
python:线程,协程,进程,网络编程
1:操作系统发展史
一:手工操作 —— 穿孔卡片:
二:批处理 —— 磁带存储
三:多道程序系统(许多个程序同时进入内存并运行。即同时把多个程序放入内存,并允许它们交替在CPU中运行)
批处理系统的一个重要缺点:不提供人机交互能力,给用户使用计算机带来不便。
四:分时系统:由于CPU速度不断提高和采用分时技术,一台计算机可同时连接多个用户终端,而每个用户可在自己的终端上联机使用计算机,好象自己独占机器一样。
分时技术:把处理机的运行时间分成很短的时间片,按时间片轮流把处理机分配给各联机作业使用。
分时系统分时间片工作,在没有遇到IO操作的时候就用完了自己的时间片被切走了,这样的切换工作其实并没有提高cpu的效率,
反而使得计算机的效率降低了。但是我们牺牲了一点效率,却实现了多个程序共同执行的效果,这样你就可以在计算机上一边听音乐一边聊qq了。
五:实时系统:系统能够及时响应随机发生的外部事件,并在严格的时间范围内完成对该事件的处理。
及时响应。每一个信息接收、分析处理和发送的过程必须在严格的时间限制内完成。
高可靠性。需采取冗余措施,双机系统前后台工作,也包括必要的保密措施等。
分时:现在流行的PC,服务器都是采用这种运行模式,即把CPU的运行分成若干时间片分别处理不同的运算请求 linux系统
实时:一般用于单片机上、PLC等,比如电梯的上下控制中,对于按键等动作要求进行实时处理
六:通用操作系统:操作系统的三种基本类型:多道批处理系统、分时系统、实时系统。
通用操作系统:具有多种类型操作特征的操作系统。可以同时兼有多道批处理、分时、实时处理的功能,或其中两种以上的功能
UNIX操作系统:通用的多用户分时交互型的操作系统
七:操作系统的进一步发展:个人计算机操作系统、网络操作系统、分布式操作系统等。
个人计算机操作系统:个人计算机上的操作系统是联机交互的单用户操作系统,它提供的联机交互功能与通用分时系统提供的功能很相似。
网络操作系统:在原来各自计算机操作系统上,按照网络体系结构的各个协议标准增加网络管理模块,其中包括:通信、资源共享、系统安全和各种网络应用服务
分布式操作系统:分布式操作系统也是通过通信网络,将地理上分散的具有自治功能的数据处理系统或计算机系统互连起来,实现信息交换和资源共享,协作完成任务
2:操作系统的作用
现代的计算机系统主要是由一个或者多个处理器,主存,硬盘,键盘,鼠标,显示器,打印机,网络接口及其他输入输出设备组成。
一般而言,现代计算机系统是一个复杂的系统。
管理硬件并且加以优化使用是非常繁琐的工作,这个繁琐的工作就是操作系统来干的,应用软件直接使用操作系统提供的功能来间接使用硬件。
精简的说的话,操作系统就是一个协调、管理和控制计算机硬件资源和软件资源的控制程序。
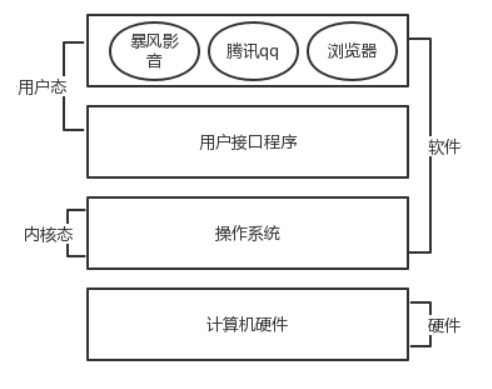
细说的话,操作系统应该分成两部分功能:
#一:隐藏了丑陋的硬件调用接口,为应用程序员提供调用硬件资源的更好,更简单,更清晰的模型(系统调用接口)。
应用程序员有了这些接口后,就不用再考虑操作硬件的细节,专心开发自己的应用程序即可。 例如:操作系统提供了文件这个抽象概念,对文件的操作就是对磁盘的操作
,有了文件我们无需再去考虑关于磁盘的读写控制(比如控制磁盘转动,移动磁头读写数据等细节), #二:将应用程序对硬件资源的竞态请求变得有序化 例如:很多应用软件其实是共享一套计算机硬件,比方说有可能有三个应用程序同时需要申请打印机来输出内容,
那么a程序竞争到了打印机资源就打印,然后可能是b竞争到打印机资源,也可能是c,这就导致了无序变得有序
3:操作系统背景知识
顾名思义,进程即正在执行的一个过程。进程是对正在运行程序的一个抽象。
进程的概念起源于操作系统,是操作系统最核心的概念,也是操作系统提供的最古老也是最重要的抽象概念之一。操作系统的其他所有内容都是围绕进程的概念展开的。
即使可以利用的cpu只有一个(早期的计算机确实如此),也能保证支持(伪)并发的能力。
将一个单独的cpu变成多个虚拟的cpu(多道技术:时间多路复用和空间多路复用+硬件上支持隔离),没有进程的抽象,现代计算机将不复存在
现在的主机一般是多核,那么每个核都会利用多道技术
有4个cpu,运行于cpu1的某个程序遇到io阻塞,会等到io结束再重新调度,会被调度到4个 cpu中的任意一个,具体由操作系统调度算法决定
空间上的复用:如内存中同时有多道程序
时间上的复用:复用一个cpu的时间片:遇到io切,占用cpu时间过长也切,核心在于切之前将进程的状态保存下来,
这样才能保证下次切换回来时,能基于上次切走的位置继续运行
4:什么是进程
进程(Process)是计算机中的程序关于某数据集合上的一次运行活动,是系统进行资源分配和调度的基本单位,是操作系统结构的基础。
在早期面向进程设计的计算机结构中,进程是程序的基本执行实体;在当代面向线程设计的计算机结构中,
进程是线程的容器。程序是指令、数据及其组织形式的描述,进程是程序的实体。
狭义定义:进程是正在运行的程序的实例(an instance of a computer program that is being executed)。
第一:进程是一个实体。每一个进程都有它自己的地址空间,一般情况下,包括文本区域(text region)、
数据区域(data region)和堆栈(stack region)。文本区域存储处理器执行的代码;数据区域存储变量和进程执行期间使用的动态分配的内存;
堆栈区域存储着活动过程调用的指令和本地变量。 第二:进程是一个“执行中的程序”。程序是一个没有生命的实体,只有处理器赋予程序生命时(操作系统执行之),它才能成为一个活动的实体,我们称其为进程。 进程是操作系统中最基本、重要的概念。是多道程序系统出现后,为了刻画系统内部出现的动态情况,
描述系统内部各道程序的活动规律引进的一个概念,所有多道程序设计操作系统都建立在进程的基础上。
从理论角度看,是对正在运行的程序过程的抽象; 从实现角度看,是一种数据结构,目的在于清晰地刻画动态系统的内在规律,有效管理和调度进入计算机系统主存储器运行的程序。
进程的特征
动态性:进程的实质是程序在多道程序系统中的一次执行过程,进程是动态产生,动态消亡的。
并发性:任何进程都可以同其他进程一起并发执行
独立性:进程是一个能独立运行的基本单位,同时也是系统分配资源和调度的独立单位;
异步性:由于进程间的相互制约,使进程具有执行的间断性,即进程按各自独立的、不可预知的速度向前推进
结构特征:进程由程序、数据和进程控制块三部分组成。
多个不同的进程可以包含相同的程序:一个程序在不同的数据集里就构成不同的进程,能得到不同的结果;但是执行过程中,程序不能发生改变。
进程和程序的区别:
程序是指令和数据的有序集合,其本身没有任何运行的含义,是一个静态的概念。 而进程是程序在处理机上的一次执行过程,它是一个动态的概念。 程序可以作为一种软件资料长期存在,而进程是有一定生命期的。 程序是永久的,进程是暂时的。
同一个程序执行两次,就会在操作系统中出现两个进程,所以我们可以同时运行一个软件,分别做不同的事情也不会混乱
4:进程的调度
要想多个进程交替运行,操作系统必须对这些进程进行调度,这个调度也不是随即进行的,而是需要遵循一定的法则,由此就有了进程的调度算法
一:先来先服务(FCFS)调度算法:是一种最简单的调度算法,该算法既可用于作业调度,也可用于进程调度。
FCFS算法比较有利于长作业(进程),而不利于短作业(进程)。由此可知,本算法适合于CPU繁忙型作业,而不利于I/O繁忙型的作业(进程)。
二:短作业(进程)优先调度算法(SJ/PF)是指对短作业或短进程优先调度的算法,该算法既可用于作业调度,也可用于进程调度。
但其对长作业不利;不能保证紧迫性作业(进程)被及时处理;作业的长短只是被估算出来的
三:时间片轮转(Round Robin,RR)法:基本思路是让每个进程在就绪队列中的等待时间与享受服务的时间成比例。在时间片轮转法中,
需要将CPU的处理时间分成固定大小的时间片,例如,几十毫秒至几百毫秒。如果一个进程在被调度选中之后用完了系统规定的时间片,
但又未完成要求的任务,则它自行释放自己所占有的CPU而排到就绪队列的末尾,等待下一次调度。同时,进程调度程序又去调度当前就绪队列中的第一个进程。
显然,轮转法只能用来调度分配一些可以抢占的资源。这些可以抢占的资源可以随时被剥夺,而且可以将它们再分配给别的进程。
CPU是可抢占资源的一种。但打印机等资源是不可抢占的。由于作业调度是对除了CPU之外的所有系统硬件资源的分配,
其中包含有不可抢占资源,所以作业调度不使用轮转法。
在轮转法中,时间片长度的选取非常重要。首先,时间片长度的选择会直接影响到系统的开销和响应时间。
如果时间片长度过短,则调度程序抢占处理机的次数增多。这将使进程上下文切换次数也大大增加,从而加重系统开销。
反过来,如果时间片长度选择过长,例如,一个时间片能保证就绪队列中所需执行时间最长的进程能执行完毕,则轮转法变成了先来先服务法。
时间片长度的选择是根据系统对响应时间的要求和就绪队列中所允许最大的进程数来确定的。
在轮转法中,加入到就绪队列的进程有3种情况: 一种是分给它的时间片用完,但进程还未完成,回到就绪队列的末尾等待下次调度去继续执行。 另一种情况是分给该进程的时间片并未用完,只是因为请求I/O或由于进程的互斥与同步关系而被阻塞。当阻塞解除之后再回到就绪队列。 第三种情况就是新创建进程进入就绪队列。 如果对这些进程区别对待,给予不同的优先级和时间片从直观上看,可以进一步改善系统服务质量和效率。
例如,我们可把就绪队列按照进程到达就绪队列的类型和进程被阻塞时的阻塞原因分成不同的就绪队列,
每个队列按FCFS原则排列,各队列之间的进程享有不同的优先级,但同一队列内优先级相同。这样,当一个进程在执行完它的时间片之后,
或从睡眠中被唤醒以及被创建之后,将进入不同的就绪队列。
四:多级反馈队列
前面介绍的各种用作进程调度的算法都有一定的局限性。如短进程优先的调度算法,仅照顾了短进程而忽略了长进程,
而且如果并未指明进程的长度,则短进程优先和基于进程长度的抢占式调度算法都将无法使用。 而多级反馈队列调度算法则不必事先知道各种进程所需的执行时间,而且还可以满足各种类型进程的需要,
因而它是目前被公认的一种较好的进程调度算法。在采用多级反馈队列调度算法的系统中,调度算法的实施过程如下所述。 (1) 应设置多个就绪队列,并为各个队列赋予不同的优先级。第一个队列的优先级最高,第二个队列次之,其余各队列的优先权逐个降低。
该算法赋予各个队列中进程执行时间片的大小也各不相同,在优先权愈高的队列中,为每个进程所规定的执行时间片就愈小。
例如,第二个队列的时间片要比第一个队列的时间片长一倍,……,第i+1个队列的时间片要比第i个队列的时间片长一倍。 (2) 当一个新进程进入内存后,首先将它放入第一队列的末尾,按FCFS原则排队等待调度。当轮到该进程执行时,
如它能在该时间片内完成,便可准备撤离系统;如果它在一个时间片结束时尚未完成,调度程序便将该进程转入第二队列的末尾,
再同样地按FCFS原则等待调度执行;如果它在第二队列中运行一个时间片后仍未完成,
再依次将它放入第三队列,……,如此下去,当一个长作业(进程)从第一队列依次降到第n队列后,在第n 队列便采取按时间片轮转的方式运行。 (3) 仅当第一队列空闲时,调度程序才调度第二队列中的进程运行;仅当第1~(i-1)队列均空时,才会调度第i队列中的进程运行。
如果处理机正在第i队列中为某进程服务时,
又有新进程进入优先权较高的队列(第1~(i-1)中的任何一个队列),则此时新进程将抢占正在运行进程的处理机,
即由调度程序把正在运行的进程放回到第i队列的末尾,把处理机分配给新到的高优先权进程。
5:进程的并行与并发
并行:并行是指两者同时执行,比如赛跑,两个人都在不停的往前跑;(资源够用,比如三个线程,四核的CPU )
并发 : 并发是指资源有限的情况下,两者交替轮流使用资源,比如一段路(单核CPU资源)同时只能过一个人,
A走一段后,让给B,B用完继续给A ,交替使用,目的是提高效率。
区别:
并行是从微观上,也就是在一个精确的时间片刻,有不同的程序在执行,这就要求必须有多个处理器。
并发是从宏观上,在一个时间段上可以看出是同时执行的,比如一个服务器同时处理多个session。
6:同步异步阻塞非阻塞
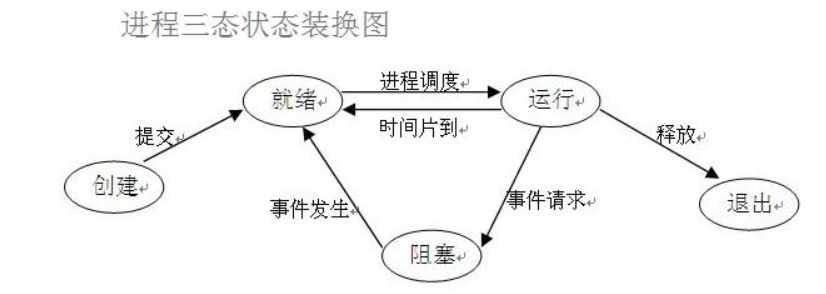
进程的几个状态。在程序运行的过程中,由于被操作系统的调度算法控制,程序会进入几个状态:就绪,运行和阻塞。
(1)就绪(Ready)状态:当进程已分配到除CPU以外的所有必要的资源,只要获得处理机便可立即执行,这时的进程状态称为就绪状态。
(2)执行/运行(Running)状态当进程已获得处理机,其程序正在处理机上执行,此时的进程状态称为执行状态。
(3)阻塞(Blocked)状态:正在执行的进程,由于等待某个事件发生而无法执行时,便放弃处理机而处于阻塞状态。
引起进程阻塞的事件可有多种,例如,等待I/O完成、申请缓冲区不能满足、等待信件(信号)等。

7:同步异步
所谓同步就是一个任务的完成需要依赖另外一个任务时,只有等待被依赖的任务完成后,
依赖的任务才能算完成,这是一种可靠的任务序列。要么成功都成功,失败都失败,两个任务的状态可以保持一致。
所谓异步是不需要等待被依赖的任务完成,只是通知被依赖的任务要完成什么工作,依赖的任务也立即执行,只要自己完成了整个任务就算完成了。
至于被依赖的任务最终是否真正完成,依赖它的任务无法确定,所以它是不可靠的任务序列。
比如我去银行办理业务,可能会有两种方式:
第一种 :选择排队等候;
第二种 :选择取一个小纸条上面有我的号码,等到排到我这一号时由柜台的人通知我轮到我去办理业务了;
第一种:前者(排队等候)就是同步等待消息通知,也就是我要一直在等待银行办理业务情况;
第二种:后者(等待别人通知)就是异步等待消息通知。在异步消息处理中,等待消息通知者(在这个例子中就是等待办理业务的人)往往注册一个回调机制,
在所等待的事件被触发时由触发机制(在这里是柜台的人)通过某种机制(在这里是写在小纸条上的号码,喊号)找到等待该事件的人
8:阻塞和非阻塞
阻塞和非阻塞这两个概念与程序(线程)等待消息通知(无所谓同步或者异步)时的状态有关。
也就是说阻塞与非阻塞主要是程序(线程)等待消息通知时的状态角度来说的(也就是等待消息通知时候的状态:
1:a需要等待消息,a停止某个函数不允许就是阻塞
2:a需要等待消息,a继续往下运行,这就是非阻塞
同步和异步是两个程序互相依赖,a运行需要b运行给个结果或者通知,a依赖这个结果就是同步,不依赖就是异步
阻塞看的是a线程等待b线程结果的运行状态
同步和异步是a线程对b线程的依赖关系,必须b完成或者不需要等待b完成)
不论是排队还是使用号码等待通知,如果在这个等待的过程中,等待者除了等待消息通知之外不能做其它的事情,
那么该机制就是阻塞的,表现在程序中,也就是该程序一直阻塞在该函数调用处不能继续往下执行。 相反,有的人喜欢在银行办理这些业务的时候一边打打电话发发短信一边等待,这样的状态就是非阻塞的,因为他(等待者)没有阻塞在这个消息通知上,而是一边做自己的事情一边等待。 注意:同步非阻塞形式实际上是效率低下的,想象一下你一边打着电话一边还需要抬头看到底队伍排到你了没有。
如果把打电话和观察排队的位置看成是程序的两个操作的话,这个程序需要在这两种不同的行为之间来回的切换,效率可想而知是低下的;
而异步非阻塞形式却没有这样的问题,因为打电话是你(等待者)的事情,而通知你则是柜台(消息触发机制)的事情,程序没有在两种不同的操作中来回切换。
同步非阻塞:a需要等b得结果,a又不阻塞,a继续往下运行,但是a在执行自己程序的同时还需要一直查询b执行完的结果,
同步阻塞:a需要等b结果,a阻塞某一段代码一直不往下运行了
异步非阻塞:a发个信号给b就行了,不需要一直等待b才能,a直接往下运行,不查询b的结果
异步组设:a发个信号给b就行了,不需要一直等待b才能的结果,但是a还是阻塞代码
9:同步/异步与阻塞/非阻塞
一:同步阻塞形式
效率最低。拿上面的例子来说,就是你专心排队,什么别的事都不做。
二:异步阻塞形式
如果在银行等待办理业务的人采用的是异步的方式去等待消息被触发(通知),也就是领了一张小纸条,假如在这段时间里他不能离开银行做其它的事情,
那么很显然,这个人被阻塞在了这个等待的操作上面
异步操作是可以被阻塞住的,只不过它不是在处理消息时阻塞,而是在等待消息通知时被阻塞。
三:同步非阻塞形式
实际上是效率低下的
一边打着电话一边还需要抬头看到底队伍排到你了没有,如果把打电话和观察排队的位置看成是程序的两个操作的话,
这个程序需要在这两种不同的行为之间来回的切换,效率可想而知是低下的
四:异步非阻塞形式
效率更高,
因为打电话是你(等待者)的事情,而通知你则是柜台(消息触发机制)的事情,程序没有在两种不同的操作中来回切换。
比如说,这个人突然发觉自己烟瘾犯了,需要出去抽根烟,于是他告诉大堂经理说,排到我这个号码的时候麻烦到外面通知我一下,
那么他就没有被阻塞在这个等待的操作上面,自然这个就是异步+非阻塞的方式了
很多人会把同步和阻塞混淆,是因为很多时候同步操作会以阻塞的形式表现出来,
同样的,很多人也会把异步和非阻塞混淆,因为异步操作一般都不会在真正的IO操作处被阻塞
10:进程的创建和结束
一:进程的创建
但凡是硬件,都需要有操作系统去管理,只要有操作系统,就有进程的概念,就需要有创建进程的方式,
一些操作系统只为一个应用程序设计,比如微波炉中的控制器,一旦启动微波炉,所有的进程都已经存在。 而对于通用系统(跑很多应用程序),需要有系统运行过程中创建或撤销进程的能力,主要分为四种形式创建新的进程: 1. 系统初始化(查看进程linux中用ps命令,windows中用任务管理器,前台进程负责与用户交互,后台运行的进程与用户无关,
运行在后台并且只在需要时才唤醒的进程,称为守护进程,如电子邮件、web页面、新闻、打印) 2. 一个进程在运行过程中开启了子进程(如nginx开启多进程,os.fork,subprocess.Popen等) 3. 用户的交互式请求,而创建一个新进程(如用户双击暴风影音) 4. 一个批处理作业的初始化(只在大型机的批处理系统中应用) 无论哪一种,新进程的创建都是由一个已经存在的进程执行了一个用于创建进程的系统调用而创建的。
1. 在UNIX中该系统调用是:fork:fork会创建一个与父进程一模一样的副本,二者有相同的存储映像、
同样的环境字符串和同样的打开文件(在shell解释器进程中,执行一个命令就会创建一个子进程) 2. 在windows中该系统调用是:CreateProcess,CreateProcess既处理进程的创建,也负责把正确的程序装入新进程。
关于创建子进程,UNIX和windows 1.相同的是:进程创建后,父进程和子进程有各自不同的地址空间(多道技术要求物理层面实现进程之间内存的隔离),
任何一个进程的在其地址空间中的修改都不会影响到另外一个进程。 2.不同的是:在UNIX中,子进程的初始地址空间是父进程的一个副本,提示:子进程和父进程是可以有只读的共享内存区的。
但是对于windows系统来说,从一开始父进程与子进程的地址空间就是不同的。
二:进程的结束
1. 正常退出(自愿,如用户点击交互式页面的叉号,或程序执行完毕调用发起系统调用正常退出,
在linux中用exit,在windows中用ExitProcess) 2. 出错退出(自愿,python a.py中a.py不存在) 3. 严重错误(非自愿,执行非法指令,如引用不存在的内存,1/0等,可以捕捉异常,try...except...) 4. 被其他进程杀死(非自愿,如kill -9)
11:python程序中的进程操作
运行中的程序就是一个进程。所有的进程都是通过它的父进程来创建的。因此,运行起来的python程序也是一个进程,
那么我们也可以在程序中再创建进程。多个进程可以实现并发效果,也就是说,当我们的程序中存在多个进程的时候,在某些时候,
就会让程序的执行速度变快。以我们之前所学的知识,并不能实现创建进程这个功能,所以我们就需要借助python中强大的模块。
12:python多进程模块multiprocess
仔细说来,multiprocess不是一个模块而是python中一个操作、管理进程的包。 之所以叫multi是取自multiple的多功能的意思,
在这个包中几乎包含了和进程有关的所有子模块。由于提供的子模块非常多,为了方便大家归类记忆,
我将这部分大致分为四个部分:创建进程部分,进程同步部分,进程池部分,进程之间数据共享。
13:multiprocess.process模块:process模块是一个创建进程的模块,借助这个模块,就可以完成进程的创建。
Process([group [, target [, name [, args [, kwargs]]]]]),由该类实例化得到的对象,表示一个子进程中的任务(尚未启动) 强调: 1. 需要使用关键字的方式来指定参数 2. args指定的为传给target函数的位置参数,是一个元组形式,必须有逗号 参数介绍: 1 group参数未使用,值始终为None 2 target表示调用对象,即子进程要执行的任务 3 args表示调用对象的位置参数元组,args=(1,2,'egon',) 4 kwargs表示调用对象的字典,kwargs={'name':'egon','age':18} 5 name为子进程的名称
1:p.start():启动进程,并调用该子进程中的p.run() 2:p.run():进程启动时运行的方法,正是它去调用target指定的函数,我们自定义类的类中一定要实现该方法 3:p.terminate():强制终止进程p,不会进行任何清理操作,如果p创建了子进程,该子进程就成了僵尸进程,
使用该方法需要特别小心这种情况。如果p还保存了一个锁那么也将不会被释放,进而导致死锁 4:p.is_alive():如果p仍然运行,返回True 5:p.join([timeout]):主进程等待p终止(强调:是主进程处于等的状态,而p是处于运行的状态)。
timeout是可选的超时时间,需要强调的是,p.join只能join住start开启的进程,而不能join住run开启的进程
1 p.daemon:默认值为False,如果设为True,代表p为后台运行的守护进程,
当p的父进程终止时,p也随之终止,并且设定为True后,p不能创建自己的新进程,必须在p.start()之前设置 2 p.name:进程的名称 3 p.pid:进程的pid 4 p.exitcode:进程在运行时为None、如果为–N,表示被信号N结束(了解即可) 5 p.authkey:进程的身份验证键,默认是由os.urandom()随机生成的32字符的字符串。
这个键的用途是为涉及网络连接的底层进程间通信提供安全性,这类连接只有在具有相同的身份验证键时才能成功(了解即可)
在Windows操作系统中由于没有fork(linux操作系统中创建进程的机制),在创建子进程的时候会自动 import 启动它的这个文件,
而在 import 的时候又执行了整个文件。因此如果将process()直接写在文件中就会无限递归创建子进程报错。
所以必须把创建子进程的部分使用if __name__ ==‘__main__’ 判断保护起来,
import 的时候,就不会递归运行了。
如下这段程序:
import time
from multiprocessing import Process
def f(name):
print('hello', name)
print('我是子进程')
p = Process(target=f, args=('bob',))
p.start()
time.sleep(1)
print('执行主进程的内容了')
这段代码会无限创建进程,主进程运行到Process创建子进程,在创建子进程的时候新开辟的内存又会加载这个py文件到子进程的空间里,这个py文件的内容又会在新的进程
又一次运行,子进程又运行到Process自己又创建子进程,同理子进程的子进程又会加载这个py文件到新的内存继续从头开始运行,无限循环
父进程创建子进程会复制子进程的全部内容,打开的文件,sorket连接,当前py文件代码的全部内容也会全部加载到新的内存空间运行,但是和父进程空间又是隔离的
14:使用process模块创建进程
# 在python中启动的第一个子进程 import time from multiprocessing import Process def f(name): print('hello', name) print('我是子进程') if __name__ == '__main__': p = Process(target=f, args=('bob',)) p.start() time.sleep(1) print('执行主进程的内容了')
# 在主进程 __name__ 等于 __main__
# 在子进程 __name__ 等于 __mp_main__
# join方法 import time from multiprocessing import Process def f(name): print('hello', name) time.sleep(1) print('我是子进程') if __name__ == '__main__': p = Process(target=f, args=('bob',)) p.start() #p.join() # 主进程等待p这个子进程终止后才继续运行 print('我是父进程') # 查看主进程和子进程的进程号 import os from multiprocessing import Process def f(x): print('子进程id :',os.getpid(),'父进程id :',os.getppid()) return x*x if __name__ == '__main__': print('主进程id :', os.getpid()) p_lst = [] for i in range(5): p = Process(target=f, args=(i,)) p.start()
os.getpid() 查看子进程的id
os.getppid() 查看父进程的id
# 进阶,多个进程同时运行(注意,子进程的执行顺序不是根据启动顺序决定的)
import time from multiprocessing import Process def f(name): print('hello', name) time.sleep(1) if __name__ == '__main__': p_lst = [] for i in range(5): p = Process(target=f, args=('bob',)) p.start() p_lst.append(p)
# 多个进程同时运行,再谈join方法(1) import time from multiprocessing import Process def f(name): print('hello', name) time.sleep(1) if __name__ == '__main__': p_lst = [] for i in range(5): p = Process(target=f, args=('bob',)) p.start() p_lst.append(p) p.join() # [p.join() for p in p_lst] print('父进程在执行')
# 现在执行需要5s以上,因为父进程每次Process开辟子进程后又join等待子进程运行结束后又开辟下一个进程,开辟运行后主进程又join等待子进程运行完毕继续开辟下一个进程
# 这样运行还是相当于单进程一样
# 多个进程同时运行,再谈join方法(2) import time from multiprocessing import Process def f(name): print('hello', name) time.sleep(1) if __name__ == '__main__': p_lst = [] for i in range(5): p = Process(target=f, args=('bob',)) p.start() p_lst.append(p) # [p.join() for p in p_lst] print('父进程在执行')
# 没有join,主进程不会等待子进程阻塞
# 多个进程运行并且主线程join等待 import time from multiprocessing import Process def f(name): print('hello', name) time.sleep(1) if __name__ == '__main__': start_tine = time.time() p_lst = [] for i in range(5): p = Process(target=f, args=('bob',)) p.start() p_lst.append(p) for i in p_lst: i.join() print('父进程在执行') end_time = time.time() print(f"父进程的执行时间{end_time - start_tine}")
# join不能放在第一个for循环里面,而且join要在阻塞等待的进程运行,主进程等待其他几个子进程,所以join放在主线程里,join放在第一个for循环
# 就变成了开辟一个进程主进程join阻塞等开辟的进程运行完成后继续运行,又for循环开辟进程,又join阻塞主进程.... 循环
15:继承Process类的形式开启进程的方式
import os from multiprocessing import Process class MyProcess(Process): def __init__(self, name): super().__init__() self.name = name def run(self): print(os.getpid()) print('%s 正在和女主播聊天' % self.name) if __name__ == '__main__': p1=MyProcess('wupeiqi') p2=MyProcess('yuanhao') p3=MyProcess('nezha') p1.start() #start会自动调用run p2.start() # p2.run() p3.start() p1.join() p2.join() p3.join() print('主线程')
if __name__ == '__main__': import os from multiprocessing import Process class MyProcess(Process): def __init__(self, name): super().__init__() self.name = name def run(self): print(os.getpid()) print('%s 正在和女主播聊天' % self.name) p1=MyProcess('wupeiqi') p2=MyProcess('yuanhao') p3=MyProcess('nezha') p1.start() #start会自动调用run p2.start() # p2.run() p3.start()
# 这样写不可以,AttributeError: Can't get attribute 'MyProcess' on <module '__mp_main__' from
# 全部写在if __name__ == '__main__':里面,子进程开辟的时候找不到MyProcess这个类来初始化
16:进程之间的数据隔离问题
from multiprocessing import Process def work(): global n n=0 print('子进程内: ',n) if __name__ == '__main__': n = 100 p=Process(target=work) p.start() print('主进程内: ',n)
# 主进程内n = 100
# 子进程内n = 0
# 数据是相互隔离的,子进程内运行work函数改变n为0也不会影响主进程的n
17:守护进程
会随着主进程的结束而结束。
主进程创建守护进程
其一:守护进程会在主进程代码执行结束后就终止
其二:守护进程内无法再开启子进程,否则抛出异常:AssertionError: daemonic processes are not allowed to have children
注意:进程之间是互相独立的,主进程代码运行结束,守护进程随即终止
# 守护线程的启动
# p.daemo = True设置p线程为守护线程,守护线程就是不重要的线程,主线程gg守护线程也gg
import os import time from multiprocessing import Process class Myprocess(Process): def __init__(self,person): super().__init__() self.person = person def run(self): print(os.getpid(),self.name) print('%s正在和女主播聊天' %self.person) if __name__ == '__main__': p = Myprocess('哪吒') p.daemon = True # 一定要在p.start()前设置,设置p为守护进程,禁止p创建子进程,并且父进程代码执行结束,p即终止运行 p.start() time.sleep(10) # 在sleep时查看进程id对应的进程ps -ef|grep id print('主')
# 主进程代码执行结束守护进程立即结束 from multiprocessing import Process import time def foo(): print(123) time.sleep(1) print("end123") def bar(): print(456) time.sleep(3) print("end456") if __name__ == '__main__': p1 = Process(target=foo) p2 = Process(target=bar) p1.daemon = True p1.start() p2.start() time.sleep(0.1) print("main-------")
# 打印该行则主进程代码结束,则守护进程p1应该被终止.
# 可能会有p1任务执行的打印信息123,因为主进程打印main----时,p1也执行了,但是随即被终止.
18:socket聊天并发实例
# 使用多进程实现socket聊天并发-server
from socket import * from multiprocessing import Process server=socket(AF_INET,SOCK_STREAM) server.setsockopt(SOL_SOCKET,SO_REUSEADDR,1) # 设置了SO_REUSEADDR的标记为true,操作系统就会在服务器socket被关闭或者服务器进程终止后马上释放该服务器的端口。这样做,可以使调试程序更简单 server.bind(('127.0.0.1',8080)) server.listen(5) def talk(conn,client_addr): while True: try: msg=conn.recv(1024) if not msg:break conn.send(msg.upper()) except Exception: break if __name__ == '__main__': #windows下start进程一定要写到这下面 while True: conn,client_addr=server.accept() p=Process(target=talk,args=(conn,client_addr)) p.start()
# client端 from socket import * client=socket(AF_INET,SOCK_STREAM) client.connect(('127.0.0.1',8080)) while True: msg=input('>>: ').strip() if not msg:continue client.send(msg.encode('utf-8')) msg=client.recv(1024) print(msg.decode('utf-8'))
19:多进程中的其他方法
# 进程对象的其他方法:terminate,is_alive from multiprocessing import Process import time import random class Myprocess(Process): def __init__(self, person): self.name = person super().__init__() def run(self): print('%s正在和网红脸聊天' % self.name) time.sleep(random.randrange(1, 5)) print('%s还在和网红脸聊天' % self.name) p1 = Myprocess('哪吒') p1.start() p1.terminate() # 关闭进程,不会立即关闭,所以is_alive立刻查看的结果可能还是存活 print(p1.is_alive()) # 结果为True print('开始')
time.sleep(1) print(p1.is_alive()) # 结果为False
# 进程对象的其他属性:pid和name from multiprocessing import Process import time import random class Myprocess(Process): def __init__(self, person): self.name = "1111" # name属性是Process中的属性,标示进程的名字 self.person = "xxx" super().__init__() # 执行父类的初始化方法会覆盖name属性,name变成默认的,后面的self.name= "xxx"才能重新修改进程名字 self.name = person # 在这里设置就可以修改进程名字了 self.person = "xxx" # 如果不想覆盖进程名,就修改属性名称就可以了 def run(self): print('%s正在和网红脸聊天' % self.name) print('%s正在和网红脸聊天' % self.person) time.sleep(random.randrange(1, 5)) print('%s正在和网红脸聊天' % self.name) print('%s正在和网红脸聊天' % self.person) if __name__ == '__main__': p1 = Myprocess('哪吒') p1.start() print(p1.pid) # 可以查看子进程的进程id
20:进程同步(multiprocess.Lock) 锁
当多个进程使用同一份数据资源的时候,就会引发数据安全或顺序混乱问题。
# 多进程抢占输出资源 import os import time import random from multiprocessing import Process def work(n): print('%s: %s is running' %(n,os.getpid())) time.sleep(random.random()) print('%s:%s is done' %(n,os.getpid())) if __name__ == '__main__': for i in range(3): p=Process(target=work,args=(i,)) p.start()
# 使用锁维护执行顺序 # 由并发变成了串行,牺牲了运行效率,但避免了竞争 import os import time import random from multiprocessing import Process,Lock
def work(lock,n): lock.acquire() print('%s: %s is running' % (n, os.getpid())) time.sleep(random.random()) print('%s: %s is done' % (n, os.getpid())) lock.release()
if __name__ == '__main__': lock=Lock() for i in range(3): p=Process(target=work,args=(lock,i)) p.start()
上面这种情况虽然使用加锁的形式实现了顺序的执行,但是程序又重新变成串行了,这样确实会浪费了时间,却保证了数据的安全。
接下来,我们以模拟抢票为例,来看看数据安全的重要性。
#文件db的内容为:{"count":1} #注意一定要用双引号,不然json无法识别 #并发运行,效率高,但竞争写同一文件,数据写入错乱 from multiprocessing import Process,Lock import time,json,random
def search(): dic=json.load(open('db')) print('\033[43m剩余票数%s\033[0m' %dic['count']) def get(): dic=json.load(open('db')) time.sleep(0.1) # 模拟读数据的网络延迟 if dic['count'] >0: dic['count']-=1 time.sleep(0.2) # 模拟写数据的网络延迟 json.dump(dic,open('db','w')) print('\033[43m购票成功\033[0m') def task(): search() get() if __name__ == '__main__': for i in range(100): #模拟并发100个客户端抢票 p=Process(target=task) p.start()
# 使用锁来保证数据安全 #文件db的内容为:{"count":5} #注意一定要用双引号,不然json无法识别 #并发运行,效率高,但竞争写同一文件,数据写入错乱 from multiprocessing import Process,Lock import time,json,random def search(): dic=json.load(open('db')) print('\033[43m剩余票数%s\033[0m' %dic['count']) def get(): dic=json.load(open('db')) time.sleep(random.random()) # 模拟读数据的网络延迟 if dic['count'] >0: dic['count']-=1 time.sleep(random.random()) # 模拟写数据的网络延迟 json.dump(dic,open('db','w')) print('\033[32m购票成功\033[0m') else: print('\033[31m购票失败\033[0m') def task(lock): search() lock.acquire() get() # get的前后加锁 lock.release() if __name__ == '__main__': lock = Lock() for i in range(100): #模拟并发100个客户端抢票 p=Process(target=task,args=(lock,)) p.start()
#加锁可以保证多个进程修改同一块数据时,同一时间只能有一个任务可以进行修改,即串行的修改,没错,速度是慢了,但牺牲了速度却保证了数据安全。 虽然可以用文件共享数据实现进程间通信,但问题是: 1.效率低(共享数据基于文件,而文件是硬盘上的数据) 2.需要自己加锁处理 #因此我们最好找寻一种解决方案能够兼顾:1、效率高(多个进程共享一块内存的数据) 2、帮我们处理好锁问题。这就是mutiprocessing模块为我们提供的基于消息的IPC通信机制:队列和管道。 队列和管道都是将数据存放于内存中 队列又是基于(管道+锁)实现的,可以让我们从复杂的锁问题中解脱出来, 我们应该尽量避免使用共享数据,尽可能使用消息传递和队列,避免处理复杂的同步和锁问题,而且在进程数目增多时,往往可以获得更好的可获展性。
21:进程间通信——队列(multiprocess.Queue)
进程间通信:IPC(Inter-Process Communication)
队列 :创建共享的进程队列,Queue是多进程安全的队列,可以使用Queue实现多进程之间的数据传递。
Queue([maxsize])
创建共享的进程队列。
参数 :maxsize是队列中允许的最大项数。如果省略此参数,则无大小限制。
底层队列使用管道和锁定实现。
方法介绍
Queue([maxsize])
创建共享的进程队列。maxsize是队列中允许的最大项数。如果省略此参数,则无大小限制。底层队列使用管道和锁定实现。
另外,还需要运行支持线程以便队列中的数据传输到底层管道中。
Queue的实例q具有以下方法:
q.get( [ block [ ,timeout ] ] )
返回q中的一个项目。如果q为空,此方法将阻塞,直到队列中有项目可用为止。block用于控制阻塞行为,默认为True.
如果设置为False,将引发Queue.Empty异常(定义在Queue模块中)。timeout是可选超时时间,用在阻塞模式中。
如果在指定的时间间隔内没有项目变为可用,将引发Queue.Empty异常。
q.get_nowait( )
同q.get(False)方法。
q.put(item [, block [,timeout ] ] )
将item放入队列。如果队列已满,此方法将阻塞至有空间可用为止。block控制阻塞行为,默认为True。
如果设置为False,将引发Queue.Empty异常(定义在Queue库模块中)。
timeout指定在阻塞模式中等待可用空间的时间长短。超时后将引发Queue.Full异常。
q.qsize()
返回队列中目前项目的正确数量。此函数的结果并不可靠,因为在返回结果和在稍后程序中使用结果之间,
队列中可能添加或删除了项目。在某些系统上,此方法可能引发NotImplementedError异常。
q.empty()
如果调用此方法时 q为空,返回True。如果其他进程或线程正在往队列中添加项目,
结果是不可靠的。也就是说,在返回和使用结果之间,队列中可能已经加入新的项目。
q.full()
如果q已满,返回为True. 由于线程的存在,结果也可能是不可靠的(参考q.empty()方法)。。
其他方法(了解)
q.close()
关闭队列,防止队列中加入更多数据。调用此方法时,后台线程将继续写入那些已入队列但尚未写入的数据,
但将在此方法完成时马上关闭。如果q被垃圾收集,将自动调用此方法。关闭队列不会在队列使用者中生成任何类型的数据结束信号或异常。
例如,如果某个使用者正被阻塞在get()操作上,关闭生产者中的队列不会导致get()方法返回错误。
q.cancel_join_thread()
不会在进程退出时自动连接后台线程。这可以防止join_thread()方法阻塞。
q.join_thread()
连接队列的后台线程。此方法用于在调用q.close()方法后,等待所有队列项被消耗。
默认情况下,此方法由不是q的原始创建者的所有进程调用。调用q.cancel_join_thread()方法可以禁止这种行为。
# 单看队列用法 ''' multiprocessing模块支持进程间通信的两种主要形式:管道和队列 都是基于消息传递实现的,都是队列接口 ''' from multiprocessing import Queue q=Queue(3) #put ,get ,put_nowait,get_nowait,full,empty q.put(3) q.put(3) q.put(3) # q.put(3) # 如果队列已经满了,程序就会停在这里,等待数据被别人取走,再将数据放入队列。 # 如果队列中的数据一直不被取走,程序就会永远停在这里。 try: q.put_nowait(3) # 可以使用put_nowait,如果队列满了不会阻塞,但是会因为队列满了而报错。 except: # 因此我们可以用一个try语句来处理这个错误。这样程序不会一直阻塞下去,但是会丢掉这个消息。 print('队列已经满了') # 因此,我们再放入数据之前,可以先看一下队列的状态,如果已经满了,就不继续put了。 print(q.full()) #满了 print(q.get()) print(q.get()) print(q.get()) # print(q.get()) # 同put方法一样,如果队列已经空了,那么继续取就会出现阻塞。 try: q.get_nowait(3) # 可以使用get_nowait,如果队列满了不会阻塞,但是会因为没取到值而报错。 except: # 因此我们可以用一个try语句来处理这个错误。这样程序不会一直阻塞下去。 print('队列已经空了') print(q.empty()) #空了
# 这个例子还没有加入进程通信,只是先来看看队列为我们提供的方法,以及这些方法的使用和现象
# 子进程发送数据给父进程 import time from multiprocessing import Process, Queue def f(q): q.put([time.asctime(), 'from Eva', 'hello']) # 调用主函数中p进程传递过来的进程参数 put函数为向队列中添加一条数据。 if __name__ == '__main__': q = Queue() # 创建一个Queue对象 p = Process(target=f, args=(q,)) # 创建一个进程 p.start() print(q.get()) p.join()
# 批量生产数据放入队列再批量获取结果 import os import time import multiprocessing # 向queue中输入数据的函数 def inputQ(queue): info = str(os.getpid()) + '(put):' + str(time.asctime()) queue.put(info) # 向queue中输出数据的函数 def outputQ(queue): info = queue.get() print ('%s%s\033[32m%s\033[0m'%(str(os.getpid()), '(get):',info)) # Main if __name__ == '__main__': multiprocessing.freeze_support() record1 = [] # store input processes record2 = [] # store output processes queue = multiprocessing.Queue(3) # 输入进程 for i in range(10): process = multiprocessing.Process(target=inputQ,args=(queue,)) process.start() record1.append(process) # 输出进程 for i in range(10): process = multiprocessing.Process(target=outputQ,args=(queue,)) process.start() record2.append(process) for p in record1: p.join() for p in record2: p.join()
22:生产者消费者模型
在并发编程中使用生产者和消费者模式能够解决绝大多数并发问题。该模式通过平衡生产线程和消费线程的工作能力来提高程序的整体处理数据的速度
为什么要使用生产者和消费者模式
在线程世界里,生产者就是生产数据的线程,消费者就是消费数据的线程。在多线程开发当中,如果生产者处理速度很快,而消费者处理速度很慢,
那么生产者就必须等待消费者处理完,才能继续生产数据。同样的道理,如果消费者的处理能力大于生产者,
那么消费者就必须等待生产者。为了解决这个问题于是引入了生产者和消费者模式。
什么是生产者消费者模式
生产者消费者模式是通过一个容器来解决生产者和消费者的强耦合问题。生产者和消费者彼此之间不直接通讯,而通过阻塞队列来进行通讯,
所以生产者生产完数据之后不用等待消费者处理,直接扔给阻塞队列,消费者不找生产者要数据,而是直接从阻塞队列里取,
阻塞队列就相当于一个缓冲区,平衡了生产者和消费者的处理能力
# 基于队列实现生产者消费者模型 from multiprocessing import Process,Queue import time,random,os def consumer(q): while True: res=q.get() time.sleep(random.randint(1,3)) print('\033[45m%s 吃 %s\033[0m' %(os.getpid(),res)) def producer(q): for i in range(10): time.sleep(random.randint(1,3)) res='包子%s' %i q.put(res) print('\033[44m%s 生产了 %s\033[0m' %(os.getpid(),res)) if __name__ == '__main__': q=Queue() #生产者们:即厨师们 p1=Process(target=producer,args=(q,)) #消费者们:即吃货们 c1=Process(target=consumer,args=(q,)) #开始 p1.start() c1.start() print('主')
# 此时的问题是主进程永远不会结束,原因是:生产者p在生产完后就结束了,但是消费者c在取空了q之后,则一直处于死循环中且卡在q.get()这一步。
# 解决方式无非是让生产者在生产完毕后,往队列中再发一个结束信号,这样消费者在接收到结束信号后就可以break出死循环。
# 改良版——生产者消费者模型 from multiprocessing import Process,Queue import time,random,os def consumer(q): while True: res=q.get() if res is None:break # 收到结束信号则结束 time.sleep(random.randint(1,3)) print('\033[45m%s 吃 %s\033[0m' %(os.getpid(),res)) def producer(q): for i in range(10): time.sleep(random.randint(1,3)) res='包子%s' %i q.put(res) print('\033[44m%s 生产了 %s\033[0m' %(os.getpid(),res)) q.put(None) # 发送结束信号None
if __name__ == '__main__': q=Queue() #生产者们:即厨师们 p1=Process(target=producer,args=(q,)) #消费者们:即吃货们 c1=Process(target=consumer,args=(q,)) #开始 p1.start() c1.start() print('主')
# 注意:结束信号None,不一定要由生产者发,主进程里同样可以发,但主进程需要等生产者结束后才应该发送该信号
# 主进程在生产者生产完毕后发送结束信号None from multiprocessing import Process, Queue import time import random import os def consumer(q): # 消费者,如果取出来的res等于None代表队列取完了,break终止函数 while True: res = q.get() if res is None: break time.sleep(random.randint(1, 3)) print('\033[45m%s 吃 %s\033[0m' %(os.getpid(),res)) def producer(q): # 生产者,产生十个数据, for i in range(10): time.sleep(random.randint(1, 3)) res = f"包子{i}" q.put(res) print('\033[44m%s 生产了 %s\033[0m' % (os.getpid(), res)) if __name__ == '__main__': q = Queue() p1 = Process(target=producer, args=(q,)) # 生产者们:即厨师们 c1 = Process(target=consumer, args=(q,)) # 消费者们:即吃货们 p1.start() # 开始 c1.start() p1.join() # 生产者线程运行后阻塞主线程,生产者进程运行结束后主线程开始运行 q.put(None) # p1生产者线程运行结束后主线程往队列里塞一个None print('主')
# 上述解决方式,在有多个生产者和多个消费者时,我们则需要用一个很low的方式去解决 # 多个消费者的例子:有几个消费者就需要发送几次结束信号 from multiprocessing import Process,Queue import time import random import os def consumer(q): while True: res = q.get() if res is None:break # 收到结束信号则结束 time.sleep(random.randint(1,3)) print('\033[45m%s 吃 %s\033[0m' % (os.getpid(), res)) def producer(name,q): for i in range(2): time.sleep(random.randint(1,3)) res = '%s%s' %( name,i) q.put(res) print('\033[44m%s 生产了 %s\033[0m' %(os.getpid(),res)) if __name__ == '__main__': q = Queue() # 生产者们:即厨师们 p1 = Process(target=producer, args=('包子', q)) p2 = Process(target=producer, args=('骨头', q)) p3 = Process(target=producer, args=('泔水', q)) # 消费者们:即吃货们 c1 = Process(target=consumer, args=(q,)) c2 = Process(target=consumer, args=(q,)) # 开始 p1.start() p2.start() p3.start() c1.start() p1.join() # 必须保证生产者全部生产完毕,才应该发送结束信号 p2.join() p3.join() q.put(None) # 有几个消费者就应该发送几次结束信号None q.put(None) # 发送结束信号 print('主')
23:JoinableQueue([maxsize])
创建可连接的共享进程队列。这就像是一个Queue对象,但队列允许项目的使用者通知生产者项目已经被成功处理。通知进程是使用共享的信号和条件变量来实现的。
# 方法介绍 JoinableQueue的实例p除了与Queue对象相同的方法之外,还具有以下方法: q.task_done() 使用者使用此方法发出信号,表示q.get()返回的项目已经被处理。如果调用此方法的次数大于从队列中删除的项目数量,将引发ValueError异常。 q.join() 生产者将使用此方法进行阻塞,直到队列中所有项目均被处理。阻塞将持续到为队列中的每个项目均调用q.task_done()方法为止。 下面的例子说明如何建立永远运行的进程,使用和处理队列上的项目。生产者将项目放入队列,并等待它们被处理。
# JoinableQueue队列实现消费之生产者模型 from multiprocessing import Process,JoinableQueue import time,random,os def consumer(q): while True: res=q.get() time.sleep(random.randint(1,3)) print('\033[45m%s 吃 %s\033[0m' %(os.getpid(),res)) q.task_done() #向q.join()发送一次信号,证明一个数据已经被取走了 def producer(name,q): for i in range(10): time.sleep(random.randint(1,3)) res='%s%s' %(name,i) q.put(res) print('\033[44m%s 生产了 %s\033[0m' %(os.getpid(),res)) q.join() #生产完毕,使用此方法进行阻塞,直到队列中所有项目均被处理。 if __name__ == '__main__': q=JoinableQueue() #生产者们:即厨师们 p1=Process(target=producer,args=('包子',q)) p2=Process(target=producer,args=('骨头',q)) p3=Process(target=producer,args=('泔水',q)) #消费者们:即吃货们 c1=Process(target=consumer,args=(q,)) c2=Process(target=consumer,args=(q,)) c1.daemon=True c2.daemon=True #开始 p_l=[p1,p2,p3,c1,c2] for p in p_l: p.start() p1.join() p2.join() p3.join() print('主') #主进程等--->p1,p2,p3等---->c1,c2 #p1,p2,p3结束了,证明c1,c2肯定全都收完了p1,p2,p3发到队列的数据 #因而c1,c2也没有存在的价值了,不需要继续阻塞在进程中影响主进程了。应该随着主进程的结束而结束,所以设置成守护进程就可以了。
24:进程之间的数据共享
展望未来,基于消息传递的并发编程是大势所趋
即便是使用线程,推荐做法也是将程序设计为大量独立的线程集合,通过消息队列交换数据。
这样极大地减少了对使用锁定和其他同步手段的需求,还可以扩展到分布式系统中。
但进程间应该尽量避免通信,即便需要通信,也应该选择进程安全的工具来避免加锁带来的问题。
以后我们会尝试使用数据库来解决现在进程之间的数据共享问题。
# Manager模块介绍 进程间数据是独立的,可以借助于队列或管道实现通信,二者都是基于消息传递的 虽然进程间数据独立,但可以通过Manager实现数据共享,事实上Manager的功能远不止于此 A manager object returned by Manager() controls a server process which holds Python objects and allows other processes to manipulate them using proxies. A manager returned by Manager() will support types list, dict, Namespace, Lock, RLock, Semaphore, BoundedSemaphore, Condition, Event, Barrier, Queue, Value and Array.
# Manager例子 from multiprocessing import Manager,Process,Lock def work(d,lock): with lock: #不加锁而操作共享的数据,肯定会出现数据错乱 d['count']-=1 if __name__ == '__main__': lock=Lock() with Manager() as m: dic=m.dict({'count':100}) p_l=[] for i in range(100): p=Process(target=work,args=(dic,lock)) p_l.append(p) p.start() for p in p_l: p.join() print(dic)
# mananger可以管理多个进程间共享的数据,比如一个字典,一个字符串,一个元组等数据
25:进程池和multiprocess.Pool模块
进程池
为什么要有进程池?进程池的概念。
在程序实际处理问题过程中,忙时会有成千上万的任务需要被执行,闲时可能只有零星任务。
那么在成千上万个任务需要被执行的时候,我们就需要去创建成千上万个进程么?首先,创建进程需要消耗时间,销毁进程也需要消耗时间。
第二即便开启了成千上万的进程,操作系统也不能让他们同时执行,这样反而会影响程序的效率。因此我们不能无限制的根据任务开启或者结束进程。那么我们要怎么做呢?
在这里,要给大家介绍一个进程池的概念,定义一个池子,在里面放上固定数量的进程,有需求来了,就拿一个池中的进程来处理任务,等到处理完毕,进程并不关闭,
而是将进程再放回进程池中继续等待任务。如果有很多任务需要执行,池中的进程数量不够,任务就要等待之前的进程执行任务完毕归来,
拿到空闲进程才能继续执行。也就是说,池中进程的数量是固定的,那么同一时间最多有固定数量的进程在运行。这样不会增加操作系统的调度难度,
还节省了开闭进程的时间,也一定程度上能够实现并发效果。
Pool([numprocess [,initializer [, initargs]]]):创建进程池 # 参数介绍 1 numprocess: 要创建的进程数,如果省略,将默认使用cpu_count()的值 2 initializer: 是每个工作进程启动时要执行的可调用对象,默认为None 3 initargs: 是要传给initializer的参数组
# 主要方法 1 p.apply(func [, args [, kwargs]]):在一个池工作进程中执行func(*args,**kwargs),然后返回结果。 2 '''需要强调的是:此操作并不会在所有池工作进程中并执行func函数。如果要通过不同参数并发地执行func函数,必须从不同线程调用p.apply()函数或者使用p.apply_async()''' 3 4 p.apply_async(func [, args [, kwargs]]):在一个池工作进程中执行func(*args,**kwargs),然后返回结果。 5 '''此方法的结果是AsyncResult类的实例,callback是可调用对象,接收输入参数。当func的结果变为可用时,将理解传递给callback。callback禁止执行任何阻塞操作,否则将接收其他异步操作中的结果。''' 6 7 p.close():关闭进程池,防止进一步操作。如果所有操作持续挂起,它们将在工作进程终止前完成 8 9 P.jion():等待所有工作进程退出。此方法只能在close()或teminate()之后调用
# 其他方法 异步返回的结果对象obj来调用 1 方法apply_async()和map_async()的返回值是AsyncResul的实例obj。实例具有以下方法 2 obj.get():返回结果,如果有必要则等待结果到达。timeout是可选的。如果在指定时间内还没有到达,将引发异常。如果远程操作中引发了异常,它将在调用此方法时再次被引发。 3 obj.ready():如果调用完成,返回True 4 obj.successful():如果调用完成且没有引发异常,返回True,如果在结果就绪之前调用此方法,引发异常 5 obj.wait([timeout]):等待结果变为可用。 6 obj.terminate():立即终止所有工作进程,同时不执行任何清理或结束任何挂起工作。如果p被垃圾回收,将自动调用此函数
# 进程池的同步调用
import os
import time
from multiprocessing import Pool
def work(n):
print('%s run' % os.getpid())
time.sleep(3)
return n**2
if __name__ == '__main__':
p = Pool(3) # 进程池中从无到有创建三个进程,以后一直是这三个进程在执行任务
res_l = []
for i in range(10):
res = p.apply(work, args=(i,)) # 同步调用,直到本次任务执行完毕拿到res,等待任务work执行的过程中可能有阻塞也可能没有阻塞
res_l.append(res) # 但不管该任务是否存在阻塞,同步调用都会在原地等着
print(res_l)
# 进程池的异步调用 import os import time import random from multiprocessing import Pool def work(n): print('%s run' %os.getpid()) time.sleep(random.random()) return n**2 if __name__ == '__main__': p=Pool(3) #进程池中从无到有创建三个进程,以后一直是这三个进程在执行任务 res_l=[] for i in range(10): res=p.apply_async(work,args=(i,)) # 异步运行,根据进程池中有的进程数,每次最多3个子进程在异步执行 # 返回结果之后,将结果放入列表,归还进程,之后再执行新的任务 # 需要注意的是,进程池中的三个进程不会同时开启或者同时结束 # 而是执行完一个就释放一个进程,这个进程就去接收新的任务。 res_l.append(res) # 异步apply_async用法:如果使用异步提交的任务,主进程需要使用jion,等待进程池内任务都处理完,然后可以用get收集结果 # 否则,主进程结束,进程池可能还没来得及执行,也就跟着一起结束了 p.close() p.join() # 阻塞主进程,等待三个进程运行结束 for res in res_l: print(res.get()) #使用get来获取apply_aync的结果,如果是apply,则没有get方法,因为apply是同步执行,立刻获取结果,也根本无需get
26:进程池版socket并发聊天
# server # Pool内的进程数默认是cpu核数,假设为4(查看方法os.cpu_count()) # 开启6个客户端,会发现2个客户端处于等待状态 # 在每个进程内查看pid,会发现pid使用为4个,即多个客户端公用4个进程 from socket import * from multiprocessing import Pool import os server=socket(AF_INET,SOCK_STREAM) server.setsockopt(SOL_SOCKET,SO_REUSEADDR,1) server.bind(('127.0.0.1',8080)) server.listen(5) def talk(conn): print('进程pid: %s' %os.getpid()) while True: try: msg=conn.recv(1024) if not msg:break conn.send(msg.upper()) except Exception: break if __name__ == '__main__': p=Pool(4) while True: conn,*_=server.accept() p.apply_async(talk,args=(conn,)) # p.apply(talk,args=(conn,client_addr)) #同步的话,则同一时间只有一个客户端能访问
# client from socket import * client=socket(AF_INET,SOCK_STREAM) client.connect(('127.0.0.1',8080)) while True: msg=input('>>: ').strip() if not msg:continue client.send(msg.encode('utf-8')) msg=client.recv(1024) print(msg.decode('utf-8'))
# 并发开启多个客户端,服务端同一时间只有4个不同的pid,只能结束一个客户端,另外一个客户端才会进来.
27:回调函数
需要回调函数的场景:进程池中任何一个任务一旦处理完了,就立即告知主进程:
我好了额,你可以处理我的结果了。主进程则调用一个函数去处理该结果,该函数即回调函数 我们可以把耗时间(阻塞)的任务放到进程池中,然后指定回调函数(主进程负责执行),
这样主进程在执行回调函数时就省去了I/O的过程,直接拿到的是任务的结果。
# 使用多进程请求多个url来减少网络等待浪费的时间 # 使用了回调函数parse_page,子进程完成后有了结果就回调这个parse_page这个函数 from multiprocessing import Pool import requests import json import os def get_page(url): print('<进程%s> get %s' % (os.getpid(), url)) respone = requests.get(url) if respone.status_code == 200: return {'url': url, 'text': respone.text} def pasrse_page(res): print('<进程%s> parse %s' % (os.getpid(), res['url'])) parse_res = 'url:<%s> size:[%s]\n' % (res['url'], len(res['text'])) with open('db.txt', 'a') as f: f.write(parse_res) if __name__ == '__main__': urls = [ 'https://www.baidu.com', 'https://www.python.org', 'https://www.openstack.org', 'https://help.github.com/', 'http://www.sina.com.cn/' ] p = Pool(3) res_l = [] for url in urls: res = p.apply_async(get_page, args=(url,), callback=pasrse_page) # callback启动回调函数,把pasrse_page传递进去,每个子进程运行函数有了结果后子进程再回调pasrse_page这个函数继续运行 res_l.append(res) p.close() p.join() print([res.get() for res in res_l]) # 拿到的是get_page的结果,其实完全没必要拿该结果,该结果已经传给回调函数处理了
'''
打印结果:
<进程3388> get https://www.baidu.com
<进程3389> get https://www.python.org
<进程3390> get https://www.openstack.org
<进程3388> get https://help.github.com/
<进程3387> parse https://www.baidu.com
<进程3389> get http://www.sina.com.cn/
<进程3387> parse https://www.python.org
<进程3387> parse https://help.github.com/
<进程3387> parse http://www.sina.com.cn/
<进程3387> parse https://www.openstack.org
[{'url': 'https://www.baidu.com', 'text': '<!DOCTYPE html>\r\n...',...}]
'''
28:异步多进程回调函数爬虫实例
import re from urllib.request import urlopen from multiprocessing import Pool def get_page(url, pattern): response = urlopen(url).read().decode('utf-8') return pattern, response def parse_page(info): pattern, page_content = info res = re.findall(pattern, page_content) for item in res: dic = { 'index': item[0].strip(), 'title': item[1].strip(), 'actor': item[2].strip(), 'time': item[3].strip(), } print(dic) if __name__ == '__main__': regex = r'<dd>.*?<.*?class="board-index.*?>(\d+)</i>.*?title="(.*?)".*?class="movie-item-info".*?<p class="star">(.*?)</p>.*?<p class="releasetime">(.*?)</p>' pattern1 = re.compile(regex, re.S) url_dic = { 'http://maoyan.com/board/7': pattern1, } p = Pool() res_l = [] for url, pattern in url_dic.items(): res = p.apply_async(get_page, args=(url, pattern), callback=parse_page) res_l.append(res) for i in res_l: print(1111) print(i.get()[-1])
29:无需回调函数
如果在主进程中等待进程池中所有任务都执行完毕后,再统一处理结果,则无需回调函数
# 无需回调函数版本 from multiprocessing import Pool import time,random,os def work(n): time.sleep(1) return n**2
if __name__ == '__main__': p=Pool() res_l=[] for i in range(10): res=p.apply_async(work,args=(i,)) res_l.append(res) p.close() p.join() #等待进程池中所有进程执行完毕 nums=[] for res in res_l: nums.append(res.get()) #拿到所有结果 print(nums) #主进程拿到所有的处理结果,可以在主进程中进行统一进行处理
30:线程概念的引入背景
进程
之前我们已经了解了操作系统中进程的概念,程序并不能单独运行,只有将程序装载到内存中,系统为它分配资源才能运行,而这种执行的程序就称之为进程。
程序和进程的区别就在于:程序是指令的集合,它是进程运行的静态描述文本;进程是程序的一次执行活动,属于动态概念。在多道编程中,
我们允许多个程序同时加载到内存中,在操作系统的调度下,可以实现并发地执行。这是这样的设计,大大提高了CPU的利用率。
进程的出现让每个用户感觉到自己独享CPU,因此,进程就是为了在CPU上实现多道编程而提出的
有了进程为什么要有线程
进程有很多优点,它提供了多道编程,让我们感觉我们每个人都拥有自己的CPU和其他资源,可以提高计算机的利用率。
很多人就不理解了,既然进程这么优秀,为什么还要线程呢?其实,仔细观察就会发现进程还是有很多缺陷的,主要体现在两点上:
进程只能在一个时间干一件事,如果想同时干两件事或多件事,进程就无能为力了。
进程在执行的过程中如果阻塞,例如等待输入,整个进程就会挂起,即使进程中有些工作不依赖于输入的数据,也将无法执行。
如果这两个缺点理解比较困难的话,举个现实的例子也许你就清楚了:如果把我们上课的过程看成一个进程的话,
那么我们要做的是耳朵听老师讲课,手上还要记笔记,脑子还要思考问题,这样才能高效的完成听课的任务。
而如果只提供进程这个机制的话,上面这三件事将不能同时执行,同一时间只能做一件事,听的时候就不能记笔记,也不能用脑子思考,
这是其一;如果老师在黑板上写演算过程,我们开始记笔记,而老师突然有一步推不下去了,阻塞住了,他在那边思考着,而我们呢,也不能干其他事,
即使你想趁此时思考一下刚才没听懂的一个问题都不行,这是其二。
现在你应该明白了进程的缺陷了,而解决的办法很简单,我们完全可以让听、写、思三个独立的过程,并行起来,
这样很明显可以提高听课的效率。而实际的操作系统中,也同样引入了这种类似的机制——线程。
线程的出现
60年代,在OS中能拥有资源和独立运行的基本单位是进程,然而随着计算机技术的发展,进程出现了很多弊端,
一是由于进程是资源拥有者,创建、撤消与切换存在较大的时空开销,因此需要引入轻型进程;
二是由于对称多处理机(SMP)出现,可以满足多个运行单位,而多个进程并行开销过大。
因此在80年代,出现了能独立运行的基本单位——线程(Threads)。
注意:进程是资源分配的最小单位,线程是CPU调度的最小单位.
每一个进程中至少有一个线程。
31: 线程与进程的区别
1)地址空间和其它资源(如打开文件):进程间相互独立,同一进程的各线程间共享。某进程内的线程在其它进程不可见。 2)通信:进程间通信IPC,线程间可以直接读写进程数据段(如全局变量)来进行通信——需要进程同步和互斥手段的辅助,以保证数据的一致性。 3)调度和切换:线程上下文切换比进程上下文切换要快得多。 4)在多线程操作系统中,进程不是一个可执行的实体。
比如主线程打开一个文件句柄,其他n个子线程和主线程都是共享这个文件句柄的,都是使用的一个文件句柄
但是主进程打印一个文件句柄,副进程之间和主进程不是共享的这个文件句柄,类似副进程copy了这个py文件的全部内容,代码copy,文件句柄copy,进程间使用的是不同的文件句柄,而不是共享
1:计算机的核心是CPU,它承担了所有的计算任务。它就像一座工厂,时刻在运行。 2:假定工厂的电力有限,一次只能供给一个车间使用。也就是说,一个车间开工的时候,
其他车间都必须停工。背后的含义就是,单个CPU一次只能运行一个任务 3:进程就好比工厂的车间,它代表CPU所能处理的单个任务。任一时刻,CPU总是运行一个进程,其他进程处于非运行状态。 4:一个车间里,可以有很多工人。他们协同完成一个任务。 5:线程就好比车间里的工人。一个进程可以包括多个线程。 6:车间的空间是工人们共享的,比如许多房间是每个工人都可以进出的。这象征一个进程的内存空间是共享的,每个线程都可以使用这些共享内存 7:可是,每间房间的大小不同,有些房间最多只能容纳一个人,比如厕所。里面有人的时候,其他人就不能进去了。
这代表一个线程使用某些共享内存时,其他线程必须等它结束,才能使用这一块内存。 8:一个防止他人进入的简单方法,就是门口加一把锁。先到的人锁上门,后到的人看到上锁,就在门口排队,等锁打开再进去。
这就叫"互斥锁"(Mutual exclusion,缩写 Mutex),防止多个线程同时读写某一块内存区域。 9:还有些房间,可以同时容纳n个人,比如厨房。也就是说,如果人数大于n,多出来的人只能在外面等着。这好比某些内存区域,只能供给固定数目的线程使用。 10:这时的解决方法,就是在门口挂n把钥匙。进去的人就取一把钥匙,出来时再把钥匙挂回原处。后到的人发现钥匙架空了,
就知道必须在门口排队等着了。这种做法叫做"信号量"(Semaphore),用来保证多个线程不会互相冲突。 不难看出,mutex是semaphore的一种特殊情况(n=1时)。也就是说,完全可以用后者替代前者。但是,
因为mutex较为简单,且效率高,所以在必须保证资源独占的情况下,还是采用这种设计。 11:操作系统的设计,因此可以归结为三点: (1)以多进程形式,允许多个任务同时运行; (2)以多线程形式,允许单个任务分成不同的部分运行; (3)提供协调机制,一方面防止进程之间和线程之间产生冲突,另一方面允许进程之间和线程之间共享资源。
32:线程的特点
在多线程的操作系统中,通常是在一个进程中包括多个线程,每个线程都是作为利用CPU的基本单位,是花费最小开销的实体。线程具有以下属性。 1)轻型实体 线程中的实体基本上不拥有系统资源,只是有一点必不可少的、能保证独立运行的资源。 线程的实体包括程序、数据和TCB。线程是动态概念,它的动态特性由线程控制块TCB(Thread Control Block)描述。
TCB包括以下信息: (1)线程状态。 (2)当线程不运行时,被保存的现场资源。 (3)一组执行堆栈。 (4)存放每个线程的局部变量主存区。 (5)访问同一个进程中的主存和其它资源。 用于指示被执行指令序列的程序计数器、保留局部变量、少数状态参数和返回地址等的一组寄存器和堆栈。
3)共享进程资源。
33:使用线程的实际场景
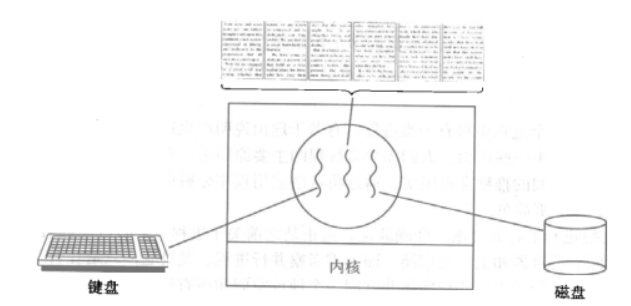
开启一个字处理软件进程,该进程肯定需要办不止一件事情,比如监听键盘输入,处理文字,定时自动将文字保存到硬盘,
这三个任务操作的都是同一块数据,因而不能用多进程。只能在一个进程里并发地开启三个线程,
如果是单线程,那就只能是,键盘输入时,不能处理文字和自动保存,自动保存时又不能输入和处理文字。
34:内存中的线程
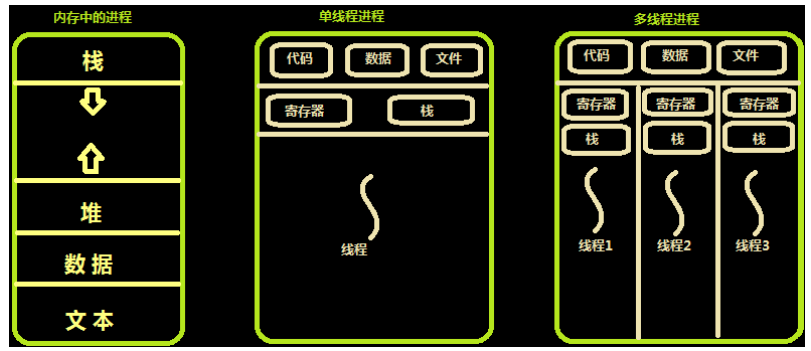
多个线程共享同一个进程的地址空间中的资源,是对一台计算机上多个进程的模拟,有时也称线程为轻量级的进程。 而对一台计算机上多个进程,则共享物理内存、磁盘、打印机等其他物理资源。多线程的运行也多进程的运行类似,是cpu在多个线程之间的快速切换。 不同的进程之间是充满敌意的,彼此是抢占、竞争cpu的关系,如果迅雷会和QQ抢资源。而同一个进程是由一个程序员的程序创建,所以同一进程内的线程是合作关系,
一个线程可以访问另外一个线程的内存地址,大家都是共享的,一个线程干死了另外一个线程的内存,那纯属程序员脑子有问题。 类似于进程,每个线程也有自己的堆栈,不同于进程,线程库无法利用时钟中断强制线程让出CPU,可以调用thread_yield运行线程自动放弃cpu,让另外一个线程运行。
线程通常是有益的,但是带来了不小程序设计难度,线程的问题是: 1. 父进程有多个线程,那么开启的子线程是否需要同样多的线程 2. 在同一个进程中,如果一个线程关闭了文件,而另外一个线程正准备往该文件内写内容呢? 因此,在多线程的代码中,需要更多的心思来设计程序的逻辑、保护程序的数据。
35:用户级线程和内核级线程
线程的实现可以分为两类:用户级线程(User-Level Thread)和内核线线程(Kernel-Level Thread),
后者又称为内核支持的线程或轻量级进程。在多线程操作系统中,各个系统的实现方式并不相同,在有的系统中实现了用户级线程,有的系统中实现了内核级线程。
用户级线程
内核的切换由用户态程序自己控制内核切换,不需要内核干涉,少了进出内核态的消耗,但不能很好的利用多核Cpu。
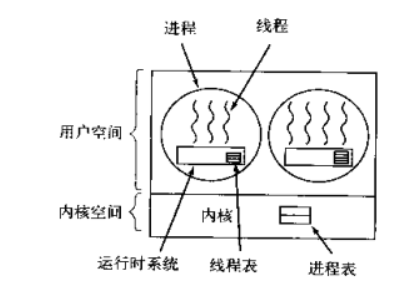
在用户空间模拟操作系统对进程的调度,来调用一个进程中的线程,每个进程中都会有一个运行时系统,用来调度线程。
此时当该进程获取cpu时,进程内再调度出一个线程去执行,同一时刻只有一个线程执行。
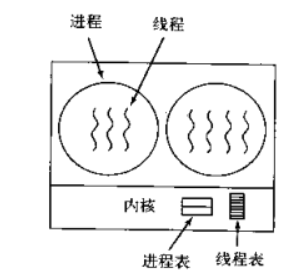
内核级线程
内核级线程:切换由内核控制,当线程进行切换的时候,由用户态转化为内核态。
切换完毕要从内核态返回用户态;可以很好的利用smp,即利用多核cpu。windows线程就是这样的。
36:用户级与内核级线程的对比
用户级线程和内核级线程的区别
内核支持线程是OS内核可感知的,而用户级线程是OS内核不可感知的。
用户级线程的创建、撤消和调度不需要OS内核的支持,是在语言(如Java)这一级处理的;而内核支持线程的创建、撤消和调度都需OS内核提供支持,而且与进程的创建、撤消和调度大体是相同的。
用户级线程执行系统调用指令时将导致其所属进程被中断,而内核支持线程执行系统调用指令时,只导致该线程被中断。
在只有用户级线程的系统内,CPU调度还是以进程为单位,处于运行状态的进程中的多个线程,由用户程序控制线程的轮换运行;在有内核支持线程的系统内,CPU调度则以线程为单位,由OS的线程调度程序负责线程的调度。
用户级线程的程序实体是运行在用户态下的程序,而内核支持线程的程序实体则是可以运行在任何状态下的程序。
内核线程的优缺点
优点:当有多个处理机时,一个进程的多个线程可以同时执行。
缺点:由内核进行调度。
用户级线程的优缺点
优点:
线程的调度不需要内核直接参与,控制简单。
可以在不支持线程的操作系统中实现。
创建和销毁线程、线程切换代价等线程管理的代价比内核线程少得多。
允许每个进程定制自己的调度算法,线程管理比较灵活。
线程能够利用的表空间和堆栈空间比内核级线程多。
同一进程中只能同时有一个线程在运行,如果有一个线程使用了系统调用而阻塞,那么整个进程都会被挂起。另外,页面失效也会产生同样的问题。
缺点:
资源调度按照进程进行,多个处理机下,同一个进程中的线程只能在同一个处理机下分时复用
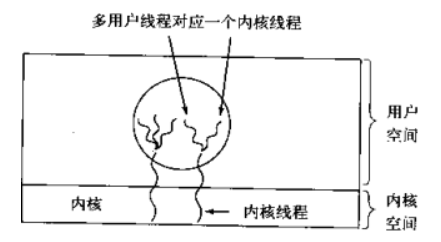
37:混合实现
用户级与内核级的多路复用,内核同一调度内核线程,每个内核线程对应n个用户线程
38:linux操作系统的 NPTL
历史 在内核2.6以前的调度实体都是进程,内核并没有真正支持线程。它是能过一个系统调用clone()来实现的,
这个调用创建了一份调用进程的拷贝,跟fork()不同的是,这份进程拷贝完全共享了调用进程的地址空间。
LinuxThread就是通过这个系统调用来提供线程在内核级的支持的(许多以前的线程实现都完全是在用户态,
内核根本不知道线程的存在)。非常不幸的是,这种方法有相当多的地方没有遵循POSIX标准,特别是在信号处理,调度,进程间通信原语等方面。 很显然,为了改进LinuxThread必须得到内核的支持,并且需要重写线程库。为了实现这个需求,开始有两个相互竞争的项目:
IBM启动的NGTP(Next Generation POSIX Threads)项目,以及Redhat公司的NPTL。在2003年的年中,
IBM放弃了NGTP,也就是大约那时,Redhat发布了最初的NPTL。 NPTL最开始在redhat linux 9里发布,现在从RHEL3起内核2.6起都支持NPTL,并且完全成了GNU C库的一部分。 设计 NPTL使用了跟LinuxThread相同的办法,在内核里面线程仍然被当作是一个进程,并且仍然使用了clone()系统调用(在NPTL库里调用)。
但是,NPTL需要内核级的特殊支持来实现,比如需要挂起然后再唤醒线程的线程同步原语futex. NPTL也是一个1*1的线程库,就是说,当你使用pthread_create()调用创建一个线程后,在内核里就相应创建了一个调度实体,
在linux里就是一个新进程,这个方法最大可能的简化了线程的实现。 除NPTL的1*1模型外还有一个m*n模型,通常这种模型的用户线程数会比内核的调度实体多。在这种实现里,线程库本身必须去处理可能存在的调度,
这样在线程库内部的上下文切换通常都会相当的快,因为它避免了系统调用转到内核态。然而这种模型增加了线程实现的复杂性,并可能出现诸如优先级反转的问题,
此外,用户态的调度如何跟内核态的调度进行协调也是很难让人满意。
39:全局解释器锁GIL
Python代码的执行由Python虚拟机(也叫解释器主循环)来控制。Python在设计之初就考虑到要在主循环中,
同时只有一个线程在执行。虽然 Python 解释器中可以“运行”多个线程,但在任意时刻只有一个线程在解释器中运行。 对Python虚拟机的访问由全局解释器锁(GIL)来控制,正是这个锁能保证同一时刻只有一个线程在运行。 在多线程环境中,Python 虚拟机按以下方式执行: a、设置 GIL; b、切换到一个线程去运行; c、运行指定数量的字节码指令或者线程主动让出控制(可以调用 time.sleep(0)); d、把线程设置为睡眠状态; e、解锁 GIL; d、再次重复以上所有步骤。 在调用外部代码(如 C/C++扩展函数)的时候,GIL将会被锁定,直到这个函数结束为止(由于在这期间没有Python的字节码被运行,所以不会做线程切换)编写扩展的程序员可以主动解锁GIL。
40:python线程模块的选择
Python提供了几个用于多线程编程的模块,包括thread、threading和Queue等。thread和threading模块允许程序员创建和管理线程。
thread模块提供了基本的线程和锁的支持,threading提供了更高级别、功能更强的线程管理的功能。
Queue模块允许用户创建一个可以用于多个线程之间共享数据的队列数据结构。
避免使用thread模块,因为更高级别的threading模块更为先进,对线程的支持更为完善,而且使用thread模块里的属性有可能会与threading出现冲突;
其次低级别的thread模块的同步原语很少(实际上只有一个),而threading模块则有很多;再者,
thread模块中当主线程结束时,所有的线程都会被强制结束掉,没有警告也不会有正常的清除工作,
至少threading模块能确保重要的子线程退出后进程才退出。
thread模块不支持守护线程,当主线程退出时,所有的子线程不论它们是否还在工作,都会被强行退出。而threading模块支持守护线程,
守护线程一般是一个等待客户请求的服务器,如果没有客户提出请求它就在那等着,如果设定一个线程为守护线程,
就表示这个线程是不重要的,在进程退出的时候,不用等待这个线程退出。
41:python的threading模块
multiprocess模块的完全模仿了threading模块的接口,二者在使用层面,有很大的相似性
42:线程的创建
# 线程的创建方式一 Thread函数模块的编写 from threading import Thread import time def sayhi(name): time.sleep(2) print('%s say hello' %name) if __name__ == '__main__': t=Thread(target=sayhi,args=('egon',)) t.start() print('主线程')
# 创建线程的方式2 继承Thread重构run方法来实现 from threading import Thread import time class MyThread(Thread): def __init__(self, func, args, name=""): # Thread.__init__(self) super().__init__() self.func = func self.args = args self.name = name def run(self): res = self.func(*self.args) print(self.name) def func(name): time.sleep(3) print(f"我的名字叫做{name}") if __name__ == '__main__': t1 = MyThread(func, ("李二狗",), func.__name__) t1.start() print("我是主线程啊")
43:多线程和多进程
# pid的比较 # 不同进程拥有不同的pid,同一进程的所有线程pi相同 from threading import Thread from multiprocessing import Process import os def func(info): print(f"当前的{info}pid:{os.getpid()}") if __name__ == '__main__': #part1:在主进程下开启多个线程,每个线程都跟主进程的pid一样 t1 = Thread(target=func, args=("线程1",)) t2 = Thread(target=func, args=("线程2",)) t1.start() t2.start() print(f"主线程/主进程{os.getpid()}") #part2:开多个进程,每个进程都有不同的pid p1 = Process(target=func, args=("进程1",)) p2 = Process(target=func, args=("进程2",)) p1.start() p2.start()
# 多线程和多进程开启效率的较量 from threading import Thread from multiprocessing import Process def work(): print('hello') if __name__ == '__main__': # 在主进程下开启线程 t = Thread(target=work) t.start() print('主线程/主进程') ''' 打印结果: hello 主线程/主进程 ''' # 在主进程下开启子进程 t = Process(target=work) t.start() print('主线程/主进程') ''' 打印结果: 主线程/主进程 hello '''
# 可以看出进程的开辟比线程需要更长的时间
# 内存数据的共享问题
# 主进程和子进程之间的数据是相互独立的,子进程copy主进程的全部代码和变量后内部改变了变量n是不会影响到主进程的
# 子线程和主线程共用的都是主进程的资源,子线程改变的n变量就是主进程里的变量,主线程和子线程共用主进程的变量,所有子线程改变变量n后,打印主进程资源的n会改变 from threading import Thread from multiprocessing import Process import os def work(): global n n = 0 if __name__ == '__main__': n=100 p=Process(target=work) p.start() p.join() print('主',n) # 毫无疑问,子进程p已经将自己的全局的n改成了0,但改的仅仅是它自己的,查看父进程的n仍然为100 # n = 1 # t = Thread(target=work) # t.start() # t.join() # print('主', n) # 查看结果为0,因为同一进程内的线程之间共享进程内的数据 # # 同一进程内的线程共享该进程的数据?
44:多线程实现socket
# server服务端 import threading import socket sk = socket.socket(socket.AF_INET, socket.SOCK_STREAM) # 创建一个基于网络tcp的套接字 sk.bind(("127.0.0.1", 8888)) print("服务器启动成功,等待连接") sk.listen(5) def acttion(conn): while 1: data = conn.recv(1024) print(data) conn.send(data.upper()) if __name__ == '__main__': while 1: conn, addr = sk.accept() print(f"有一个客户连接进来,客户是{addr}") t1 = threading.Thread(target=acttion, args=(conn,)) t1.start()
# client 客户端 import socket sk = socket.socket(socket.AF_INET, socket.SOCK_STREAM) sk.connect(("127.0.0.1", 8888)) while 1: sk.send(input(">>>>>").encode("utf8")) res = sk.recv(1024) print(res.decode("utf8"))
45:Thread类的其他方法
Thread实例对象的方法 # isAlive(): 返回线程是否活动的。 # getName(): 返回线程名。 # setName(): 设置线程名。 threading模块提供的一些方法: # threading.currentThread(): 返回当前的线程变量。当前哪个线程占据cpu正在运行 # threading.enumerate(): 返回一个包含正在运行的线程的list。正在运行指线程启动后、结束前,不包括启动前和终止后的线程。 # threading.activeCount(): 返回正在运行的线程数量,与len(threading.enumerate())有相同的结果。
# Thread其他方法代码示例 import threading import time def work(): time.sleep(3) print(threading.currentThread().getName()) # 打印Thread-1 if __name__ == '__main__': t1 = threading.Thread(target=work) t1.start() print(threading.currentThread().getName()) # 打印MainThread print(threading.currentThread()) # 打印<_MainThread(MainThread, started 14300)> print(threading.enumerate()) # 打印:[<_MainThread(MainThread, started 14300)>, <Thread(Thread-1, started 2916)>]连同主线程在内有两个运行的线程 print(threading.active_count()) # 打印 2 print('主线程/主进程')
46:thread模块join的用法
from threading import Thread import time def sayhi(name): time.sleep(2) print('%s say hello' %name) if __name__ == '__main__': t=Thread(target=sayhi,args=('egon',)) t.start() t.join() print('主线程') print(t.is_alive())
# t.join 在主线程里执行,t代表子线程,t这个子线程不运行完成主线程就一直阻塞,直到t运行结束主线程才继续运行
47:守护线程:
守护线程就是不重要的进程,threading模块创建的子进程,默认主线程都会等待子线程运行结束后主线程才结束
但是如果把threading模块创建的子线程设置成守护线程的话,主线程运行完毕后子线程被销毁
无论是进程还是线程,都遵循:守护xx会等待主xx运行完毕后被销毁。需要强调的是:运行完毕并非终止运行
#1.对主进程来说,运行完毕指的是主进程代码运行完毕
#2.对主线程来说,运行完毕指的是主线程所在的进程内所有非守护线程统统运行完毕,主线程才算运行完毕
#1 主进程在其代码结束后就已经算运行完毕了(守护进程在此时就被回收),然后主进程会一直等非守护的子进程都运行完毕后回收子进程的资源(否则会产生僵尸进程),才会结束, #2 主线程在其他非守护线程运行完毕后才算运行完毕(守护线程在此时就被回收)。因为主线程的结束意味着进程的结束,进程整体的资源都将被回收,而进程必须保证非守护线程都运行完毕后才能结束
# 守护线程实例一 from threading import Thread import time def sayhi(name): time.sleep(2) print('%s say hello' %name) if __name__ == '__main__': t = Thread(target=sayhi, args=('egon',)) t.setDaemon(True) # setDaemon设置守护线程必须在t.start()启动之前设置 t.start() print('主线程') print(t.is_alive())
此时不会打印sayhi里面的print,因为t设置了守护线程,主线程不需要等待t运行结束才结束,直接提前运行结束,主线程结束那么进程就结束,进程资源回收
# 守护线程实例二 from threading import Thread import time def foo(): print(123) time.sleep(1) print("end123") def bar(): print(456) time.sleep(3) print("end456") t1 = Thread(target=foo) t2 = Thread(target=bar) t2.daemon = True # 设置t2为守护线程,也就是bar函数执行的时候为守护线程 t1.start() t2.start() print("main-------")
48:锁与GIL
49:同步锁
# 多个线程抢占资源的情况 from threading import Thread import os import time def work(): global n temp = n time.sleep(0.1) # 让一个时间片内无法运行完整个线程,全部线程每个都拿到n了,100个线程的temp都等于100了 # 而不是第一个线程拿到n=100后n-1变成99,下一个线程拿到99继续减少1变成98 # 而是100个线程全部拿到100了,然后每个线程n=100 - 1所以n = 99 n = temp-1 print(n) if __name__ == '__main__': n = 100 l = [] # 存放所有的线程 for i in range(100): p = Thread(target=work) l.append(p) p.start() for p in l: # 子线程不运行完主线程阻塞 p.join() print(n) # 结果可能为99 # print(l)
# 同步锁Lock的使用 import threading R=threading.Lock() R.acquire() ''' 对公共数据的操作 ''' R.release()
# 同步锁的引用 import threading def work(r): r.acquire() global n temp = n n = temp-1 print(n) r.release() if __name__ == '__main__': r = threading.Lock() n = 100 l = [] for i in range(100): p = threading.Thread(target=work, args=(r,)) l.append(p) p.start() for p in l: p.join() print(n)
# 同步锁的引用2 from threading import Thread,Lock import os,time def work(): global n lock.acquire() temp = n n = temp-1 lock.release() if __name__ == '__main__': lock=Lock() n=100 l = [] for i in range(100): p=Thread(target=work) l.append(p) p.start() for p in l: p.join() print(n) # 结果肯定为0,由原来的并发执行变成串行,牺牲了执行效率保证了数据安全
# 原理就是lock锁上锁后需要解锁才会继续运行,lock.acquire()上锁后又lock.acquire()会阻塞子线程的代码,等到release解锁后阻塞的子线程才会继续运行
50:互斥锁与join的区别
# 不加锁:并发执行,速度快,数据不安全 from threading import current_thread,Thread,Lock import os,time def task(): global n print('%s is running' %current_thread().getName())
print(n) temp=n time.sleep(0.5) n=temp-1 if __name__ == '__main__': n=100 lock=Lock() threads=[] start_time=time.time() for i in range(100): t=Thread(target=task) threads.append(t) t.start() for t in threads: t.join() stop_time=time.time() print('主:%s n:%s' %(stop_time-start_time,n))
# 100个线程,因为sleep了0.5s,所以100个线程都拿到了n=100,然后内部线程n=n-1,n=99,n数据同时被100个线程拿到并且进行修改,不安全
# 但是运行速度是100个线程并行,并且遇到io阻塞就切换到下个线程执行,速度很快
# 不加锁:未加锁部分并发执行,加锁部分串行执行,速度慢,数据安全 from threading import current_thread,Thread,Lock import os,time def task(): #未加锁的代码并发运行 time.sleep(3) print('%s start to run' %current_thread().getName()) global n #加锁的代码串行运行 lock.acquire() temp=n time.sleep(0.5) n=temp-1 lock.release() if __name__ == '__main__': n=100 lock=Lock() threads=[] start_time=time.time() for i in range(100): t=Thread(target=task) threads.append(t) t.start() for t in threads: t.join() stop_time=time.time() print('主:%s n:%s' %(stop_time-start_time,n))
# 没有加锁的print打印代码是并发运行的,可能出现多个打印在一行如:Thread-15 start to runThread-21 start to run
# 加锁的代码是对n累减的操作,加锁的代码是串行运行的,线程1加锁了能对n这些代码进行操作,
# 线程2必须阻塞等待线程1运行完释放锁之后才能运行加锁和解锁中间的代码,同理线程3,线程4...
#可能有疑问:既然加锁会让运行变成串行,那么我在start之后立即使用join,就不用加锁了啊,也是串行的效果啊 #没错:在start之后立刻使用jion,肯定会将100个任务的执行变成串行,毫无疑问,最终n的结果也肯定是0,是安全的,但问题是 #start后立即join:任务内的所有代码都是串行执行的,而加锁,只是加锁的部分即修改共享数据的部分是串行的 #单从保证数据安全方面,二者都可以实现,但很明显是加锁的效率更高. from threading import current_thread,Thread,Lock import os,time def task(): time.sleep(3) print('%s start to run' %current_thread().getName()) global n temp=n time.sleep(0.01) n=temp-1 if __name__ == '__main__': n=100 lock=Lock() start_time=time.time() for i in range(100): t=Thread(target=task) t.start() t.join() stop_time=time.time() print('主:%s n:%s' %(stop_time-start_time,n))
# 耗时比并行更高,因为线程的一个个创建和销毁需要浪费时间,这里相当于一个线程跑完了又创建一个线程跑,效率更慢,
# 如果100个线程一起创建,cpu轮询一个个去创建速度很快,如果创建一个等着运行完又创建一个等着继续运行速度会慢的
51:死锁与递归锁 Rlock可重入锁
进程也有死锁与递归锁,
死锁: 是指两个或两个以上的进程或线程在执行过程中,因争夺资源而造成的一种互相等待的现象,若无外力作用,它们都将无法推进下去。
此时称系统处于死锁状态或系统产生了死锁,这些永远在互相等待的进程称为死锁进程,如下就是死锁
# 死锁 from threading import Lock as Lock import time mutexA=Lock() mutexA.acquire() mutexA.acquire() print(123) mutexA.release() mutexA.release()
死锁的解决方法,递归锁,在Python中为了支持在同一线程中多次请求同一资源,python提供了可重入锁RLock。
这个RLock内部维护着一个Lock和一个counter变量,counter记录了acquire的次数,从而使得资源可以被多次require。
直到一个线程所有的acquire都被release,其他的线程才能获得资源。上面的例子如果使用RLock代替Lock,则不会发生死锁:
# 递归锁RLock from threading import RLock as Lock import time mutexA=Lock() mutexA.acquire() mutexA.acquire() print(123) mutexA.release() mutexA.release()
# 死锁问题 # 典型问题:科学家吃面 import time from threading import Thread,Lock noodle_lock = Lock() fork_lock = Lock() def eat1(name): noodle_lock.acquire() print('%s 抢到了面条'%name) time.sleep(1) fork_lock.acquire() print('%s 抢到了叉子'%name) print('%s 吃面'%name) fork_lock.release() noodle_lock.release() def eat2(name): fork_lock.acquire() print('%s 抢到了叉子' % name) time.sleep(1) noodle_lock.acquire() print('%s 抢到了面条' % name) print('%s 吃面' % name) noodle_lock.release() fork_lock.release() for name in ['哪吒','egon','yuan']: t1 = Thread(target=eat1,args=(name,)) t2 = Thread(target=eat2,args=(name,)) t1.start() t2.start()
# for name in ['哪吒','egon','yuan']: t1 t2表示开启6个线程,t1和t2创建,t1和t2并发运行
# t1运行eat1,t2运行eat2,t1使用noodle_lock这把锁上锁了,然后t1打印 抢到了面条,t1遇到io阻塞马上跳转到t2线程
# t2线程开始运行,t2使用fork_lock这个锁上锁了,然后t2打印 抢到了叉子,t2遇到io阻塞,生下来的t3,t4,t5,t6线程开始运行,
# 但是现在t1和t2把noodle和fork两把锁都上锁了,没有释放锁,所以t3,t4,t5,t6四个线程全部阻塞
# 现在t1等了1s等待时间开始运行了,t1把noodle这个锁上锁了,现在又需要把fork这把锁上锁,但是fork这把锁被t2上锁了暂时没有解锁,所以t1暂时阻塞
# 现在t2也等待了1s开始运行,t2把fork这把锁上锁了,又需要noodle这把锁上锁,但是noodle被t1上锁了还没释放,所以t2也阻塞
# t1把noodle上锁了又马上要上锁fork,也不把noddle解锁,等待t2把fork解锁
# t2把fork上锁了又马上要上锁noodle,也不把fork解锁,等待t1把noodle解锁
# 所以t1等t2解锁,t2等t1解锁,t3,t4,t5,t6也全部等两把锁释放,全部阻塞,死锁发生了
# 递归锁解决死锁问题Rlock,可重入锁 import time from threading import Thread,RLock fork_lock = noodle_lock = RLock() def eat1(name): noodle_lock.acquire() print('%s 抢到了面条'%name) fork_lock.acquire() print('%s 抢到了叉子'%name) print('%s 吃面'%name) fork_lock.release() noodle_lock.release() def eat2(name): fork_lock.acquire() print('%s 抢到了叉子' % name) time.sleep(1) noodle_lock.acquire() print('%s 抢到了面条' % name) print('%s 吃面' % name) noodle_lock.release() fork_lock.release() for name in ['哪吒','egon','yuan']: t1 = Thread(target=eat1,args=(name,)) t2 = Thread(target=eat2,args=(name,)) t1.start() t2.start()
# 现在相当于6个线程并行执行,t1线程和t2线程开启运行,t1线程上锁,t1线程打印,t1线程继续上锁,锁了两次
# t2线程看到锁的计数器里有两个,t1线程锁了两次,所以t2现在立马阻塞,等t1线程把两个锁释放t2线程才运行,同理,t2线程把锁上锁两次
# t3看到t2锁了两次立马阻塞等t2两个锁释放才允许,同理t4,t5,t6,
# 所以现在t1,t2,t3,t4,t5,t6六个线程都是串行运行的,主线程开启所有的线程后就处于等待六个子线程运行结束的状态
52:线程队列
queue队列 :使用import queue,用法与进程Queue一样 queue is especially useful in threaded programming when information must be exchanged safely between multiple threads.
queue.Queue(maxsize=0) # 先进先出线程队列 import queue q=queue.Queue() q.put('first') q.put('second') q.put('third') print(q.get()) print(q.get()) print(q.get()) ''' 结果(先进先出): first second third '''
queue.LifoQueue(maxsize=0) # 后进先出队列 import queue q=queue.LifoQueue() q.put('first') q.put('second') q.put('third') print(q.get()) print(q.get()) print(q.get()) ''' 结果(后进先出): third second first '''
# queue.PriorityQueue(maxsize=0) 存储数据时可设置优先级的队列 import queue q=queue.PriorityQueue() #put进入一个元组,元组的第一个元素是优先级(通常是数字,也可以是非数字之间的比较),数字越小优先级越高 q.put((20,'a')) q.put((10,'b')) q.put((30,'c')) print(q.get()) print(q.get()) print(q.get()) ''' 结果(数字越小优先级越高,优先级高的优先出队): (10, 'b') (20, 'a') (30, 'c') '''
# 更多方法说明 Constructor for a priority queue. maxsize is an integer that sets the upperbound limit on
the number of items that can be placed in the queue. Insertion will block once this size
has been reached, until queue items are consumed. If maxsize is less than or equal to zero, the queue size is infinite. The lowest valued entries are retrieved first (the lowest valued entry is the one
returned by sorted(list(entries))[0]). A typical pattern
for entries is a tuple in the form: (priority_number, data). exception queue.Empty Exception raised when non-blocking get() (or get_nowait()) is called on a Queue object which is empty. exception queue.Full Exception raised when non-blocking put() (or put_nowait()) is called on a Queue object which is full. Queue.qsize() Queue.empty() #return True if empty Queue.full() # return True if full Queue.put(item, block=True, timeout=None) Put item into the queue. If optional args block is true and timeout is None (the default),
block if necessary until a free slot is available. If timeout is a positive number,
it blocks at most timeout seconds and raises the Full exception if no free slot was available
within that time. Otherwise (block is false), put an item on the queue if a free slot is
immediately available, else raise the Full exception (timeout is ignored in that case). Queue.put_nowait(item) Equivalent to put(item, False). Queue.get(block=True, timeout=None) Remove and return an item from the queue. If optional args block is true and timeout is None (the default),
block if necessary until an item is available. If timeout is a positive number,
it blocks at most timeout seconds and raises the Empty exception if no item was
available within that time. Otherwise (block is false), return an item if
one is immediately available, else raise the Empty exception (timeout is ignored in that case). Queue.get_nowait() Equivalent to get(False). Two methods are offered to support tracking whether enqueued tasks have been fully processed by daemon consumer threads. Queue.task_done() Indicate that a formerly enqueued task is complete. Used by queue consumer threads.
For each get() used to fetch a task, a subsequent call to task_done() tells the
queue that the processing on the task is complete. If a join() is currently blocking, it will resume when all items have been processed
(meaning that a task_done() call was received for every item that had been put() into the queue). Raises a ValueError if called more times than there were items placed in the queue. Queue.join() block直到queue被消费完毕
53:Python标准模块--concurrent.futures
#1 介绍 concurrent.futures模块提供了高度封装的异步调用接口 ThreadPoolExecutor: 线程池,提供异步调用 ProcessPoolExecutor: 进程池,提供异步调用 Both implement the same interface, which is defined by the abstract Executor class. #2 基本方法 #submit(fn, *args, **kwargs) 异步提交任务 #map(func, *iterables, timeout=None, chunksize=1) 取代for循环submit的操作 #shutdown(wait=True) 相当于进程池的pool.close()+pool.join()操作 wait=True,等待池内所有任务执行完毕回收完资源后才继续 wait=False,立即返回,并不会等待池内的任务执行完毕 但不管wait参数为何值,整个程序都会等到所有任务执行完毕 submit和map必须在shutdown之前 #result(timeout=None) 取得结果:result方法可以获取task的执行结果, 这个方法是阻塞的,阻塞在这里等待线程运行完成给了结果再运行下一个#add_done_callback(fn) 回调函数 # done() 判断某一个线程是否完成 task1.done() # cancle() 取消某个任务
# ProcessPoolExecutor
#介绍
ProcessPoolExecutor类是使用异步执行调用的进程。ProcessPoolExecutor使用多处理模块,
允许它绕过全局解释器但也意味着只能执行和返回可拾取的对象。
类concurrent.futures.ProcessPoolExecutor(max_workers=None,mp_context=None)
一个Executor子类,它使用最多max个进程的池异步执行调用。
如果max_workers没有或没有给定,它将默认为机器上的处理器数。
如果max_workers小于或等于0,则会引发ValueError。
#用法 from concurrent.futures import ThreadPoolExecutor,ProcessPoolExecutor import os,time,random def task(n): print('%s is runing' %os.getpid()) time.sleep(random.randint(1,3)) return n**2 if __name__ == '__main__': executor=ProcessPoolExecutor(max_workers=3) # 创建一个进程池塘,最大数目为3 futures=[] for i in range(11): future=executor.submit(task,i) # submit指定任务和参数 futures.append(future) executor.shutdown(True) # 关闭进程池 print('+++>') for future in futures: print(future.result())
# ThreadPoolExecutor #介绍
ThreadPoolExecutor是一个Executor子类它使用线程池异步执行调用。
类concurrent.futures.ThreadPoolExecutor(max_workers=None,thread_name_prefix='')
一个Executor子类,它最多使用一个max_workers线程池来异步执行调用。。
在版本3.5中发生了更改:如果max_workers是None或not given,它将默认为服务器上的处理器数机器乘以5,
假设ThreadPoolExecutor经常用于重叠I/O而不是CPU工时和工作线程数应高于ProcessPoolExecutor的工作线程数。
版本3.6中的新功能:添加了thread_name_prefix参数以允许用户控制
线程池创建的工作线程的线程名称,以便于调试
#用法 与ProcessPoolExecutor相同
# map的用法 from concurrent.futures import ThreadPoolExecutor,ProcessPoolExecutor import os,time,random def task(n): print('%s is runing' %os.getpid()) time.sleep(random.randint(1,3)) return n**2 if __name__ == '__main__': executor=ThreadPoolExecutor(max_workers=3) # for i in range(11): # future=executor.submit(task,i) executor.map(task,range(1,12)) # map取代了for+submit, 相当于开始11个线程,是一个线程绑定task这个函数,传递的task参数是range(1,12)这个遍历取值
# 回调函数 from concurrent.futures import ThreadPoolExecutor,ProcessPoolExecutor from multiprocessing import Pool import requests import json import os def get_page(url): print('<进程%s> get %s' %(os.getpid(),url)) respone=requests.get(url) if respone.status_code == 200: return {'url':url,'text':respone.text} def parse_page(res): res=res.result() print('<进程%s> parse %s' %(os.getpid(),res['url'])) parse_res='url:<%s> size:[%s]\n' %(res['url'],len(res['text'])) with open('db.txt','a') as f: f.write(parse_res) if __name__ == '__main__': urls=[ 'https://www.baidu.com', 'https://www.python.org', 'https://www.openstack.org', 'https://help.github.com/', 'http://www.sina.com.cn/' ] # p=Pool(3) # for url in urls: # p.apply_async(get_page,args=(url,),callback=pasrse_page) # p.close() # p.join() p=ProcessPoolExecutor(3) for url in urls: p.submit(get_page,url).add_done_callback(parse_page)
# parse_page拿到的是一个future对象obj,需要用obj.result()拿到结果
# ThreadPoolExecutor使用submit取值是阻塞类型的,阻塞住主线程 # 运行效率很低 from concurrent.futures import ThreadPoolExecutor import time import random def work(n, j): print(f"线程{n}正在运行") time.sleep(1) return j**2 if __name__ == '__main__': excutor = ThreadPoolExecutor(max_workers=3) for i in range(1, 12): res = excutor.submit(work, n=i, j=i+1) print(res.result())
# 这样相当于11次函数串行运行,result是阻塞调用,没有结果就会一直阻塞主线程,所有总运行时间需要11.97s,时间很长
# 如果不再for循环使用result一直取值阻塞,而是先把结果存储到列表里慢慢,一次性取值,速度可以提示很多 from concurrent.futures import ThreadPoolExecutor import time def work(n, j): print(f"线程{n}正在运行") time.sleep(1) return j**2 if __name__ == '__main__': excutor = ThreadPoolExecutor(max_workers=3) result_list = [] for i in range(1, 12): res = excutor.submit(work, n=i, j=i+1) result_list.append(res) for i in result_list: print(i.result())
# 不在第一个for循环里直接取值是不会串行的,而是把结果放在一个列表里,三个线程并发执行慢慢往列表里丢执行结果
# 然后主线程for循环取值,多子线程往列表里塞数据,主线程就去在列表里取数据出来,能节约时间
# 使用了回调函数,把启动函数和回调函数写在一行无法取值,因为取的值是add_done_callback函数的返回值,
# 想要work的返回值取到也给parse_work,必须分两行写
from concurrent.futures import ThreadPoolExecutor import time def work(n, j): print(f"线程{n}正在运行") time.sleep(1) return j**2 def parse_work(z): print("这是回调函数") print(z) if __name__ == '__main__': excutor = ThreadPoolExecutor(max_workers=3) result_list = [] for i in range(1, 12): res = excutor.submit(work, n=i, j=i+1).add_done_callback(parse_work) result_list.append(res) for i in result_list: print(i)
for i in result_list:
print(i) 这个打印的i全部都是None,work函数的返回值给了parse_work这个回调函数了,
# work函数的给两边使用,给回调函数使用也给调用者使用 from concurrent.futures import ThreadPoolExecutor import time def work(n, j): print(f"线程{n}正在运行") time.sleep(1) return j**2 def parse_work(z): print("这是回调函数") print(z.result()) if __name__ == '__main__': excutor = ThreadPoolExecutor(max_workers=3) result_list = [] for i in range(1, 12): future = excutor.submit(work, n=i, j=i+1) # 调用者想要取值必须这样分行写,写一行res接收的就是future_add_callback函数的返回值了 res = future.add_done_callback(parse_work) result_list.append(future) for i in result_list: print(i.result())
54:协程
操作系统中进程是资源分配的最小单位,线程是CPU调度的最小单位。按道理来说我们已经算是把cpu的利用率提高很多了。
但是我们知道无论是创建多进程还是创建多线程来解决问题,都要消耗一定的时间来创建进程、创建线程、以及管理他们之间的切换。 随着我们对于效率的追求不断提高,基于单线程来实现并发又成为一个新的课题,即只用一个主线程(很明显可利用的cpu只有一个)情况下实现并发。
这样就可以节省创建线进程所消耗的时间。 为此我们需要先回顾下并发的本质:切换+保存状态 cpu正在运行一个任务,会在两种情况下切走去执行其他的任务(切换由操作系统强制控制),
一种情况是该任务发生了阻塞,另外一种情况是该任务计算的时间过长
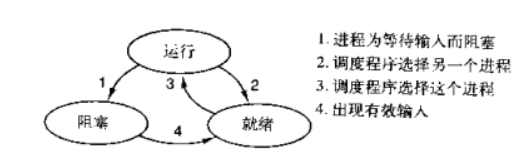
ps:在介绍进程理论时,提及进程的三种执行状态,而线程才是执行单位,所以也可以将上图理解为线程的三种状态
一:其中第二种情况并不能提升效率,只是为了让cpu能够雨露均沾,实现看起来所有任务都被“同时”执行的效果,如果多个任务都是纯计算的,这种切换反而会降低效率。
为此我们可以基于yield来验证。yield本身就是一种在单线程下可以保存任务运行状态的方法 #1 yiled可以保存状态,yield的状态保存与操作系统的保存线程状态很像,但是yield是代码级别控制的,更轻量级 #2 send可以把一个函数的结果传给另外一个函数,以此实现单线程内程序之间的切换 # 单纯地切换反而会降低运行效率 #串行执行 import time def consumer(res): '''任务1:接收数据,处理数据''' pass def producer(): '''任务2:生产数据''' res=[] for i in range(10000000): res.append(i) return res start=time.time() #串行执行 res=producer() consumer(res) #写成consumer(producer())会降低执行效率 stop=time.time() print(stop-start) #1.5536692142486572 #基于yield并发执行 import time def consumer(): '''任务1:接收数据,处理数据''' while True: x=yield def producer(): '''任务2:生产数据''' g=consumer() next(g) for i in range(10000000): g.send(i) start=time.time() #基于yield保存状态,实现两个任务直接来回切换,即并发的效果 #PS:如果每个任务中都加上打印,那么明显地看到两个任务的打印是你一次我一次,即并发执行的. producer() stop=time.time() print(stop-start) #2.0272178649902344
二:第一种情况的切换。在任务一遇到io情况下,切到任务二去执行,这样就可以利用任务一阻塞的时间完成任务二的计算,效率的提升就在于此。
# yield无法做到遇到io阻塞 import time def consumer(): '''任务1:接收数据,处理数据''' while True: x=yield def producer(): '''任务2:生产数据''' g=consumer() next(g) for i in range(10000000): g.send(i) time.sleep(2) start=time.time() producer() #并发执行,但是任务producer遇到io就会阻塞住,并不会切到该线程内的其他任务去执行 stop=time.time() print(stop-start)
对于单线程下,我们不可避免程序中出现io操作,但如果我们能在自己的程序中(即用户程序级别,而非操作系统级别)
控制单线程下的多个任务能在一个任务遇到io阻塞时就切换到另外一个任务去计算,
这样就保证了该线程能够最大限度地处于就绪态,即随时都可以被cpu执行的状态,相当于我们在用户程序级别将自己的io操作最大限度地隐藏起来,
从而可以迷惑操作系统,让其看到:该线程好像是一直在计算,io比较少,从而更多的将cpu的执行权限分配给我们的线程。
协程的本质就是在单线程下,由用户自己控制一个任务遇到io阻塞了就切换另外一个任务去执行,以此来提升效率。
为了实现它,我们需要找寻一种可以同时满足以下条件的解决方案:
#1. 可以控制多个任务之间的切换,切换之前将任务的状态保存下来,以便重新运行时,可以基于暂停的位置继续执行。 #2. 作为1的补充:可以检测io操作,在遇到io操作的情况下才发生切换
55:协程介绍
协程:是单线程下的并发,又称微线程,纤程。英文名Coroutine。一句话说明什么是协程:协程是一种用户态的轻量级线程,即协程是由用户程序自己控制调度的。
#1. python的线程属于内核级别的,即由操作系统控制调度(如单线程遇到io或执行时间过长就会被迫交出cpu执行权限,切换其他线程运行) #2. 单线程内开启协程,一旦遇到io,就会从应用程序级别(而非操作系统)控制切换,以此来提升效率(!!!非io操作的切换与效率无关)
对比操作系统控制线程的切换,用户在单线程内控制协程的切换
优点如下: #1. 协程的切换开销更小,属于程序级别的切换,操作系统完全感知不到,因而更加轻量级 #2. 单线程内就可以实现并发的效果,最大限度地利用cpu
缺点如下: #1. 协程的本质是单线程下,无法利用多核,可以是一个程序开启多个进程,每个进程内开启多个线程,每个线程内开启协程 #2. 协程指的是单个线程,因而一旦协程出现阻塞,将会阻塞整个线程
总结协程特点: 1:必须在只有一个单线程里实现并发 2:修改共享数据不需加锁 3:用户程序里自己保存多个控制流的上下文栈 4:附加:一个协程遇到IO操作自动切换到其它协程(如何实现检测IO,yield、greenlet都无法实现,就用到了gevent模块(select机制))
56:Greenlet模块
安装 :pip3 install greenlet # greenlet实现状态切换 from greenlet import greenlet def eat(name): print('%s eat 1' %name) g2.switch('egon') print('%s eat 2' %name) g2.switch() def play(name): print('%s play 1' %name) g1.switch() print('%s play 2' %name) g1=greenlet(eat) g2=greenlet(play) g1.switch('egon')#可以在第一次switch时传入参数,以后都不需要
# g1.switch('egon') 这里把线程控制权给了g1,也就是eat函数,传递的参数是egon
# 然后运行eat函数,print打印后eat函数运行g2.swithc()把线程的控制权给了g2,然后运行play函数,eat函数这里暂时记住运行状态,然后这样循环
单纯的切换(在没有io的情况下或者没有重复开辟内存空间的操作),反而会降低程序的执行速度 # 效率对比 #顺序执行 import time def f1(): res=1 for i in range(100000000): res+=i def f2(): res=1 for i in range(100000000): res*=i start=time.time() f1() f2() stop=time.time() print('run time is %s' %(stop-start)) #10.985628366470337 #切换 from greenlet import greenlet import time def f1(): res=1 for i in range(100000000): res+=i g2.switch() def f2(): res=1 for i in range(100000000): res*=i g1.switch() start=time.time() g1=greenlet(f1) g2=greenlet(f2) g1.switch() stop=time.time() print('run time is %s' %(stop-start)) # 52.763017892837524
greenlet只是提供了一种比generator更加便捷的切换方式,当切到一个任务执行时如果遇到io,那就原地阻塞,仍然是没有解决遇到IO自动切换来提升效率的问题。
单线程里的这20个任务的代码通常会既有计算操作又有阻塞操作,我们完全可以在执行任务1时遇到阻塞,就利用阻塞的时间去执行任务2。。。。如此,才能提高效率,这就用到了Gevent模块。
57:Gevent模块
安装:pip install gevent
Gevent 是一个第三方库,可以轻松通过gevent实现并发同步或异步编程,在gevent中用到的主要模式是Greenlet,
它是以C扩展模块形式接入Python的轻量级协程。 Greenlet全部运行在主程序操作系统进程的内部,但它们被协作式地调度。
用法介绍 g1=gevent.spawn(func,1,,2,3,x=4,y=5) 创建一个协程对象g1,spawn括号内第一个参数是函数名,如eat,后面可以有多个参数,可以是位置实参或关键字实参,都是传给函数eat g2=gevent.spawn(func2) g1.join() #等待g1结束 g2.join() #等待g2结束 #或者上述两步合作一步:gevent.joinall([g1,g2]) g1.value #拿到func1的返回值
# 例:遇到io主动切换 import gevent def eat(name): print('%s eat 1' %name) gevent.sleep(2) print('%s eat 2' %name) def play(name): print('%s play 1' %name) gevent.sleep(1) print('%s play 2' %name) g1=gevent.spawn(eat,'egon') g2=gevent.spawn(play,name='egon') g1.join() g2.join() #或者gevent.joinall([g1,g2]) print('主')
gevent.sleep(2)模拟的是gevent可以识别的io阻塞,而time.sleep(2)或其他的阻塞,gevent是不能直接识别的需要用下面一行代码,打补丁,就可以识别了
gevent.sleep(2)模拟的是gevent可以识别的io阻塞,而time.sleep(2)或其他的阻塞,gevent是不能直接识别的需要用下面一行代码,打补丁,就可以识别了
from gevent import monkey;monkey.patch_all() import gevent import time def eat(): print('eat food 1') time.sleep(2) print('eat food 2') def play(): print('play 1') time.sleep(1) print('play 2') g1=gevent.spawn(eat) g2=gevent.spawn(play) gevent.joinall([g1,g2]) print('主')
# 用threading.current_thread().getName()来查看每个g1和g2,查看的结果为DummyThread-n,即假线程 # 查看threading.current_thread().getName() from gevent import monkey;monkey.patch_all() import threading import gevent import time def eat(): print(threading.current_thread().getName()) print('eat food 1') time.sleep(2) print('eat food 2') def play(): print(threading.current_thread().getName()) print('play 1') time.sleep(1) print('play 2') g1=gevent.spawn(eat) g2=gevent.spawn(play) gevent.joinall([g1,g2]) print('主')
58:Gevent之同步与异步
from gevent import spawn,joinall,monkey;monkey.patch_all() import time def task(pid): """ Some non-deterministic task """ time.sleep(0.5) print('Task %s done' % pid) def synchronous(): # 同步 for i in range(10): task(i) def asynchronous(): # 异步 g_l=[spawn(task,i) for i in range(10)] # 开启了十个协程 joinall(g_l) print('DONE') if __name__ == '__main__': print('Synchronous:') synchronous() print('Asynchronous:') asynchronous() # 上面程序的重要部分是将task函数封装到Greenlet内部线程的gevent.spawn。 # 初始化的greenlet列表存放在数组threads中,此数组被传给gevent.joinall 函数, # 后者阻塞当前流程,并执行所有给定的greenlet任务。执行流程只会在 所有greenlet执行完后才会继续向下走。
59:Gevent之应用举例一
通过gevent实现单线程下的socket并发 注意 :from gevent import monkey;monkey.patch_all()一定要放到导入socket模块之前,否则gevent无法识别socket的阻塞
# server from gevent import monkey;monkey.patch_all() from socket import * import gevent #如果不想用money.patch_all()打补丁,可以用gevent自带的socket # from gevent import socket # s=socket.socket() def server(server_ip,port): s=socket(AF_INET,SOCK_STREAM) s.setsockopt(SOL_SOCKET,SO_REUSEADDR,1) s.bind((server_ip,port)) s.listen(5) while True: conn,addr=s.accept() gevent.spawn(talk,conn,addr) def talk(conn,addr): try: while True: res=conn.recv(1024) print('client %s:%s msg: %s' %(addr[0],addr[1],res)) conn.send(res.upper()) except Exception as e: print(e) finally: conn.close() if __name__ == '__main__': server('127.0.0.1',8080)
# client from socket import * client=socket(AF_INET,SOCK_STREAM) client.connect(('127.0.0.1',8080)) while True: msg=input('>>: ').strip() if not msg:continue client.send(msg.encode('utf-8')) msg=client.recv(1024) print(msg.decode('utf-8'))
# 多线程并发多个客户端 from threading import Thread from socket import * import threading def client(server_ip,port): c=socket(AF_INET,SOCK_STREAM) #套接字对象一定要加到函数内,即局部名称空间内,放在函数外则被所有线程共享,则大家公用一个套接字对象,那么客户端端口永远一样了 c.connect((server_ip,port)) count=0 while True: c.send(('%s say hello %s' %(threading.current_thread().getName(),count)).encode('utf-8')) msg=c.recv(1024) print(msg.decode('utf-8')) count+=1 if __name__ == '__main__': for i in range(500): t=Thread(target=client,args=('127.0.0.1',8080)) t.start()
60:软件开发的架构
我们了解的涉及到两个程序之间通讯的应用大致可以分为两种:
第一种是应用类:qq、微信、网盘、优酷这一类是属于需要安装的桌面应用
第二种是web类:比如百度、知乎、博客园等使用浏览器访问就可以直接使用的应用
这些应用的本质其实都是两个程序之间的通讯。而这两个分类又对应了两个软件开发的架构~
C/S架构 C/S即:Client与Server ,中文意思:客户端与服务器端架构,这种架构也是从用户层面(也可以是物理层面)来划分的。 这里的客户端一般泛指客户端应用程序EXE,程序需要先安装后,才能运行在用户的电脑上,对用户的电脑操作系统环境依赖较大。
B/S架构 B/S即:Browser与Server,中文意思:浏览器端与服务器端架构,这种架构是从用户层面来划分的。 Browser浏览器,其实也是一种Client客户端,只是这个客户端不需要大家去安装什么应用程序,
只需在浏览器上通过HTTP请求服务器端相关的资源(网页资源),客户端Browser浏览器就能进行增删改查。
61:网络基础: ip地址精确到具体的一台电脑,而端口精确到具体的程序。
1.一个程序如何在网络上找到另一个程序? 首先,程序必须要启动,其次,必须有这台机器的地址,我们都知道我们人的地址大概就是国家\省\市\区\街道\楼\门牌号这样字。
那么每一台联网的机器在网络上也有自己的地址,它的地址是怎么表示的呢? 就是使用一串数字来表示的,例如:100.4.5.6
# 什么是ip地址? IP地址是指互联网协议地址(英语:Internet Protocol Address,又译为网际协议地址),是IP Address的缩写。
IP地址是IP协议提供的一种统一的地址格式,它为互联网上的每一个网络和每一台主机分配一个逻辑地址,以此来屏蔽物理地址的差异。 IP地址是一个32位的二进制数,通常被分割为4个“8位二进制数”(也就是4个字节)。IP地址通常用“点分十进制”表示成(a.b.c.d)的形式,
其中,a,b,c,d都是0~255之间的十进制整数。例:点分十进IP地址(100.4.5.6),实际上是32位二进制数(01100100.00000100.00000101.00000110)。
# 什么是端口 "端口"是英文port的意译,可以认为是设备与外界通讯交流的出口。
在windows上查看端口占用的情况
netstat -aon|findstr "49157"
62:osi七层模型
须知一个完整的计算机系统是由硬件、操作系统、应用软件三者组成,具备了这三个条件,一台计算机系统就可以自己跟自己玩了(打个单机游戏,玩个扫雷啥的)
如果你要跟别人一起玩,那你就需要上网了,什么是互联网?
互联网的核心就是由一堆协议组成,协议就是标准,比如全世界人通信的标准是英语,如果把计算机比作人,互联网协议就是计算机界的英语。
所有的计算机都学会了互联网协议,那所有的计算机都就可以按照统一的标准去收发信息从而完成通信了。
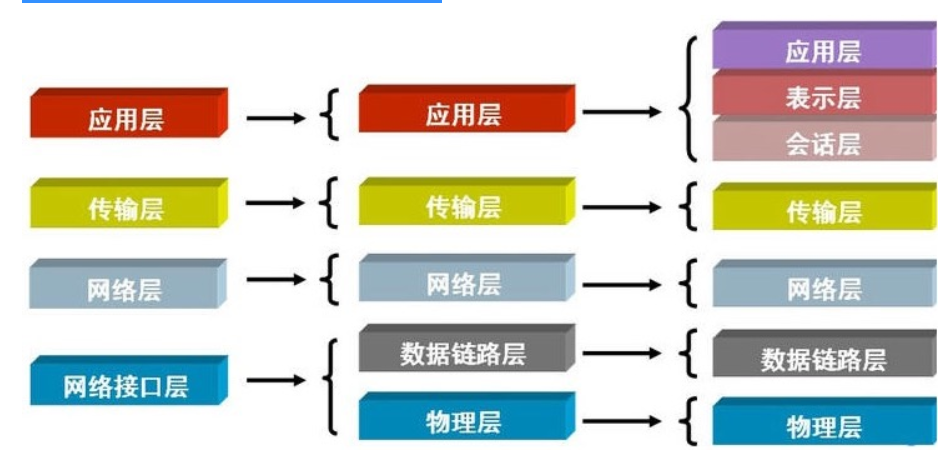
人们按照分工不同把互联网协议从逻辑上划分了层级:
63:socket的概念
socket层
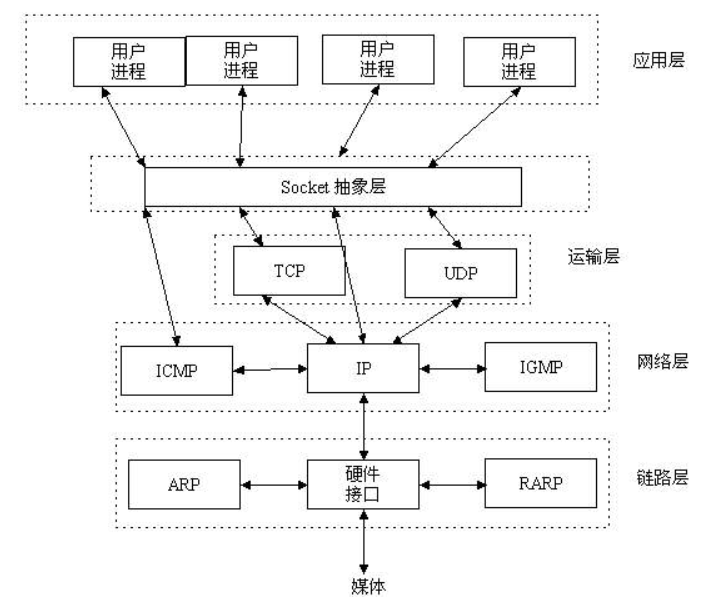
理解socket Socket是应用层与TCP/IP协议族通信的中间软件抽象层,它是一组接口。在设计模式中,Socket其实就是一个门面模式,
它把复杂的TCP/IP协议族隐藏在Socket接口后面,对用户来说,一组简单的接口就是全部,让Socket去组织数据,以符合指定的协议。
站在你的角度上看socket
socket就是一个模块。我们通过调用模块中已经实现的方法建立两个进程之间的连接和通信。
也有人将socket说成ip+port,因为ip是用来标识互联网中的一台主机的位置,而port是用来标识这台机器上的一个应用程序。
所以我们只要确立了ip和port就能找到一个应用程序,并且使用socket模块来与之通信。
64:套接字(socket)的发展史
一开始,套接字被设计用在同一台主机上多个应用程序之间的通讯。这也被称进程间通讯,或 IPC。套接字有两种(或者称为有两个种族),分别是基于文件型的和基于网络型的。
基于文件类型的套接字家族
套接字家族的名字:AF_UNIX
unix一切皆文件,基于文件的套接字调用的就是底层的文件系统来取数据,两个套接字进程运行在同一机器,可以通过访问同一个文件系统间接完成通信
基于网络类型的套接字家族
套接字家族的名字:AF_INET
(还有AF_INET6被用于ipv6,还有一些其他的地址家族,不过,他们要么是只用于某个平台,要么就是已经被废弃,或者是很少被使用,
或者是根本没有实现,所有地址家族中,AF_INET是使用最广泛的一个,python支持很多种地址家族,但是由于我们只关心网络编程,所以大部分时候我么只使用AF_INET)
65:tcp协议和udp协议
TCP(Transmission Control Protocol)可靠的、面向连接的协议(eg:打电话)、传输效率低,全双工通信(发送缓存&接收缓存)
面向字节流。使用TCP的应用:Web浏览器;电子邮件、文件传输程序。 UDP(User Datagram Protocol)不可靠的、无连接的服务,传输效率高(发送前时延小),
一对一、一对多、多对一、多对多、面向报文,尽最大努力服务,无拥塞控制。使用UDP的应用:域名系统 (DNS);视频流;IP语音(VoIP)
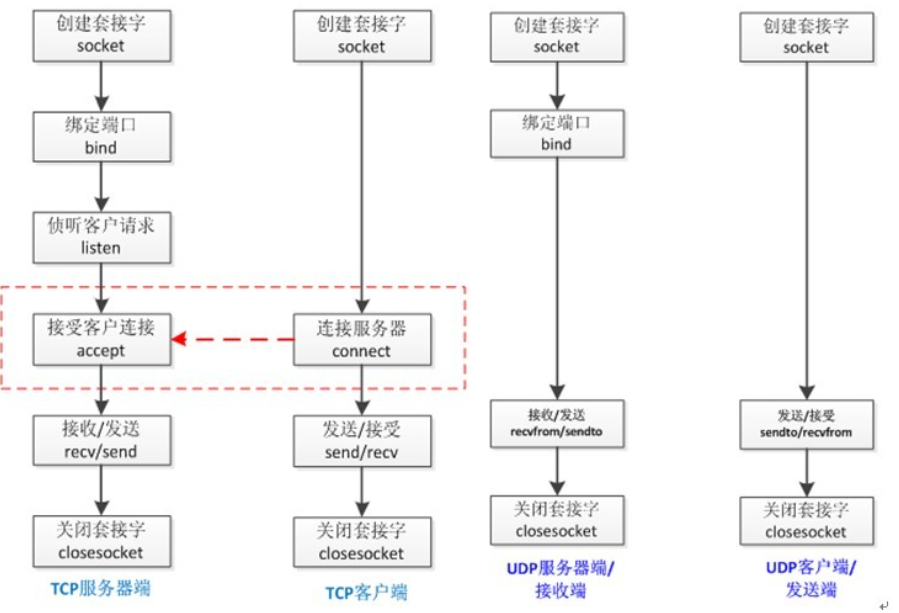
socket通信示意图:
66:基于TCP协议的socket: tcp是基于链接的,必须先启动服务端,然后再启动客户端去链接服务端
# 基础的基于tcp的socket #server端 import socket sk = socket.socket() sk.bind(('127.0.0.1',8898)) #把地址绑定到套接字 sk.listen() #监听链接,阻塞代码 conn,addr = sk.accept() #接受客户端链接 ret = conn.recv(1024) #接收客户端信息 print(ret) #打印客户端信息 conn.send(b'hi') #向客户端发送信息 conn.close() #关闭客户端套接字 sk.close() #关闭服务器套接字(可选)
如果开启服务端报错,加一条语句:
sk.setsockopt(SOL_SOCKET,SO_REUSEADDR,1) #就是它,在bind前加,这个语句的意思是:SOL_SOCKET: 基本套接口,SO_REUSEADDR的值为1代表可以占用TIME_WAIT套接字的端口
有三个参数:
level:选项定义的层次。支持SOL_SOCKET、IPPROTO_TCP、IPPROTO_IP和IPPROTO_IPV6。
optname:需设置的选项。
value:设置选项的值。
s(套接字): 指向一个打开的套接口描述字
level:(级别): 指定选项代码的类型。
SOL_SOCKET: 基本套接口
IPPROTO_IP: IPv4套接口
IPPROTO_IPV6: IPv6套接口
IPPROTO_TCP: TCP套接口
一般来说,一个端口释放后会等待两分钟之后才能再被使用,SO_REUSEADDR是让端口释放后立即就可以被再次使用。
SO_REUSEADDR用于对TCP套接字处于TIME_WAIT状态下的socket,才可以重复绑定使用。
server程序总是应该在调用bind()之前设置SO_REUSEADDR套接字选项。TCP,先调用close()的一方会进入TIME_WAIT状态
使用SO_REUSEADDR就是能使用处于四次挥手阶段的socket的套接字的端口号,不会报错
SO_REUSEADDR允许启动一个监听服务器并捆绑其众所周知端口,即使以前建立的将此端口用做他们的本地端口的连接仍存在。
这通常是重启监听服务器时出现,若不设置此选项,则bind时将出错。
SO_REUSEADDR允许在同一端口上启动同一服务器的多个实例,只要每个实例捆绑一个不同的本地IP地址即可。
对于TCP,我们根本不可能启动捆绑相同IP地址和相同端口号的多个服务器。
SO_REUSEADDR允许单个进程捆绑同一端口到多个套接口上,只要每个捆绑指定不同的本地IP地址即可。这一般不用于TCP服务器。
SO_REUSEADDR允许完全重复的捆绑:当一个IP地址和端口绑定到某个套接口上时,还允许此IP地址和端口捆绑到另一个套接口上
。一般来说,这个特性仅在支持多播的系统上才有,而且只对UDP套接口而言(TCP不支持多播)
SO_REUSEPORT选项有如下语义:
此选项允许完全重复捆绑,但仅在想捆绑相同IP地址和端口的套接口都指定了此套接口选项才行。
如果被捆绑的IP地址是一个多播地址,则SO_REUSEADDR和SO_REUSEPORT等效。
当两个socket的address和port相冲突,而你又想重用地址和端口,则旧的socket和新的socket都要已经被设置了SO_REUSEADDR特性,只有两者之一有这个特性还是有问题的。
SO_REUSEADDR可以用在以下四种情况下: (摘自《Unix网络编程》卷一,即UNPv1)
1、当有一个有相同本地地址和端口的socket1处于TIME_WAIT状态时,而你启动的程序的socket2要占用该地址和端口,你的程序就要用到该选项。
2、SO_REUSEADDR允许同一port上启动同一服务器的多个实例(多个进程)。但每个实例绑定的IP地址是不能相同的。在有多块网卡或用IP Alias技术的机器可
以测试这种情况。
3、SO_REUSEADDR允许单个进程绑定相同的端口到多个socket上,但每个socket绑定的ip地址不同。这和2很相似,区别请看UNPv1。
4、SO_REUSEADDR允许完全相同的地址和端口的重复绑定。但这只用于UDP的多播,不用于TCP
#client端
import socket
sk = socket.socket() # 创建客户套接字
sk.connect(('127.0.0.1',8898)) # 尝试连接服务器
sk.send(b'hello!')
ret = sk.recv(1024) # 对话(发送/接收)
print(ret) sk.close() # 关闭客户套接字
67:基于udp协议的socket :udp是无链接的,启动服务之后可以直接接受消息,不需要提前建立链接
# server端 import socket udp_sk = socket.socket(type=socket.SOCK_DGRAM) #创建一个服务器的套接字 udp_sk.bind(('127.0.0.1',9000)) #绑定服务器套接字 msg,addr = udp_sk.recvfrom(1024) print(msg) udp_sk.sendto(b'hi',addr) # 对话(接收与发送) udp_sk.close() # 关闭服务器套接字
# client端 import socket ip_port=('127.0.0.1',9000) udp_sk=socket.socket(type=socket.SOCK_DGRAM) udp_sk.sendto(b'hello',ip_port) back_msg,addr=udp_sk.recvfrom(1024) print(back_msg.decode('utf-8'),addr)
68:qq聊天
# server
import socket ip_port=('127.0.0.1',8081) udp_server_sock=socket.socket(socket.AF_INET,socket.SOCK_DGRAM) udp_server_sock.bind(ip_port) while True: qq_msg,addr=udp_server_sock.recvfrom(1024) print('来自[%s:%s]的一条消息:\033[1;44m%s\033[0m' %(addr[0],addr[1],qq_msg.decode('utf-8'))) back_msg=input('回复消息: ').strip() udp_server_sock.sendto(back_msg.encode('utf-8'),addr)
# client import socket BUFSIZE=1024 udp_client_socket=socket.socket(socket.AF_INET,socket.SOCK_DGRAM) qq_name_dic={ '金老板':('127.0.0.1',8081), '哪吒':('127.0.0.1',8081), 'egg':('127.0.0.1',8081), 'yuan':('127.0.0.1',8081), } while True: qq_name=input('请选择聊天对象: ').strip() while True: msg=input('请输入消息,回车发送,输入q结束和他的聊天: ').strip() if msg == 'q':break if not msg or not qq_name or qq_name not in qq_name_dic:continue udp_client_socket.sendto(msg.encode('utf-8'),qq_name_dic[qq_name]) back_msg,addr=udp_client_socket.recvfrom(BUFSIZE) print('来自[%s:%s]的一条消息:\033[1;44m%s\033[0m' %(addr[0],addr[1],back_msg.decode('utf-8'))) udp_client_socket.close()
69:时间服务器
# server import socket from time import strftime client_sk = socket.socket(socket.AF_INET, socket.SOCK_DGRAM) # 创建udp服务器 client_sk.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1) client_sk.bind(("127.0.0.1", 9000)) while 1: msg, addr = client_sk.recvfrom(1024) print(msg.decode("utf8")) if not msg: time_fmt = '%Y-%m-%d %X' else: time_fmt = msg.decode('utf-8') back_msg = strftime(time_fmt) client_sk.sendto(back_msg.encode('utf8'), addr) client_sk.close()
# client import socket ip_port = ("127.0.0.1", 9000) client_sk = socket.socket(socket.AF_INET, socket.SOCK_DGRAM) while 1: client_sk.sendto(input(">>>请输入时间格式如:%Y %m %d:").encode("utf8"), ip_port) data = client_sk.recvfrom(1024) print(data[0].decode("utf8"))
70:socket参数的详解
socket.socket(family=AF_INET,type=SOCK_STREAM,proto=0,fileno=None) 创建socket对象的参数说明:
family:地址系列应为AF_INET(默认值),AF_INET6,AF_UNIX,AF_CAN或AF_RDS。 (AF_UNIX 域实际上是使用本地 socket 文件来通信) type:套接字类型应为SOCK_STREAM(默认值),SOCK_DGRAM,SOCK_RAW或其他SOCK_常量之一。 SOCK_STREAM 是基于TCP的,有保障的(即能保证数据正确传送到对方)面向连接的SOCKET,多用于资料传送。 SOCK_DGRAM 是基于UDP的,无保障的面向消息的socket,多用于在网络上发广播信息。 proto:协议号通常为零,可以省略,或者在地址族为AF_CAN的情况下,协议应为CAN_RAW或CAN_BCM之一。 fileno:如果指定了fileno,则其他参数将被忽略,导致带有指定文件描述符的套接字返回。 与socket.fromfd()不同,fileno将返回相同的套接字,而不是重复的。 这可能有助于使用socket.close()关闭一个独立的插座
71:粘包
# 基于tcp先制作一个远程执行命令的程序(命令ls -l ; lllllll ; pwd)
import subprocess
res = subprocess.Popen('ipconfig',
shell=True,
stderr=subprocess.PIPE,
stdout=subprocess.PIPE)
print(res.stdout.read().decode('gbk'))
结果的编码是以当前所在的系统为准的,如果是windows,那么res.stdout.read()读出的就是GBK编码的,在接收端需要用GBK解码 且只能从管道里读一次结果
同时执行多条命令之后,得到的结果很可能只有一部分,在执行其他命令的时候又接收到之前执行的另外一部分结果,这种显现就是黏包。
72:基于tcp协议实现的黏包
# tcp - server from socket import * import subprocess ip_port=('127.0.0.1',8888) BUFSIZE=1024 tcp_socket_server=socket(AF_INET,SOCK_STREAM) tcp_socket_server.setsockopt(SOL_SOCKET,SO_REUSEADDR,1) tcp_socket_server.bind(ip_port) tcp_socket_server.listen(5) while True: conn,addr=tcp_socket_server.accept() print('客户端',addr) while True: cmd=conn.recv(BUFSIZE) if len(cmd) == 0:break res=subprocess.Popen(cmd.decode('utf-8'),shell=True, stdout=subprocess.PIPE, stdin=subprocess.PIPE, stderr=subprocess.PIPE) stderr=res.stderr.read() stdout=res.stdout.read() conn.send(stderr) conn.send(stdout)
# tcp- client import socket ip_port = ('127.0.0.1', 8888) BUFSIZE = 1024 tcp_client_sk = socket.socket(socket.AF_INET, socket.SOCK_STREAM) res = tcp_client_sk.connect_ex(ip_port) # connect扩展版本,此时会以错误码的形式返回问题,而不是抛出一个异常 while 1: msg = input(">>>>").strip() if len(msg) == "0": continue if msg == "q": break tcp_client_sk.send(msg.encode("utf8")) recv_data = tcp_client_sk.recv(BUFSIZE) print(recv_data.decode("gbk"), end="|||||||||||||||||||||||||||")
# 客户端和服务端同时开启,客户端每次输入得到得返回都会只获取一段,因为每次只读取了1024个字节
73:基于udp协议实现的黏包
# udp - server import socket import subprocess ip_port = ('127.0.0.1', 9000) buf_size = 1024 udp_server_sk = socket.socket(socket.AF_INET, socket.SOCK_DGRAM) # 建立udp套接字 udp_server_sk.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1) udp_server_sk.bind(ip_port) while 1: cmd, addr = udp_server_sk.recvfrom(buf_size) print("用户命令>>>", cmd) res = subprocess.Popen( cmd.decode("utf8"), shell=True, stderr=subprocess.PIPE, stdin=subprocess.PIPE, stdout=subprocess.PIPE ) stderr = res.stderr.read() stdout = res.stdout.read() udp_server_sk.sendto(stderr, addr) udp_server_sk.sendto(stdout, addr) udp_server_sk.close()
# udp_client import socket ip_port = ('127.0.0.1', 9000) buf_size = 1024 udp_client_sk = socket.socket(socket.AF_INET, socket.SOCK_DGRAM) while 1: msg = input('>>: ').strip() udp_client_sk.sendto(msg.encode('utf-8'), ip_port) err, addr = udp_client_sk.recvfrom(buf_size) out, addr = udp_client_sk.recvfrom(2048) if err: print('error : %s' % err.decode('utf-8'), end='') if out: print(out.decode('gbk'), end='')
只有TCP有粘包现象,UDP永远不会粘包
74:黏包成因
TCP协议中的数据传递 tcp协议的拆包机制 当发送端缓冲区的长度大于网卡的MTU时,tcp会将这次发送的数据拆成几个数据包发送出去。 MTU是Maximum Transmission Unit的缩写。意思是网络上传送的最大数据包。MTU的单位是字节。 大部分网络设备的MTU都是1500。
如果本机的MTU比网关的MTU大,大的数据包就会被拆开来传送,这样会产生很多数据包碎片,增加丢包率,降低网络速度。 面向流的通信特点和Nagle算法 TCP(transport control protocol,传输控制协议)是面向连接的,面向流的,提供高可靠性服务。 收发两端(客户端和服务器端)都要有一一成对的socket,因此,发送端为了将多个发往接收端的包,更有效的发到对方,
使用了优化方法(Nagle算法),将多次间隔较小且数据量小的数据,合并成一个大的数据块,然后进行封包。 这样,接收端,就难于分辨出来了,必须提供科学的拆包机制。 即面向流的通信是无消息保护边界的。 对于空消息:tcp是基于数据流的,于是收发的消息不能为空,这就需要在客户端和服务端都添加空消息的处理机制,防止程序卡住,而udp是基于数据报的,
即便是你输入的是空内容(直接回车),也可以被发送,udp协议会帮你封装上消息头发送过去。 可靠黏包的tcp协议:tcp的协议数据不会丢,没有收完包,下次接收,会继续上次继续接收,己端总是在收到ack时才会清除缓冲区内容。数据是可靠的,但是会粘包。
基于tcp协议特点的黏包现象成因
![]()
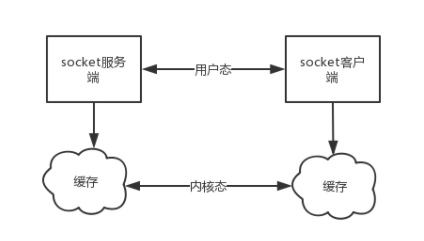
socket数据传输过程中的用户态与内核态说明 发送端可以是一K一K地发送数据,而接收端的应用程序可以两K两K地提走数据,当然也有可能一次提走3K或6K数据,或者一次只提走几个字节的数据。 也就是说,应用程序所看到的数据是一个整体,或说是一个流(stream),一条消息有多少字节对应用程序是不可见的,因此TCP协议是面向流的协议,这也是容易出现粘包问题的原因。 而UDP是面向消息的协议,每个UDP段都是一条消息,应用程序必须以消息为单位提取数据,不能一次提取任意字节的数据,这一点和TCP是很不同的。 怎样定义消息呢?可以认为对方一次性write/send的数据为一个消息,需要明白的是当对方send一条信息的时候,无论底层怎样分段分片,
TCP协议层会把构成整条消息的数据段排序完成后才呈现在内核缓冲区。
例如基于tcp的套接字客户端往服务端上传文件,发送时文件内容是按照一段一段的字节流发送的,
在接收方看了,根本不知道该文件的字节流从何处开始,在何处结束 此外,发送方引起的粘包是由TCP协议本身造成的,TCP为提高传输效率,发送方往往要收集到足够多的数据后才发送一个TCP段。
若连续几次需要send的数据都很少,通常TCP会根据优化算法把这些数据合成一个TCP段后一次发送出去,这样接收方就收到了粘包数据。
# UDP不会发生黏包 UDP(user datagram protocol,用户数据报协议)是无连接的,面向消息的,提供高效率服务。 不会使用块的合并优化算法,, 由于UDP支持的是一对多的模式,所以接收端的skbuff(套接字缓冲区)采用了链式结构来记录每一个到达的UDP包,
在每个UDP包中就有了消息头(消息来源地址,端口等信息),这样,对于接收端来说,就容易进行区分处理了。 即面向消息的通信是有消息保护边界的。 对于空消息:tcp是基于数据流的,于是收发的消息不能为空,这就需要在客户端和服务端都添加空消息的处理机制,防止程序卡住,而udp是基于数据报的,
即便是你输入的是空内容(直接回车),也可以被发送,udp协议会帮你封装上消息头发送过去。 不可靠不黏包的udp协议:udp的recvfrom是阻塞的,一个recvfrom(x)必须对唯一一个sendinto(y),
收完了x个字节的数据就算完成,若是y;x数据就丢失,这意味着udp根本不会粘包,但是会丢数据,不可靠。
udp和tcp一次发送数据长度的限制 用UDP协议发送时,用sendto函数最大能发送数据的长度为:65535- IP头(20) – UDP头(8)=65507字节。
用sendto函数发送数据时,如果发送数据长度大于该值,则函数会返回错误。(丢弃这个包,不进行发送) 用TCP协议发送时,由于TCP是数据流协议,因此不存在包大小的限制(暂不考虑缓冲区的大小),这是指在用send函数时,
数据长度参数不受限制。而实际上,所指定的这段数据并不一定会一次性发送出去,如果这段数据比较长,会被分段发送,
如果比较短,可能会等待和下一次数据一起发送。
send函数是把数据发送给内核的缓存区,recv函数接收数据也是从内核的缓存区接收数据,至于怎么发送tcp和udp的包都是底层内核决定的
75:会发生黏包的两种情况
情况一 发送方的缓存机制
发送端需要等缓冲区满才发送出去,造成粘包(发送数据时间间隔很短,数据了很小,会合到一起,产生粘包)
# 服务端 from socket import * ip_port=('127.0.0.1',8080) tcp_socket_server=socket(AF_INET,SOCK_STREAM) tcp_socket_server.bind(ip_port) tcp_socket_server.listen(5) conn,addr=tcp_socket_server.accept() data1=conn.recv(10) data2=conn.recv(10) print('----->',data1.decode('utf-8')) print('----->',data2.decode('utf-8')) conn.close()
# 客户端 import socket BUFSIZE=1024 ip_port=('127.0.0.1',8080) s=socket.socket(socket.AF_INET,socket.SOCK_STREAM) res=s.connect_ex(ip_port) s.send('hello'.encode('utf-8')) s.send('egg'.encode('utf-8'))
情况二 接收方的缓存机制
接收方不及时接收缓冲区的包,造成多个包接收(客户端发送了一段数据,服务端只收了一小部分,服务端下次再收的时候还是从缓冲区拿上次遗留的数据,产生粘包)
# 服务端
import socket ip_port = ('127.0.0.1', 8080) tcp_server_sk = socket.socket(socket.AF_INET, socket.SOCK_STREAM) tcp_server_sk.bind(ip_port) tcp_server_sk.listen() conn, addr = tcp_server_sk.accept() data1 = conn.recv(2) # 一次没有收完整 data2 = conn.recv(10) # 下次收的时候,会先取旧的数据,然后取新的 print(data1.decode('utf8')) print(data2.decode('utf8')) conn.close()
# 客户端 import socket ip_port = ('127.0.0.1', 8080) tcp_server_sk = socket.socket(socket.AF_INET, socket.SOCK_STREAM) res = tcp_server_sk.connect_ex(ip_port) tcp_server_sk.send(b"hello egg")
76:粘包
黏包现象只发生在tcp协议中: 1.从表面上看,黏包问题主要是因为发送方和接收方的缓存机制、tcp协议面向流通信的特点。 2.实际上,主要还是因为接收方不知道消息之间的界限,不知道一次性提取多少字节的数据所造成的
77:黏包的解决方案
解决方案一
问题的根源在于,接收端不知道发送端将要传送的字节流的长度,所以解决粘包的方法就是围绕,如何让发送端在发送数据前,
把自己将要发送的字节流总大小让接收端知晓,然后接收端来一个死循环接收完所有数据。
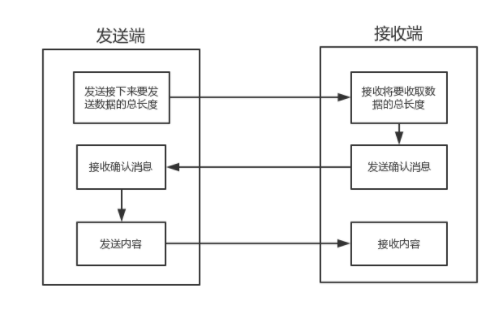
# 服务端,现发送文件大小 import socket import subprocess ip_port = ('127.0.0.1', 8080) tcp_server_sk = socket.socket(socket.AF_INET, socket.SOCK_STREAM) tcp_server_sk.bind(ip_port) tcp_server_sk.listen() while 1: conn, addr = tcp_server_sk.accept() print(f"客户端:{addr}") while 1: msg = conn.recv(1024) if not msg: break res = subprocess.Popen(msg.decode('gbk'), shell=True, stdin=subprocess.PIPE, stderr=subprocess.PIPE, stdout=subprocess.PIPE ) err = res.stderr.read() if err: ret = err else: ret = res.stdout.read() data_length = len(ret) conn.send(str(data_length).encode("utf8")) data = conn.recv(1024).decode('utf8') if data == "recv_ready": conn.sendall(ret) conn.close()
# 客户端,循环接收 import socket ip_port = ('127.0.0.1', 8080) tcp_client_sk = socket.socket(socket.AF_INET, socket.SOCK_STREAM) tcp_client_sk.connect(ip_port) while 1: msg = input(">>>>>:").strip() if len(msg) == 0: continue if msg == "q": break tcp_client_sk.send(msg.encode("utf8")) length = int(tcp_client_sk.recv(1024).decode("utf8")) tcp_client_sk.send("recv_ready".encode('utf8')) recv_size = 0 data = b"" while recv_size < length: data += tcp_client_sk.recv(1024) recv_size += len(data) print(data.decode("gbk"))
存在的问题:
程序的运行速度远快于网络传输速度,所以在发送一段字节前,先用send去发送该字节流长度,这种方式会放大网络延迟带来的性能损耗
解决方案二进阶 刚刚的方法,问题在于我们我们在发送 我们可以借助一个模块,这个模块可以把要发送的数据长度转换成固定长度的字节。这样客户端每次接收消息之前只要先接受这个固
定长度字节的内容看一看接下来要接收的信息大小,那么最终接受的数据只要达到这个值就停止,就能刚好不多不少的接收完整的数据了。
# struct模块 该模块可以把一个类型,如数字,转成固定长度的bytes struct.pack('i',1111111111111) 报错,越界了
import json,struct #假设通过客户端上传1T:1073741824000的文件a.txt #为避免粘包,必须自定制报头 header={'file_size':1073741824000,'file_name':'/a/b/c/d/e/a.txt','md5':'8f6fbf8347faa4924a76856701edb0f3'} #1T数据,文件路径和md5值 #为了该报头能传送,需要序列化并且转为bytes head_bytes=bytes(json.dumps(header),encoding='utf-8') #序列化并转成bytes,用于传输 #为了让客户端知道报头的长度,用struck将报头长度这个数字转成固定长度:4个字节 head_len_bytes=struct.pack('i',len(head_bytes)) #这4个字节里只包含了一个数字,该数字是报头的长度 #客户端开始发送 conn.send(head_len_bytes) #先发报头的长度,4个bytes conn.send(head_bytes) #再发报头的字节格式 conn.sendall(文件内容) #然后发真实内容的字节格式 #服务端开始接收 head_len_bytes=s.recv(4) #先收报头4个bytes,得到报头长度的字节格式 x=struct.unpack('i',head_len_bytes)[0] #提取报头的长度 head_bytes=s.recv(x) #按照报头长度x,收取报头的bytes格式 header=json.loads(json.dumps(header)) #提取报头 #最后根据报头的内容提取真实的数据,比如 real_data_len=s.recv(header['file_size']) s.recv(real_data_len)
服务端
1:发送报文头的长度
2:发送报文头
3:发送真实的数据内容
客户端:
1:获取报文头的长度,接收四个字节,(得到报文长度的二进制然后提取包头的长度)
2:获取报文头(也就是文件信息)
3:获取真实数据
# 关于struct的详细用法 #http://www.cnblogs.com/coser/archive/2011/12/17/2291160.html __author__ = 'Linhaifeng' import struct import binascii import ctypes values1 = (1, 'abc'.encode('utf-8'), 2.7) values2 = ('defg'.encode('utf-8'),101) s1 = struct.Struct('I3sf') s2 = struct.Struct('4sI') print(s1.size,s2.size) prebuffer=ctypes.create_string_buffer(s1.size+s2.size) print('Before : ',binascii.hexlify(prebuffer)) # t=binascii.hexlify('asdfaf'.encode('utf-8')) # print(t) s1.pack_into(prebuffer,0,*values1) s2.pack_into(prebuffer,s1.size,*values2) print('After pack',binascii.hexlify(prebuffer)) print(s1.unpack_from(prebuffer,0)) print(s2.unpack_from(prebuffer,s1.size)) s3=struct.Struct('ii') s3.pack_into(prebuffer,0,123,123) print('After pack',binascii.hexlify(prebuffer)) print(s3.unpack_from(prebuffer,0))
78:使用struct解决黏包
借助struct模块,我们知道长度数字可以被转换成一个标准大小的4字节数字。因此可以利用这个特点来预先发送数据长度。

# 服务端(自定制报头) import socket import subprocess import struct ip_port = ('127.0.0.1', 8080) tcp_server_sk = socket.socket(socket.AF_INET, socket.SOCK_STREAM) tcp_server_sk.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1) tcp_server_sk.bind(ip_port) tcp_server_sk.listen() while 1: conn, addr = tcp_server_sk.accept() while 1: cmd = conn.recv(1024) if not cmd: break print(f"cmd:{cmd}") res = subprocess.Popen( cmd.decode('utf8'), shell=True, stdout=subprocess.PIPE, stderr=subprocess.PIPE ) err = res.stderr.read() if err: back_msg = err else: back_msg = res.stdout.read() conn.send(struct.pack('i', len(back_msg))) # 先发back_msg的长度,转化成四个字节,发送自定制的报头,报头的内容为文件长度 conn.sendall(back_msg) # 发送数据内容 conn.close()
# 客户端(自定制报头) import socket import struct ip_port = ('127.0.0.1', 8080) tcp_client_sk = socket.socket(socket.AF_INET, socket.SOCK_STREAM) tcp_client_sk.connect(ip_port) while 1: msg = input(">>>>>").strip() if len(msg) == 0: continue if msg == "q": break tcp_client_sk.send(msg.encode('utf8')) info = tcp_client_sk.recv(4) # 接收四个字节,接收报头获取文件的一些列信息 data_len = struct.unpack("i", info)[0] index = 0 data = b"" while index < data_len: r_d = tcp_client_sk.recv(1024) data = data + r_d index = index + len(r_d) print(data.decode('gbk'))
我们还可以把报头做成字典,字典里包含将要发送的真实数据的详细信息,然后json序列化,然后用struck将序列化后的数据长度打包成4个字节(4个字节足够用了)

# 服务端:定制稍微复杂一点的报头 import socket import subprocess import struct import json ip_port = ('127.0.0.1', 8080) tcp_server_sk = socket.socket(socket.AF_INET, socket.SOCK_STREAM) tcp_server_sk.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1) tcp_server_sk.bind(ip_port) tcp_server_sk.listen() while 1: conn, addr = tcp_server_sk.accept() while 1: cmd = conn.recv(1024) if not cmd: break print(f"cmd:{cmd}") res = subprocess.Popen( cmd.decode('utf8'), shell=True, stdout=subprocess.PIPE, stderr=subprocess.PIPE ) err = res.stderr.read() if err: back_msg = err else: back_msg = res.stdout.read() header = {"data_size": len(back_msg)} header_bytes = json.dumps(header).encode("utf8") # 转换成json字符串类型的数据 conn.send(struct.pack('i', len(header_bytes))) # 先发header报文头的长度 conn.send(header_bytes) # 然后发送报文头 conn.sendall(back_msg) # 最后数据内容 conn.close()
# 客户端 import socket import struct import json ip_port = ('127.0.0.1', 8080) tcp_client_sk = socket.socket(socket.AF_INET, socket.SOCK_STREAM) tcp_client_sk.connect(ip_port) while 1: msg = input(">>>>>").strip() if len(msg) == 0: continue if msg == "q": break tcp_client_sk.send(msg.encode('utf8')) info = tcp_client_sk.recv(4) # 接收四个字节,内容为报文头的长度 header = tcp_client_sk.recv(struct.unpack("i", info)[0]) # 根据报文头的长度接收报文头,收到的是bytes类型 data_len = json.loads(header.decode("utf8"))['data_size'] # 根据报文头解析出文件的大小 data = b"" index = 0 while index < data_len: payload = tcp_client_sk.recv(1024) data = data + payload index = index + len(payload) print(data.decode("gbk"))
79:FTP作业:上传下载文件


import socket import struct import json import subprocess import os class MYTCPServer: address_family = socket.AF_INET socket_type = socket.SOCK_STREAM allow_reuse_address = False max_packet_size = 8192 coding='utf-8' request_queue_size = 5 server_dir='file_upload' def __init__(self, server_address, bind_and_activate=True): """Constructor. May be extended, do not override.""" self.server_address=server_address self.socket = socket.socket(self.address_family, self.socket_type) if bind_and_activate: try: self.server_bind() self.server_activate() except: self.server_close() raise def server_bind(self): """Called by constructor to bind the socket. """ if self.allow_reuse_address: self.socket.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1) self.socket.bind(self.server_address) self.server_address = self.socket.getsockname() def server_activate(self): """Called by constructor to activate the server. """ self.socket.listen(self.request_queue_size) def server_close(self): """Called to clean-up the server. """ self.socket.close() def get_request(self): """Get the request and client address from the socket. """ return self.socket.accept() def close_request(self, request): """Called to clean up an individual request.""" request.close() def run(self): while True: self.conn,self.client_addr=self.get_request() print('from client ',self.client_addr) while True: try: head_struct = self.conn.recv(4) if not head_struct:break head_len = struct.unpack('i', head_struct)[0] head_json = self.conn.recv(head_len).decode(self.coding) head_dic = json.loads(head_json) print(head_dic) #head_dic={'cmd':'put','filename':'a.txt','filesize':123123} cmd=head_dic['cmd'] if hasattr(self,cmd): func=getattr(self,cmd) func(head_dic) except Exception: break def put(self,args): file_path=os.path.normpath(os.path.join( self.server_dir, args['filename'] )) filesize=args['filesize'] recv_size=0 print('----->',file_path) with open(file_path,'wb') as f: while recv_size < filesize: recv_data=self.conn.recv(self.max_packet_size) f.write(recv_data) recv_size+=len(recv_data) print('recvsize:%s filesize:%s' %(recv_size,filesize)) tcpserver1=MYTCPServer(('127.0.0.1',8080)) tcpserver1.run() #下列代码与本题无关 class MYUDPServer: """UDP server class.""" address_family = socket.AF_INET socket_type = socket.SOCK_DGRAM allow_reuse_address = False max_packet_size = 8192 coding='utf-8' def get_request(self): data, client_addr = self.socket.recvfrom(self.max_packet_size) return (data, self.socket), client_addr def server_activate(self): # No need to call listen() for UDP. pass def shutdown_request(self, request): # No need to shutdown anything. self.close_request(request) def close_request(self, request): # No need to close anything. pass
import socket import struct import json import os class MYTCPClient: address_family = socket.AF_INET socket_type = socket.SOCK_STREAM allow_reuse_address = False max_packet_size = 8192 coding='utf-8' request_queue_size = 5 def __init__(self, server_address, connect=True): self.server_address=server_address self.socket = socket.socket(self.address_family, self.socket_type) if connect: try: self.client_connect() except: self.client_close() raise def client_connect(self): self.socket.connect(self.server_address) def client_close(self): self.socket.close() def run(self): while True: inp=input(">>: ").strip() if not inp:continue l=inp.split() cmd=l[0] if hasattr(self,cmd): func=getattr(self,cmd) func(l) def put(self,args): cmd=args[0] filename=args[1] if not os.path.isfile(filename): print('file:%s is not exists' %filename) return else: filesize=os.path.getsize(filename) head_dic={'cmd':cmd,'filename':os.path.basename(filename),'filesize':filesize} print(head_dic) head_json=json.dumps(head_dic) head_json_bytes=bytes(head_json,encoding=self.coding) head_struct=struct.pack('i',len(head_json_bytes)) self.socket.send(head_struct) self.socket.send(head_json_bytes) send_size=0 with open(filename,'rb') as f: for line in f: self.socket.send(line) send_size+=len(line) print(send_size) else: print('upload successful') client=MYTCPClient(('127.0.0.1',8080)) client.run()
80:socket的更多方法介绍
服务端套接字函数
s.bind() 绑定(主机,端口号)到套接字
s.listen() 开始TCP监听
s.accept() 被动接受TCP客户的连接,(阻塞式)等待连接的到来
客户端套接字函数
s.connect() 主动初始化TCP服务器连接
s.connect_ex() connect()函数的扩展版本,出错时返回出错码,而不是抛出异常
公共用途的套接字函数
s.recv() 接收TCP数据
s.send() 发送TCP数据
s.sendall() 发送TCP数据
s.recvfrom() 接收UDP数据
s.sendto() 发送UDP数据
s.getpeername() 连接到当前套接字的远端的地址
s.getsockname() 当前套接字的地址
s.getsockopt() 返回指定套接字的参数
s.setsockopt() 设置指定套接字的参数
s.close() 关闭套接字
面向锁的套接字方法
s.setblocking() 设置套接字的阻塞与非阻塞模式
s.settimeout() 设置阻塞套接字操作的超时时间
s.gettimeout() 得到阻塞套接字操作的超时时间
面向文件的套接字的函数
s.fileno() 套接字的文件描述符
s.makefile() 创建一个与该套接字相关的文件
# send和sendall方法 官方文档对socket模块下的socket.send()和socket.sendall()解释如下: socket.send(string[, flags]) Send data to the socket. The socket must be connected to a remote socket. The optional
flags argument has the same meaning as for recv() above. Returns the number of bytes sent.
Applications are responsible for checking that all data has been sent;
if only some of the data was transmitted, the application needs to attempt delivery of the remaining data. send()的返回值是发送的字节数量,这个数量值可能小于要发送的string的字节数,也就是说可能无法发送string中所有的数据。如果有错误则会抛出异常。
socket.sendall(string[, flags]) Send data to the socket. The socket must be connected to a remote socket.
The optional flags argument has the same meaning as for recv() above. Unlike send(),
this method continues to send data from string until either all data has been sent or an error occurs.
None is returned on success. On error, an exception is raised,
and there is no way to determine how much data, if any, was successfully sent. 尝试发送string的所有数据,成功则返回None,失败则抛出异常。 故,下面两段代码是等价的: #sock.sendall('Hello world\n') #buffer = 'Hello world\n' #while buffer: # bytes = sock.send(buffer) # 返回发送的字节数量 # buffer = buffer[bytes:]
81:验证客户端链接的合法性
如果你想在分布式系统中实现一个简单的客户端链接认证功能,又不像SSL那么复杂,那么利用hmac+加盐的方式来实现
#_*_coding:utf-8_*_ from socket import * import hmac,os secret_key=b'linhaifeng bang bang bang' def conn_auth(conn): ''' 认证客户端链接 :param conn: :return: ''' print('开始验证新链接的合法性') msg=os.urandom(32) conn.sendall(msg) h=hmac.new(secret_key,msg) digest=h.digest() respone=conn.recv(len(digest)) return hmac.compare_digest(respone,digest) def data_handler(conn,bufsize=1024): if not conn_auth(conn): print('该链接不合法,关闭') conn.close() return print('链接合法,开始通信') while True: data=conn.recv(bufsize) if not data:break conn.sendall(data.upper()) def server_handler(ip_port,bufsize,backlog=5): ''' 只处理链接 :param ip_port: :return: ''' tcp_socket_server=socket(AF_INET,SOCK_STREAM) tcp_socket_server.bind(ip_port) tcp_socket_server.listen(backlog) while True: conn,addr=tcp_socket_server.accept() print('新连接[%s:%s]' %(addr[0],addr[1])) data_handler(conn,bufsize) if __name__ == '__main__': ip_port=('127.0.0.1',9999) bufsize=1024 server_handler(ip_port,bufsize)
#_*_coding:utf-8_*_ __author__ = 'Linhaifeng' from socket import * import hmac,os secret_key=b'linhaifeng bang bang bang' def conn_auth(conn): ''' 验证客户端到服务器的链接 :param conn: :return: ''' msg=conn.recv(32) h=hmac.new(secret_key,msg) digest=h.digest() conn.sendall(digest) def client_handler(ip_port,bufsize=1024): tcp_socket_client=socket(AF_INET,SOCK_STREAM) tcp_socket_client.connect(ip_port) conn_auth(tcp_socket_client) while True: data=input('>>: ').strip() if not data:continue if data == 'quit':break tcp_socket_client.sendall(data.encode('utf-8')) respone=tcp_socket_client.recv(bufsize) print(respone.decode('utf-8')) tcp_socket_client.close() if __name__ == '__main__': ip_port=('127.0.0.1',9999) bufsize=1024 client_handler(ip_port,bufsize)
#_*_coding:utf-8_*_ __author__ = 'Linhaifeng' from socket import * def client_handler(ip_port,bufsize=1024): tcp_socket_client=socket(AF_INET,SOCK_STREAM) tcp_socket_client.connect(ip_port) while True: data=input('>>: ').strip() if not data:continue if data == 'quit':break tcp_socket_client.sendall(data.encode('utf-8')) respone=tcp_socket_client.recv(bufsize) print(respone.decode('utf-8')) tcp_socket_client.close() if __name__ == '__main__': ip_port=('127.0.0.1',9999) bufsize=1024 client_handler(ip_port,bufsize)
#_*_coding:utf-8_*_ __author__ = 'Linhaifeng' from socket import * import hmac,os secret_key=b'linhaifeng bang bang bang1111' def conn_auth(conn): ''' 验证客户端到服务器的链接 :param conn: :return: ''' msg=conn.recv(32) h=hmac.new(secret_key,msg) digest=h.digest() conn.sendall(digest) def client_handler(ip_port,bufsize=1024): tcp_socket_client=socket(AF_INET,SOCK_STREAM) tcp_socket_client.connect(ip_port) conn_auth(tcp_socket_client) while True: data=input('>>: ').strip() if not data:continue if data == 'quit':break tcp_socket_client.sendall(data.encode('utf-8')) respone=tcp_socket_client.recv(bufsize) print(respone.decode('utf-8')) tcp_socket_client.close() if __name__ == '__main__': ip_port=('127.0.0.1',9999) bufsize=1024 client_handler(ip_port,bufsize)
82:socketserver
解读socketserver源码 —— http://www.cnblogs.com/Eva-J/p/5081851.html
# server端 import socketserver class Myserver(socketserver.BaseRequestHandler): def handle(self): self.data = self.request.recv(1024).strip() print("{} wrote:".format(self.client_address[0])) print(self.data) self.request.sendall(self.data.upper()) if __name__ == "__main__": HOST, PORT = "127.0.0.1", 9999 # 设置allow_reuse_address允许服务器重用地址 socketserver.TCPServer.allow_reuse_address = True # 创建一个server, 将服务地址绑定到127.0.0.1:9999 server = socketserver.TCPServer((HOST, PORT),Myserver) # 让server永远运行下去,除非强制停止程序 server.serve_forever()
# client import socket HOST, PORT = "127.0.0.1", 9999 data = "hello" # 创建一个socket链接,SOCK_STREAM代表使用TCP协议 with socket.socket(socket.AF_INET, socket.SOCK_STREAM) as sock: sock.connect((HOST, PORT)) # 链接到客户端 sock.sendall(bytes(data + "\n", "utf-8")) # 向服务端发送数据 received = str(sock.recv(1024), "utf-8")# 从服务端接收数据 print("Sent: {}".format(data)) print("Received: {}".format(received))

 浙公网安备 33010602011771号
浙公网安备 33010602011771号