
查看所有的数据库及数据库里的表
show databases;
show tables;
创建数据库
create database db1 charset utf8; #后边是指字符集
修改数据库字符集
alter database db1 charset gbk;
建表
简单的表操作
create table biao1(id int,user char(20));
查看表的详细信息
desc biao1;
查看数据
select * from db1.biao1;
插入数据
insert into biao1(id,user) values (1,'wk'); #mysql里的数据和python很像,需要单引号''
insert into biao1(id,user) values (1,'wk'),(2,'wa'),(3,'wb'),(4,'wc'); # 同时插入多条数据
修改数据
update db1.biao1 set user='ww'; #改所有 update db1.biao1 set user='wk' where id = '2'; #将ID为2的user改为'wk'
删数据
delete from biao1 where id = '1'; #删除表内 id为1 的数据 delete from biao1; #删除表内所有数据
mysql的存储引擎
show engines\G; #查看所有支持的引擎 show variables like 'storage_engine%'; #查看当前正在使用的数据库
InnoDB 存储引擎
支持事务,其设计目标主要面向联机事务处理(OLTP)的应用。其
特点是行锁设计、支持外键,并支持类似 Oracle 的非锁定读,即默认读取操作不会产生锁。 从 MySQL 5.5.8 版本开始是默认的存储引擎。
InnoDB 存储引擎将数据放在一个逻辑的表空间中,这个表空间就像黑盒一样由 InnoDB 存储引擎自身来管理。从 MySQL 4.1(包括 4.1)版本开始,可以将每个 InnoDB 存储引擎的 表单独存放到一个独立的 ibd 文件中。此外,InnoDB 存储引擎支持将裸设备(row disk)用 于建立其表空间。
InnoDB 通过使用多版本并发控制(MVCC)来获得高并发性,并且实现了 SQL 标准 的 4 种隔离级别,默认为 REPEATABLE 级别,同时使用一种称为 netx-key locking 的策略来 避免幻读(phantom)现象的产生。除此之外,InnoDB 存储引擎还提供了插入缓冲(insert buffer)、二次写(double write)、自适应哈希索引(adaptive hash index)、预读(read ahead) 等高性能和高可用的功能。
对于表中数据的存储,InnoDB 存储引擎采用了聚集(clustered)的方式,每张表都是按 主键的顺序进行存储的,如果没有显式地在表定义时指定主键,InnoDB 存储引擎会为每一 行生成一个 6 字节的 ROWID,并以此作为主键。
InnoDB 存储引擎是 MySQL 数据库最为常用的一种引擎,Facebook、Google、Yahoo 等 公司的成功应用已经证明了 InnoDB 存储引擎具备高可用性、高性能以及高可扩展性。对其 底层实现的掌握和理解也需要时间和技术的积累。如果想深入了解 InnoDB 存储引擎的工作 原理、实现和应用,可以参考《MySQL 技术内幕:InnoDB 存储引擎》一书。
MyISAM 存储引擎
不支持事务、表锁设计、支持全文索引,主要面向一些 OLAP 数 据库应用,在 MySQL 5.5.8 版本之前是默认的存储引擎(除 Windows 版本外)。数据库系统 与文件系统一个很大的不同在于对事务的支持,MyISAM 存储引擎是不支持事务的。究其根 本,这也并不难理解。用户在所有的应用中是否都需要事务呢?在数据仓库中,如果没有 ETL 这些操作,只是简单地通过报表查询还需要事务的支持吗?此外,MyISAM 存储引擎的 另一个与众不同的地方是,它的缓冲池只缓存(cache)索引文件,而不缓存数据文件,这与 大多数的数据库都不相同。
NDB 存储引擎
年,MySQL AB 公司从 Sony Ericsson 公司收购了 NDB 存储引擎。 NDB 存储引擎是一个集群存储引擎,类似于 Oracle 的 RAC 集群,不过与 Oracle RAC 的 share everything 结构不同的是,其结构是 share nothing 的集群架构,因此能提供更高级别的 高可用性。NDB 存储引擎的特点是数据全部放在内存中(从 5.1 版本开始,可以将非索引数 据放在磁盘上),因此主键查找(primary key lookups)的速度极快,并且能够在线添加 NDB 数据存储节点(data node)以便线性地提高数据库性能。由此可见,NDB 存储引擎是高可用、 高性能、高可扩展性的数据库集群系统,其面向的也是 OLTP 的数据库应用类型。
Memory 存储引擎 #内存级表 重启表内数据消失
正如其名,Memory 存储引擎中的数据都存放在内存中,数据库重 启或发生崩溃,表中的数据都将消失。它非常适合于存储 OLTP 数据库应用中临时数据的临时表,也可以作为 OLAP 数据库应用中数据仓库的维度表。Memory 存储引擎默认使用哈希 索引,而不是通常熟悉的 B+ 树索引。
Infobright 存储引擎
第三方的存储引擎。其特点是存储是按照列而非行的,因此非常 适合 OLAP 的数据库应用。其官方网站是 http://www.infobright.org/,上面有不少成功的数据 仓库案例可供分析。
NTSE 存储引擎
网易公司开发的面向其内部使用的存储引擎。目前的版本不支持事务, 但提供压缩、行级缓存等特性,不久的将来会实现面向内存的事务支持。
BLACKHOLE
黑洞存储引擎,可以应用于主备复制中的分发主库。
MySQL 数据库还有很多其他存储引擎,上述只是列举了最为常用的一些引擎。如果 你喜欢,完全可以编写专属于自己的引擎,这就是开源赋予我们的能力,也是开源的魅 力所在。
指定表的存储引擎
create table biao2(id int)engine=innodb; #创建指定innodb存储引擎的表
复制表(可夸库复制)
create table biao6 select * from db1.biao1; #既复制结构又复制数据
create table biao7 select * from db1.biao1 where 1>5; #在db1数据库下新创建一个biao7表,给一个where条件,条件要求不成立,条件为false,只拷贝表结构
create table biao8 like biao1; #使用like(只拷贝表结构,不拷贝记录)
数据类型
详细参考链接:http://www.runoob.com/mysql/mysql-data-types.html
作用:约束存储
数值型
字符型
时间型
boolean型
枚举型
est集合型
1.数字类型
整型:tinyint int bigint #最常用的int 数据类型分为有符号和无符号,有符号为负数,各种数字型的数据类型都是有不同的范围的 小数: float :在位数比较短的情况下不精准 double :在位数比较长的情况下不精准 0.000001230123123123 存成:0.000001230000 decimal:(如果用小数,则用推荐使用decimal) #小数最常用 精准 内部原理是以字符串形式去存
create table biao9(id int); #创个一个biao9 id为int数字类型,数字类型默认是有符号的 insert into biao9 values(-1); #插入一个有符号的数字-1 select * from biao9; #查看到有数据 +------+ | id | +------+ | -1 | +------+
create table biao1(id int unsigned); #后边加unsigned 创建无符号的数字型的表 insert into biao1 values(-30); #插入负值要么报错要么插入值为0
字数不满用0填充
create table biao13(id int(5) unsigned zerofill); #定义int位数为5,zerofill不满5位的用0 填充 insert into biao13 value(12); select * from biao13; +-------+ | id | +-------+ | 00012 | +-------+
2.字符串类型
char(10):简单粗暴,浪费空间,存取速度快 #建议使用char root存成root000000 varchar:精准,节省空间,存取速度慢 sql优化:创建表时,定长的类型往前放,变长的往后放 比如性别 比如地址或描述信息 >255个字符,超了就把文件路径存放到数据库中。 比如图片,视频等找一个文件服务器,数据库中只存路径或url。
char类型: 字符长度为:0-255(一个中文是一个字符,是utf8编码的3个字节) 存储: 在存储char类型的值时,如果值的大小小于定义的char的大小,会用空格填充
create table biao2(x char(5),y varchar(4)); #创建表定义x为char类型长度为5 y为varchar类型长度为4 insert into biao2 values('呵呵哒 ','呵呵哒 '); # 往表里加值 "呵呵哒 "(后边有空格) select * from biao2; #查看表 +-----------+------------+ | x | y | +-----------+------------+ | 呵呵哒 | 呵呵哒 | +-----------+------------+ select x,char_length(x),y,char_length(y) from biao2; #使用char_length()函数查看表内键对应的值所占用的字符数 但是不显示空格所占用的字符 +-----------+----------------+------------+----------------+ | x | char_length(x) | y | char_length(y) | +-----------+----------------+------------+----------------+ | 呵呵哒 | 3 | 呵呵哒 | 4 | #此时char显示的长度并非战争的长度,因为在查询时char类型忽略了空格 +-----------+----------------+------------+----------------+
SET sql_mode = 'PAD_CHAR_TO_FULL_LENGTH'; #输入此命令,改变mode模式 select @@sql_mode; #查看当前的mode模式 +-------------------------+ | @@sql_mode | +-------------------------+ | PAD_CHAR_TO_FULL_LENGTH | +-------------------------+ select x,char_length(x),y,char_length(y) from biao2; #此时再查看char类型的值的长度 +-------------+----------------+------------+----------------+ | x | char_length(x) | y | char_length(y) | +-------------+----------------+------------+----------------+ | 呵呵哒 | 5 | 呵呵哒 | 4 | +-------------+----------------+------------+----------------+
3.时间类型
最常用:datetime
time
date
year
create table biao1(d date,t time,dt datetime,y year); #创建表1 数据类型为date,time,datetime,year insert into biao1 values(now(),now(),now(),now()); #使用数据库的内置函数now()将当前的时间插入到数据库中. select * from biao1; #now()函数会把各个字段所需要的数据插入进去 +------------+----------+---------------------+------+ | d | t | dt | y | +------------+----------+---------------------+------+ | 2019-01-26 | 12:46:36 | 2019-01-26 12:46:36 | 2019 | +------------+----------+---------------------+------+
4.枚举与集合类型
enum 和set
-> create table biao4( #创建表4 -> id int, -> name varchar(20), -> sex enum('male','female','other'), -> level enum('vip1','vip2','vip3','vip4'), #enum 在指定范围内多选一 -> fav set('play','music','read','study') #set在指定范围内既可以多选一又可以多选多 -> );
insert into biao4 values(1,'wk','male','vip4','play,music') #往里插入数据
select * from biao4; +------+------+------+-------+------------+ | id | name | sex | level | fav | +------+------+------+-------+------------+ | 1 | wk | male | vip4 | play,music | +------+------+------+-------+------------+
完整性约束 设计表
作用:保证数据的完整性和一致性,
not null 与 default #not null 不能为空 default如果为控制走默认
unique 唯一
primary key 主键,必须是唯一且不能为空
auto_increment 自增长
foreign key 外键
1.not null 与default 不能为空与默认
create table biao5( id int(5), name char(20) not null); #创建表5 并指定name字段不能为空
create table biao7( id int not null default 3, name char(20) ); #创建表7 不能为空,如果为空默认值为3 insert into biao7(name) values('wk'); #插入数据name=wk select * from biao7; #id默认为3 ,如果id插入时有值还是存插入的值 +----+------+ | id | name | +----+------+ | 3 | wk | +----+------+
desc biao7; #查看表, id 的null为no +-------+----------+------+-----+---------+-------+ | Field | Type | Null | Key | Default | Extra | +-------+----------+------+-----+---------+-------+ | id | int(11) | NO | | 3 | | | name | char(20) | YES | | NULL | | +-------+----------+------+-----+---------+-------+
2.unique 唯一
单列唯一
create table biao1(id int unique,name char(20)); #创建一个表定义ID是唯一的值 单列的id的值只能是唯一的 insert into biao1(id,name) values(1,'wk'); #先插入数据 1,wk Query OK, 1 row affected (0.00 sec) insert into biao1(id,name) values(1,'wc'); #在插入数据id还是1,wc报错 ERROR 1062 (23000): Duplicate entry '1' for key 'id'
desc biao1; #查看表, 加unique时,kye下显示UNI +-------+----------+------+-----+---------+-------+ | Field | Type | Null | Key | Default | Extra | +-------+----------+------+-----+---------+-------+ | id | int(11) | YES | UNI | NULL | | | name | char(20) | YES | | NULL | | +-------+----------+------+-----+---------+-------+
create table biao3(id int ,name char(20),unique(id)); #unique也可以这样写
多列唯一
create table biao5(id int unique,name char(20),ip char(40) unique); #多列唯一,
desc biao5; #两个uni +-------+----------+------+-----+---------+-------+ | Field | Type | Null | Key | Default | Extra | +-------+----------+------+-----+---------+-------+ | id | int(11) | YES | UNI | NULL | | | name | char(20) | YES | | NULL | | | ip | char(40) | YES | UNI | NULL | | +-------+----------+------+-----+---------+-------+
联合唯一
create table biao6(id int ,name char(20),ip char(40),unique(id,ip)); #联合唯一,只要有一列不同就可以插入
desc biao6; +-------+----------+------+-----+---------+-------+ | Field | Type | Null | Key | Default | Extra | +-------+----------+------+-----+---------+-------+ | id | int(11) | YES | MUL | NULL | | | name | char(20) | YES | | NULL | | | ip | char(40) | YES | | NULL | | +-------+----------+------+-----+---------+-------+
3.primary key 主键
一张表中只有一个主键 主键只有单列与联合没有多列
单列主键
create table biao8(id int primary key,name char(10),ip char(15)); #创建biao8,将id设为主键 主键等价于not null +unique,但是也不想同
联合主键
create table biao1(id int,name char(20),ip char(5),primary key(id,ip)); #联合主键使用很少
4.auto_increment 自增长
create table biao9(id int primary key auto_increment,name char(10),ip char(15)); #设置id为主键切自增长,自增长默认从1开始增长,增长的步伐为1
insert into biao9(name,ip) values('wk',12); #插入数据ID自增长 insert into biao9(name,ip) values('wc',13); insert into biao9(name,ip) values('wd',14); insert into biao9(name,ip) values('we',12); select * from biao9; +----+------+------+ | id | name | ip | +----+------+------+ | 1 | wk | 12 | | 2 | wc | 13 | | 3 | wd | 14 | | 4 | we | 12 | +----+------+------+
5.foreign key 外键
先创建主表在创建从表,有外键的是从表
分俩表创建一个关联的学校班级表
表一字段: id name age dep-id 学生信息 表二字段:id class 班主任 班级信息
一个班级可以有多个学生, 一个学生只能有一个班级 先创建班级信息表 在创建个学生信息表
create table 班级信息(Bid int primary key auto_increment,class char(20),班主任 char(20)); #表二,班级信息表 create table 学生信息(id int primary key auto_increment,
name char(20) not null,
age int default 18,
dep_id int,constraint fk_dep foreign key(dep_id) references 班级信息(Bid) on delete cascade on update cascade); #表1,学生信息 , fk_dep 可以是任意名字,随便起 constraint fk_dep foreign key(dep_id) references 班级信息(Bid) ,将表里的dep_id与班级信息表的Bid字段相关联
on delete cascade on update cascade 同步更新,同步删除
插入数据 先插入主表的数据, 再加入从表的数据
insert into 班级信息(Bid,class,班主任) values(1,'初1一班','苍老师'); Query OK, 1 row affected (0.00 sec)
insert into 班级信息(Bid,class,班主任) values(2,'初1二班','波老师'); Query OK, 1 row affected (0.00 sec)
insert into 班级信息(class,班主任) values('初2一班','玛老师'); Query OK, 1 row affected (0.00 sec)
insert into 班级信息(class,班主任) values('初2二班','龙老师'); Query OK, 1 row affected (0.00 sec)
select * from 班级信息; +-----+------------+-----------+ | Bid | class | 班主任 | +-----+------------+-----------+ | 1 | 初1一班 | 苍老师 | | 2 | 初1二班 | 波老师 | | 3 | 初2一班 | 玛老师 | | 4 | 初2二班 | 龙老师 | +-----+------------+-----------+
insert into 学生信息(name,age,dep_id) values('ww',3,2),('wd',5,4),('wc',3,1),('ws',8,2),('wz',21,3),('ww',1,2),('wo',8,3),('wq',8,4),('wx',3,2); select * from 学生信息; +----+------+------+--------+ | id | name | age | dep_id | +----+------+------+--------+ | 1 | wk | 8 | 1 | | 2 | ww | 3 | 2 | | 3 | wd | 5 | 4 | | 4 | wc | 3 | 1 | | 5 | ws | 8 | 2 | | 6 | wz | 21 | 3 | | 7 | ww | 1 | 2 | | 8 | wo | 8 | 3 | | 9 | wq | 8 | 4 | | 10 | wx | 3 | 2 | +----+------+------+--------+
delete from 班级信息 where Bid = '1'; #同步删除,同步更新,删除班级信息的 Bid为1的值 Query OK, 1 row affected (0.00 sec) select * from 班级信息; +-----+------------+-----------+ | Bid | class | 班主任 | +-----+------------+-----------+ | 2 | 初1二班 | 波老师 | | 3 | 初2一班 | 玛老师 | | 4 | 初2二班 | 龙老师 | +-----+------------+-----------+ select * from 学生信息; #学生信息里对应的外键为Bid为1的值也被删除了 +----+------+------+--------+ | id | name | age | dep_id | +----+------+------+--------+ | 1 | ww | 3 | 2 | | 2 | wd | 5 | 4 | | 4 | ws | 8 | 2 | | 5 | wz | 21 | 3 | | 6 | ww | 1 | 2 | | 7 | wo | 8 | 3 | | 8 | wq | 8 | 4 | | 9 | wx | 3 | 2 | +----+------+------+--------+ 8 rows in set (0.00 sec)
update 班级信息 set Bid = 2 where Bid = 1; #同步更新 Query OK, 0 rows affected (0.00 sec) select * from 班级信息; +-----+------------+-----------+ | Bid | class | 班主任 | +-----+------------+-----------+ | 1 | 初1二班 | 波老师 | | 3 | 初2一班 | 玛老师 | | 4 | 初2二班 | 龙老师 | +-----+------------+-----------+ select * from 学生信息; +----+------+------+--------+ | id | name | age | dep_id | +----+------+------+--------+ | 1 | ww | 3 | 1 | | 2 | wd | 5 | 4 | | 4 | ws | 8 | 1 | | 5 | wz | 21 | 3 | | 6 | ww | 1 | 1 | | 7 | wo | 8 | 3 | | 8 | wq | 8 | 4 | | 9 | wx | 3 | 1 | +----+------+------+--------+ 8 rows in set (0.00 sec)
外键变种
如何找出两张表之间的关系
分析步骤: #1、先站在左表的角度去找 是否左表的多条记录可以对应右表的一条记录,如果是,则证明左表的一个字段foreign key 右表一个字段(通常是id) #2、再站在右表的角度去找 是否右表的多条记录可以对应左表的一条记录,如果是,则证明右表的一个字段foreign key 左表一个字段(通常是id) #3、总结: #多对一: 如果只有步骤1成立,则是左表多对一右表 如果只有步骤2成立,则是右表多对一左表 #多对多 如果步骤1和2同时成立,则证明这两张表时一个双向的多对一,即多对多,需要定义一个这两张表的关系表来专门存放二者的关系 #一对一: 如果1和2都不成立,而是左表的一条记录唯一对应右表的一条记录,反之亦然。这种情况很简单,就是在左表foreign key右表的基础上,将左表的外键字段设置成unique即可
1.一对多或者多对一
书和出版社之间的关系:一个出版社可以出版多本书.
create table press(id int primary key auto_increment, name varchar(20)); 创建出版社表 create table book(id int primary key auto_increment, name varchar(20), press_id int not null, constraint fk_book_press foreign key(press_id) references press(id) on delete cascade on update cascade); #创建图书表 Query OK, 0 rows affected (0.01 sec) insert into press(name) values # 先往被关联表中插入记录 ('北京工业地雷出版社'), ('人民音乐不好听出版社'), ('知识产权没有用出版社') ; insert into book(name,press_id) values # 再往关联表中插入记录 ('九阳神功',1), ('九阴真经',2), ('九阴白骨爪',2), ('独孤九剑',3), ('降龙十巴掌',2), ('葵花宝典',3) ; select * from press; +----+--------------------------------+ | id | name | +----+--------------------------------+ | 1 | 北京工业地雷出版社 | | 2 | 人民音乐不好听出版社 | | 3 | 知识产权没有用出版社 | +----+--------------------------------+ select * from book; +----+-----------------+----------+ | id | name | press_id | +----+-----------------+----------+ | 1 | 九阳神功 | 1 | | 2 | 九阴真经 | 2 | | 3 | 九阴白骨爪 | 2 | | 4 | 独孤九剑 | 3 | | 5 | 降龙十巴掌 | 2 | | 6 | 葵花宝典 | 3 | +----+-----------------+----------+
2.多对多
作者和书籍的关系 一个作者可以写多本书,一本书也可以有多个作者,双向的一对多,即多对多
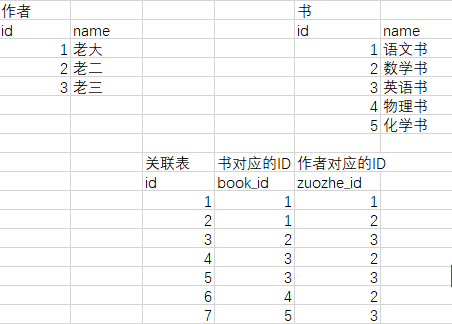
从上边的关联表可以看出
由左到右可以看出语文书(book_id 1 )由老大和老二写的(zuohe_id 1 2)
数学书(book_id 2 )由老三写的(zuohe_id 3)
英语书(book_id 3 )由老二和老三写的(zuohe_id 2 3)
物理书(book_id 4 )由老二写的(zuohe_id 2 )
化学书(book_id 3 )由老三写的(zuohe_id 3)
从右往左可以看出老大(zuohe_id 1)写了 语文书(book_id 1 )
老二(zuohe_id 2)写了 语文书 英语书 物理书(book_id 1 3 4)
老三(zuohe_id 3)写了 数学书 英语书 化学书(book_id 2 3 5)
#先创建 zuozhe表 ,zuozhe表和book表先创建谁都可以 create table zuozhe(id int primary key auto_increment,name varchar(20)); #在创建book表 create table book(id int primary key auto_increment,name char(20)); #创建关联表,这张表就存放了author表和book表的关系,即查询二者的关系查这表就可以了 create table zuozhe2book(id int not null unique auto_increment, zuozhe_id int not null, book_id int not null, constraint fk_zuozhe foreign key(zuozhe_id) references zuozhe(id) on delete cascade on update cascade, constraint fk_book foreign key(book_id) references book(id) on delete cascade on update cascade, primary key(zuozhe_id,book_id) );
#插入四个作者,id依次排开 insert into zuozhe(name) values('wk'),('xx'),('佚名'),('南派'); select * from zuozhe; +----+--------+ | id | name | +----+--------+ | 1 | wk | | 2 | xx | | 3 | 佚名 | | 4 | 南派 | +----+--------+ #插入书籍 insert into book(name) values ('九阳神功'),('九阴真经'),('九阴白骨爪'), ('独孤九剑'), ('降龙十巴掌'), ('葵花宝典'); select * from book; +----+-----------------+ | id | name | +----+-----------------+ | 1 | 九阳神功 | | 2 | 九阴真经 | | 3 | 九阴白骨爪 | | 4 | 独孤九剑 | | 5 | 降龙十巴掌 | | 6 | 葵花宝典 | +----+-----------------+ # 每个作者的代表作 wk: 九阳神功、九阴真经、九阴白骨爪、独孤九剑、降龙十巴掌、葵花宝典 xx: 九阳神功、葵花宝典 佚名:独孤九剑、降龙十巴掌、葵花宝典 南派:九阳神功 # 在author2book表中插入相应的数据 insert into zuozhe2book(zuozhe_id,book_id) values(1,1),(1,2),(1,3),(1,4),(1,5),(1,6),(2,1),(2,6),(3,4),(3,5),(3,6),(4,1); select * from zuozhe2book; +----+-----------+---------+ | id | zuozhe_id | book_id | +----+-----------+---------+ | 1 | 1 | 1 | | 2 | 1 | 2 | | 3 | 1 | 3 | | 4 | 1 | 4 | | 5 | 1 | 5 | | 6 | 1 | 6 | | 7 | 2 | 1 | | 8 | 2 | 6 | | 9 | 3 | 4 | | 10 | 3 | 5 | | 11 | 3 | 6 | | 12 | 4 | 1 | +----+-----------+---------+
3.一对一
只需要在一对多的基础上,给外键设唯一(unique),即一个表只能有一个对应的外键
表的查询
单表和多表
单表查询的语法
where 条件,拿着where指定的约束条件,去文件/表中取出一条条记录
group by 将取出的一条条记录进行分组group by,如果没有group by,则整体作为一组
having 筛选 将分组的结果进行having过滤
distinct去重
order by 将结果按条件排序
limit 限制条数
创建员工表进行测试
表的字段和数据类型 员工id id int 姓名 name varchar 性别 sex enum 年龄 age int 入职日期 hire_date date 岗位 post varchar 职位描述 post_comment varchar 薪水 salary double 办公室 office int 部门编号 depart_id int
create table employee( id int primary key auto_increment, name varchar(20) not null, sex enum('male','female') not null default 'male', #大部分是男的 age int(3) unsigned not null default 28, hire_date date not null, post varchar(50), post_comment varchar(100), salary double(15,2), office int, #一个部门一个屋 depart_id int);
#插入记录三个部门:教学,销售,运营 insert into employee(name ,sex,age,hire_date,post,salary,office,depart_id) values ('wk','male',18,'20170301','xx',7300.33,401,1),
#以下是教学部 ('wq','male',78,'20150302','teacher',1000000.31,401,1), ('ww','male',81,'20130305','teacher',8300,401,1), ('we','male',73,'20140701','teacher',3500,401,1), ('wr','male',28,'20121101','teacher',2100,401,1), ('wt','female',18,'20110211','teacher',9000,401,1), ('wy','male',18,'19000301','teacher',30000,401,1), ('wa','male',48,'20101111','teacher',10000,401,1), #以下是销售部 ('ws','female',48,'20150311','sale',3000.13,402,2), ('wd','female',38,'20101101','sale',2000.35,402,2), ('wf','female',18,'20110312','sale',1000.37,402,2), ('wg','female',18,'20160513','sale',3000.29,402,2), ('wh','female',28,'20170127','sale',4000.33,402,2), #以下是运营部 ('wt','male',28,'20160311','operation',10000.13,403,3), ('wy','male',18,'19970312','operation',20000,403,3), ('wu','female',18,'20130311','operation',19000,403,3), ('wi','male',18,'20150411','operation',18000,403,3), ('wo','female',18,'20140512','operation',17000,403,3) ; select * from employee; +----+------+--------+-----+------------+-----------+--------------+------------+--------+-----------+ | id | name | sex | age | hire_date | post | post_comment | salary | office | depart_id | +----+------+--------+-----+------------+-----------+--------------+------------+--------+-----------+ | 1 | wk | male | 18 | 2017-03-01 | xx | NULL | 7300.33 | 401 | 1 | | 2 | wq | male | 78 | 2015-03-02 | teacher | NULL | 1000000.31 | 401 | 1 | | 3 | ww | male | 81 | 2013-03-05 | teacher | NULL | 8300.00 | 401 | 1 | | 4 | we | male | 73 | 2014-07-01 | teacher | NULL | 3500.00 | 401 | 1 | | 5 | wr | male | 28 | 2012-11-01 | teacher | NULL | 2100.00 | 401 | 1 | | 6 | wt | female | 18 | 2011-02-11 | teacher | NULL | 9000.00 | 401 | 1 | | 7 | wy | male | 18 | 1900-03-01 | teacher | NULL | 30000.00 | 401 | 1 | | 8 | wa | male | 48 | 2010-11-11 | teacher | NULL | 10000.00 | 401 | 1 | | 9 | ws | female | 48 | 2015-03-11 | sale | NULL | 3000.13 | 402 | 2 | | 10 | wd | female | 38 | 2010-11-01 | sale | NULL | 2000.35 | 402 | 2 | | 11 | wf | female | 18 | 2011-03-12 | sale | NULL | 1000.37 | 402 | 2 | | 12 | wg | female | 18 | 2016-05-13 | sale | NULL | 3000.29 | 402 | 2 | | 13 | wh | female | 28 | 2017-01-27 | sale | NULL | 4000.33 | 402 | 2 | | 14 | wt | male | 28 | 2016-03-11 | operation | NULL | 10000.13 | 403 | 3 | | 15 | wy | male | 18 | 1997-03-12 | operation | NULL | 20000.00 | 403 | 3 | | 16 | wu | female | 18 | 2013-03-11 | operation | NULL | 19000.00 | 403 | 3 | | 17 | wi | male | 18 | 2015-04-11 | operation | NULL | 18000.00 | 403 | 3 | | 18 | wo | female | 18 | 2014-05-12 | operation | NULL | 17000.00 | 403 | 3 | +----+------+--------+-----+------------+-----------+--------------+------------+--------+-----------+
(1)where 约束
where可以使用 1.比较运算符:>、<、>=、<=、<>、!= 2.between 80 and 100 :值在80到100之间 3.in(80,90,100)值是80或90或100 4.like 'xiaomagepattern': pattern可以是%或者_。%小时任意多字符,_表示一个字符 5.逻辑运算符:在多个条件直接可以使用逻辑运算符 and or not #1 :单条件查询 select id,name from employee where id > 5; +----+------+ | id | name | +----+------+ | 6 | wt | | 7 | wy | | 8 | wa | | 9 | ws | | 10 | wd | | 11 | wf | | 12 | wg | | 13 | wh | | 14 | wt | | 15 | wy | | 16 | wu | | 17 | wi | | 18 | wo | +----+------+ #2 多条件查询 select name from employee where post='teacher' and salary>10000; +------+ | name | +------+ | wq | | wy | +------+ #3.关键字BETWEEN AND 在什么范围和什么之间 SELECT name,salary FROM employee WHERE salary BETWEEN 10000 AND 20000; +------+----------+ | name | salary | +------+----------+ | wa | 10000.00 | | wt | 10000.13 | | wy | 20000.00 | | wu | 19000.00 | | wi | 18000.00 | | wo | 17000.00 | +------+----------+ SELECT name,salary FROM employee WHERE salary NOT BETWEEN 10000 AND 20000; #不在什么和什么之间 #5:关键字IN集合查询 SELECT name,salary FROM employee WHERE salary=3000 OR salary=3500 OR salary=4000 OR salary=9000 ; +------+---------+ | name | salary | +------+---------+ | we | 3500.00 | | wt | 9000.00 | +------+---------+ SELECT name,salary FROM employee WHERE salary IN (3000,3500,4000,9000) ; SELECT name,salary FROM employee WHERE salary NOT IN (3000,3500,4000,9000) ; #6:关键字LIKE模糊查询 通配符’%’ SELECT * FROM employee WHERE name LIKE '%u%'; +----+------+--------+-----+------------+-----------+--------------+----------+--------+-----------+ | id | name | sex | age | hire_date | post | post_comment | salary | office | depart_id | +----+------+--------+-----+------------+-----------+--------------+----------+--------+-----------+ | 16 | wu | female | 18 | 2013-03-11 | operation | NULL | 19000.00 | 403 | 3 | +----+------+--------+-----+------------+-----------+--------------+----------+--------+-----------+ 通配符'_' 匹配一个字符 SELECT age FROM employee WHERE name LIKE 'ale_';
(2)group by 分组查询
首先明确一点:分组发生在where之后,即分组是基于where之后得到的记录而进行的
分组指的是:将所有记录按照某个相同字段进行归类,比如针对员工信息表的职位分组,或者按照性别进行分组等
为何要分组呢?
取每个部门的最高工资
取每个部门的员工数
取男人数和女人数
select * from employee group by post; #将post分组,分成了 operation ,sale, tracher,和xx组 +----+------+--------+-----+------------+-----------+--------------+------------+--------+-----------+ | id | name | sex | age | hire_date | post | post_comment | salary | office | depart_id | +----+------+--------+-----+------------+-----------+--------------+------------+--------+-----------+ | 14 | wt | male | 28 | 2016-03-11 | operation | NULL | 10000.13 | 403 | 3 | | 9 | ws | female | 48 | 2015-03-11 | sale | NULL | 3000.13 | 402 | 2 | | 2 | wq | male | 78 | 2015-03-02 | teacher | NULL | 1000000.31 | 401 | 1 | | 1 | wk | male | 18 | 2017-03-01 | xx | NULL | 7300.33 | 401 | 1 | +----+------+--------+-----+------------+-----------+--------------+------------+--------+-----------+
#由于没有设置ONLY_FULL_GROUP_BY,于是也可以有结果,默认都是组内的第一条记录,但其实这是没有意义的 如果想分组,则必须要设置全局的sql的模式为ONLY_FULL_GROUP_BY mysql> set global sql_mode='ONLY_FULL_GROUP_BY'; Query OK, 0 rows affected (0.00 sec) #查看MySQL 5.7默认的sql_mode如下: mysql> select @@global.sql_mode; +--------------------+ | @@global.sql_mode | +--------------------+ | ONLY_FULL_GROUP_BY | +--------------------+ 1 row in set (0.00 sec) mysql> exit;#设置成功后,一定要退出,然后重新登录方可生效 Bye
select * from emp group by post; #报错 ERROR 1054 (42S22): Unknown column 'post' in 'group statement' select post from employee group by post; +-----------+ | post | +-----------+ | operation | | sale | | teacher | | xx | +-----------+
(3)聚合函数
max()求最大值 min()求最小值 avg()求平均值 sum() 求和 count() 求总个数
group_concat()将每个组的所有指定字段列出来
#强调:聚合函数聚合的是组的内容,若是没有分组,则默认一组 # 每个部门有多少个员工 select post,count(id) from employee group by post; # 每个部门的最高薪水 select post,max(salary) from employee group by post; # 每个部门的最低薪水 select post,min(salary) from employee group by post; # 每个部门的平均薪水 select post,avg(salary) from employee group by post; # 每个部门的所有薪水 select post,sum(age) from employee group by post;
#列出每个职位的所有人的名字 select post,group_concat(name) from employee group by post; #将post分组,再根据grouo_concat列出每组所有人的名字 +-----------+----------------------+ | post | group_concat(name) | +-----------+----------------------+ | operation | wo,wi,wu,wy,wt | | sale | wh,wg,wf,wd,ws | | teacher | wa,wy,wt,wr,we,ww,wq | | xx | wk | +-----------+----------------------+ 4 rows in set (0.00 sec)
(4)HAVING过滤
HAVING与WHERE不一样的地方在于 #!!!执行优先级从高到低:where > group by > having #1. Where 发生在分组group by之前,因而Where中可以有任意字段,但是绝对不能使用聚合函数。 #2. Having只能发生在分组group by之后,因而Having中可以使用分组的字段,无法直接取到其他字段,可以使用聚合函数
(5)order by 查询排序
SELECT * FROM employee ORDER BY age; #排序默认升序 SELECT * FROM employee ORDER BY age ASC; #ASC 升序 SELECT * FROM employee ORDER BY age DESC; #DESC降序 #按多列排序:先按照age升序排序,如果年纪相同,则按照id降序 SELECT * from employee ORDER BY age ASC, id DESC;
limit 限制查询的记录数:
SELECT * FROM employee ORDER BY salary DESC LIMIT 3; #默认初始位置为0 SELECT * FROM employee ORDER BY salary DESC LIMIT 0,5; #从第0开始,即先查询出第一条,然后包含这一条在内往后查5条 SELECT * FROM employee ORDER BY salary DESC LIMIT 5,5; #从第5开始,即先查询出第6条,然后包含这一条在内往后查5条 第一个5是位置,第二个5是取的个数
多表查询
- 多表连接查询
- 符合条件连接查询
- 子查询
多表连接查询
准备两张表,部门表(bumen)、员工表(yuangong)
create table department( id int, name varchar(20)); create table yuangong(id int primary key auto_increment,
name varchar(20),
sex enum('male','female') not null default 'male',
age int,
dep_id int);
#插入数据
insert into bumen values (200,'技术'), (201,'人力资源'), (202,'销售'), (203,'运营'); insert into yuangong(name,sex,age,dep_id) values ('egon','male',18,200), ('alex','female',48,201), ('wupeiqi','male',38,201), ('yuanhao','female',28,202), ('nvshen','male',18,200), ('xiaomage','female',18,204) ;
# 查看数据
select * from bumen; +------+--------------+ | id | name | +------+--------------+ | 200 | 技术 | | 201 | 人力资源 | | 202 | 销售 | | 203 | 运营 | +------+--------------+ select * from yuangong; +----+----------+--------+------+--------+ | id | name | sex | age | dep_id | +----+----------+--------+------+--------+ | 1 | egon | male | 18 | 200 | | 2 | alex | female | 48 | 201 | | 3 | wupeiqi | male | 38 | 201 | | 4 | yuanhao | female | 28 | 202 | | 5 | nvshen | male | 18 | 200 | | 6 | xiaomage | female | 18 | 204 | +----+----------+--------+------+--------+
外链接语法
SELECT 字段列表
FROM 表1 INNER|LEFT|RIGHT JOIN 表2
ON 表1.字段 = 表2.字段;
第一种情况交叉连接:不适用任何匹配条件。生成笛卡尔积
select * from yuangong,bumen; +----+----------+--------+------+--------+------+--------------+ | id | name | sex | age | dep_id | id | name | +----+----------+--------+------+--------+------+--------------+ | 1 | egon | male | 18 | 200 | 200 | 技术 | | 1 | egon | male | 18 | 200 | 201 | 人力资源 | | 1 | egon | male | 18 | 200 | 202 | 销售 | | 1 | egon | male | 18 | 200 | 203 | 运营 | | 2 | alex | female | 48 | 201 | 200 | 技术 | | 2 | alex | female | 48 | 201 | 201 | 人力资源 | | 2 | alex | female | 48 | 201 | 202 | 销售 | | 2 | alex | female | 48 | 201 | 203 | 运营 | | 3 | wupeiqi | male | 38 | 201 | 200 | 技术 | | 3 | wupeiqi | male | 38 | 201 | 201 | 人力资源 | | 3 | wupeiqi | male | 38 | 201 | 202 | 销售 | | 3 | wupeiqi | male | 38 | 201 | 203 | 运营 | | 4 | yuanhao | female | 28 | 202 | 200 | 技术 | | 4 | yuanhao | female | 28 | 202 | 201 | 人力资源 | | 4 | yuanhao | female | 28 | 202 | 202 | 销售 | | 4 | yuanhao | female | 28 | 202 | 203 | 运营 | | 5 | nvshen | male | 18 | 200 | 200 | 技术 | | 5 | nvshen | male | 18 | 200 | 201 | 人力资源 | | 5 | nvshen | male | 18 | 200 | 202 | 销售 | | 5 | nvshen | male | 18 | 200 | 203 | 运营 | | 6 | xiaomage | female | 18 | 204 | 200 | 技术 | | 6 | xiaomage | female | 18 | 204 | 201 | 人力资源 | | 6 | xiaomage | female | 18 | 204 | 202 | 销售 | | 6 | xiaomage | female | 18 | 204 | 203 | 运营 | +----+----------+--------+------+--------+------+--------------+
内连接:只连接匹配的行
找两张表共有的部分,相当于利用条件从笛卡尔积结果中筛选出了匹配的结果
select * from yuangong inner join bumen on yuangong.dep_id=bumen.id; +----+---------+--------+------+--------+------+--------------+ | id | name | sex | age | dep_id | id | name | +----+---------+--------+------+--------+------+--------------+ | 1 | egon | male | 18 | 200 | 200 | 技术 | | 2 | alex | female | 48 | 201 | 201 | 人力资源 | | 3 | wupeiqi | male | 38 | 201 | 201 | 人力资源 | | 4 | yuanhao | female | 28 | 202 | 202 | 销售 | | 5 | nvshen | male | 18 | 200 | 200 | 技术 | +----+---------+--------+------+--------+------+--------------+ #上述sql等同于 select * from yuangong,bumen where yuangong.dep_id=bumen.id; +----+---------+--------+------+--------+------+--------------+ | id | name | sex | age | dep_id | id | name | +----+---------+--------+------+--------+------+--------------+ | 1 | egon | male | 18 | 200 | 200 | 技术 | | 2 | alex | female | 48 | 201 | 201 | 人力资源 | | 3 | wupeiqi | male | 38 | 201 | 201 | 人力资源 | | 4 | yuanhao | female | 28 | 202 | 202 | 销售 | | 5 | nvshen | male | 18 | 200 | 200 | 技术 | +----+---------+--------+------+--------+------+--------------+
外链接之左连接:优先显示左表全部记录
#以左表为准,即找出所有员工信息,当然包括没有部门的员工 #本质就是:在内连接的基础上增加左边有,右边没有的结果 select * from yuangong left join bumen on yuangong.dep_id=bumen.id; +----+----------+--------+------+--------+------+--------------+ | id | name | sex | age | dep_id | id | name | +----+----------+--------+------+--------+------+--------------+ | 1 | egon | male | 18 | 200 | 200 | 技术 | | 5 | nvshen | male | 18 | 200 | 200 | 技术 | | 2 | alex | female | 48 | 201 | 201 | 人力资源 | | 3 | wupeiqi | male | 38 | 201 | 201 | 人力资源 | | 4 | yuanhao | female | 28 | 202 | 202 | 销售 | | 6 | xiaomage | female | 18 | 204 | NULL | NULL | +----+----------+--------+------+--------+------+--------------+
外链接之右连接:优先显示右表全部记录
#以右表为准,即找出所有部门信息,包括没有员工的部门 #本质就是:在内连接的基础上增加右边有,左边没有的结果 select * from yuangong right join bumen on yuangong.dep_id=bumen.id; +------+---------+--------+------+--------+------+--------------+ | id | name | sex | age | dep_id | id | name | +------+---------+--------+------+--------+------+--------------+ | 1 | egon | male | 18 | 200 | 200 | 技术 | | 2 | alex | female | 48 | 201 | 201 | 人力资源 | | 3 | wupeiqi | male | 38 | 201 | 201 | 人力资源 | | 4 | yuanhao | female | 28 | 202 | 202 | 销售 | | 5 | nvshen | male | 18 | 200 | 200 | 技术 | | NULL | NULL | NULL | NULL | NULL | 203 | 运营 | +------+---------+--------+------+--------+------+--------------+
全外连接:显示左右两个表全部记录(了解)
#外连接:在内连接的基础上增加左边有右边没有的和右边有左边没有的结果 #注意:mysql不支持全外连接 full JOIN #强调:mysql可以使用此种方式间接实现全外连接 select * from yuangong left join bumen on yuangong.dep_id = bumen.id union all select * from yuangong right join bumen on yuangong.dep_id = bumen.id; +------+----------+--------+------+--------+------+--------------+ | id | name | sex | age | dep_id | id | name | +------+----------+--------+------+--------+------+--------------+ | 1 | egon | male | 18 | 200 | 200 | 技术 | | 5 | nvshen | male | 18 | 200 | 200 | 技术 | | 2 | alex | female | 48 | 201 | 201 | 人力资源 | | 3 | wupeiqi | male | 38 | 201 | 201 | 人力资源 | | 4 | yuanhao | female | 28 | 202 | 202 | 销售 | | 6 | xiaomage | female | 18 | 204 | NULL | NULL | | 1 | egon | male | 18 | 200 | 200 | 技术 | | 2 | alex | female | 48 | 201 | 201 | 人力资源 | | 3 | wupeiqi | male | 38 | 201 | 201 | 人力资源 | | 4 | yuanhao | female | 28 | 202 | 202 | 销售 | | 5 | nvshen | male | 18 | 200 | 200 | 技术 | | NULL | NULL | NULL | NULL | NULL | 203 | 运营 | +------+----------+--------+------+--------+------+--------------+ select * from yuangong left join bumen on yuangong.dep_id = bumen.id union select * from yuangong right join bumen on yuangong.dep_id = bumen.id; +------+----------+--------+------+--------+------+--------------+ | id | name | sex | age | dep_id | id | name | +------+----------+--------+------+--------+------+--------------+ | 1 | egon | male | 18 | 200 | 200 | 技术 | | 5 | nvshen | male | 18 | 200 | 200 | 技术 | | 2 | alex | female | 48 | 201 | 201 | 人力资源 | | 3 | wupeiqi | male | 38 | 201 | 201 | 人力资源 | | 4 | yuanhao | female | 28 | 202 | 202 | 销售 | | 6 | xiaomage | female | 18 | 204 | NULL | NULL | | NULL | NULL | NULL | NULL | NULL | 203 | 运营 | +------+----------+--------+------+--------+------+--------------+ #注意 union与union all的区别:union会去掉相同的纪录
符合条件链接查询
以内连接的方式查询yuangong和bumen表,并且yuangong表中的age字段值必须大于25,即找出年龄大于25岁的员工以及员工所在的部门
select yuangong.name,bumen.name from yuangong inner join bumen on yuangong.dep_id = bumen.id where age > 25; +---------+--------------+ | name | name | +---------+--------------+ | alex | 人力资源 | | wupeiqi | 人力资源 | | yuanhao | 销售 | +---------+--------------+
以内连接的方式查询employee和department表,并且以age字段的升序方式显示。
select yuangong.name,bumen.name from yuangong inner join bumen on yuangong.dep_id = bumen.id and age > 25 order by age asc; +---------+--------------+ | name | name | +---------+--------------+ | yuanhao | 销售 | | wupeiqi | 人力资源 | | alex | 人力资源 | +---------+--------------+
子查询
#1:子查询是将一个查询语句嵌套在另一个查询语句中。 #2:内层查询语句的查询结果,可以为外层查询语句提供查询条件。 #3:子查询中可以包含:IN、NOT IN、ANY、ALL、EXISTS 和 NOT EXISTS等关键字 #4:还可以包含比较运算符:= 、 !=、> 、<等
带in关键字的子查询
#查询平均年龄在25岁以上的部门名 select id,name from bumen where id in (select dep_id from yuangong where age > 25); +------+--------------+ | id | name | +------+--------------+ | 201 | 人力资源 | | 202 | 销售 | +------+--------------+ # 查看技术部员工姓名 select name from yuangong where dep_id in (select id from bumen where name = '技术'); +--------+ | name | +--------+ | egon | | nvshen | +--------+ #查看不足1人的部门名 select name from bumen where id not in (select dep_id from yuangong group by dep_id); +--------+ | name | +--------+ | 运营 | +--------+
带比较运算符的子查询
#比较运算符:=、!=、>、>=、<、<=、<> #查询大于所有人平均年龄的员工名与年龄 select name,age from yuangong where age > (select avg(age) from yuangong); +---------+------+ | name | age | +---------+------+ | alex | 48 | | wupeiqi | 38 | +---------+------+
带EXISTS关键字的子查询
#EXISTS关字键字表示存在。在使用EXISTS关键字时,内层查询语句不返回查询的记录。而是返回一个真假值。True或False #当返回True时,外层查询语句将进行查询;当返回值为False时,外层查询语句不进行查询 #department表中存在dept_id=203,Ture select * from employee where exists (select id from department where id=200); #即exists 对应的查询语句如果查得出来就执行前边的sql,如果查不出来就不执行
pymysql模块
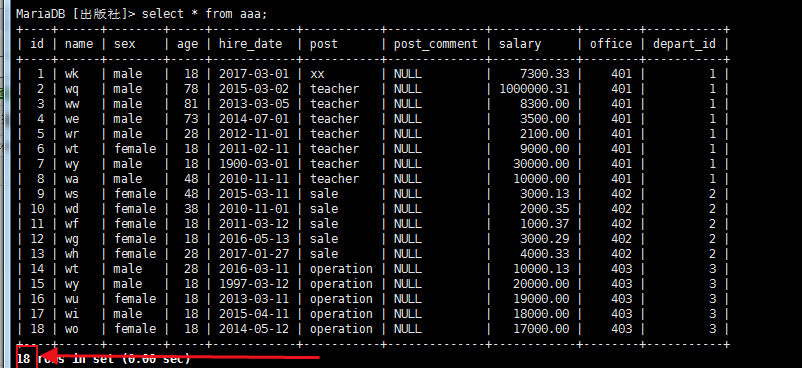
import pymysql # 创建连接 conn = pymysql.connect(host='39.96.90.45', port=3306, user='root', password='123456', db='出版社', charset='utf8') # 创建游标 cur = conn.cursor() # 执行sql语句 c = cur.execute('select * from aaa') print(c) # 关闭游标 关闭连接对象 cur.close() conn.close() 18 #查询结果为18这个18为下边图里的18
execute()之sql注入
#正常输入 wk xx import pymysql name = input('>>>>') post = input('>>>>') # 创建连接 conn = pymysql.connect(host='39.96.90.45', port=3306, user='root', password='123456', db='出版社', charset='utf8') # 创建游标 cur = conn.cursor() # 执行sql语句 c = cur.execute("select * from aaa where name = '%s'and post='%s'" % (name, post)) print(c) # 关闭游标 关闭连接对象 cur.close() conn.close() >>>>wk >>>>xx 1
#sql 注入 import pymysql name = input('>>>>') post = input('>>>>') # 创建连接 conn = pymysql.connect(host='39.96.90.45', port=3306, user='root', password='123456', db='出版社', charset='utf8') # 创建游标 cur = conn.cursor() # 执行sql语句 c = cur.execute("select * from aaa where name = '%s'and post='%s'" % (name, post)) print(c) # 关闭游标 关闭连接对象 cur.close() conn.close() >>>>wk' -- weqqwqw #sql注入, --为注释 输入wk' 等于说只有条件 name = 'wk' 后边的代码被 --注释掉了 >>>>qeq 1
#甚至不需要name也可以查询到 >>>>weqeqw' or 1=1 -- wqeqw #前边name随便输 或者1=1条件为真 后边注释掉 >>>> 18
解决方法:
改写为(execute帮我们做字符串拼接,我们无需且一定不能再为%s加引号了)
import pymysql name = input('>>>>') post = input('>>>>') # 创建连接 conn = pymysql.connect(host='39.96.90.45', port=3306, user='root', password='123456', db='出版社', charset='utf8') # 创建游标 cur = conn.cursor() # 执行sql语句 c = cur.execute("select * from aaa where name = %s and post=%s",[name,post] ) #这里%s去掉空额,后边列表里接收参数这样在输入注释就查询为空了 print(c) # 关闭游标 关闭连接对象 cur.close() conn.close()
>>>>weqeqw' or 1=1 -- wqeqw >>>> 0 #结果为空
增删改查
commit()方法:在数据库里增、删、改的时候,必须要进行提交,否则插入的数据不生效。
import pymysql name = input('>>>>') # 创建连接 conn = pymysql.connect(host='39.96.90.45', port=3306, user='root', password='123456', db='出版社', charset='utf8') # 创建游标 cur = conn.cursor() # 执行sql语句 增 cur.execute("insert into book(name) values(%s)", [name]) #同时插入多条数据 cur.executemany("insert into book(name) values(%s)", ['xixi','hehe','heihei']) #改删 只需要更改sql语句 #一定要commit提交 conn.commit() # 关闭游标 关闭连接对象 cur.close() conn.close()
查
fetchone():获取一行数据,第二次用获得第二行; fetchall():获取所有行数据源 fetchmany(4):获取4行数据
fetchone 查一个
import pymysql # 创建连接 conn = pymysql.connect(host='39.96.90.45', port=3306, user='root', password='123456', db='出版社', charset='utf8') # 创建游标 cur = conn.cursor() # 执行sql语句 cur.execute("select * from book") print(cur.fetchone()) #只查一行 print(cur.fetchone()) print(cur.fetchone()) print(cur.fetchone()) #一定要commit提交 conn.commit() # 关闭游标 关闭连接对象 cur.close() conn.close() (1, '九阳神功') (2, '九阴真经') (3, '九阴白骨爪') (4, '独孤九剑')
fetchall查所有
import pymysql # 创建连接 conn = pymysql.connect(host='39.96.90.45', port=3306, user='root', password='123456', db='出版社', charset='utf8') # 创建游标 cur = conn.cursor() # 执行sql语句 cur.execute("select * from book") print(cur.fetchall()) #一定要commit提交 conn.commit() # 关闭游标 关闭连接对象 cur.close() conn.close() ((1, '九阳神功'), (2, '九阴真经'), (3, '九阴白骨爪'), (4, '独孤九剑'), (5, '降龙十巴掌'), (6, '葵花宝典'), (7, 'wqwe'), (8, '312'), (9, 'xixi'), (10, 'hehe'), (11, 'heihei'))
fetchmany(x):获取多少行数据
import pymysql # 创建连接 conn = pymysql.connect(host='39.96.90.45', port=3306, user='root', password='123456', db='出版社', charset='utf8') # 创建游标 cur = conn.cursor() # 执行sql语句 cur.execute("select * from book") print(cur.fetchmany(4)) #一定要commit提交 conn.commit() # 关闭游标 关闭连接对象 cur.close() conn.close() ((1, '九阳神功'), (2, '九阴真经'), (3, '九阴白骨爪'), (4, '独孤九剑'))
默认情况下,我们获取到的返回值是元组,只能看到每行的数据,却不知道每一列代表的是什么,这个时候可以使用以下方式来返回字典,每一行的数据都会生成一个字典:
cursor = conn.cursor(cursor=pymysql.cursors.DictCursor) #在实例化的时候,将属性cursor设置为pymysql.cursors.DictCursor
import pymysql # 创建连接 conn = pymysql.connect(host='39.96.90.45', port=3306, user='root', password='123456', db='出版社', charset='utf8') # 创建游标 cur = conn.cursor(cursor=pymysql.cursors.DictCursor) #这样得到的数据就是个字典 # 执行sql语句 cur.execute("select * from book") print(cur.fetchmany(4)) #一定要commit提交 conn.commit() # 关闭游标 关闭连接对象 cur.close() conn.close() [{'id': 1, 'name': '九阳神功'}, {'id': 2, 'name': '九阴真经'}, {'id': 3, 'name': '九阴白骨爪'}, {'id': 4, 'name': '独孤九剑'}]
sql内置函数
now()获取当前时间的内置函数
insert into biao1 values(now(),now(),now(),now()); select * from biao1; +------------+----------+---------------------+------+ | d | t | dt | y | +------------+----------+---------------------+------+ | 2019-01-26 | 12:46:36 | 2019-01-26 12:46:36 | 2019 | +------------+----------+---------------------+------+
char_length()将键传入函数查看对应的值所占的字符的长度
select * from biao2; +-----------+------------+ | x | y | +-----------+------------+ | 呵呵哒 | 呵呵哒 | +-----------+------------+ select x,char_length(x),y,char_length(y) from biao2; +-----------+----------------+------------+----------------+ | x | char_length(x) | y | char_length(y) | +-----------+----------------+------------+----------------+ | 呵呵哒 | 3 | 呵呵哒 | 4 | +-----------+----------------+------------+----------------+

 浙公网安备 33010602011771号
浙公网安备 33010602011771号