python开发基础篇:一
0:抄录的博客学习网址
太白金星:https://www.cnblogs.com/jin-xin/default.html
Eva_J:https://www.cnblogs.com/Eva-J/default.html
python基础一:https://www.cnblogs.com/jin-xin/articles/7459977.html
1:计算机基础
cpu:中央处理器,大脑,处理各种数据计算
内存:临时存放数据,和cpu直接相连,cpu需要计算的数据加载程序直接从内存取数据,比硬盘运行速度快,内存断电数据就会消失而且贵
硬盘:储存数据,能够长久保存数据文件的
操作系统:操控cpu,内存,硬盘,输入输出设备,协调之间运行
应用程序:打开一个应用程序,程序存储在硬盘某个位置,鼠标点击,操作系统把应用程序加载到内存,
cpu来运行程序,通过操作系统cpu将内存当中的应用程序来执行
2:python历史
宏观上:python2 与 python3 区别:
python2:源码不标准,混乱,重复代码太多,
python3:统一标准,去除重复代码。
3:python的环境
编译型:一次性将所有程序编译成二进制文件(程序运行只识别010101)(一般需要大量计算和数据处理的语言使用编译型语言) 缺点:开发效率低,不能跨平台(程序大可能编译一整天,出了bug又需要重新编译) 优点:运行速度快。 :C,C++,go等等 解释型:当程序执行时,一行一行的解释成字节码交给py虚拟机(解释器)执行(从上至下运行),不是直接交给cpu运行的,cpu去运行这个解释器 缺点:运行速度慢。 :python ,php,js等等
混合型:有编译型的特定又有解释性的特点
java,c#
动态语言:(看定义变量的时候需不需要定义变量类型)
动态类型语言是指在运行期间才去做数据类型检查的语言,也就是说,在用动态类型的语言编程时,
永远也不用给任何变量指定数据类型,该语言会在你第一次赋值给变量时,在内部将数据类型记录下来。
Python和Ruby就是一种典型的动态类型语言,其他的各种脚本语言如VBScript也多少属于动态类型语言
静态语言
静态类型语言与动态类型语言刚好相反,它的数据类型是在编译其间检查的,
也就是说在写程序时要声明所有变量的数据类型,C/C++是静态类型语言的典型代表,其他的静态类型语言还有C#、JAVA等。
强类型定义语言:(变量可以可以赋不同试数据类型的值)
强制数据类型定义的语言。也就是说,一旦一个变量被指定了某个数据类型,如果不经过强制转换,
那么它就永远是这个数据类型了。举个例子:如果你定义了一个整型变量a,
那么程序根本不可能将a当作字符串类型处理。强类型定义语言是类型安全的语言。
弱类型定义语言:
数据类型可以被忽略的语言。它与强类型定义语言相反, 一个变量可以赋不同数据类型的值。
python是一门:动态解释性的强类型定义语言
4:python的优缺点
优点: 1:Python的定位是“优雅”、“明确”、“简单”,所以Python程序看上去总是简单易懂,初学者学Python,
不但入门容易,而且将来深入下去,可以编写那些非常非常复杂的程序。 2:开发效率非常高,Python有非常强大的第三方库,基本上你想通过计算机实现任何功能,
Python官方库里都有相应的模块进行支持,直接下载调用后,在基础库的基础上再进行开发,大大降低开发周期,避免重复造轮子 3:高级语言————当你用Python语言编写程序的时候,你无需考虑诸如如何管理你的程序使用的内存一类的底层细节 4:可移植性————由于它的开源本质,Python已经被移植在许多平台上(经过改动使它能够工 作在不同平台上)。
如果你小心地避免使用依赖于系统的特性,那么你的所有Python程序无需修改就几乎可以在市场上所有的系统平台上运行 5:可扩展性————如果你需要你的一段关键代码运行得更快或者希望某些算法不公开(python可以参杂一些c代码,c可以参杂python)
你可以把你的部分程序用C或C++编写,然后在你的Python程序中使用它们 6:可嵌入性————你可以把Python嵌入你的C/C++程序,从而向你的程序用户提供脚本功能。 缺点: 1:速度慢,Python 的运行速度相比C语言确实慢很多,跟JAVA相比也要慢一些,
因此这也是很多所谓的大牛不屑于使用Python的主要原因,但其实这里所指的运行速度慢在大多数情况下用户是无法直接感知到的,
必须借助测试工具才能体现出来,比如你用C运一个程序花了0.01s,用Python是0.1s,
这样C语言直接比Python快了10倍,算是非常夸张了,但是你是无法直接通过肉眼感知的,
因为一个正常人所能感知的时间最小单位是0.15-0.4s左右,哈哈。
其实在大多数情况下Python已经完全可以满足你对程序速度的要求,
除非你要写对速度要求极高的搜索引擎等,这种情况下,当然还是建议你用C去实现的 2:代码不能加密,因为PYTHON是解释性语言,它的源码都是以名文形式存放的,
不过我不认为这算是一个缺点,如果你的项目要求源代码必须是加密的,
那你一开始就不应该用Python来去实现
(有个c语言代码可以加密变成密文,python必须是明文) 3:线程不能利用多CPU问题,这是Python被人诟病最多的一个缺点,GIL即全局解释器锁(Global Interpreter Lock),
是计算机程序设计语言解释器用于同步线程的工具,使得任何时刻仅有一个线程在执行,
Python的线程是操作系统的原生线程。在Linux上为pthread,在Windows上为Win thread,
完全由操作系统调度线程的执行。一个python解释器进程内有一条主线程,以及多条用户程序的执行线程。
即使在多核CPU平台上,由于GIL的存在,所以禁止多线程的并行执行。关于这个问题的折衷解决方法,我们在以后线程和进程章节里再进行详细探讨 编写Python代码时,得到的是一个包含Python代码的以.py为扩展名的文本文件。要运行代码,就需要Python解释器去执行.py文件 整个Python语言从规范到解释器都是开源的,所以理论上,只要水平够高,
任何人都可以编写Python解释器来执行Python代码(当然难度很大)。事实上,确实存在多种Python解释器。
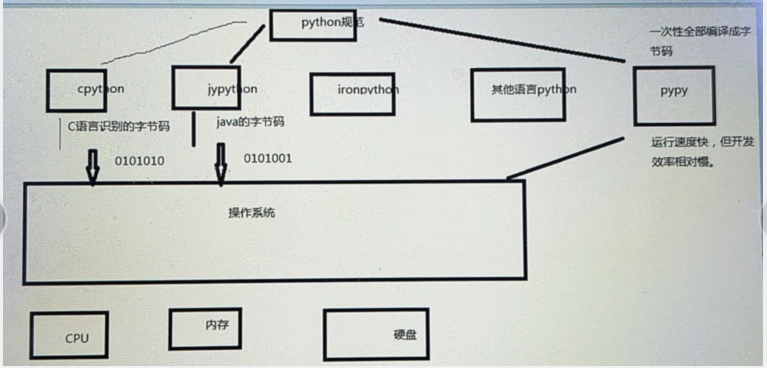
5:python种类
python的代码需要交给解释器(虚拟机)然后cpu运行解释器
所有的语言都需要依托解释器,代码放在里面运行
虽然python有多种解释器,但是写的代码都是一样的,不管你用什么解释器,写py的规范就是一种,只是用于不同解释器运行
官网的首推的是cpython基于c语言写的
python代码——>
交给cpython解释器(转化成c语言能识别的字节码(字节码就是一大堆文件,字节码才能转化成010101二进制,程序不能直接转化成010101,需要先转化成字节码))
转化成c语言的字节码能和c语言写的程序融合(c语言的程序也需要转化成c语言的字节码),这里是基于cpthon这个解释器转化成c语言能识别的字节码和c语言转化成的字节码一样的
然后c语言的字节码转化成010101二进制交给操作系统内存和cpu等来处理
cpython这个解释器把python代码转化成c语言能识别的字节码,再转化成对应的010101二进制
CPython:用C语言开发的,所以叫CPython。在命令行下运行python就是启动CPython解释器
Jython:Jython是运行在Java平台上的Python解释器,可以直接把Python代码编译成Java字节码执行
(把py代码转化成java语言识别的字节码,能和java程序结合,方便共同开发)
IronPython:IronPython和Jython类似,只不过IronPython是运行在微软.Net平台上的Python解释器,可以直接把Python代码编译成.Net的字节码
PyPy:python是解释型语言,pypy类似编译型语言,python写完了一次性全部都编译成python的字节码,然后再执行,所有的东西先编译再去运行
pypy运行速度快,类似c,但是开发效率相对低(一次性全部编译成字节码然后交给cpu运行)
主要还是使用cpython解释器,其他的解释器主要辅助其他语言开发的
6:运行第一个py文件
python3x :python 文件路径 回车
python2x :python2 文件路径 回车
python2 python3 第一个区别:python2默认编码方式是ascii码
解决方式:在文件的首行:#-*- encoding:utf-8 -*-
python3 默认编码方式utf-8(能识别中文)
python2代码里print输出有中文的时候在文件的首行加了:#-*- encoding:utf-8 -*-只能防止报错
但是print输出内容的中文还是乱码的,因为电脑的cmd终端输出的编码是gbk,而我们文件的首行默认采用了utf-8编码
#-*- encoding:utf-8 -*- 必须在文件首部写才能防止编码问题
7:变量:变量是可以更改的
变量:就是将一些运算的中间结果暂存到内存中,以便后续代码调用。
1:必须由数字,字母,下划线任意组合,且不能数字开头 2:不能是python中的关键字 ['and', 'as', 'assert', 'break', 'class', 'continue', 'def', 'del', 'elif', 'else', 'except', 'exec', 'finally', 'for', 'from', 'global', 'if', 'import', 'in', 'is', 'lambda', 'not', 'or', 'pass', 'print', 'raise', 'return', 'try', 'while', 'with', 'yield'] 3:变量具有可描述性(不要都使用a,b,c等,增加代码可读性) 4:不能是中文(中文不会报错,约定俗成)
5:变量名称不适合太长
python变量推荐定义方式
#驼峰体 AgeOfOldboy = 56 NumberOfStudents = 80 #下划线 age_of_oldboy = 56 number_of_students = 80
变量的赋值
age1 = 12
age2 = age1
age3 = age2
age2 = 100 name = '李二狗' = 是赋值符号,12赋值给age1,内存开辟一个空间里存12,然后创建一个变量age1,age1指向内存中存储12的这块内存区域(指向内存中的12)
内存先创建一个12,让age1指向12,age2 = age1——>又创建一个age2,让age2共同指向12,age3 = age2——>又创建一个age3,让age3指向内存里的12
age2 = 100——>内存里又创建一个100,让age2指向100,那么age2指向12这条线就断了,变量指向内存只能多个变量指向一个内存,不能多个内存指向一个变量
age = 12 + 3
"="是赋值,先算等于右边的,先把12+3算出来之后这个结果赋值给age,等号右边的先算赋值给左边
8:常量:不可以更改的,一直不变的量
python中没用常量的概念,c语言有
在Python中没有一个专门的语法代表常量,程序员约定俗成用变量名全部大写代表常量
AGE_OF_OLDBOY = 56
在c语言中有专门的常量定义语法,const int count = 60;一旦定义为常量,更改即会报错
9:注释
方便自己方便他人理解代码。代码的注解
单行注释:#
多行注释:'''被注释内容''' """被注释内容"""
解释器不是不读取注释的代码,读取后看到是注释只是不运行
10:基础数据类型
数字(int):12,3,45 + - * / **(幂次方) % 取余数 ps:type() 字符串转化成数字:int(str) 条件:str必须是数字组成的。 数字转化成字符串:str(int) 字符串(str):python当中凡是用引号引起来的都是字符串。 可相加:字符串的拼接 str+str 可相乘:str * int 布尔值(bool): True False(主要用于逻辑判断,首字母一定大写) 列表 元组 字典 不同数据类型干不同的操作,规定一些数据类型
python判断一个对象是什么数据类型:type()
整数类型(int)取值范围 int(整型) 在32位机器上,整数的位数为32位,取值范围为-2**31~2**31-1,即-2147483648~2147483647 在64位系统上,整数的位数为64位,取值范围为-2**63~2**63-1,即-9223372036854775808~9223372036854775807 除了int之外, 其实还有float浮点型, 复数型
python3里没用long长整型不管多大的数字都是int,py2里有但是和int没什么区别
单引号、双引号、多引号有什么区别,单双引号木有任何区别关注配合使用,外单内双,外双内单 多行字符串必须用多引号 msg = ''' 今天我想写首小诗, 歌颂我的同桌, 你看他那乌黑的短发, 好像一只炸毛鸡。 ''' print(msg)
三个引号是注释也能是一个大字符串,整体的一个可以分行的大字符串
msg = "
今天我想写首小诗,
歌颂我的同桌,
你看他那乌黑的短发,
好像一只炸毛鸡。
"
print(msg) # 这样写一个引号不行,会报错,涉及到换号必须使用三引号
11:用户交互:人与计算机进行交互 input
用户交互场景:登录qq输入密码,网上输入信息提交都是用户交互 python中用户交互:input输入 1,等待输入 2,将输入的内容赋值给了前面变量。 3,input出来的数据类型全部是str
12:if 条件判断语句 流程控制
if 条件: 满足条件后要执行的代码 冒号让条件与结果分开,冒号前面是条件,后面结果
if单分支 if 条件: 满足条件后要执行的代码
if 双分支 """ if 条件: 满足条件执行代码 else: if条件不满足就走这段 """ AgeOfOldboy = 48 if AgeOfOldboy > 50 : print("Too old, time to retire..") else: print("还能折腾几年!")
if 多分支 """ if 条件: 满足条件执行代码 elif 条件: 上面的条件不满足就走这个 elif 条件: 上面的条件不满足就走这个 elif 条件: 上面的条件不满足就走这个 else: 上面所有的条件不满足就走这段 """
# 简单的年龄游戏 age_of_oldboy = 48 guess = int(input(">>:")) if guess > age_of_oldboy : print("猜的太大了,往小里试试...") elif guess < age_of_oldboy : print("猜的太小了,往大里试试...") else: print("恭喜你,猜对了...")
# 简单匹配成绩的小程序,成绩有ABCDE5个等级,与分数的对应关系如下 A 90-100 B 80-89 C 60-79 D 40-59 E 0-39 # 要求用户输入0-100的数字后,能正确打印他的对应成绩 score = int(input("输入分数:")) if score > 100: print("我擦,最高分才100...") elif score >= 90: print("A") elif score >= 80: print("B") elif score >= 60: print("C") elif score >= 40: print("D") else: print("太笨了...E") # 这里有个问题,就是当我输入95的时候 ,它打印的结果是A,但是95 明明也大于第二个条件elif score >=80:呀,
为什么不打印B呢?这是因为代码是从上到下依次判断,只要满足一个,就不会再往下走啦,
13:python 缩进
AgeOfOldboy = 48 if AgeOfOldboy > 50 : print("Too old, time to retire..") else: print("还能折腾几年!") 上面的if代码里,每个条件的下一行都缩进了4个空格(或者一个Tab), 这就是Python的一大特色,强制缩进,目的是为了让程序知道,每段代码依赖哪个条件,
如果不通过缩进来区分,程序怎么会知道,当你的条件成立后,去执行哪些代码呢?
在其它的语言里,大多通过{}来确定代码块,比如C,C++,Java,Javascript都是这样,看一个JavaScript代码的例子 var age = 56 if ( age < 50){ console.log("还能折腾") console.log('可以执行多行代码') }else{ console.log('太老了') } 在有{}来区分代码块的情况下,缩进的作用就只剩下让代码变的整洁了 Python是门超级简洁的语言,发明者定是觉得用{}太丑了,所以索性直接不用它,那怎么能区分代码块呢?答案就是强制缩进。 Python的缩进有以下几个原则: 顶级代码必须顶行写,即如果一行代码本身不依赖于任何条件,那它必须不能进行任何缩进 同一级别的代码,缩进必须一致 官方建议缩进用4个空格,当然你也可以用2个,如果你想被人笑话的话
13:while循环
while 条件(只要是能判断真假的添条件都可以): 循环体(1:无限循环 2:终止循环(1:改变while后面的条件,使其不成立 2:break)
continue
while 条件:当条件为真的时候进入循环体,然后走循环体里面的代码,
走到循环最底部后走了一次循环又从循环体底部返回到while 条件:
继续判断条件是否为真,为真条件为真继续走循环体,为假的不进入循环体(这样一直判断)
count = 1
count = count + 1
这时候count = 2, = 是赋值运算,先计算等号右边的,count +1此时count=1那么count + 1 =2,
计算好等号右边的等于2后再赋值给count
所有count一开始本来指向1这个对象的内存地址,后面经过 = 赋值后count指向2这个对象的内存地址了
count在这里经过两个事:1:count自加1 2:count被覆盖
count本来指向内存里的1,count+1是在内存中又创建一个2,然后这个2又赋值给了count,count又指向2了
本来一开始count指向1的被覆盖掉了(没了),类似写两行第一行count=1,第二行count=2,count最后等于2
= 赋值运算符,先算等号右边的然后赋值给等号左边的
== 比较运算符,比较两边大小,返回布尔对象
# 从1打印到100 # 方法一:使用flag标志位 count = 1 flag = True # 标志位 while flag: print(count) count += 1 if count > 100: flag = False # 方法二:cout的等式不等式直接当条件 count = 1 while count <= 100: print(count) count += 1
# 1+....+100:定义两个变量一个变量是始终变化的1到100的count,还有一个变量是存储累加的值的sum
count = 1
sum = 0
while count <= 100:
sum += count
count += 1
print(sum)
# break关键字配合while循环使用来终止while循环 # while或者for循环中只要遇到break就立马中端终止循环,不管下面多少代码 sum = 0 count = 1 while 1: sum += count count += 1 if count == 101: break print(sum)
# continue(继续)关键字配合while循环使用:结束本次循环,继续下面的循环 count = 0 while count < 100: count += 1 if 5 <= count <= 95: # if count >5 and count < 95: continue print(count) # 打印除了5到95的其他1到100的整数
# else + while 特定的输出 # 当while循环被break打断时候,不走else语句块 count = 0 while count <= 5: count = count + 1 if count == 3: break print('Loop', count) else: print('循环正常执行') print('-------------------------------------------------') # 这里while循环被break打断了,不会打印else里面的print输出 # 当while循环没有被break打断时候,会走else语句块 count = 0 while count <= 5: count = count + 1 if count == 3: pass print('Loop', count) else: print('循环正常执行')、 # 这里while循环没用被break打断,会打印else里面的print输出
14:%号格式化输出
# 格式化输出 # % 占位符 s=要替换的数据是str字符串 d=要替换的数据是digit数字 # 格式化输出的字符串里面有%号,再加个百分号,第一个百分号表示转义,告诉计算机下面的百分号是真正的百分号,不是占位符 # %%只是单纯的显示% name = '袁文韬' age = 18 height = '185' msg = '我叫%s, 今年%d ,身高 %s,学习进度%%50' % (name, age, height) # 按照顺序替换 # %是占位符,s是替换的内容的类型(str字符串类型) # 格式化输出的字符串里面有%号,再加个百分号,第一个百分号表示转义,告诉计算机下面的百分号是真正的百分号,不是占位符 print(msg) # 我叫袁文韬, 今年18 ,身高 185,学习进度%50
# 格式化输出
# % s d
name = input('请输入姓名:')
age = input('请输入年龄:')
height = input('请输入身高:')
msg = "我叫%s,今年%s 身高 %s" % (name, age, height) # input输入进来的内容都是字符串类型,所以都可以使用%s
print(msg)
# 分行格式化输出 如下:
name = input('请输入姓名:')
age = input('请输入年龄:')
job = input('请输入工作:')
hobbie = input('你的爱好:')
msg = '''------------ info of %s -----------
Name : %s
Age : %d
job : %s
Hobbie: %s
------------- end -----------------''' %(name,name,int(age),job,hobbie)
print(msg)
# 格式化输出的字符串内容里有百分号:使用%来转义%号,如下
name = input('请输入姓名:')
age = input('请输入年龄:')
height = input('请输入身高:')
msg = "我叫%s,今年%s 身高 %s 学习进度为3%%s" % (name, age, height)
print(msg)
15:简单练习


# 1:输出:1,2,3,4,5,6,8,9,10 i = 1 while i < 11: if i != 7: print(i) i = i + 1 # 2:输出1-100所有数的和 i = 1 count = 0 while i < 101: count = count + i i = i + 1 print(count) # 3、输出 1-100 内的所有奇数(除2余1) i = 1 while i < 101: if i % 2 != 0: print(i) i = i + 1 # 5、求1-2+3-4+5 ... 99的所有数的和 i = 1 count = 0 while i < 100: if i % 2 != 0: count = count + i else: count = count - i i = i + 1 print(count) # 6、用户登陆(三次机会重试) # input 心中有账号,密码 while i = 0 while i < 3: username = input('请输入账号:') password = int(input('请输入密码:')) if username == '咸鱼哥' and password == 123: print('登录成功') else: print('登录失败请重新登录') i += 1
16:编码基础知识
学习网址:https://www.cnblogs.com/jin-xin/articles/10563881.html
01010100 新 11010000 开 11010100 一 01100000 家 11000000 看 11000000 看 01010100011101110101011110110 A B C 01000001 01000010 01000011 电报,电脑的传输,磁盘里存储的文件都是01010101二进制 最早的'密码本'ascii 涵盖了英文字母大小写,特殊字符,数字 01010101 ascii 只能表示256种可能,太少(ascll码只是美国标准:8位二进制)8位表示一个字节(东西)
1bit 8bit(位) == 1byte(字节)
1byte 1024byte字节(千字节) == 1kb
1kb 1024kb == 1MB
1MB 1024MB == 1GB
1GB 1024GB == 1TB
为了解决全球化文字编码问题创办了万国码 unicode(中文都9w多个字,至少需要2的17次方才能包括)
unicode:一个字节表示所有的英文,特殊字符,数字等,
起初建立初期2个字节16位表示中文,但是不够,中文9w多个字,后面unicode使用4个字节32位表示一个中文
现在地球所有文字全部加起来21位就能表示了,但是unicode使用32位
unicode:1个字节表示所有的英文,4个字节表示所有的中文 A 01000001010000010100000101000001 B 01000010010000100100001001000010 我 01000010010000100100001001000010
硬盘存储的是二进制,一个中文32位标识很浪费,中文就9w多个,unicode使用32位浪费空间 所以对Unicode 进行升级演变 utf-8 utf-16 utf-32 8位 = 1字节bytes utf-8 一个字符最少用8位去表示,英文用8位 1个字节(utf-8一个中文3个字节24位表示,相比unicode4个节约空间) 欧洲文字用16位去表示 2个字节 中文用24 位去表示 3个字节24位 utf-16 一个字符最少用16位去表示 gbk:中国人自己发明的,一个中文用2个字节16位去表示(只包括中文+英文),只能包含部分常用中文,包含不了9w中文字
gbk也是有英文的,包含了ascii码,gbk一个英文用一个字节,一个中文用两个字节
utf8和gbk不能直接转化的,gbk基于ascii码升级的
utf8基于unicode,而unicode基于ascii码,
所以gbk和utf8都需要通过unicode进行互换
假如别人的代码编码是gbk,需要先编码成unicdoe,再编码成utf-8
需要中间转换
所以为什么py2打印中文报错,因为py2默认以ascill码来进行翻译的,不包括中文,想让中文显示需要修改编码方式为utf-8
16:python编码学习二
ascii A : 00000010 8位 一个字节 unicode A : 00000000 00000001 00000010 00000100 32位 四个字节 中:00000000 00000001 00000010 00000110 32位 四个字节 utf-8 A : 00100000 8位 一个字节 中 : 00000001 00000010 00000110 24位 三个字节 gbk A : 00000110 8位 一个字节 中 : 00000010 00000110 16位 两个字节 1,各个编码之间的二进制,是不能互相识别的,会产生乱码。 2,文件的储存,传输,不能是unicode(只能是utf-8 utf-16 gbk,gb2312,ascii等) unicode 耗内存。耗流量(传输和储存用的不是gbk就是utf8的或者其他编码) 但是utf8和gbk的转换还需要用到unicode,只是传输和储存不用 py3: str字符串在内存中是用unicode编码方式存储的。 (就是一个变量 a="cc",程序运行的时候代码加载到内存,cc在内存中以unicode编码) 所以传输和储存不能直接存,需要转化() 比如一个py文件读取到内存类似一个大字符串,使用unicode编码读取的 一个py文件写完后,默认转为utf8转化存储 单独读取一个文件,默认转化成unicode编码读取 bytes类型,也是一种数据类型,bytes类型编码是以gbk,utf8或者gb2312编码的,不是unicode编码的 所以说传输和存储一个字符串,先把字符串转化成bytes类型再进行存储和传输 存储和传输一段字符串,编码方式要不是utf-8,要不就是gbk或者gb2312或者ascll码等类型 str ---》 bytes -》 存储和传输 unicode方式编码 utf-8,要不就是gbk或者gb2312或者ascll码等类型 str默认unicode编码方式,str不能直接进行存储和传输,需要转化转化成bytes类型再进行存储和传输, 对于英文: str :表现形式:s = 'alex' 编码方式: 010101010 unicode的01010101 bytes :表现形式:s = b'alex' 编码方式: 000101010 可能是utf-8 gbk。。。。 对于中文: str :表现形式:s = '中国' 编码方式: 010101010 unicode bytes :表现形式:s = b'x\e91\e91\e01\e21\e31\e32' utf-8编码 十六进制 表示中文 \e91\e91\e01 十六进制的三个字节表示一个中文, 三个字节表示一个中文代表 utf8编码 如果两个字节表示一个中文 gbk编码 记住:这是经验 编码方式: 000101010 utf-8 gbk。。。。 # encode编码 将unicode转化成utf8或者gbk,表现形式是将str转化成bytes类型, # 实际内部是将unicode转化成utf8或者gbk,encode实现 s1='alex' s11=s1.encode() # encode编码,str转化成bytes类型,存储和传输必须是bytes类型,不转换就会报错 print(s11) # b'alex' s2='中国' print(s2.encode(encoding='utf-8')) #b'\xe4\xb8\xad\xe5\x9b\xbd' \xe4表示一个字节,每个字符三个字节:utf8 print(s2.encode(encoding='gbk')) #b'\xd6\xd0\xb9\xfa' 每个字符两个字节:gbk编码
ascii : 8位 1字节 表示1个字符 unicode : 32位 4个字节 表示一个字符 utf- 8: 1个英文 8位,1个字节 欧洲 16位 两个字节 表示一个字符 亚洲 24位 三个字节 表示一个字符 gbk 1个英文 8位,1个字节 亚洲 16位 两个字节 表示一个字符 字符:看到组成字符串的最小元素(单位) 字节:8位一个字节,一个单位 python3 str内部的编码方式是unicode 存储和传输一个文件(大字符串)是以utf8或者gbk编码,unicode转化成utf8类型,字符串转化成bytes类型 bytes默认的编码类型是utf8,gbk等 ----转化很重要 decode解码和encode编码 s = 'alex' b = s.encode('utf-8') # 字符串转化成bytes类型 print(b) # b'alex'
python3.x 默认的字符编码是Unicode,默认的文件编码是utf-8
python2.x 默认的字符编码是ASCII,默认的文件编码是ASCII
字符串编码和解码
默认字符串是Unicode类型,该类型字符串只能保存在内存中
bytes类型字符串,可以保存在磁盘和网络间数据传输
字符串从Unicode到bytes,需要编码:str.enconde("utf-8")
字符串从bytes到Unicode,需要解码:str.decode("utf-8")
字节:字节(Byte)是计算机中数据存储的基本单元,一字节等于一个8位的比特,
计算机中的所有数据,不论是保存在磁盘文件上的还是网络上传输的数据(文字、图片、视频、音频文件)都是由字节组成的
字符:你正在阅读的这篇文章就是由很多个字符(Character)构成的,
字符一个信息单位,它是各种文字和符号的统称,
比如一个英文字母是一个字符,一个汉字是一个字符,一个标点符号也是一个字符
字符集:字符集(Character Set)就是某个范围内字符的集合,
不同的字符集规定了字符的个数,比如 ASCII 字符集总共有128个字符,
包含了英文字母、阿拉伯数字、标点符号和控制符。而 GB2312 字符集定义了7445个字符,包含了绝大部分汉字字符。
字符码:字符码(Code Point)指的是字符集中每个字符的数字编号,
例如 ASCII字符集用 0-127 连续的128个数字分别表示128个字符,例如 "A" 的字符码编号就是65
字符编码:字符编码(Character Encoding)是将字符集中的字符码映射为字节流的一种具体实现方案,
常见的字符编码有 ASCII 编码、UTF-8 编码、GBK 编码等。某种意义上来说,字符集与字符编码有种对应关系,
例如 ASCII 字符集对应有 ASCII 编码。ASCII 字符编码规定使用单字节中低位的7个比特去编码所有的字符。
例如"A" 的编号是65,用单字节表示就是0×41,因此写入存储设备的时候就是b'01000001'
ASCII 码:
说到字符编码,要从计算机的诞生开始讲起,计算机发明于美国,在英语世界里,常用字符非常有限,
26个字母(大小写)、10个数字、标点符号、控制符,这些字符在计算机中用一个字节的存储空间来表示绰绰有余,
因为一个字节相当于8个比特位,8个比特位可以表示256个符号。
于是美国国家标准协会ANSI制定了一套字符编码的标准叫 ASCII(American Standard Code for Information Interchange),
每个字符都对应唯一的一个数字,比如字符 "A" 对应数字是65,"B" 对应 66,以此类推。
最早 ASCII 只定义了128个字符编码,包括96个文字和32个控制符号,一共128个字符只需要一个字节的7位就能表示所有的字符,
因此 ASCII 只使用了一个字节的后7位,剩下最高位1比特被用作一些通讯系统的奇偶校验。
扩展的 ASCII,EASCII(ISO/8859-1)
然而计算机慢慢地普及到其他西欧地区时,发现还有很多西欧字符是 ASCII 字符集中没有的,
显然 ASCII 已经没法满足人们的需求了,好在 ASCII 字符只用了字节的7位 0×000x7F 共128个字符,
于是他们在 ASCII 的基础上把原来的7位扩充到8位,把0×80-0xFF这后面的128个数字利用起来,
叫 EASCII ,它完全兼容ASCII,扩展出来的符号包括表格符号、计算符号、希腊字母和特殊的拉丁符号。
然而 EASCII 时代是一个混乱的时代,各个厂家都有自己的想法,大家没有统一标准,
他们各自把最高位按照自己的标准实现了自己的一套字符编码标准,比较著名的就有 CP437 ,
CP437 是 始祖IBM PC、MS-DOS使用的字符编码。众多的 ASCII 扩充字符集之间互不兼容,
这样导致人们无法正常交流,例如200在CP437字符集表示的字符是 È ,
在 ISO/8859-1 字符集里面显示的就是 ╚,于是国际标准化组织(ISO)及国际电工委员会(IEC)联合制定的一系列8位字符集的标准 ISO/8859-1(Latin-1) ,
它继承了 CP437 字符编码的128-159之间的字符,所以它是从160开始定义的,ISO-8859-1在 CP437 的基础上重新定义了 160~~255之间的字符
多字节字符编码 GBK:
ASCII 字符编码是单字节编码,计算机进入中国后面临的一个问题是如何处理汉字,
对于拉丁语系国家来说通过扩展最高位,单字节表示所有的字符已经绰绰有余,
但是对于亚洲国家来说一个字节就显得捉襟见肘了。于是中国人自己弄了一套叫 GB2312 的双字节字符编码,
又称GB0,1981 由中国国家标准总局发布。GB2312 编码共收录了6763个汉字,
同时他还兼容 ASCII,GB 2312的出现,基本满足了汉字的计算机处理需要,
它所收录的汉字已经覆盖中国大陆99.75%的使用频率,不过 GB2312 还是不能100%满足中国汉字的需求,
对一些罕见的字和繁体字 GB2312 没法处理,后来就在GB2312的基础上创建了一种叫 GBK 的编码,
GBK 不仅收录了27484个汉字,同时还收录了藏文、蒙文、维吾尔文等主要的少数民族文字。
同样 GBK 也是兼容 ASCII 编码的,对于英文字符用1个字节来表示,汉字用两个字节来标识。
Unicode 的问世:
GBK仅仅只是解决了我们自己的问题,但是计算机不止是美国人和中国人用啊,
还有欧洲、亚洲其他国家的文字诸如日文、韩文全世界各地的文字加起来估计也有好几十万,
这已经大大超出了ASCII 码甚至GBK 所能表示的范围了,虽然各个国家可以制定自己的编码方案,
但是数据在不同国家传输就会出现各种各样的乱码问题。如果只用一种字符编码就能表示地球甚至火星上任何一个字符时,
问题就迎刃而解了。是它,是它,就是它,我们的小英雄,统一联盟国际组织提出了Unicode 编码,
Unicode 的学名是"Universal Multiple-Octet Coded Character Set",简称为UCS。
它为世界上每一种语言的每一个字符定义了一个唯一的字符码,
Unicode 标准使用十六进制数字表示,数字前面加上前缀 U+,比如字母『A』的Unicode编码是 U+0041,汉字『中』的Unicode 编码是U+4E2D
Unicode有两种格式:UCS-2和UCS-4。UCS-2就是用两个字节编码,一共16个比特位,这样理论上最多可以表示65536个字符,
不过要表示全世界所有的字符显示65536个数字还远远不过,因为光汉字就有近10万个,
因此Unicode4.0规范定义了一组附加的字符编码,UCS-4就是用4个字节(实际上只用了31位,最高位必须为0)。
理论上完全可以涵盖一切语言所用的符号
Unicode 的局限:
Unicode 有一定的局限性,一个 Unicode 字符在网络上传输或者最终存储起来的时候,
并不见得每个字符都需要两个字节,比如字符“A“,用一个字节就可以表示的字符,偏偏还要用两个字节,显然太浪费空间了。
第二问题是,一个 Unicode 字符保存到计算机里面时就是一串01数字,
那么计算机怎么知道一个2字节的Unicode字符是表示一个2字节的字符呢,
例如“汉”字的 Unicode 编码是 U+6C49,我可以用4个ascii数字来传输、保存这个字符;
也可以用utf-8编码的3个连续的字节E6 B1 89来表示它。关键在于通信双方都要认可。
因此Unicode编码有不同的实现方式,比如:UTF-8、UTF-16等等。Unicode就像英语一样,
做为国与国之间交流世界通用的标准,每个国家有自己的语言,他们把标准的英文文档翻译成自己国家的文字,这是实现方式,就像utf-8
UTF-8 具体实现:
UTF-8(Unicode Transformation Format)作为 Unicode 的一种实现方式,
广泛应用于互联网,它是一种变长的字符编码,可以根据具体情况用1-4个字节来表示一个字符。
比如英文字符这些原本就可以用 ASCII 码表示的字符用UTF-8表示时就只需要一个字节的空间,
和 ASCII 是一样的。对于多字节(n个字节)的字符,第一个字节的前n位都设为1,第n+1位设为0,后面字节的前两位都设为10。
剩下的二进制位全部用该字符的unicode码填充。以『好』为例,『好』对应的 Unicode 是597D,
对应的区间是 0000 0800--0000 FFFF,因此它用 UTF-8 表示时需要用3个字节来存储,
597D用二进制表示是: 0101100101111101,填充到 1110xxxx 10xxxxxx 10xxxxxx 得到 11100101 10100101 10111101,
转换成16进制是 e5a5bd,因此『好』的 Unicode 码 U+597D 对应的 UTF-8 编码是 "E5A5BD"
编码和解码的含义:
编码的过程是将字符转换成字节流,解码的过程是将字节流解析为字符
Python3 的编码、解码:
字符加载进内存的编码格式是Unicode
编码是用指定的字符集将字符转换为字节流
解码是用指定的字符集将字节流转化为字符
Python3 也有两种数据类型,str和bytes,str类型存unicode数据,bytes类型存bytes数据
当打开文件时,需要指定字符集来确定用什么字符集来将bytes解码成unicode数据。
保存文件时,也需要指定字符集来确定将unicode的数据编码为bytes类型数据
python字符编码unicode:
Python在处理数据时,只要数据没有指定它的编码类,那么Python默认将其当做Unicode来进行处理
最直接的表现在当我们编写的python的.py文件中编写一个 a = "中国",会把这个"中国"使用unicode编码到内存里
整个py文件运行的时候python编辑器都会用unicode的编码去处理整个脚本
python编码问题:https://blog.csdn.net/apache0554/article/details/53889253
https://www.cnblogs.com/yyds/p/6171340.html
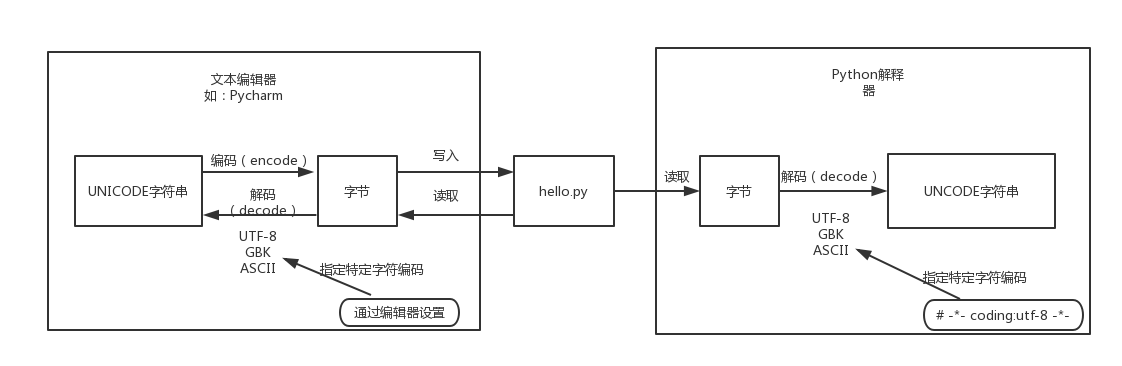
Pyhon3中字符编码有了很大改善:
1:Python 3的源码.py文件的默认编码方式为UTF-8,所以在Python3中你可以不用在py脚本中写coding声明,
并且系统传递给python的字符不再受系统默认编码的影响,统一为unicode编码
2:将字符串和字节序列做了区别,字符串str是字符串标准形式与2.x中unicode类似,
bytes类似2.x中的str有各种编码区别。bytes通过解码转化成str,str通过编码转化成bytes
我们使用Pycharm来编写Python程序时会指定工程编码和文件编码为UTF-8,
那么Python代码被保存到磁盘时就会被转换为UTF-8编码对应的字节(encode过程)后写入磁盘。
当执行Python代码文件中的代码时,Python解释器在读取Python代码文件中的字节串之后,
会先把这个utf8的文件字节码先解码(py2默认使用ascll节码,py3默认使用utf8把这个文件解码)
解码成unicode对应的字节点(也就是对应unicode这个编码表里的是十六进制)
需要将其转换为UNICODE字符串(decode过程)之后才执行后续操作
也就是一个py文件以utf8存储在磁盘,文件里的内容需要被py解释器翻译,
所以在文件的前头加一个:# -*- coding:utf-8 -*- 告诉py解释器我这个py文件是utf8编码的,
需要使用utf8对文件进行解码,把所有的字符解码成UNICODE代码点才能进行后续操作
可以多参考下图和文档: https://www.cnblogs.com/yyds/p/6171340.html
17:基本运算符
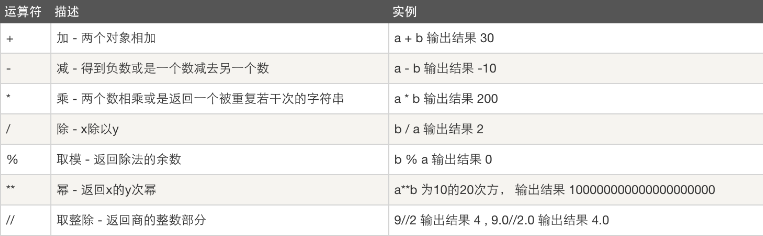
一:算数运算符 假设:a = 10, b = 20
二:比较运算符 假设:a = 10, b = 20

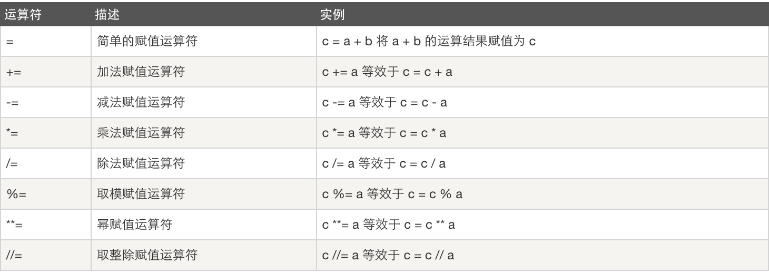
三:赋值运算符 假设:a = 10, b = 20
四:逻辑运算符

# 逻辑运算符号 and or not之间的优先级 # 在没有()的情况下not 优先级高于 and,and优先级高于or,即优先级关系为( )>not>and>or,同一优先级从左往右计算。
2 > 1 and 1 < 4 or 2 < 3 and 9 > 6 or 2 < 4 and 3 < 2
and先算:2 > 1 and 1 < 4为True ,2 < 3 and 9 > 6为True,2 < 4 and 3 < 2为False 那么最终为:True or True or False最终等于True
# 逻辑运算符and or not 前后如果非逻辑表达式的情况 # 数字转化成布尔值,非零的数字转化成布尔值就是True,零转化成布尔值就是False # ps int ----> bool 非零转换成bool True 0 转换成bool 是False print(bool(2)) #True print(bool(-2)) #True print(bool(0)) #False # 布尔值转化成数字,True=1 False=0 # bool --->int print(int(True)) # 1 print(int(False)) # 0 # x or y x为真True(非零),则返回x,x=False,则返回y print(1 or 2) # 1 print(3 or 2) # 3 print(0 or 2) # 2 print(0 or 100) # 100 print(2 or 100 or 3 or 4) # 2 print(0 or 4 and 3 or 2) # 3 and > or 0 or 3 or 2 ->3 or 2 ->3 print(1 >2 and 3 or 4 and 4 < 3) # false false and 3 or 4 and false ->false or false # x and y x为真True(非零),则返回y,x=False,则返回x print(1 and 2) # 2 print(0 and 2) # 0 print(2 or 1 < 3) # 2 or True ->2 print(3 > 1 or 2 and 2) # True or 2 and 2 -> True or 2 ->True # 本人总结 x and y :不管x是数字还是布尔表达式,一个原则:输出最后运行的逻辑符号 x为真,and(且)运算,就算前面为真,还是要运行后面的,输出最后运行的y x为假,and(且)运算,前面为假,后面的y没必要判断了,输出最后运行的x x or y x为真,or(或)运算,x为真就可以知道整个表达式为真,y没必要运行,输出最后运行的x x为假,or(或)运算,x为假还需要运行后面的y的真假才能判断整个表达式,输出最后运行的y 严格按照运算规则: () 括号第一优先级 比较运算符 比较运算符:>, <, >=, <=等在第二运算级 逻辑运算符 逻辑运算符:and or not 在第三优先级, not > and > or print(True and 2) # 理论上输出2 计算机从左往右算,
五:成员运算符号

# 成员运算符用来判断子元素是否在原字符串(字典,列表,集合)中: print('喜欢' in 'dkfljadklf喜欢hfjdkas') print('a' in 'bcvd') print('y' not in 'ofkjdslaf')
六:所有Python运算符优先级
运算符 描述
** 指数 (最高优先级)
~ + - 按位翻转, 一元加号和减号 (最后两个的方法名为 +@ 和 -@)
* / % // 乘,除,取模和取整除
+ - 加法减法
>> << 右移,左移运算符
& 位 'AND'
^ | 位运算符
<= < > >= 比较运算符
<> == != 等于运算符
= %= /= //= -= += *= **= 赋值运算符
is is not 身份运算符
in not in 成员运算符
not and or 逻辑运算符
18:简单练习
'''熟悉and or not的使用''' print(5 < 4 or 3) # False or 3 -> 3 print(2 > 1 or 6) # True or 6 ->True print(3 > 1 and 0) # True and 0 ->0 '''变量命名规范''' # 1:字母,数字下划线的组合 # 2:不能以数字开头,一般以字母开头可以下划线开头,但是下划线开头的变量一般有特殊含义,不建议用下划线开头 # 3:不能和python里面定义的一些关键字相同 # 4:大小写敏感(区分大小写) # 5:不要和内置函数相同如:print=1, # 6:变量命名最好要见名知意(很重要的规范:使用翻译软件)驼峰法命名规则或者下划线命名 '''计算 1 - 2 + 3 ... + 99 中除了88以外所有数的总和''' i = 1 count = 0 while i < 100: if i == 88: pass elif i % 2 == 0: count = count - i else: count = count + i i = i + 1 print(count) '''计算 1 - 2 + 3 ... - 99 中除了88以外所有数的总和''' # 分析:1-87 奇数+ 偶数- # 89-99 奇数- 偶数+ i = 1 count = 0 while i < 100: if i < 88: if i % 2 == 0: count = count - i else: count = count + i elif i > 88: if i % 2 == 0: count = count + i else: count = count - i i = i + 1 print(count) # 解法二: i 表示数字位 j表示符号位 i = 1 j = 1 count = 0 while i < 100: if i == 88: i = i + 1 continue count = count + i * j i = i + 1 j = j * -1 print(count) '''7:⽤户登陆(三次输错机会)且每次输错误时显示剩余错误次数(提示:使⽤字符串格式化)''' # 方法1 i = 1 while i <= 3: username = input('用户名>>>>') password = int(input('密码>>>>')) if username == '咸鱼哥' and password == 123: print('登录成功') break else: print(f'登录失败,你还有{3 - i}次等机会') if 3 - i == 0: str = input('您的登录次数已经用完,输入c继续执行登录操作') if str == 'c': i = 1 continue i = i + 1 # 方法2 i = 1 while i <= 3: username = input('用户名>>>>') if username == '咸鱼哥': password = int(input('密码>>>>')) if password == 123: print('恭喜您,登录成功') break else: if i == 3: print('你的机会已经没了!game over 下次见!') answer = input('再试试?Y or N') if answer == 'Y': i = 1 print(f'密码错误,你还有{3 - i}次输出机会') else: print(f'用户名错误,你还有{3 - i}次输出机会') if i == 3: print('你的机会已经没了!game over 下次见!') answer = input('再试试?Y or N') if answer == 'Y': i = 1 i = i + 1 else: print('你TM要不要脸') # while循环不被break打断就会走else
19:int整数类型
# int数字类型 一般就是 + - * / 等计算
bit_length() 函数 i = 5 # i是个变量,储存的是int数据类型 print(i.bit_length()) # 3 bit_length对什么有什么方法 # bit_length 把int数字转换成二进制最少的位数, ''' 1 0000 00001 有效位数1 bit_length=1 2 0000 00010 有效位数10 bit_length=2 3 0000 00011 有效位数11 bit_length=2 4 0000 00100 有效位数100 bit_length=3 '''
20:bool布尔类型
# bool类型没有什么方法,基本都是判断真和假 True False '''int ----> str 数字转字符串,没什么条件,什么都可以转换''' i = 1 s = str(i) # '1' '''str ----> int str转换成int,需要str里面只能是数字''' i = '1' s = int(i) # 1 '''int ----> bool 数字转换成布尔值,只要是0 ->False 只要是非0 ->True''' i = 1 print(bool(i)) # True '''bool ----> int 布尔值转换成int:True ->1 ,False ->0''' print(int(True)) #1 print(int(False)) #0 '''while 1 的使用 ''' while True: pass while 1: # while 1:比while True:的效率高,因为True要转换一下 pass # True转换成1.再转换成010101二进制,最好都写while 1: 效率高 '''str --->bool ''' s = '' # 空字符串转换成布尔值就是False print(bool(s)) # False s = '0' # 非空字符串转换成布尔值都是True print(bool(s)) # True s = '' if s: # s 有数据才走if里面的代码块,这这里s为空所以走else print('hello') else: print(1212)
21:str字符串类型
什么是字符串
# Python中凡是用引号引起来的数据可以称为字符串类型, # 组成字符串的每个元素称之为字符,将这些字符一个一个连接起来,然后再用引号引起来就是字符串 s = 'abcdef'
字符串的索引与切片 字符串通过索引取值 # 1:索引,就是序号,第一位索引值是0 ,通过索引取值 # 对字符串的进行任何操都会产生一个新的字符串,和原字符串没什么关系,不会修改原始字符串,字符串是不可变类型 s = 'abcdef' s1 = s[0] print(s1) # a s1是新参数的字符串'a', # 字符串切片,原来的字符串不变 s[首:尾:步长] s3 = s[0:4] #:冒号表示省略,顾头不顾尾 s4 = s[:] # 取s整个字符串 s6 = s[0:] # 取s整个字符串 s5 = s[-1] # 取字符串的最后一位 s7 = s[0:5:2] # 间隔取,跳着取,s7得到一个字符串:ace ,切片步长默认是1 s8 = s[4:0:-1] # 字符串的反向取值 4包含,0不包含 输出:edcb s9 = s[3::-1] # dcba s10 = s[3::-2] # db 反向跳着取值 s11 = s[-1::-1] # fedcba 字符串的反向取值 只要是倒着取值就是负的索引 s12 = s[::-1] # fedcba 字符串的反向取值 等同s11=s[-1::-1]
字符串的常用操作 s = "yuanWENtao" s1 = s.capitalize() # Yuanwentao 首字母强制大写,其他强制小写,对字符串里的数字和符号没有作用 s2 = s.upper() # YUANWENTAO 字符串全部变成大写 s3 = s.lower() # yuanwentao 字符串全部变成小写 s4 = s.swapcase() # YUANwenTAO 字符串大小写翻转 s = "yuan WEN tao" s21 = "yuan*WEN tao" s5 = s.title() # Yuan Wen Tao 让每个单词首字母大写 s51 = s21.title() # Yuan*Wen Tao 每个单词首字符串大写,中间只要不是英文链接字符串就行 s = "yuanWENtao" s6 = s.center(20) # 设置一个长度,让字符串居中,空白填充 s61 = s.center(20, '#') # #####yuanWENtao##### 20个长度,填充物#,居中 s = "yuanWEN\ttao" # \t table s7 = s.expandtabs() # yuanWENtao 字符串中有\t ,就会自动转换成Tab键,从这到前没有8个补齐8个,大于8位的补16位,8为单位累加 # 公共方法:字符串,列表元组等都可以使用的方法 # len() # 测量str长度,列表里面的元素,字典多少键值对,元组多长 s = "yuanWENtao" # 10个元素 print(len(s)) # 10个元素 s8 = s.startswith('yuan') # 判断字符串以什么开头 返回布尔值:True s81 = s.startswith('a', 2, 4) # 判断字符串中第3位置开始到4位置结束以什么开头, 左包右不包 s82 = s.endswith('o') # 判断字符串以什么结尾,也支持切片 # 寻找字符串有没有n这个元素 find,通过元素找索引,找不到返回-1,支持切片 s = "yuanWENtao" s9 = s.find('N') # 找到这个元素返回的是索引 6,返回一个数字类型 s91 = s.find('asd') # 找不到元素返回 -1 # 通过元素找索引 index(),找到返回索引,找不到报错 s = "yuanWENtao" s10 = s.index('A') # ValueError: substring not found 找不到报错 # 去空格 s = " yuanWENtao " s11 = s.strip() # yuanWENtao 默认删除前后空格,还可以删除其他的 s = "*yuanWENtao%" s110 = s.strip('%*') # yuanWENtao 前后找 %,*为最小单元进行删除 s = " yuanWENtao " s12 = s.lstrip() # 只删除前面的 left 左边开始删除 s13 = s.rstrip() # 只删除后面的 right 右边开始删除 # count统计个数 s = "asjdkasjd" s14 = s.count('a') # 2 ,返回int类型数据,2个,没有返回0 支持切片,支持寻找字符串和单个字母 # split 拆分,分隔,返回列表,切割后返回的列表里面的元素不包含切点 str->list s = 'asdsad askdjasd akdjas' s_list = s.split(' ') # ['asdsad', 'askdjasd', 'akdjas'] 按照空格分隔,返回列表 s_list1 = s.split() # ['asdsad', 'askdjasd', 'akdjas']什么都不传默认空格切割字符串 # format 字符串的格式化输出 s = '我叫{},今年{}'.format('袁文韬', 18) # 按照顺序填写参数 print(s) # 我叫袁文韬,今年18 s = '我叫{0},今年{1}'.format('袁文韬', 18) # 按照索引填写参数 print(s) # 我叫袁文韬,今年18 s = '我叫{name},今年{age}'.format(age=18, name="袁文韬") # 按照参数传递参数 这里必须填写键值对 print(s) # 我叫袁文韬,今年18 # python 3.6版本以上的简单字符串格式化写法 name = '袁文韬' age = 18 s = f'我叫{name},今年{age}' print(s) # 我叫袁文韬,今年18 # replace 字符串的替换,产生一个新的字符串,对原字符串没有影响 # def replace(self, old, new, count=None): old:旧参数 new:新参数 count:替换的次数 默认全部替换 s = "yuanWENtao" s15 = s.replace('WEN', 'wen') # 后面的替换前面的 print(s15) # yuanwentao # 判断字符串的组成:是否都是数字,字母或者字母加数字 s = "yuanWENtao" print(s.isdigit()) # False isdigit判断字符串是否有数字组成,digit数字 print(s.isalpha()) # True isalnum判断字符串是否都是字母组成 print(s.isalnum()) # True isalnum判断字符串是否都由数字和字符串组成
22:for循环
# for循环有限循环 while循环无限循环 # for循环一遍用于遍历字符串,列表和知道循环次数的情况 s = "asdasdasd" for i in s: # s只要是可迭代(元素众多)对象就可以(字符串,列表元组字典都可以) print(i) # 迭代完自己结束循环 # for循环配合range使用 for i in range(10): print(i, end=',') # 0,1,2,3,4,5,6,7,8,9, # in和 not in s = 'fdsa袁文韬asdkjsakd' if "袁文韬" in s: print("您的评论有敏感词")
23:python2和python3编码问题
python3.x 默认的字符编码是Unicode,默认的文件编码是utf-8 python2.x 默认的字符编码是ASCII,默认的文件编码是ASCII
字符编码就是编写了代码后运行的代码读取到计算机内存使用的编码,文件编码是py代码中打开各种文件比如with open等使用的默认编码 Python字符串编码和解码 (1)默认字符串是Unicode类型,该类型字符串只能保存在内存中 (2)bytes类型字符串,可以保存在磁盘和网络间数据传输 (3)字符串从Unicode到bytes,需要编码:str.enconde("utf-8") (4)字符串从bytes到Unicode,需要解码:str.decode("utf-8") ord()函数和chr()函数 ord()函数返回字符对应的ASCII数值或者Unicode数值(看py2和py3)print(ord('袁')) # 34945 chr()函数返回ASCII数值或者Unicode数值所对应的字符 # print(chr(34945)) # 袁 chardet模块:检测其编码方式,然后转换为字符串 pip install chardet ASCII码类型检测 import chardet name = b'hello world' encode_format = chardet.detect(name) # {'encoding': 'ascii', 'confidence': 1.0, 'language': ''} name_str = name.decode(encoding='ascii') # hello world GBK码类型检测 import chardet name = '袁文韬'.encode(encoding="gbk") # b'\xd4\xac\xce\xc4\xe8\xba' encode_format = chardet.detect(name) # {'encoding': 'TIS-620', 'confidence': 0.8095977270813678, 'language': 'Thai'} name = name.decode(encoding='gbk') # 袁文韬 # 这里使用chardet模块识别编码的时候错误了,有误差,无法精准识别 识别with open读取文件后的内容的utf8编码 import chardet with open('./1 今日内容大纲', 'rb') as f: info = f.read() print(chardet.detect(info)) # {'encoding': 'utf-8', 'confidence': 0.99, 'language': ''} print(info.decode(encoding='utf8')) # 输出1 今日内容大纲这个文件里的字符串内容 乱码问题 (1)乱码的根源是编码和解码的方式不统一导致的 (2)解决乱码问题就是把编解码方式统一
python3默认编码是unicode,而且4个字节表示一个字符 python2使用2个或者4个表示一个字符,可以改变,python2默认是两个,python2的unicode默认两个字节表示一个字符 可以改成四个,python3规定就四个字节表示一个字符,无法修改, Python2在编译安装时,可以通过参数- -enable- unicode=ucs2 或一enable- -unicode =uCs4 分别用于指定使用2个字节、4个字节表示一个unicode字符; Python3无法进行选择, 默认使用ucs4. 查看当前Python中表示unicode字符串时占用的空间: import sys print(sys.maxunicode) #如果值是65535,则表示使用ucs2标准,即: 2个字节表示 #如果值是1114111,则表示使用ucs4标准,即: 4个字节表示
24:简单练习
s = '132a4b5c' # 1:通过对字符串的切片形成新的字符串 s1,s1='123' s1 = s[0] + s[2] + s[1] # 拼接做,一次切片做不出来 print(s1) # 2:使用while和for循环分别打印字符串s=’asdfer’中每个元素 s = 'asdfer' for i in s: print(i) index = 0 # 打印每个元素通过index索引打印 while index < len(s): print(s[index]) index = index + 1 # 3:实现一个整数加法计算器 如:content = input(‘请输入内容:’) # 如用户输入:5+9或5+ 9或5 + 9,然后进行分割再进行计算。 content = input('请输入想要相加的两个数:') list_a = content.split('+') sum_ = int(list_a[0].strip()) + int(list_a[1].strip()) print(f'{content}={sum_}') content = input('>>>').strip() index = content.find("+") a = int(content[0:index]) b = int(content[index + 1:]) print(a + b) # int(str) int函数,str字符串里面可以有空格也能转成int整数, # sum(iterable[, start]) # iterable -- 可迭代对象,如:列表、元组、集合。 # start -- 指定相加的参数,如果没有设置这个值,默认为0。 print(sum([1, 2, 3], 5)) # 11 # 4:任意输入一串文字+数字 统计出来数字的个数 s = input("请输入:") # '1234324324fdsaf1fdsaf12' count = 0 for i in s: if i.isdigit(): count += 1 print(count) # 5:任意输入一串文字+数字 统计出来数字的个数 '1234324324fdsaf1fdsaf12' 1234324324 这种只算一个数字 # 思路:使用while循环,循环到下标大于字符串长度结束 # 当找到一个数字的时候,需要再进入一层循环,继续再找到这个数字的下标上一个个加, # 判断是不是数字,是数字index下标加1,直到判断index到最后一个 # 注意循环到最后一个index如果是数字需要加try,不然列表越界报错 s = '1234324324fdsaf1fdsaf12' index = 0 count = 0 while index < len(s): if s[index].isdigit(): count = count + 1 while 1: try: if s[index + 1].isdigit(): index = index + 1 else: break except: index = len(s) + 10 break index = index + 1 print(count) s = '1234324324fdsaf1fdsaf12xxxx12xxxx16xxxx19' index = 0 count = 0 while index < len(s): if s[index].isdigit(): # 如果是数字 count += 1 index += 1 while 1: try: if s[index].isdigit(): index += 1 else: break except: break else: index += 1 print(count)
25:列表的常用操作
python中的列表:
大部分语言叫数组,python叫列表,个性
每个元素 ,逗号隔开,每个元素可以放各种类型。字符串,数字,布尔值,元组,列表,字典都可以放
列表里甚至还可以存放对象
列表相比于字符串,不仅可以储存不同的数据类型,而且可以储存大量数据,32位python的限制是 536870912 个元素,
64位python的限制是 1152921504606846975 个元素。
而且列表是有序的,有索引值,可切片,方便取值。(很多操作类似字符串)
列表的增删改查的操作
li = ['alex', [1, 2, 3], 'wusir', 'egon', '女神', 'taibai'] print(li[0]) # alex 索引取值 print(li[:3]) # ['alex', [1, 2, 3], 'wusir'] 取列表前三个,截取出来还是列表 # 列表的增操作 # 1:增加 append(在后面追加)和 insert指定位置插入 li = ['alex', [1, 2, 3], 'wusir', 'egon', '女神', 'taibai'] li.append('白天') # append往列表最后添加元素,修改了原来的列表,append方法没有返回值 print(li) # ['alex', [1, 2, 3], 'wusir', 'egon', '女神', 'taibai', '白天'] # 字符串的操作和列表的操作不同点:字符串的各种操作都是返回一个新的字符串,对原数据没有影响 # 列表的各种操作很多都是在原来列表的基础上增加修改,修改原数据 # 添加员工到员工列表,增加10个人 # 1:可以连续增加 # 2:输入q退出,不输入q一直增加名称 employ = [] while 1: str_name = input('请输入员工的名称,输入q退出>>>>>') if str_name == 'q': break else: employ.append(str_name) print(employ) # inset 插入,需要有索引和位置 li = ['alex', [1, 2, 3], 'wusir', 'egon', '女神', 'taibai'] li.insert(1, "李狗") # 往li这个列表索引1的位置差入"李狗"这个字符串元素 print(li) # ['alex', '李狗', [1, 2, 3], 'wusir', 'egon', '女神', 'taibai'] # extend 迭代添加,插入多个,添加到列表的最后面 li = ['alex', [1, 2, 3], 'wusir', 'egon', '女神', 'taibai'] li.extend('李狗') # def extend(self, iterable): 需要传入一个可迭代的对象 print(li) # ['alex', [1, 2, 3], 'wusir', 'egon', '女神', 'taibai', '李', '狗'] # 把字符串分解后添加
# li.extend(123) # TypeError: 'int' object is not iterable 报错,123数字不是一个可以迭代的对象,这里的参数必须可迭代的参数
# int对象不可以迭代的,123不能拆解,是个整体,这里需要传一个可迭代的数据 li.extend([1, 2, 3]) # ['alex', [1, 2, 3], 'wusir', 'egon', '女神', 'taibai', 1, 2, 3] # 列表元素拆开插入,插入到最后
# 列表的删除操作 pop,remove,del # pop函数 li = ['alex', [1, 2, 3], 'wusir', 'egon', '女神', 'taibai'] name1 = li.pop(1) # index=None 按照索引删除,删除第二个元素,pop删除有返回值,删除返回的数据 print(li) # ['alex', 'wusir', 'egon', '女神', 'taibai'] name2 = li.pop() # pop不传参数默认删除最后一个 print(li) # ['alex', 'wusir', 'egon', '女神'] print(name1, name2) # [1, 2, 3] taibai # remove函数 li = ['alex', [1, 2, 3], 'wusir', 'egon', '女神', 'taibai'] li.remove('女神') # def remove(self, value): 按照元素值删除的,删除效率慢,没有返回值 # remove一次只能删除第一次出现的一个,多个重复的删除不了 print(li) # ['alex', [1, 2, 3], 'wusir', 'egon', 'taibai'] # del方法删除 li = ['alex', [1, 2, 3], 'wusir', 'egon', '女神', 'taibai'] del li[1] print(li) # ['alex', 'wusir', 'egon', '女神', 'taibai'] # 清空列表 clear li = ['alex', [1, 2, 3], 'wusir', 'egon', '女神', 'taibai'] li.clear() # clear 清空列表 print(li) # [] # del 可以删除整个列表,也可以删除列表里面的元素 li = ['alex', [1, 2, 3], 'wusir', 'egon', '女神', 'taibai'] del li # 删除li这个列表,那么列表就不存在了 print(li) # NameError: name 'li' is not defined 报错.li列表被删除了 li = ['alex', [1, 2, 3], 'wusir', 'egon', '女神', 'taibai'] del li[0] # 删除li列表中第0个元素 print(li) # [[1, 2, 3], 'wusir', 'egon', '女神', 'taibai'] li = ['alex', [1, 2, 3], 'wusir', 'egon', '女神', 'taibai'] del li[2:] # 类似切片删除,切片整体删除,删除一块 del print(li) # ['alex', [1, 2, 3]] 改变列表原数据
# 修改列表里面的元素 # 列表的修改 通过索引直接修改(位置上的东西删了再添加上去) li = ['alex', [1, 2, 3], 'wusir', 'egon', '女神', 'taibai'] li[-1] = '男神' print(li) # ['alex', [1, 2, 3], 'wusir', 'egon', '女神', '男神'] # 列表的切片修改操作 传入字符串或者列表序列参数,参数按照元素拆分添加到列表 li = ['alex', [1, 2, 3], 'wusir', 'egon', '女神', 'taibai'] li[0:2] = '李狗' print(li) # ['李', '狗', 'wusir', 'egon', '女神', 'taibai'] # 删了0,1元素把'李狗'字符串拆分添加到列表里面 li[0:2] = '李狗是傻逼' # 把 列表0,1元素拿出来,然后把字符串'李狗是傻逼'拆分添加进去 ---切片修改 print(li) # ['李', '狗', '是', '傻', '逼', 'wusir', 'egon', '女神', 'taibai'] # 切片修改元素,字符串多少元素都会迭代拆分添加到列表里面 li = ['alex', [1, 2, 3], 'wusir', 'egon', '女神', 'taibai'] li[1:3] = [1, 2, 3, '李狗'] print(li) # ['alex', 1, 2, 3, '李狗', 'egon', '女神', 'taibai']
# 列表的 查找(索引查找,切片查找) li = ['alex', [1, 2, 3], 'wusir', 'egon', '女神', 'taibai'] for i in li: print(i) # 查询列表中的每一个元素 print(li[0:2]) # ['alex', [1, 2, 3]] 切片查询前两个元素,查询出来的是一个列表
# 一些能够操作列表的公共方法 '''len() 查询列表里面有多少个元素''' '''count() 计算列表里元素出现的次数''' '''index() 找到列表中元素的索引,找不到就报错,''' '''sort() 列表排序,数字类型的才好排序,默认从小到大依次排序,加参数reverse=True反向排序''' '''reverse() 列表翻转''' li = ['alex', [1, 2, 3], 'wusir', 'egon', '女神', 'taibai'] print(len(li)) # 6 列表的长度 print(li.count('wusir')) # 1 wusir这个元素出现的次数 print(li.index('wusir')) # 2 索引2表示在位置3,支持切片 li = [3, 8, 9, 1, 7, 6] li.sort() # [1, 3, 6, 7, 8, 9] li.sort(reverse=True) # [9, 8, 7, 6, 3, 1] 加参数reverse=True,倒向排序 li = [3, 8, 9, 1, 7, 6] li.reverse() print(li) # [6, 7, 1, 9, 8, 3]
# 列表的嵌套,列表里面嵌套列表的一些操作 li = ['taibai', '武藤兰', '苑昊', ['alex', 'egon', 89], 23] # 1:输出'武藤兰'里面的 '藤' print(li[1][1]) # 藤
# 2:找到'taibai' 首字母大写 li[0] = li[0].capitalize() # 首字母强制大写,其他强制小写,对字符串里的数字和符号没有作用 # 3:'苑昊'改成'苑日天' li[2] = li[2].replace('昊', '日天') # ['Taibai', '武藤兰', '苑日天', ['alex', 'egon', 89], 23]
# 4:'alex'大写换到列表原位置 li[-2][0] = li[-2][0].upper() # ['Taibai', '武藤兰', '苑日天', ['ALEX', 'egon', 89], 23]
# enumerate函数用于将一个可遍历的数据对象(如列表、元组或字符串)组合为一个索引序列, # 同时列出数据和数据下标,一般用在 for 循环当中 seasons = ['Spring', 'Summer', 'Fall', 'Winter'] print(list(enumerate(seasons))) # [(0, 'Spring'), (1, 'Summer'), (2, 'Fall'), (3, 'Winter')]
26:元组的常用操作
元组:俗称不可变的列表,又被称为只读列表,元祖也是python的基本数据类型之一,用小括号括起来,
里面可以放任何数据类型的数据,
元组不能删除,不能添加,不能修改,只能查询
查询可以,循环也可以,切片也可以.但就是不能改(元组的子元素不能更改,子元素里面的子元素可以更改).
元组的查询,切片,循环等各种操作
tu = (1, 2, 3, 'alex', [2, 3, 4, 'taibai'], 'egon') # [2,3,4,'taibai'] tu元组里面的[2, 3, 4, 'taibai']这个列表整体不能更改,但是列表里面的元素可以更改 # 元组里的'alex'元素不能更改, print(tu[3]) # alex能够查询 print(tu[0:4]) # (1, 2, 3, 'alex') 元组切片查询还是返回元组 for i in tu: # 元组支持for循环遍历 print(i)
# 修改元组里面的列表里面的元素 tu = (1, 2, 3, 'alex', [2, 3, 4, 'taibai'], 'egon') tu[-2][-1] = tu[-2][-1].upper() # 元组里面的列表里面的'taibai'元素改成全大写 print(tu) # (1, 2, 3, 'alex', [2, 3, 4, 'TAIBAI'], 'egon')
# join 方法的使用 s = "alex" print('_'.join(s)) # a_l_e_x # def join(self, iterable): 参数是可迭代对象,字符串或者列表元组集合都可以,数字布尔值不行 # S.join(iterable) -> str S代表用什么相连接,形成一个新的字符串,可迭代对象的每一个元素都用S连接符连接起来 # S 字符串 # iterable 可迭代对象 # join最后返回的是一个字符串类型的数据 # 很强大功能,记住,可以把列表连接成一个字符串
# 列表 的jion,把每一个元素拼接成一个字符串
li = ['alex', 'wusir', 'egon', '女神', 'taibai']
print(''.join(li)) # alexwusiregon女神taibai
# 列表的拼接,列表里面的元素必须都是字符串类型
# 字符串转换成列表 split或者list强转 str_a = "asdasdas" print(list(str_a)) # ['a', 's', 'd', 'a', 's', 'd', 'a', 's'] print(str_a.split('s')) # ['a', 'da', 'da', ''] split分割也可以 # 列表转字符串 join方法,或者str强转 li = ['alex', 'wusir', 'egon', '女神', 'taibai'] print(''.join(li)) # alexwusiregon女神taibai # 列表的拼接,列表里面的元素必须都是字符串类型
# range 返回一个顺序排列的数字的列表[1,2,3,4,5,....,100,....200] for i in range(0, 100): # 左含右不含, print(i, end=' ') # 0 1 2 ...... 99 print(range(10), type(range)) # range(0, 10) <class 'type'> range函数返回的是一个迭代器 # 支持步长操作 for i in range(0, 100, 2): # 左含右不含, print(i) # 返回偶数 # 支持反向操作 for i in range(10, 0, -1): # 左含右不含, print(i) # 返回 10-1 for i in range(0, 10, -1): # 左含右不含, print(i) # 什么都不输出,但是不会报错,也不会进入循环里面的代码 # 循环打印一个列表 ,如果列表里面的元素还是个列表那么子列表当中的每个元素也循环打印出来 li = [1, 2, 3, 5, 'alex', [2, 3, 4, 5, 'taibai'], 'afds'] for i in range(len(li)): if type(li[i]) == list: # type(li[i]) 返回的是列表 for j in li[i]: print(j) else: print(li[i])
27:简单练习
# 1:将列表lis中的’tt’变成大写(用两种方式) lis = [2, 3, 'k', ['qwe', 20, ['k', ['tt', 3, '1']], 89], 'ab', 'adv'] lis[3][2][1][0] = lis[3][2][1][0].upper() # lis = [2, 3, 'k', ['qwe', 20, ['k', ['TT', 3, '1']], 89], 'ab', 'adv'] # 2:将列表中的数字3变成字符串’100’(用两种方式) lis = [2, 3, 'k', ['qwe', 20, ['k', ['tt', 3, '1']], 89], 'ab', 'adv'] lis[3][2][1][2] = 101 print(lis) '''5:查找列表li中的元素,移除每个元素的空格, 并找出以’A’或者’a’开头,并以’c’结尾的所有元素, 并添加到一个新列表中,最后循环打印这个新列表。 ''' li = ['taibai ', 'alexC', 'AbC ', 'egon', ' Ritian', ' Wusir', ' aqc'] for i in li: name = i.strip() if name[0].upper() == 'A' and name[-1] == 'c': print(i) # aqc ''' 6:开发敏感词语过滤程序,提示用户输入评论内容,如果用户输入的内容中包含特殊的字符: # 敏感词列表 li = ["苍老师","东京热",”武藤兰”,”波多野结衣”] # 则将用户输入的内容中的敏感词汇替换成***,并添加到一个列表中; # 如果用户输入的内容没有敏感词汇,则直接添加到上述的列表中。 ''' li = ["苍老师", "东京热", "武藤兰", "波多野结衣"] str_in = input('请输入您的评论内容>>>>>') new_li = [] for i in li: if i in str_in: l = len(i) str_in = str_in.replace(i, '*' * l) print(str_in) new_li.append(str_in) print(new_li) '''7:随便输入字符串数字,让测试字符串里面整数的个数(数字相连的整体算一个数字)''' ''' 英文字母全部换成空,数字不进行任何操作 变成这种' 123 12 13' 样子 然后按照空格进行split,然后计算个数 ''' # info = input('>>>').strip() info = 'asdaw12awdwad9awdadwd55awdwad6666awddadaw777' for i in info: if i.isalpha(): info = info.replace(i, " ") # 默认replace替换全部元素 # info字符串被替换成: 12 9 55 6666 777 l = info.split() # 默认空格切片 print(l) print(len(l))
'''7:随便输入字符串数字,让测试字符串里面整数的个数(数字相连的整体算一个数字)''' ''' 英文字母全部换成空,数字不进行任何操作 变成这种' 123 12 13' 样子 然后按照空格进行split,然后计算个数 ''' # info = input('>>>').strip() info = 'asdaw12awdwad9awdadwd55awdwad6666awddadaw777' for i in info: if i.isalpha(): info = info.replace(i, " ") # 默认replace替换全部元素 # info字符串被替换成: 12 9 55 6666 777 l = info.split() # 默认空格切片 print(l) print(len(l)) # for i in info: 上面info是一个字符串,不可变的数据类型,代码这一行运行就把一开始输入的info字符串读取到内存了 # 循环多少次已经定了,每次i的数据也定了 # if i.isalpha(): # info = info.replace(i, " ") 代码这里info变量还是会一直赋值变化,但是for第一次循环读的info字符串是 # 第一次用户输入的info,按照第一次输入的info进行一次次循环,循环到最后结束 # for i in 字符串: 字符串在循环过程中改变,实际上改变的不是原来的字符串,而是产生一个新的字符串 # # 尽管字符串改变还是按照初始字符串的每一个元素去循环,次数还是原来字符串的长度的次数去循环 # for i in 列表: 循环当中改变列表里的值,循环次数就会发生改变(列表是可变的数据类型) (重点) # 'asd asd ' #这个字符串按照空格切片,后面的空格切一刀后面不会有个空格的元素 # a='asd asd ' # print(a.split()) #['asd', 'asd'] # a="sadasda" # print(a.replace('z'," "))
28:dict字典类型的常用操作
字典dict:python当中唯一一个映射数据类型,一个键(key)对应一个值(value),键值对组成 字典的key键必须是不可变数据类型,可哈希的:str,int,元组.bool 如果键设置成了可变数据类型就会报错 字典的value值任意数据类型都可以 数据类型的划分:可变数据类型,不可变数据类型 不可变数据类型(不可更改的): 元组,bool int str 可哈希 对str的任何操作都是产生了一个新的str,原str没有任何改变 可变数据类型: list,dict set 不可哈希 哈希:内部有一张哈希表,键到最后有个对应表,对应成什么,在内存中存的是一个大范围的数字 二分查找去查询(年龄0-100,找75岁的人,先找出50岁的人,每次查询只找一半 1-100随便写的数字,猜测,二分查找去猜,猜50问大还是小 ......) 二分查找查询速度最快的, 为什么字典查询速度快:字典的key都转换成对应的数字,每次查询键值对的时候,内部转换成数字,每次切一半去查询 二分查询寻找速度最快的---字典很牛逼,列表需要for循环一个个去查找数据 这就是字典里面的哈希表 dict 优点:二分查找去查询 存储大量的关系型数据 特点:字典是无序的(3.6后的python可能会对字典排序) key不要是1,2,3,4,5,6这种,这种的话就会有序排序,整体来说字典是无序的 无序代表没有索引,需要通过键值对查找,
dict字典的增删改查
dic = { 'name': ['大猛', '小孟'], 'py9': [{'num': 71, 'avg_age': 18, }, {'num': 71, 'avg_age': 18, }, {'num': 71, 'avg_age': 18, }, ], True: 1, (1, 2, 3): 'wuyiyi', 2: '二哥', } print(dic)
# dict 增加操作: dic1 = {'age': 18, 'name': 'jin', 'sex': 'male'} # dic1['high']=185 # 对dict1增加一个键值对(higt不存在就是增操作,high存在就是修改操作) # print(dic1)
dic1.setdefault('weight') # 只传了一个键参数.没写value值.默认value值就是None print(dic1) # {'age': 18, 'name': 'jin', 'sex': 'male', 'weight': None} dic1.setdefault('grade', '一年级' ) # 增加一个所属年级的键值对 setdefault函数里面传的key值没有就做增加操作 # key有的话不做任何操作,不会修改字典,也不会覆盖 # 有键值对不做任何操作,没有才添加 print(dic1) # {'age': 18, 'name': 'jin', 'sex': 'male', 'weight': None, 'grade': '一年级'}
# dict 删除操作: pop,popitem,clear(),del # 1:按照键删除 pop dic1 = {'age': 18, 'name': 'jin', 'sex': 'male', } print(dic1.pop('age')) # 18 根据键删除,返回被删除的键对应的值 print(dic1) # {'name': 'jin', 'sex': 'male'} age被删除,列表pop有返回值,字典里面pop返回键对应的值 # dic1.pop('傻逼') #如果想要pop删除的键字典没有这个值 就会报错 KeyError: '傻逼' dic1.pop('傻逼', None) # 这样加了个None参数删除,找不到'傻逼'这个键也没有报错,避免错误 print(dic1.pop('傻逼', '没有此键')) # 返回 '没有此键' ,后面的参数可以任意去些写,会当返回值返回,可设置返回值 # None 是特殊的数据类型,不是字符串
# 字典dict随机删除popitem() # popitem()有返回值,返回一个元组形式的一个被删除的键和值 dic1 = {'age': 18, 'name': 'jin', 'sex': 'male'} dic1.popitem() # 默认后面删除,(理论上是随机删除一个键值对,3.6以上的python版本有顺序了,一直删除最后的一个元素 print(dic1) # {'age': 18, 'name': 'jin'}
# 字典清空clear() dic1 = {'age': 18, 'name': 'jin', 'sex': 'male',} dic1.clear() print(dic1) # {}:清空后为空字典了
# del可以删除字典的键值对,也可以删除整个字典 dic1 = {'age': 18, 'name': 'jin', 'sex': 'male'} del dic1['name'] print(dic1) # {'age': 18, 'sex': 'male'} del函数没有返回值 # del dic1['name1'] # del删除一个不存在的'name1'元素会报错 KeyError: 'name1' # 删除字典的元素尽量使用pop del dic1 # 删除一整个字典
# 字典dict update的修改操作 dic1 = {'age': 18, 'name': 'jin', 'sex': 'male',} dic1['age'] = 133 # dic1字典存在'age'元素就是字典的修改操作 # update 把一个字典当中的键值对,覆盖更新到一个字典中 dic = {'name': '太白', 'age': 18} dic.update(sex='男', height=175) print(dic) # {'name': '太白', 'age': 18, 'sex': '男', 'height': 175} dic1 = {"name": "jin", "age": 18, "sex": "male"} dic2 = {"name": "alex", "weight": 75} dic1.update(dic2) # 把dic2的所有键值对更新到dic1里面(键存在的就覆盖,键不存在就添加) print(dic1) # {'name': 'alex', 'age': 18, 'sex': 'male', 'weight': 75} print(dic2) # {'name': 'alex', 'weight': 75}
# dict字典的查找操作,字典也有for循环 dic1 = {'age': 18, 'name': 'jin', 'sex': 'male', } print(dic1.keys()) # dict_keys(['age', 'name', 'sex']) print(dic1.values()) # dict_values([18, 'jin', 'male']) print(dic1.items()) # dict_items([('age', 18), ('name', 'jin'), ('sex', 'male')]) # dic1.keys()和dic1.values()和dic1.items()返回的是一个迭代器,可以看成一个列表类型使用,可以for循环 # dic1.keys() 可以看成把字典里面的全部的键放到一个列表 # dic1.values() 可以看成把字典里面的全部的值放到一个列表 # dic1.items() 可以看成把字典里面的全部的键和值放到一个列表 ,看成[(),()]这种列表嵌套元组使用 for i in dic1: # 相当于遍历字典dic1里面的键, 等同for i in keys(): print(i) # 打印字典的键 for i in dic1.values(): print(i) # 打印字典的值 for i in dic1.items(): # 一个参数去接收元组 print(i) # 打印元组,里面包含键和值 ('age', 18), ('name', 'jin') ,('sex', 'male') for i, j in dic1.items(): # 两个参数去接收一个元组 print(i, j) # 直接打印key和value没有括号 age 18 name jin sex male dic1 = {'age': 18, 'name': 'jin', 'sex': 'male'} print(dic1['name']) # jin # 通过键直接找值,缺点:找不到值就报错 print(dic1.get('age1')) # 18 # get方法通过键找值,键不存在不报错,返回None print(dic1.get('age1', "不存在")) # 不存在 get方法返回自定义的值,自己随意设置---得到键值对首选get,不会报错
'''python 代码容错率很高,js容错率更高,python里面分别赋值的功能''' a = 1 b = 2
# 一行代码转换a,b的值 a, b = b, a # a,b值互换,很简单,不需要加中间变量 # 内存创建1,2两个值,a,b两个变量也会创建 # 内存里存1和2的内存地址,内存地址唯一的, # 还存储了一个名称空间space,a变量与值得对应关系,b变量与值得对应关系 # 对应关系存的就是a这个变量指向那个内存地址,通过每次地址找到里面的内容 # 代码执行的时候内存里面找到名称空间,名称空间找到内存地址对应关系,然后找到变量所指的内容 # a,b=b,a 这样写就是改变了名称空间里面内存地址的对应关系 # a和b的内存地址互换了改变了对应关系----底层逻辑 print(a, b) # 2 1 a, b = [1, 2] # 类似拆包赋值 print(a, b) # 1 2 a, b = [1, 2], [3, 4] print(a, b) # [1, 2] [3, 4] # 传参自动识别,很高级,看参数的最小单位,参数需要一一对应,不然报错 c = [4, 5] print(*c) # 4 5 *c拆包 a, b = (1, 2) # 元组列表都支持 print(a, b) # 1 2
# dict字典的嵌套 dic = {'name': ['alex', 'wusir', 'taibai'], 'py9': { 'time': '1213', 'learn_money': 19800, 'addr': 'CBD', }, 'age': 56} # 1:age修改成28岁 print(dic) # 2:name后面的列表当中添加一个名字 dic['name'].append('袁文韬') print(dic) # 3:把wusir改成全部大写 dic['name'][1] = dic['name'][1].upper() print(dic) # 4:py9字典添加一个键值对 'female':6 dic['py9']['female'] = 6 # dic['py9'].setdefault('grade','一年级') print(dic)
29:简单练习
''' 1:有如下值li= [11,22,33,44,55,66,77,88,99,90], 将所有大于 66 的值保存至字典的第一个key中, 将小于 66 的值保存至第二个key的值中。 即: {'k1': 大于66的所有值列表, 'k2': 小于66的所有值列表} ''' li = [11, 22, 33, 44, 55, 66, 77, 88, 99, 90] dict_li = {'k1': [], 'k2': []} for i in li: if i > 66: dict_li['k1'].append(i) else: dict_li['k2'].append(i) print(dict_li) # {'k1': [77, 88, 99, 90], 'k2': [11, 22, 33, 44, 55, 66]} ''' 4、输出商品列表,用户输入序号,显示用户选中的商品 商品 li = ["手机", "电脑", '鼠标垫', '游艇'] 要求:1:页面显示 序号 + 商品名称,如: 1 手机 2 电脑 … 2: 用户输入选择的商品序号,然后打印商品名称 3:如果用户输入的商品序号有误,则提示输入有误,并重新输入。 4:用户输入Q或者q,退出程序。 ''' li = ["手机", "电脑", '鼠标垫', '游艇'] # 输出商品列表 序号和index索引相关 while 1: for i in li: # for 循环打印列表索引+产品 print(f'{li.index(i) + 1}\t\t{i}') # index(i) 通过元素索引找索引,find也可以 str_in = input('请输入商品的序号或者输入"q"退出>>>>>') if str_in.isdigit(): # 如果输入的字符串都是数字才进入循环 isdigit() if int(str_in) >= 1 and int(str_in) <= len(li): # len(li)数据不要写死,自己动态变化 print(li[int(str_in) - 1]) else: print('请重新输入有效的数字') elif str_in.upper() == 'Q': print('退出循环') break else: print('请重新输入有效数字') flage = False # 定义一个标志位,改变条件能退出,一般不能总指望一个break退出,多处都需要退出使用标记比较适合 # flage=False或者break都可以退出循环 '''定义一个购物车,一个列表,添加进去,商品是列表套很多字典, 需要输入资金. 买商品前提需要资产足够买商品, ''' ''' 买家 卖家 商品 金钱 1:需要一个列表里面存放每一个水果的相关信息 ''' li = [ {'name': '苹果', 'price': 10}, {'name': '香蕉', 'price': 20}, {'name': '西瓜', 'price': 30} ] # 货物放在货架上 shoping_car = {} print('欢迎光临水果店') money = input('让我看看你的钱>>>').strip() if money.isdigit() and int(money) > 0: while 1: for i, k in enumerate(li): print(f'序号{i},商品{k["name"]},价格{k["price"]}') choose = input('请输入您要购买的商品序号,输入q退出购物车>>>') if choose.isdigit() and 0 <= int(choose) < len(li): # 输入的都是数字 num = input('您要购买的商品数量>>>>') if num.isdigit() and int(num) > 0: if int(money) > li[int(choose)]['price'] * int(num): money = int(money) - li[int(choose)]['price'] * int(num) if li[int(choose)]['name'] in shoping_car: shoping_car[li[int(choose)]['name']] = shoping_car[li[int(choose)]['name']] + int(num) else: shoping_car[li[int(choose)]['name']] = int(num) print(f'购物车中的商品有{shoping_car},您的余额为{money}') else: print('没钱了!!!!!') break else: print('您输入的商品数量有误,请重新输入') elif choose == 'q': break else: print('请输入正确的序号')
30: python2与python3的区别
python2和python3的区别:
1:默认编码不同 python2默认ascll码,python3默认utf-8
2:python2 的源码重复率高,不规范,而且python崇尚的是简单优美清晰,所以开发了py3,规范化 ---宏观上的区别
3:print的时候:
python2: print 'abc' print不需要加括号,可以加括号也可以不加
puthon3:print('abc') print一定需要加括号
4:python2中有range也有xrange--xrange在python2中是一个生成器,
python3中只有range没有xrange
5:input
python2使用raw_input() 等于python3中的input
31:python中的= 和 == 和is id的使用
= 是赋值,一个值赋值给一个变量,赋值运算,就算两个变量指向一个对象的内存地址,共用一个 所以改变li1里面的值,那么li2里面的值也会改变,共用一个内存地址 == 比较值是否相等 is 比较的是内存地址 id(内容) 返回内容的id内存地址是多少 li1 = [1, 2, 3] li2 = li1 # li1赋值给li2,共用一个列表 print(li1 is li2) # True li1的内存地址和li2的相同会返回True li3 = li2 print(id(li1), id(li2)) # 2416433318464 2416433318464
python中is和==的区别:https://www.cnblogs.com/wangkun122/p/9082088.html
https://zhuanlan.zhihu.com/p/35219174
a = [1, 2, 3]
b = [1, 2, 3]
print(a is b) # False
print(a == b) # True
简单来说is对比的是两个对象的id内存地址
而==调用的是对象的__eq__方法来对比两个对象的值
32:数字和字符串的小地址池讲解
数字,字符串 都有个小数据池,为了在一定程度上节省内存空间,共用一个 小数据池:如果创建范围之内的数字或者字符串会公用一个,为了节省内存 数字的小数据池范围 -5 -- 256,创建的变量i1和i2在这个范围内且一样,那么在内存之间只开辟一个空间 字符串的小数据池的范围:1,不能有特殊字符 2,s*20 还是同一个地址,s*21以后都是两个地址 s是一个字符 i1 = 6 i2 = 6 print(id(i1),id(i2)) #小数据池,i1和i2在小数据池的范围内在内存中公用一个,节省内存 i1 = 300 i2 = 300 print(id(i1),id(i2)) 剩下的 list dict tuple set 这些数据类型没有小数据池的概念,都会开辟两个空间,只有数字和字符串会有这种机制
33:python编码解码
# 编码 将unicode转化成utf8或者gbk,表现形式是将str转化成bytes类型,实际内部是将unicode转化成utf8或者gbk,encode实现 s1 = 'alex' s11 = s1.encode() # encode编码,str转化成bytes类型,存储和传输必须是bytes类型,不转换就会报错 print(s11) # b'alex' s2 = '中国' print(s2.encode(encoding='utf-8')) # b'\xe4\xb8\xad\xe5\x9b\xbd' \xe4表示一个字节,每个字符三个字节:utf8 print(s2.encode(encoding='gbk')) # b'\xd6\xd0\xb9\xfa' 每个字符两个字节:gbk编码 print(s2.encode())
# encode编码和decode节码
# str --->byte encode 编码 s = '二哥' b = s.encode('utf-8') # b'\xe4\xba\x8c\xe5\x93\xa5' print(b) # byte --->str decode 解码 s1 = b.decode('utf-8') # 二哥 print(s1) s = 'abf' b = s.encode('utf-8') # b'abf' print(b) # byte --->str decode 解码 s1 = b.decode('gbk') # abf print(s1)
34:python基础数据类型
str(字符串)和 int()数字类型
str # 在pycham里ctrl进去查看源码查看str的一些内建函数的使用方法 s = '' print(s.isspace()) # Python isspace() 方法检测字符串是否只由空格组成。如果字符串中只包含空格,则返回 True,否则返回 False int _下划线开始的是一些内置函数,只能内部调用
list:列表类型
# for i in range(len(lis)): #进入range循环前,已经把这个数长度测试出来了。后面循环不会改变 # :冒号之后才进入循环 :之前range测出来了长度5 # 所以range形成了一个了类似列表[0,1,2,3,4] # 第一次进入循环range()这个是死的了,后面循环不再变化 # range是一个有序的范围,确定了就不能改变了---死的了 # print(i) # i = 0 i = 1 i = 2 # del lis[i] # print(lis) # [11,22,33,44,55] [22, 44, 55] [22, 44] # # 在循环一个列表时,最好不要删除列表中的元素,这样会使索引发生改变,从而报错 '''输入列表Li的奇数位''' # 方法1: # lis = [11,22,33,44,55] # lis = lis[::2] # print(lis) # 方法2 # lis = [11,22,33,44,55] # l1 = [] # for i in lis: # if lis.index(i) % 2 == 0: # l1.append(i) # lis = l1 # print(lis) # 方法3 # lis = [11,22,33,44,55] # # for i in range(len(lis)-1,-1,-1): # range()反向排序,4-0 # if i % 2 == 1: # del lis[i] #反向删除 # print(lis)
dict 字典的各种操作方法 fromkeys() 函数用于创建一个新字典,以序列 seq 中元素做字典的键,value 为字典所有键对应的初始值。 dict.fromkeys(seq[, value]) seq -- 字典键值列表。 value -- 可选参数, 设置键序列(seq)对应的值,默认为 None dic = dict.fromkeys([1, 2, 3], '春哥') print(dic) # {1: '春哥', 2: '春哥', 3: '春哥'} dic = dict.fromkeys([1, 2, 3], []) print(dic) # {1: [], 2: [], 3: []} dic[1].append('袁姐') print(dic) # {1: ['袁姐'], 2: ['袁姐'], 3: ['袁姐']} dic[2].extend('二哥') print(dic) # {1: ['袁姐', '二', '哥'], 2: ['袁姐', '二', '哥'], 3: ['袁姐', '二', '哥']} # 为什么dic[1]添加了一个元素,1,2,3后面的值都有这个元素,因为三个键共用的一个列表 重点 dict2 = {4: [], 5: [], 6: []} dict2[4].append('袁文韬') print(dict2) # {4: ['袁文韬'], 5: [], 6: []} 这里是不同的三个列表 l1 = [] l2 = l1 l3 = l1 l3.append('a') print(l1, l2, l3) # ['a'] ['a'] ['a'] # 删除字典当中含有k元素的键值对 # 方法一 dic = {'k1': 'v1', 'k2': 'v2', 'a3': 'v3'} dic1 = {} # 创建的新字典,保存不好含"k"的键值对 # 循环一个字典的时候不能使用del删除字典的键值对,和列表的操作类似,肯定会报错,创建一个新的字典类解决 # 创建一个新的空字典,保存不含有k的键值对,然后新字典赋值旧字典 for i in dic: # 默认循环键key if 'k' not in i: dic1.setdefault(i, dic[i]) # 键值对加到新的字典 dic = dic1 print(dic) # 方法二:删除字典当中含有k元素的键值对 # 把含有key的键添加到一个列表,循环列表删除字典键值对就没问题了 dic = {'k1': 'v1', 'k2': 'v2', 'a3': 'v3'} l = [] for i in dic: if 'k' in i: l.append(i) # l里面全是含有k的键 for i in l: # 循环全是k键的列表 del dic[i] # del或者pop 根据键删除, print(dic) # 把含有k的键添加到一个列表当中,循环列表去删除字典的东西 # 循环字典去删除字典的东西是不可以的---肯定报错 # 谨记:循环列表和字典的时候不要删除里面的东西,删除就容易报错或者结果不对
转化成bool值
数字:0 数字:空 列表:空列表 元组:空 字典:空 集合:空 这些转化成bool值全都是False
剩下的数字,数字,列表,元组,字典,集合转化成bool值都是True
元组 知识点1: # 元组 如果元祖里面只有一个元素且不加,那此元素是什么类型,就是什么类型。 tu1 = (1) # 如果元组里面只有一个元素且不加,符号 那么此元素是什么类型,就是什么类型。 tu2 = (1,) print(tu1, type(tu1)) # 1 <class 'int'> print(tu2, type(tu2)) # (1,) <class 'tuple'> tu1 = ([1]) tu2 = ([1],) print(tu1, type(tu1)) # [1] <class 'list'> print(tu2, type(tu2)) # ([1],) <class 'tuple'> dic = dict.fromkeys([1, 2, 3, ], 3) dic[1] = 4 print(dic) # {1: 4, 2: 3, 3: 3} dic = dict.fromkeys([1, 2, 3, ], []) dic[1].append('李二狗') print(dic) # {1: ['李二狗'], 2: ['李二狗'], 3: ['李二狗']}
35:集合
集合:可变的数据类型,他里面的元素必须是不可变的数据类型,无序,元素不重复(列表转集合自动去重)。
{}和字典一样大括号,但是里面是一个个元素,没有键值对
增删改查能改变原数据就算可变
1:集合的定义和创建 set1 = set({1, 2, 3}) set2 = set([1, 2, 3]) set4 = set((1, 2, 3)) set3 = {1, 2, 3} print(set1, set2, set3, set4) # {1, 2, 3} {1, 2, 3} {1, 2, 3} {1, 2, 3}输出四个集合 # set1,set2和set3都可以设置集合,中括号[], 小括号(),大括号{}都可以设置集合,但是正规是{} # set3这样直接创建也行,
# 重点:集合里面必须是不可变的元素,放列表或者字典都会报错
2:集合 的add增加操作:1:add 方法 2:update方法 set1 = {'alex', 'wusir', 'ritian', 'egon', 'barry', } set1.add('女神') # add是添加单个元素 print(set1) # {'alex', 'egon', 'ritian', 'wusir', 'barry', '女神'} set1.update('abc') # update 迭代添加对象,如果对象可以迭代那么迭代添加对象里的多个元素 print(set1) # {'alex', 'egon', 'ritian', 'b', 'a', 'c', 'wusir', 'barry', '女神'}
# 3:集合的 delete删除操作和clear清空等操作 1:pop随机删除 2:remove(集合不支持del set[]这样的操作,报错)
3:clear清空集合 4:del直接删除整个集合 set1 = {'alex', 'wusir', 'ritian', 'egon', 'barry', } res = set1.pop() # pop 随机删除,返回值就是被删除的元素 print(set1) # {'egon', 'barry', 'ritian', 'alex'} print(res) set1 = {'alex', 'wusir', 'ritian', 'egon', 'barry', } set1.remove('alex') # remove按照元素删除,元素不存在报错 print(set1) # {'egon', 'ritian', 'barry', 'wusir'} set1 = {'alex', 'wusir', 'ritian', 'egon', 'barry', } set1.clear() # 清空集合 print(set1) # set() 表示空集合 set1 = {'alex', 'wusir', 'ritian', 'egon', 'barry', } del set1 # 删除整个集合 # print(set1) # NameError: name 'set1' is not defined
# 4:set集合的seach查找操作,只能for循环查询,没有索引,没有键值对 集合没有修改操作,无序,里面元素不可更改 set1 = {'alex', 'wusir', 'ritian', 'egon', 'barry', } for i in set1: print(i)
set集合的交集,并集,差集 # 1:求交集: & 和 intersection都是求交集 set1 = {1, 2, 3, 4, 5} set2 = {4, 5, 6, 7, 8} set3 = set1 & set2 # & 求交集合 print(set3) # {4, 5} print(set1.intersection(set2)) # {4, 5} intersection也是求交集 # 2:求并集,所有的元素集合到一起,两个合并成一个 | 和 union 都是求并集 set1 = {1, 2, 3, 4, 5} set2 = {4, 5, 6, 7, 8} print(set1 | set2) # {1, 2, 3, 4, 5, 6, 7,8} print(set2.union(set1)) # {1, 2, 3, 4, 5, 6, 7} # 3:求反交集合,两个集合的交集是4,5,除了4,5之外的两个集合独有的元素组成一个新的集合 ^和symmetric_difference都是求反交集 set1 = {1, 2, 3, 4, 5} set2 = {4, 5, 6, 7, 8} print(set1 ^ set2) # {1, 2, 3, 6, 7, 8} print(set1.symmetric_difference(set2)) # {1, 2, 3, 6, 7, 8} # 4:求差集, set1独有的拿出来成一个新的集合,set1 -set2 :set1独有的 - 和 difference都是差集 set1 = {1, 2, 3, 4, 5} set2 = {4, 5, 6, 7, 8} print(set1 - set2) # {1, 2, 3} # set1独有的那么就是set1 - set2 print(set1.difference(set2)) # {1, 2, 3} # 5:子集 set1 < set2 set2包含set1,所以set1是set2的子集(全都包含) < 和 issubset 都是求子集合,返回布尔值
set1 = {1, 2, 3,}
set2 = {1, 2, 3, 4, 5, 6}
print(set1 < set2) # True 返回布尔值
print(set1.issubset(set2)) # 这两个相同,都是说明set1是set2子集。 # 6:超集 set2包含set1,那么set2是超集合 > 和 issuperse都是求超集,返回布尔值 set1 = {1, 2, 3, } set2 = {1, 2, 3, 4, 5, 6} print(set2 > set1) # 返回布尔值 print(set2.issuperset(set1)) # 这两个相同,都是说明set2是set1超集
# 列表去重 li = [1,2,33,33,2,1,4,5,6,6] 列表去掉重复的元素, 方法一:算法去做 方法二:转化成集合做(py内置的一些函数效率肯定比算法高,因为是c语言写的 # 方法一:set去重 li = [1, 2, 33, 33, 2, 1, 4, 5, 6, 6] print(list(set(li))) # [1, 2, 33, 4, 5, 6] # 方法二:算法
# frozenset冻结集合,把set集合转化成不可变的数据类型 # set集合本身是可变的数据类型,但是可以一步转化转化成不可变的数据类型:frozenset冻结,变成不可变的集合 s1 = {1, 2, 3} print(s1, type(s1)) # <class 'set'> s = frozenset('barry') # <class 'frozenset'> s现在是一个不可变的集合,冻住的集合 print(s, type(s)) for i in s: print(i) # frozenset类型的集合只读,不能增加和删除元素,还是无序的
36:深拷贝和浅拷贝
# 深拷贝和浅拷贝 首先深拷贝和浅拷贝都是对象的拷贝,都会生成一个看起来相同的对象, 他们本质的区别是拷贝出来的对象的地址是否和原对象一样,也就是地址的复制还是值的复制的区别。 什么是可变对象,什么是不可变对象: 可变对象是指,一个对象在不改变其所指向的地址的前提下,可以修改其所指向的地址中的值; 不可变对象是指,一个对象所指向的地址上值是不能修改的, 如果你修改了这个对象的值,那么它指向的地址就改变了, 相当于你把这个对象指向的值复制出来一份,然后做了修改后存到另一个地址上了, 但是可变对象就不会做这样的动作,而是直接在对象所指的地址上把值给改变了,而这个对象依然指向这个地址。 深拷贝和浅拷贝需要注意的地方就是可变元素的拷贝: 在浅拷贝时,拷贝出来的新对象的地址和原对象是不一样的, 但是新对象里面的可变元素(如列表)的地址和原对象里的可变元素的地址是相同的, 也就是说浅拷贝它拷贝的是浅层次的数据结构(不可变元素), 对象里的可变元素作为深层次的数据结构并没有被拷贝到新地址里面去, 而是和原对象里的可变元素指向同一个地址, 所以在新对象或原对象里对这个可变元素做修改时, 两个对象是同时改变的,但是深拷贝不会这样, 这个是浅拷贝相对于深拷贝最根本的区别。 深拷贝浅拷贝需要导入 copy模块 import copy a = [1, 2, 3] b = copy.copy(a) print(id(a), id(b)) # 2343257562176 2343257507136 # a列表和b(通过浅拷贝拷贝过来的)列表id不同 List1 = ['a', 'b', 'c'] List2 = ['a', 'b', 'c'] print(List1[0], id([List1[0]])) # a 2343257582336 print(List2[0], id([List1[0]])) # a 2343257582336 # list1和list2两个列表中的’a’这个元素的地址是相同的,但是两个列表的地址是不同的
# 深拷贝浅拷贝案例场景:外部接口A调用的时候会返回一组数据: data = [10, 20, [100, 200]] # 返回的是嵌套列表 # 业务a和b都需要使用这组数据 # 原则:不管是a还是b调用完成之后不能对数据data产生变化 # 方案一:赋值(同一个对象 - -指向)(alist和blist指向同一内存单元(对象),blist改变会造成alist改变) a_list = [10, 20, [100, 200]] # 原数据a_list赋值一个出来 b_list = a_list # 然后a业务调用数据 b_list.append(30) print(b_list, a_list) # [10, 20, [100, 200], 30] [10, 20, [100, 200], 30] print(id(a_list), id(b_list)) # 1570674454976 1570674454976 # 使用id打印a_list和b_list的内存地址发现一样 # 方案1 pass:a业务调用这个b_list数据后会修改到a_list这 个数据的内容,无法满足需求 # 方案二:浅拷贝(简简单单拷贝一下,并不会拷贝内层对象) # 类似娶个二婚姑娘,姑娘有个小孩,拖家带口的(孩子是别人呢,内部还是连着别人的) import copy # copy 是一个模块 alist = [10, 20, [100, 200]] blist = copy.copy(alist) # 第一个copy是模块,后面的copy是模块的一个方法,
# 模块.方法(模块里面的函数)(调用这个模块里面的一个copy函数) blist.append(30) print(blist, alist) print(id(alist), id(blist)) # [10, 20, [100, 200], 30] [10, 20, [100, 200]] # 上面直接对外层列表操作没有问题,blist为[10, 20, [100, 200], 30] alist为[10, 20, [100, 200]] # blist改变没有影响alist,但是对列表里的子列表做修改浅拷贝不行:如下 # alist指向一个列表, blist指向一个列表.但是alist的子列表和blist的子列表都指向同一个对象:如[100, 200] blist[-2].append(30) print(alist, blist) # [10, 20, [100, 200, 30]] [10, 20, [100, 200, 30], 30] # 现在alist和blist都变了: a_list = [10, 20, [100, 200, 30]] b_list = [10, 20, [100, 200, 30], 30] # 因为a_list和b_list的子列表指向同一个对象的,子列表同一个地址 # 方案二paas不通过,修改blist这个列表的倒数第二个元素的时候会改动alist里面的数据 # 方案三:深拷贝(连根拔起,里外全部复制) deepcopy() import copy alist = [10, 20, [100, 200]] blist = copy.deepcopy(alist) # 不光外层的拷贝了,内部的子列表也会拷贝 alist[-1].append(300) print(alist, blist) # [10, 20, [100, 200, 300]] [10, 20, [100, 200]] # 每创建一个对象都会创建内存的空间的,根据需求合理使用拷贝,不要浪费资源 # 单层列表 - --浅拷贝 # 多层列表 - --深拷贝 # 同一个对象 - --赋值 # 代码每次运行,使用的内存都不一样(退出后会把里面的对象消除掉再运行再生成新的对象) # 只有方案三深拷贝通过
37:python中的文件操作
# open最简单的文件读取r模式,read模式 f = open('模特主妇护士班主任.txt', mode='r', encoding='utf8') # open返回一个f文件对象(句柄) content = f.read() print(content) # content返回的是字符串类型 f.close() # 关闭这个文件对象,不然一直占用内存
# 文件存储在硬盘上是以utf-8的0101储存的,所以encoding='utf8'打开 # python3当中的字符串编码方式是unicode,所以内部进行了一个转化 # 文件以utf8的格式存储到硬盘,也以utf8格式打开,但是读取出来的文字变成了unicode的str字符串 # 里面涉及到bytes类型转化成str现在到解码,我们没有操作,打开文件以bytes类型打开的 # 最后显示str,read里面自己进行了一个操作转化,open函数自己封装的,读取转化成str,便于读取
pycham下创建的所有文件默认都是utf8,设置就是utf8的编码方式 相对路径下pycham创建所有文件的编码方式都是utf8 绝对路径下自己D盘鼠标右键创建的文件是系统电脑默认编码方式 文件以什么编码方式存储的就要以什么编码方式打开(否则报错或者乱码) rb二进制打开,不用编码了,bytes类型,文件以什么010101方式存的以什么方式读出来 1:非文字类的文件打开,如图片等只能rb模式打开 2:上传和下载文件传的都是二进制,一般都是utf8,gbk的编码,unicode不能传--rb模式 3:打开图片,图片文件,写入全都是使用rb模式 f = open('模特主妇护士班主任.txt', mode='rb') # open返回一个f文件对象(句柄) content = f.read() print(content) f.close() # 关闭这个文件对象,不然一直占用内存 b'\xe4\xba\x8c\xe5\x93\xa5\xe9\x80\x80\xe5\xbd\xb9\xe4\xba\x86\xe3\x80\x82\xe3\x80\x82\xe3\x80\x82\xe3\x80\x82' # 打印bytes类型,rb打开不需要传入encoding编码参数
# 文件的写操作 只写 w+wb f = open('log', mode='w', encoding='utf8') # utf8写进去 f.write('李二狗') f.close() # w和wb模式:对于写操作,没有此文件就会创建文件,有就会覆盖以前文件写的内容 # 先把原文件内容删除,然后写入数据 f = open('log', mode='wb') # wb bytes类型写进去,write写入的数据要是bytes类型 f.write('傻逼玩意'.encode('utf8')) # 以utf8的encode写到文件,和文件默认什么编码要相同,不然打开乱码 f.close() # wb模式写入文件内容,需要看文件默认是什么编码方法,pycham上默认都是utf8的编码方式创建文件 # 使用gbk写应该就会异常,文件打不开或者乱码
# 文件的追加模式 a 和 ab 类似列表append追加 f = open('log', mode='a', encoding='utf8') # a str类型追加写 f.write('李二狗') f.close()
# 追加:w:源文件删除,顶头写 r:从头开始读,光标在最前面 a:追加,光标会移动到有文字的最后一位上 f = open('log', mode='ab') # ab bytes类型追加写 f.write('李二狗'.encode('utf8')) f.close()
# 文件的读写操作 r+和r+b都能读写 # 先读后写操作,先把原文字读出来,写的内容添加再最后 f = open('log', mode='r+', encoding='utf8') print(f.read()) f.write('李二狗') # 先读后写,写会写在文件最后面,因为读完了光标指向最后 print(f.read()) # 再读读取不出数据了,因为光标再最后面 f.close() # r+模式先写后读 f = open('log', mode='r+', encoding='utf8') f.write('zzz') # r+模式 写入的内容会从光标0从头开始写,但是不会删除源文件里的内容,从0开始覆盖写 print(f.read()) # 因为先写的,从写完后停留的光标+1开始读
# 文件 的写读操作 w+和w+b都能读写 f = open('log', mode='w+', encoding='utf8') # w+写读 f.write('aaaaaaaa') # w+ 只要有w都会先清除再写,其他的r和b都不会清除 f.seek(0) # seek调整光标到0的位置 print(f.read()) # 写完了在最后的光标,所以读取不到信息 f.close() '''文件的 a+和a+b追加读,二进制追加读''' f = open('log', mode='a+', encoding='utf8') f.write('李二狗') # a+ 追加模式 print(f.read()) # 追加后读取一般读取不到数据,追加会移动到最后
# open文件操作功能详解 f = open('log', mode='r+', encoding='utf8') res1 = f.read() # read默认读取文件里面全部内容,还可以设置读取多少字符 f.seek(0) res2 = f.read(2) # sd read设置读取多少个字符(不是字节)字符是能看到文字的最小单位 # read读出来的都是字符 f.seek(9) # seek 按照字节移动的,这里移动9个字节(utf8编码) # utf8编码中文三个字节,按照2个字节移动肯定报错,需要一定3倍数的字节 # 非3的倍数肯定会乱码或者报错---重点 # seek是按照字节值定光标移动位置,英文一个字节,中文三个字节--重点
# seek移动光标还可以传递模式参数
模式0:从开始位置计算,相对位置 打开模式可以是r
模式1:从当前位置开始计算,相对位置 打开模式一定是rb模式--bytes类型
模式2:从最后位置开始计算 打开模式一定是rb--bytes类型
print(f.tell()) # 输出当前光标的位置为:9 # tell告诉光标的位置,然后seek调整到这个位置,断点续传(需要知道光标在哪里) # 文件下载的时候,光标随着下载文件走的,时刻检测光标的位置 # 断了后监测光标的位置,再下载需要知道断的位置 # 然后把从头开始的光标调到断的位置继续往后下载 f.flush() # 强制保存,pycham自动带强制保存功能,写就保存 f.readable() # able可能,是否可读的判断文件是否可读,返回布尔值True和False f.readline() # 一行行读,读取第二行,三行,f.readline()读取一次后那么光标调整到第二行开始的位置 for i in range(2): res = f.readline() print(res) # f.readline()读取第一行,然后for循环2次读取第二行和第三行 print(f.readlines()) # readlins读取多行返回一个列表,
如果给定sizeint参数,返回总数大于sizeint字节的行,实际读取可能比sizeint大,所有需要填充缓存区 # ['aaaaaaaaaaa\n', 'bbbbbbbbbbbbb\n', 'ccccccccccccc\n', 'dddddddddddddd\n', 'eeeeeeeeeeeeee\n'] # 读取多行,返回一个列表,每一行当成列表中的一个元素,添加到列表中,支持循环打印 f.truncate(15) print(f.read()) # 输出:你是个傻逼 # 截取了15个字节,因为是utf-8编码,中文函数3个字节为一个字符,所有一共5个汉字 # truncate() 方法用于截断文件,如果指定了可选参数 size,则表示截断文件为 size 个字符 # 如果没有指定 size,则从当前位置起截断;截断之后 size 后面的所有字符被删除 f.name # 返回文件的名称log f.writable() # 是否可写,返回布尔值
f.close() # 关闭文件,open打开文件操作完成后一般都需要手动close关闭文件节省内存
file.nexi() # 返回文件下一行
file.write(str) # 将字符串写入文件
file.writeines(sequence) # 向文件写入一个有序字符串列表,如果需要换行需要自己加入每行的换行符
file.readinto() # 读取数据到一个可变缓冲区
file.fileno() # 返回一个整型的文件描述符(file descriptor FD 整型), 可以用在如os模块的read方法等一些底层操作上
file.isatty() # 如果文件连接到一个终端设备返回 True,否则返回 False
# f文件对象(句柄)还可以for循环 f = open('log', mode='r+', encoding='utf8') for line in f: # line循环句柄 print(line) # 循环打印每一行的内容,里面自带/n,换行符 # 读取文件,不要全部读取,因为不知道文件有多大,一行行读或者指定多少字符读取 # open 每次后面都需要有个close,使用with open打开文件,不需要写close,with上下文管理器会自动关闭close with open('log', mode='r+', encoding='utf8') as f: res = f.read() print(res) # 同时打开多个文件,一个with可以同时进行多次打开文件操作 with open('log', mode='r+', encoding='utf8') as f1: with open('log', mode='r+', encoding='utf8') as f2: pass with open('log', mode='r+', encoding='utf8') as f1, open('log', mode='r+', encoding='utf8') as f2: pass # 上面两种打开多个文件的方式都可行
# 使用文件进行注册,登录验证的小练习 # 先注册:注册的用户名密码写到文件,打印print注册成功,再登录:三次登录,用户名和密码读取出来验证登录 username = input('请输入您要注册的用户名>>>>') password = input('请输入您要注册的密码>>>>') with open('info_user', mode='w', encoding='utf8') as f: f.write(f'{username}\n{password}') # 用户名一行,密码一行各占一行 # write只能有一个参数,使用格式化 print('恭喜您,注册成功>>>>>>') list_info = [] with open('info_user', mode='r', encoding='utf8') as f1: for line in f1: list_info.append(line.strip()) i = 0 while i < 3: i = i + 1 username_in = input('请输入您的用户名>>>>>') password_in = input('请输入您的密码>>>>>') if username_in == list_info[0] and password_in == list_info[1]: print('恭喜您,登录成功') break else: print('请输入正确的用户名和密码')
# 修改文件(文件是不能修改的) # open是调用了系统命令,告诉操作系统打开一个文件,python不能直接操作文件的 # python透过操作系统操作文件的,操作系统是什么编码,open这里就默认什么编码 # 所有的windows操作系统默认都是gbk编码,python默认文件编码utf8,操作系统是gbk编码 with open('小护士班主任', encoding='utf-8') as f, open('小护士班主任.bak', mode='w', encoding='utf-8') as f2: for line in f: if '星儿' in line: # 班主任:星儿 line = line.replace('星儿', '啊娇') # 写文件 f2.write(line) # 小护士:金老板 # 把f1的文件内容拿出来修改后方法到f2(两个文件,文件备份) # 读取文件内容到内存,变成str数据类型,做一些处理,新的内容存储到新的文件里:两个文件 # 把原来文件删除掉,把现在文件重命名成原来的文件---修改操作 import os os.remove('小护士班主任') # 删除文件,需要用到os模块 os.rename('小护士班主任.bak', '小护士班主任') # 重命名文件需要用到os模块 # 上面操作看起来修改了文件一样,但是实际上是删除了旧文件,新文件命名成旧文件 ---修改文件的过程 # 所有的修改文件都这样做:读-修改-写-删一个-重命名
#使用print将字符串写进文件里
with open('./test.txt','wt') as f:
print('Hello World!',file=f)
# wt模式打开文件,会往text.txt文件里写入Hello World文本
38:函数基础
定义了函数里面所有的代码都暂时不执行,只是定义了,遇到调用函数才执行 函数名()就是一次调用 函数:代码装进盒子多次被调用,重复执行,便于维护 函数名和变量名一样的规则:字母数字下划线,不能使用关键字,不能数字开头等规则 def my_name(): 这就是完整的函数定义,内部代码随便写 my_name() 这就是函数的调用,必须带上括号 函数定义了之后,可以在任何需要它的地方调用 内置函数:python自带的 自定义函数:自己写的, return 定义函数的返回值, 找到内置函数,改源码
# 内置函数len 方法 s = '金老板小护士' print(len(s)) # 6
函数return返回值三种情况 1:没有返回值 1:不写return,默认return None 2:只写return也是return None 3:直接写return None 2:返回一个值 返回的这个值可以是任何数据类型:数字,字符串,列表,字典,元组 只要返回就可以接收到 如果在一个程序中有多个return,那么只执行第一个(第一个return函数接结束了,后面多少个return都没关系) 3:返回多个值 比如:return 1,2 返回多个值用多个变量接收:有多少返回值就用多少变量接收,不然报错(多了少了都不行) 用一个变量接收: 得到的是一个元组(元组是不可变的数据类型,不能修改一个函数的返回值) 本身多个返回值就是返回的一个元组:因为 a,b=(a,2),所以可以多个值接收多个返回值 函数中一旦执行了return,return后面的代码就不再继续执行了,return代表函数的结束 return可以用来结束一个函数,break结束一个循环
'''return来结束函数'''
def func():
l = ['金老板', '二哥']
for i in l:
print(i)
if i == '金老板':
return None
print('=' * 10)
res = func()
print(res)
'''return 多个参数
解释器输入1,2,3自动封装成元组(1,2,3)
所以return 1,2,3 ==return (1,2,3)
'''
def func2():
return 1, 2, 3 # return 1,2,3
'''元组,列表,字典支持解包的,python自带的解包机制'''
a, b, c = (1, 2, 3) # 元组解包
print(a, b, c) # 1 2 3
a, b, c = {1: "a", 2: "b", 3: "c"} # 字典解包,不常用
print(a, b, c) # 1 2 3
# 函数的参数:使外面的变量影响到内部函数的值,实参和形参数 ret = my_len([1,2,3,4,5]) # 传递参数:传参(调用过程中传递) def f2(l1): # 定义的地方叫接收参数 (执行定义参数的过程中才去执行的) def f2(l1): # l1形式参数 ret = my_len([1,2,3,4,5]) [1,2,3,4,5]实际参数(实参) 实参和形参 参数: 1:没有参数 定义函数和调用函数时候括号里面都是空的就行了 2:有一个参数 一个参数的情况下传什么参数就是什么,调用的时候只能传递一个参数 3:有多个参数 站在实参的角度上 按照位置参数 顺序接收ret=my_sum(1,2) 按照关键字传参 ret=my_sum(a=1,b=2) 关键字和位置传参混用也可以 但是必须先按照位置传参,再按照关键字传参数 不能给同一个变量传多个值, 站在形参的角度上(定义参数): def my_sum(a,b=1): 1:a是位置参数(必填参数) 位置参数必须传,有几个参数传几个值,多传少传参数都报错, 2:b是默认参数(非必填参数) 可以不传,如果不传就是用默认的参数,如果传了就用传的 # 函数的参数模拟代码 def my_len(s): # 自定义函数只需要0个参数,接收参数,形式参数,形参 i = 0 for k in s: i += 1 return i # 返回值 ret = my_len('金老板小护士') # 传递参数:传参,实际参数,实参 ret = my_len([1, 2, 3, 4, 5]) # 传递参数:传参 print(ret) # 函数的位置传参 ret=my_sum(1,2) def my_sum(a, b): # 接收两个参数 计算a和b和 return a + b ret = my_sum(1, 2) # 接收几个参数就传递几个参数,顺序传参 ,1传a ,2传b print(ret) # 函数的关键字传参 ret=my_sum(a=1,b=2) def my_sum(a,b): # 接收两个参数 计算a和b和 return a+b ret=my_sum(a=1,b=2) # 接收几个参数就传递几个参数,关键字传参数 ,1传a ,2传b print(ret) # 函数的关键字传递和顺序传参混合使用 ret = my_sum(1,b=2) def my_sum(a, b): print(a, b) res = a + b # result return res ret = my_sum(1, b=2) # 这样传参可以的,顺序传参需要放在前面,关键字传参放后面 # ret = my_sum(a=1,2) #不能这样使用,规定位置传参需要放在前面,关键字传参放后面 --报错 # ret = my_sum(2,a=1) # 不能这样使用,先位置传参2给了a,后面关键字传参1也给了a,这样a拥有两个值,b没有值--报错 print(ret) # 默认参数,非必填参数 def classmate(name,sex='男'): def classmate(name,sex='男'): print(f'{name}:{sex}') classmate("李二狗") classmate("小猛",'女') classmate("大猛") 调用函数的时候 1:按照位置传:直接写参数的值就行了 2:按照关键字传参:关键字=值 的形式 定义函数的时候: 1:位置参数(必填参数):直接定义参数 2:默认参数(关键字参数,非必填参数):参数名='默认的值 ' 3:动态参数(可变数量参数,关键字可变数量参数),可以接受任意多个参数 参数名之前加*,习惯参数名args,也可以是args外其他变量名, *不能变,必须带*才是动态参数 参数名之前加**,习惯参数名kwargs 4:动态参数有两种:可以接受任意个参数 *args : 接收的是按照位置传参的值,组织成一个元组 **kwargs: 接受的是按照关键字传参的值,组织成一个字典 args和kwargs放在一个函数里面,args必须在kwargs之前 函数调用的时候必须先传位置参数,再传关键字参数---传参符合规则 5:参数定义顺序:位置参数 > 动态参数(*args) > 默认参数 >动态参数(**kwargs) 如下: def fun(a,*args,b=1,**kwargs): print(a,args,b,kwargs) fun(1,2,3,4,b=10086,c=1,d=2,e=3) #1 (2, 3, 4) 10086 {'c': 1, 'd': 2, 'e': 3} # *args 动态参数(可变数量参数),有多少个参数都行 def my_sum(*args): # 计算多个值的和 *args # print(args) # (1, 2, 3, 4) args:把所有位置参数封装成了一个元组然后赋值给args sun = 0 for i in args: sun = sun + i return sun print(my_sum(1, 2, 3, 4)) # 10 def my_sum(*args): # 计算多个值的和 *args print(args) # (1, 2, 3, 4) args封装成了一个元组 my_sum() # () 不传也可以,默认为空元组 # **kwargs 动态参数(关键字可变数量参数) 按照关键字传参,也就是键=值 的模式传参 # *args 只能接收按照位置传递的参数如:my_sum(1,2,3,4) ,按照关键字传递的参数接收不了my_sum(a=1,b=2) # **kwargs 能够接受任意多个关键字形式传递的参数 def func(**kwargs): # 接受参数的使用定义 print(kwargs) func(a=1, b=2) # {'a': 1, 'b': 2} # 这里不能是传参数func(3=1,4=2) 这里参数必须是一个变量,必须符合一个变量的标准 # 前面的关键字变量必须数字,字母,或者下划线,且数字不能开头 d = {'a': 1, 'b': 2} # 定义一个字典d func(**d) # {'a': 1, 'b': 2} **d解包传参 # 动态参数的另一种传参方式:解包
# 传参方式一 直接传参:fun(1,2,3,4,5) def fun(*args): print(args) fun(1, 2, 3, 4, 5)
# 传参方式二 针对*args l=[1,2,3,4,5] fun(*l) l = [1, 2, 3, 4, 5] print(*l) # 1 2 3 4 5 def fun(*args): # 站在形参的角度上,给变量加上* 就是组合所有传来的值---这里是组合的作用 print(args) fun(l[0], l[1], l[2], l[3], l[4]) # (1, 2, 3, 4, 5) fun(*l) # (1, 2, 3, 4, 5) fun(l[0], l[1], l[2], l[3], l[4]) == fun(*l) # *l 解包,把l列表分解成一个个元素中,站在实参的角度上,给一个序列加上*就是将这个序列按照顺序打散--这里是打散的作用 # 传参方式三 针对**kwargs def func(**kwargs): print(kwargs) # func(a=1,b=2,c=3) #{'a': 1, 'b': 2, 'c': 3} dict_a = {'a': 1, 'b': 2} # 定义一个字典 func(**dict_a) # {'a': 1, 'b': 2} # print(**dict_a) # 报错,只能在func(**dict_a) 函数调用的时候使用解字典 print(*dict_a) # a b # * 配合的是args(解列表和元组) *打散一个序列 # ** 配合的是kwargs(解字典) **打散一个字典,字典的内容按照关键字方式传过来
# 函数的注释 函数是一段代码,函数+注释,加在函数定义的一开始 def fun(): ''' 这个函数实现了什么功能 参数1:作用+数据类型 参数2:作用+数据类型 :return: 返回值是什么(数字,字符串,列表长度) ''' pass # 函数和函数之间的代码不会互相影响的,函数f1和f2,f2先定义调用f1,再定义f1没问题 # 但是函数必须先定义,后调用,不然报错
def f(a):
return '栗子' # 内存(10101100内存地址)上存储'栗子',返回的'栗子' 的内存地址
sum() 方法对序列进行求和计算。
sum(iterable[, start])
iterable -- 可迭代对象,如:列表、元组、集合。
start -- 指定相加的参数,如果没有设置这个值,默认为0。
>>>sum([0,1,2])
3
>>> sum((2, 3, 4), 1) # 元组计算总和后再加 1
10
>>> sum([0,1,2,3,4], 2) # 列表计算总和后再加 2
12
# 函数默认参数的陷阱 def qqxing(l = []): # l = []默认参数列表,可变数据类型 l.append(1) print(l) qqxing() # [1] qqxing([]) # [1] qqxing() # [1,1] qqxing() # [1,1,1] # 如果默认参数的值是一个可变数据类型, # 那么每一次调用函数的时候,如果不传值就公用这个数据类型的资源 ---每一次调用都使用l默认的这个列表
38:函数进阶
# 简单的函数使用全局变量 a = 1 def func(): print(a) # 这里func这个函数使用全局变量a func()
函数的命名空间和作用域 命名空间 有三种 函数的调用必须先加载到内存里面 内置命名空间 —— python解释器 就是python解释器一启动就可以使用的名字存储在内置命名空间中 内置的名字在启动解释器的时候被加载进内存里 python解释器启动就在内存里先开个大空间,开始往内存里面放一些名字到内置命名空如print等 内置名字空间里面程序启动就可以使用这里面的变量 读第一行代码之前前面有一系列的动作,代码中的名字丢到内置命名空间里, print() len(),input,list,tuple python解释器一运行就会加载到内存,可以直接拿来使用 ---内置命名空间 全局命名空间 —— 我们写的代码但不是函数中的代码 是在程序从上到下被执行的过程中依次加载进内存的 放置了我们设置的所有变量名和函数名 局部命名空间 —— 函数 就是函数内部定义的变量和函数里面的函数 当调用函数的时候 才会产生这个名称空间 随着函数执行的结束 这个命名空间就又消失了 在局部:可以使用全局、内置命名空间中的名字 在全局:可以使用内置命名空间中的名字,但是不能用局部中使用 func函数执行开始的时候内存创建变量a=1,函数执行完后变量a消失在内存了,所以全局用不到 在内置:不能使用局部和全局的名字的(内置名字空间解释器启动内置名字读取进来,这时候程序 函数都没有运行,不会依赖局部和全局的变量)
当我们在全局定义了和内置名字空间中同名的名字时,调用的时候会使用全局的名字
在正常情况下没有定义内置名字空间中同名的名字时,直接使用内置的名字
变量当我自己命名空间(作用域)有的时候 我就不找我的上级要了,不会找自己下一级的(局部作用域的)
如果自己命名空间找不到使用的变量 就找上一级要 上一级没有再找上一级 如果内置的名字空间都没有 就报错
多个函数应该拥有多个独立的局部名字空间,不互相共享
# 1:在全局定义了和内置名字空间中同名的名字时,调用的时候会使用全局的名字 # print(a) print是内置命名空间的名字 def input(): print(1) input() # 2:func函数局部作用域调用全局作用域里的input变量,找到了就不会找内置作用域的input了 自己作用域找不到就找上一级要,上一级没有再找上一级,找到内置命名空间还找不到就报错 这就是命名空间找名字的顺序,查找顺序 局部命名空间(自己这层先找) > 全局命名空间 >内置命名空间 >内置还找不到就报错了 def input(): print('in input now') def func(): input() func() # 3:函数名字+() 就是函数的调用
func()原理:通过func变量找到函数的地址,调用地址里面的代码 a=1 1这个对象就在内存里面存储且有内存地址 def 函数() 就在内存里面存储函数,且函数名func指向这个函数的内存地址 函数调用的时候能执行也是因为函数存储在内存里了 func() 表示函数执行 func 函数名指向的是这个函数所在的内存地址 函数的内存地址+() ==函数的调用,----可以这么理解 函数名func 就是指向这个函数的内存地址 id(func) 打印func指向的函数的内存地址 print(func) 这个也是标识func函数的内存地址,打印的十六进制的 def input(): print('in input now') def func(): # input = 1 print(input) # <function input at 0x00000241FF4F2730> 打印input函数的物理地址。十六进制 func() # 每一个函数都拥有它自己的命名空间,如果多个函数就有多个局部命名空间, 全局名字空间就一个,内置名字空间也就一个,只有局部名字空间有多个 但是多个局部名字空间之间不互相共享的,是隔离开的 ---只能自己用自己的,或者往上层找 def func1(): a=1 def func2(): print(a) # 报错
# 作用域:和名字空间分不开 作用域两种 全局作用域 —— 作用在全局(整个代码) —— 内置和全局名字空间中的名字都属于全局作用域 ——globals() 局部作用域 —— 作用在局部 —— 函数(局部名字空间中的名字属于局部作用域) ——locals() # global 关键字 global 声明一个变量,这个变量它的操作就在全局有效了, 自己写的代码避免使用global,很危险,可能被调用者修改,代码极不安全 对于不可变数据类型,在局部可以查看全局作用域中的变量,但是不能直接修改全局作用域的变量 如果想要修改需要在程序的一开始添加global 声明 如果在一个局部(函数)内声明了一个global变量,那么这个变量在局部的所有操作将对全局的变量有效 a = 1 # a是全局作用域,可以在全局都使用 def func(): global a # 在局部声明了一个global变量的话那么这个变量在局部的所有操作将会影响全局 a += 1 func() print(a) # 2 ,全局变量a被修改了 # locals() 查看局部名字空间里的所有名字 globals() 查看全局名字空间里的和内置名字空间的关键字 globals 永远打印全局的名字 locals 输出什么 根据locals所在的位置 locals放在全局,全局就是本地,打印全局命名空间 locals放在局部,局部就是本地,打印局部命名空间 a = 1 b = 2 def func(): x = 'aaa' y = 'bbb' print(locals()) #{'y': 'bbb', 'x': 'aaa'}打印举报(因为locals放在局部) print(globals()) # 打印全局 # func() print(globals()) # 打印全局 print(locals()) # 打印全局(因为locals放在全局) # 写的代码避免使用global,很危险,可能被调用者修改,代码极不安全,通过传参和接收返回值这样来最安全 接收参数和返回值来完成原本需要global才能完成的操作, a = 1 def func(a): # 传参 a = 2 return a a = func(a) # a被修改了,接收返回值,这里传递的参数a能被修改且 print(a) # 输出2 ,因为a被重新赋值了 a = 1 def func(a): # a的值传参给函数a变量接收,函数内部的a变量+=2,程序执行后函数局部的a消失 a += 2 print(a) # 输出:1 a没有被func给改变
a = 1 def func(a): global a a += 2 print(a) # 这样写报错:意思是你的func(a)在定义a的时候,明明a就是一个局部变量:
(这里func(a)直接把a参数定义进去了,那么a参数就是函数func的一个局部变量,无法把a定义成全局) # 然后又在它的内部又重新global a定义a是一个全局变量,这个时候python就无法判断在接下来该怎么处理a这个变量了. # 程序上层模块应该依赖底层(下层)模块,不能反向依赖 # import this 打开python之禅
# 函数的嵌套和作用域链 # 1:函数的嵌套调用:一个函数的函数体内调用另外一个函数(调用的是全局的还是内置的名字空间的函数都是嵌套调用)函数的复用 def max(a, b): return a if a > b else b # 求最大值 def the_max(x, y, z): # 求三个值之间的最大值 函数的嵌套调用(函数的复用,函数的调用) c = max(x, y) return max(c, z) print(the_max(1, 2, 3)) # 2:函数的嵌套定义:内部函数可以使用外部函数的变量 # case 1 def out(): def inner(): print('inner') out() # 1:定义out,out名字放到内存空间
# 2:out(),调用out,顺序执行out里面的代码 # 3:def inner():定义一个inner inner放在内存空间(inner没有调用这里没有任何反应的 # inner在out函数内部的局部命名空间里的,没有调用,局部命名空间随着函数的的运行结束而被内存销毁 ) # case2 局部命名空间自己调用inner函数 def out(): def inner(): print('inner') inner() out() # 1:定义out,out名字放到内存空间
# 2:out(),调用out,顺序执行out里面的代码 # 3:def inner():定义一个inner inner放在内存空间 # 4:inner() 调用inner # 5:执行inner里面的代码print('inner') 这就是函数嵌套定义的执行流程 # 一个局部包含这另外一个局部,自己没有往上找,小范围的可以使用大范围的变量 函数的嵌套定义,内部函数可以使用外部函数的变量 所有的函数必须先定义后调用,inner2在inner里面定义也只能在inner里面内调用,外面找不到
# nonlocal和global的使用和区别 内层函数当中对外层的变量进行一个修改:使用nonlocal和global nonlocal 只能用于局部变量 找上层中离当前函数最近一层的局部变量 声明了nonlocal的内部函数的变量修改会影响到 离当前函数最近一层的局部变量 nonlocal对全局无效 nonlocal对局部 也只是对 最近的 一层 有影响(找到最近的一层影响到了就ok,不会继续再找了) a = 1 # 全局变量 a=1 def outer(): a = 1 # 局部变量a=1 def inner(): a = 2 # 小局部变量a=2 def inner2(): nonlocal a # 声明了一个上面第一层局部变量(声明了上层的局部变量,往上一层层找,找到上层inner函数的a=2,然后把这个a最累加重新赋值a=3) a += 1 # 不可变数据类型的修改,内部函数只能调用外部函数变量的使用,但是不能修改(如果想要修改需要加nonlocal或者global) inner2() print('##a## : ', a) # 输出a的值为3,因为inner空间的a被inner2里面调用并且修改了(nonlocal只能修改长一层局部) inner() print('**a** : ',a) # a输出1(inner2里面的nonlocal只能修改上一层inner局部空间里的a无法修改out和全局空间的a) outer() print('全局 :',a) # a输出1,道理同上
# global在任何一个局部, global声明一个a,只和全局有关系,局部变量不受global控制的 # nonlocal a声明一个变量,只能找局部变量,找离他最近的局部空间的变量 # 代码排错从下往上找:通常出问题的是最底下这行,而不是最上面的行,找最下面的就是我们自己写的代码出问题的地方 def outer(): a=1 def inner(): b=2 print(a) print('inner') def inner2(): global a # global声明了一个全局变量 a a+=1 # 对全局变量的a进行累加 但是全局空间没用定义a这个变量,只有局部变量a----所以运行到这里会报错 print('inner2') inner2() inner() outer()
# 例子二 a = 0 def outer(): # a = 1 def inner(): # a = 2 def inner2(): nonlocal a # 注释inner和outer两个空间里的a这里也会报错,因为nonlocal只会找最近的局部的空间,不会找到全局空间里的a来调用 print(a) inner2() inner() outer()
# 函数的高级用法: 1:计算机当中所有的变量都是内存地址, 2:函数名可以赋值,func2也指向函数的内存地址 3:函数名可以作为容器类型的元素,比如[函数名] 4:函数名可以作为函数的返回值 5:函数名可以作为函数的参数 由于函数名可以赋值,函数名可以作为函数的返回值,函数名可以作为函数的参数三个特点 得出函数是第一类对象, 1:可在运行期创建 2:可用作函数参数或者返回值 3:可以存入变量的实体,(作为容器类型的元素,可以做变量的赋值) 有1,2,3的规律的就是第一类对象,函数名就是第一类对象 函数名当成普通的变量使用就行,但是函数名和普通变量的区别在于 普通 变量() 报错,而 函数名()代表函数的调用(函数名指向的内存地址的代码的调用) def func(): print(123) # func() # 函数名就是函数内存地址 func2 = func # 函数名可以赋值,func2也指向函数的内存地址 func2() # func2()==func() l = [func,func2] # 函数名可以作为容器类型(列表,元组,字典都是容器类型)的元素 print(l) for i in l: i() def func(): print(123) def wahaha(f): f() return f # 函数名可以作为函数的返回值 qqxing = wahaha(func) # 函数名可以作为函数的参数,func是函数的内存地址,内存地址传给f # qqxing现在指代f函数的内存地址 qqxing指向f的内存地址 # func和f和qqxing三个都指向func指向变量的内存地址 qqxing() # 等同调用func函数
# 函数的闭包 # 1:闭包的定义:闭包一般是嵌套函数,内部函数调用外部函数的变量,这个变量不能是全局作用域,只能是局部作用域 # 下面inner内部函数就是闭包 def outer(): a = 1 # 如果函数内部没有定义a而是最外面全局作用域有个a ----那么不是闭包 def inner(): # inner是一个闭包,调用上层outer函数局部的a变量,这个a变量还不是属于全局空间 print(a) # 如果不使用a变量就不是闭包,只是嵌套函数而已 inner() outer() # 2:__closure__ 方式展示函数属性是不是闭包 def outer(): a = 1 def inner(): print(a) print(inner.__closure__) #(<cell at 0x000001ADA2B75468: int object at 0x0000000064816C20>,) outer() print(outer.__closure__) # 输出:None 输出为None的话说明outer函数不是闭包 # 上面输出的:(<cell at 0x000001ADA2B75468: int object at 0x0000000064816C20>,) # int object at指的是a = 1 # cell说的就是闭包函数inner ,打印函数的__closure__有打印cell...说明该函数就是一个闭包 # 3:有了闭包,内部函数可以引用外部函数的变量了 # case1:函数嵌套,outer里面直接调用inner函数---inner() case1不是常用的应用闭包的形式 def outer(): a = 1 def inner(): print(a) inner() outer() # 这种写法想要调用inner只能通过outer调用,如果频繁的调用outer,那么outer里面的所有 # 变量都会频繁的生成消失,生成消失在内存里,因为每一次调用outer都要生成 # 每次outer函数运行结束都消失了 ---创建变量,销毁变量耗费时间和内存 # 所有不直接在outer里面inner()直接调用,
# 如下case2写法:函数名当作返回值返回,高级语法 # case2:场景的应用闭包的形式是return被嵌套的inner函数的函数名 ---这是闭包的常用形式 def outer(): a = 1 def inner(): print(a) return inner # 内部场景函数inner,把函数名以返回值的形式返回outer()执行的位置 f=outer() # 变量f接收outer函数的返回值inner函数的地址 ,f变量指向函数inner的内存地址 f() # 函数的调用:可以在函数的外部使用函数内部定义的函数 ---case2是闭包最常用的形式 # 每一次调用outer都会生成新的命名空间,在命名空间创建a和inner,随着return inner结束消失了 # 如果return inner把inner函数当作内存地址传到外面,且在inner函数里调用到外面函数的变量 # 那么这个变量a会永远保存在内存里不会消失,只要程序没结束,后面有对于f函数的引用,那么 # 这个a变量和inner就永远不会消失,这个a变量只有在使用inner时候才有效,不使用inner时候a变量在内存里存着 # return inner ,inner函数的内存地址返回回去,被f接收,f是全局变量,全局变量指向内部函数地址 # f全局所以随时f()可以执行的 ,inner函数里用到a了,a是上一层函数的 # 但是必须永远用着,所以这个a = 1这个a变量不会随着outer函数的结束而消失 # 因为inner后面可能要用到,才会不消失 使用闭包的好处是:
1:保护了a变量,这个变量不是全局的,不能全局角度随意使用变量a和修改变量a 2:inner函数想使用a变量的时候可以随意使用 ----延长a变量的生存周期,让a节省很多在内存里重复的创建和删除的时间 ---代码性能更好 # 闭包的应用场景一: urllib # import urllib # urllib是一个python自带的url请求的模块(python文件实现特定的功能) # case1:普通url请求代码代码 from urllib.request import urlopen # urlopen可以打开一个网页 def get_url(): url='https://www.tupianzj.com/meinv/mm/pxmnt/' reps=urlopen(url).read() print(reps.decode('gbk')) get_url()
# 每一次调用get_url()
都会在内存中生成reps=urlopen('https://www.tupianzj.com/meinv/mm/pxmnt/').read()
都去urlopen请求,每一次都要在内存里生成url,然后去打开
# case2 :闭包实现url请求代码 闭包可以节省资源 from urllib.request import urlopen def get_url(): url='https://www.tupianzj.com/meinv/mm/pxmnt/' a=1 def inner(): nonlocal a a+=1 reps=urlopen(url).read() # print(reps.decode('gbk')) return reps.decode('gbk'),a return inner f=get_url() resp=f() resp1=f() resp2=f() resp3=f() print(resp3)
# 上面一直f()调用inner函数,闭包函数inner一直使用get_url函数局部空间里的url和a变量,a一直累加4次,后面等于5了
说明没有频繁销毁和创建url和a变量
------ def outer(): a = 1 def inner(): nonlocal a a = a + 1 return a return inner f = outer() f() f() res = f() print(res)
# 输出:4 outer调用一次就创建一次命名空间,outer函数调用返回f,
f指向outer函数内部的inner函数的内置地址,无限制的调用f函数等同调用inner函数 ------ # 内存空间的变量,变量一直存在 def outer(): a = 1 def inner(): nonlocal a a=a+1 return a return inner f=outer() res=f() res=f() res=f() print(res) # 输出:4 f=outer() res=f() print(res) # 输出:2 # outer每一次调用都会重新创建一次命名空间
------ def outer(): a = 1 def inner(): nonlocal a a = a + 1 return a return inner f = outer() res = f() res = f() res = f() print(res) # 4 s = outer() res1 = s() print(res1) # 2 res = f() res = f() res = f() print(res) # 7 # f=outer()创建一个内部命名空间和s=outer()创建一个内部命名空间相互独立,空间里的变量互不影响
# 函数的重要知识点 # 1:函数的作用域链 小范围用变量的时候,先从自己的名字空间找, 找不到就一层一层向外层找,知道找到为止。 找不到就报错。 # 2:函数名的本质 就是一串内存地址 可以赋值、可以作为容器类型的元素、函数的参数和返回值 —— 第一类对象 # 3:三种名称空间:内置 全局 局部 # 4:作用域:全局 局部 globals() locals() global 在局部声明一个全局变量 nonlocal 在局部声明最近的上一层局部中的变量 # 5:函数的嵌套调用和嵌套定义 定义在函数内部的函数不能被外界直接调用 内部函数可以使用外部的变量 # 6: 闭包 : 内部函数使用外部函数的变量,这个变量不属于全局作用域的变量
# 查看函数名字和函数的注释(返回的是字符串类型) def wahaha(): ''' 一个打印娃哈哈的函数 :return: ''' print('娃哈哈') print(wahaha.__name__) # 查看字符串格式的函数名 wahaha print(wahaha.__doc__) # document打印查看函数的注释文档
39:简单练习
# 2、写函数,检查获取传入列表或元组对象的所有奇数位索引对应的元素,并将其作为新列表返回给调用者 def func(l): return l[1::2] # 步长切片获取奇数索引 print(func([1, 2, 3, 4, 5])) # 3、写函数,判断用户传入的值(字符串、列表、元组)长度是否大于5 def func(x): return len(x) > 5 # len(x)>5 本身是一个布尔表达式,返回True和False if func('abcd'): print('长度确实大于5') # 4、写函数,检查传入列表的长度,如果大于2,那么仅保留前两个长度的内容,并将新内容返回给调用者 def func(l): return l[:2] print(func([1,2,3,4])) print([1][:5]) #[1] 切片,切的长度不够,不会报错,返回原列表 # 5、写函数,计算传入字符串中【数字】、【字母】、【空格】 以及 【其他】的个数,并返回结果 def func(s): # 'skghfoiw8qpeuqkd' dic = {'num': 0, 'alpha': 0, 'space': 0, 'other': 0} for i in s: if i.isdigit(): dic['num'] += 1 elif i.isalpha(): dic['alpha'] += 1 elif i.isspace(): dic['space'] += 1 else: dic['other'] += 1 return dic print(func('+0-0skahe817jashf wet1')) # 6、写函数,检查用户传入的对象(字符串、列表、元组)的每一个元素是否含有空内容,并返回结果 def func(x): if type(x) is str and x: # 参数是字符串,and x x可能本身是空字符串'' for i in x: if i == ' ': return True elif x and type(x) is list or type(x) is tuple: # 参数是列表或者元组还不为空--循环 for i in x: if not i: # 如果i是空返回True return True elif not x: # 如果本身是空的字符串''或者空列表[]走elif return True print(func([])) # 对于字符串来讲空格就是空内容,对于列表和元组来说判断元素是否为空[1,2,3,'',(),[]] # 7、写函数,检查传入字典的每一个value的长度,如果大于2,那么仅保留前两个长度的内容,并将新内容返回给调用者 # 长度小于等于2不做任何操作返回给调用者 # dic = {"k1": "v1v1", "k2": [11,22,33,44]} # PS:字典中的value只能是字符串或列表 def func(dic): for k in dic: if len(dic[k]) > 2: dic[k] = dic[k][:2] return dic dic = {"k1": "v1v1", "k2": [11,22,33,44]} print(func(dic)) # 8、写函数,接收两个数字参数,返回比较大的那个数字 # 写法一 def func(a, b): if a > b: return a else: return b print(func(1, 5)) # 写法二:三元运算 def func(a, b): return a if a > b else b print(func(5, 1)) # 9、写函数,用户传入修改的文件名,与要修改的内容 # 执行函数,完成整个文件的批量修改操作(进阶)。 def func(filename, old, new): with open(filename, encoding='utf-8') as f, open('%s.bak' % filename, 'w', encoding='utf-8') as f2: for line in f: if old in line: # 班主任:星儿 line = line.replace(old, new) # 写文件 f2.write(line) # 小护士:金老板 import os os.remove(filename) # 删除文件 os.rename('%s.bak' % filename, filename) # 重命名文件
40:三元运算 简单if判断可以使用
a = 1 b = 5 # a if a>b else b if成立返回a,if不成立else返回b c = a if a > b else b # 三元运算 print(c) # 变量 = 条件返回True的结果 if 条件 else 条件返回False的结果 #牛逼的写法 # 必须要有结果(a或者b) # 必须要有if和else # 只能是简单的情况
41:简单练习
# 2、写函数,接收n个数字,求这些参数数字的和 # case1 def get_sum(*args): i = 0 for j in args: i += j return i print(get_sum(1, 2, 3)) # 6 # case2 def get_sum(*args): return sum(args) print(get_sum(1, 2, 3)) # 6 # 3、读代码,回答:代码中,打印出来的值a,b,c分别是什么?为什么? a = 10 b = 20 def test5(a, b): print(a, b) # 打印20 ,10 函数没有返回值None c = test5(b, a) # 这行代码分解成两步 1:执行test5函数里面得代码 2:test5执行结果赋值给c(函数执行完再赋值) print(c) # 4、读代码,回答:代码中,打印出来的值a,b,c分别是什么?为什么? a = 10 b = 20 def test5(a, b): a = 3 b = 5 print(a, b) # 局部作用域调用变量a和b,自己作用域找得到就用自己的,找不到向外扩散找 c = test5(b, a) print(c) ''' 运行结果: 3 5 None '''

 浙公网安备 33010602011771号
浙公网安备 33010602011771号