ES基本介绍

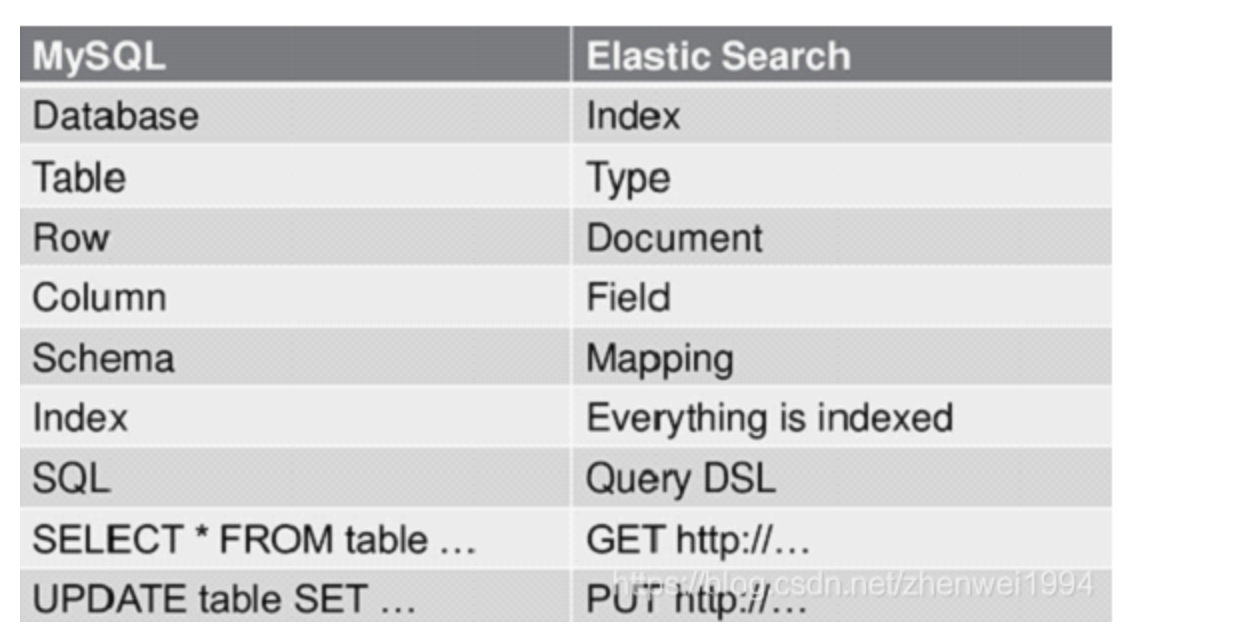
ES中有几个基本概念:索引(index)、类型(type)、文档(document)、映射(mapping)等。
ES、Lucene、solr对比:
Luence是Apache基于Java编写的信息搜索工具包(jar包),它包含了索引结构、读写索引工具、相关性工具、排序等功能,因此Lucene的使用需要我们进一步开发搜索引擎系统, 如果数据获取、解析、分词等
Solr 是一个有HTTP接口的基于Lucene的查询服务器,是一个搜索引擎系统,系统封装了很多lucene细节,Solr可以直接利用HTTP GET/POST 请求去查询,维护修改索引。Solr利用zookeeper进行分布式管理,它的实现更加全面,官方提供的功能更多。
Elasticsearch 是一个建立在全文搜索引擎Apache Lucene基础上的搜索引擎,采用的策略师分布式实时文件存储,并将每一个字段都编入索引,使其可以被搜索。es的实时搜索性比solr更好。
倒排索引:
倒排索引操作步骤:
- 先将文档中包含的关键字全部提取出来
- 然后再将关键字与文档的对应关系保存起来
- 最后对关键字本身做索引排序。
这样在用户检索关键字时, 可以先查找关键字索引,在通过关键字与文档的对应关系查找到所在的文档。
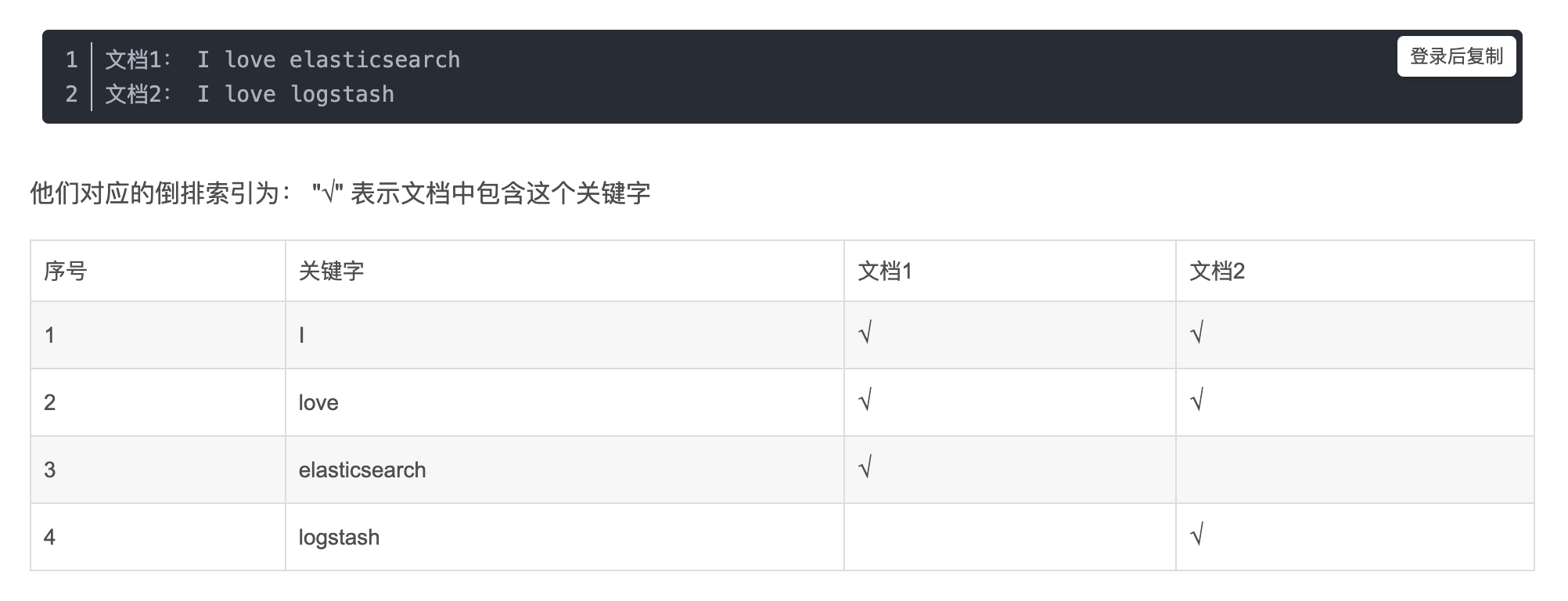
如下面的两个文档:
(2)Cluster:集群,包含多个节点,每个节点属于哪个集群是通过一个配置(集群名称,默认是elasticsearch)来决定的,对于中小型应用来说,刚开始一个集群就一个节点很正常
(3)Node:节点(简单理解为集群中的一个服务器),集群中的一个节点,节点也有一个名称(默认是随机分配的),节点名称很重要(在执行运维管理操作的时候),默认节点会去加入一个名称为“elasticsearch”的集群,如果直接启动一堆节点,那么它们会自动组成一个elasticsearch集群,当然一个节点也可以组成一个elasticsearch集群
(4)Index:索引(简单理解就是一个数据库),包含一堆有相似结构的文档数据,比如可以有一个客户索引,商品分类索引,订单索引,索引有一个名称。一个index包含很多document,一个index就代表了一类类似的或者相同的document。比如说建立一个product index,商品索引,里面可能就存放了所有的商品数据,所有的商品document。
(5)Type:类型(简单理解就是一张表),每个索引里都可以有一个或多个type,type是index中的一个逻辑数据分类,一个type下的document,都有相同的field,比如博客系统,有一个索引,可以定义用户数据type,博客数据type,评论数据type。
(6)Document&field:文档(就是一行数据),es中的最小数据单元,一个document可以是一条客户数据,一条商品分类数据,一条订单数据,通常用JSON数据结构表示,每个index下的type中,都可以去存储多个document。一个document里面有多个field,每个field就是一个数据字段。
————————————————
版权声明:本文为CSDN博主「文艺青年学编程」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/sinat_16658263/article/details/90444038

 浙公网安备 33010602011771号
浙公网安备 33010602011771号