance import api, cmd, db
7:相对路径导入模块: . 表示当前目录 和 .. 表示上一层目录 使用相对路径导入,就全部使用相对路径 想import glance就能使用glance里面所有的方法 import glance执行glance下面的init:from . import api 从当前路径导入api模块 import api又执行api下面的init:from . import policy,versions 从当前路径导入policy和versions模块,加载进来没有问题,在模块外面能够正常使用 如果不发生glance内部模块和模块之间引用的话,这样相对路径使用是没有问题的 而且glance内部模块之间的相对路径的调用只能在这个包的外面使用 from dir import glance glance.api.policy.get() # import glance 就执行了glance里面的init, # from . import api 从当前路径去导入api模块 # 使用相当路径可以随意移动包,只要能找到包的位置就可以使用包里的模块了 # 不能在包里使用这个模块了 # glance是一个包,现在在包的外面使用是正常的 # 但是在glance包里面的policy文件里面调用这个 # cmd文件夹里面的东西--包下面的文件之间发生调用且执行包里面的文件的时候使用 . 这种相对导入方式就会有问题(包外面正常执行) # 当去导入模块的时候,这个模块的东西全部都被加载到内存里了,就能知道上一层是谁了 # 假设当前002文件导入一个glance模块,glance模块的东西全部加载到内存里了,知道glance模块的上一层是谁,自己002文件也有一个路径,
# 导入glance,glance自己也有一个内部路径,glance里面的这些init记录了当前所在路径的位置,以及下一层的位置,通过. 记住了路径关系了,
# 包里面的模块通过 from .. import cmd然后直接在内部运行这个模块,找不到上一层的上一层 # 通过 .. 行为在模块里面的policy文件找不到,当前路径在policy所在的文件夹,通过 ..行为找上一层,再找上一层就找不到,
# 从最外面就能找到,因为外面有一个总的目录的,所以很清晰的知道一层,下一层都有什么内容(外面通过导入glance模块,glance模块里面的__init__会搭建一个结构目录)
# 所以外面运行通过相对路径能找到
# 而在dir/glance/api/policy.py这个py文件使用 .. 导入cmd,在policy当前文件运行,以policy为文件起点,
当前因为没有和外面impor glance,无法知道整个glance的目录结构,所以找不到policy文件的上一层的上一层
而外面调用能够找到是因为外面最开始旧导入了glance文件了解了glance文件的整个目录结构,层层结构都很清晰所以可以导入
# 只要使用了相当路径的方式,那么整体使用相对路径的整个包里面的所有模块在执行的时候都会出问题,只能外包调用才没问题 # 相对路径可以理解为导入模块的当前路径相对往前位置的路径来导入 # 比如api文件里面的init文件:from . import policy,versions # 就是以当前api文件夹为起点路径导入policy和versions
import 一个glance模块就能拿到glance模块下的所有的内容都拿出来,
import glance执行glance下的init,init里面写下from . import api,cmd, db
import api的时候又执行api下的init,init里写下from . import policy, versions
所以只要import glance,那么下一级一直执行init把所有的py文件都加载进来了
加载进来了没有问题,在外部调用也ok,
但是glance包内部发生模块和模块的相互使用相对路径调用时候脚本不能直接在glance包的范围下面直接执行
而是需要在整个glance包的外部去导入使用,不能在glance包范围下里直接运行模块
1:使用绝对路径:不管在包的内部还是外部导入了就能使用,但是不能随意挪动包 2:使用相对路径:能随意挪动包,包里的模块如果想使用其它模块的内容只能使用相对路径(绝对路径不好使的), 使用了相对路径就不能在包内直接执行py模块了,只能包外面使用
import json:就是import一个json包,json的包都是在包外面调用使用,包内部怎么在模块之间调用
怎么使用多少相对路径,外部不关注,不会打开json包单独cmd执行json的一个模块文件,
包里面的代码都是别人写好封装好直接外部导入使用就行,只关心提供的方法和怎么调用,不会执行包里面的文件
可以直接把glance这个包,可以直接copy到python的sit_packages里面,python解释器pip安装包的目录下面
把包放进去了就直接使用,
完整实现了一个功能包给别人使用的使用可以使用相对路径,
目前主要还是使用绝对路径,大部分时间要在包里执行其他代码 相对路径的范围:就以包的位置为相对路径,一般不会超过这个包,包和包之间一般不能相互依赖 但是也可以依赖,如果依赖的话安装一个包的使用需要安装另一个包 包:独立,包可以引用python解释器的内置模块,但是不应该依赖之前写过的包 依赖的话安装这个包还需要安装一个依赖的包
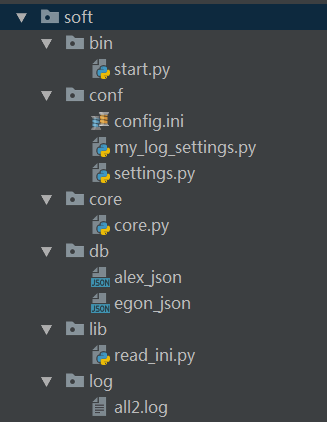
软件开发项目结构: bin目录:存放执行脚本,开始文件,程序入口,执行start.py程序就能直接跑起来了 conf目录:存放配置文件(一般给运维人员看的,比如登录验证需要从文件读取用户名和密码,文件的路径存放在conf里)
假设core的login代码需要打开文件,文件路径从conf读取 core目录:存放核心逻辑,我们写的所有的代码 db目录:存放数据库文件,比如登录认证的用户文件ser_info lib目录:存放自定义的模块与包(自己写的完整功能的模块或者包,通用模块但是没有自动安装在py解释器的,自己写的) log目录:存放日志,过程,把中间结果或者过程记录到log文件里,便于查看调试
pycham执行的时候会主动把项目路径(比如下面的soft文件)和文件执行的路径(比如下面的start执行时候的bin路径)添加到sys.path里面
正常的cmd运行不会把项目根目录和脚本运行路径bin添加到sys.path,所以都需要自己手动添加path路径
如下:在bin文件的start模块下使用sys和os模块把项目跟目录添加到sys.path里面’
import os
import sys
sys.path.insert(0, os.path.dirname(os.getcwd()))
类似这样把项目根目录添加了path路径后无论是不是在pycham执行都不会报错了
上面是一个固定模式,固定bin/satrt.py文件的东西
一:项目根目录添加到sys.path里,后面模块所有的内容都可以直接使用了
二:内部后面的模块导入都基于根目录文件夹导入,因为根目录已经在sys.path了,
2:异常处理 https://www.cnblogs.com/Eva-J/articles/7281240.html
写代码过程中:程序中难免出现错误,而错误分成两种 1.语法错误:(这种错误,根本过不了python解释器的语法检测,必须在程序执行前就改正)
比如:prin(111 2.逻辑错误:(逻辑错误)这种是能处理的异常 1/0 2+"3" [][3] {}['key'] int('a') 这种错不是语法错误
python中一些常见的异常: AttributeError 试图访问一个对象没有的属性,比如foo.x,但是foo没有属性x IOError 输入/输出异常;基本上是无法打开文件 ImportError 无法引入模块或包;基本上是路径问题或名称错误 IndentationError 语法错误(的子类;代码没有正确对齐 IndexError 下标索引超出序列边界,比如当x只有三个元素,却试图访问x[5] KeyError 试图访问字典里不存在的键 KeyboardInterrupt Ctrl+C被按下 NameError 使用一个还未被赋予对象的变量 SyntaxError Python代码非法,代码不能编译(个人认为这是语法错误,写错了) TypeError 传入对象类型与要求的不符合 UnboundLocalError 试图访问一个还未被设置的局部变量,基本上是由于另有一个同名的全局变量,导致你以为正在访问它 ValueError 传入一个调用者不期望的值,即使值的类型是正确的
程序一旦发生错误,就从错误的位置停下来了,不在继续执行后面的内容
但是我们有时候希望发生错误程序不处理还能继续运行
异常处理 程序一旦发生错误,就从错误的位置停下来了,不再继续执行后面的内容 使用try和except就能处理异常 try是我们需要处理的代码 except 后面跟一个错误类型,当代码发生错误且错误类型符合的时候,就会执行except中的代码 except支持多分支 except Exception(万能异常):
一个能处理所有错误的类型 : Exception 有了万能的处理机制仍然需要把能预测到的问题单独处理(有些错误) 单独处理的所有内容都应该写在万能异常之前 else : 没有异常的时候执行else中的代码 (类似for else和while else没有被中断从头执行到尾就会执行else里面的代码,被终端就不会执行了) finally : 不管代码是否异常,最终都会执行 finally和return相遇的时候,依然会执行 finally一般在函数里做异常处理用,不管是否异常去做一些收尾工作(比如关闭数据库关闭文件) try except:基础的异常语句,try里面的代码有没有错误一定执行的,执行的过程中发生错误才执行except里面的代码,不遇到不执行
# finally和return相遇的时候 依然会执行 def func(): try: f = open('file' ,'w') return True except: return False finally: print('执行finally了') f.close()
# 打开文件后:不管发不发生异常都要close文件,出不出问题都会关闭在这里 # return:函数只要执行到return会跳出函数,return一般都是作为函数的结尾(上面的代码遇到return会不会执行finally,理论上不会执行,但是实际是执行的)
# try里面遇到了return,如果有finally依然会先执行finally,然后才返回函数值 # 可以看成执行到return看到后面有finally函数先finally运行 # 然后再return返回 print(func())
# 执行了finally里面的代码也,也拿到了return的返回值,
# 当执行try里面的内容的时候遇到了return如果又有finally依然先执行finally
# 在return True返回回去的时候依然执行finally,先执行finally里面的内容然后才接到返回值
# 执行到return True时候发现try下面还有一个finally,先执行finally里面的内容,然后才把True返回出来
try except一般处理小段的代码逻辑,而不是大段的完整的整个程序
大段的程序加try except一般只在代码上线真的提供服务,可以让程序全线奔溃,
但是不让用户看到复杂的报错可以加try except,可以直接处理程序闪退了,也不要打印报错
try异常处理代码一小段逻辑而不是处理大段完整的整个程序
程序上线可以使用try,except让程序闪退
try...except应该尽量少用,因为它本身就是你附加给你的程序的一种异常处理的逻辑,与你的主要的工作是没有关系的
这种东西加的多了,会导致你的代码可读性变差,只有在有些异常无法预知的情况下,
才应该加上try...except,其他的逻辑错误应该尽量修正
调试的使用不要大段的加try except
# as语句捕获程序异常:使用变量捕获报错信息,查看是什么错误 try: int(input('>>>>>>>')) except Exception as error: print('你错了,傻逼', error) # 你错了,傻逼 invalid literal for int() with base 10: 'asad'
3:面向对象基础
# 面向函数和过程编写游戏:人狗大战 def Dog(name, blood, aggr, kind): dog = { 'name': name, 'blood': blood, # 血量 'aggr': aggr, # 攻击力 'kind': kind, } def bite(person): # 嵌套函数,不能外部调用了 person['blood'] -= dog['aggr'] print('%s被咬了,掉了%s的血' % (person['name'], dog['aggr'])) dog['bite'] = bite # 把函数名bite添加到dog字典然后返回出去 return dog def Person(name, blood, aggr, sex): person = { 'name': name, 'blood': blood, # 血量 'aggr': aggr, # 攻击力 'sex': sex, } def attack(dog): dog['blood'] -= person['aggr'] print('%s被打了,掉了%s的血' % (dog['name'], person['aggr'])) person['attack'] = attack return person # 使用def函数编写人和狗两个对象,让代码精简了 方便增加人物(每增加任务调用一次person函数就行) 方便修改 人物更加规范 —— 人模子,模板 jin = Dog('金老板', 1000, 100, 'teddy') alex = Person('狗剩儿', 100, 1, '不详') # nezha = Person('哪吒',200,2,'不详') print(jin) jin['bite'](alex) # jin这条狗咬了alex,调用bite函数 alex['attack'](jin) # Dog函数和Person函数 都是定义了一类事物, # 直到调用了函数,赋值了之后才真的有了一个实实在在的人或狗 # 面向对象编程:先有类才有对象 # 模子:就是类,抽象的,我能知道有什么属性,有什么技能,但不能知道属性具体的值 # jin alex nezha:就是对象,有具体的值,属性和技能都是根据类规范的 # 类是抽象的:狗类,人类,没有具体物体 # 对象是具体的:哪吒,李二狗都是对象,有属性的值 # 类:人类,狗类,手机,桌子 # 对象:李二狗,隔壁旺财
python中万物皆对象 dict:整个字典就是一个类,列表,元组,数字,字符串都是类 {'k':'v'}:这个字典就是一个对象,一个字典类的具体化 所有的数据都是类,(字典,列表,元组,字符串,数字等都是类) 最终具体到是一个什么值,1,或者[1,2]等都是对象 print(list) # <class 'list'> 这都是python提供给我们的类。类 d = {'k': 'v'} print(d) # {'k': 'v'} d是一个实际的值。对象,根据dict类创造的对象
python中自定义类:class class 类名: 属性 = 'a' print(类名.属性) 类名的作用:就是操作属性 查看属性
3:类里面的init方法:
只要调用这个类,就会首先调用init方法,调用init就得到一个返回的值,这个返回的值就是一个对象
本质上调用类的时候:
__new__是在实例创建之前被调用的:因为它的任务就是创建实例然后返回该实例对象,是个静态方法(cls)
__init__是当实例对象创建完成后被调用的:然后设置对象属性的一些初始值,通常用在初始化一个类实例的时候。是一个实例方法(self)
对象=类名() 过程: 类名()就是调用类,首先会创造出一个空的self实例对象, 调用init方法往self里面放值,调用结束会把self return出来 self最终返回给了调用的变量alex,self里的所有的值都给了alex 调用类的时候类名括号里的参数会被这里接受,执行init方法,返回self这个对象 self本质就是一个对象(self对象可以看成一个字典,可以存储很多东西) self字典就是一个对象,alex和self其实是一回事
class Person: # 类名 country = 'China' # 创造了一个只要是这个类就一定有的属性(类属性,静态属性) def __init__(self, *args): # 初始化方法init,self是实例对象,是一个必须传的参数 print(self.__dict__) # {} 一开始self是一个空字典 # self就是一个可以存储很多属性的大字典,self就是指代这个实例对象,调用类返回的时候 # 把self返回了,返回给变量alex,可以通过alex这个变量对象操作字典里的值 # init函数不能写return,self自动作为返回值返回给外面的变量alex(自动返回self) self.name = args[0] # 往self字典里添加属性的方式发生了一些变化,使用self.xxx = xxx而不是self[xxx]=xxx self.hp = args[1] self.aggr = args[2] self.sex = args[3] print(id(self)) # self的内存地址和外面的alex一样 print(self.__dict__) # {'name': '狗剩儿', 'hp': 100, 'aggr': 1, 'sex': '不详'} # 打印初始为空,往里面加了值后的self def walk(self, n): # 方法,(本质是函数)一般情况下必须传self参数,且必须写在第一个 # 后面还可以传其他参数,是自由的 print('%s走走走,走了%s步' % (self.name, n)) print(Person.country) # 通过类名就可以查看类中的静态(类)属性,不需要实例化就可以查看 alex = Person('狗剩儿', 100, 1, '不详') # 类名还可以实例化返回对象,alex对象 # 实例化:得到一个实例 print(alex.__dict__['name']) alex.__dict__['name'] = '李二狗' # 还可以这样修改类属性 print(alex.__dict__) # 查看init里面定义的所有属性,alex存储的本质上就是字典形式的一堆属性 # 对象的属性的增删改查都可以通过字典的语法进行 # 一般通过alex.name='李二狗' 这样直接通过属性修改 # alex.__dict__['name']='李二狗' 等同 alex.name='李二狗'(也可以通过前面的字典修改) alex.age = 83 # 给alex增加一个age属性,(实例属性) print(id(alex)) # 2383304059200,上面self的内存地址和这里外面的alex一样 # print(alex.name) # 查看属性值 # print(alex.hp) # 查看属性值 print(Person.__dict__) # 这个dict储存的是类里的所有的名字:country,init,walk都在 print(Person.__dict__['country']) # China 通过操作字典的形式操作类里面的属性 # Person.__dict__['country']='东京' # 报错,对象alex的字典可以进行增删改查的,而类的字典只能看,不能改 # 类似元组,做了一些限制,不让修改 Person.walk(alex, 5) # 狗剩儿走走走,走了5步 可以这样通过 类调用方法,这样需要传第一个self参数进去 alex.walk(5) # 狗剩儿走走走,走了5步 也可以通过实例调用 # alex.walk(5)== Person.walk(alex,5) 前面是简写 调用方法:类名.方法名(对象名, 参数) 后面的这种写法类调用的写法,类似alex调用walk方法,且把alex自己当作self参数传递到walk方法里面
4: 对象 = 类名() 过程: 类名():首先 会创造出一个对象,创建了一个self变量 调用init方法,类名括号里的参数会被这里接收 执行init方法 返回self对象 对象能做的事: 查看属性:alex.name 查看所有属性:print(alex.__dict__) 调用方法:alex.walk(5) 或者 Person.walk(alex,5) __dict__ 对于对象的增删改查操作都可以通过字典的语法进行 类名能做的事: 实例化: alex = Person('狗剩儿',100,1,'不详') 调用方法 : 只不过要自己传递self参数 Person.walk(alex,5) 调用类中的属性,也就是调用静态属性:
定义在init里的是实例属性,通过类名:Person.name调用不了 因为name名字属于具体某一个对象的,只能对象调用,类名调用不了
在class类下面创建一个静态属性(类属性):country = 'China' 只要是这个类就一定有的属性 Person.country可以直接调用,alex.country也可以直接调用 静态属性是整个类都拥有的,不会随着对象的创建而改变 __dict__ 对于类中的名字只能看 不能操作
# 面向对象的交互:人狗大战 class Dog(): # 对于类名开头一般都是大写开头---规范 def __init__(self, name, blood, aggr, kind): self.name = name self.blood = blood # 血量 self.aggr = aggr # 攻击力 self.kind = kind def bite(self, person): person.blood -= self.aggr print('%s被咬了,掉了%s的血' % (person.name, self.aggr)) class Person(): def __init__(self, name, blood, aggr, sex): self.name = name self.blood = blood # 血量 self.aggr = aggr # 攻击力 self.sex = sex def attack(self, dog): dog.blood -= self.aggr print('%s被咬了,掉了%s的血' % (dog.name, self.aggr)) alex = Person('狗剩儿', 100, 1, '不详') jin = Dog('金老板', 1000, 20, 'teddy') # Dog是类, jin是对象 实例化过程 # print(alex.__dict__) #{'name': '狗剩儿', 'blood': 100, 'aggr': 1, 'sex': '不详'} # print(jin.__dict__) #{'name': '金老板', 'blood': 1000, 'aggr': 100, 'kind': 'teddy'} alex.attack(jin) # alex打狗 print(jin.__dict__)
# 打印:{'name': '金老板', 'blood': 999, 'aggr': 20, 'kind': 'teddy'} jin.bite(alex) # jin咬alex print(alex.__dict__)
# 打印:{'name': '狗剩儿', 'blood': 80, 'aggr': 1, 'sex': '不详'} # 一般情况下值就是属性:多大,多高,多重,名字等 # 动作就是方法:看书,攻击,咬
定义类
init方法
self是什么(类似字典) self拥有属性都属于对象
类中可以定义静态属性
类中可以定义实例方法,方法都有一个必须传的参数self
实例化
实例、对象
对象查看属性
对象调用方法
面向对象基础知识总结: 定义类 class 关键字定义类 def函数 : 方法 动态属性 # 类中可以定义方法,方法都有一个必须传的参数self 变量 : 类属性 静态属性 # 类中可以定义静态属性 __init__方法 初始化方法,构造方法 python帮我们创建了一个对象self(一开始是空对象,后面进行赋值) 每当我们调用类的时候就会自动触发这个方法。默认传self 在init方法里面可以对self进行赋值 self是什么,self拥有属性都属于对象(self相当于是一个字典,只是另外形式表现出来) 在类的内部,self指代的就是一个对象 alex = Person() # Person类 alex对象 alex.walk() == Person.walk(alex) # self=alex 实例化:对象 = 类(参数是init方法的参数) 实例、对象 完全没有区别,实例就是对象 对象查看属性 对象.属性名 对象调用方法 对象.方法名(参数) == 类名.方法名(对象名,参数)
4:面向对象之——类和对象命名空间
1:类里可以定义两种属性 静态属性(类属性):language = ['Chinese'] 静态属性(类属性)不能通过 __dict__方法修改它, 但是静态属性(类属性)可以通过Course.language = 'English'这样直接:类.类属性 =xxx 进行修改 动态属性 class Course(): # 定义课程类 language = ['Chinese'] # 定义静态属性 def __init__(self, teacher, course_name, period, price): self.teacher = teacher # 老师 self.name = course_name # 课程名 self.period = period # 周期 self.price = price # 学费 def func(self): pass # Course.language = 'English' # 这样可以修改类的静态属性language # Course.__dict__['language'] = 'Chinese' # 不能通过__dict__方法修改类的静态属性,会报错 # print(Course.language) python = Course('egon', 'python', '6 months', 20000) # 创建一个python课程,约束属性,这个课程必须有这些属性 # 类不仅方便操作方法,少传递参数,还能帮助规范一些对象--课程大概张什么样子 linux = Course('oldboy', 'linux', '6 months', 20000)
print(linux.__dict__) # {'teacher': 'oldboy', 'name': 'linux', 'period': '6 months', 'price': 20000}
linux.__dict__['teacher'] = '李二狗'
print(linux.__dict__) # {'teacher': '李二狗', 'name': 'linux', 'period': '6 months', 'price': 20000}
linux.teacher = "二逼子"
print(linux.__dict__) # {'teacher': '二逼子', 'name': 'linux', 'period': '6 months', 'price': 20000}
结论:
类的静态属性可以通过 类.类属性 = xxx 进行修改 但是不可以通过 类.__dict__['类属性'] = xxx 进行修改
对象的实例属性可以使用 对象.实例属性 = xxx 和 对象.__dict['实例属性'] = xxx 这两种方法都能进行修改
2:类中的静态属性(变量)的调用:(为什么静态属性既可以通过类名又可以通过对象名调用) 1:静态属性可以通过类名调用 2:静态属性也可以通过对象名调用 函数名和变量名都只是定义在类中的名字,都只是一个内存地址,可以类名调用 类的定义的分析: 执行class Course创建一个类的时候,内存里打开一个属于类的命名空间 然后往命名空间里面放东西,language = ['Chinese'] --》就往空间 放一个language的名字,def __init__:空间放一个init的名字 def func,内存空间里放一个func,内存空间就有了三个名字,
python = Course('egon','python','6 months',20000)
每当实例化一个对象的时候 就给这个对象创建了一个属于这个对象的命名空间,创建一个叫python的对象(命名空间) 调用这个python这个对象的时候,创建一个标识,python对象指向自己的类Course(是什么类实例化的), 这个标识叫:类对象指针,这个标识存储在对象里的,有了类不能找到每一个类的实例化的实例 但是有了对象能找到类的,单向联系,实例化之后有很多属性,存储在self里,存在python对象命名空间里 python对称存储各种名字:如teacher,course_name,period,price, 但是python这个对象空间没有language这个名字,对象调用一个属性名字的时候,先在自己的内存空间找 如果自己内存空间找不到就到他的类的内存空间找, Course.language 这个直接在Course类自己的名称空间找 python.language 这个先在python自己的空间找,没找到再去Course类命名空间找 -----这就是为什么 Course.language和python.language都能调用静态属性的原因 前面代码同1 print(Course.language) # 类名调用静态属性 ['Chinese'] print(python.language) # 对象名调用静态属性 ['Chinese']
3: Course:类
python:对象
只能python找Course命名空间的名字,而Course不能反着找python空间的名称,单向联系 所以实例属性teacher,course_name,period,price都只能python.teacher 对象名称调用,不能Course.teacher 通过类名称调用
前面代码同1 print(python.name) print(Course.name) # 报错:AttributeError: type object 'Course' has no attribute 'name'
4:同一个类实例化多个不同对象之间的关系 python = Course('egon','python','6 months',20000) linux = Course('oldboy','linux','6 months',20000) python和linux这两个对象什么关系:本质上没啥关系 Course:类有自己的命名空间 python:python也创建自己的命名空间 linux:linux也创建自己的命名空间 python和linux都是平行的关系,没什么关系,但是内部都有类指针对象指向自己的Course类
5:通过Course类名修改静态属性language的话 python.language和linux.language也会修改 Course.language = 'English' print(python.language) # English print(linux.language) # English
6:通过python或者linux对象名称修改language的话
执行python.language = 'Japan' 实际上是在python自己的命名空间创建一个language新的属性值等于Japan 不会改变Course类里面的language属性,Course类的命名空间的language还是等于['Chinese']没有变化 linux的language找的还是Course的language 所以不会影响到Course类空间的属性和linux空间的属性 注意:当一旦使用对象名称对静态属性发生修改之后,这个对象就再也调用不到Course类命名空间里 这个被修改值的属性了,因为修改了就会在自己的名称空间创建一个同名的属性了,以后 调用优先自己命名空间查找这个属性 所以如果修改之后还是想使用Course类里面的language属性的话 需要del清除掉python自己命名空间的language del python.language 删除python对象里的language属性使得对象内部找不到language属性,从而找类Course里面的静态变量 类中的静态变量 可以被对象和类调用 对于不可变数据类型来说:类变量最好用类名操作,不要用对象名操作, 对于可变数据类型来说:对象名的修改是共享的,重新赋值是独立的 class Course(): # 定义课程类 language = ['Chinese'] # 定义静态属性 def __init__(self, teacher, course_name, period, price): self.teacher = teacher # 老师 self.name = course_name # 课程名 self.period = period # 周期 self.price = price # 学费 def func(self): pass python = Course('egon', 'python', '6 months', 20000) linux = Course('oldboy', 'linux', '6 months', 20000) python.language = 'Japan' print(python.language) # Japan
print(Course.language) # ['Chinese']
print(linux.language) # ['Chinese']
print(python.__dict__)
# 打印:{'teacher': 'egon', 'name': 'python', 'period': '6 months', 'price': 20000, 'language': 'Japan'}
del python.language print(python.language) # ['Chinese'] print(python.__dict__) # 打印:{'teacher': 'egon', 'name': 'python', 'period': '6 months', 'price': 20000} print(Course.language) # ['Chinese'] print(linux.language) # ['Chinese'] print(linux.__dict__) # 打印:{'teacher': 'oldboy', 'name': 'linux', 'period': '6 months', 'price': 20000}
Course.language.append('eng')
print(Course.language) # ['Chinese', 'eng']
print(python.language) # ['Chinese', 'eng']
print(linux.language) # ['Chinese', 'eng']
python.language.append('ppp')
print(Course.language) # ['Chinese', 'eng', 'ppp']
print(python.language) # [['Chinese', 'eng', 'ppp']
print(linux.language) # ['Chinese', 'eng', 'ppp']
7: 对于不可变数据类型来说,类变量最好用类名操作,不要用对象名操作, 对于可变数据类型来说,对象名的修改是共享的,重新赋值是独立的 python.language[0]='japan' 修改 共享的 python.language=['japan'] 重新赋值 独立的 可变数据类型:
因为对于列表来讲,列表里面的内容改变不影响这个列表所在的内存地址 Course类里开了个空间,里面存了个名字language,language指向一个list列表的内存地址 列表一开始存了个Chinese(指向一个Chinese的内存地址), python对象和linux对象的language指向Course类里面的language,这个language始终指向列表, python.language[0]='japan' 通过python对象名称修改这个列表的第0个元素的时候 0元素本来指向Chinese的内存断开指向,改成指向japan这个内存地址,连线改变了 但是没有影响python和linux的指向,任然指向Course的language,language指向列表 列表内存地址没变,只是列表内部元素指向内存地址改变了 ---所以对于可变数据类型来说就是这样的 如果不是修改列表中的元素,而是直接修改language的值,python.language=['japan'] Course里本身就有个language,language=['Chinese'] python.language=['japan'] 那么相当于在python命名空间创建一个新的language属性 如果python.language[0]='japan' 这样修改的形式会改变Course内存空间language列表里的一个值
class Course(): # 定义课程类 language = ['Chinese'] # 定义静态属性 def __init__(self, teacher, course_name, period, price): self.teacher = teacher # 老师 self.name = course_name # 课程名 self.period = period # 周期 self.price = price # 学费 def func(self): pass python = Course('egon', 'python', '6 months', 20000) linux = Course('oldboy', 'linux', '6 months', 20000) # 现在的Course里面的静态属性是一个列表['Chinese'] language = ['Chinese'] Course.language[0] = 'English' # 使用类名 修改 print(Course.language) # ['English'] print(python.language) # ['English'] print(linux.language) # ['English'] python.language[0] = 'japan' # 使用对象名 修改(属性的第0个位置)可变数据对象 print(Course.language) # ['japan'] print(python.language) # ['japan'] print(linux.language) # ['japan']
8:模拟人生:只要是静态变量,使用类名操作,所有的对象都共享的 class Person: money = 0 def work(self): Person.money += 1000 # 这里money的操作都在Person这整个类的命名空间 # self.money+=1000 # 这个money会存储到mother和fathe对象自己的内存空间,而不是整个Person类的命名空间 mother = Person() father = Person() mother.work() Person.money += 1000 # 类属性操作 Person.money += 1000 print(Person.money) mother.work() # 等于执行:Person.money += 1000 father.work() print(Person.money) print(mother.money) print(father.money)
# 静态变量(类属性)money只要是被Person这个类名操作的话,对这个类实例化的所有对象而言,这个静态属性是共享的
9:创建一个类,每实例化一个对象就计数 最终所有的对象共享这个数据---所有的对象都能共享需要是静态属性,不能是init里面的实例属性 所有的静态变量和类的方法都存在类的命名空间里的 class Foo(): index = 0 # 静态变量, def __init__(self): Foo.index += 1 # 类名操作静态变量,那么index这个静态变量一直在Foo这个类的命名空间,全部对象共享 # index这个变量 s1 = Foo() s2 = Foo() s3 = Foo() s4 = Foo() print(Foo.index) # 4 print(s1.index) # 4
10: 认识绑定方法:对象对于func来讲,func函数需要借助self才能执行起来, f1.func的话相当于把对象绑定给这个方法了,这个对象里所有的数据这个方法都可以去调用了 这就是绑定的关系 对象调用方法的时候就是把对象里面的值传给这个方法了:发生了一种绑定关系 f1.func() 绑定了就是相当于f1当作self传进去了,Foo.func(f1) 非绑定方法就没法取到值 类名调用函数都不能产生绑定关系 一个对象名去调用一个类内的方法的时候,那么这个方法就和这个对象绑定在一起了 这个对象能够以self的形式传到方法里面,这个方法里面可以使用self的这种情况 就是发生了绑定关系 def func(): pass print(func) # <function func at 0x00000208339C2EA0> 函数 class Foo: # 这个类没有init,没有init也能实例化 def func(self): print('func') def fun1(self): pass f1 = Foo() # 这个类没有init,没有init也能实例化,也能拿到self,只是self没有任何值而已(类似空字典) print(Foo.func) # <function Foo.func at 0x0000020833D448C8> 类里的方法 print(f1.func) # <bound method Foo.func of <__main__.Foo object at 0x0000020833D3EBE0>> print(f1.fun1) # <bound method Foo.fun1 of <__main__.Foo object at 0x0000020833D3EBE0>> # f1.func 绑定在Foo类 object上的一个方法 Foo object是f1 # 在0x0000020833D3EBE0这个地址上的Foo类的一个对象的绑定方法 # f1的一个绑定方法
11:包 —— __init__ import package —— (为什么import package就会执行这个package里面的init文件) python里一切皆对象,引入一个包的时候相当于实例化了一个对象,实例化对象的名字的时候 就要执行一个init文件做初始化,导入一个包的过程就像是类的实例化的过程,会自动调用init的py文件 import time time.time() # 类似对象访问方法,对象访问属性
12:类里的名字有:类变量(静态属性)+ 方法名(动态属性) 对象里的名字:对象属性 对象 —— > 类 对象找名字 : 先找自己的 找类的 再找不到就报错 对象修改静态属性的值 对于不可变数据类型来说,类变量最好用类名操作 对于可变数据类型来说,对象名的修改是共享的,重新赋值是独立的
5:面向对象之——类的组合使用
1:面向对象的三大特性 : 继承 多态 封装
2:组合的概念:面向对象的用法 组合:在一个对象里的属性值是另外一个类的实例对象, alex.weapon 是alex对象的属性,他的值是weapon类的一个实例对象 这就是组合 alex.weapon.hand18(alex,jin)
class Dog: def __init__(self, name, aggr, hp, kind): self.name = name self.aggr = aggr self.hp = hp self.kind = kind def bite(self, person): # 狗咬人 person.hp -= self.aggr class Person: def __init__(self, name, aggr, hp, sex): self.name = name self.aggr = aggr self.hp = hp self.sex = sex self.money = 0 # 上来就为0 def attack(self, dog): # 人打狗 dog.hp -= self.aggr def get_weapon(self, weapon): # 给人一个武器装备 if self.money >= weapon.price: self.money -= weapon.price # 买装备减钱 self.weapon = weapon # 装备上一个变量了 self.aggr += weapon.aggr # 攻击力增加 else: print("余额不足,请先充值") class Weapon: # 武器类 def __init__(self, name, aggr, njd, price): self.name = name # 装备名称 self.aggr = aggr # 攻击力 self.njd = njd # 耐久度 self.price = price # 价格 def hand18(self, person, dog): # 武器放大招 if self.njd > 0: dog.hp -= person.aggr * 2 # 人拿着武器放大招,狗掉人双倍攻击力的血 self.njd -= 1 # 耐久度减少1 alex = Person('alex', 0.5, 100, '不详') jin = Dog('金老板', 100, 500, 'teddy') w = Weapon('打狗棒', 100, 3, 998) # 创建一个武器,攻击力100,耐久度3次,价格998 # alex装备打狗棒:get_weapon # alex.money=1000 #这样也可以,假如alex类里面没有设计money属性,直接在外面添加一个money属性 alex.money += 1000 # alex充钱 alex.get_weapon(w) # alex装备武器 print(alex.weapon) # <__main__.Weapon object at 0x000001EA31E6EE80> print(alex.aggr) # 查看alex攻击力 alex.attack(jin) print(jin.hp) # 399.5 500变成了399.5了 alex.weapon.hand18(alex, jin) # alex有个武器属性(weapon是武器类的一个对象)--这就是组合使用(alex拿着武器放大招) print(jin.hp) # 199.5
面向对象组合的使用 test1: 圆形类 圆环类:用上组合 from math import pi class Circle: # 圆形类 def __init__(self, r): self.r = r def area(self): return self.r ** 2 * pi def perimeter(self): return 2 * pi * self.r class Ring: # 圆环类,有一个大r和小r def __init__(self, outside_r, inside_r): # self.outside_c = Circle(outside_r) # 另外一个类的对象作为 当前对象的属性---组合 self.inside_c = Circle(inside_r) # 组合 :一个类的对象作为另外一个类的属性 # 圆环里存储两个圆实例 def area(self): # 计算面积 return self.outside_c.area() - self.inside_c.area() def perimeter(self): # 计算周长--两个圆环相加 return self.outside_c.perimeter() + self.inside_c.perimeter() ring1 = Ring(20, 10) print(ring1.area()) # 942.4777960769379 print(ring1.perimeter()) # 188.49555921538757 test2:
创建一个老师类, 老师有生日 生日也可以是一个类:年,月,日 组合实现 class Teacher(): def __init__(self, name, age, sex, birthday): self.name = name self.age = age self.sex = sex self.birthday = birthday self.Course = Course(self, 'python', '6 month', 2000) # 实例化一个课程对象给Teacher的属性 # self是Teacher实例化后的自己传给Course # self是我自己传给Course里面的Teacher, class Birthday: def __init__(self, year, month, day): self.year = year self.month = month self.day = day class Course: # 课程类 def __init__(self, teacher, course_name, period, price): self.teacher = teacher self.name = course_name self.period = period self.price = price b = Birthday(2018, 1, 16) Mrwang = Teacher('王老师', '30', '女', b) # 直接传b这个对象 print(Mrwang.birthday.day) # 组合使用 print(Mrwang.name) # 王老师 # Mrwang.birthday 拿到的是一个b对象,通过b.day查看属性 print(Mrwang.Course.price) # 查看课程的价格 2000 print(Mrwang.Course.teacher) # <__main__.Teacher object at 0x000001C4CC36ECF8> # self.Course= Course(self,'python','6 month',2000) Teacher把实例化后的self传给了课程Course的Teacher属性
6:面向对象之——单继承
类和对象一些基础知识总结: 面向对象编程 思想 :角色的抽象,创建类, 创建角色(类的实例化),操作这些实例 面向对象的关键字 class 类名: 静态属性 = 'aaa' def __init__(self):pass 类里面:
加载类的时候,从上到下把类里面的名字都存储在内存空间里了,装的是名字,不是类里面的方法函数里的内容 名字装到内存之后才能实现不实例化通过 类名.静态属性,如果没有提前加载就肯定调不到这个属性了 名字都已经加载到类的命名空间里了,后面直接拿来用就行,占内存的只是类里面变量名称和函数名称 函数内部的内容依然不占用空间的, # 类名.静态属性 —— 静态属性存储在类的命名空间里 # 对象 = 类名() # 实例化:先创造了一个self对象,执行init方法(init里有些往self里面添加变量的操作), #返回self对象给外部 # 对象.属性 # 使用对象查看属性 # 对象.方法() # 类名.方法(对象) 使用对象调用方法,这个方法就被称之为一个绑定方法, #方法和对象绑定在一起了 # 对象可以使用静态变量? True # 类可以使用对象(init里定义的属性)里的属性么? False
面向对象的三大特性 1:继承 2:多态 3:封装 1:继承的定义:
继承是一种创建新类的方式,在python中,新建的类可以继承一个或多个父类 父类又可称为基类或超类,新建的类称为派生类或子类 class A(object):pass # 父类,基类,超类 class B:pass # 父类,基类,超类 class A_son(A,B):pass # 子类,派生类 class AB_son(A):pass # 子类,派生类
一个类可以被多个类继承 一个类可以继承多个父类:python里特有的,其他语言没有多继承 继承也是单向联系:儿子能找到爹,爹不知道自己几个儿子 子类之间互不相干,没有关系,父类之间也是没有关系 print(A_son.__bases__) print(AB_son.__bases__) print(A.__bases__) # python3 -属于新式类# 没有继承父类默认继承object
class A(object): pass # 父类,基类,超类 class B: pass # 父类,基类,超类 class A_son(A, B): pass # 子类,派生类 class AB_son(A): pass # 子类,派生类 print(A_son.__dict__) # {'__module__': '__main__', '__doc__': None} print(A_son.__bases__) # (<class '__main__.A'>, <class '__main__.B'>) # .__bases__ 查看类继承了谁(查看父类) print(B.__bases__) # (<class 'object'>,) 没有继承父类默认继承object # python中任何一个没有父类的类他都是object类的儿子,继承object # python3里所有的类都有父类,如果没有发生继承那么就是object类的子类 # python3这种默认继承object的类是新式类,后面括号写不写object都可以(不写默认继承object)
2:继承与抽象(先抽象再继承) 抽象即抽取类似或者说比较像的部分。 抽象分成两个层次: 1.将奥巴马和梅西这俩对象比较像的部分抽取成类; 2.将人,猪,狗这三个类比较像的部分抽取成父类。 假如一个人类一个狗类:人类和狗类都有共同点,都是动物,有name,aggr,hp等属性 所有抽象出一个animal动物类,人类和狗类继承动物类 class Animals: def __init__(self, name, aggr, hp): self.name = name self.aggr = aggr self.hp = hp class Dog(Animals): def __init__(self, name, aggr, hp, kind): super().__init__(name, aggr, hp) # 继承父类的属性 self.kind = kind def bite(self, person): person.blood -= self.aggr print('%s被咬了,掉了%s的血' % (person.name, self.aggr)) dog1 = Dog('金老板', 1000, 100, 'teddy') print(dog1.name)
1:单继承实例 狗类 吃 喝 看门(guard) 鸟类 吃 喝 下蛋(lay) 实例化的时候:
子类自己有init就用子类自己的,子类自己没有init方法就用父类Animal的init方法 继承:
当子类自己有一个方法的时候就不用父类的,当子类自己没有这个方法的时候就用父类的 父类中没有的属性在子类中出现:叫派生属性 父类中没有的方法在子类中出现:叫派生方法 只要是子类的对象调用子类中有的名字一定用子类的,子类中没有才找父类的,如果父类还没有,找object类 如果都没有就报错(一直往上找,直到object) 如果父类子类都有的属性和方法,优先调用子类自己的(子类没有的情况下才找父类的) 如果子类自己有还想用父类的,需要单独调用父类的,还需要传self参数 class Animal: def __init__(self): print('执行Animal.__init__') self.func() def eat(self): print('%s eating' % self.name) def drink(self): print('%s drinking' % self.name) def func(self): print('Animal.func') class Dog(Animal): def guard(self): print('guarding') def func(self): print('Dog.func') dog = Dog() # Dog()Dog类的实例化:1:执行init之前先创建一个self,self是对象-->指向Dog类 # 找到Dog类发现Dog类没有init方法,就找Dog类的爹Animal的init方法来执行 # 打印:执行Animal.__init__ # 执行父类Animal里面的:self.func() self对象调用方法,相当于dog.func() dog实例调用func方法 # 因为self指向Dog类的,相当于调用Dog.func(self),先找自己Dog类的func方法 # 自己有用自己的,自己没有用Dog类的爹Animal类的 # 所以这里打印:Dog.func class Bird(Animal): def __init__(self, name): self.name = name def lay(self): print('laying') # dog.drink() # 报错:dog对象没有name属性,AttributeError: 'Dog' object has no attribute 'name' bird = Bird('李二鸟') # Bird类自己重构了init方法没有继承父类Animal的init bird.drink() # 打印:李二鸟 drinking dog.guard() # 打印:guarding bird.lay() # 打印:laying
2:人狗大战单继承版本 # 实例化的时候:子类自己有init就用子类自己的,子类自己没有init方法就用父类Animal的init方法 class Animal: def __init__(self, name, aggr, hp): self.name = name self.aggr = aggr self.hp = hp def eat(self): print('吃药回血') self.hp += 100 class Dog(Animal): def __init__(self, name, aggr, hp, kind): # 现在的self是Dog的实例,在执行init之前创建self,这个self和dog类有关联 # Animal.__init__(self,name,aggr,hp) 把这个self传给Animal类的init # 那么init拿到的self仍然是Dog类的self,所以Animal里面给self赋了值能感知到,所以上面和下面的self都是属于Dog类的 Animal.__init__(self, name, aggr, hp) # 调用Animal类的init,继承父类Animal的属性(继承父类的init构造方法) # 为什么传self:Animal()实例化的时候调用init,自动会创建一个self,
# 现在这里不需要自动创建self(也不会自动创建self) # 用自己Dog类创建的self对象,所以这里初始化Animal的init的时候还把self和需要的参数都传递进去 # 这样的话Animal.__init__(self,name,aggr,hp)做完初始化之后,self里面自动就有值了 # 因为把self传给它用了,它给self赋完值以后自动就有值了之后再往这里面写东西 # 就是建立在之前基础上去写了 self.kind = kind # 派生属性:原本父类的属性外又添加了新的属性 def eat(self): Animal.eat(self) # 如果既想实现新的功能也想使用父类原本的功能,还需要在子类中再调用父类 # Animal.eat找父类Animal的eat方法,传了self对象(Dog类的实例化对象)给Animal类的eat方法 # 不能执行self.eat() 这样就变成执行自己的eat了,变成递归了,需要调用父类的eat # 只能指名道姓找父类调用eat方法,self发生了变化了,不是父类派生的self对象 # 而是Dog实例化的self对象(传给了Animal.eat) self.teeth = 2 def bite(self, person): # 派生方法,父类没有,子类自己有的方法 person.hp -= self.aggr jin = Dog('金老板', 100, 500, '吉娃娃') 运行步骤:
1:Dog('金老板',100,500,'吉娃娃')实例化Dog类,先创建一个self, 调用Dog类的init方法返回一个self 然后还调用父类Animal的init实例化方法,把一开始创建的Dog类的self对象传进去 调用父类Animal的init方法又返回一个Dog类的self Dog类自己有个eat()方法,
1: Animal.eat(self) 调用父类的eat方法传self对象进去实现父类功能 2: self.teeth = 2 自己再给eat方法加功能 ---实现自己功能的基础上还调用父类的功能 --重构 jin.eat() print(jin.hp) class Person(Animal): def __init__(self, name, aggr, hp, sex): Animal.__init__(self, name, aggr, hp) self.sex = sex # 派生属性:父类没有,子类新创建出来的属性 self.money = 0 # 派生属性 def attack(self, dog): dog.hp -= self.aggr def get_weapon(self, weapon): if self.money >= weapon.price: self.money -= weapon.price self.weapon = weapon self.aggr += weapon.aggr else: print("余额不足,请先充值") alex = Person('alex', 1, 2, None) alex.eat() print(alex.hp) jin.bite(alex) print(alex.hp)
父类中没有的属性 在子类中出现 叫做派生属性 父类中没有的方法 在子类中出现 叫做派生方法 只要是子类的对象调用,子类中有的名字 一定用子类的,子类中没有才找父类的,如果父类也没有报错 如果父类 子类都有 用子类的 如果还想用父类的,单独调用父类的: 父类名.方法名 需要自己传self参数 super().方法名 不需要自己传self 正常的代码中 单继承 === 减少了代码的重复 继承表达的是一种 子类是父类的关系
py3中类的继承super关键字的使用 1:py3新式类当中的关键字super super().__init__(name,aggr,hp) 等同 Animal.__init__(self, name, aggr, hp) 在一个类的内部使用了super()意思是找我的父类,找父类之后就能调用父类的init了 使用super调用父类的方法不需要传self了,因为在super这个地方省略了两个参数,省略的参数1:(Dog:自己这个类) 省略的参数2(self:自己当前这个对象) self在super(Dog,self)这里传了,并且传递的两个参数Dog和self可以省略,所以后面init方法里面不用传self这些参数了,不需要super().__init__(self,xxx,xxx,xxx)这样使用
不需要在init里传self等参数,因为super()在类里面默认传了两个参数,只是在类里使用比较特殊可以把参数省略super() == super(Dog, self)
这些参数在supe里可以省略不传
在自己的Dog类里面使用super().__init__(xxx,xxx,xxx)可以知道当前在那个类里调用,知道当前是调用这个函数super()函数的对象是什么,所以在类里可以省略Dog和self两个参数不传 super(Dog,self).__init__(name,aggr,hp) super(Dog,self).__init__(name,aggr,hp)==super().__init__(name,aggr,hp) 执行super().__init__(name,agge,hp)相当于执行super(Dog, self).__init__(name, aggr, hp)就自动找到Dog父类Animal的init方法了 super关键字只在新式类才有,py3中所有的类都是新式类,都可以使用super方法找到父类 super方法多继承有一点小问题,对单继承来说super就可以直接找到父类了 super除了可以在类内部使用,也可以在内外使用
class Animal: def __init__(self, name, aggr, hp): self.name = name self.aggr = aggr self.hp = hp def eat(self): print('吃药回血') self.hp += 100 class Dog(Animal): def __init__(self, name, aggr, hp, kind): super().__init__(name, aggr, hp) self.kind = kind def eat(self): print('Dog eat') jin = Dog('金老板', 100, 500, '吉娃娃') print(jin.name) 2:super除了可以在类内部使用,也可以在类外使用 在类的内部使用的话不需要传super的默认参数(当前的类名和self) super(Dog,self).__init__(name,aggr,hp)==super().__init__(name,aggr,hp) 在类的外部使用的话必须要传类名和对象名 super(Dog,jin).eat() super(Dog, jin).eat() # 吃药回血,super调用Dog父类的eat方法 jin.eat() # 现在自己Dog类的eat,找不到才执行父类Animal的eat--这里执行自己的
7:面向对象之——多继承
1:两种子类当中调用父类的方法 1:单独调用父类:Animal.eat(self) 父类名.方法名 需要自己传self参数 Animal.eat(self) 调用父类Animal的eat方法 2:使用super().方法名 不需要自己传self了:super(Dog,jin).eat() super(Dog,jin).eat() 调用Dog父类的eat方法 正常的代码中 单继承 === 减少了代码的重复 继承表达的是一种 :子类是父类的关系 比如:狗是动物,教授是老师, 组合是两个类的关系:比如老师,生日 老师有生日(组合关系) 有相似的代码:继承
2:多继承test1 D继承A,B,C class A: def func(self): print('A') class B: def func(self): print('B') class C: def func(self): print('C') class D(A, B, C): def func(self): print('D') class E(A, B, C): pass d = D() d.func() # 打印:D 这时候调用的是自己类D的func函数 e = E() e.func() # 打印:A
# E类没有func方法,继承了A,B,C,但是离A最近,调用A类的func方法 # 如果把A的def func(self) 注释就调用B的 # 如果把B的def func(self) 注释就调用C的 # 如果A,B,C的func函数都注释就找不到func方法了--报错 # 谁的关系最近就找谁,从左往右找 A->B->C super(D, d).func() # 打印:A
# 这里调用D的父类 A类的func方法
3:多继承之钻石继承问题:B继承A,C继承A,D继承B和C class A(object): def func(self): print('A') class B(A): def func(self): super().func() print('B') class C(A): def func(self): super().func() print('C') class D(B, C): def func(self): super().func() print('D') d = D() d.func() # 打印:A,C,B,D 执行D类的func方法 # D继承了B,C b和c又同一个爹a,
# 先找b,b这里找不到就能感应到一个a了,没有应该去找a # 但是因为知道c继承的也是a 先往同一级(爸爸)找,找到c,再往深度(爷爷,祖宗)找,找到a
# 这里类似一个递归函数,调用D的func,D的func里调用B的func,B的func调用C的func,C的func调用A的func
# 所以最先调用完的是A的func,再C的func,再B的func,再D的func
python3所有的新式类都采用广度优先的找法,找不到再找深度的值
python3新式类多继承里:广度优先算法 class F: def func(self): print('F') class A: def func(self): print('A') class B(A): pass # def func(self): print('B') class E(F): pass # def func(self): print('E') class C(E): pass # def func(self): print('C') class D(B, C): pass def func(self): print('D') d = D() d.func() # 先找D,D没有找B,B是A的子类,只能通过B找A,只能这时候通过B找A, # 错过了B这个节点C找不到A了,所以只能这里先找A了,A找不到再找C, # C找不到找E,E找不到找F
# 如果再后面还有机会能找到A,那么可以后面再找,如果没有机会找A了,那么现在就要从A找 # 这就是广度优先算法 print(D.mro())
[<class '__main__.D'>, <class '__main__.B'>, <class '__main__.A'>,
<class '__main__.C'>, <class '__main__.E'>, <class '__main__.F'>, <class 'object'>]
D继承B C
B继承A
C继承E
E继承F
4:多继承:小乌龟问题--类的查找顺序 D.mro() :返回一个列表,里面记录所有的继承顺序,
新式类的继承顺序:遵循广度优先 class F: def func(self): print('F') class A(F): pass # def func(self): print('A') class B(A): pass # def func(self): print('B') class E(F): pass # def func(self): print('E') class C(E): pass # def func(self): print('C') class D(B, C): pass # def func(self):print('D') d = D() d.func() # 先找D,再B->A->C->E->F # 找完A之后不找F,是因为E也能找到F,再找C->E->F print(D.mro()) # [<class '__main__.D'>, # <class '__main__.B'>, # <class '__main__.A'>, # <class '__main__.C'>, # <class '__main__.E'>, # <class '__main__.F'>, # <class 'object'>]
5:py2.7版本类的继承顺序:py2.7能够实现两种类,py3只能实现一种类 新式类:继承object类的才是新式类 新式类都是广度优先(A类继承(B,C)) 先走B的,B和C如果有同一个爹的话就会再走C,B,C没有一个爹那就没得办法,只能走B后走B的爹 因为这时候不走B的爹就走不到B的爹了,B的爹走完再走C,再走C的爹 经典类:如果你直接创建一个类在2.7中就是经典类 深度优先 (一条线一直往上走,找爹,爹的爹,爹的爹的爹....,这条线走完了再找下一条线---深度优先,简单 一条线往上走,找没有走过的路走,走过的路不走了) print(D.mro()) D.mro() 单继承:子类有的用子类的 子类没有用父类的 多继承:我们子类的对象调用一个方法,默认是就近原则,找的顺序是什么? 经典类中 深度优先 新式类中 广度优先 python2.7 新式类和经典类共存,且新式类要继承object python3 只有新式类,默认继承object 经典类和新式类还有一个区别 :mro方法只在新式类中存在 super 只在python3中存在 super的本质 :不是单纯找父类 而是根据调用者的节点位置的广度优先顺序来的 如果:D继承(A,B,C)--那么D的super是A A的super是B B的super是C 如果:D继承(B,C) ,B继承A,C继承A 那么D的super是B B的super是C C的super是A 遵循广度优先顺序原则,不是单纯的super就是找父类,super是根据广度优先顺序找节点 因为B和C都能找到A,所有B这里不用急着往上找A,因为后面的C也能找得到A,所有广度优先 B的下个节点是C,C的下个节点是A 继续写作业 : 学生管理系统 登录,识别身份 进阶 : 不同视图不同的菜单 class A(object): def func(self): print('A') class B(A): def func(self): super().func() print('B') class C(A): def func(self): super().func() print('C') class D(B ,C): def func(self): super().func() # 这里调用B的func,B里面super().func()调用的A的func print('D') b = D() b.func() print(B.mro()) # [<class '__main__.B'>, <class '__main__.A'>, <class 'object'>] print(D.mro()) # [<class '__main__.D'>, <class '__main__.B'>, <class '__main__.C'>, <class '__main__.A'>, <class 'object'>]
class A(object): def func(self): print('A') class B(A): def func(self): super(B, self).func() print('B') class C(A): def func(self): super(C, self).func() print('C') class D(B, C): def func(self): super(D, self).func() # 这里调用B的func,B的调用的A的func print('D') def ccc(self): super(C, self).func() b = D() b.ccc() # 打印:A
调用D类里面的ccc方法,ccc里面调用super(C, self).func()
调用实例化self对象的类D的多继承顺序列表里的C类后面的一个类的func()方法
D类的继承顺序里面[D, B, C, A, object],C类后面一个类是A类,所以直接调用A类的func方法
python继承知识总结: # 继承 : 什么是什么的关系 # 单继承 ***** # 先抽象再继承,几个类之间的相同代码抽象出来,成为父类 # 子类自己没有的名字(变量和方法),就可以使用父类的方法和属性 # 如果子类自己有(变量和方法),一定是先用自己的 # 在类中使用self的时候,一定要看清楚self指向谁,子类的self还是父类的self,子类的对象还是父类的对象 决定使用名字的时候优先使用子类的还是优先使用父类的 # 多继承 *** # 新式类(继承object)和经典类(py2.7版本才有经典类): # 多继承寻找名字的顺序 : 新式类广度优先,经典类深度优先 # 新式类中 有一个类名.mro方法,查看广度优先的继承顺序 # python3中 有一个super方法,根据广度优先的继承顺序查找上一个类
8:面向对象之——接口类 from abc import abstractmethod, ABCMeta 实现一种规范
java : 面向对象编程
设计模式:一本书介绍了很多设计模式的方式 —— 接口类来源于设计模式
是编程的一种规范,设计问题需要用到什么方式去编写最容易实现,这就是接口类和抽象类
是一种编写程序的思想,思维方式,源自于java
接口类和抽象类都是一直思想而不是怎么编程的
接口类:python原生不支持接口类(可以使用python代码去实现)
抽象类:python原生支持抽象类
接口类和抽象类在python中很接近,在其他语言不同
1:开发一个支付系统,可以微信支付也可以支付宝支付 写了一个Payment规范的类,这个规范的类要求实现一个pay的方法 而Applepay类里没有实现pay方法,所以就报错 如果Applepay类里实现pay方法就不会报错 这就是abstractmethod和ABCMeta的作用:实现一个接口类(建立规范的过程) Payment是一个规范,Payment既可以说是抽象类买也可以说是接口类,本身就是一种规范 希望建立一套规范来约束它,继承了约束类的几个类都有同名的方法,让统一路口进行支付
通过一段代码把他们都是约束起来,就是通过这个接口类----这就是接口类的概念 接口类固定写法: 1:必须指定元类metaclass=ABCMeta 2:@abstractmethod 必读对函数加这个装饰器(里面的raise都可以不要) 这么写就是一种规范,
下面的payment类这种规范:叫接口类或者抽象类都可以 接口类:默认(支持)多继承,一般多继承使用接口类,
接口类的特点:接口类中所有的方法都必须不能实现(就是下面payment接口类里的pay函数里面必须是pass,接口类的pay函数里什么都不能写)
--是从java里面演化来的,在java里有这个概念,但是python里你硬是往接口类的pay方法里写除pass外的内容,也行,只是一般情况下python里不建议写多余内容
抽象类:不支持多继承,使用抽象类时候只用单继承,抽象类中可以实现一些方法,抽象类中的方法可以有一些代码的实现, --也是java里面演化来的,
上面的只是一种设计思想,写代码的规范,规范子类,python中其实都可以不这么写,但是只是写代码的一种模式规范而已
python中这两种类可以理解为这是一种,就是为了规范编码,规范子类
# 不使用abc来实现一个接口类(父类主动抛出一个异常,如果子类没有实现pay方法就调用父类的pay方法,主动抛出异常)
class Payment: def pay(self, money): raise NotImplemented # 没有实现这个方法 class Wechat(Payment): # 微信支付接口类 def pay(self, money): print('已经用微信支付了%s元' % money) class Alipay(Payment): # 支付宝支付接口类 def pay(self, money): print('已经用支付宝支付了%s元' % money) class Applepay(Payment): def fuqian(self, money): print('已经用Applepay支付了%s元' % money) def pay(pay_obj, money): pay_obj.pay(money) apple = Applepay() pay(apple, 1000) # TypeError: exceptions must derive from BaseException
# 子类没有pay方法会主动调用父类的pay方法抛出异常
# 所以子类必须自己有pay方法才不会报错,自己主动构造异常让你一看就知道什么错误
上面不使用abc来实现接口类还是不够完美,需要子类调用pay方法才会报错,
使用abc来实现能够让我们马上就知道我们的代码不对劲,如下
# 使用abc库里的abs和ABCmate来实现一个接口类 from abc import abstractmethod, ABCMeta class Payment(metaclass=ABCMeta): # 创建一个支付的父类
# metaclass指定元类:要想在python中创建一个类,也是需要机制支持创建一个类,元类支持创造一个类出来
# 直接使用class能够创建类是因为使用到默认默认创建类的元类type来创建的,默认创建类的元类是type,使用type创建所有的类
# 指定元类是ABCMeta之后,相当于用ABCMeta这个现成的类创造了Payment类,指定了这个说明将要
# 写一个类的规范了,Payment规范下面所有子类的规范 @abstractmethod # 加这个装饰器之后
# app=Applepay()实例化的时候就会报错,报错信息为:没有实现一个抽象的pay方法,
# 不需要调用pay方法才报错,实例化的时候就报错了
# 实例化一个Applepay类就快速发现这个问题了---快速找错
def pay(self, money): raise NotImplemented
# raise 主动抛出一个异常NotImplemented # 字类继承payment,如果子类自己没有pay方法,没有实现这个pay方法就会抛出一个 NotImplemented异常 # 如果不实现一个pay的方法,就会执行raise NotImplemented
payment规范的类,要去继承他的字类实现一个pay方法,子类没有实现那么子类实例化的时候就会报错
子类实现pay方法就不会报错了,这就是abstractmethod和ABCmeta的作用,实现一个接口类(建立规范的过程)
但是这个payment既可以说是抽象类也可以说是接口类,本身就是一种规范,
希望建立一套规范来约束他,继承的几个子类都拥有同名的pay方法来统一入口进行支付,想通过一段代码把他们都约束起来,就是通过接口类
# p=Payment() # p.pay() #raise NotImplemented
class Wechat(Payment): # 微信支付接口类
def pay(self, money): print('已经用微信支付了%s元' % money) class Alipay(Payment): # 支付宝支付接口类
def pay(self, money): print('已经用支付宝支付了%s元' % money) class Applepay(Payment): def fuqian(self, money): print('已经用Applepay支付了%s元' % money) # 不想让用户关心是怎么pay的,只需要最终调用pay函数,传一个支付的对象以及需要pay多少钱
# 这就是一种设计代码的思想,类似python内置函数len,可以给列表,元组,字符串都去调用,len(xxx)
# 更简便,只关心len函数接收什么参数,不需要想其他的,统一一个程序的入口 def pay(pay_obj, money): # 统一支付路口,不管是ali支付还是微信支付统一调用pay函数实现支付(这就是一种设计思想)
pay_obj.pay(money)
# 假设公司来了个傻逼程序员李二狗,写applepay,这个傻逼写了个fuqian函数,而没有实现pay函数
# 所有用户的支付功能统一入口pay函数,如下:调用pay(app, 300)的时候会报错 wechat = Wechat() ali = Alipay() app = Applepay() pay(wechat, 100) # 微信支付100 pay(ali, 100) # 支付宝支付100 pay(app, 300) # AttributeError: 'Applepay' object has no attribute 'pay' # 报错,pay函数内部默认调用pay(),而Applepay里面没有实现pay的方法 # 只是实现了一个fuqian的方法--虽然功能一样,但是名字不同
# 所以出现了一种新的设计思想:创建payment的父类
# 调用Applepay对象的pay该方法的时候,没有走Applepay类里面的方法而是走了Payment里面的pay方法 # 执行到它就肯定报错
python接口类的多继承 1:接口类的实例:接口类的多继承 python里没有接口类:去实现不同的功能去继承不同接口来规范当前这个类里要有哪些函数- 接口类 :刚好满足接口隔离原则 面向对象开发的思想 一种规范 在继承抽象类的过程中,我们应该尽量避免多继承; 而在继承接口的时候,我们反而鼓励你来多继承接口
python中本来没有接口类,接口的概念大概是实现不同的功能去继承不同的接口来规范当前这个类要哪些函数(一种开发规范) 接口隔离原则: 使用多个专门的接口,而不使用单一的总接口。即客户端不应该依赖那些不需要的接口。
飞的动物使用飞的功能,走的动物使用走的功能,游的动物使用游的功能,而不是使用一个animal接口类里面有飞有游又有走
功能被隔离开来,用到这个功能只继承和这个功能有关的所有的方法就可以了 比如创建一个tigler类不依赖fly这个功能,不依赖不需要的接口(一种开发原则和思想) 动物园 tiger(老虎): 走路 游泳 swan(天鹅): 走路 游泳 飞 oldying(老鹰): 走路 飞 from abc import abstractmethod, ABCMeta class Swim_Animal(metaclass=ABCMeta): # 加这个ABCMeta就变成接口类,接口类里面的方法本身不实现功能----这就是接口类 @abstractmethod def swim(self): pass # 这个方法里什么都没有,只是一个规范而已,paas就行 # 接口类里面的方法本身不实现,只做规范 class Walk_Animal(metaclass=ABCMeta): @abstractmethod def walk(self): pass class Fly_Animal(metaclass=ABCMeta): @abstractmethod def fly(self): pass class Tiger(Walk_Animal, Swim_Animal): # 老虎类继承Walk_Animal和Swim_Animal def walk(self): pass def swim(self): pass # 继承了Walk_Animal和Swim_Animal,必须在Tiger里面实现walk和swim方法-- # 对于这种既会走又会游的类的动物产生了一个规范,必须有walk和swim方法 # 继承了类里面的相应的方法就必须得写--约束,规范,不容易出问题
# 做规范用的,但是代码行数还是很臃肿重复
class OldYing(Fly_Animal, Walk_Animal): pass class Swan(Swim_Animal, Walk_Animal, Fly_Animal): pass t = Tiger() # O=OldYing() # TypeError: Can't instantiate abstract class OldYing with abstract methods fly, walk
9:面向对象之——抽象类 https://www.cnblogs.com/Eva-J/articles/7293890.html#_label9 概念很模糊
1:如果说类是从一堆对象中抽取相同的内容而来的, 那么抽象类就是从一堆类中抽取相同的内容而来的,内容包括数据属性和函数属性。 抽象类:也是一种规范 一般情况下 单继承 能实现的功能都是一样的,所以在父类中可以有一些简单的基础实现 多继承的情况 由于功能比较复杂,所以不容易抽象出相同的功能的具体实现写在父类中 抽象类还是接口类 : 面向对象的开发规范(python中没有本来没有接口类)所有的接口类和抽象类都不能实例化 java :java里有接口这个概念,但是java不支持多继承,所以创造了一个接口Interface这个概念来解决多继承的规范问题
(python里没有interface这种东西,所以python中用自己概念模拟了接口的理念,python自带多继承,所以我们直接用class来实现了接口类
所以pyhon中接口类和抽象类没有那么大的区别,因为python中自带多继承所以接口就不是一个特殊的数据类型
而python中的抽象类是有的,python中的抽象类一般情况下单继承,
java里的抽象类也是一个类,java里的类只支持单继承,所以java里所有的抽象类都是单继承
但是python中自带多继承,多继承也没关系,一般情况下都是单继承是根据java来的)
类和接口有什么不同:java里接口不能实现,实现就报错,语法不通过,python里没有这个接口类这个概念
一般情况下:抽象类单继承且可以实现python代码,接口类和抽象类都不能实例化
java里的所有类的继承都是单继承,所以抽象类完美的解决了单继承需求中的规范问题 但对于多继承的需求,由于java本身语法的不支持,所以创建了接口Interface这个概念来解决多继承的规范问题
(都是java的概念,有抽象类和接口类两种东西,python中有点傻逼模仿java单继承抽象类和多继承的接口类不伦不类,python天生多继承没有接口的概念
所以python中父类既可以解决多继承的问题也可以解决单继承的问题,python中接口类和抽象类很接近,
只不过套用java里的概念---抽象类推荐使用单继承(解决几个类功能非常相近的问题的这种规范)
接口类推荐多继承解决复杂的几个类之间有相同功能但是不完全相同的这种问题) 单继承抽象类:几个类功能很相似,所以抽象出一个这几个类的大爹,来规范这几个类 多继承的接口类:一个类多继承多个小的接口类,几个类之间有相同功能但是不完全相同 python中抽象类很接口类很接近,因为python支持多继承 python python中没有接口类 : python中自带多继承 所以我们直接用class来实现了接口类 python中支持抽象类 : 一般情况下 单继承 接口类和抽象类都不能实例化 且可以实现python代码 接口类和抽象类都是一种规范:python没有接口类,在python中只是一种概念而已, # 操作系统当中一切都是文件,python里一切都是对象 import abc # 利用abc模块实现抽象类
class All_file(metaclass=abc.ABCMeta): all_type = 'file' @abc.abstractmethod # 定义抽象方法,无需实现功能 def read(self): # @abc.abstractmethod装饰器加功能,检测子类当中是不是有同名的方法而已 '子类必须定义读功能' pass # 这里是能实现一些功能的,比如with open等 @abc.abstractmethod # 定义抽象方法,无需实现功能 def write(self): '子类必须定义写功能' pass
# 定义一个一切皆文件的抽象类All_file,这个抽象类里面两个方法read和write
# 说明只要是文件就做两件事,读和写,
# class Txt(All_file): # pass # # t1=Txt() #报错,子类没有定义抽象方法 class Txt(All_file): # 子类继承抽象类,但是必须定义read和write方法 def read(self): print('文本数据的读取方法') def write(self): print('文本数据的读取方法') class Sata(All_file): # 子类继承抽象类,但是必须定义read和write方法 def read(self): print('硬盘数据的读取方法') def write(self): print('硬盘数据的读取方法') class Process(All_file): # 子类继承抽象类,但是必须定义read和write方法 def read(self): print('进程数据的读取方法') def write(self): print('进程数据的读取方法') # 这样读取硬盘和txt都是在读文件,读取进程也是在读文件,创建这三个类统统继承all_file
# 意味着这三个类继续实现read方法和write方法
# 始终是单继承的,没有多继承,因为这三个东西太接近了,都是实现读写方法
# 且还有可能all_file类里面的read方法里都可能以读的形式打开一个文件,打开文件的方式都是一样的,with open什么的然后再读,里面实现了一点点基础的内容
# 这样的类就是抽象类
# 抽象类一般都是单继承,抽象类也是一种规范,
# 一般情况下是单继承,子类都能实现的功能几乎都是一样的,相似的这种情况使用单继承,所以在父类中可以有一些简单的基础实现
# 动物园例子实现的功能都是不一样的,但是又有相似的地方,这种情况多使用多继承(多继承不好控制),比如鱼和老虎游泳的方式不同,所有在规范的类里难以实现统一的代码
# 多继承情况由于功能比较复杂所有不容易抽象出相同的功能的具体实现写在父类中(接口类)比如动物的例子,老虎和鱼需要继承多个动物类(游泳动物,走路动物等)
# 而单继承,由于实现的功能都是一样的,所以在父类中可以有一些简单的基础实现(抽象类) wenbenwenjian = Txt() yingpanwenjian = Sata() jinchengwenjian = Process() # 这样大家都是被归一化了,也就是一切皆文件的思想,文本和硬盘文件和进程都可以看成文件进行read读和write写 wenbenwenjian.read() yingpanwenjian.write() jinchengwenjian.read() print(wenbenwenjian.all_type) print(yingpanwenjian.all_type) print(jinchengwenjian.all_type)
10:面向对象之——多态
面向对象的三大特性:封装,继承,多态
1:多态:python天生支持多态 多态指的是一类事物有多种形态 动物有多种形态:人,狗,猪 # 下面是模拟其他语言的一段代码 # def func(int num,str name): # 对于其他语言定义函数还需要告诉他输入的变量是什么数据类型,不然报错 # pass # # func('alex',2) 这样传不行,因为前面必须传一个num数字小,后面必须传一个str字符串 # func(2,'alex') 这样传才可以
一个简单的例子:
class Alipay():
def pay(self, money):
print('已经用支付宝支付了%s元' % money)
class Applepay():
def pay(self, money):
print('已经用applepay支付了%s元' % money)
# def pay(类的对象(传Alipay obj或者Applepay obj) pay_obj,int money): # 统一支付入口 归一化设计
# pay_obj.pay(money)
python是一门动态强数据类型的语言
在其他强数据类型语言里定义了pay函数需要告诉函数第一个传入的变量的数据类型是什么(强类型语言的数据类型约束)
如上,定义pay函数的时候第一个参数需要指定一个数据类型这里是类的对象,传Alipay或者Applepay都有问题
给了一个Alipay那么调用pay函数的时候传入的第一个参数是Applepay实例化的对象那么调用就会出问题,同理指定参数是Applepay那么传的参数不能是Alipay类的对象
这样的问题都是在其他语言里的,python压根就没这问题,
其他语言解决上述问题的方案如下:(
多态的概念来解决的搞个Payment类,这个类什么都不干都行,Alipay继承Payment,applepay继承Payment
编写pay函数的时候指定pay函数的第一个参数的数据类型是Payment的obj,这样后面调用pay函数的时候既可以传Alipay也可以传Applepay的对象
基于这种情况实现了多态----这种问题其他语言才有,python没这种问题,写函数不需要指定数据类型)
上面的就是相当于写一个父类,把两个子类统一在同一数据类型下面
class Payment :pass class Alipay(Payment): def pay(self ,money): print('已经用支付宝支付了%s元' % money) class Applepay(Payment): def pay(self ,money): print('已经用applepay支付了%s元' % money) # def pay(Payment pay_obj,int money): # 统一支付入口 归一化设计 # pay_obj.pay(money) # python本身没有这种问题,但是其他语言传参数需要写类型,比如这里要传pay_obj # 前面写的类型只能是Alipay或者Applepay,假如写的是Applepay, # 那么以后传参Alipay pay_obj就会有问题---解决办法,Alipay和Applepay都继承一个Payment类 # 然后 # def pay(Payment pay_obj,int money): # 统一支付入口 归一化设计 # pay_obj.pay(money) # 这样的话既可以传Alipay对象也可以传Applepay的对象了----基于这样一种情况实现了多态(其他语言才有的) # python不用继承,传参也不需要传数据类型,直接传就行 def pay(pay_obj, money): # 所以python天生支持多态,传任何数据类型进来都被接受,不用写一个父类,把下面的两个类统一在一种数据类型下面 pay()
多态实例一: import abc class Animal(metaclass=abc.ABCMeta): # 同一类事物:动物 @abc.abstractmethod def talk(self): pass class People(Animal): # 动物的形态之一:人 def talk(self): print('say hello') class Dog(Animal): # 动物的形态之二:狗 def talk(self): print('say wangwang') class Pig(Animal): # 动物的形态之三:猪 def talk(self): print('say aoao') # Animal动物类的多种形态,Animal有人形态,狗形态,猪的形态,这就是多态
多态实例二:文件有多种形态,文本文件,可执行文件 import abc class File(metaclass=abc.ABCMeta): # 同一类事物:文件 @abc.abstractmethod def click(self): pass class Text(File): # 文件的形态之一:文本文件 def click(self): print('open file') class ExeFile(File): # 文件的形态之二:可执行文件 def click(self): print('execute file') # ExeFile和Text本质上都是文件,文件的多态
多态性 一:什么是多态动态绑定(在继承的背景下使用时,有时也称为多态性) 多态性是指在不考虑实例类型的情况下使用实例 在面向对象方法中一般是这样表述多态性: 向不同的对象发送同一条消息 (!!!obj.func():是调用了obj的方法func,又称为向obj发送了一条消息func), 不同的对象在接收时会产生不同的行为(即方法)。 也就是说,每个对象可以用自己的方式去响应共同的消息。所谓消息,就是调用函数, 不同的行为就是指不同的实现,即执行不同的函数。 比如:老师.下课铃响了(),学生.下课铃响了(),老师执行的是下班操作, 学生执行的是放学操作,虽然二者消息一样,但是执行的效果不同 class Payment :pass class Alipay(Payment): # 支付宝支付接口类 def pay(self, money): print('已经用支付宝支付了%s元' % money) class Applepay(Payment): def fuqian(self, money): print('已经用Applepay支付了%s元' % money) # Alipay执行pay是付钱,Applepay执行pay也是付钱,这两都是在执行付钱的功能, # 但是实现了不同的形态,不同的事情, def pay(pay_obj, money): # 统一支付入口, 归一化设计 pay_obj.pay(money) # 执行pay函数只需要传对象alipay和applepay,传了对象alipay和applepay都是调用pay函数 # 只不过调用了pay方法参数不同执行的代码不一样而已,----这就是多态性 # 多态性:做一个事情执行的相同的方法pay方法,但是根据自己是不同的东西(alipay或者applepay)做不同的事,这就是多态性 # java语言,实现多态性,只能借助父类来完成这件事,不同的对象进来执行相同的方法,但是做不同的事情,根据参数不同做的事情不同 # python的话不需要继承父类,直接不同对象就可以进来,进来了做不同的事情--不需要借助父类实现多态的效果了 # python天生支持多态 # python对数据类型不敏感才能实现多态 # 上面多个对象(比如alipay和applepay)都能传给pay函数,传进来都干一个事情pay_obj.pay(money), # 根据不同的对象做不同的事情 ---多态 # python很有特性:面向对象 又弱类型
python动态强类型语言,不能说是强类型,强类型比如上面定义pay函数的时候必须定义数据类型,(python传参这点上表现的是弱的)
python也不是一门弱类型的语言,弱类型语言支持2+"str"这种语法变成2str,python不支持这种操作(python这点上表情是强类型语言)
所以说python是一门动态的强类型语言(不能单纯说是强类型,某些特性和强类型不一样,所以说是动态的,变化的)
python不借助父类表现相似处,java必须借助父类来表现多态(因为定义函数如上必须传父类的数据类型)而python不需要传数据类型所以不需要借助父类
python崇尚鸭子类型
在我看来:
多态:就是一个对象能表现多种形态,比如动物类里有大象类,猴子类等不同形态
多态性:就是搞一个函数,多次调用这个函数,根据传入的参数的不同做不同的事情---多态性
类似上面的pay函数,根据传参的不同,不同对象调用不同的pay函数实现不同的功能
在我看来这就是傻逼玩意
什么是多态 python 动态强类型的语言, 强类型的语言传参需要指定数据类型 弱类型语言支持 2 + 'str'=2str python传参表现是弱的,在2 + 'str'=2str这里报错表现是强语言 --动态强类型的语言
class List: def __len__(self): pass class Tuple: def __len__(self): pass def len(obj): return obj.__len__() l = Tuple() len(l) # 强类型语言 多态 # python 语言 鸭子类型 # 接口类和抽象类 在python当中的应用点并不是非常必要
python不崇尚多态 python崇尚鸭子类型 list列表 tuple元组很相似:都有index,len,都可迭代,都能切片,count
那么写这两种数据类型的时候是不是思考使用父类,相同的方法放到父类里,list和tuple继承父类
用父类的规范让list和tuple必须实现相同的内容,这样看起来很好
但是python里list数据类型继承的object,tuple也继承的object,object没有提供list和tuple里面相似的方法
鸭子类型:不崇尚根据继承所得来的相似,而是我只是自己实现我自己的代码就可以了,
如果两个类刚好相似,那么他们并不是同一个父类子类的这种兄弟关系,不产生父类的子类的兄弟关系而是鸭子类型
如果两个数是鸭子类型,说明这两个数据类型非常的相近,相近就会有一些相同的方法,
相同的方法的名字比如index等方法只是依靠自己写的代码规范来写的,各个数据类型的方法都叫index,
而不是通过父类同名的然后子类都去继承父类然后必须实现一个index的方法,
类似就是一种编码习惯,全凭自己编码自觉,不是硬性规范,
假设list里面的index方法是父类约束的,那么把list里面的index方法删了就不行,因为是根据规范来的
假设用鸭子类型这种全凭自觉那么list里面删了index方法也不会影响整体程序运行
逗比时刻: Python崇尚鸭子类型,即‘如果看起来像、叫声像而且走起路来像鸭子,那么它就是鸭子’ python程序员通常根据这种行为来编写程序。例如,如果想编写现有对象的自定义版本,可以继承该对象 也可以创建一个外观和行为像,但与它无任何关系的全新对象,后者通常用于保存程序组件的松耦合度。 例1:利用标准库中定义的各种‘与文件类似’的对象,尽管这些对象的工作方式像文件, 但他们没有继承内置文件对象的方法 例2:序列类型有多种形态:字符串,列表,元组,但他们直接没有直接的继承关系 鸭子类型: 不崇尚根据继承所得来的相似 我只是自己实现我自己的代码就可以了。 如果两个类刚好相似,并不产生父类的子类的兄弟关系,而是鸭子类型 list tuple 这种相似,会有一些相同的方法,相同方法的名字:index等 都只是依靠自己写的代码 类似list和tuple是自己写代码的时候约束的,而不是通过父类约束同名继承的,那么就没有保障,想删了就可以删了也不会报错 优点 : 松耦合 每个相似的类之间都没有影响 缺点 : 太随意了,没有硬性规范让类必须实现这个功能,只能靠自觉
比如len(list)函数本质上是调用了 list.__len__()方法,因为没有父类约束list这个数据类型,list里面可以把__len__删除
如果删除了__len__那么调用len(list)就不行了,太随意了,因为知道调用要调用__len__方法所以必须实现这个方法
假如list里面的index方法是父类约束的,删了index就不行,因为是根据规范来的 现在删除,不影响整体程序的运行---所以这种相似是自己写代码的时候约束的,而不是通过父类约束的 自己写代码的时候约束是没有保证的,想删了就删了,想留下就留下 优点 : 松耦合 每个相似的类之间都没有影响 list来讲删了一个功能不影响tuple,str --这三个数据类型互相独立,删除哪个都不影响其他的:这就是松耦合,代码耦合的比较松 紧耦合删除功能可能影响其他的代码,毒瘤,代码耦合得太紧 缺点 : 太随意了,没有硬性规定实现某个功能,只能靠自觉 # 强类型语言:多态(只能用多态来编码,不使用多态都不支持多个数据类型传到同一个函数里,
比如len(list),len(str),len(tuple)在python中使用鸭子类型实现的,
而在java等语言中只能使用多态来实现
因为len函数归一化定义的时候需要定义参数的数据类型,这个数据类型不能是list不能是str不能是tuple而应该是list和str,tuple的一个爹fateher传进去定义len函数
这就是多态,一个爹father有三种数据形态,list,str,tuple也就是list,str,tuple都是属于father,
而在python中使用鸭子类型来实现len(list)和len(str),len(tuple)
也就是不越苏,不搞父类规范,list,str,tuple三种数据类型各自内部实现自己的__len__方法,然后做个归一化设计
定义一个len函数,len函数需要传递一个obj进来,len函数的函数体直接obj.__len__(),这就是python鸭子类型的实现
) # python语言(动态强类型语言):鸭子类型 class foo(): def slice(self): pass def index(self): pass class list(foo): def slice(self): pass def index(self): pass class tuple(foo): def slice(self): pass def index(self): pass # list和tuple相似,内部很多重复的代码,所以抽取一个父类,抽取相同的方法到父类,然后继承父类 # 使用父类的规范必须实现相同的内容 8:List类和Tuple类实现了很相似的方法,这两个类就是鸭子类型 因为这两中实现了同样的方法,所以len()函数同时去调用它--这两个数据类型就是鸭子类型 强类型语言就不行,因为len函数传参需要指定类型,传List和Tuple都不行,需要给Tuple和List指定一个爹 class List(): def __len__(self):pass class Tuple(): def __len__(self):pass def len(obj): return obj.__len__() l = Tuple() len(l)
这是在python里面,两种数据类型都实现__len__,然后定义一个len函数实现归一化
python里面不搞父类哪些,两种数据类型各自实现自己的__len__这个很相似的方法-----这两个类List和Tuple就是鸭子类型
他两种都实现了同样的方法所以都可以使用len函数同时去调用,这两个数据类型就是鸭子类型
(在python里才这样,其他强类型语言里就不行,因为len函数这里定义的时候需要告诉他是一个list还是一个tuple,
所以如果定义里传的一个list那么传的是一个tuple1的对象就会报错,数据类型不对,
这时候搞个父类Foo,让list和Tuple继承,当他们的爸爸,len函数这里定义的时候传Foo对象进来
只要是Foo的儿子后面传递进来都可以使用,这时候既可以传一个tuple也能传list,这是其他语言的问题,这就是多态,实现的都是类似代码归一化的功能
) 9:其他语言的多态代码演示如下 class foo(): pass # 摆设父类,证明List和Tuple是一家子,让len函数里能指定数据类型 #强类型语言才要这么搞,python里不需要父类,直接写就行 #因为python语言里有个鸭子类型, class List(foo): def __len__(self):pass class Tuple(foo): def __len__(self):pass def len(foo obj): return obj.__len__() l = Tuple() len(l)
# 强类型语言 多态 # python 语言 鸭子类型 # 接口类和抽象类 在python当中的应用点并不是非常必要
(java里面需要使用这种规范,因为没有鸭子类型,需要通过多态,搞个父类让两个子类具有同一属性,
既然搞了父类顺便java再用这个父类做一些规范的工作就很合理
假设面试别人问设计模式:接口类和抽象类:回答下面 python不崇尚使用继承方式去做规范,list和tuple如此相似的两个数据类型都没有用继承模式去设计 list和tuple用继承是最完美的,里面很多方法完全都可以规范起来 python崇尚鸭子类型,不崇尚采用继承的形式去规范代码
python中不崇尚使用一个父类去约束子类这种方式,比如python中的list和tuple口没有使用这种方式去设计
接口类,抽象类,封装多态继承知识总结: # 接口类 抽象类 # python中没有接口类,有抽象类,抽象类通过abc模块中的metaclass = ABCMeta和@abstructmethod来实现的 # 接口类 抽象类本质是做代码规范用的,希望在子类中实现和父类方法名字完全一样的方法 # 在java的角度上看 接口类和抽象类是有区别的 # java本来就支持单继承 所以就有了抽象类(为了规范子类)单继承父类约束子类,子类只能有一个父类 #按照一个父类的方法来实现,不能同时实现两个父类的方法 # java没有多继承 所以为了接口隔离原则,设计了接口这个概念,支持多继承了 # python既支持单继承也支持多继承,所以对于接口类和抽象类的区别就不那么明显了 # 甚至在python中没有内置接口类(扩展模块有实现接口类的) # 多态和鸭子类型 # 多态 —— python天生支持多态(传参传一个数据类型,为了多个对象都能传进来,为多个类搞个爹,传数据类型的时候 # 把爹的数据类型传上,然后后面写参数,那么这几个子类都能传参数了) # 鸭子类型(python崇尚鸭子类型) —— 不依赖父类的情况下实现两个相似的类中的同名方法 # java里依靠继承关系约束子类都要用这个方法,python里没有父类的事情,两个类自己实现同名的方法就是鸭子类型 # 封装 —— 私有的 # 在python中只要__名字 # 在python中只要__名字,就把这个名字私有化了 # 私有化了之后 就不能能从类的外部直接调用了 # 静态属性 ,方法, 对象属性 都可以私有化 # 这种私有化只是从代码级别做了变形,并没有真的约束 # 变形机制 _类名__名字 在类外用这个调用,在类的内部直接__名字调用
11:面向对象之——封装
广义上面向对象的封装:代码的保护,面向对象的思想本身就是一种封装
只让自己的对象能调用自己类中的方法,实现代码的保护
狭义上的封装:面向对象的三大特性之一
把属性 和 方法都藏起来 不让你看见,仅对外提供公共访问方式。
好处
1. 将变化隔离;
2. 便于使用;
3. 提高复用性;
4. 提高安全性;
封装原则
1. 将不需要对外提供的内容都隐藏起来;
2. 把属性都隐藏,提供公共方法对其访问。
python中的私有变量和私有方法:
在python中用双下划线开头的方式将属性隐藏起来(设置成私有的)
python中私有属性和私有变量的使用
class Person: __key = 123 # 双下划线定义私有静态属性
def __init__(self, name, passwd): self.name = name self.__passwd = passwd # python中双下划线定义私有实例属性
def __get_pwd(self): # python中双下划线定义私有方法
return self.__passwd # 只要在类的内部使用私有属性,就会自动的带上_类名 # 类的外部没有这回事的,不会自动转化
# self.__passwd == self._Person__passwd self当前等于alex
# return self._Person__passwd这样写也可以
def get_pwd(self): return self.__passwd
def login(self): # 正常的方法调用私有的方法 self.__get_pwd() alex = Person('alex', 'alex3714') # print(alex.__passwd) # 私有属性__passwd外部无法调用 # print(alex.__dict__) # {'name': 'alex', '_Person__passwd': 'alex3714'} # python里的私有属性并不是真正约束你数据安全,而是代码级别上加了一层密而已 # 只是不允许print(alex.__passwd) 这样外部调用 # 私有属性外头调不到的,只能内部调用
# print(alex._Person__passwd) # _类名__属性名 这个名字能调用__passwd这个私有属性 # 可以这样掉,但是不推荐这样用,有这个原理,直接调用是调用不了的,代码级别上变得私有了
# print(alex.get_pwd()) # alex3714 通过get_pwd方法也能获取到静态属性self.__passwd的值 # 为什么这样能获取到静态属性:程序里面定义双下划线的私有属性的时候, # 存储的时候就已经存成了_person_password 这种形式了,在哪里都是这么存储
# print(alex.__get_pwd()) # 私有的方法不能在外部调用 错误
alex = Person('李二狗', 'liergoushabi') print(alex.__dict__) # {'name': '李二狗', '_Person__passwd': 'liergoushabi'} print(Person.__dict__) # {'__module__': '__main__', '_Person__key': 123, '__init__': <function Person.__init__ at 0x0000021BFB13C4C0>, # '_Person__get_pwd': <function Person.__get_pwd at 0x0000021BFB13C700>, 'get_pwd': <function Person.get_pwd at # 0x0000021BFB3AD0D0>, 'login': <function Person.login at 0x0000021BFB3AD550>, '__dict__': <attribute '__dict__' of # 'Person' objects>, '__weakref__': <attribute '__weakref__' of 'Person' objects>, '__doc__': None}
2:只要在类的内部使用私有属性,就会自动的带上_类名 类的外部没有这回事的,不会自动转化 class Person: __key = 123 # 双下划线定义私有静态属性 def __init__(self, name, passwd): self.name = name self.__passwd = passwd # python中双下划线定义私有实例属性 def __get_pwd(self): # python中双下划线定义私有方法 return self.__passwd # 只要在类的内部使用私有属性,就会自动的带上_类名 def get_pwd(self): return self.__passwd def login(self): # 正常的方法调用私有的方法 self.__get_pwd() alex = Person('alex', 'alex3714') alex.__high = 1 print(alex.__dict__) # {'name': 'alex', '_Person__passwd': 'alex3714', '__high': 1} print(alex.__high) # 打印:1 # 这样在类外面定义一个双下属性__high,没有加_Person,不是私有属性,外部还是能够直接调用 # 自动的带上_类名 只在类的内部调用私有属性才会发生,类的外部定义不了私有属性
3:私有方法:类的内部定义def __get_pwd(self): 这种双下方法就变成私有方法, 私有方法只能提供类的Person内部调用,外部使用不了 class Person: __key = 123 # 双下划线定义私有静态属性 def __init__(self, name, passwd): self.name = name self.__passwd = passwd # python中双下划线定义私有实例属性 def __get_pwd(self): # python中双下划线定义私有方法 return self.__passwd # 只要在类的内部使用私有属性,就会自动的带上_类名 def get_pwd(self): return self.__passwd def login(self): # 正常的方法调用私有的方法 self.__get_pwd() alex = Person('alex', 'alex3697') print(alex.__dict__) # {'name': 'alex', '_Person__passwd': 'alex3714'} print(Person.__dict__) # {'__module__': '__main__', '_Person__key': 123, # '__init__': <function Person.__init__ at 0x00000189198441E0>, # '_Person__get_pwd': <function Person.__get_pwd at 0x00000189198447B8>, # 'get_pwd': <function Person.get_pwd at 0x0000018919844840>, # 'login': <function Person.login at 0x00000189198448C8>, # '__dict__': <attribute '__dict__' of 'Person' objects>, # '__weakref__': <attribute '__weakref__' of 'Person' objects>, '__doc__': None} # alex.__get_pwd() # 私有方法__get_pwd调用不了,调用就报错AttributeError: 'Person' object has no attribute '__get_pwd' print(alex._Person__get_pwd() ) # alex3697 这样才可与调用__get_pw这个私有方法
4:python中所有的私有 都是在变量的左边加上双下划綫 对象的私有属性 类中的私有方法 类中的静态私有属性 所有的私有的 都不能在类的外部使用,只能类的内部使用--了解机制
私有属性:私有属性通过类里面的方法查看和设置 get方法和set方法,让私有属性的保护,不随随便便修改变量 class Room: # 房子类 def __init__(self, name, length, width): self.__name = name # 房子所有者 私有属性 self.__length = length # 房子长 私有属性 self.__width = width # 房子宽 私有属性 def get_name(self): # 返回房子的名称 return self.__name def set_name(self, newName): # 这样写可以约束一下,不让外面随便修改self.__name # 私有属性的保护,不随随便便修改变量 # c++语言全部的属性都设置成这个样子, # 每一个属性都有一个get方法和set方法 # python没那么搞,不想让别人看就设置成私有 if type(newName) is str and newName.isdigit() == False: self.__name = newName else: print('不合法的姓名') def area(self): # 计算房子的面积 , return self.__length * self.__width # 两个私有属性,隐藏不让看,但是可以用来计算看到结果---私有属性的用法 jin = Room('金老板',2,1) print(jin.area()) jin.set_name('2') print(jin.get_name())
# 这里设置name为"2"没有设置成功,所以获取name还是一开始的"金老板"
父类的私有属性 能被 子类调用么(父类的私有属性是无法被子类继承的) 父类的私有属性是不能被子类调用的 私有属性在类的内部,调用过程中发生了变形 __key = '123'这样定义私有属性的时候,内部存储的是_Foo__key='123' 存储在Foo类的内存空间里
Son这里调用不了父类的私有属性的,父类的私有的静态属性,对象属性,方法都调用不了 私有属性只能在自己类里调用,别人类调用不了,没有被子类继承
case1:
class Foo: __key = '123' # 私有属性__key在Foo内部存储的是:_Foo__key = "123" class Son(Foo): print(Foo.__key) # 这么在类的内部调用私有属性__key发生变形:会找 _Son__key这个属性 # 而在Foo类的空间里存储的私有属性是_Foo__key = "123",所以在父类里_Son__key这个属性找不到的 # 所以子类找不到父类中的私有属性的(不管父类私有的静态属性,对象属性,还是方法子类都找不到) # 定义成私有的了就只能自己类里使用了,再怎么继承也继承不到 # AttributeError: type object 'Foo' has no attribute '_Son__key'
case2: class Foo: __key = '123' # _Foo__key name = "Foo" @classmethod def p_n(cls): # 静态属性name只能通过类方法修改 print(cls.name) cls.name = 'zzz' print(cls.name) def p_z(self): print(self.name) # name这个静态属性可以通过self和Foo调用,但是修改只能通过类Foo去修改 print(Foo.name) # Foo().p_n() # Foo().p_z() print(Foo.__dict__) class Son(Foo): print(Foo.name) # print(Foo._Foo__key) # print(_Foo) # print(Foo.__key) # 父类的私有属性__key是不能被子类调用的 # print(Foo.__key) # 这里变形会找Foo._Son__key所以找不到
什么情况下会用到私有的这个概念的场景 1.隐藏起一个属性 不想让类的外部调用 2.我想保护这个属性,不想让属性随意被改变 3.我想保护这个属性,不被子类继承
12:面向对象之——property的使用,property是内置装饰器函数 只在面向对象中使用
1:property:内置装饰器函数 只在面向对象中使用 使用@property 装饰器把方法伪装成属性 如下: 加了@property装饰器调用方法的时候可以不加括号--伪装 使用@property装饰的方法里面不能传任何参数,不然c1.area这样调用不了area这个方法了 from math import pi class Circle: # 圆类 def __init__(self, r): self.r = r @property def perimeter(self): # 计算圆的周长 return 2 * pi * self.r @property def area(self): # 计算圆的面积 return self.r ** 2 * pi c1 = Circle(5) print(c1.area) # 圆的面积 78.53981633974483 print(c1.perimeter) # 圆的周长 31.41592653589793 # 圆的面积和周长是一个方法,类里面定义的是一个动作:方法 名词:属性 # 这里圆的面积和周长是一个名词,应该是一个属性 # 这个属性是通过计算得到的 # 使用@property 装饰器把方法伪装成属性 # 没有@property 得到面积和周长要c1.area() c1.perimeter() 这样调用方法 # 有了@property 可以c1.area和c1.perimeter得到圆的周长和面积,看起来像一个属性了
例一:BMI指数(bmi是计算而来的,但很明显它听起来像是一个属性而非方法, 如果我们将其做成一个属性,更便于理解) 成人的BMI数值: 过轻:低于18.5 正常:18.5-23.9 过重:24-27 肥胖:28-32 非常肥胖, 高于32 体质指数(BMI)=体重(kg)÷身高^2(m) EX:70kg÷(1.75×1.75)=22.86 class Person: def __init__(self, name, high, weight): self.name = name self.high = high self.weight = weight @property # @property 方法伪装成属性 def bmi(self): # 计算操作属性的在类里面就是方法 return self.weight / (self.high ** 2) jin = Person('金老板', 1.71, 70) print(jin.bmi) # 23.938989774631512 # jin.bmi = 50 # 报错:AttributeError: can't set attribute # 方法伪装的属性不能修改的 ,bmi是计算出来的 ,这个bmi属性修改不了 jin.age = 30 # 但是可以 往对象里面加新的属性 print(jin.age)
对对象的修改:@property和@name.setter配合使用 1:一定要现有一个@property方法后面才能用@name.setter 2:本来方法伪装的属性是不能修改的,现在使用@name.setter增加一个新的方法 可以让外面调用属性修改 1:tiger.name 调用name属性的时候使用的是@property装饰的name方法 2:tiger.name = '全班' 修改name属性值得时候调用的是@name.setter装饰的name方法 class Person: def __init__(self, name): self.__name = name # 私有属性name @property def name(self): # name方法,把所有人的name加了个sb,name方法伪装成一个属性 return self.__name + 'sb' @name.setter # 修改操作,把self.__name私有属性修改成new_name # 这里要定义一个和上面伪装属性的name一模一样的方法 # 这里只接受一个参数new_name,接收到的参数是外部调用的时候=等号后面的值 def name(self, new_name): self.__name = new_name tiger = Person('泰哥') print(tiger.name) tiger.name = '全班' print(tiger.name)
@property的练习: 使用@property场景:把一个属性也就是商品原价设置成私有的,外部想要对这个私有属性进行包装操作(打折)产生一个新的属性 就可以使用@property定义一个同名的方法,然后去查看属性时候实际查看的是私有属性和一些操作结束的结果(这里是打折操作), 使用property装饰这个打折操作后这个操作的结果(打折后的商品加个)变成一个属性了 class Goods: # 定义一个Goods物品类 discount = 0.8 # 折扣 def __init__(self, name, price): self.name = name # 商品名字 self.__price = price # 商品原价设置成私有属性 @property def price(self): # 折后价格定义成一个方法,使用property变成一个属性 return self.__price * Goods.discount apple = Goods('苹果', 5) # 苹果实例 5块钱 print(apple.price) # 4.0
property:属性的 查看 修改 删除 class Person_1: def __init__(self, name): self.__name = name self.price = 20 @property def name(self): return self.__name @name.deleter # 定义一个删除方法 def name(self): del self.__name # 删除__name这个私有属性 @name.setter # 修改名字的方法,通过公有的属性(方法)对私有属性的查和修改和删除--@property def name(self, new_name): self.__name = new_name brother2 = Person_1('二哥') print(brother2.name) # 打印:二哥 调用property装饰的name方法 del brother2.name # 执行del 动作触发了被@name.deleter装饰的删除方法,只要一执行del XXX, # 就去执行类里面被 @name.deleter装饰的name方法,方法里内容是什么就执行什么 # del 这里并没有删除作用,只是和deleter互相关联了 # 执行del 就去类里找deleter装饰的函数,执行函数里面的内容 # 借助了公有的方法删除内部私有的属性 --类内操作 # 正常 del 属性 在python里能删除真实的属性 # 而 del brother2.name 这里没有办法通过对象删除一个函数,函数是在类的名称空间的 # 类有权利删除类里定义的方法,而对象没有权利删除类里的方法 # 所以这里只能调用函数帮助完成删除操作 # print(brother2.name) # 报错,因为通过@name.deleter装饰的方法删除了__name这个私有属性:AttributeError: 'Person_1' object has no attribute '_Person_1__name' print(brother2.price) del brother2.price # 实例属性可以del直接在类外面删除 # print(brother2.price) # 因为实例brother2的price属性被删除了所以报错:AttributeError: 'Person_1' object has no attribute 'price'
13:面向对象之——类的静态的方法@classmethod的使用(当这个方法的操作只涉及静态属性的时候,就应该使用classmethod来装饰这个方法定义一个类方法)
1:method 方法 staticmathod 类里面的静态的方法 *** classmethod 类方法 **** property 类方法伪装成属性,*****
classmethod:类的操作行为,而不是实例对象的 class Goods: __discount = 0.8 def __init__(self, name, price): self.name = name self.__price = price @property def price(self): return self.__price * Goods.__discount def p_discount(self): print(self.__discount) def change_discount(self, new_discount): Goods.__discount = new_discount apple = Goods('苹果', 5) print(apple.price) # 4.0 apple.p_discount() # 0.8 apple.change_discount(0.5) apple.p_discount() # 0.5 # 上面这样通过apple对象的change_discount方法修改Goods里面的类属性也是可以实现的 # 但是只能通过apple.change_discount(0.5)来修改折扣 # 不是很合理,折扣是所有的商品的折扣,是类的,和某个商品没有关系, # 所有的商品都从8折变成5折,不应该依赖苹果对象修改折扣 # 需要Goods.change_discount就完美了,不需要依赖任何对象调用,直接商品类调用
def change_discount(new_discount):方法直接删除self也可以,但是不能这么写 class Goods1: __discount = 0.8 def __init__(self, name, price): self.name = name self.__price = price @property def price(self): return self.__price * Goods1.__discount @classmethod def p_discount(cls): print(cls.__discount) def change_discount(new_discount): Goods1.__discount = new_discount Goods1.change_discount(0.5) # 这样写也可以,但是不建议使用, Goods1.p_discount() # 直接在类Coods1的内存空间里存储了一个change_discount的函数, 可以直接Goods1.change_discount(xxx)调用函数,但是不建议这样使用 g = Goods1('苹果', 5) g.change_discount(0.6) # TypeError: change_discount() takes 1 positional argument but 2 were given
# 这样 g.change_discount(0.6) 实例对象调用change_discount这个方法的时候会报错,
因为实例对象g调用change_discount会自动传个g对象给change_discount方法的第一个参数,
这里又传了0.6这个参数进去,所以g.change_discount(0.6)相当调用change_discount方法
传递了g和0.6两个参数进去,而change_discount只能接收一个参数所以报错
Goods1.p_discount()
# 实例方法只能实例对象调用,类调用异常 class A: def __init__(self, name, age): self.name = name self.age = age def zzz(self): print(self) return 'zzz' a = A('李二狗', 18) print(a) # <__main__.A object at 0x0000018C71676E50> print(a.zzz()) # <__main__.A object at 0x0000018C71676E50> # zzz # A.zzz() # 报错:因为没有传递self参数进去,TypeError: zzz() missing 1 required positional argument: 'self' print(A.zzz(a)) # 传个实例对象a进去给self参数才正常调用 # <__main__.A object at 0x0000028C3CA16E50> # zzz # 类里面定义一个普通函数只能类调用,实例调用会报错 class A: def __init__(self, name, age): self.name = name self.age = age def zzz(): return 'zzz' print(A.zzz()) # 打印:zzz a = A('李二狗', 18) a.zzz() # 报错:TypeError: zzz() takes 0 positional arguments but 1 was given # 因为实例对象a调用zzz方法的时候会默认传递一个参数a到zzz方法里,但是zzz方法不接受任何参数所以报错 # a.zzz()类似这样A.zzz(a) 这样调用,多传了个a参数进去zzz方法不能接收参数所以报错
@classmethod 类方法 1:@classmethod 类方法能够直接通过 Goods2.方法名 类名调用 2:@classmethod 类方法还能够直接通过 对象.方法名 实例对象调用 当这个方法的操作只涉及静态属性的时候,就应该使用classmethod来装饰这个方法,---定义一个类方法 class Goods2: __discount = 0.8 def __init__(self, name, price): self.name = name self.__price = price @property def price(self): return self.__price * Goods2.__discount @classmethod def p_discount(cls): print(cls.__discount) @classmethod # 单纯只属于类的方法,不一定需要对象去调用了 # 把一个方法 变成一个类中的方法,这个方法就直接可以被类调用,不需要依托任何对象 def change_discount(cls, new_discount): # cls指代类 cls.__discount = new_discount Goods2.change_discount(0.5) # change_discount是类方法了,直接使用类名Goods2调用 Goods2.p_discount() # 0.5 改成了0.5折 apple = Goods2('苹果', 10) apple.change_discount(0.3) # change_discount类方法通过实例对象也能调用 Goods2.p_discount() # 0.3
当类里面某个方法的操作只涉及静态属性的时候,就应该使用classmethod来装饰这个方法定义一个类方法
类方法可以类名调用也可以实例对象调用
14:面向对象之——staticmethod 类里面定义普通函数,一个普通函数,和类没有什么关系
staticmethod :只是一个函数,和类没有什么关系, 在完全面向对象的程序中, 如果一个函数 既和对象没有关系 也和类没有关系 那么就用staticmethod将这个函数变成一个静态方法 类方法(classmethod)和静态方法(staticmethod) 都可以通过类名调用的 实例对象对象可以调用类方法和静态方法(静态方法和类方法都是存储在类里的名字,可以通过对象调用) 虽然对象可以调用类方法和静态方法,但是还是推荐使用类名调用 对象可以调用静态属性(对象有个指针指向类,可以在类里找名字) 类方法:有一个默认参数 cls 代表这个类 cls=类 self=对象 静态方法:没有默认的参数 就象函数一样(可以传普通参数,但是不传self和cls这种特殊必传的参数 所以静态方法就是普通函数,和类跟方法没关系。不会涉及到类里面的静态属性和实例属性的调用) java只支持面向对象编程,python支持面向对象和过程编程 class Login: def __init__(self, name, password): self.name = name self.pwd = password def login(self): pass @staticmethod # 静态方法,不和类和对象参产生任何关系,既不需要默认传一个self # 也不需要传一个cls,静态方法不操作类里面的任何属性(实例属性和静态属性) def get_usr_pwd(): # 静态方法 usr = input('用户名 :') pwd = input('密码 :') Login(usr, pwd) # 拿到用户名和密码执行登录 return usr, pwd res = Login.get_usr_pwd() # 调用静态方法,不需要进行任何实例化对象,就像任何普通的函数一样 # 但是调用还是需要前头加类名 print(res) # 在完全面向对象的程序中,(java就是全面向对象的程序),如果一个函数 既和对象没有关系 也和类没有关系 那么就用staticmethod将这个函数变成类里的一个静态方法
面向对象三大特性:封装,继承,多态
接口:面向对象写的方法都是一个对外的接口,要操作类中的对象使用的方法,
给出的方法设计的参数,设计的返回值都经过深入思考拿到一个返回值
面向对象知识点汇总: class 类名:首字母大写(父类,父类2): 静态属性='' # 静态属性,类属性 def __init__(self): pass # init初始化方法 self.name='alex' def func(self): # 动态属性,类方法 print(self.age) 对象=类名() # 实例化,这个括号里传的参数对应init里面的参数(init方法看传参) #对象.方法名() #对象.属性名 #对象能调用init方法里面的属性 对象.name 对象.age=18 # 给对象创建一个age属性,值等于18 对象.func() # 类名.func(对象) 能调用func中新传入的age属性 组合:表达的是 什么有什么的关系 --组合必须是多个类的关系 一个类的属性是另外一个类的对象 命名空间:类和对象分别存在不同的命名空间里,对象能找到类而类找不到对象(单向查找) 所以类永远调用不了对象中的名字,而对象找不到自己空间中的名字的时候调用类的 面向对象的三大特殊:封装,继承,多态 继承: 单继承: 父类(超类,基类), 子类(派生类):派生方法,只要是父类没有的都是派生出来的, 子类对象调用方法和属性的时候先查找自己对象里的,再查找这个对象的类的、 最后查找类的爹,自己没有就用父类,都找不到就报错 多继承:如果子类自己有用自己的,如果没有就用离子类最近的那个父类的方法 经典类和新式类的继承规则不同,新式类是广度优先,经典类是深度优先---很重要 抽象类,接口类 python本身就支持抽象类,但是不支持接口类,可以使用某些手段实现接口类 python中抽象类和接口类差不多 super:只能在python3中使用, super是根据mro广度优先顺序找上一个类的,不是单纯的找父类 super和mro一套 super就是找继承的关系节点 多态:python本身支持多态, 多态:其他语言实现两个差不多类的机制 鸭子类型:python里实现两个差不多类的机制 封装:私有属性和方法,私有静态属性 __ 双下名字,双下方法 如果是私有的只能在类的内部调用,子类都无法继承,记住这个就行 封装:为了隐藏属性,不让外面随便使用 @property # 将方法变成属性调用,规范, @name.setter # 调用类里面的name命名函数 @staticmethod # 定义静态方法,不重要 @classmethod # 定义类方法(当一个方法只使用类的静态变量时就把这个方法定义成类方法加 # @classmethod,默认传cls参数) class Coods: __discount=0.8 @classmethod #类方法修改类(静态)属性 def change_discount(cls,indata): cls.__discount=indata Coods.change_discount(0.5) # 修改了打折折扣,类属性,所有对象共享的
15:简单练习


练习一:在终端输出如下信息 小明,10岁,男,上山去砍柴 小明,10岁,男,开车去东北 小明,10岁,男,最爱大保健 老李,90岁,男,上山去砍柴 老李,90岁,男,开车去东北 老李,90岁,男,最爱大保健 老张… 1:函数式编程 def shangshan(name, age, sex): # 上山函数 print('%s,%s岁,%s,上山去砍柴' % (name, age, sex)) def drive(name, age, sex): # 开车函数 print('%s,%s岁,%s,开车去东北' % (name, age, sex)) def favor(name, age, sex): # 爱好函数 print('%s,%s岁,%s,最爱大保健' % (name, age, sex)) shangshan('小明', '10', '男') drive('小明', '10', '男') 2:面向对象编程 当调用某一些函数需要反反复复传入相同的值的时候适合面向对象编程 适合面向对象编程的情况: 非常明显的处理一类事物,这些事物都具有相似的属性和功能 当有几个函数 需要反反复复传入相同的参数的时候,就可以考虑面向对象 这些参数都是对象的属性 class Person(): # 定义一个人类 def __init__(self, name, age, sex): self.name = name self.age = age self.sex = sex def shangshan(self): print(f'{self.name},{self.age},{self.sex},上山去砍柴') def driver(self): print(f'{self.name},{self.age},{self.sex},开车去东北') def favor(self): print(f'{self.name},{self.age},{self.sex},最爱大保健') xiaoming = Person('小明', '10', '男') xiaoming.driver() xiaoming.shangshan() xiaoming.favor() # 这样调用小明的方法不需要反反复复传参 3:练习 circle 属性:半径 两个方法:求周长和面积 周长:2pir 面击:pir**2 from math import pi class Circle(): # 定义一个圆类,需要半径属性 def __init__(self, radius): self.radius = radius def perimeter(self): return self.radius * 2 * pi def the_measure_of_area(self): return self.radius ** 2 * pi c1 = Circle(5) print(c1.the_measure_of_area()) # 78.53981633974483 计算面击 print(c1.perimeter()) # 计算周长
16:反射:getattr,hasattr,setattr三个内置函数的使用
反射:
反射的概念是由Smith在1982年首次提出的,
主要是指程序可以访问、检测和修改它本身状态或行为的一种能力(自省)。
这一概念的提出很快引发了计算机科学领域关于应用反射性的研究。
它首先被程序语言的设计领域所采用,并在Lisp和面向对象方面取得了成绩。
python面向对象中的反射:通过字符串的形式操作对象相关的属性。
python中的一切事物都是对象(都可以使用反射)
变量name='alex'
'name' 通过字符串拿到变量'alex'
class Teacher: dic = {'查看学生信息': 'show_student', '查看讲师信息': 'show_teacher'} def show_student(self): # 展示学生方法 print('show_student') def show_teacher(self): # 展示讲师信息 print('show_teacher') @classmethod # 类方法 def func(cls): print('hahaha') menu = Teacher.dic # menu for k in menu: print(k) ret = getattr(Teacher, 'dic') print(ret) # {'查看学生信息': 'show_student', '查看讲师信息': 'show_teacher'}
这就是反射的机制:有一个字符串的数据类型的在命名空间存储的名字,能够通过getattr这个方法拿到这个值 从Teacher这个类的命名空间里拿到'dic'这个名字的值 等同Teacher.dic python中一切皆对象,类也是对象,对象是某个类的对象,类是创建这个类的那个类的对象模块也是对象,根据模块调用模块里的名字
1:类.属性: ret = getattr(Teacher, 'dic') # 这里寻找的是 dic变量的值,拿到一个值 print(ret) # {'查看学生信息': 'show_student', '查看讲师信息': 'show_teacher'}
2:类.方法 ret2=getattr(Teacher,'func') 这里寻找的是 func函数的值,拿到的是一个函数的地址, 函数的内存地址+() 就是执行函数 等同Teacher.func获取到Teacher类里func这个函数 ret2 = getattr(Teacher, 'func') # <bound method Teacher.func of <class '__main__.Teacher'>> print(ret2) # 打印的是一个地址,类里面func函数的地址 ret2() # 函数的地址+()就能运行这个函数了 打印:hahaha
3:hasattr()和getattr()是一对,
hasattr():表示命名空间能拿到名字返回True,否则返回false 那么有这个属性肯定能使用getattr()这个方法 如果命名空间没有一个属性而使用getattr()去获取属性的值,就会报错 # getattr(Teacher, 'dic4') # 报错,因为Teacher这个类的名称空间没有dic4这个名字 if hasattr(Teacher, 'func4'): ret = getattr(Teacher, 'func4') print(ret) else: print('Teacher名称空间没有func4这个名字')
4:实例对象也可以使用getattr反射调用方法 class Teacher: dic = {'查看学生信息': 'show_student', '查看讲师信息': 'show_teacher'} def show_student(self): # 展示学生方法 print('show_student') def show_teacher(self): # 展示讲师信息 print('show_teacher') @classmethod # 类方法 def func(cls): print('hahaha') alex = Teacher()
alex.show_student() # 打印:show_student 调用show_student这个方法
res = getattr(alex, 'show_student') # 从alex这个实例对象拿到show_student这个方法的内存地址,加()可以执行这个方法 print(res)
# 打印:<bound method Teacher.show_student of <__main__.Teacher object at 0x000001E9F8981550>>
# res,得到的是一个绑定方法,Teacher类里面的show_student这个方法,这个方法绑定了alex这个实例对象,所以下面可以res()加括号调用这个绑定方法 res() alex = Teacher() for key in Teacher.dic: print(key)
key = input('输入需求:>>>>>>') print(Teacher.dic[key]) # 拿到字符串类型的方法名,比如输入"查看学生信息"这个字符串,Teacher.dic[key]这里得到"show_student" 这个字符串 func = getattr(alex, Teacher.dic[key]) func() # 使用getattr获取类里面的方法,然后调用方法,这样不需要if else input去判断了, # 这里直接使用反射,输入什么,就调用对应的方法,不需要关心输入什么
5:通过反射:反射拿到的名字和字符串相关的 对象名 获取对象属性 和 普通方法 类名 获取静态属性 和类方法 和 静态方法 普通实例方法:self 静态方法:@staticmethod 类方法:@classmethod 属性方法:@property 私有方法:__xxx 双下划线 静态属性 普通属性(实例属性) 私有属性:__xxx 双下划线 继承 封装的
6:isinstance
isinstance()是一个内置函数,用于判断一个对象是否是一个已知的类型,类似type()
isinstance() 函数来判断一个对象是否是一个已知的类型,类似 type()。
isinstance() 与 type() 区别:type() 不会认为子类是一种父类类型,不考虑继承关系,而isinstance() 会认为子类是一种父类类型,考虑继承关系。
isinstance(obj,cls)检查是否obj是否是类 cls 的对象 1:判断对象和类的关系 2:判断子类和父类的关系 class A: pass
class Foo(A): pass obj = Foo() print(isinstance(obj, Foo)) # 打印:True 判断obj是不是Foo的对象,是返回True
print(isinstance(Foo, object)) # 打印:True # Foo默认继承object这个基类,子类是父类的对象(子类是父类的一个子类)
class A: pass class B(A): pass isinstance(A(), A) # returns True type(A()) == A # returns True isinstance(B(), A) # returns True type(B()) == A # returns False
print(isinstance(B, A)) # False
print(isinstance(B(), A)) # True
print(isinstance(B(), object)) # True
print(isinstance(B, object)) # rue
7:issubclass(sub, super):检查sub类是否是 super 类的派生类 检查子类和父类的关系,sub是否是super的子类 class Foo(object): pass class Bar(Foo): pass print(issubclass(Bar, Foo)) # True
8:反射 是用字符串类型的名字 去操作 变量 和eval有点相似eval('1+2+3'):字符串形式操作代码,拿到python代码类型的字符串执行 eval代码里产生很大隐患,执行的字符串是别的地方拿的,用户输入或者文件读取,往里传输的字符串一旦执行就很危险 反射:就没有安全问题,反射不是真的拿到一段新的python代码去执行,而是去操作内存当中已经存在的变量 如:执行已经存在的函数,或者写在类里的方法,安全隐患很低,因为调用自己的函数不会出现很大隐患 name = 'alex' # 正常情况下只能通过name取到名字,但是现在只有一个字符串类型的'name'那么只能使用反射操作这个变量
9:反射对象中的属性和方法 反射就下面四个方法: hasattr() getattr() setattr() delattr() class A: def func(self): print('in func') a = A() print(a.__dict__) # {} a.name = 'alex' # 正常往实例对象a里面添加属性 print(a.__dict__) # {'name': 'alex'}
10:getattr(对象(名称空间), 属性名(名称空间里的属性的字符串形式 )) 有时候知道对象有属性,但是只能拿到字符串形式, 比如说 变量名=input print(getattr(a, 变量名)) class A: def func(self): print('in func') a = A() a.name = 'alex' # 正常往实例对象a里面添加属性
# 反射对象的属性 getattr 通过字符串拿到a名称空间里 name变量的值
print(getattr(a, 'name')) # 打印:alex # 通过变量名的字符串形式获取到的值:这就是反射的核心内容 # 反射:当某一种情况下只有字符串,需要拿这个字符串名称属性对应的值的时候---反射
11:通过__dict__找到名称空间属性的值(可以通过getattr也可以使用对象的__dict__特性) 利用字典的特性, 但是如果想执行对象里的方法,实例对象里只存属性,没有存方法,方法都存在类A里面 class A: def func(self): print('in func') a = A() a.name = 'alex' 变量名 = input('>>>>>') # 外部输入字符串形式的“name” print(a.__dict__) # {'name': 'alex'} print(a.__dict__[变量名]) # alex
12:反射实例对象里的方法 1:getattr拿到方法的内存地址 2:内置地址() 就是调用函数 class A: def func(self): print('in func') a = A() a.name = 'alex' res = getattr(a, 'func') # 拿到a对象里 func字符串对应的值(这里的值就是方法的内存地址) print(res) # 得到的是一个绑定方法,方法func绑定了实例对象a # <bound method A.func of <__main__.A object at 0x000001E085A0EB38>> res() # res是内存地址,地址()就是调用函数
13:python里一切皆对象,类也是对象 1:反射类的属性和类的方法 2:反射类的方法:@classmethod和@staticmethod都可以被类名直接调用 类名.方法名()去调用,不需要默认传的必须参时 self的方法需要 类名.方法名(对象)去调用,需要传一个对象参数, class B(): price = 20 # 静态属性,B.price调用的属性 def func(self): print('in func') @classmethod def inner(cls): print('类方法') # 1:反射类的属性(静态属性)--反射拿到的值一定是正常就能取到值 print(getattr(B, 'price')) # 20 # 2:反射类的方法 B.inner() # 类名.类方法名称() 可以直接调用方法 if hasattr(B, 'inner'): getattr(B, 'inner')() # <bound method B.inner of <class '__main__.B'>> else: print('空间里没有这个名称')
getattr(B, 'inner'):得到的是一个绑定方法,方法inner和类B绑定,因为类方法可能使用到类名称空间的一些属性什么,所以得到的是一个绑定方法
14:模块里面的反射 1:反射模块里的属性 2:反射模块里的方法 my_module.py 里定义如下内容 day = 'Monday' # 周一 def hahhaha(): print('hahahaha') class C: pass from day27 import my_module print(my_module.day) # 打印:Monday 这是模块属性的正常调用 # 1:反射形式拿模块属性 res = getattr(my_module, 'day') print(res) # Monday # 2:反射模块里的方法 ret = getattr(my_module, 'hahhaha') print(ret) # <function hahhaha at 0x000001D1EEC34950> 拿到函数的内存地址 ret() # 打印:hahahaha
15:反射自己模块文件 1:反射当前自己模块文件的变量 2:反射当前自己模块文件的函数 year = 2021 def qqxing(): print('qqxing') import sys # sys.modules查看所有导入进来的模块,返回一个字典,前面的键是模块名称,后面的值是模块对象 print(sys.modules) print(sys.modules['__main__']) # 打印:<module '__main__' from 'E:/Users/ywt/PycharmProjects/Python_Development/day27/002 反射.py'> # sys.modules['__main__'] 找到的是当前模块 print(sys.modules["__main__"].year) # 打印:2021 调用本模块的year名字 # 1:反射获取本模块的变量 ret = getattr(sys.modules["__main__"], 'year') print(ret) # 2:反射获取本模块的函数 res = getattr(sys.modules["__main__"], 'qqxing') res() # qqxing res1 = getattr(sys.modules[__name__], 'qqxing') res1() 还是要用__name__这个内置的变量,在本模块运行时候 __name__ = "__main__"
而如果被其他模块导入执行的时候 __name__ = 模块名称
这样不仅在本模块正常反射,被其他模块导入使用的使用也能正常反射当前这个模块
如下:
import sys
from day27 import my_module
print(sys.modules['day27.my_module'].day)
# 这样调用my_module模块里的day变量,
# 但是无法调用my_module模块里if __name__ == '__main__':里定义的函数和变量
16:反射练习 time 模块 输入time就打印time.time 输入asctime就调用time.asctime 随意输入函数方法名调用内置函数中的方法 ----反射 要反射的函数有参数:反射调用的使用传参就像 import time print(time.time()) # 1644406712.8966777 print(time.asctime()) # Wed Feb 9 19:38:32 2022 f_time = getattr(time, 'time') # 反射 print(f_time()) # 1644406712.8966777 print(getattr(time, 'asctime')(time.localtime(1500000000))) # Fri Jul 14 10:40:00 2017
17:一个模块中的类被反射得到 xxx.xxx 的形式都能通过反射拿到 from day27 import my_module res = getattr(my_module, 'C') # <class 'day27.my_module.C'> 拿到一个类的地址 res() # 类地址() 相当于实例化类
18: hasattr(对象,变量)和getattr(对象,变量) 是一对,配合使用,hasattr判断模块有这个变量
才能getattr拿到这个变量的值
19: setattr() 和 delattr() setattr() 设置修改变量 delattr() 删除一个变量 本模块,类里面,都可以使用---少用,对程序不安全 # setattr()的使用 class A(): pass setattr(A, 'name', 'alex') # 相当于给A对象添加一个静态属性name,值为'alex' # A的name存储在类的内存空间里面 print(A.name) a = A() setattr(a, 'name', 'nezha') # 给实例对象a的内存空间添加一个name属性,值为'nezha' # a的name存储在对象的内存空间里的 print(a.name) # 2:delattr() delattr(a, 'name') # 删除a对象的name属性,对象的name属性没有了,会从类的空间找name属性 print(a.name) delattr(A, 'name') # print(a.name) # AttributeError: 'A' object has no attribute 'name' # 现在A类,和a对象内存空间的name属性都删了,就找不到了
17:简单练习
使用python编写一个简单的计算器 express='1 - 2* ( (60-30 +(-40/5) * (9-2*5/3 + 7 /3*99/4*2998 +10 * 568/14 ))- (-4*3)/ (16-3*2) ) 比如计算上面的express: 步骤如下: 1:去空格 2:提取括号里面没有其他括号的表达式 3:计算没有括号的表达式(乘除优先) import re def cal_exp_son(exp_son): # 计算子表达式 # 用来计算原子型的表达式,两个数之间的乘除法 if '/' in exp_son: a, b = exp_son.split('/') return str(float(a) / float(b)) elif '*' in exp_son: a, b = exp_son.split('*') return str(float(a) * float(b)) def deal_with(express): # 简化表达式 express = express.replace('+-', '-') express = express.replace('--', '+') return express # 0:写一个计算没有括号的表达式 def cal_express_no_braket(exp): ''' 计算没有括号的表达式 exp:是没有经过处理的最内层带括号的表达式 :return: ''' # 1:去括号 rstrip exp = exp.strip('()') while 1: # 循环找乘除,然后计算替换 # 2:表达式先乘除,后加键 re.search:一个个找,一个个算 ret = re.search('\d+\.?\d*[*/]-?\d+\.?\d*', exp) # .? . 出现一次或者多次,因为可能是小数 # -? 可能后面的数是小数,所以负号要管 # . 需要转义, if ret: # 说明表达式中还有乘除法,把一个子表达式中的乘除算法 exe_son = ret.group() # 子表达式 最简单的乘除法 ret = cal_exp_son(exe_son) exp = exp.replace(exe_son, ret) # 可能计算乘除等出现 1--xx的表达式 exp = deal_with(exp) # deal_with 算式的整理 else: # 说明子表达式乘除算完了,只有+ -了,else里计算加减的值 ret = re.findall('-?\d+\.?\d*', exp) # 拿到小数或者整数的列表 sum = 0 for i in ret: sum += float(i) return str(sum) # 2:提取括号里面没有其他括号的表达式 def remove_racket(new_express): while 1: ret = re.search('\([^()]+\)', new_express) # 匹配左右是括号,且中间不是括号 if ret: # 如果匹配上了, express_no_bracket = ret.group() # 拿到一个没有括号的表达式 res = cal_express_no_braket(express_no_bracket) new_express = new_express.replace(express_no_bracket, res) new_express = deal_with(new_express) # print(new_express,express_no_bracket) else: # 否则说明表达式里面没有带括号的表达式了 info = cal_express_no_braket(new_express) break return info if __name__ == '__main__': express = '1 - 2* ( (60-30 +(-40/5) * (9-2*5/3 + 7 /3*99/4*2998 +10 * 568/14 ))- (-4*3)/ (16-3*2) )' # 1:去空格 new_express = express.replace(' ', '') # print(new_express) # 1-2*((60-30+(-40/5)*(9-2*5/3+7/3*99/4*2998+10*568/14))-(-4*3)/(16-3*2)) res = remove_racket(new_express) print(res) print(eval(express))
18:类里面的内置方法(双下方法)(魔术方法) __str__,__repr__,__len__,__del__,__call__
双下方法:__str__和__repr__ 方法 str(1) 数字1也是一个对象,1是int这个类的对象 str() str(obj) 内部都是调用obj对象的 __str__方法 repr() repr(obj) 内部都是调用obj对象的 __repr__方法 print(repr('1')) '1' repr让字符串原形毕露,带双引号 len()和 __len__()方法 内置的类方法和内置的函数之间有者千丝万缕的联系
# __str__:类里面双下str方法的使用
class A: pass a = A() print(a) # <__main__.A object at 0x0000018967CDEBE0> print(str(a)) # <__main__.A object at 0x0000018967CDEBE0> # 上面print(a)和print(str(a))打印类似内存地址的东西, # object类里内置实现了一个__str__,一旦被调用,就返回调用这个方法的对象的内置地址 # python里所有类的父类都是object, # str(a) -> 实例对象a的内存空间找__str__方法,没找到找爹object的__str__方法,父类的str方法有这么一个功能 # 所以现在执行就是父类object的__str__拿到的结果
class B: pass def __str__(self): return 'B is object' b = B() print(str(b)) # B is object # 如果自己类里面自己实现了__str__,
调用str(b)就执行__str__方法,所以打印B is object print(b) # B is object # print(b)的时候就是打印b.__str__()方法返回的东西
# 没有为什么,默认这样,只要对象有__str__方法 # print(b.__str__())等同 print(b) # 打印对象a的时候,就是调用a.__str__,类自己没有__str__方法的话,那么会调用父类object的__str__方法 # 类自己有__str__方法的时候调用自己的__str__方法 ---python的规定 # 打印对象的时候偷偷调用__str__方法,拿到__str__方法的返回值 print('%s:%s' % ('B', b)) # 打印:B:B is object # 这里print(b)也是调用了 b__str__() 方法 l = [1, 2, 3, 4, 5] # 实例化 实例化一个list列表类的对象 print(l) # 打印:[1, 2, 3, 4, 5] # 这里之所以能打印l里每个元素,是因为list类重定制了__str__方法,而没有使用object类的__str__方法
# repr() 和 __repr__ __str__和__repr__都必须return回去一个字符串的数据类型 class Teacher: def __init__(self, name, salary): self.name = name self.salary = salary def __str__(self): return f"Teacher's object:{self.name}" def __repr__(self): return str(self.__dict__) def func(self): return "wahaha" nezha = Teacher('哪吒', 3000) print(repr(nezha)) # 打印:{'name': '哪吒', 'salary': 3000} print(repr(nezha) == nezha.__repr__()) # True %r 也是调用__repr__双下方法,拿到__repr__方法的返回值, 对象nezha 的reper方法的返回值填在了%r的位置 %r 和 repr() 实际上走的是__repr__内置方法 print('>>>%r' % nezha) # 打印:>>>{'name': '哪吒', 'salary': 3000} %s 和str()和print(xxx)直接打印,实际上调用的是 __str__ 双下方法 print('>>>%s ' % nezha) # 打印:>>>Teacher's object:哪吒
# __str__和__repr__ class Teacher: def __init__(self, name, salary): self.name = name self.salary = salary def __str__(self): return f"Teacher's object:{self.name}" def func(self): return "wahaha" nezha = Teacher('哪吒', 3000) print(nezha) # 打印:Teacher's object:哪吒 nezha直接调用__str__该方法 print(repr(nezha)) # 打印:<__main__.Teacher object at 0x00000296A57A57C0> print('>>>>%r ' % nezha) # 打印:>>>><__main__.Teacher object at 0x00000296A57A57C0> # Teacher类里把__repr__方法删除后再打印repr(nezha)和 '>>>>%r'%nezha还是会打印出内存地址 # 假设没有__repr__方法就会报错,现在还能调到__repr__方法是因为Teacher类父类object有__repr__方法,使用的父类object的__repr__方法 class Teacher: def __init__(self, name, salary): self.name = name self.salary = salary def __repr__(self): return str(self.__dict__) def func(self): return "wahaha" nezha = Teacher('哪吒', 3000) print(nezha) # 打印:{'name': '哪吒', 'salary': 3000} print(str(nezha)) # 打印:{'name': '哪吒', 'salary': 3000} print('>>>>%s ' % nezha) # 打印:{'name': '哪吒', 'salary': 3000} # 现在把__str__方法删除了,__repr__方法留下 # __repr__是__str__的备胎方法, # 调用str()的时候理论上调用__str__,如果没有__str__,就调用__repr__方法 # repr是str的备胎 # 只有str没有repr,使用repr()或者%r的时候不会调用str里面的内容,str不是repr的备胎 str和repr的总结 '%s'%obj,print(obj),str(obj)的时候,实际上是对象内部调用了obj__str__()方法, 如果str方法有返回值,那么它返回的必定是一个字符串数据类型,不返回字符串数据类型会报错的,
如果没有__str__方法,会先找本类中的__repr__方法 再找不到,找父类objcet中的__str__方法,再找不到找父类的__repr__方法,再没有就报错 不可能报错的,内置objcet中有__str__方法和__repr__方法 找到objcet类最终打印的是一段内存地址了 repr(),'%r'%obj的时候,只会找内置的__repr__如果没有找父类的__repr__ __repr__和__str__只能实现一个方法的话,应该实现__repr__方法 一个类里面优先实现__repr__方法,因为实现__repr__能给str备用, 只实现__str__调用__repr__不好使 _repr__和__str__是内置函数调用它对象里面的内置方法, 内置函数,str(q) 一切皆对象,随便传个值,只有是个变量一定是对象 那么对象一定有个类,类里面实现了__str__方法才能使用str(对象) 之所以所有的对象都能使用str(),是因为都继承了object类 object类里面实现了 __repr__和__str__两个双下方法---所以能拿到值 内置的方法有很多,不一定都在object里面, 比如len(),len计算不了int数据类型
# __len__:双下len方法的使用 class A: def __len__(self): return 10 a = A() print(len(a)) # 10 # len(a) 等同 a__len__() # 带双下的方法都是类的内置方法, __len__和len函数对应起来,有特殊意义的 # 不是所有的函数都被object收录了,一些数据不能计算长度的,int,time都不能计算长度 # object拥有的都是所有类兼容的方法---想调用需要自己实现 class Classes: def __init__(self, name): self.name = name self.student = [] # def __len__(self): return len(self.student) def __str__(self): return '李二狗' py_s9 = Classes('py全栈9期') py_s9.student.append('李二狗') py_s9.student.append('二逼子') print(len(py_s9)) # 2 # 定制类里面len方法, # 内置的len函数和__len__是一回事,一对协调调用的 info = py_s9 print(info) # 打印:李二狗 调用py_s9的__str__方法
# 析构函数__del__ 析构函数:假如很多变量对象,创建5000个变量使用,用一次后不用内存还在, 解释器有个垃圾回收的机制,机制里面去找,发现没有用了就删除,但是这件事情是解释器代替做的 解释器需要去找才能删除---造成解释器的负担 # 析构函数:主动使用del执行删除或者运行结束后解释器自动删除都会调用 __del__函数执行 # 删除就一定会执行__del__函数----析构函数 # 析构函数:在删除一个对象之前进行一些收尾工作 class A: def __del__(self): print('执行析构函数') # del a 既执行了__del__方法,又删除了变量(先执行后删除) a = A() del a # del a 既执行了__del__方法,又删除了变量(先执行后删除) # print(a) # 报错:NameError: name 'a' is not defined # 2:不执行del a,当程序结束的时候也会执行析构函数 python解释器做了删除这个事情 # 为什么不是不用了之后立即删除: # 变量:引用计数机制,print(a)代表a这个变量还会被引用,a的引用计数+1,变成1 # 执行完print(a)引用计数变成0了, 1:只有引用计数变成0的变量才会被删除 2:不会在内存只有一个变量的时候就开始启用删除机制,到一个程度(比如:700个变量了,有闲置的就删除了 ) a1 = A() import time time.sleep(1) a = A() list = [] for i in range(1000): list.append(A()) # 列表添加1000个变量,产生1000个对象,只要list列表还在使用,1000个变量都不会被释放 a = list.pop() # 对象a pop出来,列表最后一个对象取出来没有被引用了,python解释器回收机制回收这个对象a会执行对象a的析构函数__del__ time.sleep(1) # 析构函数:主动使用del执行删除或者运行结束后解释器自动删除都会调用 __del__函数执行 # 删除就一定会执行__del__函数----析构函数 # 析构函数使用场景 # a.f=open('') # 打开一个文件,1:操作系统中打开文件 2:拿到文件操作符号存储在内存中 # del a # 把变量a删除,a.f也消失在内存里了,文件操作符号也消失了 # 但是文件打开没有关闭,使用析构函数:加个self.f.close() # 执行del a的时候先执行析构函数里的close,关闭文件,然后删除文件操作符号 # 这就是析构函数,删除一个对象之前做一些收尾的工作 class A: def __del__(self): self.f.close()
# __call__ 方法 class A: def __init__(self, name): self.name = name def __call__(self): return self.__dict__ a = A('alex') # a是一个对象 print(a()) # 执行__call__方法 # a() 等同 a.__call__()
#一个对象加括号相当于执行__call__方法, # 没有__call__方法,使用对象()就会报错,
19:面向对象之——类里面定义item系列方法 __getitem__ ,__setitem__,__delitem__
dic = {'k':'v'}
# dic是一个对象,k和v是字典里的属性
# 对象:对象里一般只能放属性,对象一般存储属性和调用方法,存储在字典里面的值一定属性
dic['k'] = 'v' # 这种形式去操作属性--我们也能实现这种形式去操作属性,使用item系列
# item系列三种方法 __getitem__ __setitem__ __delitem__ class Foo: def __init__(self, name, age, sex): self.name = name self.age = age self.sex = sex def __getitem__(self, item): if hasattr(self, item): return self.__dict__[item] def __setitem__(self, key, value): self.__dict__[key] = value def __delitem__(self, key): print('del obj[key]时,我执行') # self.__dict__.pop(key) del self.__dict__[key] def __delattr__(self, item): print('del obj.key时,我执行') self.__dict__.pop(item) f = Foo('slex', 38, '男') # 1:f['name'] 等同 f.__getitem__('name') print(f['name']) # 打印:slex 这样写触发getitem的行为,'a'会被当参数传递进去 # f['name'] == f.__getitem__('name') print(f.__getitem__('name')) # 打印:slex # 2:f.hobby 是对象属性自带的访问形式 f['hobby'] 是通过__getitem__方法实现的 f['hobby'] 等同 f__getitem__('hobby') f['hobby']='男' 等同 f__setitem__('hobby','男') f['hobby'] = '男' # f['hobby']='男' == f__setitem__('hobby','男') print(f.hobby) # 打印:男 print(f['hobby']) # 打印:男 # 3:正常情况下del f.age1 可以删除一个f对象的age1属性 如果想del f1['age']这样删除属性可以通过__delitem__方法实现,del f['xxx'] 等同调用 f.__delitem__('xxx') f['hobby'] = '男' # 类里设置一个 hobby属性=男 print(f.hobby) # 打印:男 del f.hobby # 删除f对象的hobby属性, print(f.__dict__) # 打印:{'name': 'slex', 'age': 38, 'sex': '男'} f['hobby'] = 'xxx' print(f.__dict__) # 打印:{'name': 'slex', 'age': 38, 'sex': '男', 'hobby': 'xxx'} del f['hobby'] # del f['hobby'] 等同调用 f.__delitem__('hobby') # 执行del f['hobby'] 会打印:del obj[key]时,我执行 print(f.__dict__) # 打印:{'name': 'slex', 'age': 38, 'sex': '男'} # item系列:从此以后操作对象和操作字典一样的,使用双下方法去操作数据--python语法支持的 # 字典就是这样实现的,只要是使用使用[]的形式去访问值都是item系列双下方法的机制 # 4:__delattr__ 对应 del obj.key 正常情况下不用实现__delattr__,object实现了__delattr__ object没有实现__getitem__ 和__setitem__和__delitem__ del obj.key 是object类原生支持的 __delattr__和del obj.key这个动作关联在一起 del obj.key 等同调用 obj.__delattr__(key) del obj['key'] 是通过自己写的__delitem__实现的,等同调用obj.__delitem__('key')
记住__delattr__和__delitem__的区别,一个对应del obj.key 一个对应 del obj['key']
20:面向对象之双下方法——__new__
__init__:是类里的初始化方法 其他的编程语言里想创建一个对象需要先new一下,获取到新的对象,new一个对象,创建一个对象先调用new函数就能获取到一个新的对象了 __new__:__new__才是类里的构造方法,构造方法用来创建一个实例对象,init执行之前已经创建了一个self了,这个self就是__new__创造的,这就是new方法的妙用 class A: def __init__(self): self.x = 1 print('in init function') def __new__(cls, *args, **kwargs): print('in new function') return object.__new__(A, *args, **kwargs) a = A() # 实例化对象的时候先执行new方法,再执行init方法,new是创建self的机制 # 执行new方法的时候没有self, # return object.__new__(A,*args, **kwargs) 借助object类的new方法来创建一个新的对象返回出去, # object.__new__(A,*args, **kwargs) 创造一个新对象,return出去 # return到init里面的self,再执行self的时候就能拿到这个对象正常使用 print(a.x) # 打印:1
return object.__new__(A, *args, **kwargs) 等同 return super().__new__(cls) 等同 return super(A, cls).__new__(A)
def __new__(cls, *args, **kwargs):
定义__new__方法的时候里面传的是cls参数,而不是self,因为new就是创建self的机制
在执行new方法的时候还没有self,所以只能把cls类传进来,传进来后自己也不会创建对象,
只能借助object的__new__方法去创建一个新的对象
object.__new__(A, *args, **kwargs)创建一个新对象,把这个对象return给init的self位置
再执行self的时候就能拿到这个self对象了,拿到这个对象就能正常使用了
21:面向对象之——单例模式
设计模式:单例模式(一共23种设计模式) 单例模式:一个类始终只有一个实例,限制一个类在内存里从始至终只有一个对象 类可以实例化多次,实例化出的每个对象都不同 第一次实例化这个类的时候就创建一个实例化的对象 之后再来实例化的时候就用之前创建的那个对象, 从头到尾都只操作一个实例对象
使用__new__方法来实现,因为类的实例对象的创建就是__new__创建的 class B: __instance = False # 私有的静态属性 def __init__(self, name, age): self.name = name self.age = age
# def __new__(cls, *args, **kwargs): # if cls.__instance: #cls.__instance =True # return cls.__instance # else: # cls.__instance=object.__new__(B) # return cls.__instance
# @classmethod # 这个装饰器可加可不加,__new__方法本质上就是一个类方法 def __new__(cls, *args, **kwargs): if cls.__instance: # cls.__instance =True,如果已经被实例化了,实例对象已经存在了直接返回实例对象cls._instance就行 return cls.__instance # return作为一个函数的结束 cls.__instance = object.__new__(B) # 括号的参数是 B或者cls都可以,代表本类,调用父类object的__new__方法来创建一个实例 return cls.__instance egen = B('egg', 33) egen.cloth = '小花袄' nezha = B('nezha', 33) print(id(egen), id(nezha)) # 1688971239208 1688971239208 # 现在实例对象egen和实例对象nezha内存地址一样,对象完全一样的 print(egen.name) # nezha print(nezha.name) # nezha # 现在两个对象egen和nezha的name都是nezha,最后赋值的为准
print(nezha.cloth) # 小花袄 # egen和nezha现在是指向一个对象,是一个内存空间,内存空间存储着name,age,cloth # 每次实例化就是修改这个同一内存空间里面名字的值 单例模式 # __new__里面控制创造对象---高级 # 执行的时候借助object里面的__new__创造实例化的方法,只有object类能创建self对象 # cls.__instance=object.__new__(B) 创建对象的时候不必传参数,创建对象不需要传递任何参数就能创建一个对象
*args和**keargs这些外面传进来的参数是传递给实例对象的,传给init方法的
object.__new__(B):只有object类里的new方法才能实例化,自己类重构new方法实例化的时候先执行自己的new方法
执行自己的new方法再借助object的new方法创建对象
22:面向对象之双下方法——__eq__
# 当判断两个对象是否相等:正常情况下是比较内存地址,如果重新定制__eq__方法,就会根据定制的条件去判断两个对象是否相等 # obj1==obj2 等同 obj1.__eq__(obj2) 等同 C.__eq__(obj1,obj2) # 值的等于就会触发 eq双下方法 # 1:正常判断两个对象是否相等(我们自己不重构__eq__方法):调用父类object的 __eq__方法 比较两个对象的内存地址 class C: def __init__(self, name): self.name = name obj1 = C('egg') obj2 = C('egg') print(obj1 == obj2) # 打印:False obj1 != obj2 # 2:自己重构__eq__方法:obj1 == obj2比较两个对象是否相等的时候就会调用C.__eq__(obj1,obj2) class C: def __init__(self, name): self.name = name def __eq__(self, other): if self.name == other.name: return True else: return False obj1 = C('egg') obj2 = C('egg') print(obj1 == obj2) # 打印:True 因为obj1.name == obj2.name # 所有的是否相等默认就是比较内存地址,但是我们这里自己定义了__eq__方法,比较相等就会调用__eq__方法 print(id(obj1), id(obj2))
23:面向对象之双下方法——__hash__
python3自定义类:重写__eq__和__hash__函数:https://blog.csdn.net/anlian523/article/details/80910808
python 何时单用__hash__或__eq__何时一起用:https://blog.csdn.net/sinat_38068807/article/details/86519944
__hash__:可哈希,不可哈希得,可哈希的肯定内部都实现了一个__hash__双下方法 # 不重写__hash__方法,就会默认调用父类object类的__hash__方法 # object类的hash方法默认 返回和对象id相关的hash值:return hash(id(self)) class D: def __init__(self, name, sex): self.name = name self.sex = sex a = D('egon', '男') b = D('egon', '男') print(hash(a)) # 141877824958 print(hash(b)) # 141877824982 # 没有重写__hash__方法,所以对象a和对象b调用hash函数返回的哈希值和对象的id相关,
对象a和对象b的id不同,所以上面hash(a)和hash(b)返回了两个不同的哈希值 # 自己重写__hash__方法 class D: def __init__(self, name, sex): self.name = name self.sex = sex def __hash__(self): return hash(self.name + self.sex) a = D('egon', '男') b = D('egon', '男') print(hash(a)) # 307214104266093222 print(hash(b)) # 307214104266093222 # 不自己重写__hash__方法使用父类object类默认的__hash__方法不会根据属性哈希,
而是根据对象内存地址进行哈希,内存地址一定不同哈希结果不同 # 有时候希望属性值相同哈希值也相同, # 这时候自己重构了__hash__函数根据定制规则返回hash值, # 执行hash就走自己定制的 __hash__,两个对象的hash值相不相等自己控制了,如上
24:内置函数内置模块内置的基础数据类型和类的内置方法的关系
内置函数以及内置的模块,以及内置的基础数据类型都和类的内置方法千丝万缕,互相关联 内置函数--内部就是调用的内置方法, == 就是双下 __eq__ 对应 len() 对应 __len__
25:简单练习
1:纸牌的游戏:使用namedtuple 可命名元组和格子模式方法实现一副扑克牌类 import json from collections import namedtuple # namedtuple 可命名元组 Card = namedtuple('Card', ['rank', 'suit']) # rank 牌面的大小,suit牌面的花色 c1 = Card(2, '红心') print(c1) # Card(rank=2, suit='红心')
print(c1.suit) # 红心 # Card = namedtuple('Card',['rank','suit']) 类似创建一个类 # c1=Card(2,'红心') 类似实例化,这个类没有方法,只有属性,只有属性没有方法的类
class FranchDeck: ranks = [str(n) for n in range(2, 11)] + list('JQKA') # 牌面大小组成的列表,从2到A的列表[2, 3, 4....J, Q, K, A] suits = ['红心', '方板', '梅花', '黑桃'] # 四种花色
def__init__(self): self._cards = [Card(rank, suit) for rank in FranchDeck.ranks for suit in FranchDeck.suits] # for rank in FranchDeck.ranks:
# for suit in FranchDeck.suits:
# Card(suit,rank)
# self._cards列表 存储了一副没有大小王的牌
def__len__(self): return len(self._cards) def__getitem__(self, item): # 实现deck[0] 所有取值
return self._cards[item] def__setitem__(self, key, value): self._cards[key] = value # 索引等于值
def__str__(self): return json.dumps(self._cards, ensure_ascii=False) # ensure_ascii=False 如果想中文不转义加这个参数 deck = FranchDeck() print(deck[0]) # 打印:Card(rank='2', suit='红心')
# deck[0] 等同调用 deck__getitem__(0) 会返回 self._cards[0] 返回列表里的第1个元素 print(deck._cards[0]) # 打印:Card(rank='2', suit='红心') 和上面调用deck[0]返回值相同 # print(deck.__dict__)
from random import choice print(choice(deck)) print(choice(deck)) # choice从对象中随机抽取一个值,choice依赖内置的 __len__方法 # 这个len方法返回纸牌的长度可以了 # choice函数从对象随机抽取一个值,会使用到对象内置的__len__长度,从长度种随机取个值
# 然后使用这个值调用对象的__getitem__函数从对象里取值
# choice从对象随机抽取一个值本质上就是调用了类内置的__len__+__getitem__双方法实现的
# 洗牌,shuffle依赖内置的 __setitem__方法 # 内部shuffle打乱顺序的时候把每一个索引位置上的值都变了,依赖self._cards[key] = value 这种方式改变
from random import shuffle shuffle(deck)
# shuffle洗牌本质上也是需要使用到类里的__len__+__getitem__两个魔术方法实现
# 知道整个列表的长度,然后随机函数从列表0位置开始一种使用getitem去重新把列表每个位置进行重新赋值
print(deck[:5]) # __getitem__方法还实现了切片,deck[xxx]这样取值调用的都是类的getitem方法
print(deck)
# print(deck)本质上就是调用了对象的__str__方法,__str__只能返回一个字符串的数据类型
26:set去重内部原理详解
# 如下一个set去重的需求 # 一个类有一百个对象,一百个对象其中很多对象的名字和性别相同, # 现在想要年龄不同相同名字和相同性别的名字只留下一个,去重---set class Person: def __init__(self, name, age, sex): self.name = name self.age = age self.sex = sex def __hash__(self): return hash(self.name + self.sex) # 想根据对象的名字和性别属性去重,所以根据名字和性别哈希:hash(self.name+self.sex) # 肯定不止对比哈希值,去重可能对比值(==默认对比内置地址),实现eq方法:如下 def __eq__(self, other): if self.name == other.name and self.sex == other.sex: return True return False # 如果 name相等和sex相等,那么self和other就是相等的返回True a = Person('alex', 37, '男') b = Person('alex', 38, '男') print(set([a, b]))
# 打印: {<__main__.Person object at 0x000002D10F90FFD0>}
只打印一个对象,因为对象a和对象b的名字和性别相同,所以就认为a和b是同一个对象,把a和b进行去重操作就剩下一个对象了 # py3.2对对象集合进行set会报错unhashable # set依赖对象的__hash__和__eq__方法,set去重
27:hashlib加密模块的使用
hashlib:密码密文存储 摘要算法,加密算法 两个字符串:500w个字,500w个字里一个不同,那么最终结果就一定不同的---摘要算法 1:hashlib是提供摘要算法的模块 2:摘要算法是一堆算法,md5,SHA1算法,SH256,SH128等,很多算法,最多的是md5算法 不管算法多么不同,摘要的功能始终不变, 对于相同的字符串使用同一个算法进行摘要,得到的值总是不变的 使用不同算法对相同的字符串进行摘要得到的值应该不同 不管使用什么算法,hashlib的方式永远不变 3:sha算法,随着复杂程度的增加,我摘要的时间成本,空间成本(占用的内存)都会增加
import hashlib md5 = hashlib.md5() # 创建一个md5的对象 md5.update(b'alex3714') # update必须是bytes类型 print(md5.hexdigest()) # aee949757a2e698417463d47acac93df # 摘要算法对同一个字符串进行摘要,结果永远不会变化,
摘要算法的使用: 1:密码的密文存储 2:文件的一致性验证(网上下载东西,下完了检验文件,这时候就是在和远程的文件作对比) 在下载的时候会检查我们下载的文件和远程服务上的文件是否一致 两台机器上的两个文件,检查两个文件是否相等 访问百度服务器,500台机器同时接受访问,500台机器完全相同,可能一台出问题, 检查机器上的所有文件和正常的机器文件是否相等,都相等说明没问题,不相等需要copy
hashlib加密模块的简单实例 创建过程模拟用户注册 1:用户输入用户名, 2:用户输入密码 3:明文的密码进行摘要拿到一个密文的密码 4:输入的密码和写到文件里的密码进行对比 模拟用户登录 import hashlib use = input('username:') psd = input('password:') with open('userinfo', encoding='utf8') as f: for line in f: username, password, role = line.split('|') # print(username,password,role) md5 = hashlib.md5() md5.update(bytes(psd, encoding='utf8')) # 二进制才能update加密 md5_pwd = md5.hexdigest() if username == use and md5_pwd == password: print('登录成功')
# md5加密算法加盐
# 不加盐时候的加密结果 import hashlib md5 = hashlib.md5() md5.update(b'123456') print(md5.hexdigest()) # 打印:e10adc3949ba59abbe56e057f20f883e # 加盐后的结果 import hashlib md5 = hashlib.md5(bytes('salt', encoding='utf8')) md5.update(b'123456') print(md5.hexdigest()) # 打印:f51703256a38e6bab3d9410a070c32ea 这是加盐后的结果
# 加盐本质上也就是在原密码内加一些数据然后再使用md5加密 import hashlib md5 = hashlib.md5() data = b'salt' + b'123456' md5.update(data) print(md5.hexdigest()) # 打印:f51703256a38e6bab3d9410a070c32ea 这是加盐后的结果 # 加盐:本质上就是在密码123456前加一个字符串salt然后继续md5加密
动态加盐
用户名 密码
使用用户名的一部分或者 直接使用整个用户名作为盐
# 使用md5来进行文件的一致性校验 # 文件的一致性校验不需要加盐 import hashlib md5 = hashlib.md5() md5.update(b'alex') md5.update(b'3714') # 把alex3714分次摘要和整体摘要结果一模一样 print(md5.hexdigest()) # aee949757a2e698417463d47acac93df
# 比较两个文件是否相同,使用md5模块,比较两个文件的md5,两个文件的md5相同那么就是同一文件 import os import hashlib import requests def get_file_md5(filename): md5 = hashlib.md5() if type(filename) == str: if not os.path.isfile(filename): return f = open(filename, 'rb') while True: b = f.read(8096) if not b: break md5.update(b) f.close() return md5.hexdigest() else: md5.update(filename) return md5.hexdigest() if __name__ == '__main__': print(get_file_md5('../data/im/upload_file/2mb.exe')) # 根据文件路径求一个文件的md5 ret=requests.get('http://mgim-sdk.zhuanxin.com/other/41190a5ddc051e93be4406563c7e5a17.exe').content # 使用requests下载一个文件的content二进制格式求md5 print(get_file_md5(ret))
28:简单练习——教学管理系统 桌面查看
29:configparser 处理配置文件的模块
configparser:处理配置文件的模块 配置文件:conf.config configparser:一种处理配置文件的机制 配置文件是py文件可以直接读取变量 如果配置文件是txt文档格式的,读取出来是个字符串,还需要对字符串进行处理拿到数据--很麻烦 configparser帮助处理配置文件的模块,要求文档格式比较规范 配置信息必须基于组的文件--格式要求严格
# 用python生成一个配置文件 import configparser config = configparser.ConfigParser() # ConfigParser类 类的初始化,驼峰式命名 config["DEFAULT"] = {'ServerAliveInterval': '45', 'Compression': 'yes', 'CompressionLevel': '9', 'ForwardX11': 'yes' } config['bitbucket.org'] = {'User': 'hg'} config['topsecret.server.com'] = {'Host Port': '50022', 'ForwardX11': 'no'} # 上面代码配置了三组内容, with open('ywt.ini', 'w') as f: # 以写的形式打开配置文件f文件操作符号 config.write(f) # f传进去写文件,生成配置文件ywt.ini # 一般情况下以configparser这样的形式处理的配置文件都是以 .ini结尾的
上面的代码在ywt.ini文件里生成如下内容:
[DEFAULT]
serveraliveinterval = 45
compression = yes
compressionlevel = 9
forwardx11 = yes
[bitbucket.org]
user = hg
[topsecret.server.com]
host port = 50022
forwardx11 = no
example.ini文件内容如下: [DEFAULT] serveraliveinterval = 45 compression = yes compressionlevel = 9 forwardx11 = yes [bitbucket.org] user = hg [topsecret.server.com] host port = 50022 forwardx11 = no # 查找文件 import configparser config = configparser.ConfigParser() # ---------------------------查找文件内容,基于字典的形式 # 没有给需要读取的文件 sections打印一个空列表 print(config.sections()) # 打印:[] sections获取所有的组 config.read('example.ini') # DEFAULT默认不显示 print(config.sections()) # 打印:['bitbucket.org', 'topsecret.server.com'] # 查看节是不是在config里 print('bytebong.com' in config) # 打印:False print('bitbucket.org' in config) # 打印:True # 通过节去打印节里面配置项目 print(config['bitbucket.org']["user"]) # 打印:hg print(config['DEFAULT']['Compression']) # 打印:yes # 通过节拿到default里面的项目,default不显示组,但是拿值没问题的 print(config['DEFAULT']['compression']) print(config['topsecret.server.com']['ForwardX11']) # no # 打印Section地址, print(config['bitbucket.org']) # <Section: bitbucket.org> # 不知道组里有什么名字,使用循环这个组 for key in config['bitbucket.org']: # 注意,有default会默认default的键 print(key, config['bitbucket.org'][key]) # default不作为特有节的名字显示出来,不管循环那个节去取值都能取到default里面值下面的内容 # default不同:是个关键字 # options同for循环,找到'bitbucket.org'下所有键 print(config.options('bitbucket.org')) # config.items找到'bitbucket.org'下所有键值对 ---很像操作字典 print(config.items('bitbucket.org')) # get方法Section下的key对应的value ---get方法取值 print(config.get('bitbucket.org', 'compression')) # 打印:yes
# ini文件的增删改操作 import configparser config = configparser.ConfigParser() # 创建操作符号 config.read('example.ini') # 读取文件 config.add_section('yuan') # 增加一个section: config.remove_section('bitbucket.org') # 删除一个section config.remove_option('topsecret.server.com', "forwardx11") # 删除一个配置项 config.set('topsecret.server.com', 'k1', '11111') # 给组里面新建一个k1=11111 config.set('yuan', 'k2', '22222') # 组里面新建一个k2=22222 with open('new2.ini', "w") as f: config.write(f) # 修改的内容写进一个文件 # 把example.ini文件内容修改后写到new2.ini,example.ini文件的内容如上 # 如果想实现修改可以使用os模块删除原来的example.ini然后把new2.ini修改名称
30:logging日志模块:
logging日志模块参考文档:https://www.cnblogs.com/xianyulouie/p/11041777.html
logging模块 log:日志 logging:日志模块 日志:程序当中的操作中间过程记录下来, 用来记录用户行为的或者代码的执行过程. 通过变量控制输出和不输出, 1:排错,将错误打印出来,打印细节来帮助排错 2:有一些用户行为有没有错记录下来‘ 3:严重的错误都需要记录下来 logging也是在打印,这种打印能够控制打印级别,分级别打印的,和print一样需要你让程序打印才会打印 记录的东西需要自己写
2:logging模块 5个级别:如下 import logging logging.debug('debug message') # 低级别的,排错信息 logging.info('info message') # 正常的信息 logging.warning('warning message') # 警告信息 logging.error('error message') # 错误信息 logging.critical('critical message') # 高级别的,严重错误信息 # 默认只输出info往上级别的内容,不包含info的
logging模块:日志的配置,有两种方式配置日志 1:basicconfig:这种形式直接配置,简单,能做的事情相对少 logging.basicConfig()函数中可通过具体参数来更改logging模块默认行为,可用参数有: filename:用指定的文件名创建FiledHandler,这样日志会被存储在指定的文件中。 filemode:文件打开方式,在指定了filename时使用这个参数,默认值为“a”还可指定为“w”。 format:指定handler使用的日志显示格式。 datefmt:指定日期时间格式。 level:设置rootlogger(后边会讲解具体概念)的日志级别 stream:用指定的stream创建StreamHandler。 可以指定输出到sys.stderr,sys.stdout或者文件(f=open(‘test.log’,’w’)), 默认为sys.stderr。若同时列出了filename和stream两个参数,则stream参数会被忽略。 format参数中可能用到的格式化串: %(name)s Logger的名字 %(levelno)s 数字形式的日志级别 %(levelname)s 文本形式的日志级别 %(pathname)s 调用日志输出函数的模块的完整路径名,可能没有 %(filename)s 调用日志输出函数的模块的文件名 %(module)s 调用日志输出函数的模块名 %(funcName)s 调用日志输出函数的函数名 %(lineno)d 调用日志输出函数的语句所在的代码行 %(created)f 当前时间,用UNIX标准的表示时间的浮 点数表示 %(relativeCreated)d 输出日志信息时的,自Logger创建以 来的毫秒数 %(asctime)s 字符串形式的当前时间。默认格式是 “2003-07-08 16:49:45,896”,逗号后面的是毫秒 %(thread)d 线程ID。可能没有 %(threadName)s 线程名。可能没有 %(process)d 进程ID。可能没有 %(message)s用户输出的消息 2:配置log对象 稍微有点复杂,能做的事相对多 # 日志的配置方式一:basicconfig进行配置如下: import logging logging.basicConfig(level=logging.DEBUG, format='%(asctime)s - %(filename)s - %(lineno)s -%(levelname)s: %(message)s', datefmt='%Y-%m-%d %H:%M:%S %p', filename='./tmp/test.log', filemode='w' )
# 上面basicConfig里面配置信息详解 level=logging.DEBUG:表示从DEBUG往上的所有级别全部都显示,只能控制显示这以上, 多级别有数字的,大于某个数字的信息就显示,小于就不打印 format格式化: asctime 时间 filename 文件名,当前debug所在的文件的名字 lineno 调用日志输出函数的语句所在的代码行 levelname 文本形式的日志级别,debug还是info还是warning等级, message 用户实际输出的信息 print('%(key)s'%{'key':'value'}) # 打印:value print('%s%s'%('key', 'value')) # 打印:keyvalue # %s后面接的是字典 处理key value里面的东西 datefmt 时间的格式,format里面配置asctime输出时间了,datefmt 配置时间输出的格式
filename 输出日志往文件里面打,没有配置默认print输出
filemode='w' 往文件里写,要以写的形式打印文件 # 日志,默认情况下打开就不关闭了,一直往里写,程序不结束一直往里写日志,一直不关, # 所以a模式还是w模式打开日志文件都可以 logging.debug('debug message') logging.info('info message') logging.warning('warning message') logging.error('error message') logging.critical('critical message') try: int(input('num>>>')) except ValueError as f: logging.error('输入的值不是一个数字'+str(f)) # 发生了ValueError错误就会走except里面的代码内容,就会记录日志 basicConfig两个坑: 1:解决不了中文乱码的问题 2:不能同时往文件和屏幕上输出(要么输出文件,要么输出屏幕) logging:规范化输出内容,
log日志不仅仅可以写入文件里,还可以输出日志,不写 filename就会输出到终端
logging模块很重要,代码肯定需要日志的, 选课系统项目:
1:老师在那个时间点登录记录下来 2:学生在那个时间点登录记录下来,什么时间点交了作业记录下来 3:管理员,什么时间点删除了课程,学生,都需要日志记录下来这些东西都需要logging日志模块记录
# 日志的配置方式二:配置log对象 logging:配置log对象八个步骤 1:logger = logging.getLogger() 创建一个对象 2:fh = logging.FileHandler('test.log',encoding='utf-8') 创建一个FileHandle(文件操作符),可以指定编码utf-8,指定打开的文件test.log 3:ch = logging.StreamHandler() 创建一个StreamHandler,控制台的操作符 4:logging.Formatter格式化的输出格式 5:fh.setLevel(logging.DEBUG) 设置DEBUG以上的信息都输出 6:fh.setFormatter(formatter) ch.setFormatter(formatter) 文件操作符和屏幕操作符号绑定格式 7:logger.addHandler(fh) # logger对象可以添加多个fh和ch对象 logger.addHandler(ch) lpgger对象绑定文件操作符和屏幕操作符号 8:然后logger.debug什么就能显示信息了 配置log对象的八个步骤 import logging logger = logging.getLogger() # 步骤一:创建一个log对象
logger.setLevel(logging.INFO)
# log等级总开关,很重要,必须要设置这个才能把info级别以上的log传给文件句柄或者显示台,下面的fh设置的是文件里的日志等级 fh = logging.FileHandler('log.log', encoding='utf-8') # 步骤二:创建一个文件操作符,用于写入日志文件 # 指定encoding='utf-8'编码就能写中文了,不会乱码,打开文件写入的模式默认是a追加模式,可以自己修改
formatter = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s') # 步骤四:设置日志的格式:时间,文件名,等级,信息---根据表里面写 # logger:log对象,管日志输出 # fh:filehandle对象,管文件打开 # formatter:formater对象,管格式 # 用文件操作符和格式关联 # log对象和文件操作符关联 fh.setLevel(logging.DEBUG) # fh文件操作符,DEBUG以上的才写到文件 fh.setFormatter(formatter) # fh文件操作符和formatter格式关联 logger.addHandler(fh) # log对象和文件操作符fh文件操作符关联--串连的过程 logger.debug('logger debug message') logger.info('logger info message') logger.warning('logger warning message') logger.error('logger error message') logger.critical('logger critical message')
logging:配置log对象 实现日志输出到文件和屏幕:双日志 输出到屏幕的log和文件的log都是独立的,可以各种设置定制输出的格式,灵活 程序的充分解耦 让程序变得高可定制 zabbix:监控系统,1w台机器,只能所有机器上写软件监测正常,检测到正常信息返回给我 不好就报警--监控信息 import logging logger = logging.getLogger() # 创建一个log对象 fh = logging.FileHandler('log.log', encoding='utf-8') # 创建一个文件操作符,用于写入日志文件 ch = logging.StreamHandler() # 创建一个控制台的操作符,用于输出到控制台 formatter = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s') # 设置日志的格式:时间,文件名,等级,信息---根据表里面写 fh.setLevel(logging.DEBUG) fh.setFormatter(formatter) ch.setFormatter(formatter) logger.addHandler(fh) # logger对象可以添加多个fh和ch对象 logger.addHandler(ch) logger.debug('logger debug message') logger.info('logger info message') logger.warning('logger warning message') logger.error('logger error message') logger.critical('logger critical message')
logging日志模块总结 1:五种级别的日志记录模式 debug:做计算器的时候,每一个中间小的值,结果都能打印出来,排错,出来细节 info:正常的一些信息,谁操作的,谁登录的使用info记录 error:用户的一些行为导致程序的错误,需要用try except处理的基本都属于错误error 文件依赖配置文件,文件没有出现,error信息 warning:警告错误,不影响程序正常运行的,会出现一个小问题的,warning警告信息 critical:很严重的,操作系统基本的错误 2:两种方式配置日志 1:basicconfig对象(只能完成基础配置) 2:log对象配置(能完成更细节的配置)log对象可以高可定制化,输出的格式,输出到哪些文件都可以定制 可以往三个文件写日志,写三个filehandle就可以了 3:log只能帮你打印你想打印的信息,加格式,没有那么智能,
31:简单练习
1:文件操作中有哪些模式, r w a rb wb ab a+ w+ r+ 2:用户输入一个任意数字n,求1-n之间所有的奇数 range(1,n,2) 3:s='kskskhlkshjakf'去除s字符串中重复的字母 1:set 集合,不好,集合是无序的 print(''.join(set(s))) #asklhfj 2:for循环去做 s='kskskhlkshjakf' new_s='' for i in s: if i not in new_s: new_s=new_s+i print(new_s) #kshljaf 4:看代码 a=10 b=20 def test(a,b): print(a,b) c=test(b,a) print(c) 打印的结果:a=20 b=10 c=None 5:s='123.33sdhf3424.34fdg323.324'计算字符串中所有数字的和 方法一: s='123.33sdhf3424.34fdg323.324' import re res=re.findall('\d+\.?\d.',s) #正则表达式提取小数 #'\d+\.?\d.'或者'\d+\.?\d{,2}' #{,2}取0-2次 res_new=map(lambda x:round(float(x),2),res) #map返回迭代器 #round提取两位小数 print(round(sum(list(res_new)),2)) 方法二: s='123.33sdhf3424.34fdg323.324' import re res=re.findall('\d+\.?\d.',s) res='+'.join(res) print(eval(res)) 6:d={'k1':'v1','k2' :[1,2,3],( 'k’,' 3' ):{1, 2, 3}} 请用程序实现: 1:输出上述字典中value为列表的key d={'k1':'v1','k2':[1,2,3],('k','3'):{1, 2, 3}} for i in d: if type(d[i]) ==list: print(i) 2:如果字典中的key是一个元祖,请输出对应的value值。 d={'k1':'v1','k2':[1,2,3],('k','3'):{1, 2, 3}} for i in d: if type(i) == tuple: print(d[i]) 3:d[(k',' 3' )]对应的value是一个什么数据类型 print(type(d[('k','3')])) #<class 'set'> 集合类型 8.如果不使用ewrapper装饰器,请在a()之前加入一句代码, 达到相同的效果 def wrapper(func): def inner(*args,**kwargs): func(*args,**kwargs) print('装饰器') return inner # @wrapper def a(arg): print(arg) a=wrapper(a) # @wrapper==a=wrapper(a) a(111) 9:请处理文件7th_questions,输出所有以T'开头的行 with open('7th_questions') as f: for i in f: if i.startswith('T'): print(i) 10:读登陆文件夹中的代码,请为这段代码画流程图 11: 默写10个字符串对象的内置方法,描述它的作用 split() a.strip() a.rstrip() a.lstrip() a.endswith() a.startswith() a.replace() a.index() a.find() a.upper() a.lower() 12:有如下代码,写出调用的顺序以及结果 def f1(): print('funcname is f1') def f2(): print('funcname is f2') return 1 def f3(func1): l1=func1() print('funcname is f3') return l1 print(f3(f2)) f2传参给func1 l1=f2() print('funcname is f2') l1=1 print('funcname is f3') return 1 13:创建一个闭包函数需要满足那几点条件 1:嵌套函数 2:函数内部用到外部的变量,这个变量不是全局作用域里面的变量 14:将时间打印成一个2017/10/01 18:08:15的格式 将'2017-11-18' 17:43:43 转换成结构化时间 time.struct_time 15:用什么模块直到一个文件夹存不存在,怎么获取文件夹的大小 os.path.isdir() #查看文件夹存不存在 os.path.getsize() #只能获取文件大小 循环文件夹里所有的文件,然后把大小加起来 16:写出一个能够匹配手机号的正则语句 import re # res=re.findall('1[345789][\d]{9}','18397500597') res=re.findall('1[3456789]\d{9}','18397500597') print(res) 17:有四个数,1,2,3,4,能够组成多少个互不相同且无重复数字的三位数?各是多少 def func(): for i in range(1,5): for j in range(1,5): for k in range(1, 5): if i==j or i==k or j==k: continue yield str(i)+str(j)+str(k) for i in func(): print(i) 18:类,对象,实例化,实例这些名词的含义 19:面向对象的三大特性:封装,继承,多态 20:有一个类的定义 class Person(): def __init__(self,name,age): self.name=name self.age=age 1:初始化是个不同的对象 2:求最高的age的对象的name 21:读代码 class Base(): def f1(self): self.f2() def f2(self): print('.....') class Foo(): def f2(self): print('9999') obj=Foo() obj.f1() 1:面向对象中的self指的是什么 self指的对象自己 2:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号