jmeter工具快速使用
1:jmeter官网:https://jmeter.apache.org
运行jmeter需要基于java环境,jmeter可以在windows,mac和linux下运行,代码通用化 jmeter用来负载测试,用于性能测试的 性能测试-从功能测试而来,软件测试功能最核心,性能和自动化+接口都在后面,功能测试是一切测试的基础 性能测试核心:业务场景,性能测试核心,哪些场景可能会有性能问题,
2:一款软件测试顺序
功能测试1(接口测试)-性能测试N(接口)-自动化测试(接口)
接口测试通常在功能+性能+自动化里面都会涉及到,接口测试分布在各个点,有功能接口,性能接口,有自动化
功能测试:软件能不能工作的问题
性能测试:一群用户使用软件能不能正常工作的问题
自动化测试:把功能+性能做的工作用软件程序工具完成(软件比较稳定的时候开展,价值是下一次版本发布变化比较少的部分可以自动化回归)
所以功能测试对应的是1(一个用户),性能测试对应的是N(大部分大量的用户登录操作的问题)
SOAP/REST:SOAPUI+POSTMAN(这两工具也可以搞性能)
jmeter主要可以做web服务和接口的性能
3:性能测试的核心
jmeter主要工作在协议层 性能测试核心:在协议分析,jmeter主要工作在协议层,jmeter模拟浏览器动作,用的是HTTP和HTTPS协议测试web,
绕过浏览器直接和远端服务器进行连接发送消息,jmeter不调用(打开)浏览器,直接调用协议模拟浏览器 调用浏览器:程序-进程,浏览器是进程 http协议:用的是线程,线程的开销比进程低很多 jmeter:jmeter是用线程来做的,一个jmeter软件运行的时候开启一个jmeter进程,
java虚拟机环境一个进程,然后启动很多http请求的线程向远端服务器发请求来节省资源
(这就是jemeter快速的原因:打开200个浏览器开启两百个进程电脑卡死,但是jmeter java虚拟机里面的一个进程,
启动占用一个进程空间,然后进程空间里调用多个线程发送http请求,
jtemer给网站发送请求是创建一个sample元件,消息协议请求,就是线程,多个线程组)
浏览器打开网页执行html+JavaScript+css各种脚本,jmeter只发送请求,然后服务器把html文档返回来就结束了,不会执行JavaScript来消耗时间
所以jmeter比浏览器响应和反应时间更快
jmeter能不能测试app:
看app走的协议是不是jmeter所支持的,全部的端比如app,web等都是一个外壳,内部都是协议和服务端通信
性能测试核心点:在服务端,在后端
jmeter是模拟所支持的协议往系统的后端发送大流量,模拟流量往后台发送,前端是啥都不重要,重要是jmeter能不能模拟你当前的通信协议
jmeter只关注协议,绕开程序的客户端,构造负载直达服务器,验证服务器的处理能力
工具本质:模拟成千上万的浏览器去访问服务器
jmeter支持的协议
能够加载和性能测试许多不同的应用程序/服务器/协议类型:
网络 - HTTP、HTTPS(Java、NodeJS、PHP、ASP.NET,...)
SOAP/REST 网络服务
FTP
通过 JDBC 数据库
LDAP
通过 JMS 的面向消息的中间件 (MOM)
邮件 - SMTP(S)、POP3(S) 和 IMAP(S)
本机命令或 shell 脚本
TCP
Java 对象
分布式:客户端和服务器是分开的
4:jmeter下载安装:https://jmeter.apache.org/download_jmeter.cgi

下载一个二进制的版本,tgz一般放在linux里面做解压,zip可以直接下载到windows解压
zip文件解压后生成一个文件夹,解压后的目录解构如下
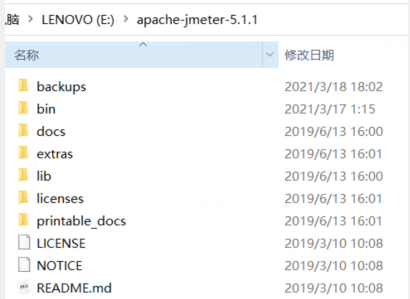
bin目录下是jmeter的一些应用程序,双击就可以运行的各种小工具,电脑安装了java可以看到ApacheJMeter.jar双击可以运行启动jmeter如下:
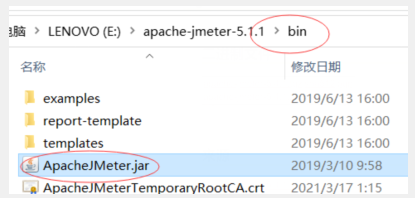
如果安装了java环境但是双击这个ApacheJMeter.jar还是报错,注意jtemer需要依赖的jdk版本是不是一致
5:jmeter"测试计划" 所有的测试工作都是组织在这个计划里面的(组织工作)
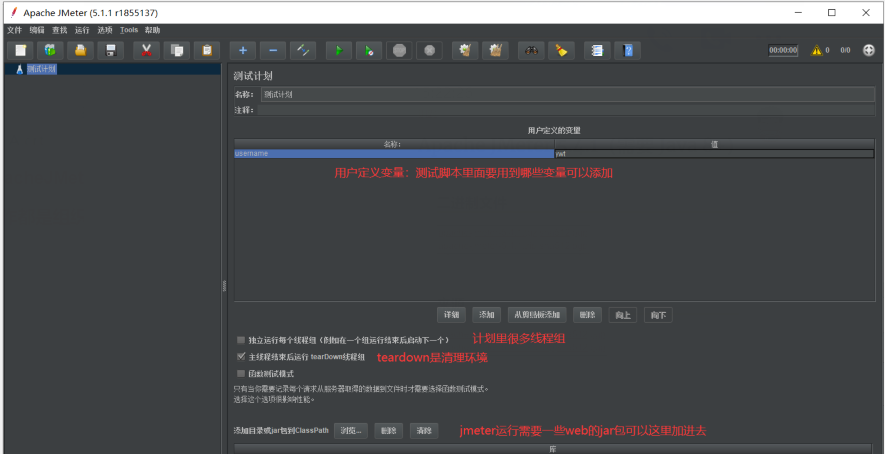
测试计划的配置很简单
名称:专信BQY项目性能测试
注释:随便写不写
用户定义的变量:变量所有的人都需要用到的可以写这里
都填写好了点击"保存测试计划"如下:
6:线程组(测试计划搞好了后创建线程组:类似雇佣一个人,一个用户)
使用jmeter四步骤:
人物:线程组,user
事情:协议:操作
结果:jmeter里面的结果元件,对应用户里面的响应
验收:断言 对用户来说判断结果是否正确
多少人指的就是线程组数:
选择一个测试计划右击鼠标,点击添加——>线程(用户)——>线程组
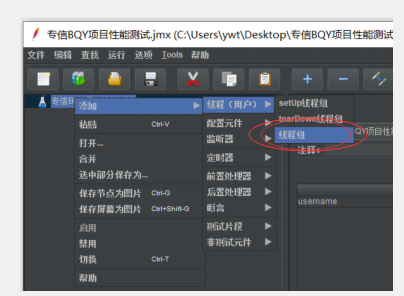
配置线程组:
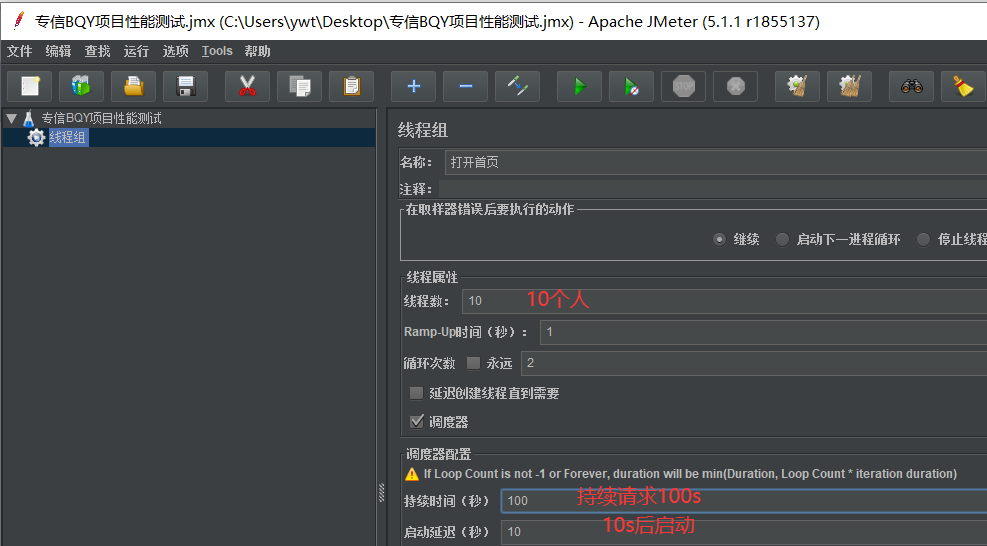
人数:10个人(10个线程组)
线程组里面创建事务(创建http请求)
事务:往BQY官网发请求,使用的是http协议(线程组(打开首页)里面右击鼠标——>添加——>取样器(sampler))——>找到对应的协议(这里选择http请求)
注意一:填写服务器名称或ip时候前面不需要添加https://,比如一个网址https://console.bqy.com/login只需要填写console.bqy.com/login就行,jmeter会自动添加https://
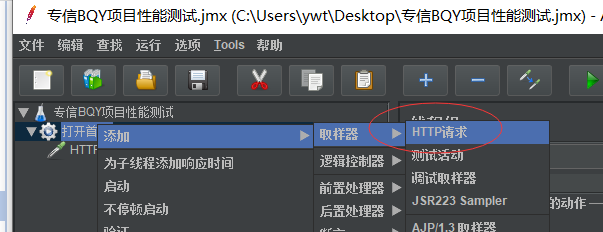
创建事务后填写这个事务(http请求)的基本信息:如基础配置里的:名称,服务器名称或者ip,方法,路径 高级配置里的:连接超时时间,响应超时时间

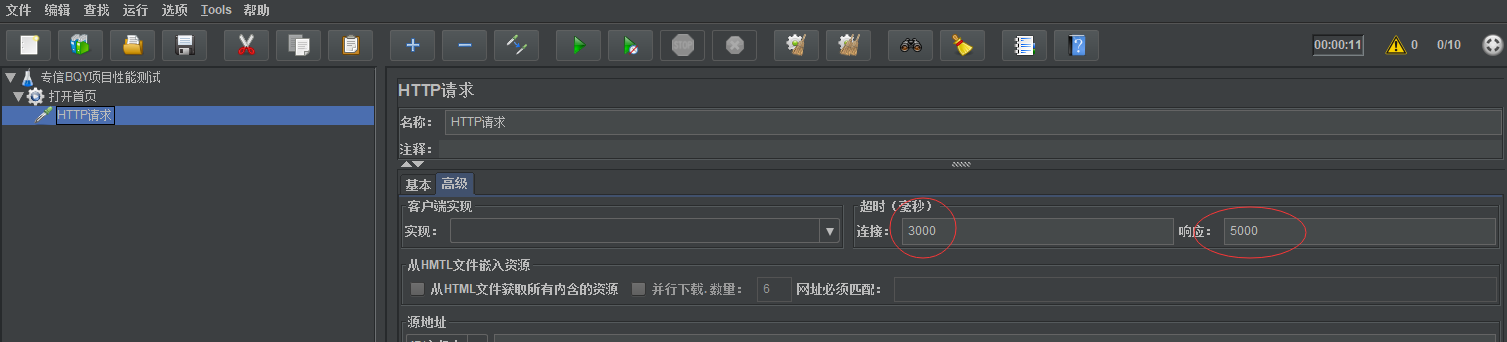
超时时间注意单位是ms,设置3秒的话需要设置成3000
创建监听器:上面对线程组(人数指定了事情了,完成了一个请求,需要查看结果),现在还需要指定一个结果
线程组(右击鼠标)——>添加——>监听器——>(http请求一般使用查看结果树比较好,发出的请求和响应都有)
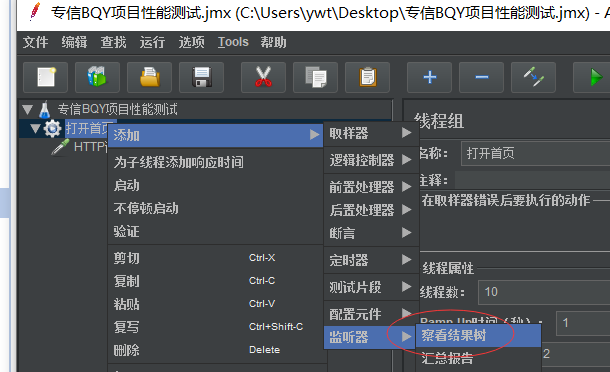
然后点击上面一排的绿色执行箭头运行脚本,查看结果树,绿色表示成功
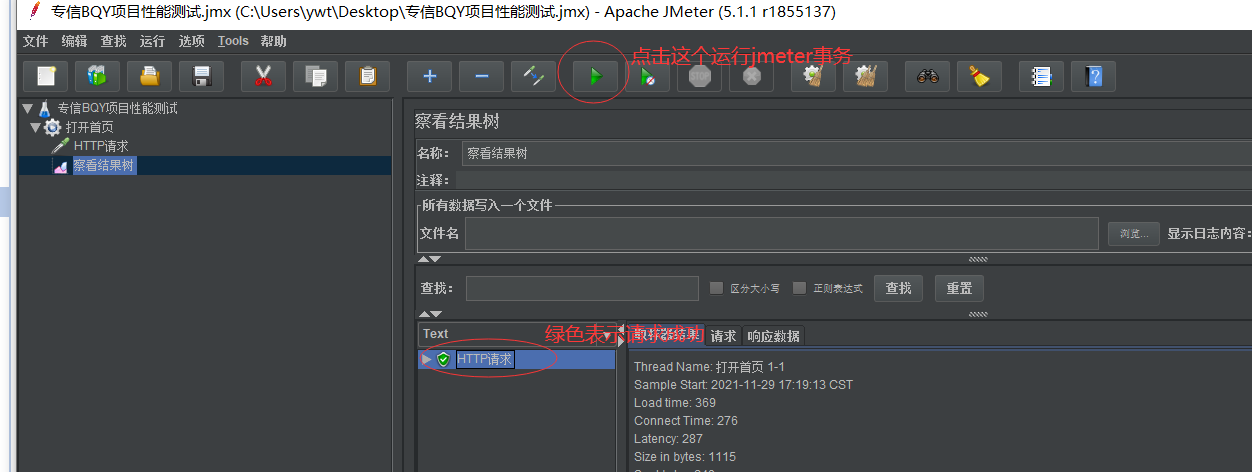
这里获取到BQY首页的登录页面
创建断言:创建断言来判定返回的结果是不是正确
线程组(右击鼠标)——>添加——>断言——>对应http来说一般使用(响应断言)
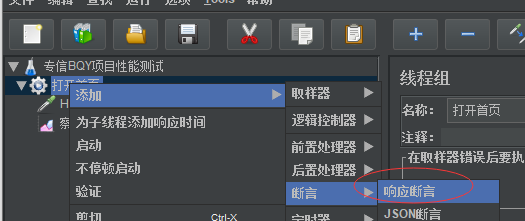
设置断言名称
apply to:响应检测谁的,一般检测main sample and sub sample(检测主线程和子线程)
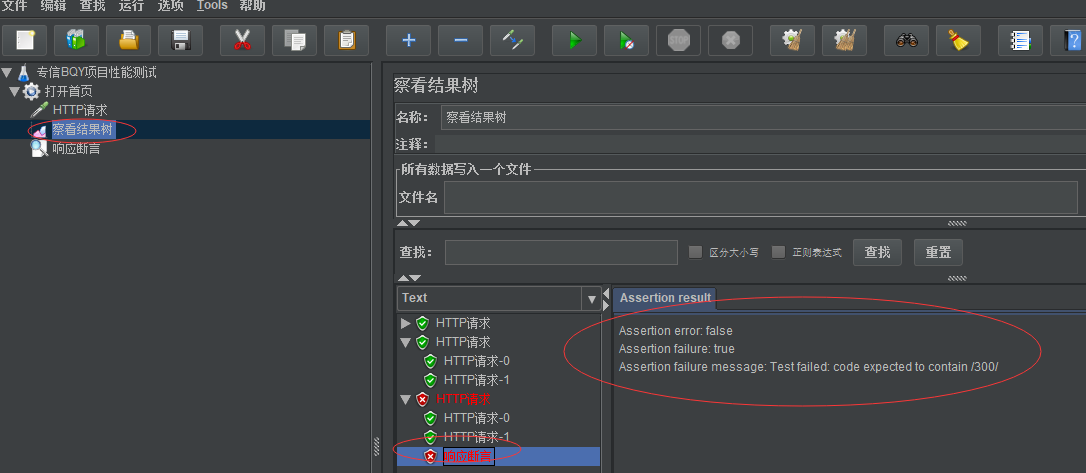
测试字段:这里可以设置"响应代码"返回300让故意断言失败(如果断言成功不会有任何显示)
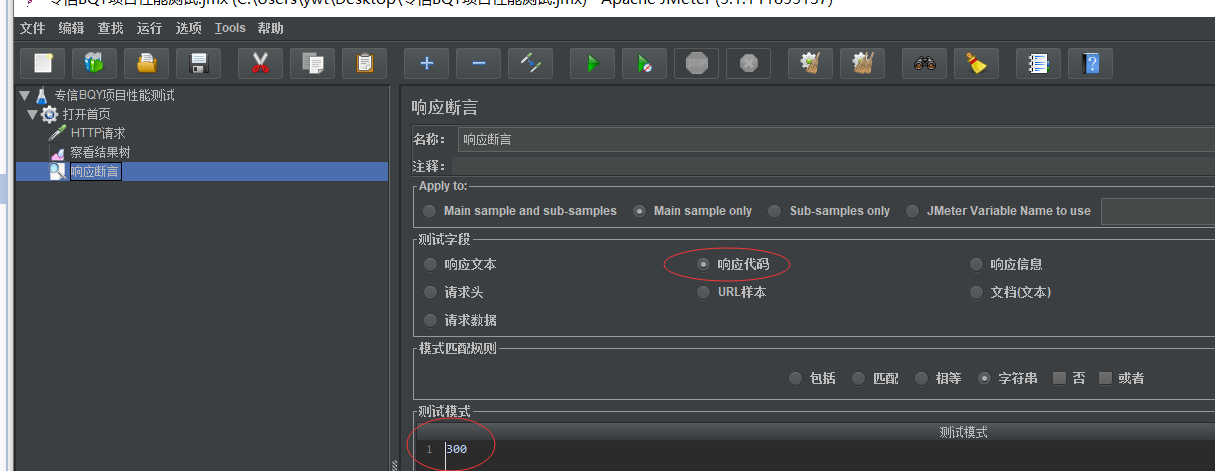
如果断言失败可以从查看结果树看到相应失败结果和内容:如下
上面就是最简单的模拟请求过程:
0:新建测试计划
1:线程组(打开首页):就是模拟人,多少个人
2:http请求(添加取样器):创建事务,模拟干什么
3:查看结果树(监听器):查看结果
4:响应断言(断言):检查结果正确与否
7:jmeter主要功能元件之:测试计划(线程组)右击鼠标——>添加按钮——>逻辑控制器
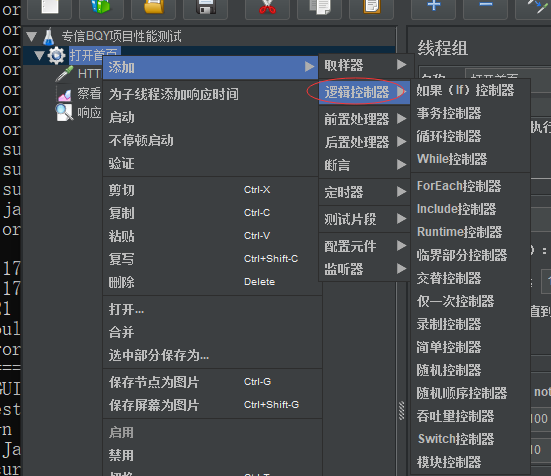
逻辑控制器:jmeter类似变成语言,控制请求发一次或者多次,控制请求发的多少速度,这是逻辑控制器
8:jmeter主要功能元件之:测试计划(线程组)右击鼠标——>添加按钮——>配置元件
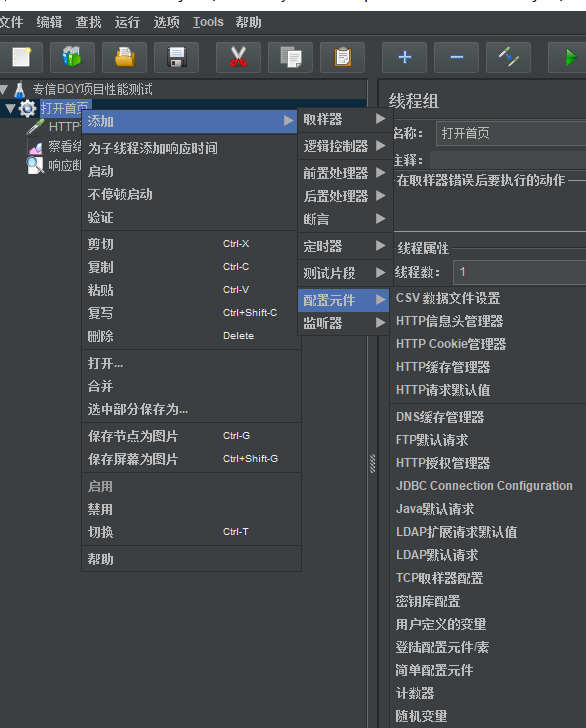
比如有数据库信息,或者配置文件jmeter需要读取,这里需要使用到配置元件
9:jmeter主要功能元件之:测试计划(线程组)右击鼠标——>添加按钮——>定时器
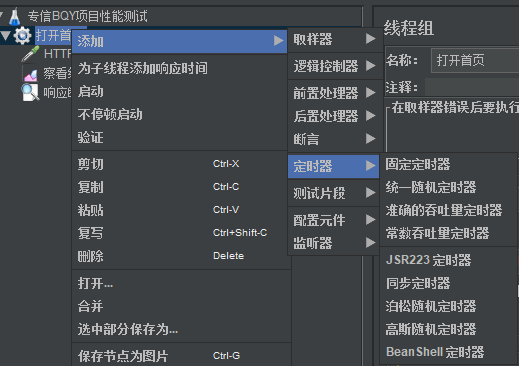
定时器:性能测试的时候等待多少秒
9:jmeter主要功能元件之:测试计划(线程组)右击鼠标——>添加按钮——>前置处理器
前置处理器:发请求之前的一些准备操作
10:jmeter主要功能元件之:测试计划(线程组)右击鼠标——>添加按钮——>取样器(sampler)
取样器:创建事务的,支持各种特定协议
11:jmeter主要功能元件之:测试计划(线程组)右击鼠标——>添加按钮——>后置处理器
后置处理器:一般正则表达式提取器使用比较多,比如发送了请求得到了响应之后把结果里面想要的信息比如session_id等提取出来后面使用
12:jmeter主要功能元件之:测试计划(线程组)右击鼠标——>添加按钮——>断言
断言:判断返回结果对不对的
13:jmeter主要功能元件之:测试计划(线程组)右击鼠标——>添加按钮——>监听器
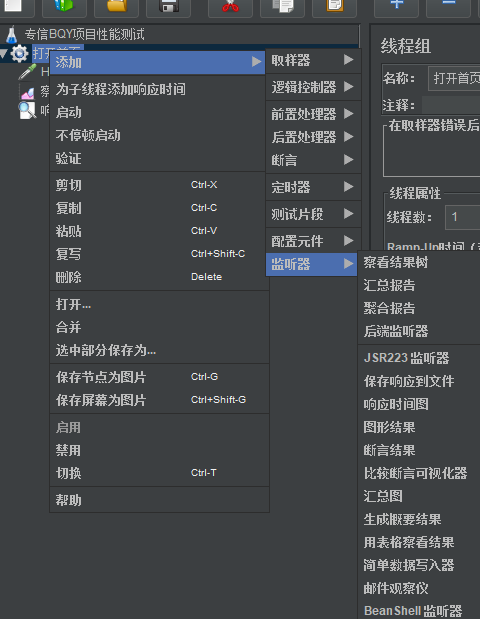
监听器:各种角度查看结果,比如使用图线或者表格,或者文件形式查看的
14:jmeter工具在windows和linux下的使用
windows下: bin文件夹里面的jmeter.bat批处理文件双击打开(点击ApacheJMeter.jar也可以)
linux下: bin文件夹里面的jmeter.sh批处理文件打开
15:断言错误信息
Assertion error(错误): false(这个断言语句格式本身没有错误,进行断言的结果返回的是false) Assertion failure(失败): true(表示断言是失败的) Assertion failure message(失败原因): Test failed: code expected to contain /300/(代码期望返回的是300)
16:jmeter中元件的作用域和变量
jmeter元件作用域概述
元件的作用城是靠测试计划的的树型结构中元件的父子关系来确定的,作用域的原则是:
取样器(sampler) 元件不和其它元件相互作用,因此不存在作用域的问题。
逻辑控制器(Logic Controller)元件只对其子节点中的取样器和逻辑控制器作用。
除取样器和逻辑控制器元件外,其他6类元件,如果是某个sampler的子节点,则该元件仅对其父子节点起作用
除取样器和逻辑控制器元件外的其他6类元件,如果其父节点不是sampler,
则其作用域是该元件父节点下的其他所有后代节点(包括子节点,子节点的子节点等)
17:测试计划
测试工作元件都是属于测试计划下的,如果一个元件不在测试计划下,执行这个测试计划不会执行这个元件
jmeter的测试过程就一个测试计划(测试计划里面可以添加多个线程组)
多个线程组代表行为:先打开首页——>再登录——>跳转到帮组页面
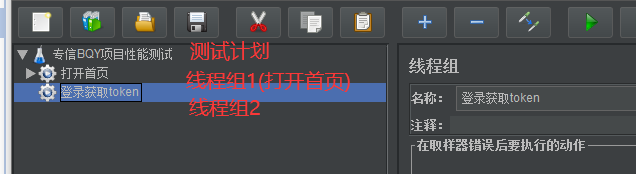
性能测试一个个去模拟用户行为,组合在一起,完整的性能测试一个场景由多个线程组构成的
一个线程组里多个请求还是分别放入不同线程组
比如下面三个场景三个任务三个线程组:
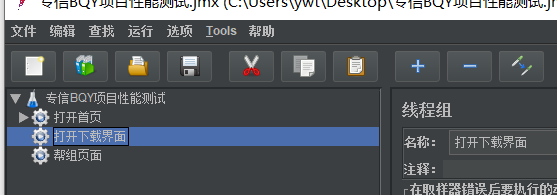
打开首页人比较多,下载人稍微少点,帮助的时候人更少
每个线程组里有自己的行为查看结果和监听
执行的测试的时候通常以一个线程组为单位来执行:
比如这一群人10个人访问主页
这一群5个人访问帮助页面
通常是单个行为来执行的,一个线程组里包含多个请求:如下:线程组打开首页里三个请求动作:首页+直播课程A+直播课程B
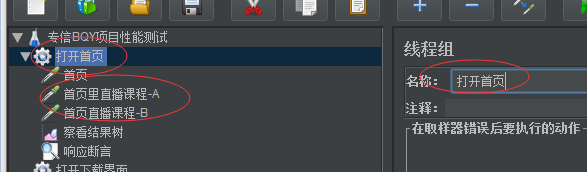
上面这个线程组是测试一群用户上来打开首页,然后访问第一个课程,然后访问第二个课程,是这样一系列动作的业务场景
上面的多个请求组合在一起构成了业务场景。
业务场景的构成:是由samper(取样器勾选协议)元件来构造的
性能测试一般都是多个请求组合一起构成业务
18:断言组件的作用域
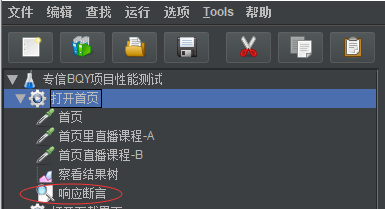
如上:三个采样器构造请求,断言响应放在最外面和线程组下面和采样器请求同一级别
那么这个"响应断言"是属于这个线程组下所有的,这个线程组里所有的进程都会用到这个断言,
作用于这三个请求(首页+直播课程A+直播课程B)
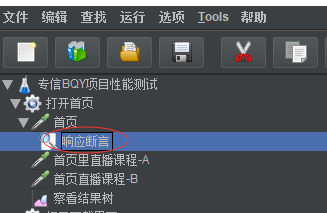
如上:把响应断言放到首页这个请求下面,那么这个响应断言只作用于首页,对其他的请求没有断言效果
这就是元件的作用域,
响应断言和查看结果树等各种元件都是这样的机制,在什么下面就作用于哪里
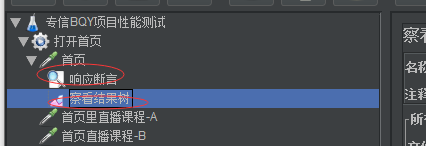
如上:响应断言+查看结构树这两个组件都只作用于首页这个请求,对其他两个请求没有影响
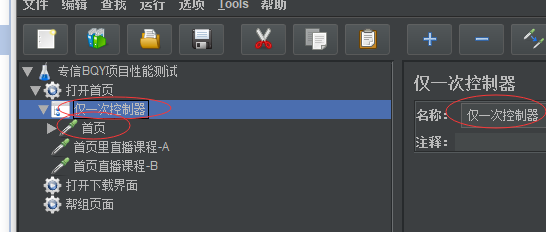
添加个逻辑控制器——>仅一次执行——>把首页这个请求放在仅一次执行这个逻辑控制器里面
然后修改线程组:线程数1,循环次数2次
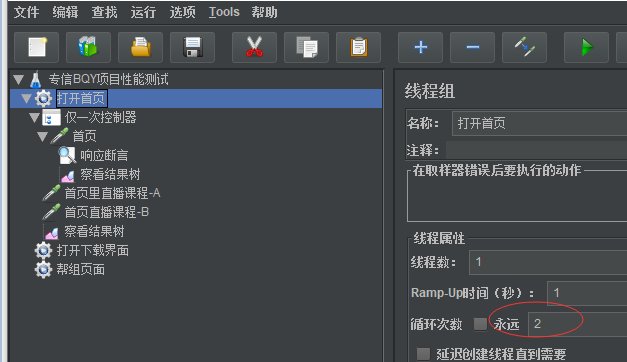
然后查看结果
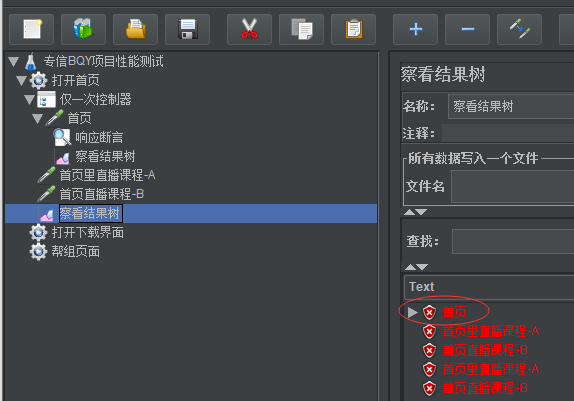
可以看到直播课程A和直播课程B都执行了2次,只有首页只执行了1次,因为首页被仅一次控制器控制着
比如可以使用仅一次控制器控制登录行为,然后其他的请求疯狂瞎几把乱点
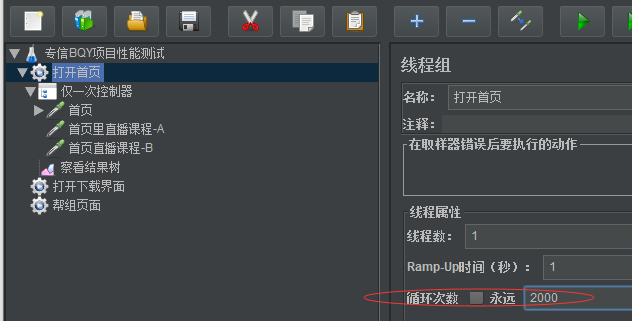
把所有请求放到仅一次控制器里面,就算线程组里面设置循环2000次,也只会执行一次,设置的2000次不会生效
仅一次控制器控制着他下面的所有请求只执行一次,不管线程这不设置多少次
19:jmeter变量的使用
构造消息:
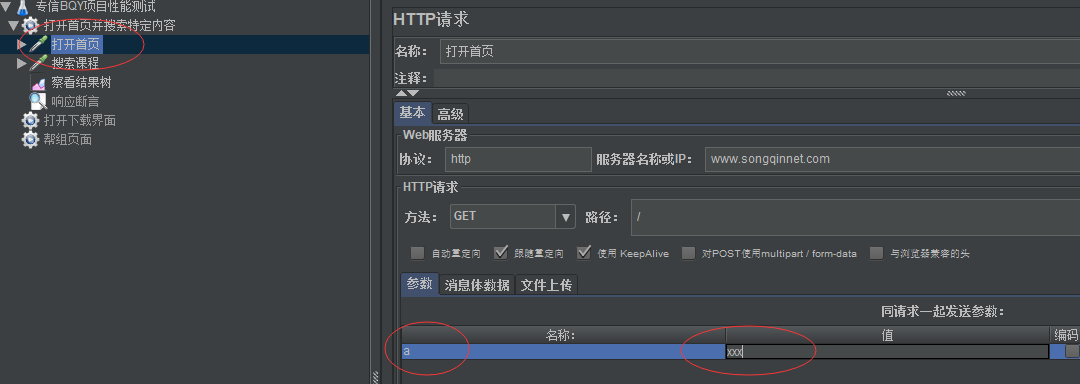
1:打开首页:https://www.songqinnet.com/
2:首页下搜索内容:比如http,sql(这个搜索的内容要可以配置,参数化)https://www.songqinnet.com/search?q=http
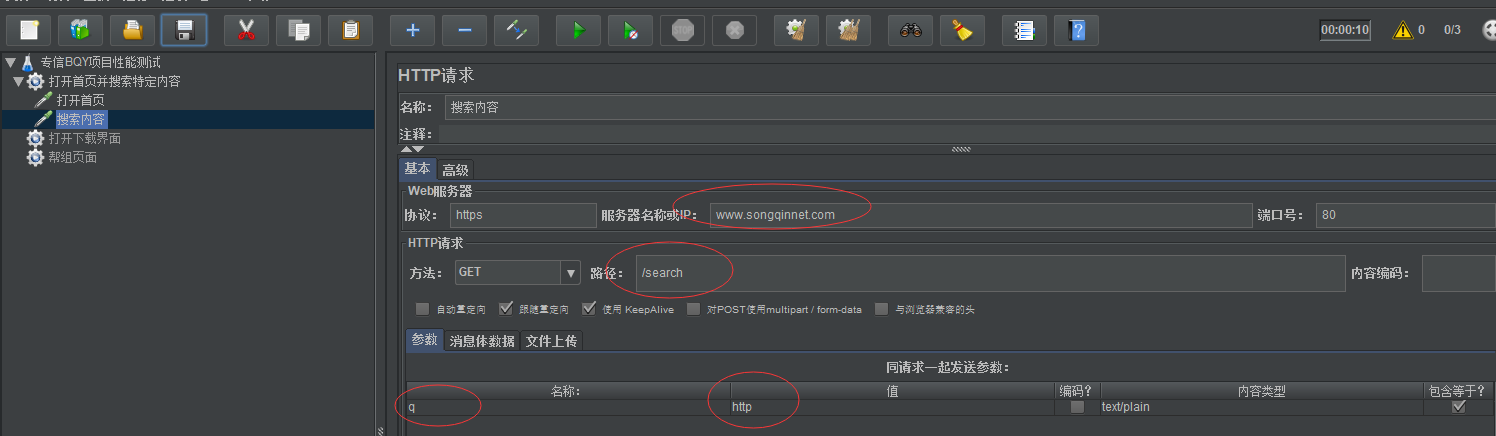
如下在http里填写搜索内容请求,这时候jmeter会自动组装网址+路径+参数内容(最后组装成:https://www.songqinnet.com/search?q=http)
https://www.songqinnet.com/search?q=http:
/www.songqinnet.com:主机
search:路径
q=http:参数,变量q=http
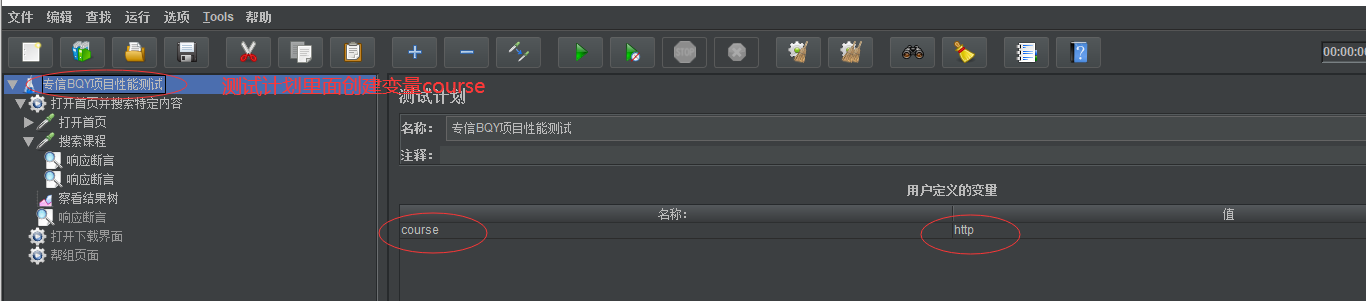
jmeter创建变量方法一:每个线程组都需要使用到的变量放到最顶层(测试计划里添加的变量是测试计划下所有的线程组都可以使用的)
下面在测试计划里定义变量 course
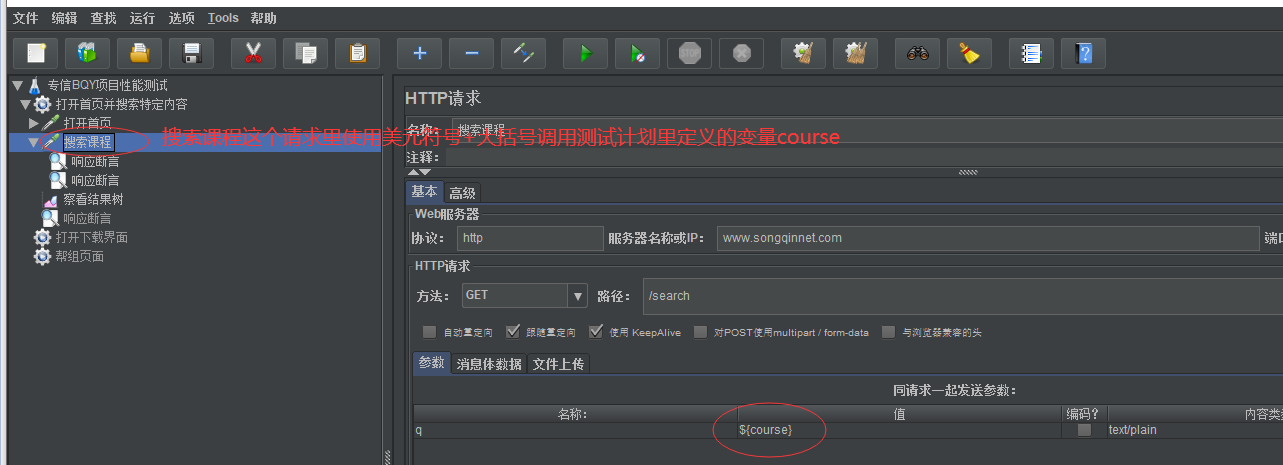
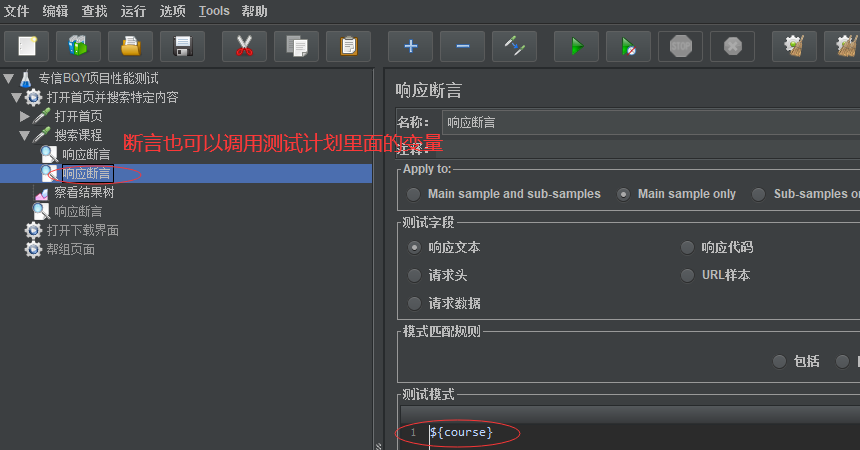
然后在线程组下的搜索课程这个请求里使用 ${course} 调用这个course变量,搜索课程请求内部的断言也可以使用${course}调用这个变量
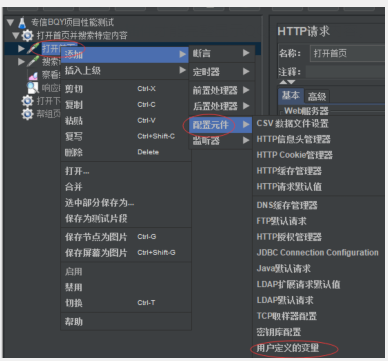
jmeter创建变量方法二:只属于单个请求内部的变量,可以在打开首页这个http请求里添加一个用户定义的变量的配置元件
这时候用户定义的变量组件里定义的变量只能给打开首页这个请求使用
(但是实际上搜索课程这个请求也能使用打开首页这个请求里设置的"用户定义的变量")
只要是在一个测试计划里面的用户定义变量,一开始就被初始化了,所以后面其他的请求都可以使用
所以就算如下在打开首页这个请求里面添加一个“用户定义的变量”但是还是整个测试计划里所有请求都可以使用的
这里用户定义的变量在测试执行之前就先初始化了,后面的所有请求都可以直接使用,可以跨越线程组,
作用域就是整个测试计划(专信BQY项目性能测试)
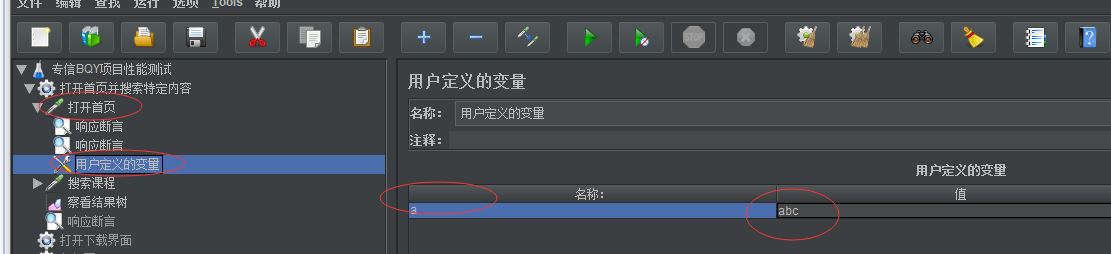
jmeter创建变量方法三:直接在线程请求里写,单独某个请求使用
20:jmeter脚本录制
编写性能测试脚本(场景):人数设置成为1,模拟着1个用户行为 编写性能脚本运行步骤:1:利用工具录制 2:自己构造请求协议 jmeter录制工具(jmeter或者地三方的一些录制工具,采用代理机制) 代理原理: B:浏览器 S:服务器 B输入服务器S的url(全球统一资源定位符,网址),浏览器和服务器直接连接通过网络走tcp/IP协议 浏览器发出和收到的消息(请求和应答消息)使用代理(proxy)来获取 代理工作在浏览器和服务器之间 浏览器和手机都可以设置代理的ip地址 所有的网络协议都是二元组的(tcp/ip协议):端口+ip,tcp是属于传输层协议,传输层需要和应用层对接,
传输层听过端口来判断把数据传递给哪个应用层(电脑收到数据包依靠端口把数据传递给应用程序比如yy或者qq),
端口位于tcp/ip协议里面的传输层,端口对应应用程序,tcp/ip就是一个socket(套接字:核心的就算端口+ip二元组),
tcp这层是端口号,ip协议这层是ip地址, 所有浏览器设置代理需要设置代理服务器的ip+代理服务器的端口(通过这两个才可以找到代理服务器里面具体某个代理服务应用) 网络程序启动的时候都会向操作系统获取端口资源(1-65535端口资源是操作系统预留的), 某些端口资源是公共的:80是web服务器端口,53是DNS的,21是FTP的,22S是SSH的,23是telnet的 等等
代理服务器除了需要提供ip+端口,有的代理服务器还需要设置用户名+密码(一些私有收费的)
代理的作用就是消息的转发
jmeter代理服务器,把浏览器上网记录抓取,浏览器和服务器之间加一个代理服务器,浏览器里配置jmeter代理服务器的地址和端口
所有请求发给jmeter代理服务器,然后jmeter代理服务器把请求发给外网,所有的数据的经过jmeter所以可以进行录制
jmeter记录所有请求数据,记录下来找到对应的元件塞进去就可以录制脚本了
代理服务器如果有问题,不可信的代理服务器有很大安全问题,泄露信息
21:一些浏览器的代理设置
chrome浏览器设置代理:https://zhidao.baidu.com/question/204679423955769445.html
jmeter设置代理服务器录制脚本: https://www.cnblogs.com/niunai/p/11078879.html
https脚本录制: https://www.cnblogs.com/testway/p/8674918.html
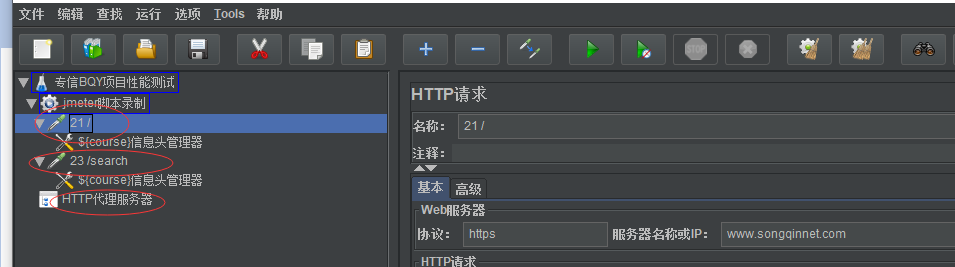
如上录制好脚本之后,在录制好脚本的线程组界面 ctrl+f 查找想要访问网址相关的请求(比如筛选:baidu或者songqinnet)
红色是筛选出来跟你请求有关的,没有红色是和songqinnet请求无关的可以删除,不要的都删除掉
全选和window快捷操作一样,ctrl+A全选,ctrl+s拖动鼠标
然后根据网页特性自己删除一些不必要的请求,最后就能看到只留下两个,一个是打开首页,一个是搜索http课程 如下:
脚本录制步骤: 1:浏览器设置代理 2:jmeter设置代理服务器 3:http代理服务器里面设置目标控制器到一个已经创建的线程组(就是把脚本录制到这个已经创建的线程组) 4:http代理服务器设置分组选项,一般不对样本进行分组,全部录制下来自己进行分组 5:删除一些不必要的录制,进行分组或者组合重命名等操作 6:浏览器代理取消 7:然后jmeter线程组设置用户跑脚本
8:后面就是脚本完善,加断言,加用户量,加报告来进行性能测试(录制脚本先跑通一个用户再考虑大量用户)
20和21就是使用jmeter代理服务器录制jmeter脚本的全程,代理服务器的设置等等
22:抓包来进行脚本录制(windows下使用wireshark(嵌套了winpcap),linux下使用tcpdump)
wireshark:抓取计算机网络层协议的工具,比较底层了(应用层,传输层,ip层,数据链路层等原始数据都可以抓取,不管什么协议,只要经过网卡都可以抓取)
抓包规则过滤:http and http.host contains "songqinnet"
学习一下wireshark抓包的使用
抓包工具抓取原始的http请求,根据请求的消息在jmeter里面构造数据(数据十分直观,但是填写数据量构造消息工作大)
23:badboy进行jmeter脚本录制(现在不更新了,可以放弃了,但是脚本录制还是不错的)
badboy:可以做独立的功能自动化工具,把抓取的脚本导出去,导成jmx格式
badboy打开就处于recording录制状态了,
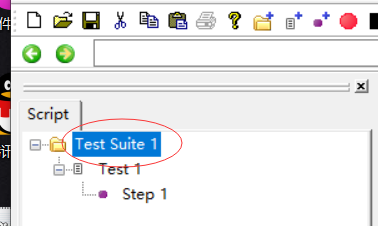
test suite:测试用例集合,里面可以创建一个个测试用例
启动默认一个test 1测试用例,step 1是测试用例的第一个步骤
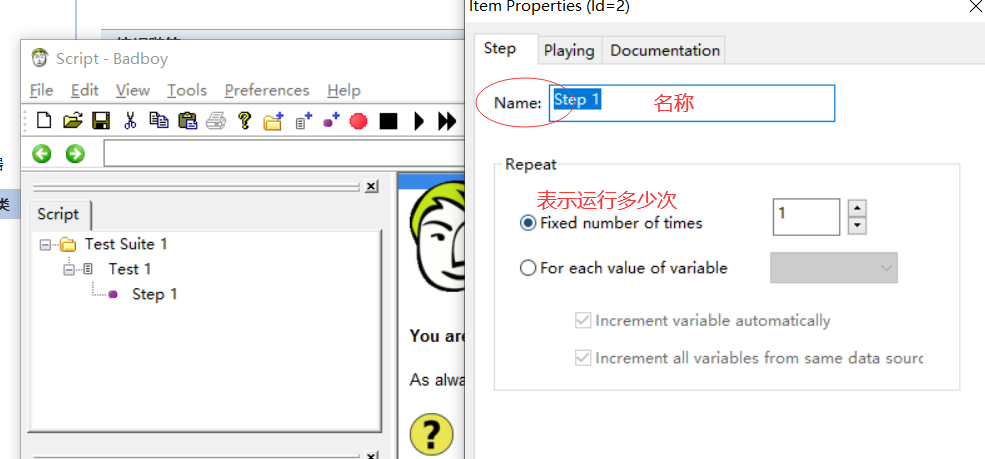
可以添加步骤,add断言什么的,双击step 1 可以修改name名称
badboy录制:
1:输入框输入要访问的网站
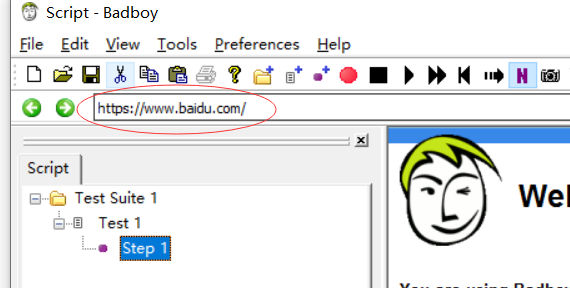
2:点击录制按钮
3:点击访问按钮
4:然后右下角就会跳转到百度页面,可以点击各种操作,比如搜索啊还有点击页面跳转,都会录制每一步的操作
5:录制完成之后暂停,选中test suite 1单机鼠标右键选中play whole suite回方查看,把刚才的操作都回放起来了
6:录制好之后点击file——>export to jmeter 到处一个 Script.jmx 文件
7:然后在jmeter里面点击“编辑”——>点击“打开”——>选择Script.jmx文件打开
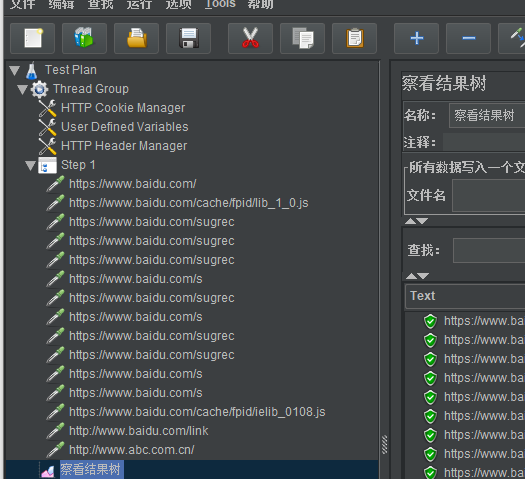
8:然后jmeter工具就多了个test plan测试计划了,就转化成jmeter脚本了,
添加一个监听器直接运行把刚才的操作都显示出来了而且现在的脚本的调试更简单没有太多多余的东西
格式也比较方便,头和用户名和cookie等都录制下来了
梳理业务逻辑: 1:业务:简单业务 打开主页-访问(每一个访问创建一个http请求)-page1-page2-page3
2:业务2:复杂点的业务有 打开主页 -登录(csv文件放进去一批用户比如100个,创建100个线程去读取这些用户然后进行登录)——>
每个用户登录后每个线程都进行不同的操作(访问不同的页面或者查询操作,模拟现实使用)——>
监听器获取测试数据指标(TPS,响应时间,错误率这是前端能查看的数据)(还能配合linux后台监听查看cpu,内存,disk磁盘,net网络带宽等)
加某些逻辑操作 登录只需要登录一次使用一次控制器,某些操作需要循环或者随机数来模拟现实用户使用的情况,不断优化加压, 需要一个完整的需求: 如果测试系统最高的负载那么一直加压 如果测试系统稳定性那么保持一定的流量让他稳定运行多少个小时 做什么决定性能怎么开展
jmeter:
模拟用户的:添加线程组、
模拟用户具体行为的:采样器(sampler),协议的代表
进行测试次数逻辑控制的:逻辑控制器
把数据参数化,保存在文件里:csv或者config组件
验证测试结果:断言
查看测试结果:监听器
jmeter就是创建线程组,选择具体采样器,使用逻辑控制器和配置文件模拟行为,对测试结果数据结果进行断言判断,监听器记录测试过程
真正大流量测试过此不会使用jmeter GUI界面,可能自己先gg了,测试的时候是使用命令行启动jmeter的,无窗口,
jmeter脚本通过窗口调试完成之后,把脚本单独倒出来,运行jmeter的时候把脚本关联上去,使用命令行方式无gui界面
直接运行jmx文件,不然影响性能
jmeter xxx:使用jmeter命令运行加再jmx文件,查看结果树也是调试过程中使用的,真正测试过程中不使用
查看结果树让jmeter消耗大量的时间和网络带宽和资源来现实,脚本通了后查看结果树就不使用了
很多时间数据上不去就是因为jmeter界面本身影响性能,一般命令行运行而不使用窗口,脚本通了后通过命令运行
24:wireshark抓包条件设置
wireshark:and和or组合条件,清楚查找的条件位于第几层,正确的选择条件,然后点击应用生效,最后点击重新抓包
25:jmeter集合点技术
jmeter跑的时候使用线程跑的,线程是由cpu控制的,所有的程序运行都是在cpu里面运行的,cpu运行的时候有个调度算法,
线程量大的时候会出现有些线程跑得快,有些线程跑的慢,这个性能测试有些违背了,性能测试需要的是突发性,瞬间的,
严格意义上的高并发,单核cpu绝对意义上的并发是不存在的,cpu一定要一个个运行,除非多核,可以多个线程一起运行,
同规格内核里面分配了大量的线程也存在顺序排序调度,为了尽可能地减少干扰,减少cpu调度系统地干扰,jmeter提供了一个工具叫集合点
jmeter集合点:
比如学校规定一个时间操场集合,有些人走得快有些人走得慢,但是当到这个点地时候大家应该都到操作可,然后全部集合开启篮球赛
(早的人等,慢地人赶点过来,到时间点大家全到了,大家一并跑出去,这就是集合点,让线程到点都集中在一起,不做操作了,
当这些用户到了之后一并去触发他,这就是集合点)
集合点应用在高并发环境,应用在需要对系统进行触发操作的时候,高并发量时候,模拟大量同时点击量的时候需要使用集合点
同时搜索http这个用户量50,那么线程组配置线程数50,
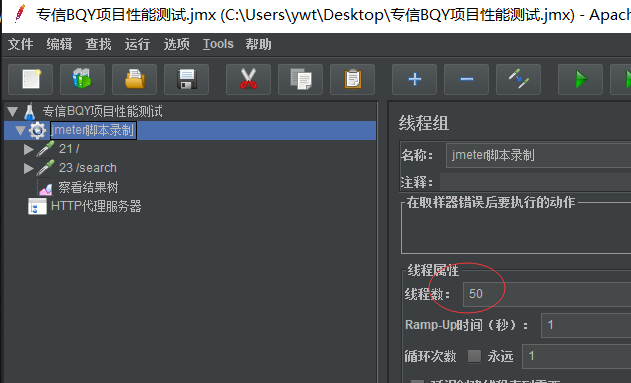
当请求多的时候,比如23/search前面有十几二十个,线程组里面的顺序虽然是从上往下开始运行,但是50个线程
运行的时候有的线程可能慢一些有的线程可能快一些,如果 23/search这个请求前面有十几二十个请求,到达查询这个
23/search的时候可能就达不到要求的50个量,有的线程跑的慢一些,可能48个可能40个,也可能都达到了
这时候为了保证search达到50并发,需要在search之前放一个集合点,让他们集中到这个里面来——这就是集合点的应用场景
保证同时多少人真正严格意义上去查找http,
性能测试大多时候对于同一数据高并发的查找或者写入性能方面容易出问题的地方(特别同时写一个东西的时候)------集合点的使用场景
集合点的添加:线程组里单机鼠标右键——>添加——>定时器——>synchronizing Timer(同步定时器)
同步定时器:到达某个点的时候阻塞线程,知道x数量线程已经达到预期的线程数然后一起释放
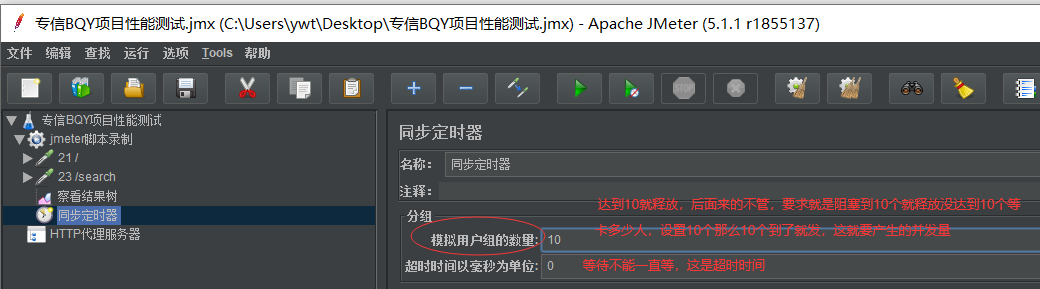
模拟用户组的数量和用户量,jmeter里面没有用户量的概率,只有线程数,一个用户对应一个线程
线程数设置50个表示雇佣50个人来干活,
Unix 高级环境编程 技术+业务(行业知识) 编程语言: 语法:语句(顺序,选择,判断,循环+变量(常量,整型,小数,字符串)+函数+库+实战
把这个“同步定时器”放在需要需要集合得请求里面
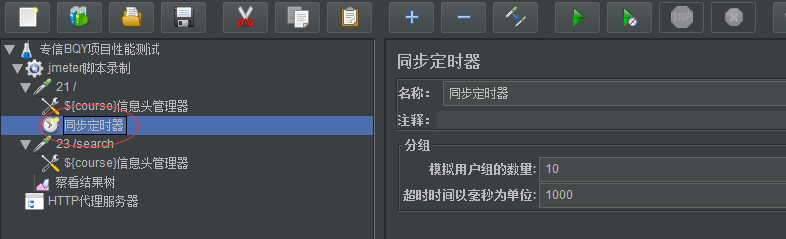
设置线程组100个,集合点设置10个,线程100个但是不是同时到的,当10个到了这个21/获取页面信息请求后就释放一批
那么着一瞬间并发就是10,限速的东西,这个点能够保证量10个,如果不适应集合点怕先后顺序不能精准的模拟tps
加了定时器后设置0,相当于更加精准化,50个线程或者10个线程一起发出去,到某个点精准的一起发
一般用的比较多的就是0,和线程组数量保存一致,保证多个请求消息之间都是能够真正按照设置的数量(50)并发的
假如没同步定时器,那么50个全部打开21,然后50个全部打开23,有可能先打开21就立马打开23,
有些线程还处于打开21,这样导致并发量不同步,
脚本运行50个全部打开,然后21运行完成后在同步定时器停止一下,10就放开一起运行23 /search
一并运行,更加严谨
同步定时器放在哪里就对哪里起作用,一般放在请求之间也可以方请求里面,这里放在21里面
对21请求起作用,一般放在请求之间,请求21完成到定时器这里停一下,然后一起到23
保持请求之间不乱套,多个请求之间正真的并发是50,或者10,消息多的时候会有这种问题
因为请求走的路由网络可能不同,有的请求快,有的请求慢,得到的响应时间也不同,这样导致
有的请求完成了有的还没来,某些点并发上不来
超时时间:到了超时时间还没满足数量那么过了超时时间就不管了,之间解除阻塞
如果请求要求并发非常严格的,请求和请求中间都放一个同步定时器,严格意义上高并发,
保证每个请求之前消息量都达到了,都能达到高并发的要求
26:jmeter检查点/断言技术
断言:从测试反馈回来的结果里面匹配是否得到我们需要的内容,检测机制
软件测试:根据需求构造各种输入数据,运行软件,匹配软件的输出,尽早尽快尽多的发现软件bug,
提示软件的质量,提高用户的满意度(检测软件是否达到需求,对输出的结果进行检测是否达到期望)
测试结果检查-检查点 检查点:指的是对于响应消息结果进行检查,在Jmeter中,称为断言。 Jmeter中的各个请求sampler中都可以添加断言。 用于检查测试中得到的响应数据等是否符合预期,用以保证性能测试过程中的数据交互与预期一致
线程组里面可以直接添加断言
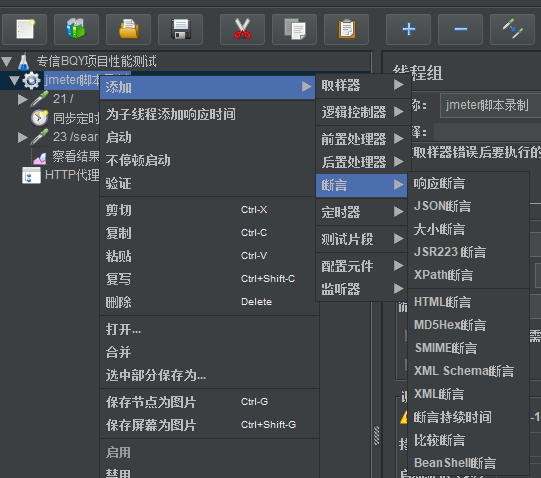
一般使用响应断言,响应断言对收到的消息(响应)的数据,一般选择main+sub第一个对主线程和主线程下的子线程都断言
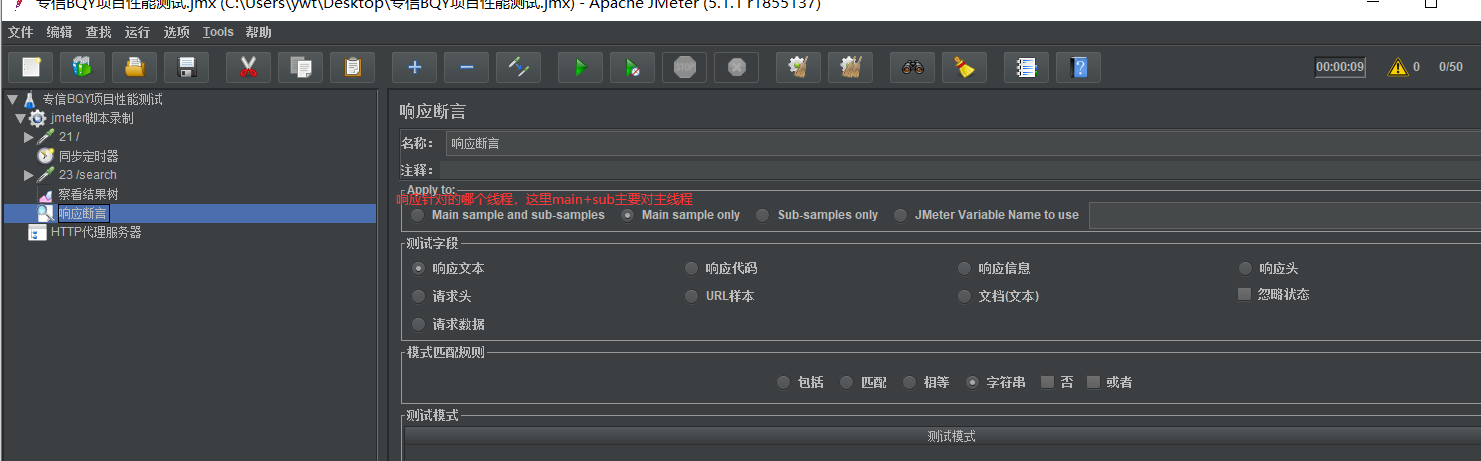
响应文本:就是请求得到的响应数据(抓取的是html网页代码里面的body部分的内容,没用头部分的内容和其他)
url样本:url响应的网址
文档(文本):不是网页html返回的格式使用这个模式获取各种各样的文本(网页就使用响应文本)
响应代码:http请求的200或者300
响应信息:响应具体相信信息,http协议返回的200时候会带上响应信息ok,这里对应的就是ok
消息头:网站的响应消息头部
模式匹配:内容期望和响应过来信息匹配的格式
包括:包含我们填写的,响应回来的文本包含正则表达式里面的内容
abc响应结果包含abc,a.b响应结果包含以a开头中间任意字符然后以b结尾的字符串
匹配:
相等:
字符串:
否:
或者:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号