
redis多实例
创建redis的存储目录
vim /usr/local/redis/conf/redis.conf #修改redis的配置文件 dir /data/redis/ #将存储路径配置修改为/data/redis/
mkdir -p /data/redis #创建存储目录 redis-server /usr/local/redis/conf/redis.conf #启动redis redis-cli -a 123456 #登录redis 127.0.0.1:6379> set name2 xixi #插入数据 OK 127.0.0.1:6379> save #保存数据 [3456] 08 Oct 04:39:05.169 * DB saved on disk OK 127.0.0.1:6379> quit #退出redis
ls /data/redis/ #查看保存的文件
dump.rdb redis.log #rdb快照及日志
创建redis多实例的存储目录及文件
#创建redis多实例存储目录 mkdir -p /data/6380/data mkdir -p /data/6381/data #创建redis多实例配置文件 cp /usr/local/redis/conf/redis.conf /data/6380/ cp /usr/local/redis/conf/redis.conf /data/6381/ #修改多实例配置文件的数据存储路 径占用端口 pid文件位置 vim /data/6380/redis.conf dir /data/6380/data port 6380 pidfile /data/6380/redis_6380.pid appendonly yes vim /data/6381/redis.conf dir /data/6381/data port 6381 pidfile /data/3381/redis_6381.pid appendonly yes
启动redis多实例进程
redis-server /usr/local/redis/conf/redis.conf
redis-server /data/6380/redis.conf redis-server /data/6381/redis.conf
netstat -anpt|grep redis
tcp 0 0 0.0.0.0:6379 0.0.0.0:* LISTEN 1544/redis-server 0
tcp 0 0 0.0.0.0:6380 0.0.0.0:* LISTEN 1508/redis-server 0
tcp 0 0 0.0.0.0:6381 0.0.0.0:* LISTEN 1513/redis-server 0
查看多实例文件夹目录树一览
tree /data/ /data/ ├── 6380 #redis实例6380启动目录 │ ├── data #redis实例6380数据目录 │ │ └── appendonly.aof #redis实例6380的数据持久化日志(记录了数据库的修改,类似binlog) │ ├── redis_6380.pid #redispid文件 │ └── redis.conf #redis实例6380数据存储文件 ├── 6381 │ ├── data │ │ └── appendonly.aof │ └── redis.conf └── redis ├── dump.rdb ├── redis_6379.pid └── redis.log
appendonly.aof实际上里面记录的是我们对redis数据库的修改记录,这点类似于MySQL的binlog日志。
Redis主从同步
Redis主从同步特点
- 一个master可以拥有多个slave
- 多个slave可以连接同一个master,还可以连接到其他slave
- 主从复制不会阻塞master,在同步数据时,master可以继续处理client请求。
- 提高系统的伸缩性
Redis主从同步的过程
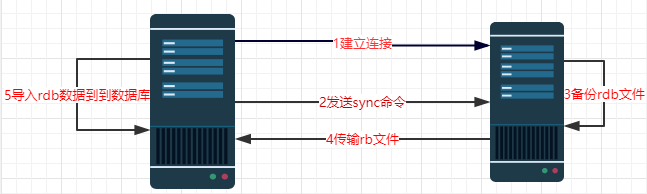
- 配置好slave服务器连接master后,slave会建立和master的连接,然后发送sync命令。
- 无论是第一次同步建立的连接还是连接断开后的重新连接,master都会启动一个后台进程,将数据库快照保存到磁盘文件中,同时master主进程会开始收集新的写命令并缓存起来。
- 当后台进程完成写磁盘文件后,master就将快照文件发送给slave,slave将文件保存到磁盘上,然后加载到内存将数据库快照恢复到slave上。
- slave完成快照文件的恢复后,master就会把缓存的命令都转发给slave,slave更新内存数据库。
- 后续master收到的写命令都会通过开始建立的连接发送给slave。从master到slave的同步数据的命令和从client到master发送的命令使用相同的协议格式。当master和slave的连接断开时,slave可以自动重新建立连接。如果master同时收到多个slave发来的同步连接命令,只会使用启动一个进程来写数据库镜像,然后发送给所有slave。
Redis的主从同步具有明显的分布式缓存特点:
(1)一个master可以有多个slave,一个slave下面还可以有多个slave
(2)slave不仅可以连接到master,slave也可以连接其他slave形成树状。
(3)主从同步不会阻塞master,但是会阻塞slave。也就是说当一个或多个slave与master进行初次同步数据时,master可以继续处理client发来的请求。相反slave在初次同步数据时则会阻塞不能处理client的请求。
(4)主从同步可以用来提高系统的可伸缩性,我们可以用多个slave专门处理client端的读请求,也可以用来做简单的数据冗余或者只在slave上进行持久化从而提升集群的整体性能。
(5)对于老版本的redis,每次重连都会重新发送所有数据。
Redis主动同步设置方法
有两种方式可以用来完成进行主从Redis服务器的同步设置。都需要在slave服务器上进行,指定slave需要连接的Redis服务器(可能是master,也可能是slave)。
redis的主从同步,不用修改master任何配置 只需要在redis-slave上指定master的IP地址即可
1在redis.conf配置文件中设置
通过简单的配置slave(master端无需配置),用户就能使用redis的主从复制
我们让端口6379的redis做master;端口6380的redis做slave
#修改/data/6380/redis.conf的配置文件 slaveof 192.168.50.167 6379 #指定主master的IP和端口 masterauth 123456 #在此处添加本行内容,指定验证的密码
#重启服务
当再次启动从库时日志文件出现如下信息:
Server initialized #服务器初始化 DB loaded from append only file: 0.000 seconds #数据从磁盘加载0秒 Ready to accept connections #准备接受连接 Connecting to MASTER 192.168.50.167:6379 #连接到master 192.168.200.165:6379 MASTER <-> SLAVE sync started #开始主从同步 Non blocking connect for SYNC fired the event. #这是一个不阻塞事件 Master replied to PING, replication can continue... #master答应了ping 同步开始 Partial resynchronization not possible (no cached master) #部分同步不可能(master没有缓存主文件) Full resync from master: 42a28d64ff5c8cb992b3139a98463ec37151accc:140 #从master同步全部数据 MASTER <-> SLAVE sync: receiving 304 bytes from master #从master接收到304字节数据 MASTER <-> SLAVE sync: Flushing old data #刷新旧数据 MASTER <-> SLAVE sync: Loading DB in memory #加载数据到内存 MASTER <-> SLAVE sync: Finished with success #同步完成 Background append only file rewriting started by pid 1957 #AOF重写 AOF rewrite child asks to stop sending diffs. Parent agreed to stop sending diffs. Finalizing AOF... Concatenating 0.00 MB of AOF diff received from parent. SYNC append only file rewrite performed AOF rewrite: 0 MB of memory used by copy-on-write Background AOF rewrite terminated with success #AOF重写成功 Residual parent diff successfully flushed to the rewritten AOF (0.00 MB) Background AOF rewrite finished successfully #AOF重写完毕
主库log日志信息
#从192.168.50.167:6380请求同步 26003:M 11 Aug 14:14:55.342 * Slave 192.168.50.167:6380 asks for synchronization #从192.168.50.167:6380请求完整的重新同步 26003:M 11 Aug 14:14:55.342 * Full resync requested by slave 192.168.50.167:6380 #master启动bgsave与目标的磁盘进行同步 26003:M 11 Aug 14:14:55.342 * Starting BGSAVE for SYNC with target: disk #后台保存rdb的进程的pid号为26128 26003:M 11 Aug 14:14:55.342 * Background saving started by pid 26128 #rdb文件已经保存到了磁盘 26128:C 11 Aug 14:14:55.344 * DB saved on disk #rdb写时复制使用了0MB的内存 26128:C 11 Aug 14:14:55.344 * RDB: 0 MB of memory used by copy-on-write #后台保存成功 26003:M 11 Aug 14:14:55.414 * Background saving terminated with success #与从192.168.50.167:6380同步成功 26003:M 11 Aug 14:14:55.415 * Synchronization with slave 192.168.50.167:6380 succeeded
redis-cli slaveof no one #停止主从同步 redis-cli slaveof 192.168.50.167 6379 #启动主从同步
redis主从同步相关配置参数解释
slaveof 192.168.0.135 6379 #用于标识master的连接IP及端口号 masterauth 123456 #如果master设置了连接密码,这里要写上 slave-serve-stale-data yes #如果设置yes,那么一旦从库连接不上主库,从库继续响应客户端发来的请求并回复,但是回复的内容有可能是过期的。如果no,那么slave会应答一个错误提示,就不提供访问了。 slave-read-only yes #yes:从库被设置为只能读 repl-backlog-size 1mb #用于同步的backlog大小,用于从库增量同步 slave-priority 100 #slave的优先级
查看redis各项参数的方法
info #查看各项信息 info cpu #查看CPU信息 info memory #查看内存信息 info memory #查看内存信息
info replication #查看同步信息role:master #本redis是主slave0:ip=192.168.0.135,port=6380,state=online,offset=11972,lag=1 #主库ip,端口,状态,偏移量等
redis的高级特性
1.redis数据过期设置及过期机制
Redis支持按key设置过期时间,过期后值将被删除(在客户端看来是被删除了的)
用TTL命令可以获取某个key值的过期时间(-1表示永久不过期)
127.0.0.1:6379> TTL name #查看key过期时间(-1为永久不过期,-2为已经过期) (integer) -1
给key值设置6秒过期时间
127.0.0.1:6379> expire wk 6 #设置key值wk6秒过期时间 (integer) 1 127.0.0.1:6379> TTL wk (integer) 2 127.0.0.1:6379> TTL wk (integer) 1 127.0.0.1:6379> TTL wk (integer) 0 127.0.0.1:6379> TTL wk #已过期 过期的key是无法获取value的
(integer) -2
2.redis持久化
Redis的所有数据都存储在内存中,但是他也提供对这些数据的持久化
redis是一个支持持久化的内存数据库,也就是说redis需要经常将内存中的数据同步到磁盘来保证持久化。redis支持两种持久化方式,一种是Snapshotting(快照)也是默认方式,另一种是Append-only file(缩写aof)的方式。
①数据快照
#与rdb相关的配置文件信息 dir /data/redis/ #dir为rdb存储的路径 dbfilename dump.rdb #rdb存储文件的名字 save 900 1 #900 秒内如果超过1个key被修改,则发起快照保存 save 300 10 #300 秒内如果超过10个key被修改,则发起快照保存 save 60 10000 #60 秒内如果超过10000个key被修改,则发起快照保存 rdbcompression no #rdb压缩最好关闭,影响cpu
介绍详细的快照保存过程:
redis调用fork,现在有了子进程和父进程.
父进程继续处理client请求,子进程负责将内存内容写入到临时文件。由于Linux的写时复制机制(copy on write)父子进程会共享相同的物理页面,当父进程处理写请求时Linux会为父进程要修改的页面创建副本,而不是写共享的页面。所以子进程地址空间内的数据是fork时的整个数据库的一个快照。
当子进程将快照写入临时文件完毕后,用临时文件替换原来的快照文件,然后子进程退出。client也可以使用save或者bgsave命令通知redis做一次快照持久化。save操作是在主线程中保存快照的,由于redis是用一个主线程来处理所有client的请求,这种方式会阻塞所有client请求。所以不推荐使用,bgsave开启一个子进程因此不会阻塞。另一点需要注意的是,每次快照持久化都是将内存数据完整写入到磁盘一次,并不是增量的只同步变更数据。如果数据量大的话,而且写操作比较多,必然会引起大量的磁盘io操作,可能会严重影响性能.
数据快照的原理是将整个Redis中存的所有数据一遍一遍的存到一个扩展名为rdb的数据文件中。通过SAVE命令可以调用这个过程。
redis关闭时,redis自动进行RDB文件的保存 启动时会读取RDB文件.如果没有找到RDB文件则数据丢失.
设置开启或者关闭rdb存储
方法一: vim /usr/local/redis/conf/redis.conf save "" #关闭rdb save 60 10000 #开启rdb save 300 10 save 900 1 方法二: redis-cli config set save "" #关闭rdb存储 redis-cli config rewrite #配置保存 redis-cli config set save "180 1 120 10 60 10000" #开启rdb redis-cli config rewrite #配置保存
②Append-Only File(追加式的操作日志)
redis的appendonly(aof)持久化存储会把用户每次的操作都记录到文件中(类似mysqlbinlog)
由于快照方式是在一定间隔时间做一次的,所以如果redis意外down掉的话,就会丢失最后一次快照后的所有修改。如果应用要求不能丢失任何修改的话,可以采用aof持久化方式。
aof比快照方式有更好的持久化性,是由于在使用aof持久化方式时,redis会将每一个收到的写命令都通过write函数追加到文件中(默认是appendonly.aof)。当redis重启时会通过重新执行文件中保存的写命令来在内存中重建整个数据库的内容.当然由于os会在内核中缓存write做的修改,所以可能不是立即写到磁盘上。这样aof方式的持久化也还是有可能会丢失部分修改。不过我们可以通过配置文件告诉redis我们想要通过fsync函数强制os写入到磁盘的时机。有三种方式如下(默认是:每秒fsync一次)
appendonly yes #启用aof持久化方式 no关闭
appendfsync always #收到写命令就立即写入磁盘,最慢,但是保证完全的持久化
appendfsync everysec #每秒钟写入磁盘一次,在性能和持久化方面做了很好的折中
appendfsync no #完全依赖os,性能最好,持久化没保证
aof引发的问题:
aof的方式也同时带来了另一个问题。持久化文件会变得越来越大.例如我们调用incr test命令100次,文件中必须保存全部的100条命令,其实有99条都是多余的。因为要恢复数据库的状态其实文件中保存一条set test 100 就够了。为了压缩aof的持久化文件。redis提供了bgrewriteaof命令。收到此命令redis将使用与快照类似的方式将内存中的数据以命令的方式保存到临时文件中,最后替换原来的文件。
过程:
- redis调用fork,现在有父子两个进程
- 子进程根据内存中的数据库快照,往临时文件中写入重建数据库状态的命令。
- 父进程继续处理client请求,除了把写命令写入到原来的aof文件中。同时把收到的写命令缓存起来.这样就能保证如果子进程重写失败的话并不会出问题。
- 当子进程把快照内容写入已命令方式写到临时文件中后,子进程发信号通知父进程。然后父进程把缓存的写命令也写入到临时文件。
- 现在父进程可以使用临时文件替换老的aof文件,并重命令名,后面收到的写命令也开始往新的aof文件中追加。
vim /data/6380/redis.conf appendonly yes auto-aof-rewrite-percentage 100 #当100%达到最小大小的时候才会执行重写 auto-aof-rewrite-min-size 64mb #自动重写aof文件的最小大小

 浙公网安备 33010602011771号
浙公网安备 33010602011771号